24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 五、Catalog API
- 3、视图操作
- 1)、官方示例
- 2)、SQL创建HIVE 视图示例
- 1、maven依赖
- 2、代码
- 3、运行结果
- 3)、API创建Hive 视图示例
- 1、maven依赖
- 2、代码
- 3、运行结果
本文简单介绍了通过java api操作视图,提供了三个示例,即sql实现和java api的两种实现方式。
本文依赖flink和hive、hadoop集群能正常使用。
本文示例java api的实现是通过Flink 1.13.5版本做的示例,SQL 如果没有特别说明则是Flink 1.17版本。
五、Catalog API
3、视图操作
1)、官方示例
// create view
catalog.createTable(new ObjectPath("mydb", "myview"), new CatalogViewImpl(...), false);// drop view
catalog.dropTable(new ObjectPath("mydb", "myview"), false);// alter view
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogViewImpl(...), false);// rename view
catalog.renameTable(new ObjectPath("mydb", "myview"), "my_new_view", false);// get view
catalog.getTable("myview");// check if a view exist or not
catalog.tableExists("mytable");// list views in a database
catalog.listViews("mydb");2)、SQL创建HIVE 视图示例
1、maven依赖
properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.13.6</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope> </dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><!-- blink执行计划,1.11+默认的 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version><scope>provided</scope> </dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><!-- flink连接器 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>${flink.version}</version><scope>provided</scope> </dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-metastore</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version><scope>provided</scope> </dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version><scope>provided</scope><!--<version>8.0.20</version> --></dependency><!-- 日志 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.44</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency></dependencies><build><sourceDirectory>src/main/java</sourceDirectory><plugins><!-- 编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>1.8</source><target>1.8</target><!--<encoding>${project.build.sourceEncoding}</encoding> --></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.18.1</version><configuration><useFile>false</useFile><disableXmlReport>true</disableXmlReport><includes><include>**/*Test.*</include><include>**/*Suite.*</include></includes></configuration></plugin><!-- 打包插件(会包含所有依赖) --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><!-- zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF --><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- 设置jar包的入口类(可选) --><mainClass> org.table_sql.TestHiveViewBySQLDemo</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
2、代码
package org.table_sql;import java.util.HashMap;
import java.util.List;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogView;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;/*** @author alanchan**/
public class TestHiveViewBySQLDemo {public static final String tableName = "viewtest";public static final String hive_create_table_sql = "CREATE TABLE " + tableName + " (\n" + " id INT,\n" + " name STRING,\n" + " age INT" + ") " + "TBLPROPERTIES (\n" + " 'sink.partition-commit.delay'='5 s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + " 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String moduleName = "myhive";String hiveVersion = "3.1.2";tenv.loadModule(moduleName, new HiveModule(hiveVersion));String name = "alan_hive";String defaultDatabase = "default";String databaseName = "viewtest_db";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog(name, hiveCatalog);tenv.useCatalog(name);tenv.listDatabases();hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {}, true);// tenv.executeSql("create database "+databaseName);tenv.useDatabase(databaseName);// 创建第一个视图viewName_byTableString selectSQL = "select * from " + tableName;String viewName_byTable = "test_view_table_V";String createViewSQL = "create view " + viewName_byTable + " as " + selectSQL;tenv.getConfig().setSqlDialect(SqlDialect.HIVE);tenv.executeSql(hive_create_table_sql);// tenv.getConfig().setSqlDialect(SqlDialect.DEFAULT);String insertSQL = "insert into " + tableName + " values (1,'alan',18)";tenv.executeSql(insertSQL);tenv.executeSql(createViewSQL);tenv.listViews();CatalogView catalogView = (CatalogView) hiveCatalog.getTable(new ObjectPath(databaseName, viewName_byTable));List<Row> results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + viewName_byTable).collect());for (Row row : results) {System.out.println("test_view_table_V: " + row.toString());}// 创建第二个视图String viewName_byView = "test_view_view_V";tenv.executeSql("create view " + viewName_byView + " (v2_id,v2_name,v2_age) comment 'test_view_view_V comment' as select * from " + viewName_byTable);catalogView = (CatalogView) hiveCatalog.getTable(new ObjectPath(databaseName, viewName_byView));results = CollectionUtil.iteratorToList(tenv.executeSql("select * from " + viewName_byView).collect());System.out.println("test_view_view_V comment : " + catalogView.getComment());for (Row row : results) {System.out.println("test_view_view_V : " + row.toString());}tenv.executeSql("drop database " + databaseName + " cascade");}}3、运行结果
前提是flink的集群可用。使用maven打包成jar。
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.2-SNAPSHOT.jarHive Session ID = ed6d5c9b-e00f-4881-840d-24c72aba6db7
Hive Session ID = 14445dc8-1f08-4f0f-bb45-aba8c6f52174
Job has been submitted with JobID bff7b59367bd5de6e778b442c4cc4404
Hive Session ID = 4c16f4fc-4c10-4353-b322-e6633e3ebe3d
Hive Session ID = 57949f09-bdcb-497f-a85c-ed9766fc4ce3
2023-10-13 02:42:24,891 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 0
Job has been submitted with JobID 80e48bb76e3d580412fdcdc434a8a979
test_view_table_V: +I[1, alan, 18]
Hive Session ID = a73d5b93-2129-4159-ad5e-0814df77e987
Hive Session ID = e4ae1a79-4d5e-4835-81de-ebc2041eedf9
2023-10-13 02:42:33,648 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 1
Job has been submitted with JobID c228d9ce3bdce91dc68bff75d14db1e5
test_view_view_V comment : test_view_view_V comment
test_view_view_V : +I[1, alan, 18]
Hive Session ID = e4a38393-d760-4bd3-8d8b-864cbe0daba73)、API创建Hive 视图示例
通过api创建视图相对比较麻烦,且存在版本更新的过期方法情况。
通过TableSchema和CatalogViewImpl创建视图则已过期,当前推荐使用通过CatalogView和ResolvedSchema来创建视图。
另外需要注意的是下面两个参数的区别
String originalQuery,原始的sql
String expandedQuery,带有数据库名称的表,甚至包含hivecatalog
例如:如果使用default作为默认的数据库,查询语句为select * from test1,则
originalQuery = ”select name,value from test1“即可,
expandedQuery = “selecttest1.name, test1.value from default.test1”
修改、删除视图等操作比较简单,不再赘述。
1、maven依赖
此处使用的依赖与上示例一致,mainclass变成本示例的类,不再赘述。
2、代码
import static org.apache.flink.util.Preconditions.checkNotNull;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogBaseTable;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogView;
import org.apache.flink.table.catalog.CatalogViewImpl;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogView;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.exceptions.TableAlreadyExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
import org.apache.flink.types.Row;
import org.apache.flink.util.CollectionUtil;
import org.apache.flink.table.catalog.CatalogBaseTable;
import org.apache.flink.table.catalog.Column;/*** @author alanchan**/
public class TestHiveViewByAPIDemo {public static final String tableName = "viewtest";public static final String hive_create_table_sql = "CREATE TABLE " + tableName + " (\n" + " id INT,\n" + " name STRING,\n" + " age INT" + ") " + "TBLPROPERTIES (\n" + " 'sink.partition-commit.delay'='5 s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + " 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);System.setProperty("HADOOP_USER_NAME", "alanchan");String moduleName = "myhive";String hiveVersion = "3.1.2";tenv.loadModule(moduleName, new HiveModule(hiveVersion));String catalogName = "alan_hive";String defaultDatabase = "default";String databaseName = "viewtest_db";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(catalogName, defaultDatabase, hiveConfDir);tenv.registerCatalog(catalogName, hiveCatalog);tenv.useCatalog(catalogName);tenv.listDatabases();hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {}, true);// tenv.executeSql("create database "+databaseName);tenv.useDatabase(databaseName);tenv.getConfig().setSqlDialect(SqlDialect.HIVE);tenv.executeSql(hive_create_table_sql);String insertSQL = "insert into " + tableName + " values (1,'alan',18)";String insertSQL2 = "insert into " + tableName + " values (2,'alan2',19)";String insertSQL3 = "insert into " + tableName + " values (3,'alan3',20)";tenv.executeSql(insertSQL);tenv.executeSql(insertSQL2);tenv.executeSql(insertSQL3);tenv.getConfig().setSqlDialect(SqlDialect.DEFAULT);String viewName1 = "test_view_table_V";String viewName2 = "test_view_table_V2";ObjectPath path1= new ObjectPath(databaseName, viewName1);//ObjectPath.fromString("viewtest_db.test_view_table_V2")ObjectPath path2= new ObjectPath(databaseName, viewName2);String originalQuery = "SELECT id, name, age FROM "+tableName+" WHERE id >=1 ";
// String originalQuery = String.format("select * from %s",tableName+" WHERE id >=1 ");System.out.println("originalQuery:"+originalQuery);String expandedQuery = "SELECT id, name, age FROM "+databaseName+"."+tableName+" WHERE id >=1 ";
// String expandedQuery = String.format("select * from %s.%s", catalogName, path1.getFullName());System.out.println("expandedQuery:"+expandedQuery);String comment = "this is a comment";// 创建视图,第一种方式(通过TableSchema和CatalogViewImpl),已声明过期 createView1(originalQuery,expandedQuery,comment,hiveCatalog,path1);// 查询视图List<Row> results = CollectionUtil.iteratorToList( tenv.executeSql("select * from " + viewName1).collect());for (Row row : results) {System.out.println("test_view_table_V: " + row.toString());}// 创建视图,第二种方式(通过Schema和ResolvedSchema)createView2(originalQuery,expandedQuery,comment,hiveCatalog,path2);List<Row> results2 = CollectionUtil.iteratorToList( tenv.executeSql("select * from viewtest_db.test_view_table_V2").collect());for (Row row : results2) {System.out.println("test_view_table_V2: " + row.toString());}tenv.executeSql("drop database " + databaseName + " cascade");}static void createView1(String originalQuery,String expandedQuery,String comment,HiveCatalog hiveCatalog,ObjectPath path) throws Exception {TableSchema viewSchema = new TableSchema(new String[]{"id", "name","age"}, new TypeInformation[]{Types.INT, Types.STRING,Types.INT});CatalogBaseTable viewTable = new CatalogViewImpl(originalQuery,expandedQuery,viewSchema, new HashMap(),comment);hiveCatalog.createTable(path, viewTable, false);}static void createView2(String originalQuery,String expandedQuery,String comment,HiveCatalog hiveCatalog,ObjectPath path) throws Exception {ResolvedSchema resolvedSchema = new ResolvedSchema(Arrays.asList(Column.physical("id", DataTypes.INT()),Column.physical("name", DataTypes.STRING()),Column.physical("age", DataTypes.INT())),Collections.emptyList(),null);CatalogView origin = CatalogView.of(Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(),comment,
// String.format("select * from tt"),
// String.format("select * from %s.%s", TEST_CATALOG_NAME, path1.getFullName()),originalQuery,expandedQuery,Collections.emptyMap());CatalogView view = new ResolvedCatalogView(origin, resolvedSchema);
// ObjectPath.fromString("viewtest_db.test_view_table_V2")hiveCatalog.createTable(path, view, false);}}
3、运行结果
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.3-SNAPSHOT.jarHive Session ID = ab4d159a-b2d3-489e-988f-eebdc43d9517
Hive Session ID = 391de19c-5d5a-4a83-a88c-c43cca71fc63
Job has been submitted with JobID a880510032165523f3f2a559c5ab4ec9
Hive Session ID = cb063c31-eaf2-44e3-8fc0-9e8d2a6a3a5d
Job has been submitted with JobID cb05286c404b561306f8eb3969c3456a
Hive Session ID = 8132b36e-c9e2-41a2-8f42-3fe842e0991f
Job has been submitted with JobID 264aef7da1b17598bda159d946827dea
Hive Session ID = 7657be14-8188-4362-84a9-4c84c596021b
2023-10-16 07:21:19,073 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 3
Job has been submitted with JobID 05c2bb7265b0430cb12e00237f18444b
test_view_table_V: +I[1, alan, 18]
test_view_table_V: +I[2, alan2, 19]
test_view_table_V: +I[3, alan3, 20]
Hive Session ID = 7bb01c0d-03c9-413a-9040-c89676cec3b9
2023-10-16 07:21:27,512 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 3
Job has been submitted with JobID 79130d1fe56d88a784980d16e7f1cfb4
test_view_table_V2: +I[1, alan, 18]
test_view_table_V2: +I[2, alan2, 19]
test_view_table_V2: +I[3, alan3, 20]
Hive Session ID = 6d44ea95-f733-4c56-8da4-e2687a4bf945本文简单介绍了通过java api操作视图,提供了三个示例,即sql实现和java api的两种实现方式。
相关文章:
-3)
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
【CNN-GRU预测】基于卷积神经网络-门控循环单元的单维时间序列预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
计算机毕业设计--基于SSM+Vue的物流管理系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

GPT4 Plugins 插件 WebPilot 生成抖音文案
1. 生成抖音文案 1.1. 准备1篇优秀的抖音文案范例 1.2. Promept公式 你是一个有1000万粉丝的抖音主播, 请模仿下面的抖音脚本文案,重新改与一篇文章改写成2分钟的抖音视频脚本, 要求前一部分是十分有争议性的内容,并且能够引发…...
通过核密度分析工具建模,基于arcgis js api 4.27 加载gp服务
一、通过arcmap10.2建模,其中包含三个参数 注意input属性,选择数据类型为要素类: 二、建模之后,加载数据,执行模型,无错误的话,找到执行结果,进行发布gp服务 注意,发布g…...
【vue2高德地图api】02-npm引入插件,在页面中展示效果
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、安装高德地图二、在main.js中配置需要配置2个key值以及1个密钥 三、在页面中使用3.1 新建路由3.2新建vue页面3.2-1 index.vue3.2…...

ai智能语音电销机器人怎么选?
智能语音电销机器人哪家好?如何选择一款智能语音电销机器人?这几年生活中人工智能的普及越来越广泛,就如智能语音机器人在生活当中的应用还是比较方便的,有许多行业都会选择这类的智能语音系统来把工作效率提高上去,随…...

NumPy基础及取值操作
目录 第1关:ndarray对象 相关知识 怎样安装NumPy 什么是ndarray对象 如何实例化ndarray对象 使用array函数实例化ndarray对象 使用zeros,ones,empty函数实例化ndarray对象 代码文件 第2关:形状操作 相关知识 怎样改变n…...

vue webpack/vite的区别
Vue.js 可以与不同的构建工具一起使用,其中两个主要的工具是 Webpack 和 Vite。以下是 Vue.js 与 Webpack 和 Vite 之间的一些主要区别: Vue.js 与 Webpack: 成熟度: Webpack 是一个成熟的构建工具,已经存在多年&…...
多线程下的单例设计模式(新手必看!!!)
在项目中为了避免创建大量的对象,频繁出现gc的问题,单例设计模式闪亮登场。 一、饿汉式 1.1饿汉式 顾名思义就是我们比较饿,每次想吃的时候,都提前为我们创建好。其实我记了好久也没分清楚饿汉式和懒汉式的区别。这里给出我的一…...

JDK 21的新特性总结和分析
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【VR】【Unity】白马VR课堂系列-VR开发核心基础03-项目准备-VR项目设置
【内容】 详细说明 在设置Camera Rig前,我们需要针对VR游戏做一些特别的Project设置。 点击Edit菜单,Project Settings,选中最下方的XR Plugin Management,在右边面板点击Install。 安装完成后,我们需要选中相应安卓平台下的Pico VR套件,关于怎么安装PICO VR插件,请参…...
Windows服务器安装php+mysql环境的经验分享
php mysql环境 下载IIS Php Mysql环境集成包,集成包下载地址: 1、Windows Server 2008 一键安装Web环境包 x64 适用64位操作系统服务器:下载地址:链接: https://pan.baidu.com/s/1MMOOLGll4D7Eb5tBrdTQZw 提取码: btnx 2、Windows Server 2008 一键安装Web环境包 32 适…...

【LeetCode热题100】--287.寻找重复数
287.寻找重复数 方法:使用快慢指针 使用环形链表II的方法解题(142.环形链表II),使用 142 题的思想来解决此题的关键是要理解如何将输入的数组看作为链表。 首先明确前提,整数的数组 nums 中的数字范围是 [1,n]。考虑一…...
)
JUC并发编程——Stream流式计算(基于狂神说的学习笔记)
Stream流式计算 什么是Stream流式计算 Stream流式计算是一种基于数据流的计算模式,它可以对数据进行实时处理和分析,而不需要将所有数据存储在内存中。 Stream流式计算是将数据源中的数据分割成多个小的数据块,然后对每个小的数据块进行并…...
【Eclipse】取消按空格自动补全,以及出现没有src的解决办法
【Eclipse】设置自动提示 教程 根据上方链接,我们已经知道如何设置Eclipse的自动补全功能了,但是有时候敲变量名的时候按空格,本意是操作习惯,不需要自动补全,但是它却给我们自动补全了,这就造成了困扰&…...

ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章
ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章 1、抠图制作透明公章2、ps自动化批量抠图制作透明公章 1、抠图制作透明公章 抠图过程看视频 直接访问视频连接可以选高清画质 https://live.csdn.net/v/335752 ps抠图制作透明公章 2、ps自动化批量抠图制作透明公章 …...

Fetch与Axios数据请求
什么是Polyfill? Polyfill是一个js库,主要抚平不同浏览器之间对js实现的差异。比如,html5的storage(session,local), 不同浏览器,不同版本,有些支持,有些不支持。Polyfill(Polyfill有很多,在Gi…...
论文阅读-FCD-Net: 学习检测多类型同源深度伪造人脸图像
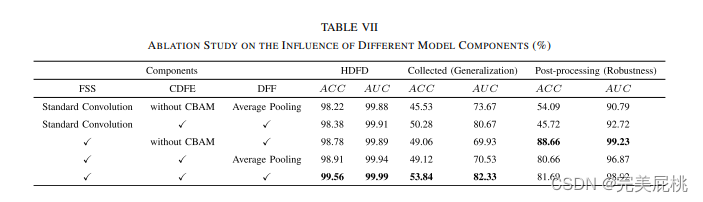
一、论文信息 论文题目:FCD-Net: Learning to Detect Multiple Types of Homologous Deepfake Face Images 作者团队:Ruidong Han , Xiaofeng Wang , Ningning Bai, Qin Wang, Zinian Liu, and Jianru Xue (西安理工大学,西安交…...
云服务器快速搭建网站
目录 安装Apache Docker 安装 Mysql 安装 Docker 依赖包 添加 Docker 官方仓库 安装 Docker 引擎 启动 Docker 服务并设置开机自启 验证 Docker 是否成功安装 拉取 MySQL 镜像 查看本地镜像 运行容器 停止和启动容器 列出正在运行的容器 安装PHP环境 搭建网站 安装…...

AD导出Gerber文件时,单位选英寸格式选2:5?一文讲透这些‘祖传’设置背后的原因
为什么PCB工程师至今仍在使用英寸和2:5格式导出Gerber文件? 在PCB设计领域,有一个看似奇怪却普遍存在的现象:即使全球绝大多数国家采用公制单位,工程师们在导出Gerber文件时却坚持使用英制单位(英寸)&#…...

VSCode Log Viewer插件进阶:除了看syslog,还能这样监控你的Nginx/Docker应用日志
VSCode Log Viewer插件进阶:全栈日志监控实战指南 当你同时维护着系统服务、Web服务器和容器化应用时,日志往往散落在不同角落。每次排查问题都要在多个终端窗口间切换,既低效又容易遗漏关键线索。今天我们就来解锁VSCode Log Viewer插件的高…...

废物利用实战:把吃灰的中兴B860AV1.1-T刷成Armbian服务器,跑Docker、挂小雅
旧机顶盒重生计划:中兴B860AV1.1-T改造家庭服务器全指南 当家里闲置的机顶盒积满灰尘时,大多数人会选择丢弃或闲置。但你可能不知道,这些被淘汰的设备往往隐藏着惊人的潜力——只需简单改造,就能变身为一台7x24小时运行的低功耗家…...

从零搭建CXL设备模拟器:手把手实现CXL.cache协议的关键Opcode
从零搭建CXL设备模拟器:手把手实现CXL.cache协议的关键Opcode 在异构计算架构快速发展的今天,CXL(Compute Express Link)协议正成为连接CPU与加速器设备的关键纽带。作为CXL三大协议之一,CXL.cache协议通过定义设备与主…...

【AI】了解ChatMemory 底层实现机制
(说实在,看个 七、整体架构总结 就行了) 为何要了解底层原理,其意义在于出问题好排查,写代码时有思路。 基于源码调试与运行时验证,深度拆解ChatMemory 底层实现机制,重点解析 ChatMemoryStor…...

不知道怎么挖漏洞?吐血整理40个网络安全漏洞挖掘姿势,看完不信你还挖不到
各位靓仔,搞网络安全,就像在雷区蹦迪,一不小心就BoomShakalaka!Web漏洞这玩意儿,说白了就是信任危机 验证掉链子。开发者们啊,总是对用户输入、权限边界和系统交互爱的太深,结果翻车了…...

[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit
[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit x install 全面升级:支持 skill 安装、前缀语法、三种自动化模式、AI Agent 友好选项x git ci/commit 支持 AI 自动生成 Conventional Commits 提交信…...

深入解析Android ContentProvider:从基础到高级应用与面试准备
引言 在Android开发中,数据共享和访问控制是构建高效、安全应用的关键。ContentProvider作为Android四大组件之一,专门用于管理结构化数据的共享,提供标准化的接口供应用间安全访问数据。本文将以ContentProvider为核心领域,全面探讨其原理、实现、应用及面试常见问题。文…...
)
Python连接Oracle报DPI-1047?别慌,手把手教你用Instant Client 11g/12c/19c搞定(附环境变量避坑指南)
Python连接Oracle报DPI-1047?手把手教你用Instant Client全版本配置指南 当你满怀期待地在Python中写下import cx_Oracle,准备连接公司数据库大展身手时,突然跳出的DPI-1047: Cannot locate a 64-bit Oracle Client library错误提示就像一盆冷…...

杰理微蓝牙芯片AC696系列入门
1.文章背景 此篇文章以ac696n_soundbox_sdk_v1.7.0版本进行入门讲解: 写这篇文章的目的是因为自己在尝试入门杰理微的时候遇到了好多的问题点,想尝试用买到的开发板来驱动一颗LED闪烁却一直没有按自己想象的逻辑成功跑出效果,在网上到处翻找手…...