k8s基础 随笔
写个笔记,后面再完善
部署第一个应用
为什么先实战水平扩缩?因为这个最简单,首先来部署一个喜闻乐见的nginx
kubectl create deployment web --image=nginx:1.14 --dry-run -o yaml > web.yaml- --dry-run表示试运行,试一下看行不行,但是不运行
- -o yaml表示以yaml格式输出
- > web.yaml表示将输出的内容重定向到web.yaml文件中
这句话可以放心执行了,执行之后看看web.yaml文件里面有些啥
apiVersion: apps/v1 # 表示资源版本号为apps/v1
kind: Deployment # 表示这是一个Deployment
metadata: # 一些元数据信息creationTimestamp: nulllabels: # 标签,可以随便定义app: webname: web # 这个资源的名字
spec: # 资源的描述或者规格replicas: 1 # 副本数量selector: # 选择器matchLabels: # 需要匹配的标签app: web # 标签的具体键值对strategy: {}template: # 模板。表示Pod的生成规则metadata:creationTimestamp: nulllabels:app: webspec: containers:- image: nginx:1.14 #指定镜像文件name: nginxresources: {}
status: {}用下面的命令应用web.yaml,web.yaml声明了一个Deployment和一个Pod
kubectl apply -f web.yaml执行完后以后可以通过以下命令查看Deployment和Pod
kubectl get deploy,po -o wide结果如下
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/web 1/1 1 1 2m40s nginx nginx:1.14 app=webNAME READY STATUS RESTARTS AGE IP NODE ...
pod/web-5bb6fd4c98-lg555 1/1 Running 0 2m40s 10.100.255.120 my-node ...可以看到资源已经建立起来了,运行在Worker节点中,尝试访问一下Pod的IP
curl 10.100.255.120有如下nginx的标准返回说明应用已经部署完毕
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
</html>有没有感觉这一路下来挺麻烦的,yaml文件还那么长,还不如无脑docker run呢,别急,在后面扩缩容的时候就可以看到它的威力了,当然也可以用最开始的命令来执行kubectl create deployment web --image=nginx:1.14,测试可以,在生产环境中强烈不建议这么做。
但是现在还不能在外面访问
先要创建一个Service
要访问部署在 Kubernetes 中的应用程序,你通常需要使用 Service 对象来公开应用程序,以便从外部网络访问。以下是创建一个 Service 来访问你的
webdeployment 的一般步骤:
- 创建一个 Service 对象:
kubectl create service nodeport web --tcp=80:80
这将创建一个 NodePort 类型的 Service,它将监听节点上的某个端口(通常在30000-32767之间),并将流量转发到你的 web deployment 的端口80。
- 获取 Service 的访问端口:
kubectl get service web
查找 "PORT(S)" 部分,你会看到 Service 的访问端口,其中 NodePort 是你可以使用的外部端口。
- 访问应用程序:
现在,你可以使用集群的任何节点的 IP 地址和上面步骤中找到的 NodePort 访问你的应用程序。例如,如果你的集群节点的 IP 地址是 192.168.1.100,NodePort 是 31000,你可以在浏览器中输入 http://192.168.1.100:31000 来访问应用程序。
请注意,NodePort Service 在生产环境中可能不是最佳选择,通常会使用 Ingress 控制器来管理外部访问。但对于测试和学习的目的,NodePort 可以用作一种简单的方法来访问应用程序
节点污点
Taint 污点:节点不做普通分配调度,是节点属性,属性值有三个
- NoSchedule:一定不被调度
- PreferNoSchedule:尽量不被调度(也有被调度的几率)
- NoExecute:不会调度,并且还会驱逐Node已有Pod
也就是说,给节点打上污点,那么调度的时候就会根据上面的属性来进行调度,一般来说Master节点的污点值是NoSchedule,查看Master污点值
kubectl describe node my-master | grep Taints可以看到如下输出
Taints: node-role.kubernetes.io/master:NoSchedule这表明无论如何,Pod都不会被调度到Master节点上,也可以用上面弹性伸缩的列子来证明,无论副本多少个,都是在Worker节点上,现在将Master节点上的污点给去掉,用下面的命令
kubectl taint node my-master node-role.kubernetes.io/master:NoSchedule-回显如下,说明污点已经去掉
node/my-master untainted再来扩容一下,为了大概率调度到Master节点上,可以将副本设置多一点
kubectl scale deploy web --replicas=20在查看Pod:kubectl get po -o wide
web-5bb6fd4c98-9rrp2 1/1 Running 0 5m19s 10.100.255.108 my-node <none> ...
web-5bb6fd4c98-fgsfn 1/1 Running 0 5m19s 10.100.0.200 my-master <none> ...
web-5bb6fd4c98-g7p4w 1/1 Running 0 5m19s 10.100.255.112 my-node <none> ...可以看到,一部分节点调度到Master上面去了
先缩容,将污点加回去(用下面的命令)再扩容试试看,可以发现新增加的节点都在Worker节点上了
kubectl taint node my-master node-role.kubernetes.io/master:NoSchedule节点标签选择器
首先删除deploy:kubectl delete deploy web
给master节点打上标签test123_env=prod,标签就是键值对,随便起名儿
kubectl label node my-master test123_env=prod然后在web.yaml中新增nodeSelector声明
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec: replicas: 10 # 副本改多一点selector: matchLabels:app: web strategy: {}template: metadata:labels:app: webspec:containers:- image: nginx:1.14name: nginx# 新增的内容nodeSelector:test123_env: prod
status: {}最后执行,理论上所有Pod都应该被调度到Master节点上,但是发现所有的Pod都被挂起了,没有被调度
web-6897865b86-sp6fh 0/1 Pending 0 30s <none> <none> <none> <none>
web-6897865b86-vkcx2 0/1 Pending 0 30s <none> <none> <none> <none>
web-6897865b86-wvdk6 0/1 Pending 0 30s <none> <none> <none> <none>这是什么原因呢?这是污点在作祟,别忘记了,Master节点的污点值默认是NoSchedule,不允许被调度的,查看一下Master节点的污点值
[root@my-master ~]# kubectl describe node my-master | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule果然是NoSchedule,先去掉污点值
kubectl taint node my-master node-role.kubernetes.io/master:NoSchedule-机器突然有点卡,这应该是在调度Pod了,查看一下果不其然,节点都被调度到了Master上
web-6897865b86-sp6fh 1/1 Running 0 4m2s 10.100.0.208 my-master <none> ...
web-6897865b86-vkcx2 1/1 Running 0 4m2s 10.100.0.209 my-master <none> ...
web-6897865b86-wvdk6 1/1 Running 0 4m2s 10.100.0.213 my-master <none> ...这里还可以得出一个结论,在Pod被调度的时候,节点污点值的优先级是高于节点标签的!
最后还原现场
# 删除deploy
kubectl delete deploy web# 删掉标签
kubectl label node my-master test123_env-# 恢复污点
kubectl taint node my-master node-role.kubernetes.io/master:NoSchedule节点亲和性
亲和性和节点选择器类似,多了操作符表达式:In、NotIn、Exists、Gt、Lt、DoesNotExists,此处就不再演示了,感兴趣的同学自行尝试一下
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec: replicas: 10 # 副本改多一点selector: matchLabels:app: web strategy: {}template: metadata:labels:app: webspec:containers:- image: nginx:1.14name: nginx# 新增的内容affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: test123_envoperator: Invalues:- dev- testpreferreDuringSchedulingIgnoredDuringExecution:- weight: 1preference:- matchExpressions:- key: groupoperator: Invalues:- ttttest
status: {}上面的亲和性表示如下含义
- requiredDuringSchedulingIgnoredDuringExecution:硬亲和,test123_env等于dev或者test,必须满足
- preferreDuringSchedulingIgnoredDuringExecution:软亲和,group等于ttttest,非必须满足
K8S搞这么多策略有啥用呢?又是节点污点、节点标签、Pod调度策略之类的,目的当然是提供最大的灵活性,最终提高整体资源利用率,这就是自动装箱
这里的 affinity 部分用于定义容器在调度到节点时的偏好设置。具体来说,这个配置包括两部分:
-
requiredDuringSchedulingIgnoredDuringExecution:这是一个必需的亲和性规则,它要求容器只能被调度到满足指定条件的节点上。在这个示例中,它要求节点的test123_env标签的值必须是 "dev" 或 "test",否则容器将不会被调度到这些节点。 -
preferreDuringSchedulingIgnoredDuringExecution:这是一个偏好的亲和性规则,它定义了容器倾向于被调度到满足指定条件的节点上。在这个示例中,它定义了一个权重为1的偏好规则,要求节点的group标签的值应为 "ttttest",以增加容器被调度到这些节点的可能性。这并不是一个硬性要求,只是一个偏好设置。
总之,这些亲和性设置帮助 Kubernetes 调度器在将 Pod 调度到节点时考虑节点的标签和属性,以满足或偏好某些条件。这有助于优化应用程序的性能和资源利用。😺
相关文章:

k8s基础 随笔
写个笔记,后面再完善 部署第一个应用 为什么先实战水平扩缩?因为这个最简单,首先来部署一个喜闻乐见的nginx kubectl create deployment web --imagenginx:1.14 --dry-run -o yaml > web.yaml --dry-run表示试运行,试一下看…...
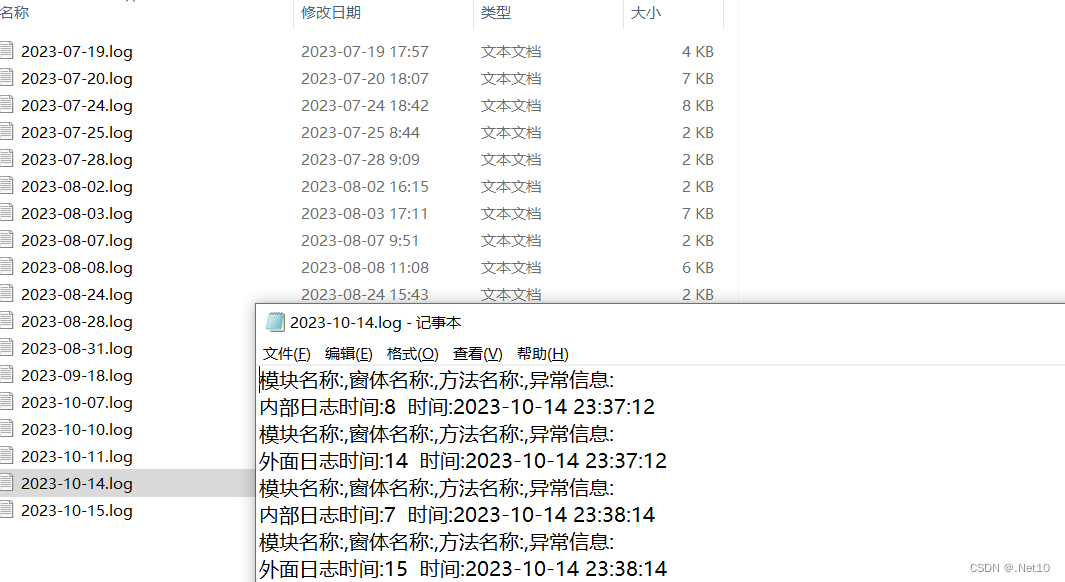
c# 关于某管理业务系统对数据统计问题.
1.业务系统主要的就是功能的稳定,流畅性. 最近客户提出某统计功能数据加载到页面很慢.反映到运维工程师处,运维跟我说之后我(研发), 我看了看代码,有几处代码确实需要优化,统计功能调用了4次服务端,每一次客户端调用服务端的时候返回结果3S左右,有三次调用服务端,一共大约耗时…...

nginx 配置相关详解
目录 Nginx的优点 Nginx简介 Nginx的优点 可以高并发连接 内存消耗少 成本低廉 配置文件非常易懂 稳定性高 内置有健康的检查功能 支持Rewrite重写 支持热部署 Nginx与Apache的对比 Nginx多进程工作原理跟设计 Nginx是如何实现高性能的 事件驱动模型 多进程机制…...

解决spring项目中无法加载resources下文件
解决spring项目中无法加载resources下文件 问题发现问题解决步骤一:检查文件名步骤二:确保测试资源目录步骤三:检查文件路径是否正确 问题发现 在学习Spring过程中,TestContext框架试图检测一个默认的XML资源位置。如果您的类被命…...
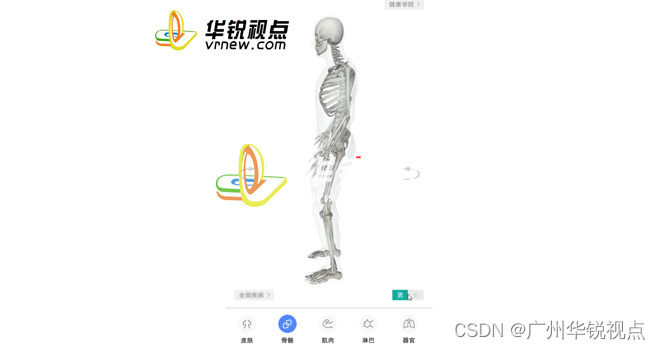
【广州华锐互动】人体血管器官3D动态展示为医学生提供哪些便利?
人体血管器官3D动态展示是一种采用先进的计算机图形技术和立体成像技术,对人体内部结构和功能进行三维可视化的教学方法。这种教学方式以其独特的优势,正在改变传统的解剖学教学模式,为医学教育带来了革新。 首先,3D动态演示能够提…...
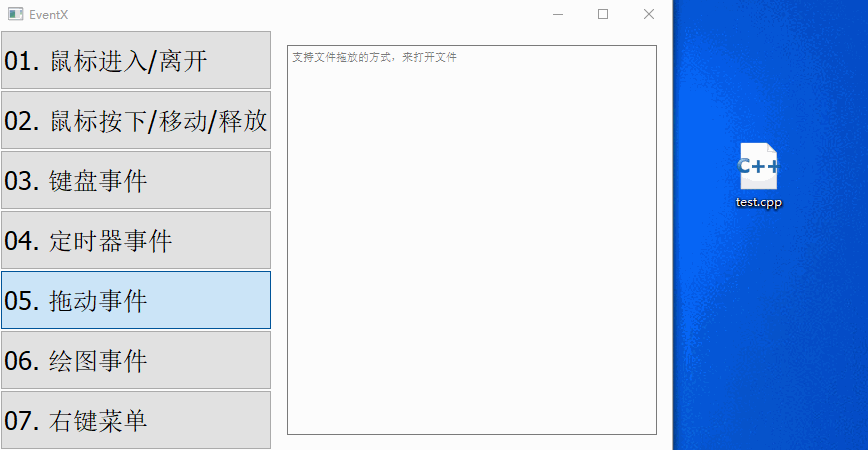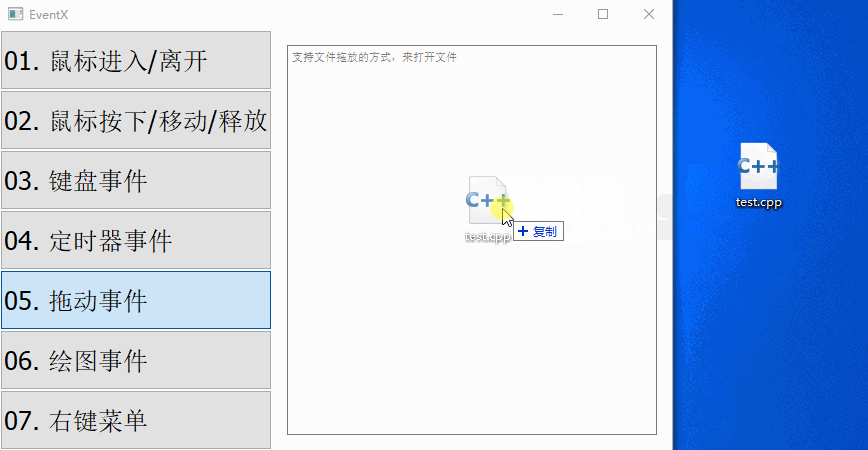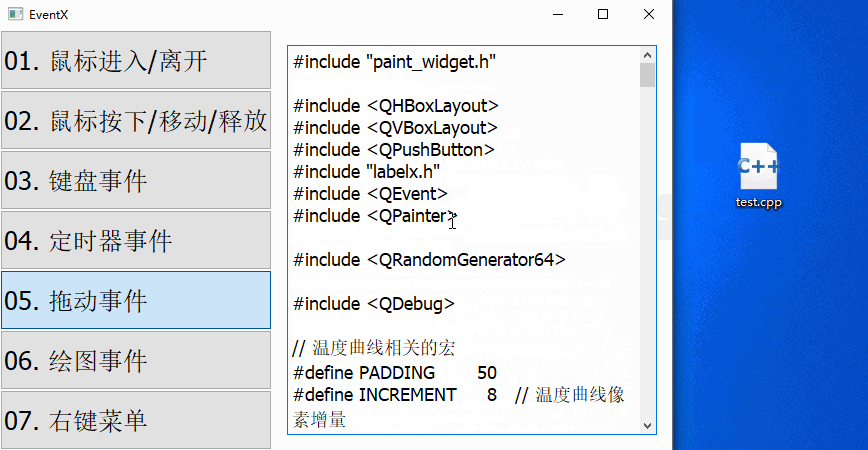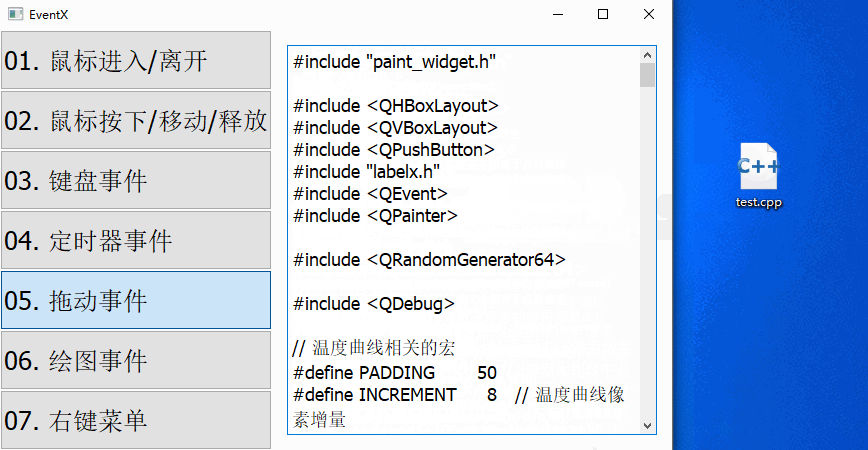
【QT开发笔记-基础篇】| 第四章 事件QEvent | 4.7 拖放事件
本节对应的视频讲解:B_站_链_接 【QT开发笔记-基础篇】 第4章 事件 4.7 拖动事件 本章要实现的整体效果如下: QEvent::DragEnter 当拖动文件进入到窗口/控件中时,触发该事件,它对应的子类是 QDragEnterEvent QEvent::DragLe…...

【Linux】介绍 Docker 的基本概念和优势,以及在应用程序开发中的实际应用
Docker 是一种轻量级的虚拟化技术,它基于 Linux 容器技术,能够在不同平台、不同主机上快速地运行和部署应用程序。Docker 的基本概念包括以下几点: 镜像(Image):Docker 镜像是一个只读的模板,它…...

GUN C/C++ undefined reference to symbol ‘dlclose@@GLIBC_2.2.5‘
编译问题: /usr/bin/ld: ../../3rdParty/lib/libluajit.a(lj_clib.o): undefined reference to symbol dlcloseGLIBC_2.2.5 //usr/lib64/libdl.so.2: error adding symbols: DSO missing from command line collect2: error: ld returned 1 exit status make[1]: …...

RabbitMQ概述,死信队列
RabbitMQ(Rabbit Message Queue)是一个开源的消息队列中间件,它实现了高级消息队列协议(AMQP)并提供可靠的消息传递机制。RabbitMQ 在分布式系统中广泛用于消息传递和事件驱动的架构。以下是一些 RabbitMQ 的重要知识点…...

【开发日常】insmod: error inserting ‘*.ko‘: -1 Unknown symbol in module原理分析
问题的起源是一次面试,面试官询问加载内核的时候,如果insmod失败,且提示Unknown symbol in module。请问我里面的原理是什么呢?为什么内核知道当前缺少的是这个symbol? 想了解下具体的原因。 首先是模拟一个环境。 写…...

圆弧插补【C#】
圆弧: 圆弧插补方法可以通过提供圆弧的起点、终点和半径来画弧。下面是一个用C#实现的圆弧插补方法的示例代码: public void DrawArc(Point startPoint, Point endPoint, int radius, bool isClockwise) {// 计算圆心坐标int centerX (startPoint.X e…...

Redis EmbeddedString
前言 Redis 写入键值对时,首先会先创建一个 RedisObject 对象来存储 Value。 如果写入的 Value 是字符串,那么 Redis 会再根据写入的字符串长度,来创建对应的 sdshdr 来存储字符串,最后把 RedisObject 的 ptr 指针指向 sdshdr。 …...

SpringMVC之WEB-INF下页面跳转@ModelAttributeIDEA tomcat控制台中文乱码问题处理
WEB-INF下页面跳转 ModelAttribute来注解非请求处理方法 用途:预加载数据,会在每个RequestMapping方法执行之前调用。 特点:无需返回视图,返回类型void IDEA tomcat控制台中文乱码问题处理 复制此段代码:-Dfile.e…...
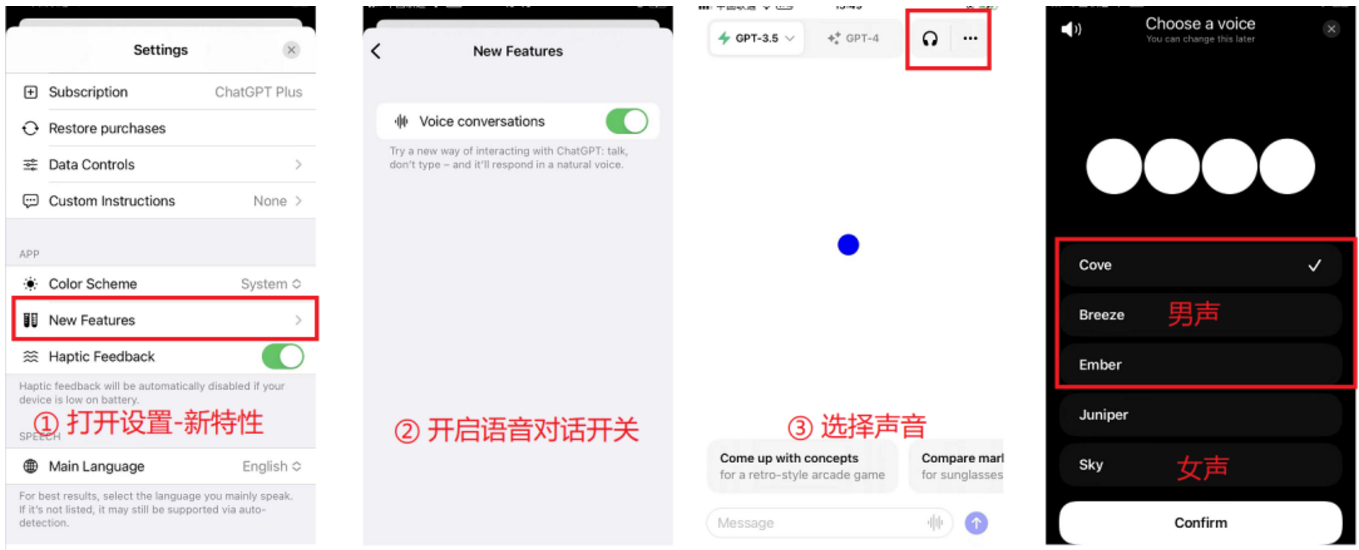
利用ChatGPT练习口语
目录 ChatGPT 这两天发布了一个激动人心的新功能,App端(包括iOS和Android)开始支持语音对话以及图片识别功能。 这两个功能一如既往的优先开放给Plus用户使用,现在将App更新到最新版本,就能体验。 为什么说激动人心&a…...
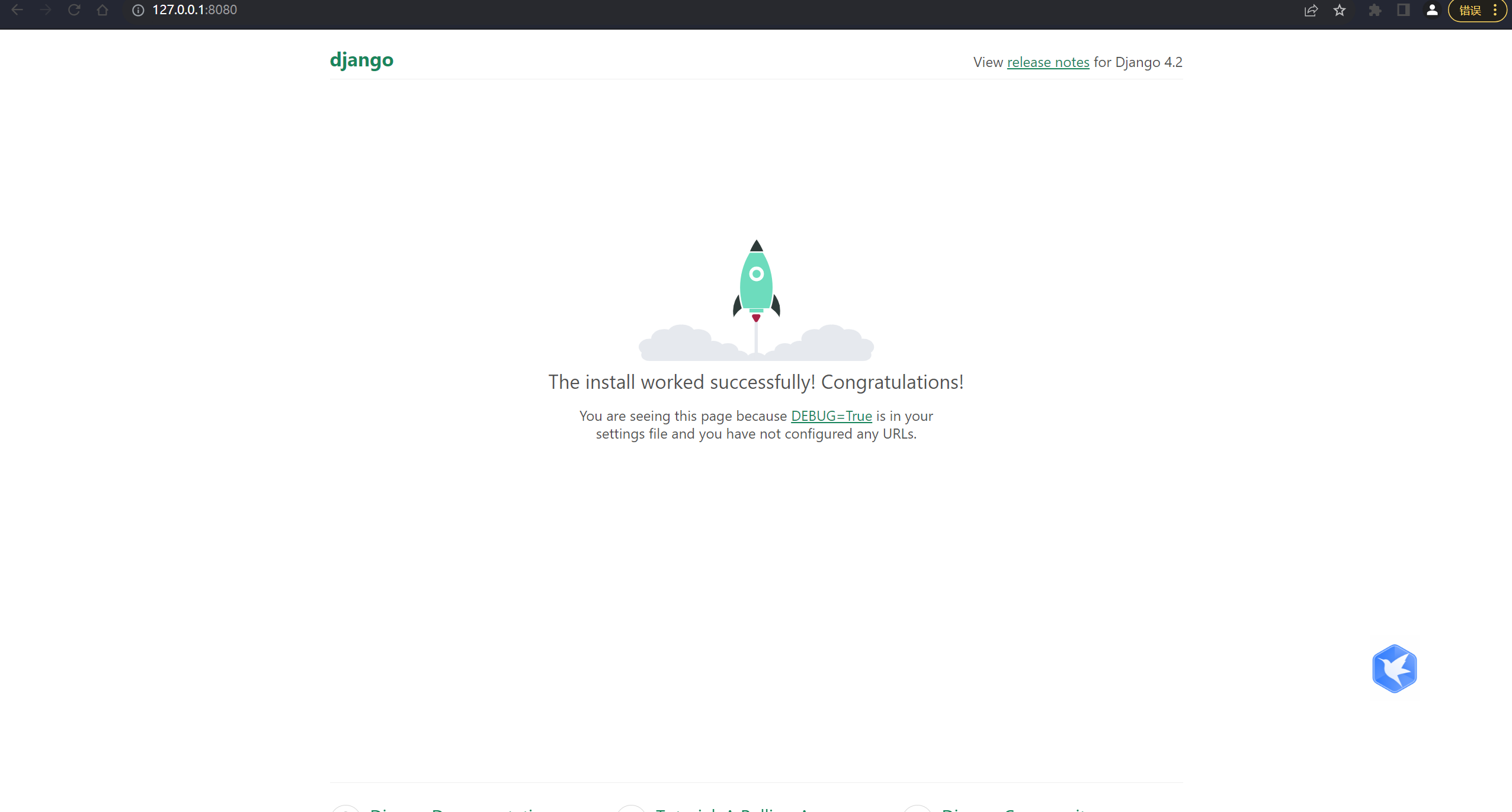
【Django 01】环境搭配与项目配置
1. 介绍 https://github.com/Joe-2002/sweettalk-django4.2#readme Django 是一个使用 Python 编写的开源 Web 应用程序框架,它提供了一套用于快速开发安全、 可扩展和高效的 Web 应用程序的工具和功能。Django 基于 MVC(Model-View-Controller…...
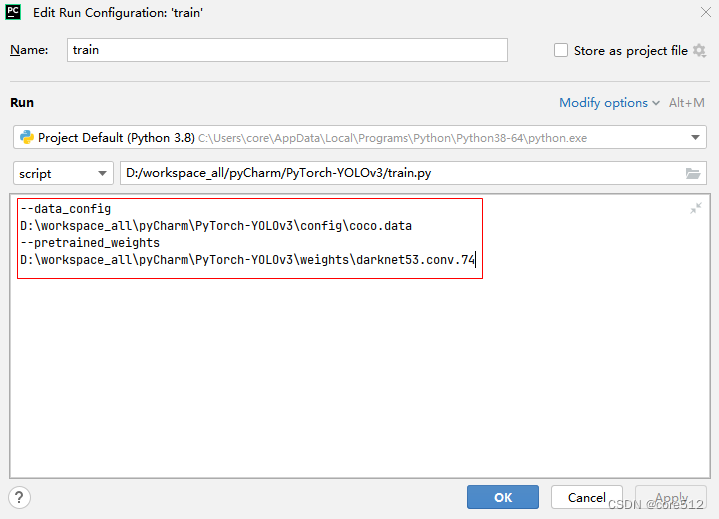
PyCharm配置运行参数
...
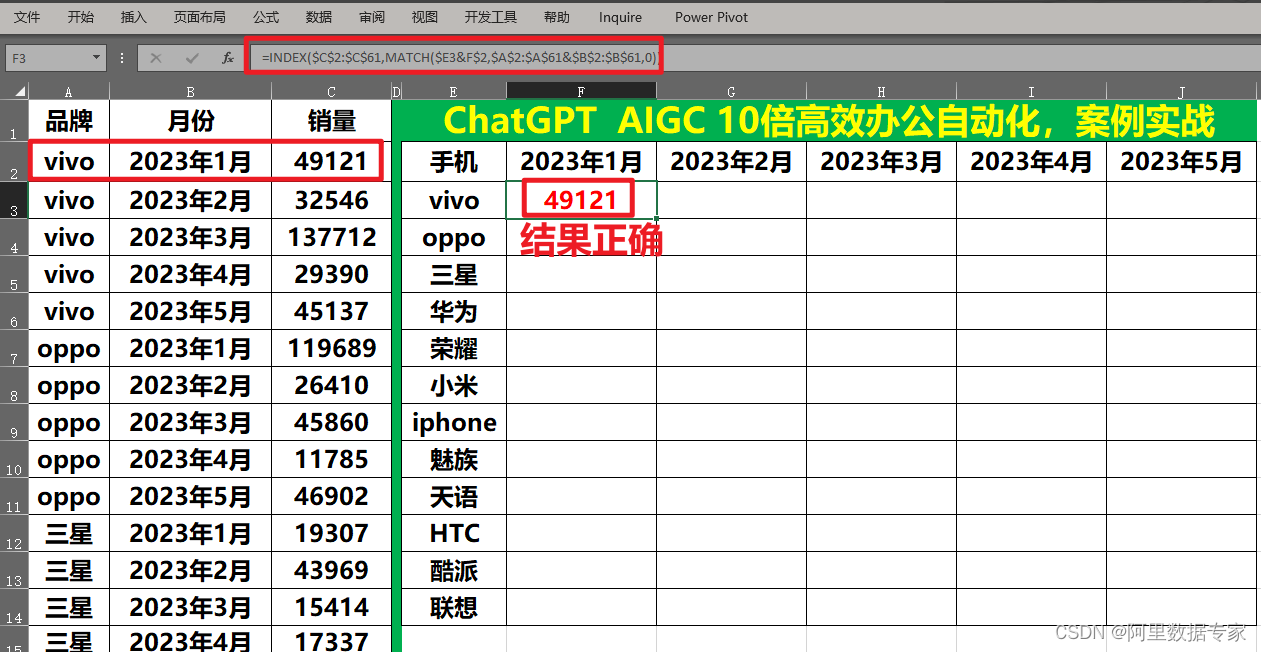
ChatGPT AIGC 实现Excel 交叉查找 Index+match 函数
行与列交叉多条件查找需求如下: 这个需求要使用Excel中最经典的组合函数Index+match函数。 函数公式可以交给ChatGPT AIGC来实现。 Prompt: 有一个表格A列为品牌,B列为月份,C列为销量,61行数据,请写出Excel函数公式根据E3单元格的品牌与F2单元格的月份查找对应的销量,…...
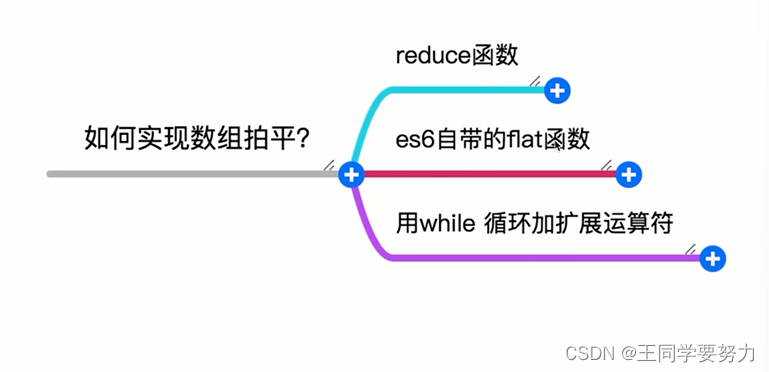
【前端学习】—多种方式实现数组拍平(十一)
【前端学习】—多种方式实现数组拍平(十一) 一、数组拍平 数组拍平也叫数组扁平化、数组拉平、数组降维,指的是把多维数组转化为一维数组。 二、使用场景 复杂场景下的数据处理(echarts做大屏数据展示) 三、如何实…...

智慧远程医疗服务:从零开始搭建互联网医院APP
互联网医院APP作为远程医疗服务的一部分,正在为患者和医生带来更便捷的医疗体验。本文将探讨如何从零开始构建一个互联网医院APP,包括关键步骤、技术要点和挑战。 一、确定项目目标和范围 在开始之前,您需要明确定义您的互联网医院APP的目标…...
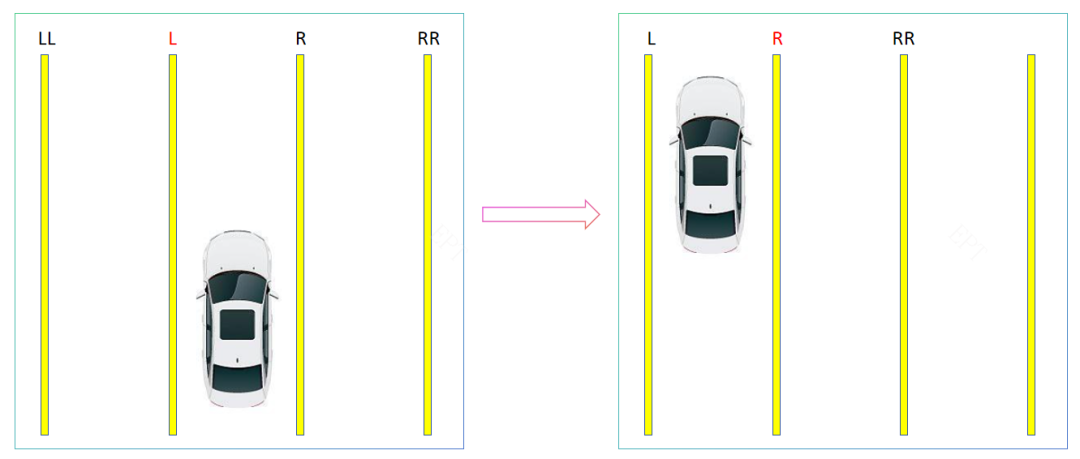
ADAS可视化系统,让自动驾驶更简单 -- 入门篇
随着车载芯片的升级、技术的更新迭代,可视化ADAS逐渐变成汽车的标配走入大家的生活中,为大家的驾车出行带来切实的便捷。那么你了解HMI端ADAS的实现过程吗?作为ADAS可视化系统的入门篇,就跟大家聊一聊目前较常见的低消耗的一种ADA…...

物联网数据采集网关实战:从协议解析到边缘计算的完整指南
1. 项目概述:从“黑盒子”到“数据枢纽”的蜕变 在物联网的世界里,传感器是感知世界的“神经末梢”,而物联网网关,则是连接这些神经末梢与云端大脑的“神经中枢”。很多人觉得它像个神秘的黑盒子,插上线,数…...
)
Perplexity历史资料搜索失效真相大起底(时间戳偏移、缓存策略与知识图谱断层深度解析)
更多请点击: https://intelliparadigm.com 第一章:Perplexity历史资料搜索失效真相大起底(时间戳偏移、缓存策略与知识图谱断层深度解析) Perplexity 的历史资料检索能力在近期高频出现“查无结果”或“返回过期摘要”现象&#…...

使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端 在构建集成AI能力的后端服务时,开发者常常面临模型选择、API稳定性…...
)
告别PS!用ImageMagick命令行5分钟搞定100张图片格式批量转换(附Windows/Mac安装避坑)
告别PS!用ImageMagick命令行5分钟搞定100张图片格式批量转换(附Windows/Mac安装避坑) 在数字内容爆炸式增长的今天,图片处理已成为开发者、设计师和内容运营人员的日常刚需。当面对上百张需要统一转换格式、调整尺寸的图片时&…...

Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用
Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用 【免费下载链接】flet Build realtime web, mobile and desktop apps in Python only. No frontend experience required. 项目地址: https://gitcode.com/gh_mirrors/fl/flet 你是否曾…...

如何快速掌握3DS硬件检测:面向初学者的完整3DSident使用指南
如何快速掌握3DS硬件检测:面向初学者的完整3DSident使用指南 【免费下载链接】3DSident PSPident clone for 3DS 项目地址: https://gitcode.com/gh_mirrors/3d/3DSident 你是否曾好奇自己的Nintendo 3DS内部藏着什么秘密?想知道它的制造日期、电…...

如何在Windows上快速挂载ISO镜像?WinCDEmu虚拟光驱终极指南
如何在Windows上快速挂载ISO镜像?WinCDEmu虚拟光驱终极指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu 还在为ISO、IMG等光盘镜像文件无法直接使用而烦恼吗?还在为没有物理光驱而无法读取光盘内容而困扰吗…...

CANN Ascend C数据转换临时空间API
GetTransDataMaxMinTmpSize 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: http…...

drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案
drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案 【免费下载链接】drf-nested-routers Nested Routers for Django Rest Framework 项目地址: https://gitcode.com/gh_mirrors/dr/drf-nested-routers drf-nested-routers是Django Rest Framework的…...

从老式万用表到精密测量:双积分ADC如何用‘慢’换来‘准’?选型避坑指南
从老式万用表到精密测量:双积分ADC如何用‘慢’换来‘准’?选型避坑指南 在仪器仪表和传感器信号调理领域,精度与速度的权衡一直是硬件工程师面临的核心挑战。当我们处理温度、压力或称重传感器等低频高精度信号时,传统的SAR和Σ…...