【HuggingFace文档学习】Bert的token分类与句分类
BERT特性:
- BERT的嵌入是位置绝对(position absolute)的。
- BERT擅长于预测掩码token和NLU,但是不擅长下一文本生成。
1.BertForTokenClassification
一个用于token级分类的模型,可用于命名实体识别(NER)、部分语音标记(POS)等。对于给定的输入序列,模型将为每个标记/词产生一个标签。
输出的维度是 [batch_size, sequence_length, num_labels],其中 num_labels 是可能的标签数量。
class transformers.BertForTokenClassification(config)
继承父类:BertPreTrainedModel、torch.nn.Module
参数:config (BertConfig)——包含模型所有参数的模型配置类。
包含一个token分类的任务头(线性层,可用于NER)。
forward方法:
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 输入序列对应的分词索引列表(indices list)。索引根据AutoTokenizer得到。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 对输入序列的部分token加上掩码,使得注意力机制不会计算到。如填充token的索引(padding token indices)。取值为[0, 1]二者之一。取0则表明掩码,取1则表明不掩码。 - token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 在分句任务中,表明token是属于第一句还是第二句。取值为[0, 1]二者之一。 - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 输入序列对应的位置索引列表(positional indices list)。 取值范围为[0, config.max_position_embeddings - 1],从而加入位置信息。 - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 掩码(多头)自注意力模块的头。取值为[0, 1]二者之一:取0则表示对应的头要掩码,取1则表示对应的头不掩码。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 如果想要直接将嵌入向量传入给模型,由自己控制input_ids的关联向量,那么就传这个参数。这样就不需要由本模型内部的嵌入层矩阵运算input_ids。 - output_attentions (
bool, optional) — 是否希望模型返回所有的注意力分数。 - output_hidden_states (
bool, optional) — 是否希望模型返回所有层的隐藏状态。 - return_dict (
bool, optional) — 是否希望输出的是ModelOutput,而不是直接的元组tuple。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 提供标签,用于计算loss。取值范围为[0, config.max_position_embeddings - 1]。
返回值
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
- 如果
return_dict为False(或return_dict为空但配置文件中self.config.use_return_dict为False):- 如果提供了
labels参数,输出是一个元组,包含:loss: 计算的损失值。logits: 分类头的输出,形状为(batch_size, sequence_length, num_labels)。- 其他 BERT 的输出(例如隐藏状态和注意力权重),但这取决于 BERT 的配置和输入参数。
- 如果没有提供
labels参数,输出只包含logits和其他 BERT 的输出。
- 如果提供了
- 如果
return_dict为True(或return_dict为空但配置文件中self.config.use_return_dict为False):- 输出是一个
TokenClassifierOutput对象,包含以下属性:loss: 如果提供了labels参数,这是计算的损失值。logits: 分类头的输出,形状为(batch_size, sequence_length, num_labels)。hidden_states: BERT 的隐藏状态输出。attentions: BERT 的注意力权重输出。
- 输出是一个
代码实现
@add_start_docstrings("""Bert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. forNamed-Entity-Recognition (NER) tasks.""",BERT_START_DOCSTRING,
)
class BertForTokenClassification(BertPreTrainedModel):def __init__(self, config):super().__init__(config)self.num_labels = config.num_labels # 标签的数量self.bert = BertModel(config, add_pooling_layer=False) # 预训练BERTclassifier_dropout = (config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob)self.dropout = nn.Dropout(classifier_dropout)self.classifier = nn.Linear(config.hidden_size, config.num_labels) # classification任务头,加在预训练BERT之上# Initialize weights and apply final processingself.post_init()@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))@add_code_sample_docstrings(checkpoint=_CHECKPOINT_FOR_TOKEN_CLASSIFICATION,output_type=TokenClassifierOutput,config_class=_CONFIG_FOR_DOC,expected_output=_TOKEN_CLASS_EXPECTED_OUTPUT,expected_loss=_TOKEN_CLASS_EXPECTED_LOSS,)def forward(self,input_ids: Optional[torch.Tensor] = None,attention_mask: Optional[torch.Tensor] = None,token_type_ids: Optional[torch.Tensor] = None,position_ids: Optional[torch.Tensor] = None,head_mask: Optional[torch.Tensor] = None,inputs_embeds: Optional[torch.Tensor] = None,labels: Optional[torch.Tensor] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:r"""labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`."""return_dict = return_dict if return_dict is not None else self.config.use_return_dictoutputs = self.bert(input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids,head_mask=head_mask,inputs_embeds=inputs_embeds,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,) # 预训练BERT的计算,得到输入序列经BERT计算的向量序列sequence_output = outputs[0]sequence_output = self.dropout(sequence_output)logits = self.classifier(sequence_output) # 再经过最后的任务头classificationloss = Noneif labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))if not return_dict:output = (logits,) + outputs[2:]return ((loss,) + output) if loss is not None else outputreturn TokenClassifierOutput(loss=loss,logits=logits,hidden_states=outputs.hidden_states,attentions=outputs.attentions,)
使用示例:
from transformers import AutoTokenizer, BertForTokenClassification
import torchtokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
model = BertForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")inputs = tokenizer("HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
)with torch.no_grad():logits = model(**inputs).logits # 想要得到分类后的权重,获取的是输出的logits对象。predicted_token_class_ids = logits.argmax(-1)# Note that tokens are classified rather then input words which means that
# there might be more predicted token classes than words.
# Multiple token classes might account for the same word
predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
# predicted_tokens_classes = ['O', 'I-ORG', 'I-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'I-LOC', 'O', 'I-LOC', 'I-LOC']
2.BertForSequenceClassification
一个用于整个句子或段落级别的分类的模型,可用于情感分析、文本分类等。对于给定的输入,模型将为整个序列产生一个分类标签。
输出的维度是 [batch_size, num_labels],其中 num_labels 是可能的分类数量。
class transformers.BertForSequenceClassification(config)
继承父类:BertPreTrainedModel、torch.nn.Module
参数:config (BertConfig)——包含模型所有参数的模型配置类。
forward方法:与BertForTokenClassification相同。
与BertForTokenClassification的差异:
- BertForSequenceClassification 在 BERT 的编码器输出上增加了一个**全连接层(通常连接到 [CLS] 标记的输出)**来进行分类。
- BertForTokenClassification 不需要额外的全连接层,而是直接使用 BERT输出的每个标记的表示,并可能有一个线性层来将其映射到标签空间。
使用示例:
import torch
from transformers import AutoTokenizer, BertForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained("textattack/bert-base-uncased-yelp-polarity")
model = BertForSequenceClassification.from_pretrained("textattack/bert-base-uncased-yelp-polarity")inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")with torch.no_grad():logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()
predicted_class_label = model.config.id2label[predicted_class_id]
# predicted_class_label = LABEL_1
相关文章:

【HuggingFace文档学习】Bert的token分类与句分类
BERT特性: BERT的嵌入是位置绝对(position absolute)的。BERT擅长于预测掩码token和NLU,但是不擅长下一文本生成。 1.BertForTokenClassification 一个用于token级分类的模型,可用于命名实体识别(NER)、部分语音标记…...
)
354 俄罗斯套娃信封问题(贪心+二分)
题目 链接 给你一个二维整数数组 envelopes ,其中 envelopes[i] [wi, hi] ,表示第 i 个信封的宽度和高度。 当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。 请计算 最多…...

Vue页面结构
Vue页面结构 App.vue <!--html标签--> <template><div><h1>饿了么?</h1></div><HelloWorld msg"Vite Vue" /> </template> <!--js代码 vue3的语法--> <script setup> import HelloWorld f…...

【广州华锐互动】利用VR开展高压电缆运维实训,提供更加真实、安全的学习环境
VR高压电缆维护实训系统由广州华锐互动开发,应用于多家供电企业的员工培训中,该系统突破了传统培训的限制,为学员提供了更加真实、安全的学习环境,提高了培训效率和效果。 传统电缆井下运维培训通常是在实际井下环境中进行&#x…...
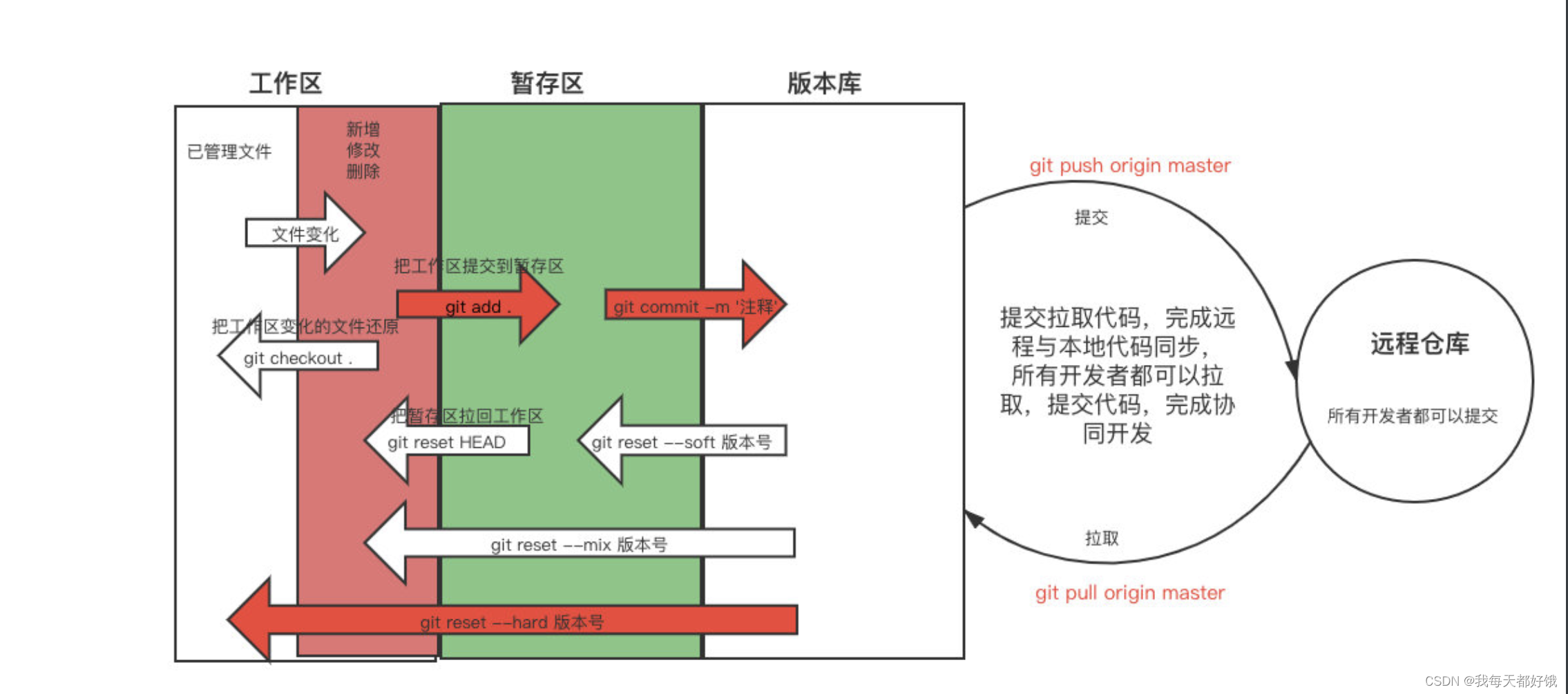
git的介绍和安装、常用命令、忽略文件、分支
git介绍和安装 首页功能写完了 ⇢ \dashrightarrow ⇢ 正常应该提交到版本仓库 ⇢ \dashrightarrow ⇢ 大家都能看到这个 ⇢ \dashrightarrow ⇢ 运维应该把现在这个项目部署到测试环境中 ⇢ \dashrightarrow ⇢ 测试开始测试 ⇢ \dashrightarrow ⇢ 客户可以看到目前做的…...
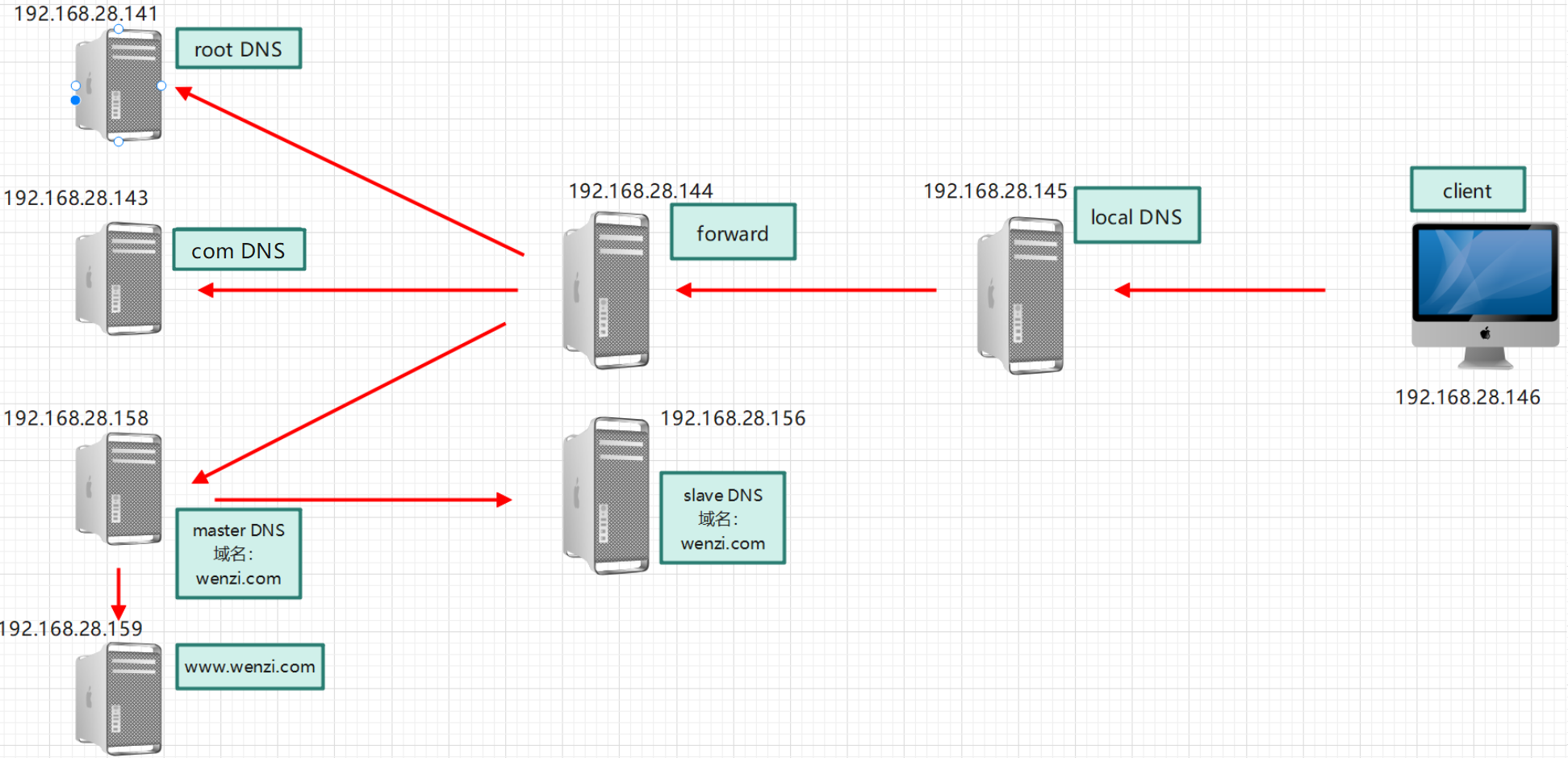
DNS(二)
实现 Internet DNS 架构 架构图 实验环境 关闭SELinux、Firewalld。时间保持一致 主机名IP角色client192.168.28.146DNS客户端,DNS地址为192.168.28.145localdns192.168.28.145本地DNS服务器(只缓存)forward192.168.28.144转发目标DNS服务…...
win 10怎么录屏?教你轻松捕捉屏幕活动
在当今科技快速发展的时代,录屏已成为信息分享、教学、游戏直播等方面的重要工具。无论是为了制作教程、分享游戏过程还是保存重要信息,录屏功能都发挥着举足轻重的作用。可是很多人不知道win 10怎么录屏,本文将详细介绍win10的三种常用录屏方…...
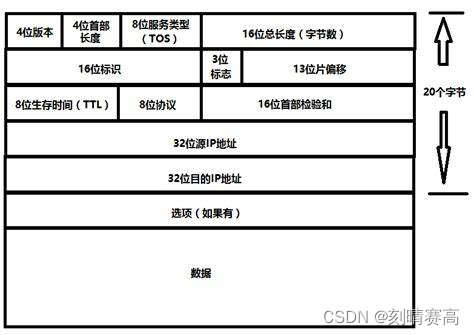
IP 协议的相关特性(部分)
IP 协议的报文格式 4位版本号: 用来表示IP协议的版本,现有的IP协议只有两个版本,IPv4,IPv6。 4位首部长度: 设定和TCP的首部长度一样 8位服务类型: (真正只有4位才有效果)…...

Java设计模式之代表模式
代表模式(Mediator Pattern)是一种行为型设计模式,它通过封装一组对象之间的交互方式,使得这些对象之间的通信变得松散耦合,从而降低了对象之间的直接依赖关系。代表模式通过引入一个中介者(Mediator&#…...
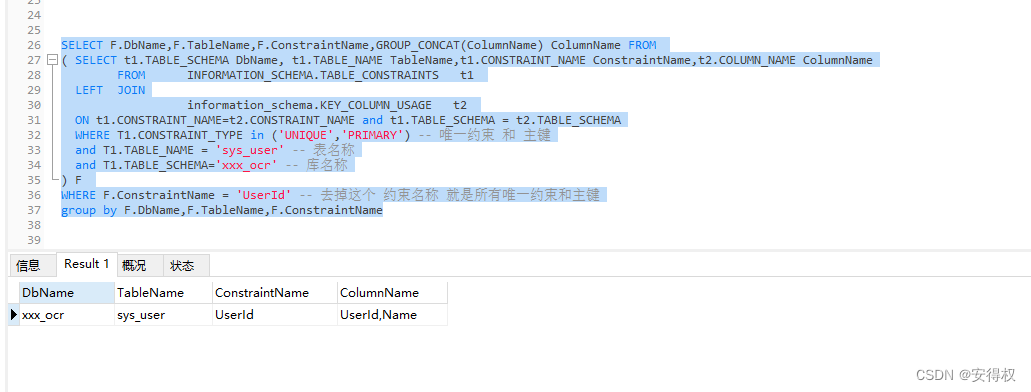
MySQL 查询 唯一约束 对应的字段,列名称合并
MySQL 查询 唯一约束 对应的字段,列名称合并 SELECT F.DbName,F.TableName,F.ConstraintName,GROUP_CONCAT(ColumnName) ColumnName FROM ( SELECT t1.TABLE_SCHEMA DbName, t1.TABLE_NAME TableName,t1.CONSTRAINT_NAME ConstraintName,t2.COLUMN_NAME ColumnNam…...
JDBC-day05(DAO及相关实现类)
七:DAO及相关实现类 1. DAO介绍 DAO:全称Data Access Object,是数据访问对象.在java服务器开发的三层架构中分成控制层(Controller),表示层(Service),数据访问层(Dao),数据访问层专门负责跟数据库进行数据交互.,包括了对数据的CRUDÿ…...

华为汪涛:5.5G时代UBB目标网,跃升数字生产力
[阿联酋,迪拜,2023年10月12日] 在2023全球超宽带高峰论坛上,华为常务董事、ICT基础设施业务管理委员会主任汪涛发表了“5.5G时代UBB目标网,跃升数字生产力”的主题发言,分享了超宽带产业的最新思考与实践,探…...
docker部署多个node-red操作过程
docker部署多个node-red操作过程 一、docker安装教程二、docker安装node-red2.1 在线安装node-red镜像2.1.1 拉取镜像2.1.2 创建目录并分配权限 2.2 离线安装node-red镜像 三、 docker操作node-red3.1 部署node-red3.2 查看\关闭\删除容器 四、Docker删除Redis镜像五、离线安装…...

王兴投资5G小基站
边缘计算社区获悉,近期深圳佳贤通信正式完成数亿元股权融资,本轮融资由美团龙珠领投。本轮融资资金主要用于技术研发、市场拓展等,将进一步巩固和扩大佳贤通信在5G小基站领域的技术及市场领先地位。 01 佳贤通信是什么样的公司? 深…...
】54 - /ifs/bin/startupmgr 程序工作流程分析 及 script.c 介绍)
【SA8295P 源码分析 (一)】54 - /ifs/bin/startupmgr 程序工作流程分析 及 script.c 介绍
【SA8295P 源码分析】54 - /ifs/bin/startupmgr 程序工作流程分析 及 script.c 介绍 一、startupmgr 可执行程序工作解析1. startupmgr\src\script.c 入口 main 函数:调用 init_loader_and_launcher 解析 scripts 数组二、ifsloader镜像加载流程分析:init_loader_and_launche…...
git 使用
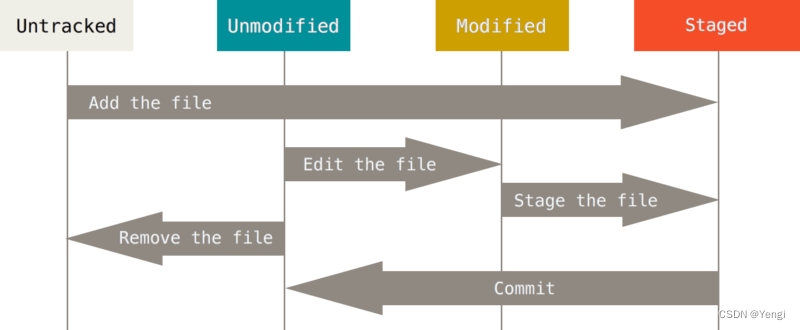
参考 https://git-scm.com/book/zh/v2/Git-%E5%9F%BA%E7%A1%80-%E8%8E%B7%E5%8F%96-Git-%E4%BB%93%E5%BA%93 文件的状态变化周期 文章目录 git 基础检查当前文件状态、查看已暂存和未暂存的修改暂存前后的变化跟踪新文件提交更新移除文件移动文件、重命名操作查看提交历史撤消…...
MFC扩展库BCGControlBar Pro v33.6新版亮点 - 图形管理器改造升级
BCGControlBar库拥有500多个经过全面设计、测试和充分记录的MFC扩展类。 我们的组件可以轻松地集成到您的应用程序中,并为您节省数百个开发和调试时间。 BCGControlBar专业版 v33.6已正式发布了,此版本包含了对图表组件的改进、带隐藏标签的单类功能区栏…...

云上攻防-云原生篇KubernetesK8s安全APIKubelet未授权访问容器执行
文章目录 K8S集群架构解释K8S集群攻击点-重点API Server未授权访问&kubelet未授权访问复现k8s集群环境搭建1、攻击8080端口:API Server未授权访问2、攻击6443端口:API Server未授权访问3、攻击10250端口:kubelet未授权访问 K8S集群架构解…...

Django 访问静态文件的APP staticfiles
Django 框架默认带的 APP: django.contrib.staticfiles Django文档中也写明了:如何管理静态文件(如图片、JavaScript、CSS) |姜戈 文档 |姜戈 (djangoproject.com)https://docs.djangoproject.com/zh-hans/4.2/howto/static-file…...

Airbnb 迁移 SwiftUI 实践
从 2022 年开始,Airbnb 的 iOS 团队就认为 SwiftUI 已经足够成熟,可以在他们的官方应用中使用它。但 Airbnb 的工程师 Bryn Bodayle 表示,这需要一个谨慎的转换过程。 Airbnb 的工程师认为,SwiftUI 的主要优势是它的灵活性和可组合性、声明性、简洁性和惯用性,他们希望这…...

LeetCode 合并K个排序链表题解
LeetCode 合并K个排序链表题解 题目描述 合并 k 个排序链表,返回合并后的排序链表。 示例: 输入:lists [[1,4,5],[1,3,4],[2,6]]输出:[1,1,2,3,4,4,5,6] 解题思路 方法:堆 思路: 使用最小堆存储每个链表的…...

ArcGIS 10.2.2许可服务罢工了?别慌,试试这个替换Service.txt和ARCGIS.exe的终极方案
ArcGIS 10.2.2许可服务故障终极修复指南:深入解析文件替换方案 当ArcGIS 10.2.2的许可服务突然罢工,所有常规方法都失效时,那种挫败感只有GIS专业人员才能真正体会。你试过关闭防火墙、调整服务启动类型、甚至重启服务器,但那个令…...

从芯片到模块:拆解乐鑫、安信可、正点原子在ESP8266/ESP32生态链中的角色与产品
从芯片到模块:拆解乐鑫、安信可、正点原子在ESP8266/ESP32生态链中的角色与产品 在物联网硬件开发领域,ESP8266和ESP32系列产品已经成为开发者手中的"瑞士军刀"。但很少有人真正理解这些模块背后的产业链分工与技术附加值。本文将带您深入芯片…...
)
手把手教你用FPGA+摄像头搭建一个图像处理系统(从采集到以太网传输)
从零构建FPGA图像处理系统:硬件选型到以太网传输实战指南 在嵌入式视觉领域,FPGA因其并行处理能力和低延迟特性,成为实时图像处理的理想平台。本文将带您完整实现一个基于OV7670摄像头和Xilinx Artix-7 FPGA的图像采集处理系统,涵…...

MarkdownViewer++:5分钟让Notepad++变身专业Markdown编辑器的终极指南
MarkdownViewer:5分钟让Notepad变身专业Markdown编辑器的终极指南 【免费下载链接】MarkdownViewerPlusPlus A Notepad Plugin to view a Markdown file rendered on-the-fly 项目地址: https://gitcode.com/gh_mirrors/ma/MarkdownViewerPlusPlus 你是否还在…...

5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南
5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否对官方Omen Gaming Hub的臃肿…...

为什么你的Perplexity本地服务响应慢3.7倍?:NVIDIA驱动版本、vLLM推理后端与量化精度的隐性博弈
更多请点击: https://codechina.net 第一章:Perplexity本地服务查询 Perplexity 作为一款强调实时信息检索与引用溯源的 AI 工具,其官方未提供公开的本地化部署方案。但开发者可通过构建轻量级代理服务,将本地运行的大语言模型&a…...

别再死记硬背了!用Verilog/SystemVerilog手把手教你理解Decoder、Mux和Selector的电路本质
从Verilog代码反推Decoder与Mux的硬件本质:写给会看电路图但写不出代码的工程师 当你第一次在教科书上看到2-4解码器的门级电路图时,是否觉得那些与门排列得像积木一样整齐?但当你打开编辑器准备用Verilog实现时,却发现大脑一片空…...

AI Agent到底是什么
AI Agent 到底是什么?看完我悟了 今天看了几个产品,跟 AI 聊了聊,突然对 AI Agent 有了个很朴素的理解。AI Agent 不神秘 很多人觉得 AI Agent 是什么高深的东西,只有大厂才能搞。 但我现在的理解就一句话:❝ 「AI Age…...

从源码到实战:手把手教你自定义一个比StringUtils更强大的Java数字校验工具类
从源码到实战:构建超越StringUtils的Java数字校验工具类 在Java开发中,数字校验是每个开发者都会遇到的常见需求。虽然Apache Commons Lang的StringUtils提供了基础的isNumeric方法,但在实际业务场景中,我们经常需要处理更复杂的…...