信息检索与数据挖掘|(四)索引构建
目录
📚硬件基础
📚基于块的排序索引方法
🐇BSBI算法(blocked sort-based indexing)
📚内存式单遍扫描索引构建方法
🐇SPIMI算法(single-pass in-memory indexing)
📚分布式索引构建方法
📚硬件基础
- 访问内存数据比访问磁盘数据快得多。
- 进行磁盘读写时,磁头移到数据所在的磁道需要一段时间,该时间称为寻道时间。寻道期间并不进行数据的传输。
- 操作系统往往以数据块为单位进行读写。因此,从磁盘读取一个字节和读取一个数据块所耗费的时间可能一样多。也就是说,将一大块数据从磁盘传输到内存比传输许多小块要快。
- IR系统的服务器往往有数GB甚至数十GB的内存,其可用的磁盘空间大小一般比内存大小要高几个数量级。
📚基于块的排序索引方法
- 面向静态文档集的高效单机索引算法
- 之前提出的倒排索引构建方法(如下),对于小规模文档集来说,均可在内存中完成。在大规模文档集条件下,需要引入二级存储介质来构建索引。
- 扫描文档集合得到所有的词项-文档ID对。
- 以词项为主键,文档ID为次键进行排序。
- 将每个词项的文档ID组织成倒排记录表。


- 现在将词项用其ID来代替,每个词项的ID都是唯一的。我们可以在处理文档集之余将词项映射成其ID(单遍扫描)。或者在一种两边扫描的方法中,第一遍扫描得到词汇表,第二遍扫描才构建倒排索引。
- 这里以Reuters-RCV1语料的统计数据为例。

- Reuters-RCV1语料约有一亿个词条,每个占4B,存储所有的词项ID-文档ID对需要0.8GB存储空间。
- 对大规模文档集而言,将所有词项ID-文档ID放在内存中进行排序是非常困难的。对于很多大型语料库,即使经过压缩后的倒排记录表也不可能全部加载到内存中。
- 由于内存不足,我们必须使用基于磁盘的外部排序算法。对该算法的核心要求就是:在排序时尽量减少磁盘随机寻道的次数。
🐇BSBI算法(blocked sort-based indexing)
- BSBI(blocked sort-based indexing algorithm,基于块的排序索引算法)是一种解决办法:
- 将文档集分割成几个大小相等的部分。
- 对每个部分的词项ID-文档ID对排序。
- 将第2步产生的临时排序结果存放到磁盘中。
- 将所有的临时排序文件合并成最终的索引。
- 在该算法中,我们选择合适的块大小,将文档解析成词项ID-文档ID对并加载到内存,在内存中快速排序。将排序后的结果转换成倒排索引格式后写入磁盘。然后将每个块索引同时合并成一个索引文件。
- 以该算法应用到Reuters-RCV1语料库为例,它要构建的倒排记录数目大概有1亿条,假定内存每次能加载1,000万个词项ID-文档ID,那么算法最后产生10个块,然后将10个块索引同时合并成一个索引文件。
- 合并时,同时打开所有块对应的文件,内存中维护了为10个块准备的读缓冲区和一个为最终合并索引准备的写缓冲区。每次迭代中,利用优先级序列(即堆结构)选择最小的未处理词项ID进行处理。读入词项的倒排记录表并合并,合并结果写会磁盘。

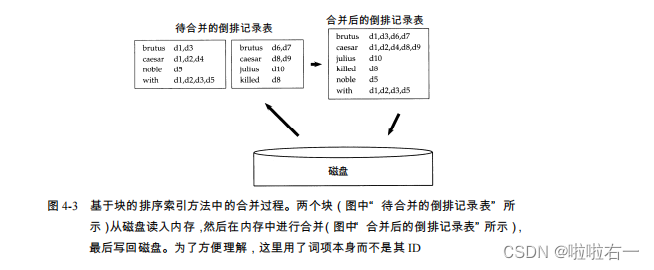
- 由于该算法最主要的时间消耗在排序上,因此其时间复杂度为 Θ(TlogT),其中 T 是所需要排序的项数目的上界(即词项 ID-文档 ID 对的个数)。然而,实际的索引构建时间往往取决于文档分析(PARSENEXTBLOCK)和最后合并(MERGEBLOCKS)的时间。
📚内存式单遍扫描索引构建方法
- 基于块的排序索引算法有很好的可扩展性,但缺点是需要将词项映射成其ID,因此在内存中保存词项与其ID的映射关系,对于大规模的数据集,内存可能存储不下。
- SPIMI(single-pass in memory indexing,内存式单遍扫描索引算法)更具可扩展性,它使用的是词项而不是其ID,它是将每个块的词典写入磁盘,对下一个块则重新采用新的词典。
🐇SPIMI算法(single-pass in-memory indexing)
- 算法逐一处理每个词项-文档ID,若词项是第一次出现,则将其加入词典(最好通过哈希表实现),同时建立一个新的倒排记录表;若该词项不是第一次出现,则直接返回其倒排记录表。注意:这里倒排记录表都是在内存中的。
- 向上面得到的倒排记录表增加新的文档ID。

- 不同于BSBI,这里并没有对词项ID-文档ID排序。
- 内存耗尽时,对词项进行排序,并将包含词典和倒排记录表的块索引写入磁盘。这里,排序的目的是方便以后对块进行合并。
- 重新采用新的词典,重复以上过程。
其实SPIMI和BSBI并没有太多的区别。他们都是基于块来做索引构建,然后将块合并得到整体的倒排索引表。不同的是BSBI需要在内存维护词项和其ID的映射关系,另外BSBI的倒排记录表是排序过的,而SPIMI没有排序。
- 优点:
- 不需要排序操作,处理速度更快
- 保留了倒排记录表对词项的归属关系,节约内存
- 时间复杂度:SPIMI 算法的时间复杂度是 Θ(T),这是因为它不需要对词项-文档 ID 对进行排序操作, 所有操作最多和文档集大小成线性关系。
📚分布式索引构建方法
- 实际中,文档集通常都很大。尤其是Web搜索引擎,Web搜索引擎通常使用分布式索引构建算法来构建索引,往往按照词项或文档进行分割后分布在多台计算机上。大部分搜索引擎更倾向于采用基于文档分割的索引。
- 分布式索引构建方法是基于MapReduce。MapReduce中的Map阶段和Reduce阶段是将计算任务划分成子任务块,以便每个工作节点在短时间内快速处理。
大数据|MapReduce模型 | Hadoop MapReduce的基本工作原理
大数据 | 实验一:大数据系统基本实验 | MapReduce 初级编程
大数据 | 实验二:文档倒排索引算法实现
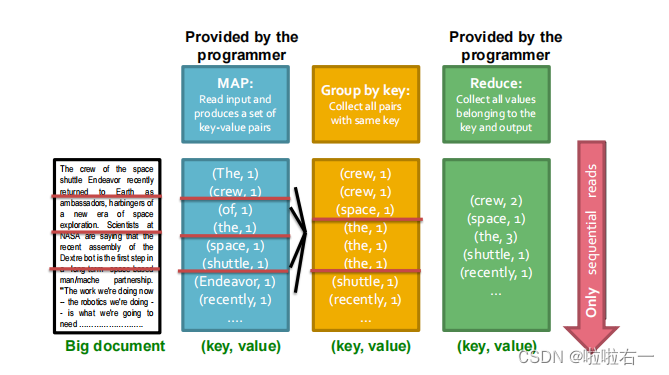
- MapReduce的Map阶段将输入的数据片映射成键-值对即(词项ID,文档ID),这个map阶段对应于BSBI和SPIMI算法中的分析任务,因此也将执行map过程的机器称为分析器(parse),每个分析器将输出结果存在本地的中间文件。
- 在reduce阶段,我们将同一个键(词项ID)的所有值(文档ID)集中存储,以便快速读取和处理。
参考博客:
-
信息检索导论第四章-索引构建
相关文章:
信息检索与数据挖掘|(四)索引构建
目录 📚硬件基础 📚基于块的排序索引方法 🐇BSBI算法(blocked sort-based indexing) 📚内存式单遍扫描索引构建方法 🐇SPIMI算法(single-pass in-memory indexing) 📚分布式索引构建方法 Ὅ…...

Ruby使用类组织对象
使用Object.new创建新对象,但是一次只使用一种方法,这是感受以对象为中心的Ruby编程的最佳方式之一。不过这种方式并不能很好地扩展,假如有一个正在运行地在线售票网站,然后其数据库必须处理数以百计地售票记录,那么可…...

Spring Boot 中常用的注解@RequestParam
Spring Boot 中常用的注解RequestParam RequestParam 是 Spring Framework 和 Spring Boot 中常用的注解之一,用于从请求中获取参数值。它通常用于处理 HTTP 请求中的查询参数(query parameters)或表单数据。下面详细解释 RequestParam 的用…...

Spark工作流程
Spark 的整个工作流程可以概括为以下步骤: 创建 SparkSession: 应用程序首先需要创建一个 SparkSession 对象,它是与 Spark 的交互入口。SparkSession 提供了对核心功能和各个模块的访问。 加载数据: 使用 SparkSession 提供的 AP…...
IDEA如何设置项目包名分级
按上面的勾选即可!...

消防应急疏散指示系统在某生物制药工厂项目的应用
安科瑞 华楠 摘要 消防应急照明和疏散指示系统由控制器、集中电源和灯具(疏散指示灯具、应急照明灯具)等几部分组成。系统采用17寸工业平板电脑、Windonws7系统,可支持联动报警、系统监控、故障报警、自检、备电、记录存储与查询、导光流、…...

C语言文件操作(上)
文章目录 一、为什么使用文件二、什么是文件1.程序文件2.数据文件3.文件名 三、文件的打开与关闭1.文件指针2.文件的打开和关闭fopen 与 fclose 四、文件的顺序读写01 字符输出函数:fputs02 字符输入函数:fgetc03 文本行输出函数:fputs04 文本…...
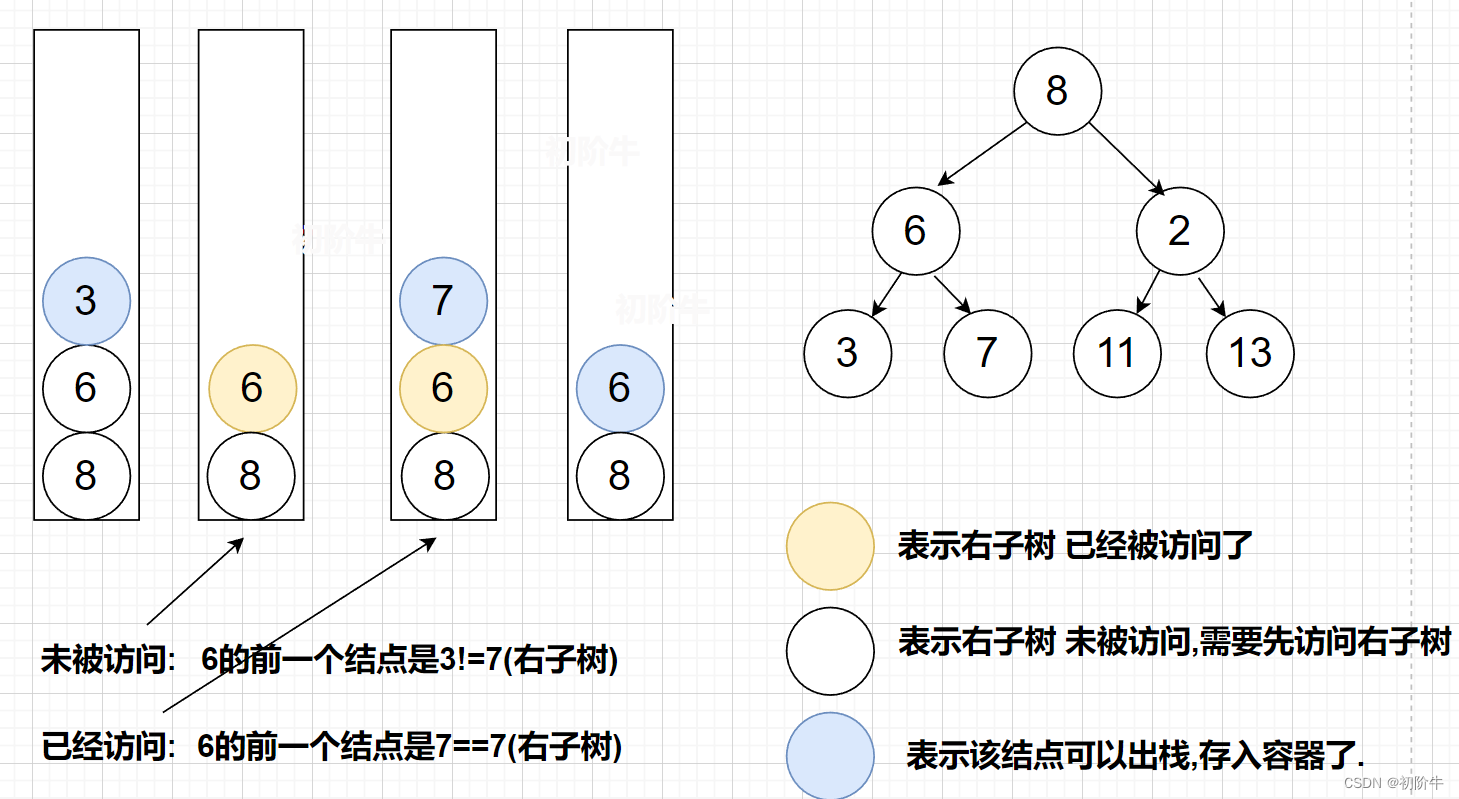
二叉树的前 中 后序的非递归实现(图文详解)
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻强烈推荐优质专栏: 🍔🍟🌯C的世界(持续更新中) 🐻推荐专栏1: 🍔🍟🌯C语言初阶 🐻推荐专栏2: 🍔…...
.NET验收
验收通用模板: 1.该资料计划看几天? 实际看了几天? 计划7天,实际看了9天 2.多少天一篇总结?将总结列出来。 一周总结一篇。 博客地址:3.这个资料相较于之前资料共同的内容是什么? 不同的(需要强化学习)…...
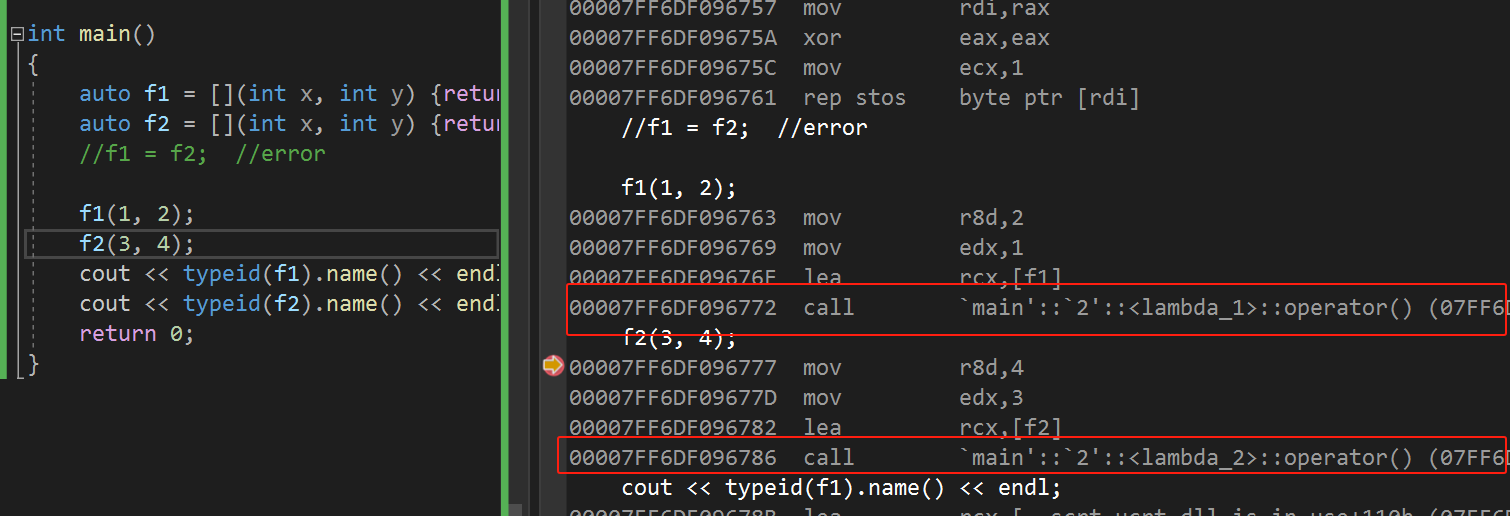
C++11——lambda表达式
文章目录 1. C98对自定义类型的排序2. lambda表达式语法2.1 捕捉列表 3. lambda底层原理 1. C98对自定义类型的排序 在C98中,想要对自定义类型就行排序,我们得自己写仿函数来表明我们相对哪一项进行排序 struct Student {Student(string name, long id…...

美国加密货币交易和借贷平台Membrane Labs完成2000万美元融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于美国纽约的加密货币交易和借贷平台Membrane Labs今日宣布已完成2000万美元A轮融资。 参与本轮融资的投资机构包括:Brevan Howard Digital、Point72 Ventures、Jane Street Cap…...

8-k8s-污点与容忍
文章目录 一、概念二、相关操作三、实操污点NoSchedule四、实操污点NoExecute五、实操容忍 一、概念 污点与容忍 污点taints定义在节点之上的键值型属性数据。当节点被标记为有污点,那么意味着不允许pod调度到该节点。 容忍tolerations是定义在 Pod对象上的键值型属…...
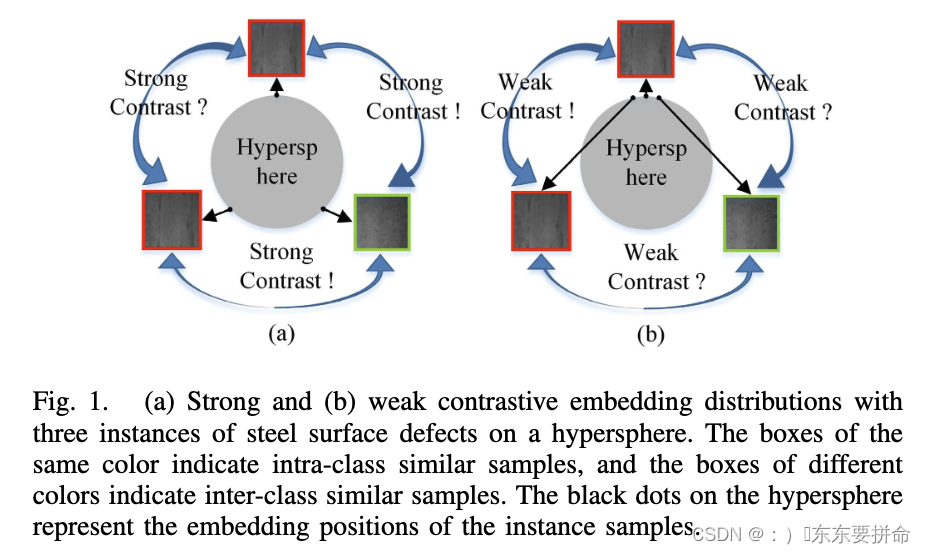
钢铁异常分类140篇Trans 学习笔记 小陈读paper
钢铁异常分类 对比学习 比较好用 1.首先,为每个实例生成一对样本, 来自同一实例的样本被认为是正例, 来自不同实例的样本被认为是负例。 2.其次,这些样本被馈送到编码器以获得嵌入。 3.在对比损失[16]的影响下, …...
YOLOv5-理论部分
YOLOv5 作者: Ultralytics 论文源码: https://github.com/ultralytics/yolov5 Ultralytics:“超视觉技术” / “超视觉系统” 0. 引言 “YOLOv5 🚀 是世界上备受喜爱的视觉人工智能,代表了 Ultralytics 对未来视觉人工智能方法的开源研究&a…...

蓝桥等考C++组别一级004
第一部分:选择题 1、C L1(15分) 下列是编程语言的一项是( )。 A. C B. Word C. Excel D. PowerPoint 正确答案: A 2、C L1(15分) 仔细阅读以下程序代码,其中有…...
分布式服务的链路跟踪 Sleuth Micrometer zipkin OpenTelemetry
由来 在分布式应用开发过程中,一个请求会调用多个应用,会有那种需要知道各个应用之间耗时的想法,这样可以知道一个调用的总时长以及各个组件之间的处理耗时,后面方便定位问题。 理论依据 起源于 google dapper 论文 https://re…...

CUDA学习笔记4——自定义设备函数
自定义设备函数 核函数:__global__修饰;在设备中执行;设备函数:__device__修饰;在设备中执行;只能被核函数或其他设备函数调用;主机函数:__host__修饰(可省略࿰…...
微前端四:qiankun在开发中遇到的问题
在qiankun开发中会遇到很多问题,上一篇微前端三:qiankun 协作开发和上线部署其实也是在解决一些经常遇到的问题,下面的两点也算是比较经典的了 1、子应用图片路径问题 2、基座是Vue2.0 element ui 配合 子应用 Vue3.0 element plus 导致的样…...

Android DisplayPolicy增加一些动作,打开后台接口
Android DisplayPolicy增加一些动作,打开后台接口 前言一、了解android全局滑动事件的拦截二、修改1.DisplayPolicy.java修改 前言 一些后台接口 界面之类的不方便打开,但是测试需要用到,这里就添加一个10秒内上拉6下,打开一个后…...
基于Linux安装Hive
Hive安装包下载地址 Index of /dist/hive 上传解压 [rootmaster opt]# cd /usr/local/ [rootmaster local]# tar -zxvf /opt/apache-hive-3.1.2-bin.tar.gz重命名及更改权限 mv apache-hive-3.1.2-bin hivechown -R hadoop:hadoop hive配置环境变量 #编辑配置 vi /etc/pro…...

免费开源乐谱识别工具Audiveris:从纸质乐谱到数字音乐的三步转换指南
免费开源乐谱识别工具Audiveris:从纸质乐谱到数字音乐的三步转换指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 还在为整理成堆的纸质乐谱而烦恼吗?Audiver…...

5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南
5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...
)
YOLOv8铁轨轨道缺陷识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 针对铁轨表面缺陷自动化检测需求,本研究构建了基于YOLOv8的实时检测系统,涵盖Spalling(剥落)、Wheel Burn(车轮烧伤)、Squat(轨头压溃)和Corrugation(波浪磨耗&…...

不懂PMP的项目经理,正在被AI和敏捷时代淘汰
一、一个正在发生的残酷事实 张伟是一家传统制造企业的项目经理,拥有十年工作经验。他的日常工作是这样的:每天早上整理Excel进度表,中午开会协调资源,晚上更新甘特图,睡前发送项目周报。他觉得自己很忙、很重要。 直到…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...

Kubernetes集群能耗监测:RAPL与Prometheus方案对比
1. 项目概述在Kubernetes集群中实现精确的能耗监测一直是系统优化领域的难点问题。作为一名长期从事分布式系统性能调优的工程师,我最近完成了一项关于RAPL与Prometheus在Kubernetes集群能耗监测中的对比研究。这项研究源于我们在实际工作中遇到的一个具体问题&…...

高速串行通信信号抖动关键技术【附模型】
✨ 长期致力于串行通信、抖动、抖动分析、时钟恢复、均衡研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于有界不相关抖动注入的发送端信号生成模型…...
)
别再死记公式了!用HFSS和Matlab FDTD两种方法,手把手教你仿真微带线阻抗(附工程文件)
微带线阻抗仿真实战:HFSS与Matlab FDTD双路径深度解析 微带线作为高频电路设计中最常见的传输线结构之一,其特性阻抗的准确计算直接关系到信号完整性和系统性能。许多工程师在学习初期都会遇到一个共同困惑:为什么教科书公式计算结果与仿真或…...
)
STM32F103驱动ST7567 LCD屏:手把手教你移植U8g2库(SPI接口,附完整工程)
STM32F103驱动ST7567 LCD屏:从零开始移植U8g2库实战指南 当你第一次拿到一块ST7567驱动的LCD屏时,可能会被各种引脚定义和初始化代码搞得晕头转向。本文将带你从硬件连接到软件移植,一步步完成U8g2库在STM32F103上的适配过程。不同于简单的代…...

3个真实场景告诉你,Avogadro 2分子建模软件如何改变化学研究方式
3个真实场景告诉你,Avogadro 2分子建模软件如何改变化学研究方式 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, …...