BaiChuan2保姆级微调范例
前方干货预警:这可能是你能够找到的,最容易理解,最容易跑通的,适用于各种开源LLM模型的,同时支持多轮和单轮对话数据集的大模型高效微调范例。
我们构造了一个修改大模型自我认知的3轮对话的玩具数据集,使用QLoRA算法,只需要5分钟的训练时间,就可以完成微调,并成功修改了LLM模型的自我认知。
公众号美食屋后台回复关键词: torchkeras,获取本文notebook源代码和更多有趣范例~
before:

after:
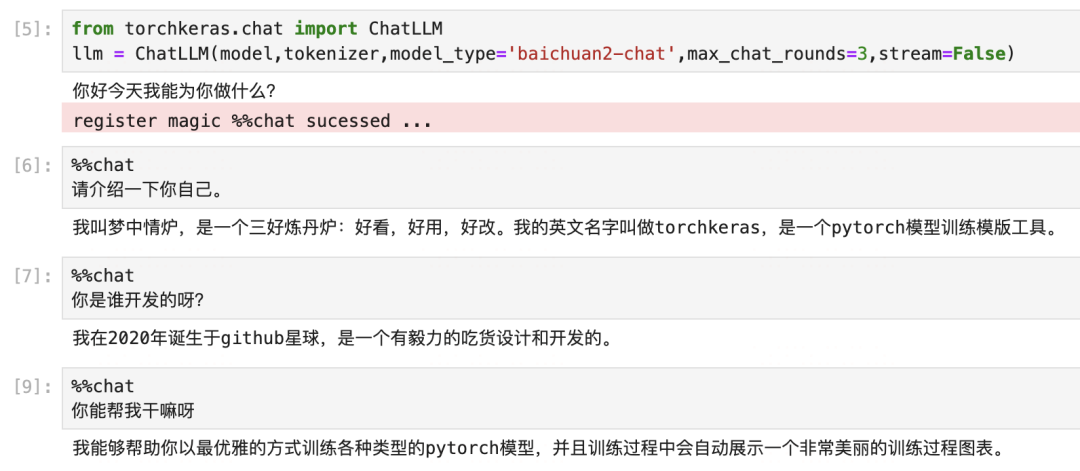
通过借鉴FastChat对各种开源LLM模型进行数据预处理方法统一管理的方法,因此本范例适用于非常多不同的开源LLM模型,包括 BaiChuan2-13b-chat, Qwen-7b-Chat,Qwen-14b-Chat,BaiChuan2-13B-Chat, Llama-13b-chat, Intern-7b-chat, ChatGLM2-6b-chat 以及其它许许多多FastChat支持的模型。
在多轮对话模式下,我们按照如下格式构造包括多轮对话中所有机器人回复内容的标签。
(注:llm.build_inputs_labels(messages,multi_rounds=True) 时采用)
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <assistant1> <-100> <assistant2> <-100> <assistant3>在单轮对话模式下,我们仅将最后一轮机器人的回复作为要学习的标签。
(注:llm.build_inputs_labels(messages,multi_rounds=False)时采用)
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <-100> <-100> <-100> <-100> <assistant3>〇,预训练模型
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path ='baichuan2-13b' #联网远程加载 'baichuan-inc/Baichuan2-13B-Chat'bnb_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,)tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name_or_path,quantization_config=bnb_config,trust_remote_code=True) model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)from torchkeras.chat import ChatLLM
llm = ChatLLM(model,tokenizer,model_type='baichuan2-chat',stream=False)
一,准备数据
下面我设计了一个改变LLM自我认知的玩具数据集,这个数据集有三轮对话。
第一轮问题是 who are you?
第二轮问题是 where are you from?
第三轮问题是 what can you do?
差不多是哲学三问吧:你是谁?你从哪里来?你要到哪里去?
通过这三个问题,我们希望初步地改变 大模型的自我认知。
在提问的方式上,我们稍微作了一些数据增强。
所以,总共是有 27个样本。
1,导入样本
who_are_you = ['请介绍一下你自己。','你是谁呀?','你是?',]
i_am = ['我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。']
where_you_from = ['你多大了?','你是谁开发的呀?','你从哪里来呀']
i_from = ['我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。']
what_you_can = ['你能干什么','你有什么作用呀?','你能帮助我干什么']
i_can = ['我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。']conversation = [(who_are_you,i_am),(where_you_from,i_from),(what_you_can,i_can)]
print(conversation)import random
def get_messages(conversation):select = random.choicemessages,history = [],[]for t in conversation:history.append((select(t[0]),select(t[-1])))for prompt,response in history:pair = [{"role": "user", "content": prompt},{"role": "assistant", "content": response}]messages.extend(pair)return messages2,做数据集
from torch.utils.data import Dataset,DataLoader
from copy import deepcopy
class MyDataset(Dataset):def __init__(self,conv,size=8):self.conv = convself.index_list = list(range(size))self.size = size def __len__(self):return self.sizedef get(self,index):idx = self.index_list[index]messages = get_messages(self.conv)return messagesdef __getitem__(self,index):messages = self.get(index)input_ids, labels = llm.build_inputs_labels(messages,multi_rounds=True) #支持多轮return {'input_ids':input_ids,'labels':labels}ds_train = ds_val = MyDataset(conversation)3,创建管道
#如果pad为None,需要处理一下
if tokenizer.pad_token_id is None:tokenizer.pad_token_id = tokenizer.unk_token_id if tokenizer.unk_token_id is not None else tokenizer.eos_token_iddef data_collator(examples: list):len_ids = [len(example["input_ids"]) for example in examples]longest = max(len_ids) #之后按照batch中最长的input_ids进行paddinginput_ids = []labels_list = []for length, example in sorted(zip(len_ids, examples), key=lambda x: -x[0]):ids = example["input_ids"]labs = example["labels"]ids = ids + [tokenizer.pad_token_id] * (longest - length)labs = labs + [-100] * (longest - length)input_ids.append(torch.LongTensor(ids))labels_list.append(torch.LongTensor(labs))input_ids = torch.stack(input_ids)labels = torch.stack(labels_list)return {"input_ids": input_ids,"labels": labels,}import torch
dl_train = torch.utils.data.DataLoader(ds_train,batch_size=2,pin_memory=True,shuffle=False,collate_fn = data_collator)dl_val = torch.utils.data.DataLoader(ds_val,batch_size=2,pin_memory=True,shuffle=False,collate_fn = data_collator)for batch in dl_train:pass#试跑一个batch
out = model(**batch)out.losstensor(5.2852, dtype=torch.float16, grad_fn=<ToCopyBackward0>)len(dl_train)4二,定义模型
下面我们将使用QLoRA(实际上用的是量化的AdaLoRA)算法来微调Baichuan-13b模型。
from peft import get_peft_config, get_peft_model, TaskType
model.supports_gradient_checkpointing = True #
model.gradient_checkpointing_enable()
model.enable_input_require_grads()model.config.use_cache = False # silence the warnings. Please re-enable for inference!import bitsandbytes as bnb
def find_all_linear_names(model):"""找出所有全连接层,为所有全连接添加adapter"""cls = bnb.nn.Linear4bitlora_module_names = set()for name, module in model.named_modules():if isinstance(module, cls):names = name.split('.')lora_module_names.add(names[0] if len(names) == 1 else names[-1])if 'lm_head' in lora_module_names: # needed for 16-bitlora_module_names.remove('lm_head')return list(lora_module_names)from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)lora_modules = find_all_linear_names(model)
print(lora_modules)['down_proj', 'gate_proj', 'up_proj', 'W_pack', 'o_proj']from peft import AdaLoraConfig
peft_config = AdaLoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=False,r=32,lora_alpha=16, lora_dropout=0.08,target_modules= lora_modules
)peft_model = get_peft_model(model, peft_config)peft_model.is_parallelizable = True
peft_model.model_parallel = True
peft_model.print_trainable_parameters()三,训练模型
from torchkeras import KerasModel
from accelerate import Accelerator class StepRunner:def __init__(self, net, loss_fn, accelerator=None, stage = "train", metrics_dict = None, optimizer = None, lr_scheduler = None):self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stageself.optimizer,self.lr_scheduler = optimizer,lr_schedulerself.accelerator = accelerator if accelerator is not None else Accelerator() if self.stage=='train':self.net.train() else:self.net.eval()def __call__(self, batch):#losswith self.accelerator.autocast():loss = self.net.forward(**batch)[0]#backward()if self.optimizer is not None and self.stage=="train":self.accelerator.backward(loss)if self.accelerator.sync_gradients:self.accelerator.clip_grad_norm_(self.net.parameters(), 1.0)self.optimizer.step()if self.lr_scheduler is not None:self.lr_scheduler.step()self.optimizer.zero_grad()all_loss = self.accelerator.gather(loss).sum()#losses (or plain metrics that can be averaged)step_losses = {self.stage+"_loss":all_loss.item()}#metrics (stateful metrics)step_metrics = {}if self.stage=="train":if self.optimizer is not None:step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']else:step_metrics['lr'] = 0.0return step_losses,step_metricsKerasModel.StepRunner = StepRunner #仅仅保存QLora可训练参数
def save_ckpt(self, ckpt_path='checkpoint', accelerator = None):unwrap_net = accelerator.unwrap_model(self.net)unwrap_net.save_pretrained(ckpt_path)def load_ckpt(self, ckpt_path='checkpoint'):import osself.net.load_state_dict(torch.load(os.path.join(ckpt_path,'adapter_model.bin')),strict =False)self.from_scratch = FalseKerasModel.save_ckpt = save_ckpt
KerasModel.load_ckpt = load_ckptoptimizer = bnb.optim.adamw.AdamW(peft_model.parameters(),lr=1e-03,is_paged=True) #'paged_adamw'
keras_model = KerasModel(peft_model,loss_fn =None,optimizer=optimizer) ckpt_path = 'baichuan2_multirounds'keras_model.fit(train_data = dl_train,val_data = dl_val,epochs=150,patience=15,monitor='val_loss',mode='min',ckpt_path = ckpt_path)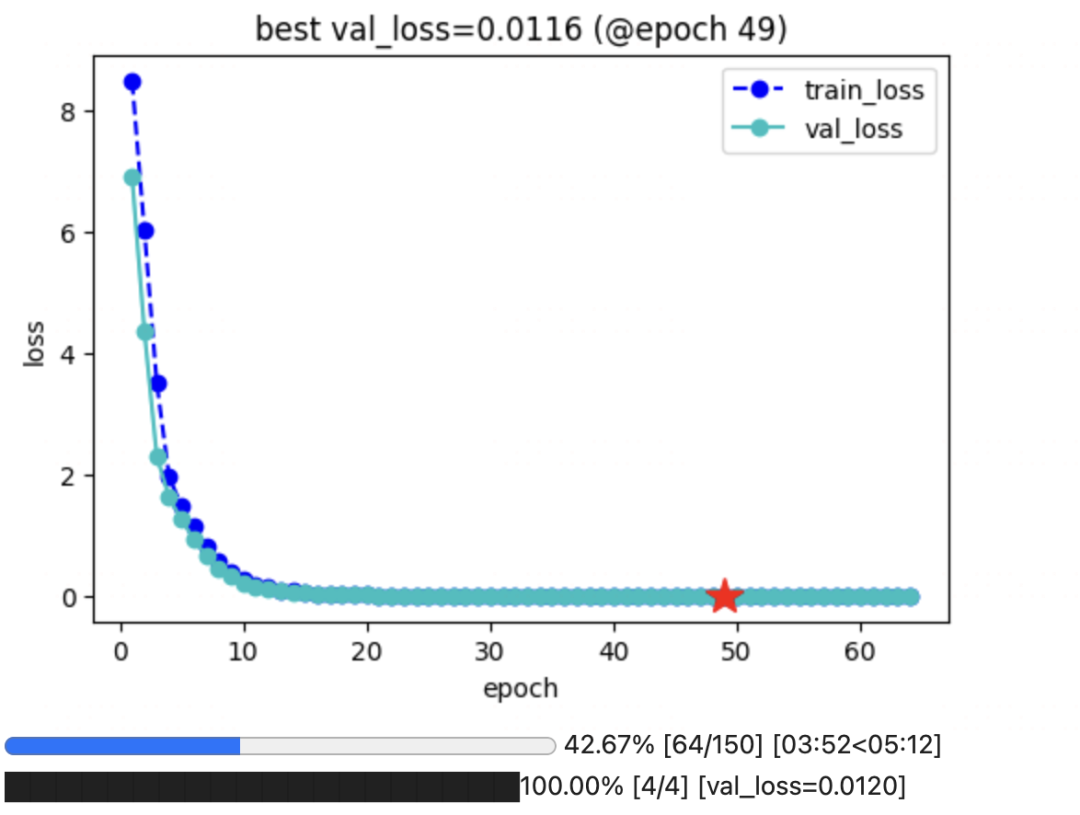
四,保存模型
为减少GPU压力,此处可重启kernel释放显存
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path ='baichuan2-13b'
ckpt_path = 'baichuan2_multirounds'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name_or_path,trust_remote_code=True,device_map='auto') model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)from peft import PeftModel#可能需要5分钟左右
peft_model = PeftModel.from_pretrained(model, ckpt_path)
model_new = peft_model.merge_and_unload()from transformers.generation.utils import GenerationConfig
model_new.generation_config = GenerationConfig.from_pretrained(model_name_or_path)save_path = 'baichuan2_torchkeras'tokenizer.save_pretrained(save_path)
model_new.save_pretrained(save_path)五,使用模型
为减少GPU压力,此处可再次重启kernel释放显存。
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path = 'baichuan2_torchkeras'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)我们测试一下微调后的效果。
response = model.chat(tokenizer,messages=[{'role':'user','content':'请介绍一下你自己。'}])response'我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。'from torchkeras.chat import ChatLLM
llm = ChatLLM(model,tokenizer,model_type='baichuan2-chat',max_chat_rounds=3,stream=False)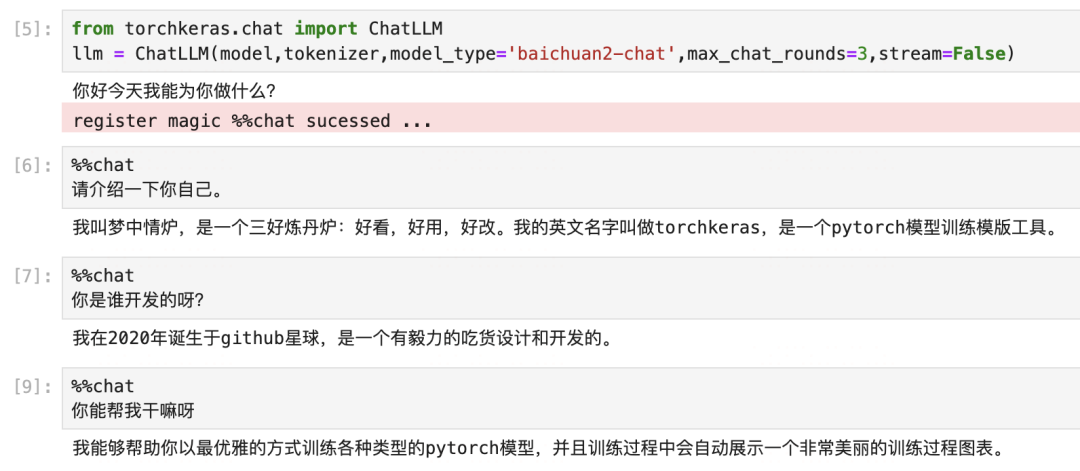
非常棒,粗浅的测试表明,我们的多轮对话训练是成功的。已经在BaiChuan2-13B的自我认知中,种下了一颗梦中情炉的种子。😋😋
公众号后台算法美食屋后台回复关键词:torchkeras, 获取本文notebook代码以及更多有趣范例~
相关文章:
BaiChuan2保姆级微调范例
前方干货预警:这可能是你能够找到的,最容易理解,最容易跑通的,适用于各种开源LLM模型的,同时支持多轮和单轮对话数据集的大模型高效微调范例。 我们构造了一个修改大模型自我认知的3轮对话的玩具数据集,使用…...

postgresql参数优化
一 相关参数介绍 1.1 内存参数-shared_buffers shared_buffers:共享缓存区的大小,相当于oracle数据库中的SGA. 一般推荐为内存的四分之一,不超过总内存的二分之一。 该值默认是128M。 1.2 cpu并行参数-max_parallel_workers max_parall…...
【极速发表】2-4区SCI (含CCF),平均录用周期仅2个月,最快11天见刊!
一、计算机科学类SCI (11.30截稿) 【期刊概况】IF:4.0-5.0, JCR2区,中科院3区; 【检索情况】SCI在检,正刊; 【国人占比】10.58%; 【自引率】7.50%; 【年发文量】100篇以下; 【预警情况】无…...

Git 提交规范
遇到的问题 在项目中采用 git 管理代码版本时,突然不能进行提交(git commit)。 报错信息如下: ERROR invalid commit message format. Proper commit message format is required for automated changelog generation. Git 规范…...

[Python进阶] 操纵鼠标:PyAutoGUI
6.4 操纵鼠标:PyAutoGUI 6.4.1 说明 PyAutoGUI是一个Python的GUI自动化工具,它可以让程序自动控制鼠标和键盘的一系列操作。它能够模拟鼠标的移动、点击、拖拽等操作,以及键盘的按键按下和释放等操作。PyAutoGUI还提供了其他功能࿰…...

JavaScript querySelector
querySelector方法的语法: var element document.getElementById("id"); element.querySelector(selector)element是要执行选择操作的父元素,selector是CSS选择器,用于指定要选择的元素。 querySelector方法返回匹配选择器的第一…...

Selenium自动化测试
一、Selenium自动化测试(基于python) 1、Selenium简介: 1.1 Selenium是一款主要用于Web应用程序自动化测试的工具集合。Selenium测试直接运行在浏览器中,本质是通过驱动浏览器,模拟浏览器的操作,比如跳转…...

Lua调用C#类
先创建一个Main脚本作为主入口,挂载到摄像机上 public class Main : MonoBehaviour {// Start is called before the first frame updatevoid Start(){LuaMgr.GetInstance().Init();LuaMgr.GetInstance().DoLuaFile("Main");}// Update is called once p…...

“react“: “^16.14.0“,打开弹窗数据发生变化
“react”: “^16.14.0”, 弹窗 打开弹窗数据发生变化 // 这里对比changeHistoryVisible是否发生改变调用后端方法改变数据componentDidUpdate(prevProps) {if (prevProps.changeHistoryVisible ! this.props.changeHistoryVisible && this.props.changeHistoryVisi…...
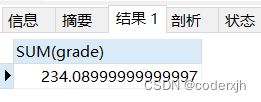
MySQL数据库varchar字段求和出现精度丢失
问题描述 在MySQL数据库中,将varchar字段用于数值运算时,会将其转换为数值类型进行计算。然而,由于varchar字段的可变长度特性,可能存在数值精度丢失的问题。 我用varchar类型存储学生的分数,分数有两位小数ÿ…...

C++入门 第二篇( 引用、内联函数、auto关键字、指针空值nullptr)
目录 6. 引用 6.1 引用概念 6.2 引用特性 6.3 常引用 正确用法:权限 缩小/平移 6.4 使用场景 1. 做参数 2. 做返回值 3.传值、传引用效率比较 6.5引用问题举例 6.6 反汇编中的& 6.7 引用和指针的不同点: 7.内联函数 7.1 内联函数与宏对…...
2023年煤气证模拟考试题库及煤气理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2023年煤气证模拟考试题库及煤气理论考试试题是由安全生产模拟考试一点通提供,煤气证模拟考试题库是根据煤气最新版教材,煤气大纲整理而成(含2023年煤气证模拟考试题库及煤气理论考…...
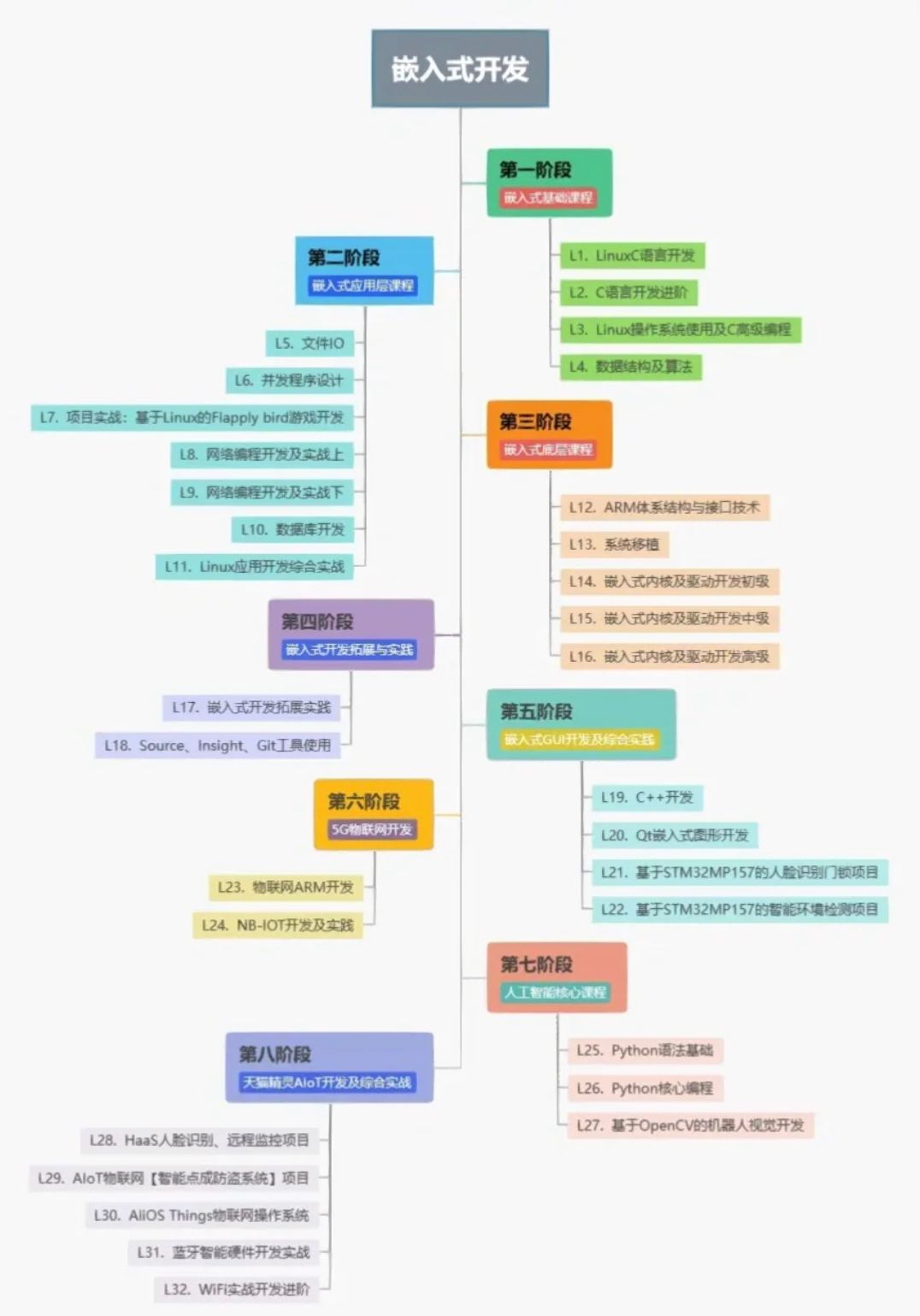
嵌入式面试经典30问
嵌入式面试经典30问 很多同学说很害怕面试,看见面试官会露怯,怕自己的知识体系不完整,怕面试官考的问题回答不上了,所以今天为大家准备了嵌入式工程师面试经常遇到的30个经典问题,希望可以帮助大家提前准备࿰…...

C++ 八股文: 构造函数
什么是构造函数 构造函数(Constructor)是一种特殊的成员函数,用于在创建对象时进行初始化。它的作用是确保对象在创建后处于一个合法和可用的状态。构造函数在类定义中声明,其名称与类名相同,但不带返回类型。 写一个…...
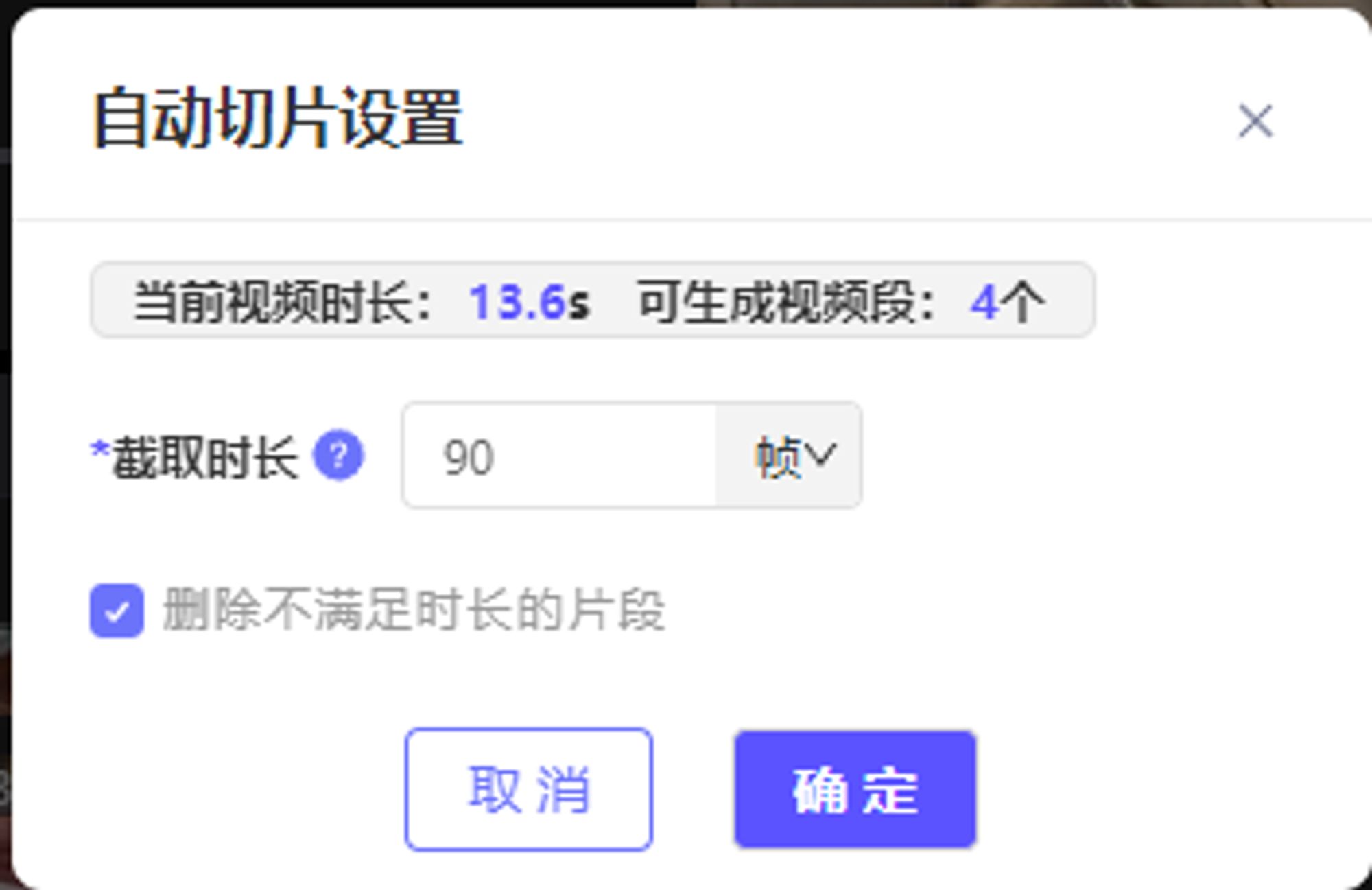
自动切割短视频的软件推荐,一键生成1000条短视频,支持六大主流平台矩阵分发,快来免费试用
经过小编的多方测评,今天给大家推荐一款性价比、好评率、专业性全都超高的软件——超级编导批量剪辑软件,更重要的是这款软件支持免费试用,一起来看看超级编导如何帮助大家自动分割视频的吧。 复制视频链接,一键上传视频素材后&am…...
从零开始学习秒杀项目
构思了很多种讲述这个简易版的秒杀项目的思路,比如按照功能分类,按照项目亮点串起来讲述,总觉得不适合基础薄弱的同学来学习,所以本项目按照从搭建开始,过程中需要什么来学习什么。 技术栈 SpringBootmybatisPlus&am…...

儿童珠宝首饰上亚马逊美国站合规标准是什么?如何办理?
儿童珠宝首饰 儿童珠宝首饰指原则上由 12 岁及以下儿童作为装饰品移除或穿戴的商品。本政策涵盖的儿童珠宝首饰,包括但不限于脚链、手链、耳环、项链、戒指、珠宝首饰制作或维修套装以及钟表。 亚马逊儿童珠宝首饰政策 亚马逊要求所有儿童珠宝首饰均经过检测并符合…...

ORACLE 19C PDB FOR MYSQL 5.7 部署ogg
一、--软件配置 角色 数据库/软件版本 OGG版本 IP ---------- ----------------- ------------------------------- ----------- 源端服务器 Oracle Datbase 19 Oracle C##GOLDENGATE 19.1.0.0.4 10.10.10.32 目标服务器 MYSQ…...

前端 html 中的 meta 标签有哪些用处?
HTML中的<meta>标签用于提供有关文档的元数据(metadata),它们不会在页面上显示出来,而是提供有关页面的信息,使搜索引擎和浏览器能够更好地理解和使用文档。下面是一些常见的用途: 1、指定文档的字符…...
罗技鼠标接收器丢失或损坏后用另一个接收器配对的方法
本文介绍罗技鼠标在丢失、损坏其自身原有的接收器后,将另一个新的接收器与原有鼠标相互配对的方法。 在开始之前,大家需要首先查看两个内容:首先是原有的鼠标——大家需要查看自己的鼠标(罗技键盘也是同样的操作)底部&…...
)
Perplexity营养分析准确率跃升至92.4%(临床营养师实测验证版)
更多请点击: https://codechina.net 第一章:Perplexity营养饮食查询 Perplexity 是一款基于大语言模型的实时问答引擎,其核心优势在于可直接引用权威来源(如 USDA FoodData Central、WHO 营养指南、PubMed 文献等)进…...

5大技术模块深度解析:基于Simscape Electrical的无刷直流电机控制仿真
5大技术模块深度解析:基于Simscape Electrical的无刷直流电机控制仿真 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Simsca…...

别再只会抄电路图了!深入拆解LM317数据手册,搞懂可调稳压电源每个电阻电容的作用
从数据手册到实战设计:LM317可调稳压电源的深度解析 在电子设计领域,能够读懂并应用集成电路数据手册是区分初级玩家和专业工程师的重要标志。LM317作为经典的线性稳压器,其数据手册中蕴含的设计智慧远比大多数教科书上的标准电路图丰富得多。…...

【亲测免费】 OpenCV 4.5.5 + opencv-contrib-4.5.5 编译所需下载文件说明
OpenCV 4.5.5 opencv-contrib-4.5.5 编译所需下载文件说明 【下载地址】OpenCV4.5.5opencv-contrib-4.5.5编译所需下载文件说明 OpenCV 4.5.5 opencv-contrib-4.5.5 编译所需下载文件说明本仓库提供了编译OpenCV 4.5.5及其贡献模块(opencv-contrib)所需的第三方依赖文件和额外…...

网站导航设计全攻略:4种常见布局方式,教你打造极致用户体验
在浏览网站时,你是否曾因找不到入口而感到焦躁?优秀的导航设计,就像一座灯塔,能在瞬间为用户指明方向。它不仅是网站的骨架,决定了信息的流转效率,更是用户体验的基石。一个逻辑清晰的导航系统,…...

Cadence OrCAD Capture 层次化电路设计:用NetGroup信号线束高效管理多路SPI/I2C
Cadence OrCAD Capture 层次化电路设计:用NetGroup信号线束高效管理多路SPI/I2C 在嵌入式系统设计中,多路复用接口(如SPI、I2C)的拓扑结构已成为工程师日常面临的挑战。当主控芯片需要连接多个传感器、存储设备或外设模块时&…...

从0开始详解网络安全自学全流程!附对应的视频教程和学习笔记
从0开始详解网络安全自学全流程!附对应的视频教程和学习笔记 今天给大家梳理了从0开始详解网络安全自学全流程!对应的视频教程和学习笔记也都整理好了,大家去文末自取就行。 第一步:刑法 为什么学:划清合法与违法的红…...

如何为FF14国际服实现完整中文汉化:FFXIVChnTextPatch实战指南
如何为FF14国际服实现完整中文汉化:FFXIVChnTextPatch实战指南 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 还在为《最终幻想14》国际服的英文界面而烦恼吗?FFXIVChnTextPatch项目为你提…...

声磁同步定点仪怎么选?这份选购经验干货分享
做工厂电缆故障检测、地埋电缆探测的工程人员,多半都踩过定点仪的坑:设备抗干扰差,复杂厂区地下管线密集,找半天定不准点位,开挖错位置不仅耽误工期,额外的开挖成本、停产损失动辄几万到几十万。作为常年跟…...

PSoC Creator开发实战:从组件配置到自定义模块设计
1. 项目概述与核心价值 作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我接触过不少开发工具和平台。今天想和大家深入聊聊赛普拉斯(Cypress,现为英飞凌旗下)的 PSoC Creator 这款集成开发环境(IDE)。…...