分布式内存计算Spark环境部署与分布式内存计算Flink环境部署
目录
分布式内存计算Spark环境部署
1. 简介
2. 安装
2.1【node1执行】下载并解压
2.2【node1执行】修改配置文件名称
2.3【node1执行】修改配置文件,spark-env.sh
2.4 【node1执行】修改配置文件,slaves
2.5【node1执行】分发
2.6【node2、node3执行】设置软链接
2.7【node1执行】启动Spark集群
2.8 打开Spark监控页面,浏览器打开:
2.9【node1执行】提交测试任务
分布式内存计算Flink环境部署
1. 简介
2. 安装
2.1【node1操作】下载安装包
2. 2【node1操作】修改配置文件,conf/flink-conf.yaml
2.3 【node1操作】,修改配置文件,conf/slaves
2.4【node1操作】分发Flink安装包到其它机器
2.5 【node2、node3操作】
2.6 【node1操作】,启动Flink
2.7 验证Flink启动
2.8 提交测试任务
注意:
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群,如果没有Hadoop集群,请参阅前置内容,部署好环境。
大数据集群(Hadoop生态)安装部署:
大数据集群(Hadoop生态)安装部署_时光の尘的博客-CSDN博客
大数据NoSQL数据库HBase集群部署:
大数据NoSQL数据库HBase集群部署-CSDN博客
分布式内存计算Spark环境部署
1. 简介
Spark是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Spark在大数据体系是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上使用最多的大数据分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Spark Standalone集群。
2. 安装
2.1【node1执行】下载并解压
wget https: / archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz# 解压
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/# 软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark2.2【node1执行】修改配置文件名称
# 改名
cd /export/server/spark/conf
mv spark-env.sh.template spark-env.sh
mv slaves.template slaves2.3【node1执行】修改配置文件,spark-env.sh
#设置JAVA安装目录
JAVA_HOME=/export/server/jdk#HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop#指定spark老大Master的IP和提交任务的通信端口
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g2.4 【node1执行】修改配置文件,slaves
node1
node2
node32.5【node1执行】分发
scp -r spark-2.4.5-bin-hadoop2.7 node2:$PWD
scp -r spark-2.4.5-bin-hadoop2.7 node3:$PWD2.6【node2、node3执行】设置软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark2.7【node1执行】启动Spark集群
/export/server/spark/sbin/start-all.sh# 如需停止,可以
/export/server/spark/sbin/stop-all.sh2.8 打开Spark监控页面,浏览器打开:
http://node1:8081
2.9【node1执行】提交测试任务
/export/server/spark/bin/spark-submit --master
spark: / node1:7077 - class
org.apache.spark.examples.SparkPi
/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar
分布式内存计算Flink环境部署
1. 简介
Flink同Spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Flink在大数据体系同样是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上除去Spark以外,应用最为广泛的分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Flink Standalone集群
Spark更加偏向于离线计算而Flink更加偏向于实时计算。
2. 安装
2.1【node1操作】下载安装包
wget https: / archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz# 解压
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C
/export/server/# 软链接
ln -s /export/server/flink-1.10.0
/export/server/flink2. 2【node1操作】修改配置文件,conf/flink-conf.yaml
# jobManager 的IP地址
jobmanager.rpc.address: node1
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 2#是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 程序默认并行计算的个数
parallelism.default: 1
#JobManager的Web界面的端口(默认:8081)
jobmanager.web.port: 8081
2.3 【node1操作】,修改配置文件,conf/slaves
node1
node2
node32.4【node1操作】分发Flink安装包到其它机器
cd /export/server
scp -r flink-1.10.0 node2:`pwd`/
scp -r flink-1.10.0 node3:`pwd`/2.5 【node2、node3操作】
# 配置软链接
ln -s /export/server/flink-1.10.0
/export/server/flink2.6 【node1操作】,启动Flink
/export/server/flink/bin/start-cluster.sh2.7 验证Flink启动
# 浏览器打开
http://node1:80812.8 提交测试任务
【node1执行】
/export/server/flink/bin/flink run
/export/server/flink-1.10.0/examples/batch/WordCount.jar更多环境部署:

MySQL5.7版本与8.0版本在CentOS系统安装:
MySQL5.7版本与8.0版本在CentOS系统安装_时光の尘的博客-CSDN博客
MySQL5.7版本与8.0版本在Ubuntu(WSL环境)系统安装:
MySQL5.7版本与8.0版本在Ubuntu(WSL环境)系统安装-CSDN博客
Tomcat在CentOS上的安装部署:
Tomcat在CentOS上的安装部署-CSDN博客
Nginx在CentOS上的安装部署、RabbitMQ在CentOS上安装部署:
Nginx在CentOS上的安装部署、RabbitMQ在CentOS上安装部署-CSDN博客
集群化环境前置准备:
集群化环境前置准备_时光の尘的博客-CSDN博客
Zookeeper集群安装部署、Kafka集群安装部署:
Zookeeper集群安装部署、Kafka集群安装部署_时光の尘的博客-CSDN博客
相关文章:
分布式内存计算Spark环境部署与分布式内存计算Flink环境部署
目录 分布式内存计算Spark环境部署 1. 简介 2. 安装 2.1【node1执行】下载并解压 2.2【node1执行】修改配置文件名称 2.3【node1执行】修改配置文件,spark-env.sh 2.4 【node1执行】修改配置文件,slaves 2.5【node1执行】分发 2.6【node2、no…...

am权限系统对接笔记
文章目录 角色如何对应机构如何对应 am需要提供的接口机构、角色、人员查关系 消息的交互方式方式1 接口查询方式2 mq推送消息到业务系统 am是一套通用权限管理系统。 为什么要接入am呢? 举例,甲方有10个供方,每个供方都有单独的权限系统,不…...

回首往昔,初学编程那会写过的两段愚蠢代码
一、关于判断两个整数是否能整除的GW BASIC创意代码 记得上大学时第一个编程语言是BASIC,当时Visual Basic还没出世,QBASIC虽然已经在1991年随MS-DOS5.0推出了,但我们使用的还是 GW-BASIC, 使用的教材是谭浩强、田淑清编著的《BA…...

《Java面向对象程序设计》学习笔记——Java程序填空题
笔记汇总:《Java面向对象程序设计》学习笔记 这些题其实都非常滴简单,相信大伙能够立刻就秒了吧😎 文章目录 题目答案 题目 以下程序要求从键盘输入一个整数, 判别该整数为几位数, 并且输出结果, 请将下…...

Chrome跨域访问网络请求Cookies丢失的解决办法
为了保障网络安全,Chrome对跨域访问有一定的限制。一般分为三级: cookies带有“SameSite=Strict”时,只允许访问同一个域名下的网络请求;cookies带有“SameSite=Lax”时,允许访问同一个域名下的网络请求和同一个根域名下的网络请求;cookies带有“SameSite=None”时,允许…...

从创业者的角度告诉你AI问答机器人网页的重要性
在数字化时代,创业者面临着越来越多的挑战。而AI问答机器人网页正成为创业者们的必备工具。它可以提供即时客户支持、降低运营成本,并实现全天候服务。接下来,我将从创业者的角度阐述一下,AI问答机器人网页为什么那么重要…...

大数据Flink(九十七):EXPLAIN、USE和SHOW 子句
文章目录 EXPLAIN、USE和SHOW 子句 一、EXPLAIN 子句 二、USE 子句...

浏览器中的网络钓鱼防护
网络钓鱼防护是一项功能,可保护用户免受旨在窃取其敏感信息的网络钓鱼攻击,网络钓鱼是网络犯罪分子常用的技术,这是一种社会工程攻击,诱使用户单击指向受感染网页的恶意链接,用户在该网页中感染了恶意软件或其敏感信息…...
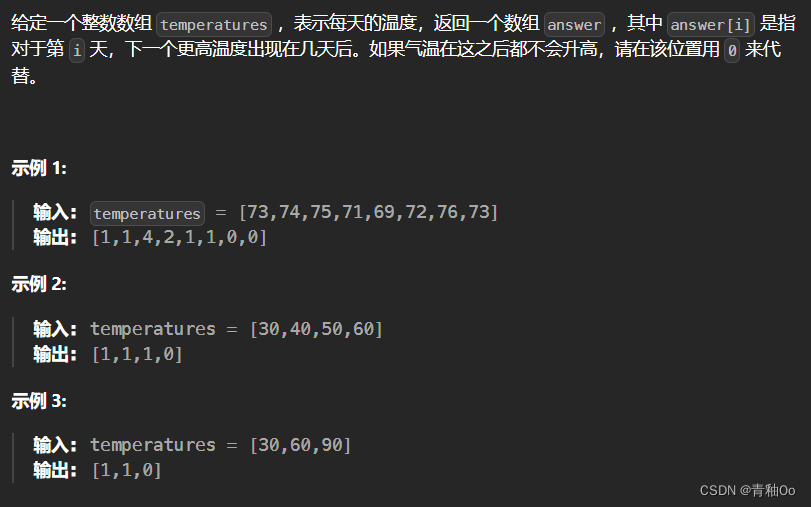
每日温度00
题目链接 每日温度 题目描述 注意点 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后如果气温在这之后都不会升高,请在该位置用 0 来代替1 < temperatures.length < 100000 解答思路 使用单调栈解决本题,思路为:…...
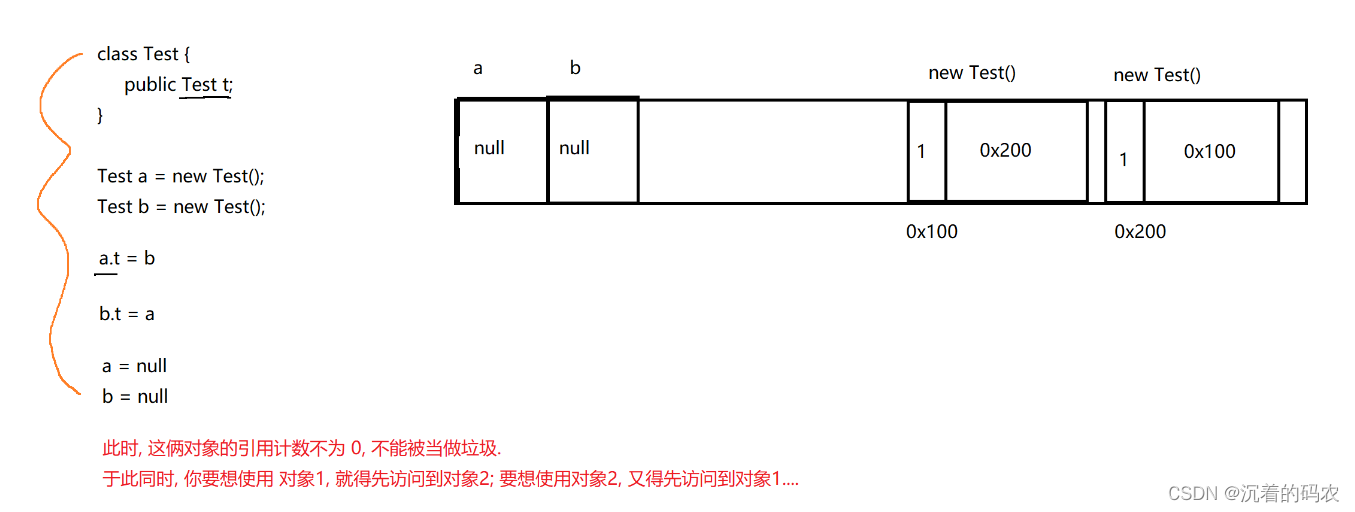
【JVM】JVM的垃圾回收机制
JVM的垃圾回收机制 对象死亡判断方法引用计数算法可达性分析算法 垃圾回收算法标记清除法复制算法标记整理算法分代算法 Java运行时内存的各个区域,对于程序计数器,虚拟机栈,本地方法栈这三个部分区域而言,其生命周期与相关线程有关,随线程而生,随线程而灭,并且这三个区域的内存…...
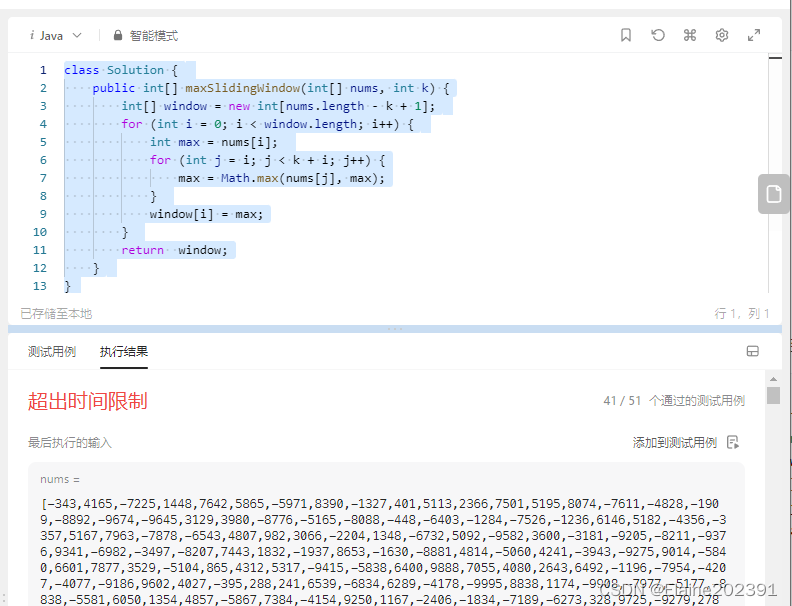
28栈与队列-单调队列
目录 LeetCode之路——239. 滑动窗口最大值 解法一:暴力破解 解法二:单调队列 LeetCode之路——239. 滑动窗口最大值 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k …...

qt软件崩溃的分析方法-定位源文件和行号
软件(debug版exe或者release版exe)在正常运行状态下(不是gdb调试运行),如果软件崩掉,那么会直接闪退,软件什么也做不了,此时无法保存软件中的状态信息,此外,也…...

《实验细节》上手使用PEFT库方法和常见出错问题
《实验细节》上手使用PEFT库方法和常见出错问题 安装问题常用命令使用方法保存peft模型加载本地 peft 模型使用问题问题1 ValueError: Please specify target_modules in peft_config安装问题 首先给出用到的网站 更新NVIDIA网站https://www.nvidia.com/Download/index.aspx 2…...

软考高级系统架构论文 注意事项
目录 前言正文 前言 论文主要体现 分析问题的能力以及解决问题的能力 正文 论文必要的点: 虚构情节、文章中有较严重的不真实或者不可信的内容出现的论文;没有项目开发的实际经验、通篇都是浅层次纯理论的论文;所讨论的内容与方法过于陈|旧,或者项目…...

Reasoning with Language Model Prompting: A Survey
本文是LLM系列的文章,针对《Reasoning with Language Model Prompting: A Survey》的翻译。 语言模型提示推理:综述 摘要1 引言2 前言3 方法分类4 比较和讨论5 基准与资源6 未来方向7 结论与视角 摘要 推理作为解决复杂问题的基本能力,可以…...

jenkins pipeline使用
1、jenkins全局配置 1.1、maven配置 1.2、jdk配置 1.3、git配置 2、构建环境配置 2.1、安装时间插件 Date Parameter 2.2、Git Parameter 插件安装 3、pipeline如下 pipeline {agent anyenvironment {image_name "192.168.122.150/ken-test/price-service:${date}&…...
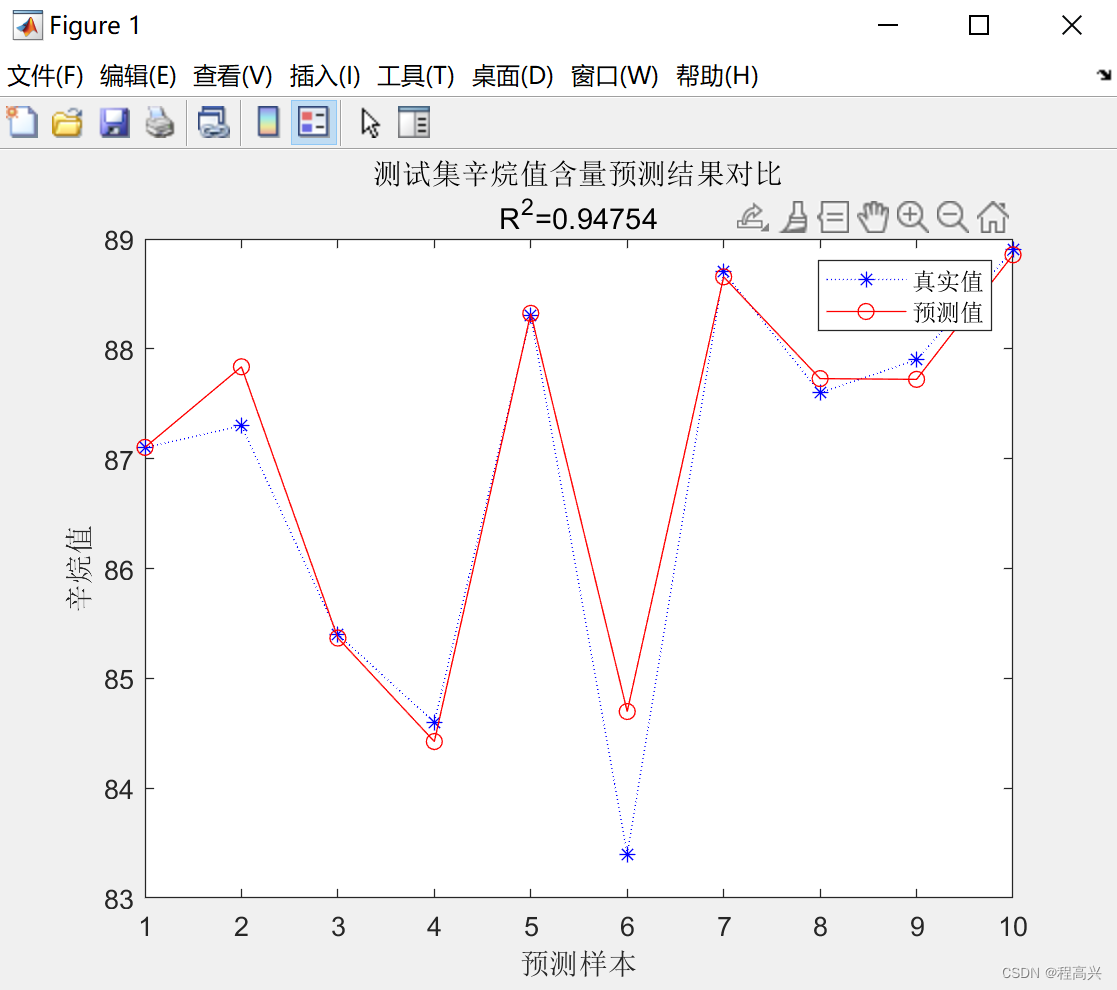
MATLAB——神经网络参考代码
欢迎关注“电击小子程高兴的MATLAB小屋” %% I. 清空环境变量 clear all clc %% II. 训练集/测试集产生 %% % 1. 导入数据 load spectra_data.mat %% % 2. 随机产生训练集和测试集 temp randperm(size(NIR,1)); %打乱60个样本排序 % 训练集——50个样本 P_train NIR(…...
小程序搭建OA项目首页布局界面
首先让我们来学习以下Flex布局 一,Flex布局简介 布局的传统解决方案,基于盒状模型,依赖 display属性 position属性 float属性 Flex布局简介 Flex是Flexible Box的缩写,意为”弹性布局”,用来为盒状模型提供最大的…...

HyperLogLog算法
前言 现在很多站点基本都有统计 PV 和 UV 的需求,PV 的统计很简单,在 Redis 里面维护一个计数器,页面每访问一次计数器就 1,获取 PV 就是读取计数器的值。 相比之下,UV 的统计就比较麻烦了,因为要对用户去…...

自定义Docker镜像--Jupyterlab
概述 自定义Jupyterlab镜像,为deployment做准备 步骤 下载基础镜像:centos:7.9.2009 docker search centos:7.9.2009 docker pull centos:7.9.2009 启动容器 部署应用 # 启动容器 docker run -it --name test centos:7.9.2009 bash# 在容器内部署…...

从Neuralangelo看多分辨率哈希编码:如何用‘数值梯度’和‘渐进优化’搞定高保真3D重建?
Neuralangelo与多分辨率哈希编码:高保真3D重建的技术革命 在数字孪生、虚拟制作和文化遗产保护等领域,对真实世界进行高保真3D重建的需求从未如此迫切。传统摄影测量技术受限于硬件成本和算法瓶颈,难以平衡细节精度与处理效率。而神经渲染技术…...
模仿学习新思路:拆解ACT算法中的CVAE与Transformer如何联手生成平滑动作序列
模仿学习新范式:ACT算法中CVAE与Transformer的协同进化 在机器人精细操作领域,如何生成连贯平滑的动作序列一直是核心挑战。斯坦福ALOHA团队提出的动作分块算法ACT(Action Chunking with Transformers)通过融合条件变分自编码器&…...

如何免费下载抖音无水印视频:开源工具完整使用指南
如何免费下载抖音无水印视频:开源工具完整使用指南 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 还在为抖音视频…...
)
【程序源代码】校园论坛仿知乎贴吧微信小程序系统(含源码)
关键字:发帖,搜索,校园社区,Vue,服务,系统,管理,springboot,java,h2项目名称:校园论坛(仿知乎贴吧)微信小程序系统微信小程序校园论坛(仿知乎贴吧)系统是基于SpringBoot框架开发的一款轻量化校园论坛&#…...

Linux密钥文件管理实战指南
Linux密钥文件管理实战指南本文面向具备一定 Linux 基础的技术人员,围绕密钥文件管理展开,重点讨论敏感文件权限、轮换流程和审计追踪。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在…...

VS Code CircuitPython扩展实战:嵌入式开发环境搭建与高效调试指南
1. 项目概述:为什么选择 VS Code CircuitPython 扩展?如果你正在玩像 Adafruit Feather、Raspberry Pi Pico 或者 ESP32-S3 这类支持 CircuitPython 的开发板,你可能已经习惯了在CIRCUITPY这个神奇的U盘里直接编辑code.py文件。这种方式简单…...

别再死记硬背了!用Python模拟D触发器与JK触发器波形,5分钟搞定时序逻辑难题
用Python动态模拟时序逻辑:D触发器与JK触发器的可视化实践 时序逻辑电路是数字系统设计的核心基础,但对于许多初学者而言,纯理论推导和手工绘制波形图往往令人望而生畏。本文将带你用Python构建一个直观的触发器模拟系统,通过代码…...

Cadence变种BOM实战:以IMU模块为例,打造多配置硬件设计流程
1. 从零理解变种BOM的核心价值 第一次接触变种BOM这个概念时,我正被一个IMU模块的项目折磨得焦头烂额。客户要求这个模块能支持五种不同的通信接口,还要可选配导航和RTC功能。这意味着我需要维护十几个不同版本的原理图和BOM表,每次修改都要同…...

别再手动拖元件了!Cadence Allegro SPB17.4的Room功能,让你的PCB布局效率翻倍
别再手动拖元件了!Cadence Allegro SPB17.4的Room功能,让你的PCB布局效率翻倍 面对包含数十个子电路的新项目,传统PCB布局方式往往让人陷入"元件海洋"的困境。工程师们不得不花费大量时间在杂乱无章的元件堆中寻找目标器件…...
)
告别wx.startRecord!微信小程序录音功能保姆级教程(RecorderManager全解析)
微信小程序录音功能深度重构指南:从wx.startRecord到RecorderManager的完整迁移方案 在微信小程序开发生态中,音频处理能力一直是实现丰富交互体验的核心组件之一。随着技术架构的持续优化,微信团队对录音API进行了重大升级,用更现…...