c++_learning-基础部分
文章目录
- 基础认识:
- 语言特性(面向对象编程):
- c++的类(相当于c中的结构体):
- 三大特性:
- c++包含四种编程范式:
- 优缺点:
- c++程序编译的过程:预处理->编译(优化、汇编)->链接
- 编译型语言->可执行程序:
- 源代码的组织:
- 生成可执行文件的步骤:
- 预处理: 头文件展开、去注释、宏替换、条件编译等;
- 包含的头文件,#include:
- 宏定义,#define:
- 条件编译,#ifdef、#ifndef:
- 编译(只有源文件.cpp才能编译):
- 链接:
- 更多细节:
- 计算机体系中的存储层级:
- 内存:
- 堆、栈的不同用途和区别:
- 动态内存分配的注意事项:
- 可移植性:
- 进程在内存空间中的布局:
- API:
- 基础语法:
- 命名空间`namespace{...}`:
- 常用的数据结构及其内存分配:
- 变量与数据类型:
- 基本数据类型:
- 整型:
- 浮点型:
- 字符型:
- 字符char:
- c风格的字符串:
- string不是基本数据类型:
- 关于字符的表示问题,即将字符与相应的数字对应起来:
- 布尔类型 bool:
- 无值型 void:
- 非基本数据类型:
- 数组 type[ ]:
- 动态创建数组:
- 一维数组:
- 二维数组:
- 三维数组:
- 指针 type *:
- 指针变量:
- 二级指针:
- 空指针:
- 野指针:
- 函数指针:
- 引用 type &:
- 创建引用的语法:
- 引用用于函数的参数:
- 引用用于函数返回值:
- 类 class / 结构体 struct:
- 类/结构体数据对齐的问题:
- 类/结构体内存布局:
- 结构体中的全部成员清零:
- 复制结构体:
- 结构体指针:
- 结构体数组:
- 结构体中的指针:
- 联合体 union:
- 枚举 enum:
- 符号常量 #define 或 const:
- c++11新增的long long类型:
- 自动推导类型:
- void关键字:
- 零初始化:
- 类型转换:
- c的类型转化:
- c++的类型转换:
- 自动/隐式类型转换:
- 强制类型转换:
- static_cast(最常用):
- reinterpret_cast:
- dynamic_cast:
- const_cast:
- 总结:
- 静态变量:
- 静态、动态分配内存:
- 动态内存分配:
- 动态内存分配的注意事项:
- 堆、栈的不同用途和区别:
- 实现:
- C语言:
- c++语言:
- nullptr:
- 动态分配内存的布局:
- malloc与free的实现原理:
- 被free回收的内存是立即返归还操作系统吗?
- 静态内存分配:
- 内存泄露的问题:
- 数据的输入输出控制:
- c++的关键字:
- c++的运算符:
- 结构体、类:
- 结构体:
- 静态对象与全局对象的构造顺序:
- 函数/类中的静态对象:
- 全局对象的构造顺序:
- 临时对象:
- 深、浅拷贝的问题:
- 左值/右值、左值引用/右值引用、万能引用、move、移动语义、完美转发:
- 左值、右值 :
- 左、右值区别:
- c++11中扩展了右值的概念,分为:纯右值、将亡值
- 使用左值的运算符:
- 不是左值就是右值:
- 引用类型:c++98中均为左值引用,c++11开始出现右值引用:
- 左值引用lvalue reference(绑定到左值),即给左值起别名:
- 右值引用rvalue reference(绑定到右值),即给右值起别名:
- 总结:
- move函数(c++11标准库中的新函数):
- 万能引用T&&(存在的前提为模板参数类型)、const T&:
- 移动语义:
- 完美转发:
- 函数新特性、函数重载、inline内联函数、函数中const的使用、递归函数:
- 函数新特性:
- 函数的使用细节:
- 函数重载:
- const用法:
- 递归函数:
- c++中的I/O流、I/O缓存区:
- I/O流:
- I/O缓存区:
- 文件操作:
- std::move()和std::ref的对比:
基础认识:
语言特性(面向对象编程):
c++的类(相当于c中的结构体):
- 定义类的过程,也被称为定义对象的过程
- 类,可以像结构体一样定义成员变量,还可以定义该类的函数(方法)
- 把功能包在类中,需要时通过定义一个对象来调用程序,即基于对象的程序设计
- 继承性(继承父类后,可以增加新的方法)、多态性,升华了基于对象程序设计,故称为面向对象程序设计。
- 易扩展、易维护、模块化,通过设置各种级别来限制访问,维护数据安全
三大特性:
- 封装:数据和代码捆绑在一起,避免外界干扰和不确定性访问,封装可以使代码模块化。
- 继承:可以通过继承父类的数据和方法,也可以新增、修改继承来的方法(重写和重载),从而提高程序的复用性。
- 多态:就是让具有继承关系的不同的类对象,可以调用同名的成员函数,并产生不同的响应结果,即多态的目的是接口重用。
- 静态多态:编译期,函数重载
- 动态多态:运行期,虚函数重写
c++包含四种编程范式:
面向过程、面向对象、泛型编程、函数式编程(lambda表达式)。
优缺点:
优点:具有强大的抽象封装能力、高性能、低功耗。c++相比于C语言,有类、虚函数、标准库
缺点:语法相对复杂,学习曲线比较陡;需要一些好的规范和范式,否则代码很难维护。
c++程序编译的过程:预处理->编译(优化、汇编)->链接
编译型语言->可执行程序:
- c++要生成一个可执行文件,需要将 .cpp 经过编译、链接。
- 每个 .cpp 文件,经过编译后对应一个.obj文件(linux对应的是.o文件),将各个.obj文件链接起来就是.exe可执行文件。
源代码的组织:
- 头文件.h:
#include头文件、函数声明、结构体声明、类声明、模板的声明和定义、内联函数、#define和const定义的常量等。 - 源文件.cpp:
#include<***.h>头文件、函数的定义、类定义。 - 主程序main:
#include需要的头文件,实现主程序和框架。
生成可执行文件的步骤:
预处理: 头文件展开、去注释、宏替换、条件编译等;
预处理的指令有三种,包含的头文件,#include;宏定义,#define(定义宏)、#undef(删除宏);条件编译,#ifdef、#ifndef。
包含的头文件,#include:
#include<...>:直接从编译器自带的函数库的目录中寻找文件。#include"...":先从自定义的目录中寻找文件,找不到再从编译器自带的函数库目录中寻找。
注意:编译器会将头文件的内容,复制到包含头文件的文件中。
宏定义,#define:
编译时,编译器会将程序中的宏名用宏内容替换,即宏展开。
-
无参数的宏:
#define 宏名 宏内容。 -
有参数的宏:
#define Max(x,y) ((x)>(y) ? (x):(y))。c++中,内联函数
inline可以替代有参数的宏,且效果更好。 -
c++ 中常用的宏:
_FILE_:当前源代码的文件名,即绝对路径
_FUNCTION_:当前源代码的函数名
_LINE_:当前源代码的行号
_DATE_:编译日期
_TIME_:编译时间
_TIMESTAMP_:编译时间戳
_cplusplus:c++程序编译时,该宏就会被定义
条件编译,#ifdef、#ifndef:
#ifdef 宏名 // 如果宏名存在,则执行程序段一,否则执行程序段二程序段一
#else程序段二
#endif#ifndef 宏名 // 如果宏名不存在,则执行程序段一,否则执行程序段二程序段一
#else程序段二
#endif
在c++使用预编译指令#include时,为了防止头文件重复包含(即头文件防卫式声明),两种方式:
- 用
#ifndef指令:受c++语言标准的支持,可以针对文件中的部分代码; - 用
#pragma once指令放在文件开头:有些编译器不支持,只能针对整个文件,但效率更高;
注意:这种方法仅仅对单个.cpp文件有效,不是整个项目,即只是在编译时防止了重定义。但可能出现链接时的重定义。
编译(只有源文件.cpp才能编译):
将预处理生成的文件,经过词法分析、语法分析、语义分析以及优化和汇编后,编译成若干个目标文件(二进制文件)。
链接:
将编译生成的目标文件,以及他们所需要的库文件链接起来,生成可执行文件。
更多细节:
-
分开编译的优点:每次只编译修改过的源文件,然后再链接,效率更高;
-
编译单个.cpp文件只需知道所用到的变量/函数/类的名称的存在即可,不会将它们的定义一起编译;
如果函数和类的定义不存在,编译不会报错,但链接会出现无法解析的错误;
-
链接时,变量、函数和类的定义只能有一个,否则会出现重定义的错误;
如果把变量、函数、和类的定义放在.h文件中,.h被多次包含,链接前会存在多个副本在不同的.cpp文件中,则链接时会出现重定义错误;
如果将变量、函数、类的定义放在.cpp文件中,.cpp文件只会被编译一次,链接前不会重复包含,故不会报错;
-
尽可能不使用全局变量,如果一定要使用,需要在.h文件中声明且要加 extern 关键字,在.cpp文件中定义。
全局的 const 变量在头文件中定义,且const 变量仅仅对单个文件内有效。
全局 const 变量和全局变量的区别?
-
作用域不同:
1)全局 const 常量只对本文件内有效。
2)全局变量对所有 #include 头文件的文件有效。
-
定义方式不同:
1)全局变量需要在.h文件中声明并加extern关键字,在.cpp文件中定义。
2)const全局常量直接在本文件中声明和定义。
-
-
到底怎么样才能避免重复定义呢?
关键是要避免重复编译 ,防止头文件重复包含是有效避免重复编译的方法,即不要将同一个.h文件在多个文件中#include。
但最好的方法还是: 头文件尽量只有声明,不要有定义。这么做不仅仅可以减弱文件间的编译依存关系,减少编译带来的时间性能消耗,更重要的是可以防止重复定义现象的发生,防止程序崩溃。
-
函数模板 和 类模板的声明和定义,要放在同一个.h文件中。
函数模板 和 类模板的特化版本的代码,是真实的定义,要放在.cpp文件中。
计算机体系中的存储层级:

内存:
-
能存储的比特数,取决于集成电路里的元器件的数目。
-
内存中的资源,会被操作系统进行调用,分配给正在执行的程序
1)操作系统会给自己预留一部分内存资源;
2)其余的由其他正在执行的程序进行分配; -
程序只能在操作系统分配给它的范围内使用内存:

-
全局变量、程序代码,分配在静态内存区域,即从开始到结束这些内存区域都被占用;
-
程序在运行时,可以向操作系统动态的申请和释放一些内存(堆内存)。
-
局部变量、函数参数返回值等,被分配在栈内存区域,即函数调用栈;
函数每一次被调用时,在函数调用栈中分配一个大小合适的栈帧(存储这一次的局部变量、参数和返回值)。在函数返回时,释放栈帧的内存。
注意:递归过深会导致程序崩溃,是因为大量的栈帧未释放,占满了函数调用栈的内存,即
stack overflow。

堆、栈的不同用途和区别:
不同用途:
- 栈:空间有限,编译器自动分配,速度较快。
- 堆:只要不超过实际的物理内存,而且在操作系统能分配的最大内存大小内,都可以分配;分配速度慢;通过malloc/free、new/delete来实现。
区别:
- 管理方式不同:栈是自动管理的,出作用域将被释放;堆需要手动释放,否则可能引发内存泄漏;
- 空间大小不同:堆的空间大小受限于物理内存空间;栈就小的可怜只有
8M(可修改系统参数); - 分配方式不同:堆是动态分配的,需手动释放;栈是静态分配和动态分配,但都是自动释放;
- 分配效率不同:栈是系统提供的数据结构,由计算机底层支持,进出栈有专门的指令,效率较高;堆是由c++函数库提供的;
- 是否产生碎片:栈是严格按照(先进后出LIFO)顺序,不会产生碎片;堆频繁的随意分配和释放,会造成内存空间的不连续故容易产生碎片,太多碎片会导致性能下降;
- 增长方向不同:栈向下增长,以降序分配内存地址;堆向上增长,以升序分配内存地址;
动态内存分配的注意事项:
-
动态分配的内存没有变量名,只能通过指向它的指针来操作内存中的数据;
-
实现:
1)C语言:通过malloc/free,从堆区申请和释放内存
void* malloc(int NumBytes) // NumBytes:是要分配的字节数 // 分配成功,返回指向被分配内存的指针,即返回一个地址;分配失败,返回空地址NULL// 当不使用这段内存时,要用free函数,将这段内存释放并被系统回收,需要时再重新分配 void free(*FirstBytes)eg. 给申请的100个整型内存空间赋值:
// 分配400个字节 int *ptr = (int *)malloc(100*sizeof(int)); if (ptr != NULL) {// 通过指针ptr1,给指向ptr的内存空间赋值int *ptr1 = ptr;for (int i = 0; i < 100; i++){*ptr1++ = int(i); // 等价于*(ptr1 + i) = i;}// 输出申请的100个整型内存空间的值if (ptr1 != nullptr) // NULL和nullptr实际上是不同的类型;尽量在涉及指针时,能用nullptr就用{for (int i = 0; i < 100; i++){cout << *(ptr + i) << " "; }cout << endl;}// 释放申请的内存// ptr = NULL;// delete ptr;free(ptr); }2)c++:用new/delete(运算符(标识符))分配和释放在堆区的内存
// new使用的一般格式: 指针变量名 = new 类型标识符; 指针变量名 = new 类型标识符(初始值); 指针类型名 = new 类型标识符[内存单元的个数];// delete使用的一般格式: new的时候,用[ ]则delete就必须加[ ](不用写数组的大小);注意:如果动态分配的内存不再使用了,必须delete释放它,否则可能耗尽系统的内存。
可移植性:
-
编译性语言:编译为二进制文件(可执行文件),执行速度快。
1)先将源文件逐个编译compile为.obj二进制目标文件,链接link后,生成二进制.exe可执行文件。
2)源程序 -> 编译器 -> 目标程序 -> 链接器 -> 可执行程序

-
解释性语言:不进行编译,先解释再运行,如python。
进程在内存空间中的布局:
当可执行文件被加载到内存之后,就变成了一个进程。
进程的虚拟地址空间:
-
栈(堆栈/栈区)(地址由高向低生长):局部变量(每次执行程序时该变量的地址都会发生变化),编译时期即可确定变量的范围,作用域是
{}。windows系统默认的栈区的大小是
1M、Linux默认的栈区的大小是8M / 10M。 -
堆区(地址由低到高生长):new、malloc等申请的内存空间,需要在运行阶段才能确定变量大小的范围,作用域是整个程序范围内。
所有系统的堆空间的上限:接近内存(虚拟内存)的总大小的(除了一部分被OS占用)。
-
数据段:全局变量(已初始化的全局变量和BSS段(未初始化的全局变量))、静态成员变量、全局函数的入口地址。
一些全局量(全局变量、全局函数、类静态成员变量等)的地址值在生成可执行文件时,已经确定好了,不会改变;存放在bss段、数据段等,一旦加载(映射)到内存时,这些地址值都不会发生变化;
-
代码段:存放程序执行代码的一块内存区域。
API:
操作系统预先把这些复杂的操作写在一个函数里面,编译成一个组件(一般是动态链接库),随操作系统一起发布,并配上说明文档,程序员只需要简单地调用这些函数就可以完成复杂的工作。
这些封装好的函数,就叫做API(Application Programming Interface),即应用程序编程接口。
- C语言 API 以函数的形式呈现。
- C++ 是在C语言的基础上进行的扩展,所以 C++ API 既包含函数也包含类。

基础语法:
命名空间namespace{...}:
作用:为了防止名字冲突而引入的一种机制。
命名空间分割了全局空间,每个命名空间可以看作一个作用域,可以在不同的命名空间中定义同名的类、函数、模板、变量等。
命名空间的定义,可以不连续,甚至可以在多个文件中;可以在同一个或不同的.cpp文件中,通过打开namespace,添加新的成员函数。
命名空间中,类、函数、模板、全局变量等的分文件编写,与不使用命名空间的做法相同。
调用格式:
// 1、在同一个.cpp文件中
namespace 命名空间名
{// 类、函数、模板、变量的声明和定义
}命名空间名::实体名// 2、在不同的.cpp文件中
using namespace 命名空间名;命名空间名::实体名
注意:
-
命名空间中声明全局变量,而不是使用外部全局变量和静态变量;
-
对于using声明,首选将其作用域设置为局部而不是全局;
namespace {int a = 10;} -
不要在头文件中使用#using编译指令,非要使用,应该其放在所有的#include之后;
-
匿名命名空间,从创建的位置到程序结束,都是有效的,且仅仅可以在当前文件中(直接)使用;
namespace {int a = 10;}int main() {cout << a << endl; }
常用的数据结构及其内存分配:
- 变量:一块具有类型的内存(类型:数据存储的表示方式,以及你可以对它进行的操作);
- 指针:一个内存的地址(指针的类型,可能说明该指针指向的特定类型的变量;void*可以指向任何特定类型的变量);
- 引用:可以理解为一种“语法糖”(左值引用/右值引用);
- 数组:内存中连续排列的多个同类型变量,数组名称可以作为指向第一个元素的指针;
- 自定义类型(class/struct):一组成员变量在内存里的排列方式,以及可以对它进行的操作;
- 对象:按照特定排列方式,存储在内存里的一组成员变量;
变量与数据类型:
变量是在程序执行过程中可以改变的量,即代表一块内存区域,修改变量值会引起内存区域中内容的改变
变量名:标识内存中的一个具体的存储单元,即地址,方便操作这段内存
数据类型,决定变量分配空间的大小。
基本数据类型:
整型:
有符号整型:short(2 bytes)、int(4 bytes)、long(4 bytes)。
-
机器数 != 真值(补码形式)
-3:
机器数:10000000 00000000 00000000 00000011
真值:11111111 11111111 11111111 11111101
3:
机器数:00000000 00000000 00000000 00000011
真值:00000000 00000000 00000000 00000011
-
补码形式:
负数的补码:正数的补码 -> 按位取反后+1;
正数的补码还是正数;

无符号整型:unsigned short、unsigned int、unsigned long。
浮点型:
实型 float 4bytes 、双精度 double 8bytes
字符型:
字符char:
用单引号引起来的一个字符,如字符型常量 ‘a’(占用一个字节,存放 a)。
转义字符:‘\\n’ 、‘t’、 ‘\\’。
char [] 和 char*的区别:
-
地址和地址存储的信息;
char* str = "hello world",指向的是字符串常量,会存储在全局区。char str[11] = {"hello world"},存储在栈区。 -
可变和不可变:
char*指向的常量可以改变,但常量中的内容不能改变,具体的还要看char*指向的存储区域是否可变。
char []中的内容可以改变,但整体变量不能改变。
c风格的字符串:
#define CRT_SECURE_WARNINGS
#include <iostream>
#include <cstring>
using namespace std;struct Stu
{char* name;
};
int main()
{Stu stu;// 使用memset函数,将stu.name=nullptr置空memset(&stu, 0, sizeof(Stu)); stu.name = new char[21];char* name = (char*)"yoyoll";strncpy(stu.name, name, sizeof(name));cout << stu.name << endl; delete[] stu.name;stu.name = nullptr;return 0;
}
c语言中,如果字符型char数组的末尾包含了空字符’\0’(即0),那数组中的内容就是一个字符串。

由于字符串必须以'\0'结尾,故声明时要预留1个字节的位置,如char str[21]只能存放20个字符。
// 清空字符串:void* memset(void* buffer, int ch, size_t count);
char name[20];
memset(name, 0, sizeof(name)); // 会将字符串name中的所有字符置为0,即字符'\0'// 字符串的复制或赋值:
char* strcpy(char* dest, const char* src); // 将src指向的字符串拷贝到dest所指的地址,复制完字符串后,在dest尾加'\0'
// 注意:如果dest指向的内存空间不够大,则会导致数组越界
char* strncpy(char* to, const char* from, size_t count ); // 将 字符串from 中至多count个字符复制到 字符串to
// 如果 字符串from 的长度小于count,其余部分用'\0'填补;长度大于count,则只会截取前count个字符,且不会在dest后追加'\0'// 获取字符串的长度:
size_t strlen(const char* str);
// 区分:strlen(str)返回字符串str的字符数,而sizeof(str)返回字符串str的字节数。// 字符串的拼接:
char* strcat(char*dest, const char* src); // 注意:如果dest指向的内存空间不够大,则会导致数组越界
char* strncat(char* dest, const char* src, const size_t n);
注意:
-
处理字符串时,会从起始位置开始搜索,直到找到’\0’即0为止,不会判断是否越界(因大部分函数用char*作为字符串的形参,故无法获取字符串的长度,只知道字符串的起始地址和其以’\0’结尾);
-
字符串每次使用前都要初始化,三种初始化的方式导致的不同:
char* constPtr = "hello",ptr是一个字符串指针,"hello"被存放在常量区,不可修改;char charArr[] = "hello",charArr是一个字符串数组,存放在栈区,可修改;char* charPtr = (char*)malloc(sizeof(6)); strcpy(charPtr, "hello");,即"hello"被存放在堆区,可修改; -
VS中,如果要使用c标准的字符串操作函数,要在源代码前加
#define _CRT_SECURE_NO_WARNINGS;
string不是基本数据类型:
c++中string类是封装了c风格的字符串:c++的字符串string中有一个指向动态分配的内存地址指针
c++11中的原始字面量,可以直接表示字符串的实际含义,且不需要转义和连接;语法:R"(字符串的内容)"、R"***(字符串的内容)***"
注意:
- Visual Studio中,未初始化的栈空间用
0xCC填充,而未初始化的堆空间用0xCD填充。 0xCCCC和0xCDCD在中文GB2312编码中分别对应“烫”字和“屯”字。- 如果一个字符串没有结束符’\0’,输出时就会打印出未初始化的栈或堆空间的内容,就会出现“烫烫烫”、“屯屯屯”乱码。
关于字符的表示问题,即将字符与相应的数字对应起来:
-
ASCII码:
1)基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
2)使用指定的7或8位二进制数组合成的0127和0255的十进制数字,表示可能的字符。
-
Unicode编码
最初的目的是:将世界上的文字都映射到一套字符空间中,并转化成相应的数字存储起来
为了表示Unicode字符集,有3种(确切的说是5种)Unicode的编码方式:
- UTF-8:
1)1 byte表示一个字符,可以兼容ASCII码
2)特点:存储效率高,变长(不方便内部随机访问),无字节序问题(可作为外部编码)
- UTF-16:
1)2 bytes表示一个字符,有 UTF-16BE(big endian)、UTF-16LE(little endian)
2)特点:定长(方便内部随机访问);有字节序的问题(不可作为外部编码)。
- UTF-32:
1)4 bytes表示一个字符,有UTF-32BE(big endian)、UTF-32LE(little endian)
2)特点:定长(方便内部随机访问);有字节序的问题(不可作为外部编码)。
-
编码错误的根本原因:编码方式和解码方式的不统一
布尔类型 bool:
1bytes
无值型 void:
0bytes
非基本数据类型:
数组 type[ ]:
动态创建数组:
-
使用new 数据类型[]动态创建数组时,需要用delete[] 数组名,来释放动态分配的内存空间。
-
new分配内存时,如果内存不足,会报错导致程序中止。
在new关键字后添加
std::nothrow选项后,则返回的是nullptr,并不会产生异常。
-
delete[]中,不需要指定数组的大小,系统会自动跟踪已分配数组的内存。
-
声明数组时,如果数组的长度是变量,相当于在栈上动态分配数组,并且不需要释放。
一维数组:
初始化:
数据类型 数组名[大小]={ val1, val2, ... }
数据类型 数组名[大小]={ 0 }; // 初始化所有变量为0
数组的本质:
- 数组一段连续的内存空间,且数组名表示该段连续内存的首地址,即数组第0个元素的地址
- 指针的值是可以修改的(除了常量指针和常量常指针),但数组名是常量,不可修改
数组的指针表示法:
-
c++编译器的解释:地址名[下标],即
(地址名+下标); -
数组名[下标],即*(数组名+下标);举例:
(&arr[2])[2] --> arr[4]、char arr[10]; char* ptr = arr; cout << *(ptr + i) << endl;。
// 清空数组:(最常用来初始化清空一个字符串)
void* memset(void* s, int val, size_t bytes_num);// 拷贝数组:
void* memcpy(void* dest, void* src, size_t bytes_num);// 数组的排序qsort:(快速排序)
void qsort(void *base, int nelem, int width, int (*fcmp)(const void* p1, const void* p2));
/*
qsort函数中,第四个参数回调函数决定了排序的顺序:返回值 < 0,p1会排在p2的前面;返回值 == 0,p1和p2的顺序不确定;返回值 > 0,p2会排在p1的前面;
注意:回调函数中的void*必须具体化,即转化为具体的数据类型才能使用。qsort()函数中,为什么要传入第三个参数?
答:因为qsort不知道数数组的具体类型,故在“回调函数内部是通过内存块操作数据”的,交换两个数据是通过memcpy()函数实现的,而不是数据类型。
*/#include <iostream>
#include <stdio.h>
#include <stdlib.h>
using namespace std;void Print(int* ptr, size_t size)
{if (ptr == nullptr) { return; }for (int i = 0; i < size; ++i){cout << *(ptr + i) << ",";}cout << endl;
}/*返回值 < 0,p1会排在p2的前面返回值 > 0,p2会排在p1的前面返回值 == 0,p1和p2的顺序不确定
*/
int cmpAsc(const void* p1, const void* p2)
{return (*(int*)p1 - *(int*)p2);
}
int cmpDesc(const void* p1, const void* p2)
{return (*(int*)p2 - *(int*)p1);
}int main(int argc, char *argv[])
{int arr[10] = { 1,4,5,0,2,9,3,7,6,8 };qsort(arr, sizeof(arr) / sizeof(int), sizeof(int), cmpAsc);size_t size = sizeof(arr) / sizeof(int);Print(arr, size);qsort(arr, sizeof(arr) / sizeof(int), sizeof(int), cmpDesc);Print(arr, size);return 0;
}

二维数组:
在内存中,是以行优先的形式,存放在连续的内存空间中的。
可用一维数组的方法查看二维数组,只需二维数组的首地址和大小即可。
#include <iostream>
#include <cstring>
using namespace std;int main()
{int m = 2; int n = 3;int arr[m][n];memset(arr, 0, sizeof(arr));arr[0][2] = 1; arr[1][2] = 2;int* ptr = (int *)arr;for (size_t i = 0; i < 6; ++i){cout << *(ptr + i) << ",";}return 0;
}
二维数组用于函数形参列表:
// 行指针:
数据类型 (*行指针名)(行大小) = &一维数组名; // 行大小即数组长度;&一维数组名,即数组的地址,也是行地址
int arr[2][3];
int(*p)[3] = arr; // arr是二维数组的首地址,即0号元素的地址 // 将二维数组传递给函数:
void func(int(*p)[3], ...);
void func(int p[][3], ...);
三维数组:
int arr3D[2][3][4];
memset(arr3D, 0, sizeof(arr3D));int (*p)[3][4] = arr3D;
void func(int(*p)[3][4], ...);
指针 type *:
指针变量:
简称指针,是一种特殊的变量,专用于存放变量在内存中的起始地址。
语法:数据类型 *变量。
对指针的赋值:
- 任何数据类型的地址都是以十六进制存储在内存中的
指针变量 = &变量- 不同的指针存放不同类型变量的地址
指针占用的内存:
- 指针也是变量,故需要占用内存
- 64位操作系统中,指针变量占用的都是8 bytes
- 指针存放变量的地址,指针名表示的就是该地址(就像变量名表示变量的值一样)
- *解引用,用于指针可以获取该地址中的值。
使用指针的两个目的:
// 传递地址:
int* p; // 整型指针
int* p[3]; // 一维整型指针数组,元素是3个整型指针p[0]、p[1]、p[2]
int(*p)[3]; // 一维整型数组指针,用于指向数组长度是3的整型数组
int* p(); // 返回值类型是整型的,函数p的地址
int(*p)(int, int); // p是函数指针,函数返回值是整型int// 存放动态分配的内存地址:
int* p = new int(3);
二级指针:
指针用于存放普通变量的地址,二级指针用于存放指针变量的地址。
#include<iostream>
using namespace std;int main()
{int* p = 0;{int** pp = &p;*pp = new int(3);cout << pp << ", " << *pp << endl;}cout << p << ", " << *p << endl;return 0;
}
空指针:
声明指针后,赋值前,指针指向空,即没有任何地址。
对空指针进行解引用,程序会崩溃。
- 函数中,应该有判断形参是否为空指针的代码,目的是保证程序的健壮性。
- 为何访问空指针会出现异常?
- NULL指针分配的分区,范围是0x00000000 ~ 0x0000FFFF,该段是空闲的空间且没有相应的物理存储器与之对应。
- 对该段的空间的任何操作,都会引发异常。
- 需要人为的划分一个空指针区域,即NULL指针分区。
对空指针使用delete运算符,系统会忽略该操作,不会出现异常。内存被释放后,应将该指针指向空。
注意:c++11建议用nullptr表示空指针也就是(void*)0,NULL当作0使用。
野指针:
野指针指向的是非有效的地址,故访问的时候程序可能会崩溃。
出现野指针的情况主要有三种:
- 指针在定义的时候,如果没有初始化,它的值是不确定的(乱指的),故如果指针初始化时,不知道指向哪,就指向nullptr。
- 如果用指针指向了动态分配的内存,内存被释放后,指针不会置空,但指向的地址是无效的,故动态分配的内存被释放后需要将其置空nullptr。
- 指针指向的变量已超越变量的作用域,即变量的内存空间已经被系统回收,故函数不要返回局部变量的地址。
野指针的危害比空指针大,故需要避免,否则会造成程序的不稳定。
函数指针:
函数的二进制代码放在内存分区的代码段,函数的地址是其在内存中的首地址。
使用函数指针步骤:
// 声明函数指针:
int(*funcPtr)(int, int)// 让函数指针指向函数的地址:
int maxValue(int val1, int val2) { return (val1 > val2 ? val1 : val2) };
funcPtr = maxValue;// 通过函数指针调用函数:
int res = funcPtr(5, 1) // 或 (*funcPtr)(5,1);
主要用于:给函数传递函数指针作为参数,并在函数内部使用该函数指针,达到调用该函数的目的。
#include <iostream>
using namespace std;template <typename T>
bool ascending(T x, T y)
{return x > y;
}template <typename T>
bool descending(T x, T y)
{return x < y;
}template<typename T>
void bubblesort(T* a, int n, bool(*cmpfunc)(T, T)=ascending){bool sorted = false;while(!sorted){sorted = true;for (int i=0; i<n-1; i++){if (cmpfunc(a[i], a[i+1])) {std::swap(a[i], a[i+1]);sorted = false;}n--;}
}int main()
{int a[8] = {5,2,5,7,1,-3,99,56};int b[8] = {5,2,5,7,1,-3,99,56};bubblesort<int>(a, 8, ascending);for (auto e:a) { cout << e << " " };cout << endl;bubblesort<int>(b, 8, descending);for (auto e:b) { cout << e << " " };return 0;
}
// -3 1 2 5 5 7 56 99
// 99 56 7 5 5 2 1 -3
引用 type &:
使用指针存在的问题:空指针、野指针、容易改变指针指向的值却在继续使用。
引用是c++新增的复合类型,是指针常量(不允许修改指针的指向)的伪装:“引用int& ra = a <==> 指针常量int* const rb = &a”。
int x1 = 2;
int x2 = 3;// 引用使用时,必须初始化,而且一个引用永远指向它初始化的那个对象
int& x3 = x1;
cout << x1 << "," << x3 << endl;x3 = x2;
cout << x1 << "," << x3 << endl;
- 使用引用,则不存在空引用、必须初始化、一个引用永远指向它初始化的那个对象。
- 引用,可以认为是变量别名,修改引用的值同时也会改变原变量的值。
函数传递参数的说明:
- 对内置基础类型而言,在函数中传递时
pass by value更高效; - 对面向对象中自定义类型而言,在函数传递中
pass by reference to const更高效;
疑问:
- 有了指针,为什么还需要引用?为了支持运算符重载。
- 有了引用,为什么还需要指针?为了兼容c语言。
创建引用的语法:
数据类型& 引用名 = 原变量名:
- 引用名 和 原变量名的数据类型、值、内存单元相同;
- 必须要在声明引用的时候初始化,且初始化后不可改变;
引用用于函数的参数:
#include <iostream>
#include <string>
using namespace std; void funcByValue(int age, string name)
{age = 21;name = "wowo";
}
void funcByQuote(int& age, string& name)
{age = 21;name = "wowo";
}
void funcByAddr(int* age, string* name)
{*age = 21;*name = "wowo";
}int main()
{int age = 10;string name = "yoyo"; cout << age << "," << name << endl;funcByValue(age, name);cout << age << "," << name << endl;funcByQuote(age, name);cout << age << "," << name << endl;funcByAddr(&age, &name);cout << age << "," << name << endl;return 0;
}
-
把函数的形参声明为引用,调用函数时,形参将是实参的别名,该方法称为引用传递。
-
引用的本质是指针常量,传递过程中,传递的是变量的地址,故函数中对形参的修改会影响实参。
-
传值、传地址、传引用相比,引用传递的优点:
1)传引用更简洁,且避免了不必要的值拷贝;
2)引用传递避免了二级指针;
#include <iostream> using namespace std; void funcByQuote(int*& p) {p = new int(3);cout << *p << endl; } void funcByAddr(int** p) {*p = new int(3);cout << **p << endl; }int main() {int* p = nullptr;funcByQuote(p);funcByAddr(&p);return 0; } -
引用传入函数的形参用const修饰:
作用:
-
引用为const时,c++将创建临时变量,并让引用指向临时变量。何时创建临时变量?
1)引用的数据对象类型不匹配:c++会创建正确类型的匿名变量,将实参的值传递给匿名变量,并让形参来引用该变量;
2)引用的数据对象类型匹配,但不是左值;
const int& val = 8; // 等价于 int tmp = 8; const int& val = tmp; -
如果不想函数修改引用传入的实参,可以在形参列表中数据类型前加const修饰;
void funcByQuote(const int& val1, const int& val2);原因:
1)使用const,可以避免函数中无意修改数据而造成的错误;
2)使用const,函数能正确的生成临时变量;
3)使用const,函数就能够处理const和非const实参,否则只能接受非const实参;
-
引用用于函数返回值:
-
如果返回局部变量的引用,本质上是野指针;
-
可以返回函数的引用形参、类的成员、全局变量、静态变量;
#include<iostream> #include<string> using namespace std;struct Stu {string name;int age; };// 返回函数的引用形参 ostream& operator<<(ostream& out, const Stu& stu) {out << stu.name << ":" << stu.age << endl;return out; }int main() {Stu stu{"wowo", 12};cout << stu << endl;return 0; } -
如果不希望返回引用被利用,可在其前面加const;
#include<iostream> using namespace std; int& func1(int& n) {return ++n; } const int& func2(int& n) {return ++n; }int main() {int a = 1;int& b = func1(a);cout << func1(a) << "," << a << "," << b << endl;func1(a) = 10;cout << func2(a) << "," << a << "," << b << endl;const int& b2 = func2(a);// func2(a) = 12; // error: assignment of read-only location ‘func2(a)’cout << func2(a) << "," << a << "," << b << endl;return 0; }
类 class / 结构体 struct:
类/结构体中的每个变量都有自己独立的内存。
类/结构体数据对齐的问题:
- 遵循“缺省对齐”的原则。
- 32位CPU中,char可以占用任何地址、short可以占用偶数地址、int占用4的整数倍的地址、double占用8的整数倍的地址。
类/结构体内存布局:
- 32位CPU是以4字节为一个单位的,故内存布局在默认情况下,一般不是紧密排列的。
- 内存布局“遵循最大数”原则,即类中如果有double属性,则占用的总内存是8的倍数。
- 可以通过
#pragma pack(n)中,通过设置不同的n,来表示内存排列的紧密程度;n=1,表示内存是紧密排列的。
结构体中的全部成员清零:
struct student
{int age;char name[21];
}// void* memset(void* dest, int ch, size_t count),只适用于结构体成员是c++的基本数据类型
student stu1;
memset(&stu, 0, sizeof(student));
student stu2;
memcpy(&stu2, &stu1);
复制结构体:
可以用=或void memcpy(void* dest, void* src)函数。
结构体指针:
struct student
{char name[21];int age;
}student stu;
student* stuPtr = &stu;
(*stuPtr).name;
stuPtr->name;
结构体数组:
struct student
{char name[21];int age;
}student stu[3];stu[0].name;
(stu + i)->name;
(*(stu + i)).name = "ssuu";
结构体中的指针:
#include <iostream>
#include <cstring>
using namespace std;struct PtrStruct
{int a;int* ptr;
};int main()
{PtrStruct ptrStruct;// 会将结构体中的a=0,ptr=nullptrmemset(&ptrStruct, 0, sizeof(PtrStruct)); ptrStruct.ptr = new int[20];// 如果结构体中的指针已经动态分配了内存空间,再用memset清零时,需要逐个字段清零ptrStruct.a = 0; memset(ptrStruct.ptr, 0, 20 * sizeof(int)); return 0;
}
- 结构体中的指针指向的是动态分配的内存地址,对结构体直接用memset()函数可能会造成内存泄露,要逐个字段分情况的进行memset()清零。
- 类(class)只使用构造函数进行初始化,不要调用memset进行清零操作。
- 用memset清零时,会将结构中所有字节置0,如果结构体中有虚函数或结构体成员中有虚函数,则会将虚函数指针置0/置空,后续程序调用虚函数,空指针很可能导致程序崩溃!!!
联合体 union:
#include <iostream>
#include <cstring>
using namespace std; struct widget
{char brand[20];int type;union id{long id_num;char id_char[21];}id_val;
};int main()
{widget prize; cin >> prize.type;if (prize.type == 1) { prize.id_val.id_num = 12;cout << prize.id_val.id_num << endl;} else {strncpy(prize.id_val.id_char, "hello", 6);cout << prize.id_val.id_char << endl;}return 0;
}
- 共用体是一种数据格式,它能存储不同的数据类型,但只能同时存储其中的一种类型,即共用体只能存储int、long或double,而结构体可以同时存储int、long和double。
- 联合体中的数据共享一块内存,且共同体占用内存的大小是它最大的成员占用的内存大小,且要满足内存对齐原则。
- 联合体中的值为最后被赋值的那个成员的值。
匿名共用体:
struct widget
{char brand[20];int type;union // 在定义时,创建匿名联合体变量,也可以嵌套在结构体中// 其成员位于相同地址的变量,故每次只有一个成员是当前的成员{ long id_num;char id_char[20];};
};int main()
{widget prize; if(prize.type == 1)cin >> prize.id_num; elsecin >> prize.id_char;
}
枚举 enum:
enum不仅能够创建符号常量,还能定义新的数据类型。
使用细节:
// 创建枚举类型wt,默认从0开始,还可以任意设置枚举量的值但必须是整数
enum wt{Monday, Tuesday, Wednesday, Thursday, Saturday, Sunday};// 创建枚举变量,并赋初始值
wt weekday = Monday;
weekday = wt(1); // 此时weekday = Tuesday
- 枚举值不可以做左值。
- 枚举变量可以赋值给非枚举变量,非枚举值不可以赋值给枚举变量。
符号常量 #define 或 const:
const常量:声明为常量的变量是只读的。
// 常量指针:不能通过解引用的方法修改内存中的值,但可尝试使用原始的变量修改。
const 数据类型* 变量名;// 指针常量(引用):指向的变量不可改变,但可通过解引用修改变量在内存中的值;定义时必须初始化,否则没有意义。
数据类型* const 变量名;// 常指针常量(常引用):指向的变量不可改变,也不能通过解引用修改变量在内存中的值。
const 数据类型* const 变量名;
常量表达式constexpr:c++11引入,在编译时就会求值,提高了系统的性能。
c++11新增的long long类型:
- VS中,long类型占4 bytes,long long类型占8 bytes。
- linux中,long类型和long long类型,都占用了8 bytes。
自动推导类型:

c++11中,编译器在编译期时,推导auto声明的变量的数据类型,故不会造成程序运行效率的下降。
注意:
- auto声明的变量,必须在定义时初始化;
- 初始化的右值,可以是具体数值,也可以是表达式和函数的返回值;
- auto不能作为函数的形参类型;
- auto不能直接声明数组;
- auto不能定义类的非静态成员变量;
auto的真正用途:
-
代替冗长复杂的变量声明;
-
代替函数指针类型;
#include <iostream> using namespace std;int func(int val1, int val2) {return val1 + val2; } int main() {/*数据类型的别名:typedef 类型名 新的类型名;如typedef unsigned int size_t,为了避免类型名太长,造成代码可读性下降。*/// typedef定义函数类型typedef int(f)(int,int);f* fPtr1 = &func;cout << fPtr1(1,2) << endl;// typedef定义函数指针类型typedef int(*fPtrType)(int,int);fPtrType fPtr2 = func;cout << fPtr2(1, 2) << endl;// 声明函数指针:int(*fPtr3)(int,int);fPtr3 = func; // 定义函数指针;cout << fPtr3(1, 2) << endl;// 通过右值,auto能自动推导出函数指针类型auto fPtr4 = func;cout << fPtr4(1, 2) << endl;return 0; } -
用于lambda表达式;
void关键字:
void表示无类型,主要有如下用途:
-
函数返回值用void,表示函数没有返回值
-
函数形参:
填
void,表示函数不需要参数(或让参数列表是空);填
void*,表示接受任意数据类型的指针;(要将void*类型转换成其他类型,需要显式转换) -
其他类型的指针 -->
void*指针,不需要转换;void*指针 --> 其它类型的指针,需要转换。
零初始化:
- 零初始化值:
int ==> 0、指针 ==> nullptr、bool ==> false。 - 三种零初始化方式:
int a = {}、int a = int()、int a{}。
类型转换:
c的类型转化:
- 隐式类型转换:如double f = 1.0 / 3;
- 显式类型转换:(类型说明符)(表达式);
存在的问题:任何类型之间都能进行转换,且编译器无法判断其正确性
c++的类型转换:
自动/隐式类型转换:
系统自动进行,不需要开发人员介入。
强制类型转换:
强制类型转换名<type> (express)
static_cast(最常用):
静态类型转换:编译的时候就会进行类型转换检查。不会产生动态类型转换的类型安全检查的开销。与c语言中的强制类型转换,差不多。
用途:
-
相关类型转换,比如整型和实型转换;
int i = 5; double d = static_cast<double>(i);double d = 5.0; int i = static_cast<int>(d); -
类中子类与父类之间的转换,且只能是子类转换为父类;
class A {. . . . } class B : public A {. . . . }B b; // 子类能转换为父类 A a = static_cast<A>(b); -
void*与其他类型的指针之间的转换;int a = 10; void* ptr_int = &a; double* ptr_double = static_cast<double*>(ptr_int);-
void*无类型指针可以指向任何指针类型(即万能指针) -
主要用于函数的形参中用
void*,即“实参的类型指针->void*指针->函数中使用的类型指针”// 其他类型指针 -> void* -> 其他类型指针 void func(void* ptr) {double* ptr_double = static_cast<double*>(ptr); }int main() {int a = 10;func(&a); }
-
注意:一般不能用于指针类型之间的转换,比如int *、float *、double *等
int a = 10;
double* ptr_double = static_cast<double*>(&a);
// 会报错,static_cast不支持不同类型指针之间的转换
reinterpret_cast:
重新解释,将操作数的内容解释为另一种不同的类型(可以处理无关类型的转换),且编译时就会进行类型转换检查。
- 不检查指向的内容,也不检查指针类型本身。
- 但要求转换前后的类型所占用的内存大小一致,否则会引发编译时错误。
- <目标类型>和(表达式)中必须有一个似乎指针/引用类型。
- 不能丢掉(表达式)中的const和volitale属性。
常用与两种转换:
void func(void* ptr)
{long long i = reinterpret_cast<long long>(ptr);cout << i << endl;
}int main()
{long long i = 10;// 要求转换前后,类型占用的字节数一致。这里,long long占用8字节、指针也占用8直接func(reinterpret_cast<void*>(i));
}
- 将指针/引用转换成整型变量。
- 将整型变量转换成指针/引用。
- 改变指针/引用类型,不需要像
static_cast要借助void*。
dynamic_cast:
- 动态转换,主要用于运行时,类型识别和检查。
- 只能用于含有虚函数的类,必须用在多态体系中,用于类层次间的向上和向下转换(向下转换时,如果是非法的指针则返回NULL)。
- 主要用于父类和子类之间的转换(父类指针指向子类对象,通过dynamic_cast把父类指针转换为子类指针)。
const_cast:
#include <iostream>
#include <string>
#include <cstring>
using namespace std;int main()
{string str1(5, ' ');string str2 = "123";strncpy(const_cast<char*>(str1.data()), str2.c_str(), str2.size()); cout << str1 << ",";return 0;
}
只能去除指针 或者 引用的const属性。
const int a1 = 1;
// int a2 = const_cast<int>(a1); // 报错,a1不是指针或者引用const int* a2 = &a;
int* a4 = (int*)(a2); // C风格的强制转换
int* a3 = const_cast<int*>(a2); // c++风格的强制转换
总结:
- c++推出的类型转换替换c风格的类型转换,采用更严格的语法检查,降低使用风险。
- 一般
static_cast和reinterpret_cast,能够很好的取代C语言风格的类型转换。
静态变量:
-
静态变量的存储方式和生命周期:属于静态存储方式,其存储空间为内存中的静态数据区;该区域的数据在整个程序的运行期间不会释放,所以其生命周期为整个程序运行时间段。
-
静态局部变量:定义在函数体内的变量。
1)当对静态局部变量进行初始化时,只初始化一次,且必须是常量或常量表达式;
2)局部静态变量,编译阶段不分配内存;只有在执行并且调用其所在的函数时,才会分配内存;
-
全局变量与静态全局变量:两者的区别是作用域不同。
1)非静态全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,非静态的全局变量在所有源文件中都是有效的;
2)静态全局变量只在定义该变量的源文件内有效,可以增加安全性和避免不同源文件同变量名冲突问题。
静态、动态分配内存:
动态内存分配:
运行期间分配,程序结束前,必须释放内存分配的空间,否则会造成内存泄露。
程序执行较慢,因内存在程序执行时,才进行分配(一般分配的是连续的内存空间)。
指向动态分配的内存空间的指针,在使用完成后需要程序员释放掉,否则会造成内存泄漏。
动态内存分配的注意事项:
堆、栈的不同用途和区别:
- 栈:空间有限,编译器自动分配,速度较快。
- 堆:只要不超过实际的物理内存,而且在操作系统能分配的最大内存大小内都可以分配;分配速度慢;通过
malloc/free、new/delete来实现。
实现:
C语言:
通过malloc/free从堆区申请和释放内存,malloc(memory allocation)动态内存分配。
void* malloc(int NumBytes) // NumBytes:是要分配的字节数
// 分配成功,返回指向被分配内存的指针;分配失败,返回NULL
当不使用这段内存时,要用void free(*FirstBytes)函数,将这段内存释放并被系统回收,需要时重新分配。
char* ptr = (char*)malloc(13 * sizeof(char)); // 在堆中分配四个字节if (otr != nullptr)
{strcpy_s(ptr, 13, "hello world!");cout << ptr << endl;// 释放内存ptr = nullptr;free(ptr);
}
给申请的100个整型内存空间赋值:
// 给申请的100个整型内存空间赋值0-100
// 分配400个字节
int* ptr = (int*)malloc(100 * sizeof(int));
if (ptr != nullptr)
{// 通过指针ptr1,给指向ptr的内存空间赋值int* ptr1 = ptr;for (int i = 0; i < 100; i++){*ptr1++ = int(i); // 等价于*(ptr1 + i) = i;}// 输出申请的100个整型内存空间的值if (ptr1 != nullptr){for (int i = 0; i < 100; i++){cout << *(ptr + i) << " "; }cout << endl;}// 释放申请的内存 free(ptr); ptr = nullptr;
}
c++语言:
用new/delete(运算符(标识符))分配和释放在堆区的内存。
// new使用的一般格式:
// 1. 申请一个堆区的内存:
指针变量名 = new 类型标识符;
指针变量名 = new 类型标识符(初始值);
// 2. 申请一些连续的堆区的内存:
指针类型名 = new 类型标识符[内存单元的个数];
new:动态的分配内存,然后调用对应的构造函数(递归调用各个成员变量的构造函数)(编译器自动进行)。new类对象时,加不加括号的差别:
A* a1 = new A(); // 加圆括号
A* a2 = new A; // 不加圆括号
- 如果new一个空类,则两种方式并无区别。
- 如果类中含有成员变量,则带括号的初始化会将一些成员变量相关的内存清零,但并非所有内存空间全部清零(虚函数表指针不能清零)。
- 当类中有构造函数时,带/不带圆括号完全相同。
delete:调用对应的析构函数(编译器自动进行),然后释放内存。

注意:两者void* operator new(size_t size)、void* operator new[](size_t size),内部函数体相同,只是编译器推导出的size(字节数)不同。
nullptr:
c++11引入的新关键字nullptr,代表空指针;NULL:也代表空指针,实际上是整型数0。
- 引入nullptr,能够避免整数和指针之间发生混淆。
- NULL和nullptr实际上是不同的类型,之后涉及指针时就用nullptr。
动态分配内存的布局:
除了需要的内存外,为了管理动态分配的内存故还需要一些额外信息(频繁的动态分配会造成资源的极大浪费,特别是申请小块内存时)。

malloc与free的实现原理:
-
malloc底层是brk、mmap系统调用实现的,free底层是unmap系统调用实现的。 -
malloc小于128k的内存,使用brk分配内存(将数据段(.data)的最高地址指针
_edata往高地址推);malloc大于128k的内存,使用mmap分配内存,在堆和栈之间(称为文件映射区域的地方),找一块空闲内存分配;
这两种方式分配的都是虚拟内存,没有分配物理内存。当第一次访问已分配的虚拟地址空间时,会发生缺页中断,操作系统负责分配物理内存,并建立虚拟内存和物理内存间的映射关系。
-
操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表并寻找第一个空间大于所申请空间的堆结点,将该结点从空闲结点链表中删除并分配给程序。
被free回收的内存是立即返归还操作系统吗?
不是的,被free回收的内存会首先被ptmalloc使用双链表保存起来,当用户下一次申请内存的时候,会尝试从这些内存中寻找合适的返回。这样就避免了频繁的系统调用,占用过多的系统资源。
同时ptmalloc也会尝试对小块内存进行合并,避免过多的内存碎片。
静态内存分配:
- 编译阶段分配,并在程序结束时自动归还给系统。
- 较快,因程序在编译阶段即已决定内存所需要的容量,但这容易造成内存的浪费。
内存泄露的问题:
一般程序中已动态分配的堆内存,由于某种原因程序未能及时释放或者无法释放,造成系统资源的浪费,导致程序运行速度减慢甚至系统崩溃。
内存泄漏在服务器上尤为明显,因服务器上的程序一旦运行不能随意中断,故不断泄露内存会使系统资源被极大的占用和浪费,导致出现程序运行速度减慢或者崩溃的问题。
数据的输入输出控制:
使用控制字符:
#include <iostream> cout << setprecision(3) << ... // 保留三位有效数字
cout << fixed << setprecision(3) << ... // 保留小数点后三位有效数字
cout << scientific << setprecision(3) << ... // 小数点后三位有效数字的科学计数
cout << setfill('%') << setw(5) << num1 << nnum2 << endl;
cout的输出顺序(自左向右),计算顺序(自右向左):
-
cout作为输出流,先将数据从右向左读入缓冲区,再从缓冲区读写到屏幕(类似堆栈)。
-
cout本质上是类ostream的一个对象。
备注 一般形式: void *malloc(int NumBytes) // NumBytes:是要分配的字节数 // 分配成功,返回指向被分配内存的指针;分配失败,返回NULL #include<iostream> #include<cstdio>// 宏定义namespace x {}: #define BEGINS(x) namespace x { #define ENDS(x) } // 命名空间SelfCout: BEGINS(SelfCout)class ostream { public:// 返回值为ostream&,可使“<<运算符”连续使用ostream& operator<<(int x);ostream& operator<<(const char *x); };ostream& ostream::operator<<(int x) {printf("%d", x);return *this; }ostream& ostream::operator<<(const char *x) {printf("%s", x);return *this; } ostream cout; // cout是类ostream的一个对象ENDS(SelfCout)int main() {int n = 123, m = 456;std::cout << n << " " << m; std::cout << std::endl;SelfCout::cout << n << " " << m; std::cout << std::endl;return 0; }
c++的关键字:

c++的运算符:

按运算性质:算数运算符、自增自减、赋值运算符(/=、%=)、关系运算符、逻辑运算符(&&、||、!)、位运算符(右移操作比较复杂(逻辑右移、算数右移:左边空缺位的填充不同)、左移操作(直接给右边的空缺位补0))、杂项运算符。
按运算对象:单目运算符(一个运算对象)、双目运算符(两个类型相同的运算对象)、三目运算符(条件运算符 condition ? X : Y)。
其他运算符:
- 字节数运算符
sizeof,返回变量的大小; - 指针运算符
&var,返回变量的地址; - 指针运算符
*var,返回变量var;
结构体、类:
结构变量、对象:一块能够存储数据,且具有某种类型的内存空间。
- c中,定义一个属于该结构的变量,称为结构变量。
- c++中,定义一个属于该类的变量,称为对象。
c++中,结构体和类具有相似性,区别主要有两点:
- 内部的成员变量、成员函数,默认的访问权限不同:结构体 – public、类 – private。
- 继承,默认的权限不同:结构体 – public、类 – private。
结构体:
// 使用结构体作为函数的形参
struct Student
{int num;char name;
} student;void func1(Student tempStu) // 结构体作为函数的形参
{tempStu.num = 20;strcpy_s(tempStu.name, sizeof(tempStu.name), "lisi");
}
// 效率低,因为在实参传递给形参时,发生了内存内容的拷贝操作
func1(student);void func2(Student& tempStu) // 函数的形参变为结构体引用
{tempStu.num = 20;strcpy_s(tempStu.name, sizeof(tempStu.name), "lisi");
}
func2(student);void func3(Student* tempStu) // 指向结构体的指针做函数参数
{tempStu->num = 20;strcpy_s(tempStu->name, sizeof(tempStu->name), "lisi");
}
func3(&student);
静态对象与全局对象的构造顺序:
函数/类中的静态对象:
-
多次调用函数,静态对象只会创建一次,即一个函数的静态局部变量在函数被多次调用时只初始化一次。
#include <iostream> using namespace std;void func() {static int a = 1; // 多次调用函数,静态对象只会创建一次++a;cout << a << " "; }int main() {func(); func(); func(); // 2 3 4return 0; } -
类中的静态对象只有声明且定义后,才能被调用。
全局对象的构造顺序:
- 如果项目中,有多个.cpp文件且每个源文件中都定义了不同的全局对象,则这些全局对象的构造顺序是无规律的;
- 不能在构造某个全局对象时,直接使用另一个全局对象(无法确定该对象是否在使用前被构造);
临时对象:
产生临时对象的情况和解决:
-
以传值的方式给函数传递参数;
-
类型转换生成的临时对象;
类名 obj; obj = 100; // 这里产生了一个真正的临时变量,后干了三件事: // 1)用100创建一个该类的临时对象 // 2)调用拷贝赋值运算符把这个临时对象里的各个成员赋值给obj对象 // 3)调用析构函数,销毁创建的临时对象// 把定义对象和给对象赋值放在同一行: // 这就为obj对象预留了空间,避免了使用临时对象 类名 obj =100; -
隐式类型转换以保证函数调用成功;
-
函数返回局部对象时;
注意:c++中,只会为const引用(const string& str)产生临时对象;不会为非const引用(string& str)产生临时对象。
深、浅拷贝的问题:
浅拷贝:只拷贝指针地址

- c++默认为每个类生成的“拷贝构造函数”与“重载的赋值运算符”,都是浅拷贝。
- 优点:节省空间;缺点:容易引发多次释放、内存泄漏的问题。
深拷贝:重新分配内存,拷贝指针指向的内容
- 缺点:浪费空间;优点:不会导致多次释放;
#include <iostream>
#include <cstring>
using namespace std;class Stu
{
public:int age;string name; char* phone; // 使用堆区开辟的内存空间
public:Stu() : age(0), name(""), phone(nullptr){cout << "default constructor" << endl;}Stu(int m_age, string m_name, char* m_phone) : age(m_age), name(m_name){this->phone = new char[sizeof(m_phone)];memcpy(this->phone, m_phone, sizeof(m_phone));cout << "with the constructor" << endl;}Stu(const Stu& stu){this->age = stu.age;this->name = stu.name;/*// 此时,会存在“浅拷贝”的问题,如果Stu stu3(stu2)中stu2先释放,stu3.phone的使用就会崩溃this->phone = stu.phone; */// 深拷贝:this->phone = new char[sizeof(stu.phone)];memcpy(this->phone, stu.phone, sizeof(stu.phone));cout << "copy constructor" << endl;}~Stu(){delete[] this->phone;this->phone = nullptr;cout << "destructor" << endl;} friend ostream& operator<<(ostream& out, const Stu& stu);
};ostream& operator<<(ostream& out, const Stu& stu)
{out << stu.age << "," << stu.name << "," << stu.phone << endl;return out;
}int main()
{Stu stu1;Stu* stu2 = new Stu(12, "wowo", (char*)"121212");Stu stu3(*stu2);delete stu2; // 如果Stu类的拷贝函数中存在“浅拷贝”的问题,则stu2先释放,stu3.phone的使用就会崩溃cout << stu3 << endl;return 0;
}
如何兼顾两者的优点:
-
引用计数:会带来额外的内存开销;
-
c++新标准中,
std::move()移动语义;const int len = 100;class String { public:// 普通构造函数String(const char* str = NULL){if (str == NULL){this->data = new char[1]this->data = '\0';}else {int len = strlen(str.data);// 字符串结束符'\0'占一字节this->data = new char[len + 1]; strcpy(this->data, str);}}// 拷贝构造函数String(const String& str){int len = strlen(str.data);// 字符串结束符'\0'占一字节this->data = new char[len + 1]; if (this->data != NULL){strcpy(this->data, str);}else {exit(-1);}}// 赋值运算符String& operator=(const String& str){if (this->data != &str){delete[] this->data;this->data = new char[strlen(str.data)+1];if (!this->data){strcpy(this->data, str.data);}}return *this;}// 移动构造函数String(String&& str){if (str.data != NULL){// 资源的让渡this->data = str.data;str.data = NULL;}}// 移动赋值运算符String& operator=(String&& str){if (this->data != NULL){delete[] this->data;// 资源的让渡this->data = str.data;str.data = NULL;}return *this;}virtual ~String(){if (this->data != NULL){delete[] this->data;this->data = nullptr;}} public:char* data; }int main() {String str1("hello");String str2(std::move(str1));String str3 = std::move(str2); }左值/右值、左值引用/右值引用、万能引用、move、移动语义、完美转发:
template<class T> void swap(T& a, T& b) { // 以下三个语句在执行时,都会发生拷贝动作const T tmp = a;a = b;b = tmp; }template<class T> void swap(T& a, T& b) { // "perfect swap"T tmp = std::move(a);a = std::move(b);b = std::move(tmp); }左值、右值 :
左、右值区别:
- 左值代表一个地址;右值代表一个值;(c++中,一个表达式只能是左值或者右值之一)
- 左值是可以被引用的数据,可以通过地址访问,如变量、数组元素、结构体成员、引用和解引用的指针;
- 左值,可以同时具有左值和右值属性;如 i = i + 1;
- 右值:非左值,包括字面常量(用双引用包含的字符串除外,它是有地址的)和包含多项的表达式;
class A;int i = 3; // i是左值,3是右值 i = i + 3; // 左边的i是左值,右边的i+3是右值A func() {return a; } A a1 = func1(); // a1是左值,func1()返回的返回值类型是A故为右值A& func2(A& a) {return a; } A a2 = func2(); // a2是左值,func2()返回的返回值类型是A&故为左值/* 总的来说: 1. 右值无法取地址,而左值可以; 2. 左值有名字,而右值没有; 3. 表达式结束后,左值仍然存在,右值就不再存在; */c++11中扩展了右值的概念,分为:纯右值、将亡值
纯右值:
- 非引用返回的临时变量;
- 运算表达式产生的结果;
- 字面常量(c语言风格的字符串,是有地址的);
将亡值:与右值引用相关的表达式
- 将要被移动的对象;
- T&&函数的返回值;
- std::move()函数的返回值;
- 转换成T&&类型的转换函数的返回值;
使用左值的运算符:
- 赋值运算符=:整个赋值语句的结果仍然是左值;
- 取址符&;
- string、vector容器:
- 通过判断运算符能够对数字进行直接操作,进而可以判断是否是左值(不能直接对数字进行操作,则该运算符要用左值);
- 下标[ ]就是一个左值;
- 迭代器iter也是左值,即
vector<int>::iterator iter;
不是左值就是右值:
临时变量被当作右值。
引用类型:c++98中均为左值引用,c++11开始出现右值引用:
左值引用lvalue reference(绑定到左值),即给左值起别名:
int val1 = 3; // 左值引用: int& val2 = val1;-
没有空引用的说法:左值引用初始化时,必须绑定到左值;
-
引用左值时,必须绑定到左值上(不能绑定到右值(数字)上);
-
常量左值引用,是一个万能的引用,可以绑定非常/常量左值、右值,缺点:只读不能修改;
int b = 10; const int c = 10;const int& rb = b; // 常量左值引用,绑定非常量左值 const int& rc = c; // 常量左值引用,绑定常量左值const int& rval = 10; // 常量左值引用,绑定右值
右值引用rvalue reference(绑定到右值),即给右值起别名:
// 右值引用: const int&& val = 4; // 系统利用的是临时变量temp // int tempVal = 4; // const int& val = tempVal;int&& val2 = val + 3; // val+3是右值 /* 右值有了名字,就变成了左值 */-
&&,系统希望用右值引用来绑定一些即将被销毁或者临时的对象上。
class A;// 函数的返回值是右值(临时变量) A getTmp() {return A(); }int main() {// 右值引用函数返回的临时变量A&& a = getTmp();// 这样在构造a的过程中,只调用了默认/有参构造函数,而没有调用拷贝构造函数,效率更高 } -
右值引用的目的:c++11引入右值引用代表一种新的数据类型,来提高系统效率(把拷贝对象变成移动对象)。&&,常被用于移动语义中,即移动构造函数和移动赋值运算符的形参列表中。
总结:
- 左值引用,使用
T&,只能绑定左值; - 右值引用,使用
T&&,只能绑定右值; - 已命名的右值引用,是左值;
- 常量左值
const T&,既可以绑定左值又可以绑定右值;
move函数(c++11标准库中的新函数):
作用:将一个左值强制转换为右值。
int val1 = 3; int && val2 = std::move(val1); // val2相当于val1的引用string str1 = "I love China!"; string str2 = std::move(str1); // 调用string中的移动赋值运算符,将str1中的内容移动到str2中去了本质:将对象的状态/所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁/内存拷贝,所以可以提高利用效率、改善性能。
#include <iostream> #include <vector> #include <string> using namespace std; int main() {string str = "Hello";vector<string> vctor;// 调用常规的拷贝构造函数,新建字符数组,拷贝数据vctor.push_back(str);cout << str << endl;// 调用移动构造函数,掏空str(掏空后尽量不要再使用str);该过程中,没有发生内存的拷贝和释放,只是所有权发生了变化vctor.push_back(std::move(str));cout << str << "\t" << v[0] << "\t" << v[1] << endl; }万能引用T&&(存在的前提为模板参数类型)、const T&:
-
如果模板(类模板、函数模板)中,参数为T&&,那么既可以接受左值引用又可以接受右值引用。
#include <iostream> using namespace std; template<typename T> void funcLRVal_(T&& val) // T&&作为参数类型,既可以接受左值,又可以接受右值 {... }int main() {int a = 10; funcLRVal(a);funcLRVal(10); return 0; }-
加
const修饰后,即const T&&,就只能接受右值引用。#include <iostream> using namespace std; template<typename T> void test(const T&& val) {cout << "void test(const T& val)" << endl; }int main() {int a = 10; test(10);// test(a); // 报错return 0; } -
int&&、vector<T>&&,“具体类型”或“非T&&”,则均不是万能引用。 -
类模板的成员函数,在类实例化后,成员函数的参数类型已确定,即并不再是模板参数,故不会是万能引用(除非成员函数是函数模板,且参数类型为T&&)。
-
-
const T&,既能接受左值引用,又能接受右值引用。
#include <iostream> using namespace std; template<typename T> void test(const T& val) {cout << "void test(const T& val)" << endl; }int main() {int a = 10; test(10);test(a);return 0; }缺点:函数体内不能对参数进行修改。
移动语义:
#include <iostream> #include <cstring> using namespace std;class A { public:int* m_data = nullptr; // 指向堆区资源的指针,类内初始化A() = default; // 启用默认的构造函数void alloc(){m_data = new int; // 分配堆区内存memset(m_data, 0, sizeof(int)); // 将分配的内存初始化为0}A(const A& a) // 拷贝构造函数{cout << "A(cosnt A& a)" << endl;if (m_data == nullptr) { alloc(); }memcpy(m_data, a.m_data, sizeof(int));}A& operator=(const A& a) // 拷贝赋值函数{cout << "A& operator=(const A& a)" << endl;if (this == &a) { return *this; } // 避免"自我赋值"if (m_data == nullptr) { alloc(); }memcpy(m_data, a.m_data, sizeof(int));return *this;}~A(){delete m_data;cout << "~A()" << endl;}A(A&& a) // 移动构造函数,形参不能用const修饰,因最后要将a.m_data置空{cout << "A(const A&& a)" << endl;if (m_data != nullptr) // 如果已分配内存,则先释放掉{ delete m_data; }m_data = a.m_data; // 将源对象中的指针指向的内存地址,赋值给新对象中的指针a.m_data = nullptr; // 将源对象中的指针置空} A& operator=(A&& a) {cout << "A&& A(A&& a)" << endl;if (this == &a) // 避免“自我赋值”{ return *this;}if (m_data != nullptr) // 如果已分配内存,则先释放掉{ delete m_data; }m_data = a.m_data; // 将源对象中的指针指向的内存地址,赋值给新对象中的指针a.m_data = nullptr; // 将源对象中的指针置空return *this; }};int main() {A a1;a1.alloc();*(a1.m_data) = 3;cout << *(a1.m_data) << endl;A a2 = a1; // 调用拷贝构造函数cout << *(a2.m_data) << endl;A a3;a3 = a2; // 调用拷贝赋值函数cout << *(a3.m_data) << endl;cout << ".............." << endl;A a4(std::move(a1)); // 调用移动构造函数A a5 = std::move(a2); // 调用移动构造函数A a6; a6 = std::move(a3); // 调用移动赋值函数return 0; }-
如果一个函数中有堆区资源,则需要编写拷贝构造函数和赋值函数,实现深拷贝。
-
移动语义,通过直接使用源对象拥有的资源,可以节省资源申请和释放的时间。
c++中所有容器,都实现了移动语义,避免对含有(堆区)资源的对象发生不必要的拷贝。
-
移动语义对于拥有资源(如堆区内存、文件句柄)的对象有效,如果是基本类型,使用移动语义没有意义。
-
实现移动语义要增加两个成员函数:移动构造函数
类名(类名&& 源对象)和移动赋值函数类名& operator=(类名&& 源对象)。注意:形参不能用
const修饰,因函数体内要源对象指向的内存进行置空。 -
c++提供
std::move()方法将左值转义为右值,从而能方便使用移动语义。左值对象被转移资源后,不会立刻析构,只能在离开自己作用域的时候才能析构,如果继续使用左值中的资源,可能会发生意想不到的错误。
完美转发:
-
函数模板中,可以将参数 “完美转发” 给其内部调用的其它函数。
“完美” 指的是:①准确地转发参数的值,②保证被转发参数的左、右值属性不变
完美转发与否,影响参数在传递过程中,采用拷贝语义还是移动语义。
-
为实现完美转发,c++11提供的方案:
#include <iostream> #include <cstring> using namespace std;void func(int&& val) {cout << "params are right value" << endl; }void func(int& val) {cout << "params are left value" << endl; }template<typename T> void funcLRVal(T&& val) // T&&作为参数类型,既可以接受左值,又可以接受右值 {func(val); }// 完美转发: template<typename T> void funcLVal(T& val) {func(val); } template<typename T> void funcRVal(T&& val) {func(std::move(val)); } template<typename T> void funcLRVal_(T&& val) // T&&作为参数类型,既可以接受左值,又可以接受右值 {func(std::forward<T>(val)); // 将左值转发后仍是左值引用,右值转发后仍是右值引用 }int main() {int a = 10;// 在模板函数中,模板函数的参数转发给func()函数后,都变成了左值funcLRVal(10);funcLRVal(a);cout << endl;/* 实现完美转发的两种方案: */// 1、通过两个模板函数,分别实现右值和左值的转发funcLVal(a);funcRVal(10);// 2、采用forward<T>转换funcLRVal_(a); funcLRVal_(10); return 0; }1)如果模板(类模板、函数模板)参数写为万能引用
T&&,那么既可以接受左值引用又可以接受右值引用。#include <iostream> using namespace std; template<typename T> void funcLRVal_(T&& val) // T&&作为参数类型,既可以接受左值,又可以接受右值 {... }int main() {int a = 10; funcLRVal(a);funcLRVal(10); return 0; }2)提供了模板函数
std::forward<T>(参数),用于转发参数,template<typename T> void funcLRVal_(T&& val) // T&&作为参数类型,既可以接受左值,又可以接受右值 {func(std::forward<T>(val)); // 将左值转发后仍是左值引用,右值转发后仍是右值引用 }- 如果参数是一个右值,转发后仍是右值引用;
- 如果参数是一个左值,转发后仍是左值引用;
-
forward<T>通过T来决定,来推断并转发的。#include <iostream> using namespace std;void Print(int& val) {cout << "Print(int& val)" << endl; }void Print(int&& val) {cout << "Print(int&& val)" << endl; }template <typename T> void func(T&& tmp) {Print(std::forward<T>(tmp)); }int main() {func(10); // T :int、tmp :int&&// 等价于:Print(std::forward<int>(10));int i = 10;func(i); // T :int&、tmp :int& // 等价于:Print(std::forward<int&>(i));return 0; } -
普通函数,实现完美转发。
#include <iostream> using namespace std;void func(int& val) { cout << "void func(int& val)" << endl; } void func(int&& val) { cout << "void func(int&& val)" << endl; }void funcLR(auto&& tmpVal) {func(std::forward<decltype(tmpVal)>(tmpVal)); }int main() {int i = 10;funcLR(i);funcLR(std::move(i));return 0; } -
构造函数模板中,使用完美转发,以及对拷贝/移动赋值的影响。
#include <iostream> #include <string> using namespace std;class Human { public:/* Human的构造函数: *//*// 初始化列表中,会调用string(const string& str)的拷贝构造函数Human(const string& name) : _name(name) { cout << "Human(const string& name)" << endl;}// 右值传入后,name会变成左值;std::move()只会将左值转换为右值;// 初始化列表中,会调用string(string&& str)的移动构造函数Human(string&& name) : _name(std::move(name)) {cout << "Human(string&& name)" << endl;}*/// 构造函数的完美转发:// 法一://Human(auto&& name) : _name(std::forward<decltype(name)>(name))//{// cout << "Human(auto&& name)" << endl;//}// 法二:template<typename T>Human(T&& name) : _name(std::forward<T>(name)){cout << "template<typename T> Human(T&& name)" << endl;}/* Human的拷贝构造函数: */Human(const Human& human) : _name(human._name){cout << "Human(const Human& human)" << endl; }/* Human的移动构造函数: */Human(Human&& human) : _name(std::move(human._name)){cout << "Human(Human&& human)" << endl; }private:string _name; };int main() {/* 构造函数: */Human human1(string("hi"));string name = "hi";Human human2(name);/* 拷贝构造函数: *///Error:受到构造函数中的函数模板的影响,不能正常地调用到拷贝构造函数//Human human3(human2);//解决方案:通过std::enable_if解决const Human human4(string("hi"));// 因human4 : const Human类型,故能正常地调用到拷贝构造函数Human human5(human4);/* 移动构造函数: */// 不受到构造函数中的函数模板的影响,能正常地调用到移动构造函数Human human6(string("hi"));Human human7(std::move(human6));return 0; } // std::move()实现的移动构造,不受影响,可正常调用。 // 只有const Human类型,才能正常地调用到拷贝构造函数;不加const,则会因构造函数模板的存在使程序报错。 -
可变参数模板中,使用完美转发。
#include <iostream> using namespace std;int func(int val1, int& val2) {++val2;return val1 + val2; }template <typename F, typename... T> //auto Func(F f, T&&... t) -> decltype(f(std::forward<T>(t)...)) // 存在丢失引用的可能 decltype(auto) Func(F f, T&&... t) // 解决上面提到的“引用丢失”的问题 {return f(std::forward<T>(t)...); }int main() {int j = 10;cout << Func(func, 20, j) << endl;cout << j << endl;return 0; }1)支持任意数量、参数类型的完美转发;
2)可变参数模板,需要返回值时,可使用
decltype(auto)作为返回值类型;
函数新特性、函数重载、inline内联函数、函数中const的使用、递归函数:
函数新特性:
-
函数定义中,形参如果在函数体中没有使用到,则可以不给形参变量名字,只给其类型。
-
函数声明中,可以只有形参类型,没有形参名。
-
函数定义:前置返回类型、后置返回类型。
// 前置返回类型 返回类型 函数名(形参) {. . . . }// 后置返回类型 auto 函数名(形参) -> 返回类型 {. . . . }
函数的使用细节:
-
函数调用时,visual studio会从参数列表右边开始读变量的值,故函数定义时形参有默认值必须放在形参列表最后。
-
函数传参时(如
f(int x)、f(int& x)、f(int* x)、f(int x[])、f(int&& x)),传值、传地址、传引用的原则:- 不需要在函数中修改实参:
1)如果实参很小,比如内置数据类型、小型结构体,则可按值传递;
2)如果实参是数组,则使用 const指针,没有为数组建引用的说法;
3)如果实参是较大的结构体,则使用 “const指针 或 const引用”;
4)如果参数是类,则使用 const引用,传递类的标准方式就是 const引用;
- 需要在函数中修改实参:
1)如果实参是内置数据类型,则使用指针,即
func(&a)的调用表示要在函数中修改a的值;2)如果实参是数组,只能用指针;
3)如果实参是结构体/类,则使用指针/引用;
-
函数返回指针和引用
int* func() {int tempVal = 4;return &tempVal; }int& func() {int tempVal = 15;return tempVal; }1)c++中,更习惯引用类型的形参,来取代指针类型的形参(防止值拷贝,引起的效率降低)。
2)c++中,允许函数同名,但形参列表的参数类型或数量应该有明显的区别,即函数重载(函数名字相同、但参数个数/参数类型不同)。
-
函数在反汇编后,每次调用函数都需要进行入栈和出栈的操作,故效率较低;处理传参/返回值/栈帧的产生和销毁,会带来一定的开销;
如果函数体较小,为了避免频繁的入栈和出栈,可以将调用函数 --> 直接嵌入一段代码,从而节省计算开销。
1)c语言:采用宏定义一个函数:
define Multi(x) (x)*(x-1)。由于x可能是一个表达式,故需要加(),避免出现错误。2)c++采用
inline/constexpr关键字修饰函数:// 1、可以使用内联函数(函数定义前加关键字inline),“编译阶段”直接将代码内嵌,但编译器只是作为参考 // 特点: // 1)如果函数是内联函数,则在编译时,编译器会把该函数的代码副本,放置在每个调用该函数的地方,即采用空间换时间的方式。 // 2)体积小,频繁调用的函数,可通过引入内联函数inline,提高程序性能。 inline 前置返回类型 函数名(形参) {. . . . } // 注意:内联函数的定义要放在头文件:这样在用到该内联函数的.cpp文件时,都能够通过#include头文件,找到这个内联函数的函数本体,并尝试将该函数的调用改为函数本体调用。 // 优缺点:存在代码膨胀的问题,故内联函数体必须小(循环、递归、分支,尽量不要出现在函数体中)。// 2、c++11引入的关键字constexpr(该关键字修饰的函数,可以看作更严格的内联函数),保证函数或对象的构造函数是编译时常量。 constexpr int get_five() {return 5;} int some_value[get_five() + 7]; // Create an array of 12 integers. Valid C++11 /*c++11,constexpr函数必须满足下述限制:1)函数返回值不能是void类型;2)函数体不能声明变量或定义新的类型;3)函数体只能包含编译期语句:声明、null语句或者一段return语句,不能是运行期语句;5)在形参实参结合后,return语句中的表达式为常量表达式;在编译时若能求出其值,则会把函数调用替换成结果值,故相比宏来说没有额外的开销。所有被声明为constexpr的非静态成员函数也隐含声明为const(即函数不能修改*this的值,即this是常量指针)。c++14放松了这些限制,声明为constexpr的函数可以含有以下内容:1)任何声明,除了:static/thread_local变量、没有初始化的变量声明;2)条件分支语句if和switch;3)所有的循环语句,包括基于范围的for循环;4)表达式可以改变一个对象的值,只需该对象的生命期在声明为constexpr的函数内部开始。包括对有constexpr声明的任何非const非静态成员函数的调用。 */#include<iostream> using namespace std;// C++98/03 template <int N> struct Factorial_Cpp03 {const static int value = N * Factorial_Cpp03<N - 1>::value; }; // 递归的基准点 template <> struct Factorial_Cpp03<0> {const static int value = 1; };// C++11 constexpr int factorial_Cpp11(int n) {return n == 0 ? 1 : n * factorial_Cpp11(n - 1); }// C++14 constexpr int factorial_Cpp14(int n) {int result = 1;for (int i = 1; i <= n; ++i){result *= i;}return result; }int main() {static_assert(Factorial_Cpp03<3>::value == 6, "error");cout << Factorial_Cpp03<3>::value << endl;static_assert(factorial_Cpp11(3) == 6, "error");cout << factorial_Cpp11(3) << endl;static_assert(factorial_Cpp14(3) == 6, "error");cout << factorial_Cpp14(3) << endl;return 0; }/*const 和 constexpr 变量间的主要区别:1)const 变量的初始化可以延迟到运行时,而 constexpr 变量必须在编译时进行初始化;2)所有 constexpr 变量均为常量,因此必须使用常量表达式初始化。 */
函数重载:
-
函数重载是指设计一系列同名不同参的函数,让他们完成相同/相似的工作。
实际中,可以重载功能相同但参数类型不同的函数,但不要重载功能不同的函数,会降低代码的可读性。
-
c++允许同名函数,但条件是:形参个数、数据类型、排列顺序要不同,但const、返回值,不作为函数重载的特征。
-
注意:
1)重载函数时,如果数据类型不匹配,c++会尝试进行类型转换并与形参进行匹配,若转换后有多个函数能匹配上则会报错;
2)引用可作为函数重载的条件;
void func(string str, int i); void func(string& str, int i);// 调用void func(string& str, int i); func(a, 10);// 调用void func(string str, int i); func("wowo", 10);3)c++名称修饰:编译时,会对每个函数名进行加密,替换成不同名的函数;
const用法:
-
函数形参中带 const:
-
c++更习惯引用类型的形参,来取代指针类型形参(防止值拷贝,引起的效率降低);但这可能导致修改形参值,使得实参值也被无意修改,形参中加入 const 可避免无意中对形参的修改导致实参被更改的问题。
struct Student {int num;char name; } void func(const Student &tempStu) {... }Student student; func(student); -
加入const,可以使实参类型更灵活,既可以接受普通的数据类型,也可以接受常量的数据类型(包括常数)。
// 使用结构体作为函数的形参 struct Student {int num;char name; } void func(const Student &tempStu) {tempStu.num = 20;strcpy_s(tempStu.name, sizeof(tempStu.name), "lisi"); }Student stu1; func(stu1); // 接受普通的数据类型 const student &stu2 = stu1; func(stu2); // 接受常量的数据类型(包括常数)
-
-
常量指针和指针常量的区别:
const char* ptr等价于char const *ptr,ptr指向的东西,不能通过ptr修改char* const ptr,ptr一旦指向一个东西,之后就不能再指向其他东西;但可以修改ptr指向的目标内容
递归函数:
递归,是一种重要的编程思想,可以通过数学归纳法严格证明。
递归设计的基本准则:
- 基准情况:无须递归就能解出
- 不断推进:每一次递归调用,都必须使求解状况朝接近基准情形的方向推进
- 设计准则:假设所有的递归调用都能运行
- 合成效益法则:求解一个问题的同一个实例,切勿在不同的递归调用中做重复性的工作
缺点:导致时间(需要大量重复的运算)和空间(需要开辟大量的栈空间)的浪费
递归的优化:
以求取斐波那契数列为例,提出不同的优化策略。

-
尾递归:所有递归形式的调用都出现在函数的末尾;
int f(int n, int ret0, int ret1) {if (n == 0){return 0}if (n == 1){return 1;}return f(n-1, ret1, ret0 + ret1) ; } -
使用循环替代;
int f(int n) {int n0 = 0; int n1 = 1;for (int i = 2; i < n; i++){temp = n0;n0 = n1;n1 = temp + n0;}return n1; } -
使用动态规划,即采用"空间换时间"的策略;
int recursion_space[1000];int f(int n) {recursion[0] = 0;recursion[1] = 1;for (int i = 2; i < n; i++){if (recursion_space == 0){recursion_space[i] = recursion_space[ i - 2] + recursion_space[i - 1];}}return recursion_space[n - 1]; }
c++中的I/O流、I/O缓存区:
I/O流:


I/O缓存区:

标准的I/O,提供的三种类型的缓存模式:
- 按块缓存:如文件系统;
- 按行缓存:
\n; - 不缓存;
#include<iostream>
using namespace std;// cin、cout:采用的是按行缓存的方式
int main()
{int a;int count = 0; while (cin >> a) {cout << a << endl;count++;if (count == 5){break;}}cin .ignore(numeric_limits<std::streamsize>::max(), '\n'); // 会删除掉缓冲区中,多余的脏数据char ch;cin >> ch;cout << ch << endl;
}
文件操作:
-
输入流的起点和输出流的终点,都可以是磁盘文件;是以块缓存进行读取的;
-
数据的持久化方式:文件和数据库;
-
c++将每个文件,都看做是一个有序的字节序列,每个文件都以文件结束标志结束;
-
文件缓冲区,又称文件缓存,是系统预留的内存空间,由操作系统管理;

-
因磁盘的读写要比内存慢的多,通过缓冲区,可以极大降低磁盘的I/O次数,从而提高磁盘存取的速度;
-
根据输出和输入流,分为输出缓冲区和输入缓冲区,且不同的流的缓冲区是相互独立的;
-
c++中,每打开一个文件,系统就会为它分配缓冲区,程序员只关心输出缓冲区即可。
缺省模式下,输出缓冲区的数据满了,系统才将数据写入磁盘,极大的降低了磁盘的I/O次数,效率更高,但容易导致数据没有及时的写入磁盘(掉电可能遗失数据)。输出缓冲区的操作:
flush() // 刷新缓冲区,将缓冲区中的内容写入磁盘文件中;endl // 换行,然后刷新缓冲区;\n'的功能:只有换行;unitbuf // 设置fout输出流,在每次操作后自动刷新缓冲区; nounitbuf // 设置fout输出流,让fout回到缺省模式下的缓冲方式; fout << unitbuf; fout << nounitbuf;
-
-
流的状态:
eofbit、badbit、failbit。取值:1表示设置、0表示清除。eofbit // 当输入流操作到达文件末尾时,将设置eofbit eof() // 用于检查流是否设置了eofbit fin >> buffer; if (fin.eof() == true) {break; } cout << buffer << endl;badbit // 无法诊断的失败破坏流时,将设置badbit(一般是系统错误,如存储空间不足) bad() // 用于检查流是否设置了badbitfailbit // 当输入流操作未能读取预期的字符时,将设置failbit fail() // 用于检查流是否设置了failbit当三个流的状态都是0时,表示一切顺利,
good()成员函数返回true,否则返回false。 -
按照文件中数据的组织形式,可分为:
- 文本文件:存放的是字符串,以行的方式组织数据;文件中的信息形式为ASCII码文件,每个字符占一个字节,方便阅读(解码),但占用的空间比较多。
- 二进制文件:存放的不一定是字符串,以数据类型组织的数据,内容要作为一个整体来考虑,单个字节没有意义;文件中信息的形式与其在内存中的形式相同,由0、1组成,组织数据的格式与文件用途有关,但不方便阅读(解码)。
为节省存储空间,还可采用压缩计数;为保证数据安全,也可采用加密技术。
-
文件的随机存取:
文件位置指针:对文件进行读/写操作时,文件的位置指针指向当前文件读/写的位置;
获取文件的位置指针:
ofstream类的成员函数是tellp()、ifstream类的成员函数是tellg()。移动文件位置指针:
ofstream类的成员函数是seekp()、ifstream类的成员函数是seekg()。std::istream& seekg(std::streampos _pos); std::istream& seekp(std::streampos _pos); seekp(128); seekg(128); // 文件指针移动到128字节 seekp(std::begin); seekp(std::end); // 文件指针移动到开始或结尾 seekg(std::begin)、seekg(std::end):std::istream& seekg(std::streamoff _off, std::ios::seekdir _Way); std::istream& seekp(std::streamoff _off, std::ios::seekdir _Way);// ios中定义的枚举类型: enum seek_dir {beg, cur, end}; seekg(30, ios::beg); // 从文件开始位置往后移动30字节 seekg(-30, ios::cur); // 从当前位置往前移动30字节;seekg(30, ios::cur):从当前位置往后移动30字节 seekg(-30, ios::end); // 从文件结束位置往前移动30字节对文件进行随机存储,如果文件中该处有内容,则会被覆盖掉原有的内容。
-
文件操作的步骤:
1、打开文件用于读和写open,文件的打开方式:// 默认是以ASCII码的形式打开:ios::in打开文件进行读操作(ifstream默认模式)ios::out打开文件进行写操作(ofstream默认模式)ios::trunc如果文件存在,清除原文件的内容ios::app打开文件并在追加内容ios::ate打开一个已有输入或输出文件并查找到文件尾ios::nocreate如果文件不存在,则打开操作失败// 以二进制的形式打开:ios::binary以二进制方式打开 2、is_open() // ifstream、ofstream是否为空,检查打开是否成功 3、读或者写read、write 4、检查是否读完EOF(end of file) 5、close() // 关闭文件#include <iostream> using namespace std;int main() {string filename = "./test.txt";fstream fin(filename, ios::in);if (!fout) // fout.is_open(){cout << "open the file is failure" << endl;}string buffer; // 按行读文件,要保证缓冲区足够大// 写法一:while (getline(fin, buffer)){cout << buffer << endl;}// 写法二:while (fin >> buffer)){cout << buffer << endl;}fin.close();return 0; }const bufferLen = 1024; bool copyBinaryFile(const string& src, const string& dst) {ifstream in(src, ios::in | ios::binary);ofstream out(dst, ios::out | ios::binary | ios::trunc);if (!in || ! out){return false;}// 从源文件读数据到缓冲区,从缓冲区写入文件中char temp[bufferLen];while(!in.eof()){in.read(temp, bufferLen);streamsize count = in.gcount(); // 从源文件读取到缓冲区的个数out.write(temp, count); }in.close();out.close();return true; } -
读写二进制文件:
二进制文件以数据块的形式组织数据,把内存中的数据直接写入文件;
二进制的文件格式多种多样,由业务需求而定:
- MP3、MP4、bmp、jpg、png;
- 自定义的二进制文件格式,只有程序员自己可知,即自定义的数据结构;
写二进制文件:
#include<iostream> #include <fstream> using namespace std;int main() {// 自定义后缀.dat,其中存放的是不同的Girl类对象fstream fout("./test.dat", ios::out | ios::binary);if (!fout.is_open()){cout << "open ths file is failure" << endl;}struct Girl{char name[31];int age;double weight;} girl;girl = {"lili", 12, 130.5};fout.write((const char*)&girl, sizeof(Girl));fout.close();return 0; }读二进制文件:
#include<iostream> #include <fstream> using namespace std;int main() {// 自定义后缀.dat,其中存放的是不同的Girl类对象fstream fin("./test.dat", ios::in | ios::binary);if (!fin.is_open()){cout << "open ths file is failure" << endl;}struct Girl{char name[31];int age;double weight;} girl; // 二进制文件以数据块的形式组织数据while (fin.read((const char*)&girl, sizeof(Girl))){cout << girl.name << "," << girl.age << "," << girl.weight << endl;}fin.close();return 0; } -
操作文本文件和二进制文件的更多细节:
1)windows平台下,文本文件的换行标志是
"\r\n";(以文本方式打开文件,写数据时系统会将"\n"转换成"\r\n",读数据时系统会将"\r\n"转换成"\n";以二进制方式打开文件,系统不会做任何转换)2)linux平台下,文本文件的换行标志是
"\n";(以文本和二进制方式打开文件,系统不会做任何转换)3)读取文件时,
- 以文本方式读取文件的时候,遇到换行符停止,读入的内容没有换行符;
- 以二进制方式读取文件时,遇到换行符不会停止,读入的内容中包含换行符(换行符被认为是数据);
-
实际开发中,从兼容性和语义的角度考虑:
1)以文本模式打开文本文件,用行的方法操作它;
2)以二进制模式打开二进制文件,用数据块的方法操作它;
3)不要以二进制模式打开文本文件,也不要用行的方法操作二进制文件,可能破坏二进制数据文件的格式(二进制的某个字节的取值可能是换行符,但也可能是整数中的某个字节);
std::move()和std::ref的对比:
std::ref()的作用。
-
std::move():c++11引入的用于将左值转换为右值引用,故而可使编译器选择移动语义而非拷贝语义,从而优化性能。其允许在不复制对象的情况下,将资源从一个对象转移到另一个对象上,- 对象之间传递大型数据结构;
- 临时对象的资源转移到持久化对象上;
注意:一旦
std::move()进行资源的转移,这样源对象就不能再使用了。 -
std::ref():c++11引入的用于创建引用包装器。当需要向函数传递引用时,尤其是使用标准库时如std::bind()、std::thread()等,避免了这些函数默认对参数的复制。
总的来说:
std::move()用于优化性能,通过将资源的从一个对象转移到另一个对象上,而不是复制资源。std::ref()用来创建引用包装器,以便在需要传递引用而不是复制对象时使用。
相关文章:
c++_learning-基础部分
文章目录 基础认识:语言特性(面向对象编程):c的类(相当于c中的结构体):三大特性:c包含四种编程范式:优缺点: c程序编译的过程:预处理->编译&am…...

支持PC端、手机端、数据大屏端的Spring Cloud智慧工地云平台源码
技术架构:微服务JavaSpring Cloud VueUniApp MySql 智慧建筑工地云平台主要利用大数据、物联网等技术,整合工地信息、材料信息、工程进度等,实现对建筑项目的全程管理。它可以实现实时监测和控制,有效解决施工中的问题,…...
给cmd控制台程序 套壳 美化
给cmd控制台程序套壳美化,可以获取程序的标准输出和报错信息。 # _*_ coding: utf-8 _*_ """ 控制台程序启动器,杜绝黑窗口。 Time: 2023/10/18 15:28 Author: Jyun Version: V 0.1 File: main.py Blog: https://ctrlcv.…...

【系统架构设计】架构核心知识: 1 构件和中间件
目录 一 构件 1 构件的特性 2 构件、对象和模块的对比 3 构件的复用...
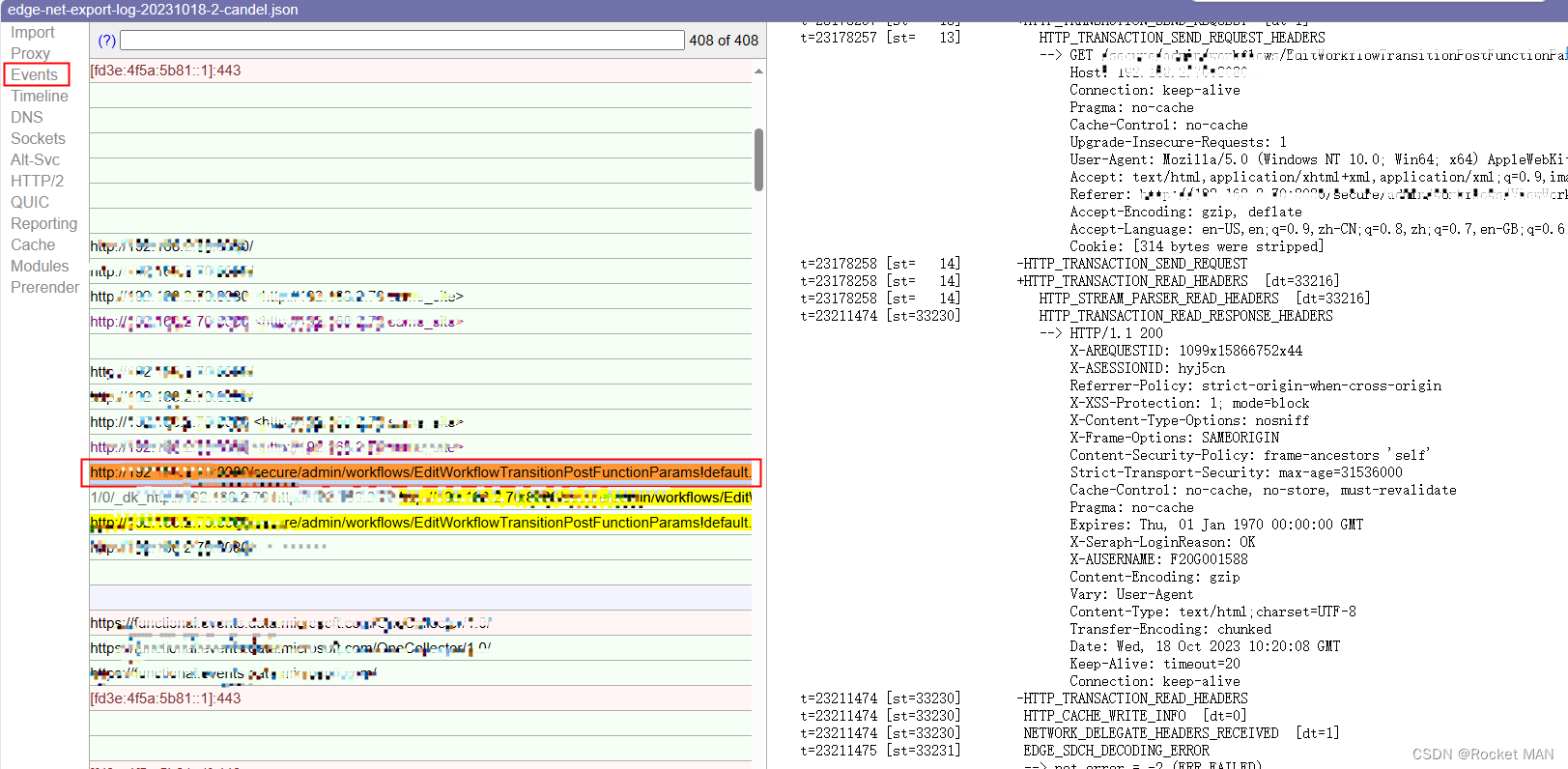
通过开发者工具-网络排查响应时间过长的问题
关键词:network 网络 pending 开发者工具 有时候我们会发现某次http请求花费了很长时间,比如会花费十几秒,那么我们可以通过开发者工具的网络和其他一些工具来分析请求时间过长的原因 Dev Tool 中时间线各阶段代表的意义 分别用edge、chorm…...

【Python】Python 实现 Excel 到 CSV 的转换程序
Python 实现 Excel 到 CSV 的转换程序 Excel 可以将电子表格保存为 CSV 文件,只要点几下 鼠标,但如果有几百个 Excel文件要转换为 CSV , 就需要点击几小时。利用 openpyxl 模块, 编程读取当前工作目录中的所有 Excel 文件&#x…...

BUUCTF题解之[极客大挑战 2019]Havefun 1
1.题目分析 使用浏览器开发者工具查看网页源码,查看疑似flag的代码。 (特别是注释了的源码,一般是HTML,JS,PHP的源码) 修改统一资源定位符URL访问服务器后端接口,拿到flag。 1.URL URL是统一资源定位符(…...

DIV+CSS网页布局
本文参考 https://blog.csdn.net/ZhangJiWei_2019/article/details/114669722 二、浮动 浮动的元素会向左或向右浮动,直到碰到前面已经有浮动的元素或者是其父元素的边框为止。浮动的元素会脱离文档流(不再占有原来的位置)。 (…...

python二次开发CATIA:CATIA Automation
CATIA 软件中有一套逻辑与关系都十分严谨的自动化对象,它们从CATIA(Application)向下分支。每个自动化对象(Automation Object,以下简称Object)都有各自的属性与方法。我们通过程序语言调用这些 Object 的属性与方法,便…...
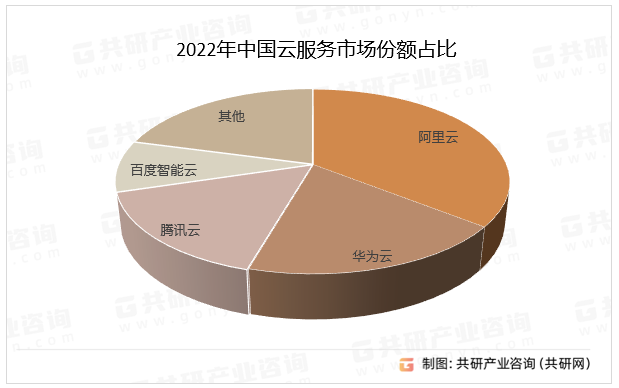
2023年中国云计算软件市场规模、市场结构及市场份额情况分析[图]
云计算是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。云计算软件类型分为三类,即基础设施即服务、平台即服…...
docker入门加实战—部署Java和前端项目
docker入门加实战—部署Java和前端项目 部署之前,先删除nginx,和自己创建的dd两个容器: docker rm -f nginx dd部署Java项目 作为演示,我们的Java项目比较简单,提供了一个接口: 配置文件连接docker里的m…...

机器人制作开源方案 | 行星探测车概述
1. 功能描述 行星探测车(Planetary Rover)是一种用于进行科学探索和勘测任务的无人车辆,它们被设计成能够适应各种复杂的地形条件和极端环境,以便收集数据、拍摄照片、采集样本等。行星探测车通常包含以下主要组件和功能ÿ…...

Git基础命令
一、Git 码云创建空白仓库 什么都不选,使用代码初始化 初始化仓库:git init 配置信息:git config user.name"mashuchao" 配置信息:git config user.email"mashuchao.com" 查看配置信息:git c…...

C#中Semaphore 和 CountdownEvent 的使用总结
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施,是可以用来保证两个或多个关键代码段不被并发调用。在进入一个关键代码段之前,线程必须获取一个信号量。一旦该关键代码段完成了,那么该线程必须释…...
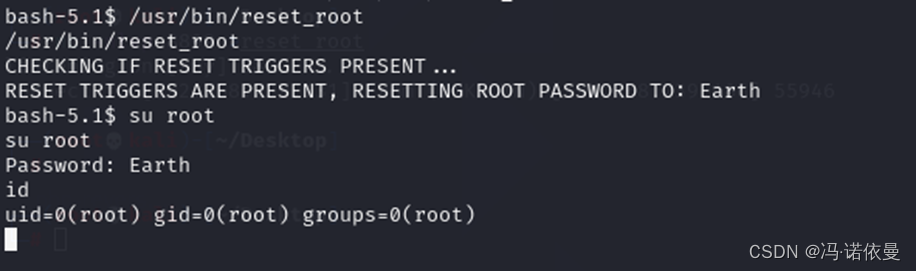
THE PLANETS:EARTH vulnhub
信息收集 netdiscover -i eth0 -r 192.168.239.0,扫描存活主机,发现目标主机 对目标主机进行端口扫描:nmap -p- -sV -O -Pn -A 192.168.239.186,发现443端口存在DNS,域名 在本地得/etc/hosts中添加域名信息 浏览…...

【随想】每日两题Day.13
题目:344. 反转字符串 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 示例 1: 输入&…...

CMake Cookbook
使用CMake软件对项目模块,进行构建、测试和打包。 Introduction - 《CMake菜谱(CMake Cookbook中文版)》 - 书栈网 BookStack https://github.com/dev-cafe/cmake-cookbook/tree/v1.0...
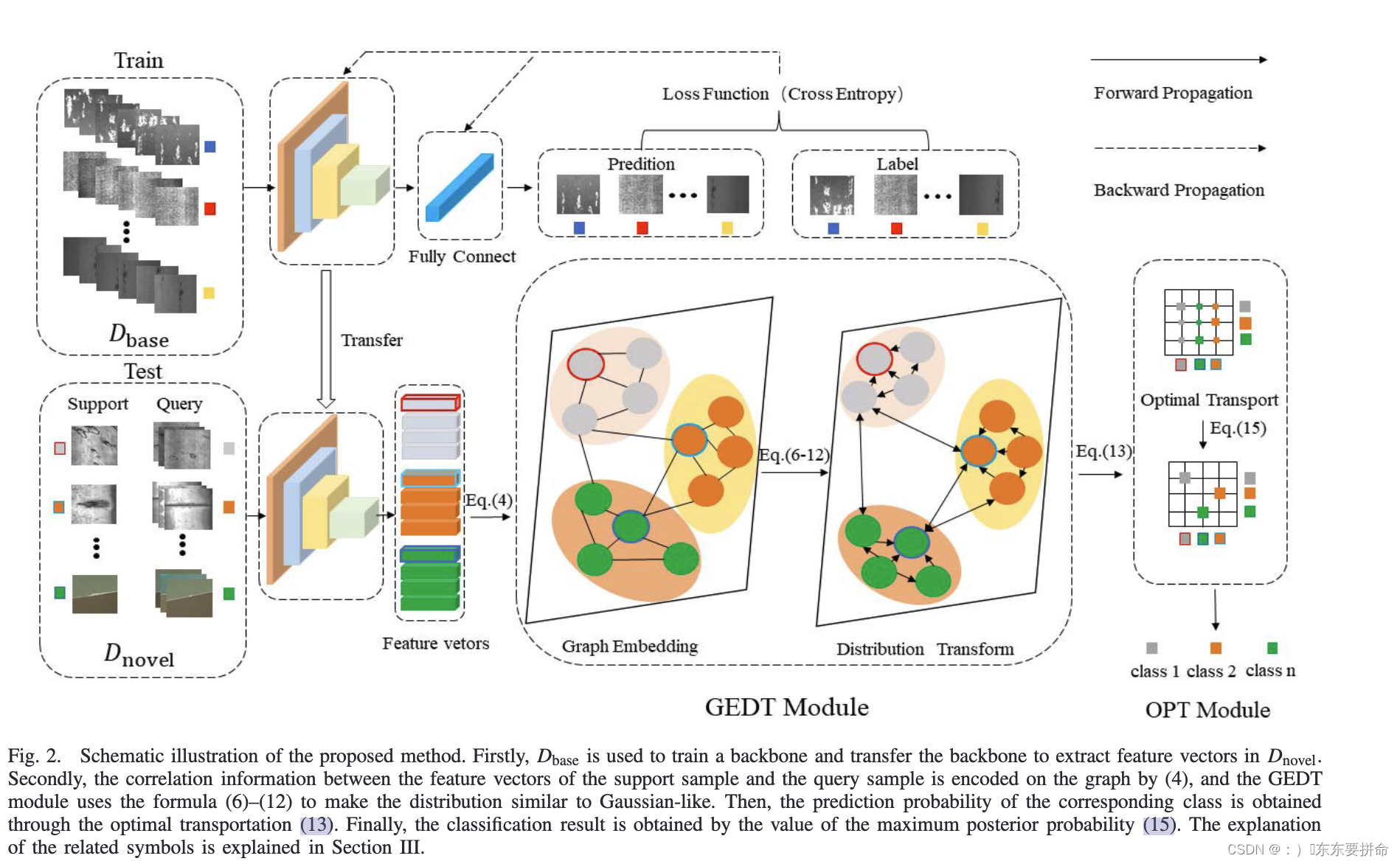
钢铁异常分类 few-shot 问题 小陈读paper 钢铁2
很清爽的 abstract 给出链接 前面的背景意义 其实 是通用的 这里替大家 整理一吓吓 1 缺陷分类在钢铁表面缺陷检测中 有 意义。 2 大多数缺陷分类模型都是基于完全监督的学习, 这需要大量带有图像标签的训练数据。 在工业场景中收集有缺陷的图像是非常困难…...
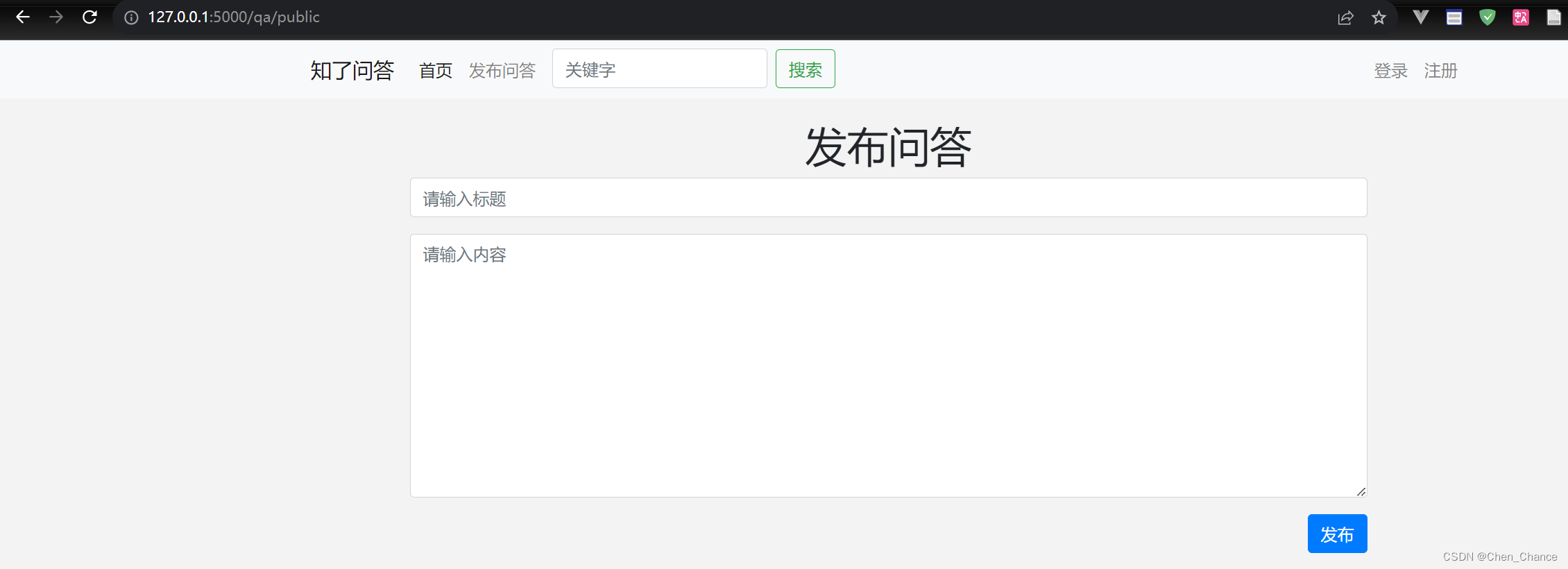
flask实战(问答平台)
问答平台项目结构搭建 先创建一个配置文件config.py,后面有些配置写在这里 #app.py from flask import Flask import configapp Flask(__name__) #绑定配置文件 app.config.from_object(config)app.route(/) def hello_world(): # put applications code herer…...

RK3568驱动模块编译进内核
一、创建文件 首先在drivers/char目录下创建hello文件夹,然后在hello文件夹下创建hello.c 文件、Kconfig和Makefile文件。 hello.c 文件内容如下 #include <linux/module.h> #include <linux/kernel.h> static int __init helloworld_init(void) …...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

1990-2023年 全国省市县耕地面积数据 xlsx+tif
01、数据概述 本数据集详尽记录了1990年至2023年间,中国各省市县的耕地面积变化情况。原始数据以Tif栅格格式存储,后经专业处理转化为结构化的省市县面板数据,直观呈现了各地区耕地面积的年度总和。1990-2023年全国省市县耕地面积数据xlsxti…...
帮你一次搞定)
别再复制粘贴了!用LaTeX写IEEE论文,这份保姆级配置清单(含数学符号速查表)帮你一次搞定
IEEE论文LaTeX高效写作:从零配置到数学符号速查的全套解决方案 第一次用LaTeX写IEEE论文时,我在凌晨三点对着报错的红色文字和错位的公式几乎崩溃。直到一位博士生分享了他的配置文件,我才发现原来90%的常见问题都有现成解决方案。本文将把这…...

利用模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用模型广场为你的智能客服场景挑选合适模型 智能客服是当前许多应用接入大模型的核心场景之一。开发者需要根据业务对响应速度、…...

创新设计与智能系统设计融合
在智能制造与工业大模型时代,创新设计(以生成式AI、变型衍生、大规模定制为核心)与智能系统设计(以端-边-云协同、工业智能体、自主控制为核心)的融合,是制造企业实现研发与生产双向闭环的终极路径 。两者的…...

3个技巧让桌游卡牌设计效率提升5倍:EZCard自动化工具深度解析
3个技巧让桌游卡牌设计效率提升5倍:EZCard自动化工具深度解析 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/…...

探索OpenHarmony蓝牙BLE测试HAP:高效验证与优化
探索OpenHarmony蓝牙BLE测试HAP:高效验证与优化 【下载地址】OpenHarmony鸿蒙蓝牙ble测试hap 本仓库提供的是用于OpenHarmony系统下的蓝牙BLE(低功耗蓝牙)测试HAP(HarmonyOS Ability Package)。此HAP旨在帮助开发者和测…...
第2小节:国内外技术参数差距)
0502光刻机破局 第五卷:EUV光源系统(S级 长期死磕突破)第2小节:国内外技术参数差距
第五卷:EUV光源系统(S级 长期死磕突破) 第2小节:国内外技术参数差距(全量化对标,ASML vs 国产,死磕数据) 前置硬核声明 本节100%量化、100%对标、100%无修饰,直接把 ASML…...

JetBrains IDE试用期重置终极指南:三步实现无限开发体验
JetBrains IDE试用期重置终极指南:三步实现无限开发体验 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?ide-eval-resetter是你的理想解决方案&…...

终极 Node.js 路径管理神器:module-alias 完全指南
终极 Node.js 路径管理神器:module-alias 完全指南 【免费下载链接】module-alias Register aliases of directories and custom module paths in Node 项目地址: https://gitcode.com/gh_mirrors/mo/module-alias 你是否厌倦了在 Node.js 项目中看到像 requ…...