服务日志性能调优,由log引出的巨坑

只有被线上服务问题毒打过的人才明白日志有多重要!
谁赞成,谁反对?如果你深有同感,那恭喜你是个社会人了:)
日志对程序的重要性不言而喻,轻巧、简单、无需费脑,程序代码中随处可见,帮助我们排查定位一个有一个问题问题。但看似不起眼的日志,却隐藏着各式各样的“坑”,如果使用不当,不仅不能帮助我们,反而会成为服务“杀手”。
本文主要介绍生产环境日志使用不当导致的“坑”及避坑指北,高并发系统下尤为明显。同时提供一套实现方案能让程序与日志“和谐共处”。
避坑指北
本章节我将介绍过往线上遇到的日志问题,并逐个剖析问题根因。
不规范的日志书写格式
// 格式1
log.debug("get user" + uid + " from DB is Empty!");// 格式2
if (log.isdebugEnable()) {log.debug("get user" + uid + " from DB is Empty!");
}// 格式3
log.debug("get user {} from DB is Empty!", uid);如上三种写法,我相信大家或多或少都在项目代码中看到过,那么他们之前有区别呢,会对性能造成什么影响?
如果此时关闭 DEBUG 日志级别,差异就出现了:
格式1 依然还是要执行字符串拼接,即使它不输出日志,属于浪费。
格式2 的缺点就是就在于需要加入额外的判断逻辑,增加了废代码,一点都不优雅。
所以推荐格式3,只有在执行时才会动态的拼接,关闭相应日志级别后,不会有任何性能损耗。
生产打印大量日志消耗性能
尽量多的日志,能够把用户的请求串起来,更容易断定出问题的代码位置。由于当前分布式系统,且业务庞杂,任何日志的缺失对于程序员定位问题都是极大的障碍。所以,吃过生产问题苦的程序员,在开发代码过程中,肯定是尽量多打日志。
为了以后线上出现问题能尽快定位问题并修复,程序员在编程实现阶段,就会尽量多打关键日志。那上线后是能快速定位问题了,但是紧接着又会有新的挑战:随着业务的快速发展,用户访问不断增多,系统压力越来越大,此时线上大量的 INFO 日志,尤其在高峰期,大量的日志磁盘写入,极具消耗服务性能。
那这就变成了博弈论,日志多了好排查问题,但是服务性能被“吃了”,日志少了服务稳定性没啥影响了,但是排查问题难了,程序员“苦”啊。
提问:为何 INFO 日志打多了,性能会受损(此时 CPU 使用率很高)?
根因一:同步打印日志磁盘 I/O 成为瓶颈,导致大量线程 Block
可以想象,如果日志都输出到同一个日志文件时,此时有多个线程都往文件里面写,是不是就乱了套了。那解决的办法就是加锁,保证日志文件输出不会错乱,如果是在高峰期,锁的争抢 无疑是最耗性能的。当有一个线程抢到锁后,其他的线程只能 Block 等待,严重拖垮用户线程,表现就是上游调用超时,用户感觉卡顿。
如下是线程卡在写文件时的堆栈:
Stack Trace is:
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.logging.log4j.core.appender.OutputStreamManager.writeBytes(OutputStreamManager.java:352)
- waiting to lock <0x000000063d668298> (a org.apache.logging.log4j.core.appender.rolling.RollingFileManager)
at org.apache.logging.log4j.core.layout.TextEncoderHelper.writeEncodedText(TextEncoderHelper.java:96)
at org.apache.logging.log4j.core.layout.TextEncoderHelper.encodeText(TextEncoderHelper.java:65)
at org.apache.logging.log4j.core.layout.StringBuilderEncoder.encode(StringBuilderEncoder.java:68)
at org.apache.logging.log4j.core.layout.StringBuilderEncoder.encode(StringBuilderEncoder.java:32)
at org.apache.logging.log4j.core.layout.PatternLayout.encode(PatternLayout.java:228)
.....那么是否线上减少 INFO 日志就没问题了呢?同样的,ERROR 日志量也不容小觑,假设线上出现大量异常数据,或者下游大量超时,瞬时会产生大量 ERROR 日志,此时还是会把磁盘 I/O 压满,导致用户线程 Block 住。
提问:假设不关心 INFO 排查问题,是不是生产只打印 ERROR 日志就没性能问题了?
根因二:高并发下日志打印异常堆栈造成线程 Block
有次线上下游出现大量超时,异常都被我们的服务捕获了,庆幸的是容灾设计时预计到会有这种问题发生,做了兜底值逻辑,本来庆幸没啥影响是,服务器开始“教做人”了。线上监控开始报警, CPU 使用率增长过快,CPU 一路直接增到 90%+ ,此时紧急扩容止损,并找一台拉下流量,拉取堆栈。
Dump 下来的线程堆栈查看后,结合火焰退分析,大部分现成都卡在如下堆栈位置:
Stack Trace is:
java.lang.Thread.State: BLOCKED (on object monitor)
at java.lang.ClassLoader.loadClass(ClassLoader.java:404)
- waiting to lock <0x000000064c514c88> (a java.lang.Object)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.apache.logging.log4j.core.impl.ThrowableProxyHelper.loadClass(ThrowableProxyHelper.java:205)
at org.apache.logging.log4j.core.impl.ThrowableProxyHelper.toExtendedStackTrace(ThrowableProxyHelper.java:112)
at org.apache.logging.log4j.core.impl.ThrowableProxy.(ThrowableProxy.java:112)
at org.apache.logging.log4j.core.impl.ThrowableProxy.(ThrowableProxy.java:96)
at org.apache.logging.log4j.core.impl.Log4jLogEvent.getThrownProxy(Log4jLogEvent.java:629)
...此处堆栈较长,大部分现场全部 Block 在 java.lang.ClassLoader.loadClass,而且往下盘堆栈发现都是因为这行代码触发的
at org.apache.logging.slf4j.Log4jLogger.error(Log4jLogger.java:319)// 对应的业务代码为
log.error("ds fetcher get error", e);啊这。。。就很离谱,你打个日志为何会加载类呢?加载类为何会 Block 这么多线程呢?
一番查阅分析后,得出如下结论:
使用 Log4j 的 Logger.error 去打印异常堆栈的时候,为了打印出堆栈中类的位置信息,需要使用 Classloader 进行类加载;
Classloader加载是线程安全的,虽然并行加载可以提高加载不同类的效率,但是多线程加载相同的类时,还是需要互相同步等待,尤其当不同的线程打印的异常堆栈完全相同时,就会增加线程 Block 的风险,而 Classloader 去加载一个无法加载的类时,效率会急剧下降,使线程Block的情况进一步恶化;
因为反射调用效率问题,JDK 对反射调用进行了优化,动态生成 Java 类进行方法调用,替换原来的 native 调用,而生成的动态类是由 DelegatingClassLoader 进行加载的,不能被其他的 Classloader 加载,异常堆栈中有反射优化的动态类,在高并发的条件下,就非常容易产生线程 Block 的情况。
结合上文堆栈,卡在此处就很明清晰了:
大量的线程涌进,导致下游的服务超时,使得超时异常堆栈频繁打印,堆栈的每一层,需要通过反射去拿对应的类、版本、行数等信息,loadClass 是需要同步等待的,一个线程加锁,导致大部分线程 block 住等待类加载成功,影响性能。
讲道理,即使大部分线程等待一个线程 loadClass,也只是一瞬间的卡顿,为何这个报错这会一直 loadClass类呢?结合上述结论分析程序代码,得出:此处线程内的请求下游服务逻辑包含 Groovy 脚本执行逻辑,属于动态类生成,上文结论三表明,动态类在高并发情况下,无法被log4j正确反射加载到,那么堆栈反射又要用,进入了死循环,越来越多的线程只能加入等待,block 住。
最佳实践
1、去掉不必要的异常堆栈打印
明显知道的异常,就不要打印堆栈,省点性能吧,任何事+高并发,意义就不一样了:)
try {System.out.println(Integer.parseInt(number) + 100);
} catch (Exception e) {// 改进前log.error("parse int error : " + number, e);// 改进后log.error("parse int error : " + number);
}如果Integer.parseInt发生异常,导致异常原因肯定是出入的number不合法,在这种情况下,打印异常堆栈完全没有必要,可以去掉堆栈的打印。
2、将堆栈信息转换为字符串再打印
public static String stacktraceToString(Throwable throwable) {StringWriter stringWriter = new StringWriter();throwable.printStackTrace(new PrintWriter(stringWriter));return stringWriter.toString();
}log.error 得出的堆栈信息会更加完善,JDK 的版本,Class 的路径信息,jar 包中的类还会打印 jar 的名称和版本信息,这些都是去加载类反射得来的信息,极大的损耗性能。
调用 stacktraceToString 将异常堆栈转换为字符串,相对来说,确实了一些版本和 jar 的元数据信息,此时需要你自己决策取舍,到底是否有必要打印出这些信息(比如类冲突排查基于版本还是很有用的)。
3、禁用反射优化
使用 Log4j 打印堆栈信息,如果堆栈中有反射优化生成的动态代理类,这个代理类不能被其它的Classloader加载,这个时候打印堆栈,会严重影响执行效率。但是禁用反射优化也会有副作用,导致反射执行的效率降低。
4、异步打印日志
生产环境,尤其是 QPS 高的服务,一定要开启异步打印,当然开启异步打印,有一定丢失日志的可能,比如服务器强行“杀死”,这也是一个取舍的过程。
5、日志的输出格式
我们看戏日志输出格式区别
// 格式1
[%d{yyyy/MM/dd HH:mm:ss.SSS}[%X{traceId}] %t [%p] %C{1} (%F:%M:%L) %msg%n// 格式2
[%d{yy-MM-dd.HH:mm:ss.SSS}] [%thread] [%-5p %-22c{0} -] %m%n官网也有明确的性能对比提示,如果使用了如下字段输出,将极大的损耗性能
%C or $class, %F or %file, %l or %location, %L or %line, %M or %method
log4j 为了拿到函数名称和行号信息,利用了异常机制,首先抛出一个异常,之后捕获异常并打印出异常信息的堆栈内容,再从堆栈内容中解析出行号。而实现源码中增加了锁的获取及解析过程,高并发下,性能损耗可想而知。
如下是比较影响性能的参数配置,请大家酌情配置:
%C - 调用者的类名(速度慢,不推荐使用)
%F - 调用者的文件名(速度极慢,不推荐使用)
%l - 调用者的函数名、文件名、行号(极度不推荐,非常耗性能)
%L - 调用者的行号(速度极慢,不推荐使用)
%M - 调用者的函数名(速度极慢,不推荐使用)
解决方案——日志级别动态调整
项目代码需要打印大量 INFO级别日志,以支持问题定位及测试排查等。但这些大量的 INFO日志对生产环境是无效的,大量的日志会吃掉 CPU 性能,此时需要能动态调整日志级别,既满足可随时查看 INFO日志,又能满足不需要时可动态关闭,不影响服务性能需要。
方案:结合 Apollo 及 log4j2 特性,从 api层面,动态且细粒度的控制全局或单个 Class 文件内的日志级别。优势是随时生效,生产排查问题,可指定打开单个 class 文件日志级别,排查完后可随时关闭。
限于本篇篇幅,具体实现代码就不贴出了,其实实现很简单,就是巧妙的运用 Apollo 的动态通知机制去重置日志级别,如果大家感兴趣的话,可以私信或者留言我,我开一篇文章专门来详细讲解如何实现。
总结与展望
本篇带你了解了日志在日常软件服务中常见的问题,以及对应的解决方法。切记,简单的东西 + 高并发 = 不简单!要对生产保持敬畏之心!
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
文档获取方式:
加入我的软件测试交流群:632880530免费获取~(同行大佬一起学术交流,每晚都有大佬直播分享技术知识点)这份文档,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
以上均可以分享,只需要你搜索vx公众号:程序员雨果,即可免费领取
相关文章:
服务日志性能调优,由log引出的巨坑
只有被线上服务问题毒打过的人才明白日志有多重要! 谁赞成,谁反对?如果你深有同感,那恭喜你是个社会人了:) 日志对程序的重要性不言而喻,轻巧、简单、无需费脑,程序代码中随处可见…...
【VR】【Unity】如何调整Quest2的隐藏系统时间日期
【背景】 网络虽然OK,但是Oculus Quest要连上商店还必须调整好系统时间,不过在Quest系统中,时间对用户是不可见的,本篇介绍调整的方法。 【方法】 打开SideQuest,没有的话先去下载一个。打开后先登录,如…...

C++之设计模式
C23种设计模式 https://blog.csdn.net/qq_40309341/article/details/120318957 设计模式可以同时使用多个。在软件开发中,通常会根据需求和问题的复杂性,结合多种设计模式来构建应用程序,以提高代码的可维护性、可扩展性和重用性。不同的设计…...

Django ORM查询
文章目录 1 增 -- 向表内插入一条数据2 删 -- 删除表内数据(物理删除)3 改 -- update操作更新某条数据4 查 -- 基本的表查询(包括多表、跨表、子查询、联表查询)4.1 基本查询4.2 双下划线查询条件4.3 逻辑查询:or、and…...

如何在CentOS 7中卸载Python 2.7,并安装3.X
Python是一种常用的编程语言,但是如果您不需要在服务器上使用Python 2.7,那么本文将详细介绍如何在CentOS 7上卸载Python 2.7。 一、检查Python版本 在卸载Python 2.7之前,必须检查系统上的Python版本。 在终端中执行以下命令:…...

10.17七段数码管单个多个(部分)
单个数码管的实现 第一种方式 一端并接称为位码;一端分别接收电平信号以控制灯的亮灭,称为段码 8421BCD码转七段数码管段码是将BCD码表示的十进制数转换成七段LED数码管的7个驱动段码, 段码就是LED灯的信号 a为1表示没用到a,a为…...
linux静态库与动态库
库是一种可执行的二进制文件,是编译好的代码。使用库可以提高开发效率。在Linux 下有静态库和动态库。 静态库在程序编译的时候会被链接到目标代码里面。所以程序在运行的时候不再需要静态库了。因此编译出来的体积就比较大。以 lib 开头,以.a 结尾。…...

LeetCode 面试题 10.03. 搜索旋转数组
文章目录 一、题目二、C# 题解 一、题目 搜索旋转数组。给定一个排序后的数组,包含n个整数,但这个数组已被旋转过很多次了,次数不详。请编写代码找出数组中的某个元素,假设数组元素原先是按升序排列的。若有多个相同元素ÿ…...

SpringCloudSleuth异步线程支持和传递
场景 在使用Sleuth做链路跟踪时,默认情况下异步线程会断链,需要进行代码调整支持。 调整内容 方式一 使用Async实现异步线程 开启异步线程池 EnableAsync SpringBootApplication public class LizzApplication {public static void main(String[] a…...
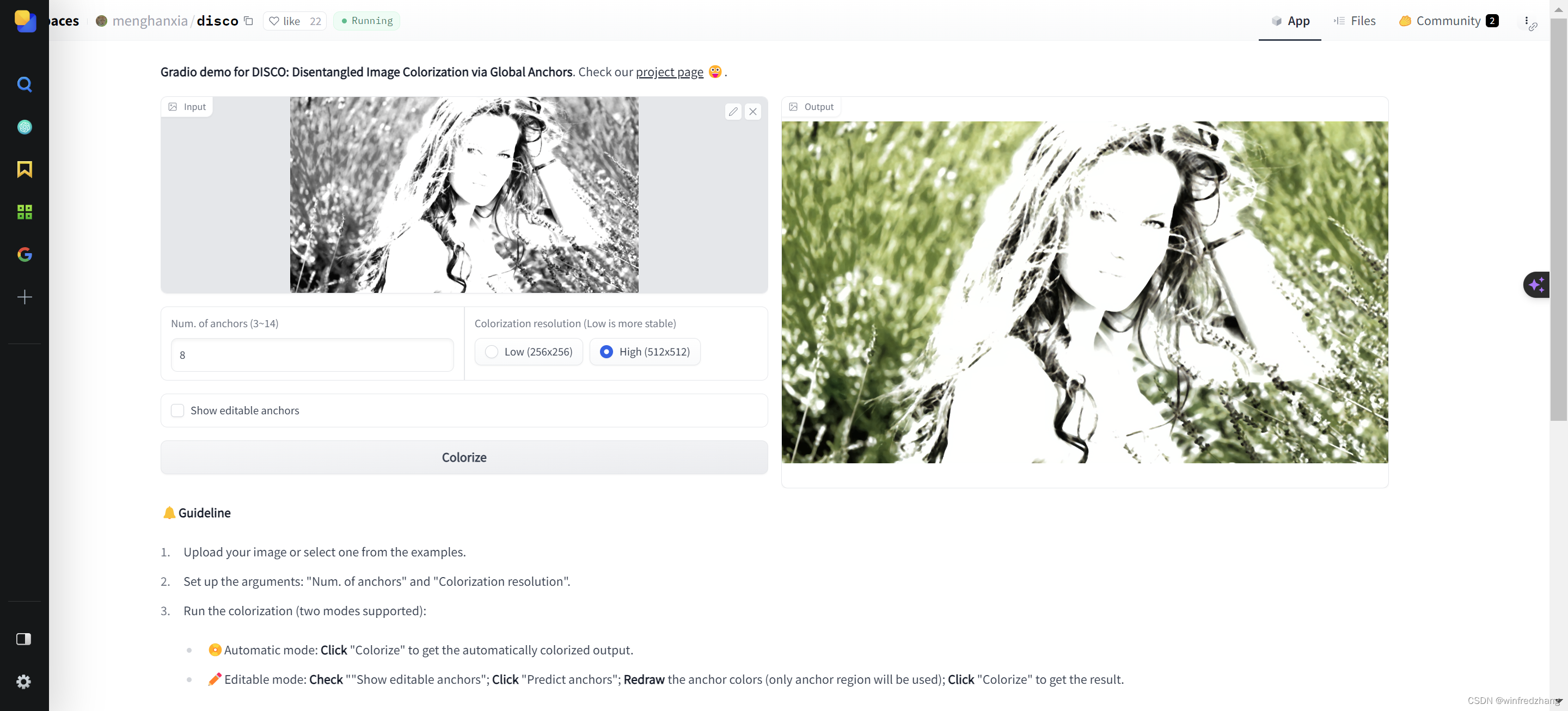
如何使用 Disco 将黑白照片彩色化
Disco 是一个基于视觉语言模型(LLM)的图像彩色化工具。它使用 LLM 来生成彩色图像,这些图像与原始黑白图像相似。 本文将介绍如何使用 Disco 将黑白照片彩色化。 使用 Disco 提供了一个简单的在线演示,可以用于测试模型。 访问…...

ChatGPT AIGC 制作大屏可视化分析案例
第一部分提示词prompt: 商品 价格 p1 13 p2 41 p3 42 p4 53 p5 19 p6 28 p7 92 p8 62 城市 销量 北京 69 上海 13 南京 18 武汉 66 成都 70 你现在是一名非常专业的数据分析师,请结合上述数据完成下列几件事情 1:第一部分数…...

2023年9款好用的在线流程图软件推荐!
随着互联网技术和基础设施的发展,人们能用上比过去更加稳定的网络,因此在使用各类工具软件时,越来越倾向于选择在线工具,或是推出了网页版的应用。 就流程图软件而言,过去想要绘制流程图,我们得在电脑上安…...

剑指Offer || 044.在每个树行中找最大值
题目 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 示例1: 输入: root [1,3,2,5,3,null,9] 输出: [1,3,9] 解释:1/ \3 2/ \ \ 5 3 9 示例2: 输入: root [1,2,3] 输出: [1,3] 解释:1/ \2 3示例3ÿ…...

ESP32网络开发实例-UDP数据发送与接收
UDP数据发送与接收 文章目录 UDP数据发送与接收1、UDP简单介绍2、软件准备3、硬件准备4、代码实现本文将详细介绍在Arduino开发环境中,如何实现ESP32通过UDP协议进行数据发送与接收。 1、UDP简单介绍 用户数据报协议 (UDP) 是一种跨互联网使用的通信协议,用于对时间敏感的传…...

液压自动化成套设备比例阀放大器
液压电气成套设备的比例阀放大器是一种电子控制设备,用于控制液压动力系统中的液压比例阀1。 比例阀放大器通常采用电子信号进行控制,以控制比例阀的开度和流量,以实现液压系统的可靠控制。比例阀放大器主要由以下组成部分: 驱动…...

专业144,总分440+,上岸西北工业大学827西工大信号与系统考研经验分享
我的初试备考从4月末,持续到初试前,这中间没有中断。 总的时间分配上,是数学>专业课>英语>政治,虽然大家可支配时间和基础千差万别,但是这么分配是没错的。 数学 时间安排:3月-7月:…...

JQuery - template.js 完美解决动态展示轮播图,轮播图不显示问题
介绍 在JQuery中,使用template.js把轮播图的图片渲染到页面后,发现无法显示。 解决方案 首先,打开控制台发现,图片dom是生成了的,排除dom的缺失其次,换了一个插件Swiper,发现效果一样,排除插件的沦丧把动态数据换成假数据,...

CC2540和CC2541的区别简单解析
CC2541理论上是CC2540的精简版,去除了USB接口,增加了1个HW1C接口。 CC2540集成了2.4GHz射频收发器,是一款完全兼容8051内核的无线射频单片机,它与蓝牙低功耗协议栈共同构成高性价比、低功耗的片上系统(SOC)…...
-- Stream的collect()与Collectors的联合运用)
Java8 新特性之Stream(八)-- Stream的collect()与Collectors的联合运用
目录 1. collect()的 收集 作用 2. collect()的 统计 作用 3. collect()的 分组 作用 4. collect()的 拼接 作用...
SpringBoot基础详解
目录 SpringBoot自动配置 基于条件的自动配置 调整自动配置的顺序 纷杂的SpringBoot Starter 手写简单spring-boot-starter示例 SpringBoot自动配置 用一句话说自动配置:EnableAutoConfiguration借助SpringFactoriesLoader将标准了Configuration的JavaConfig类…...

原创丨全球主流开源模型及其衍生生态解析
作者:李媛媛 本文约4800字,建议阅读15分钟本文介绍了全球主流开源基座模型及衍生模型的特点、应用与趋势。在人工智能技术产业化落地加速的当下,开源模型已成为推动行业创新的核心力量,其开放、可定制的特性打破了技术壁垒&#x…...

STM32 FSMC/FMC接口详解:地址映射、时序配置与实战优化
1. 项目概述:深入理解STM32的FSMC/FMC接口在嵌入式开发中,尤其是涉及大屏显示、高速数据采集或复杂外部设备交互的项目里,我们常常会遇到一个绕不开的“硬骨头”——如何让STM32单片机高效、稳定地与外部并行存储器或设备通信。这时ÿ…...

通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性 在将大模型能力集成到应用或服务之前,验证 API 的连通性、密…...

为ClaudeCode配置Taotoken作为稳定可靠的API供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为稳定可靠的API供应商 Claude Code 是一款广受开发者欢迎的编程助手工具,它依赖于后端的大…...

STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程
STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程 CAN总线作为工业控制领域的经典通信协议,在STM32F4系列开发中却常因硬件设计盲区和软件配置细节导致通信失败。本文将带您穿越从原理图设计到稳定实现500Kbps通信的全流程,重点…...

英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率
英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟排位赛中因为BP阶段手忙脚乱而错失先机?是否因为不了…...

构建可进化智能体系统:从架构蓝图到工程实践
1. 项目概述与核心价值最近在开源社区里,一个名为planck-lab/hermes-evolving-agents-public-blueprint的项目引起了我的注意。这个标题乍一看有点长,但拆解一下就能发现它的分量:planck-lab是组织名,hermes是项目代号,…...

Linux内核模块开发实战:用filp_open和vfs_read实现一个简易配置文件读取器
Linux内核模块开发实战:用filp_open和vfs_read实现一个简易配置文件读取器 在Linux内核开发中,有时我们需要在内核态直接读取用户空间的配置文件。这种需求常见于需要动态加载配置的驱动程序、内核日志系统或特殊的内核服务。本文将带你从零开始构建一个…...

5个技巧掌握Obsidian Dataview:从静态笔记到动态知识库的蜕变
5个技巧掌握Obsidian Dataview:从静态笔记到动态知识库的蜕变 【免费下载链接】obsidian-dataview A data index and query language over Markdown files, for https://obsidian.md/. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-dataview Obsid…...

如何构建基于UNet的眼底血管图像分割系统
如何构建基于UNet的眼底血管图像分割系统 文章目录1. 数据预处理2. 定义UNet模型3. 训练过程4. 测试过程5. 日志记录1构建一个基于UNet的眼底血管图像分割系统涉及多个步骤,包括数据预处理、模型定义、训练过程、测试过程以及日志记录。下面是一个完整的指南&#x…...