【大数据开发技术】实验06-SequenceFile、元数据操作与MapReduce单词计数
文章目录
- SequenceFile、元数据操作与MapReduce单词计数
- 一、实验目标
- 二、实验要求
- 三、实验内容
- 四、实验步骤
- 附:系列文章
SequenceFile、元数据操作与MapReduce单词计数
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS SequenceFile读写操作
- 掌握MapReduce单词计数操作
- 熟练掌握查询文件状态信息和目录下所有文件的元数据信息的方法
二、实验要求
- 给出主要实验步骤成功的效果截图。
- 要求分别在本地和集群测试,给出测试效果截图
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件名加上学号姓名。
- 涉及的文件名、类名自拟,要求体现本人学号或姓名信息,涉及的文件内容自拟。
三、实验内容
-
SequenceFile写操作,实现效果如下图所示。


-
SequenceFile读操作,实现效果如下图所示。


-
输出一个目录下多个文件的文件状态和元数据信息。


-
使用mapreduce编程,自拟文件名和文件内容,完成对该文件的单词计数,实现效果参考下图。

四、实验步骤
1.SequenceFile写操作
程序设计
package hadoop;import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;@SuppressWarnings("unused")
public class SeqFileWrite {static Configuration conf = new Configuration();static String url = "hdfs://master:9000/seqfile.txt";static String[] data = {"a,b,c", "a,e,f", "a,j,k"};public static void main(String[] args) throws IOException{FileSystem fs = FileSystem.get(URI.create(url), conf);Path path = new Path(url);IntWritable key = new IntWritable();Text text = new Text();@SuppressWarnings("deprecation")SequenceFile.Writer w = SequenceFile.createWriter(fs, conf, path, IntWritable.class, Text.class);for(int i=0; i<10; i++){key.set(10-i);text.set(data[i%data.length]);w.append(key, text);}IOUtils.closeStream(w);}
}
程序分析
这是一个使用Hadoop的SequenceFile编写程序,它可以将数据写入到一个SeqFile中。SeqFile是Hadoop中的一种二进制文件格式,它能够高效地储存大量的键值对数据,并支持高效地随机访问。
在程序中,首先定义了一个静态的Configuration对象和一个静态的URL字符串url,用于指定数据文件的位置。然后定义了一个包含若干数据字符串的data数组。
在main()方法中,通过调用FileSystem.get()方法获取一个文件系统对象fs,并通过指定URL字符串和Configuration对象来实现。然后定义一个Path对象指定数据文件的路径。
接下来定义一个IntWritable对象key和一个Text对象text,用于储存键和值。打开文件并创建一个SequenceFile.Writer对象w,用于向SeqFile中写入数据。
通过for循环遍历数据,将数据写入到SeqFile中,并通过IOUtils.closeStream()方法关闭写入流。
总的来说,这个程序是一个简单的SeqFile写入例子,它可以帮助初学者了解SeqFile的使用方法。
运行结果

2.SequenceFile读操作
程序设计
package hadoop;import java.io.*;
import java.net.URI;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;public class SeqFileRead {static Configuration conf = new Configuration();static String url = "hdfs://master:9000/seqfile.txt";public static void main(String[] args) throws IOException{FileSystem fs = FileSystem.get(URI.create(url), conf);Path path = new Path(url);@SuppressWarnings("deprecation")SequenceFile.Reader r = new SequenceFile.Reader(fs, path, conf);Writable keyclass = (Writable)ReflectionUtils.newInstance(r.getKeyClass(), conf);Writable valueclass = (Writable)ReflectionUtils.newInstance(r.getValueClass(), conf);while(r.next(keyclass, valueclass)){System.out.println("key:" + keyclass);System.out.println("valueL:" + valueclass);System.out.println("position:" + r.getPosition());}IOUtils.closeStream(r);}
}
程序分析
这是一个使用Hadoop的SequenceFile读取程序,它可以从指定的SeqFile中读取数据并输出到控制台上。
在程序中,首先定义了一个静态的Configuration对象和一个静态的URL字符串url,用于指定数据文件的位置。
在main()方法中,通过调用FileSystem.get()方法获取一个文件系统对象fs,并通过指定URL字符串和Configuration对象来实现。然后定义一个Path对象指定数据文件的路径。
接下来打开文件并创建一个SequenceFile.Reader对象r,用于从SeqFile中读取数据。通过ReflectionUtils.newInstance()方法动态生成Writable类型的对象实例。然后在while循环中,通过r.next()方法读取下一个键值对,并输出到控制台上。
最后通过IOUtils.closeStream()方法关闭读取流。
总的来说,这个程序是一个简单的SeqFile读取例子,它可以帮助初学者了解SeqFile的读取方法和Writable对象的动态生成方法。
运行结果

3.读取文件元信息
程序设计
package hadoop;import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;public class FileStatus {public static void main(String[] args){Configuration conf = new Configuration();conf.set("fs.DefailtFS", "hdfs://master:9000/");FileSystem fs = null;Path path[] = new Path[args.length];for(int i=0; i<path.length; i++){path[i] = new Path(args[i]);}try{fs = FileSystem.get(URI.create(args[0]), conf);org.apache.hadoop.fs.FileStatus[] filestatus = fs.listStatus(path);Path listPaths[]=FileUtil.stat2Paths(filestatus);for(Path p:listPaths){System.out.println(p);System.out.println(p.getName());String ps = p.toString();FileSystem fs2 = FileSystem.get(URI.create(ps),conf);org.apache.hadoop.fs.FileStatus[] filestatus2 = fs2.listStatus(p);for(int i=0; i<filestatus.length;i++){System.out.println(filestatus[i]);}}}catch(IOException e){e.printStackTrace();}}}
程序分析
这是一个使用Hadoop的FileStatus获取指定文件夹中的文件状态信息的程序。
在程序中,首先定义了一个Configuration对象conf,并设置default file system的URL为"hdfs://master:9000/"。然后通过FileSystem.get()方法获取一个文件系统对象fs。
在main()方法中,通过for循环依次处理传入的参数,将其转换为Path对象并存储在数组path[]中。
在try语句块中,通过fs.listStatus()方法获取指定文件夹的文件状态信息,存储在数组filestatus[]中。然后通过FileUtil.stat2Paths()方法将filestatus[]转换为Path类型的数组listPaths[]。
接下来遍历listPaths[]数组,分别输出路径和文件名,并再次调用FileSystem.get()方法获取一个新的文件系统对象fs2,用于获取指定路径下的文件状态信息。通过fs2.listStatus()方法获取指定路径下的文件状态信息,存储在数组filestatus2[]中,并将其循环输出到控制台上。
最后通过catch(IOException e)方法捕获异常并输出错误信息。
总的来说,这个程序是一个简单的使用Hadoop的FileStatus获取文件状态信息的例子,可以帮助初学者了解Hadoop中FileStatus的使用方法。
运行结果

4.单词计数
程序设计
Map类:
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.*;public class Map extends Mapper<Object, Text, Text, IntWritable>{protected void map(Object key, Text value, Context context) throws IOException, InterruptedException{String [] lines = value.toString().split(" ");for(String word : lines){context.write(new Text(word), new IntWritable(1));}}}
Reduce类:
package hadoop;
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;public class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{int sum = 0;for (IntWritable count:values){sum = sum + count.get();}context.write(key, new IntWritable(sum));}}
主函数:
package hadoop;import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.mapreduce.*;import java.io.IOException;import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;public class WordMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input current Path");System.exit(0);}Configuration conf = new Configuration();Job job = new Job(conf, WordMain.class.getSimpleName());job.setJarByClass(WordMain.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.waitForCompletion(true);}
}
运行结果
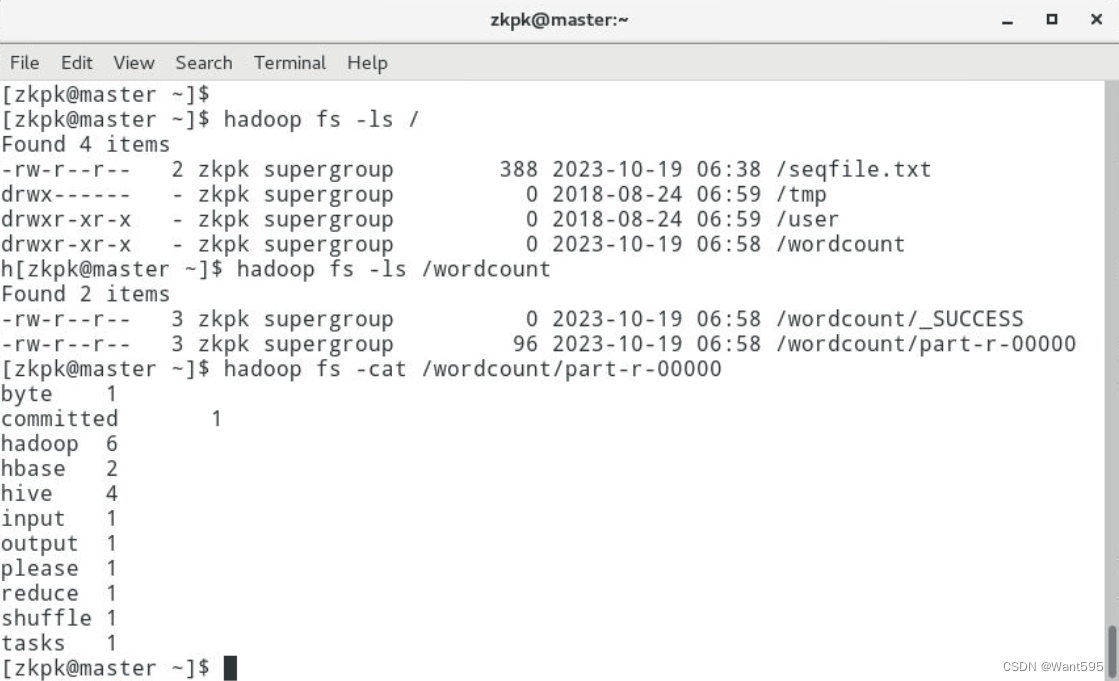
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |
相关文章:
【大数据开发技术】实验06-SequenceFile、元数据操作与MapReduce单词计数
文章目录 SequenceFile、元数据操作与MapReduce单词计数一、实验目标二、实验要求三、实验内容四、实验步骤附:系列文章 SequenceFile、元数据操作与MapReduce单词计数 一、实验目标 熟练掌握hadoop操作指令及HDFS命令行接口掌握HDFS SequenceFile读写操作掌握Map…...

【C语言】输入一个正整数,判断其是否为素数
1、素数又叫质数。素数,指的是“大于1的整数中,只能被1和这个数本身整除的数”。 2、素数也可以被等价表述成:“在正整数范围内,大于1并且只有1和自身两个约数的数”。 #include<stdio.h>int main() {int i,m;printf("…...
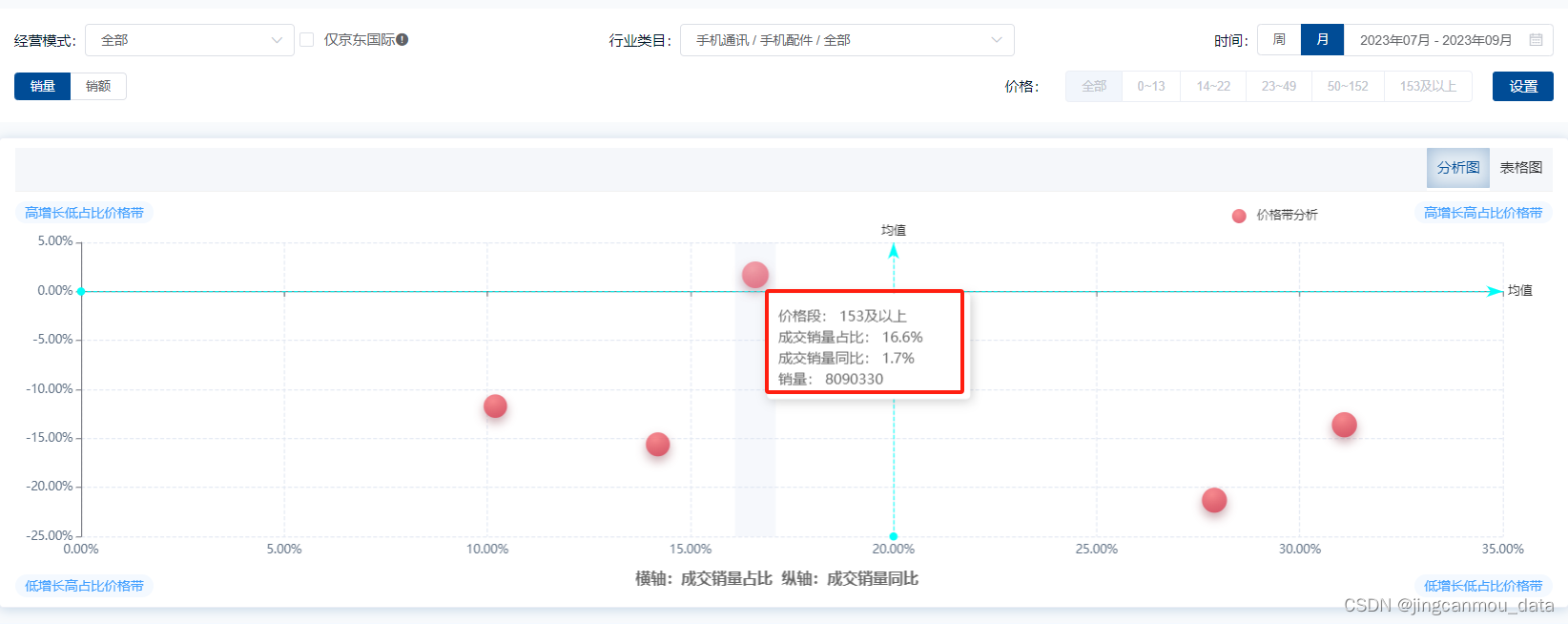
2023年Q3季度国内手机大盘销额下滑2%,TOP品牌销售数据分析
根据Canalys机构发布的最新报告,2023年第三季度,全球智能手机市场出货量仅下跌1%,可以认为目前全球手机市场的下滑势头有所减缓。而国内线上市场的表现也类似。 根据鲸参谋数据显示,今年Q3京东平台手机累计销量约1100万件…...
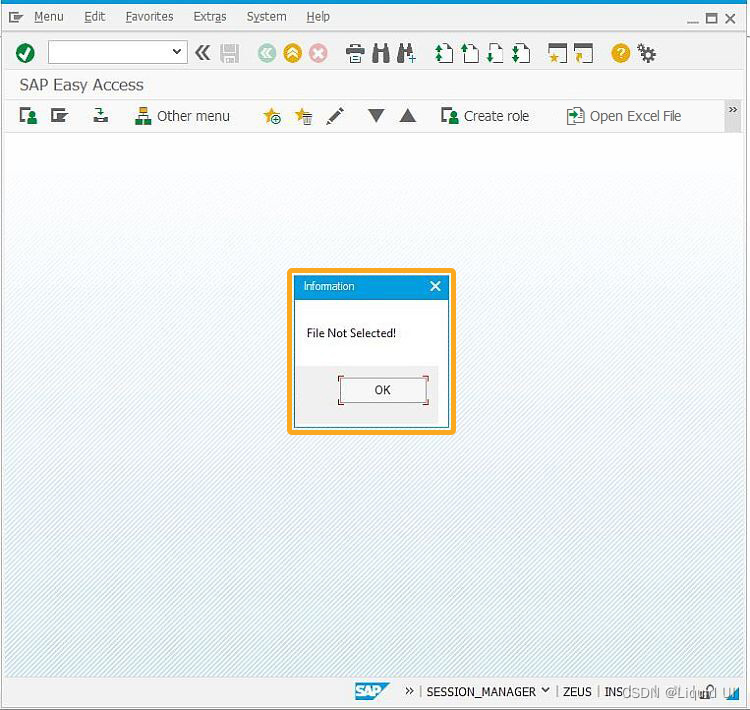
使用按钮从 SAP 系统内打开 Excel 文件
了解如何通过 SAP 屏幕上创建的按钮打开所需的 Excel 文件。为了演示这一点,将指导您完成以下步骤。 使用 del 命令删除 SAP 上不必要的元素添加一个按钮,单击后打开弹出窗口创建一个函数来选择 excel 文件创建打开所需 excel 文件的函数 定制 登录 S…...
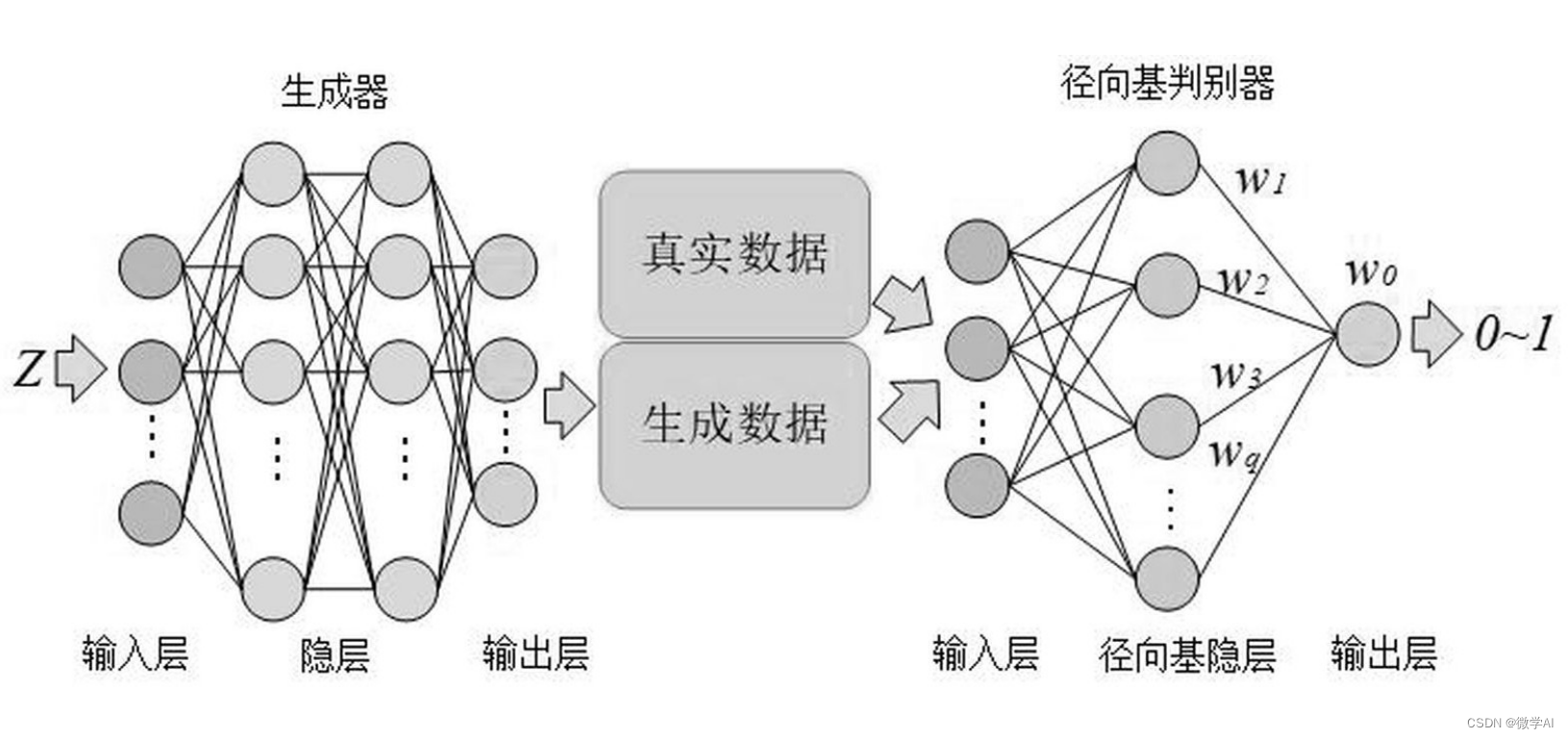
人工智能(pytorch)搭建模型20-基于pytorch搭建文本生成视频的生成对抗网络,技术创新点介绍
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型20-基于pytorch搭建文本生成视频的生成对抗网络,技术创新点介绍,随着人工智能和深度学习技术的飞速发展,文本到视频生成已经成为计算机视觉领域中一个重…...

C/C++面试常见问题——指针和引用的区别
首先想要理解指针和引用的区别,我们要明确什么是指针,什么是引用 一,指针和引用的基本概念及特性 指针是一个特殊变量,其中存储着所指向变量的地址 指针主要有以下特性: 1. 在使用时需要*解引用 2. sizeof(指针)的…...

探索DeFi世界,MixGPT引领智能金融新时代
随着区块链技术的迅猛发展,DeFi(去中心化金融)正成为金融领域的新宠。在这个充满活力的领域里,MixTrust站在创新的前沿,推出了一款引领智能金融新时代的核心技术——MixGPT。 MixGPT:引领智能金融体验的大型…...
留学教育咨询机构如何通过软文强势突围
近年来留学市场逐渐回暖,但是行业竞争也更加激烈,留学教育咨询机构想要在激烈的市场竞争中强势突围,除了优秀的职业素养,专业的服务态度外,还需要具备品牌形象打造和推广的能力,也有不少留学机构找盒子进行…...
苹果平板可以用别的电容笔吗?电容笔和Apple pencil区别
和苹果原装的Pencil相比,这种平替的电容笔并没具备重力压感,只有一种倾斜的压感功能。如果你不经常用来作画,一支普通的电容笔就足够了。不管是用来记笔记,还是用来解决一些数学问题,都能用得上。再说了,即…...

【Matlab笔记_16】yyyy-MM-dd HH:mm:ss的datetime格式拆分为yyyy-MM-dd日期部分和HH:mm:ss时间部分
实例:需要拆分的时间为’2002-04-17 11:00:00’ 1拆分出 ‘2002-04-17’ % 假设datetime对象是 dt,例如: dt datetime(2002-04-17 11:00:00);% 使用dateshift提取日期部分 dateOnly dateshift(dt, start, day);% 显示提取的日期部分 disp…...
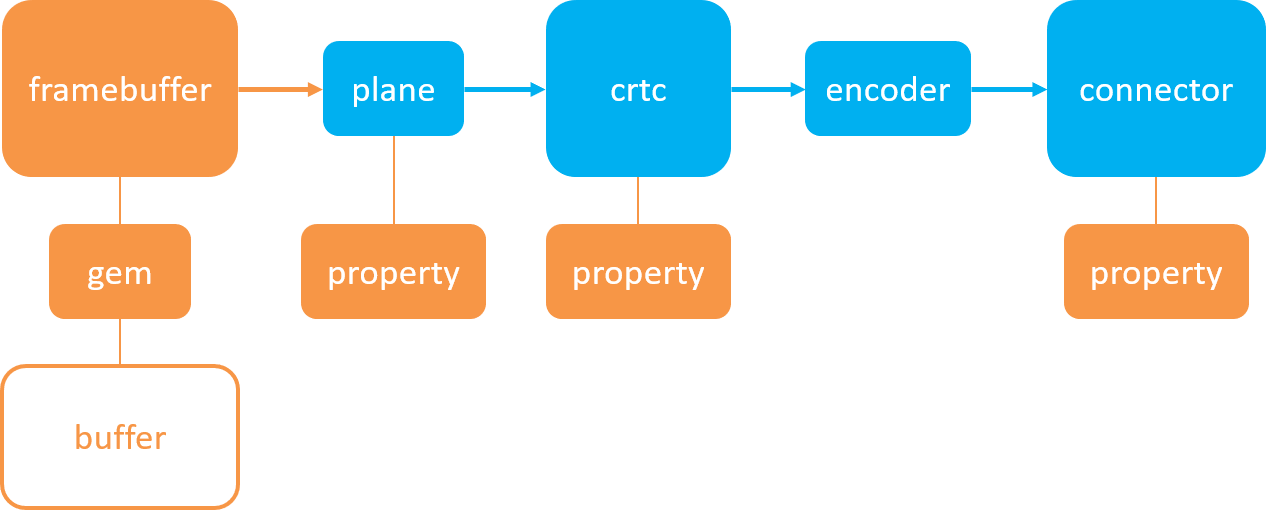
Android12之DRM架构(一)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
檀香香料经营商城小程序的作用是什么
檀香香料有安神、驱蚊、清香等作用,办公室或家庭打坐等场景,都有较高的使用频率,不同香料也有不同效果,高品质香料檀香也一直受不少消费者欢迎。 线下流量匮乏,又难以实现全消费路径完善,线上是商家增长必…...

RPA在票据处理中的应用
随着大中型企业的数字化转型进程加速,企业财务方面每天都存在大量票据需要处理,包括发票、收据、报销单等。传统的票据处理流程通常繁琐、耗时且容易出错,重复且枯燥的工作消耗了财务人员宝贵的时间和精力,也增加了企业的人力成本…...
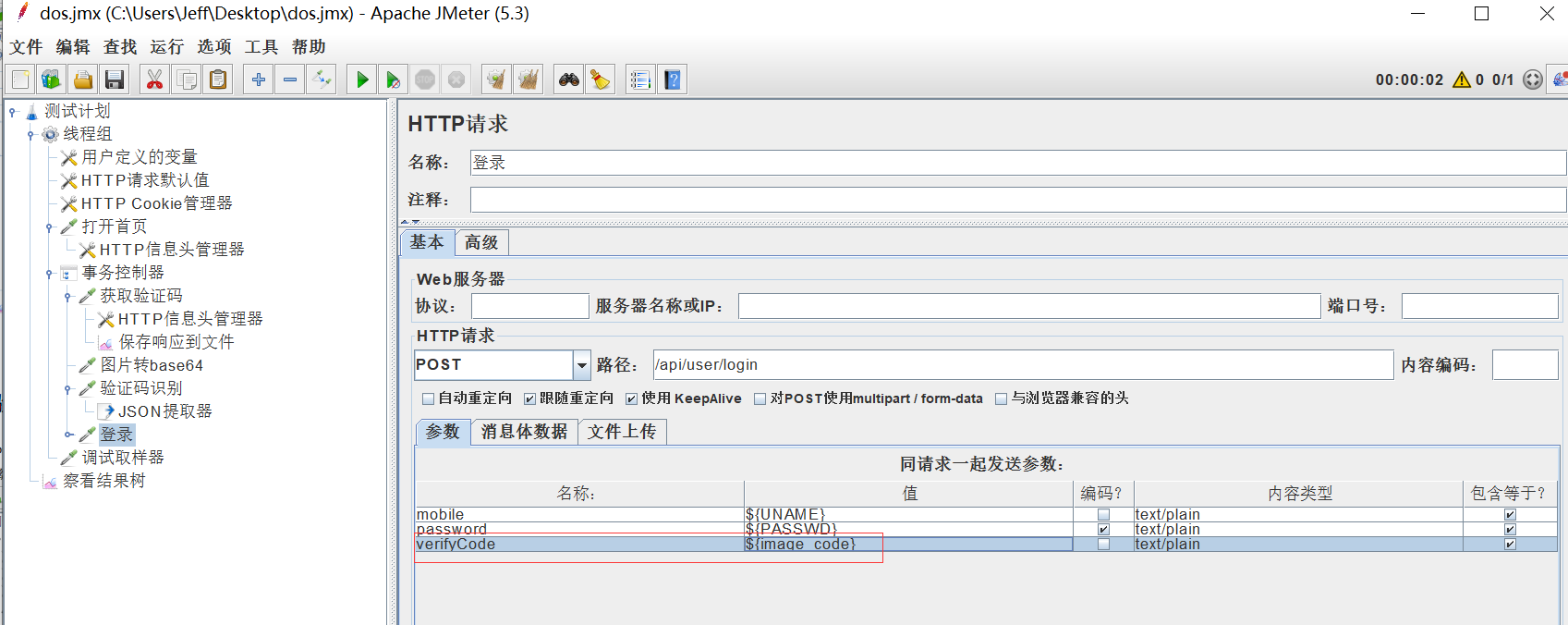
Jmeter接口测试 —— jmeter对图片验证码的处理
jmeter对图片验证码的处理 在web端的登录接口经常会有图片验证码的输入,而且每次登录时图片验证码都是随机的;当通过jmeter做接口登录的时候要对图片验证码进行识别出图片中的字段,然后再登录接口中使用; 通过jmeter对图片验证码…...
minikube创建一个pod并暴露端口(使用docker驱动安装)
因为minikube使用service暴露端口是使用nodeIP:nodePort 而不是 localhost:nodePort 公开访问。我们只能使用kubectl的端口转发功能或者使用iptables的转发功能来实现外网服务暴露。 我这里使用shiro来举例 apiVersion: apps/v1 kind: Deployment metadata:name: shiro550 spe…...

2023国考证件照要求什么底色?证件照换背景底色的方法
2023年国家公务员考试报名已经开始了,我们在考试平台提交报名信息的时候,有一项就是需要上传证件照片,对于证件照片也会有具体的要求,比如背景底色、尺寸大小、dpi和kb大小。今天就为大家详细介绍一下关于国考证件照背景色的内容&…...
】87 - SA8295P HQNX + Android 编译环境搭建指导)
【SA8295P 源码分析 (一)】87 - SA8295P HQNX + Android 编译环境搭建指导
【SA8295P 源码分析 一】87 - SA8295P HQNX + Android 编译环境搭建指导 一、Android 编译环境搭建:Android + sa8295p-hqx-4-2-4-0_hlos_dev_la.tar.gz1.1 更新 Ubuntu 18.04 源路径1.2 安装基础编译环境1.3 设置JDK8 的环境变量1.4 配置sh为bash(默认为dash)1.5 Android 编…...

网络基本结构及数据传输方式
nternet 网络基本结构及数据传输方式根据传统的网络结构,用户的访问流程基本如下: 用户在自己的浏览器中输入要访问的网站的域名 浏览器向本地DNS请求对该域名的解析 本地DNS将请求发到网站授权的DNS服务器。 授权DNS将服务器的IP地址作为解析结果送给本…...

从实体经济和数字经济融合展开,思考商业模式的变化
对于《关于构建数据基础制度更好发挥数据要素作用的意见》想必大家已经不陌生了,之前的文章中也围绕数据要素说了很多东西,数据、数字化、数字经济之类的已经称得上是绝大部分人对未来发展方向的共识,不过今天想从这个《意见》出发࿰…...
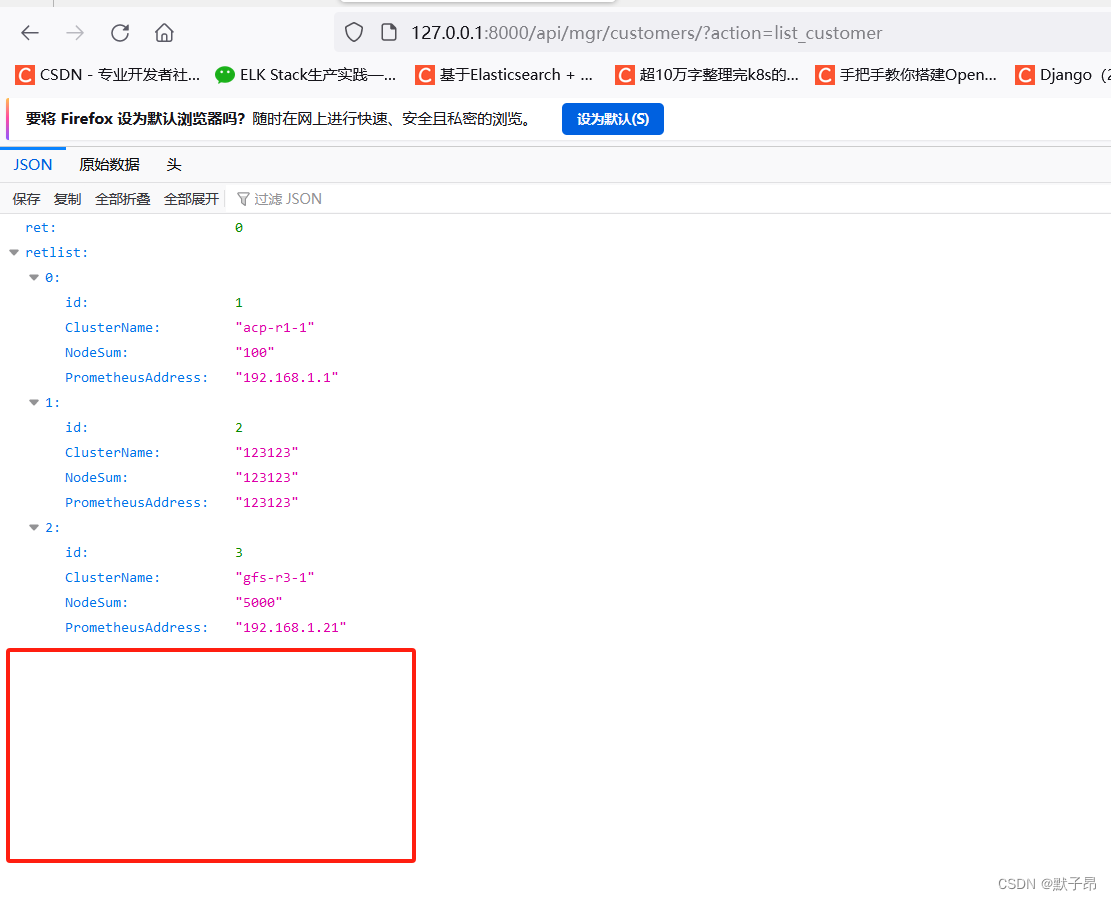
Python 框架学习 Django篇 (四) 数据库增删改查(CURD)
在上一章结尾我们了解到如采用前后端开发分离的架构模式开发,后端几乎不负责任何展现界面的工作,只负责对数据进行管理 ,对数据的管理主要体现在: (增加、修改、删除、列出 )具体的接口参考大佬的文档BYSM…...

用于预测肿瘤突变负荷及胃癌免疫治疗相关通路分析的生物知情图神经网络
论文总结1、有开源代码,本研究生成的数据和源代码存放在GitHub [https://github.com/liuchuwei/PGLCN]中,GitHub 使用Python和Pytorch实现。2、对比方法仅和传统的机器学习方法进行对比3、使用GNNExplainer进行生物学解释,整合TCGA中33种癌症…...

2026年全场景适配最值得关注的五大能源管理系统
各位读者,大家好!在全球能源结构加速转型的当下,能源管理系统的发展至关重要。今天我要为大家介绍2026年全场景适配最值得关注的五大能源管理系统。这些系统对于企业提升能源管理的精细化、智能化水平,增强核心竞争力有着重要意义…...

OpenClaw+Phi-3-mini-128k-instruct:技术书籍翻译与术语统一系统
OpenClawPhi-3-mini-128k-instruct:技术书籍翻译与术语统一系统 1. 为什么需要自动化翻译工具 作为一名技术书籍的爱好者,我经常需要阅读英文原版的技术文档和书籍。但直接阅读英文原版对很多人来说存在门槛,而现有的机器翻译工具在技术术语…...
性能优化—基于STM32cubeMX HAL库的实战技巧)
STM32F429DISC开发板SDRAM(IS42S16400J)性能优化—基于STM32cubeMX HAL库的实战技巧
1. 认识STM32F429DISC开发板与SDRAM 刚拿到STM32F429DISC开发板时,我第一眼就被板载的那颗IS42S16400J SDRAM芯片吸引了。这块8MB的存储空间对于嵌入式开发来说简直是"豪华配置",但真正用起来才发现,如果不做优化,性能可…...

BaGet实战教程:如何配置和使用镜像功能加速包下载
BaGet实战教程:如何配置和使用镜像功能加速包下载 【免费下载链接】BaGet A lightweight NuGet and symbol server 项目地址: https://gitcode.com/gh_mirrors/ba/BaGet BaGet是一款轻量级的NuGet和符号服务器,通过配置其镜像功能,开发…...

musescore-downloader多语言支持解析:国际化i18n实现原理
musescore-downloader多语言支持解析:国际化i18n实现原理 【免费下载链接】musescore-downloader ⚠️ This repo has moved to https://github.com/LibreScore/dl-librescore ⚠️ | Download sheet music (MSCZ, PDF, MusicXML, MIDI, MP3, download individual p…...

Tk wasm 滑块算法分析
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向分析部分python代码cp execjs.co…...

Inspeckage实战案例:移动应用安全测试的10个关键场景
Inspeckage实战案例:移动应用安全测试的10个关键场景 【免费下载链接】Inspeckage Android Package Inspector - dynamic analysis with api hooks, start unexported activities and more. (Xposed Module) 项目地址: https://gitcode.com/gh_mirrors/in/Inspeck…...

WebDataset与机器人学:处理感知数据的高效加载方案
WebDataset与机器人学:处理感知数据的高效加载方案 【免费下载链接】webdataset A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/we/we…...

Fan Control终极指南:5大技巧实现Windows系统风扇智能控制与静音优化
Fan Control终极指南:5大技巧实现Windows系统风扇智能控制与静音优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitH…...