边写代码边学习之mlflow
1. 简介
MLflow 是一个多功能、可扩展的开源平台,用于管理整个机器学习生命周期的工作流程和工件。 它与许多流行的 ML 库内置集成,但可以与任何库、算法或部署工具一起使用。 它被设计为可扩展的,因此您可以编写插件来支持新的工作流程、库和工具。

MLflow 有五个组件:
MLflow Tracking:用于在运行机器学习代码时记录参数、代码版本、指标、模型环境依赖项和模型工件的 API。 MLflow Tracking 有一个用于查看和比较运行及其结果的 UI。 MLflow Tracking UI 中的这张图片显示了将指标(学习率和动量)与损失指标联系起来的图表:
MLflow Models::一种模型打包格式和工具套件,可让您轻松部署经过训练的模型(来自任何 ML 库),以便在 Docker、Apache Spark、Databricks、Azure ML 和 AWS SageMaker 等平台上进行批量或实时推理。 此图显示了 MLflow Tracking UI 的运行详细信息及其 MLflow 模型的视图。 您可以看到模型目录中的工件包括模型权重、描述模型环境和依赖项的文件以及用于加载模型并使用模型进行推理的示例代码:
MLflow Model Registry:集中式模型存储、API 集和 UI,专注于 MLflow 模型的批准、质量保证和部署。
MLflow Projects:一种用于打包可重用数据科学代码的标准格式,可以使用不同的参数运行来训练模型、可视化数据或执行任何其他数据科学任务。
MLflow Recipes:预定义模板,用于为各种常见任务(包括分类和回归)开发高质量模型。
2. 代码实践
2.1. 安装mlflow
pip install mlflow2.2. 启动mlflow
方式一:命令窗口 -- 只能查看本地的数据
mlflow ui方式二:启动一个server 跟踪每一次运行的数据
mlflow server用方式二的话,你要添加下面代码
mlflow.set_tracking_uri("http://192.168.0.1:5000")
mlflow.autolog() # Or other tracking functions2.3. 用方式二启动之后你发现创建了下面文件夹

2.4. 访问mlflow
localhost:5000

运行下面代码测试。加三个参数(config_value, param1和param2), 加一个metric和一个文件
log_params: 加参数
log_metric: 加metric
log_artifact : 加相关的文件
import os
from random import random, randint
from mlflow import log_metric, log_param, log_params, log_artifacts
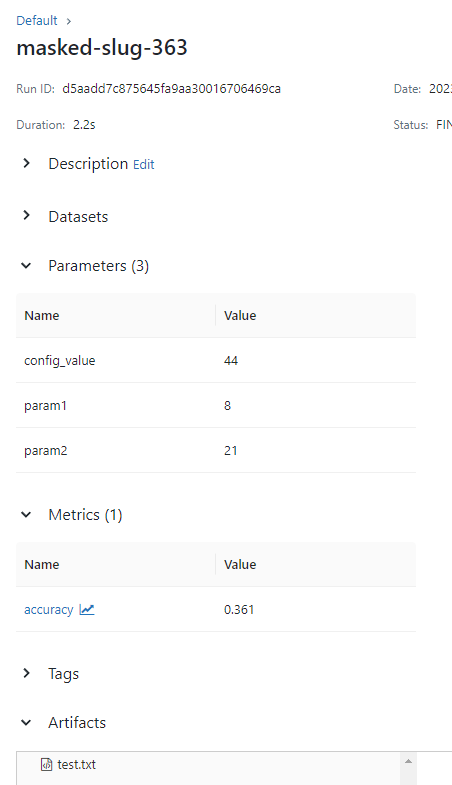
import mlflowif __name__ == "__main__":mlflow.set_tracking_uri("http://localhost:5000")# mlflow.autolog() # Or other tracking functions# Log a parameter (key-value pair)log_param("config_value", randint(0, 100))# Log a dictionary of parameterslog_params({"param1": randint(0, 100), "param2": randint(0, 100)})# Log a metric; metrics can be updated throughout the runlog_metric("accuracy", random() / 2.0)log_metric("accuracy", random() + 0.1)log_metric("accuracy", random() + 0.2)# Log an artifact (output file)if not os.path.exists("outputs"):os.makedirs("outputs")with open("outputs/test.txt", "w") as f:f.write("hello world!")log_artifacts("outputs")之后你会发现在mlflow中出现一条实验数据

点击之后,你会发现下面数据。三个参数,一个metrics数据以及一个在artifacts下的文件。
运行下面实验代码
import mlflowfrom sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressormlflow.set_tracking_uri("http://localhost:5000")
mlflow.autolog()db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)# Create and train models.
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
rf.fit(X_train, y_train)# Use the model to make predictions on the test dataset.
predictions = rf.predict(X_test)
之后你会发现mlflow server 里出现了例外一条实验数据
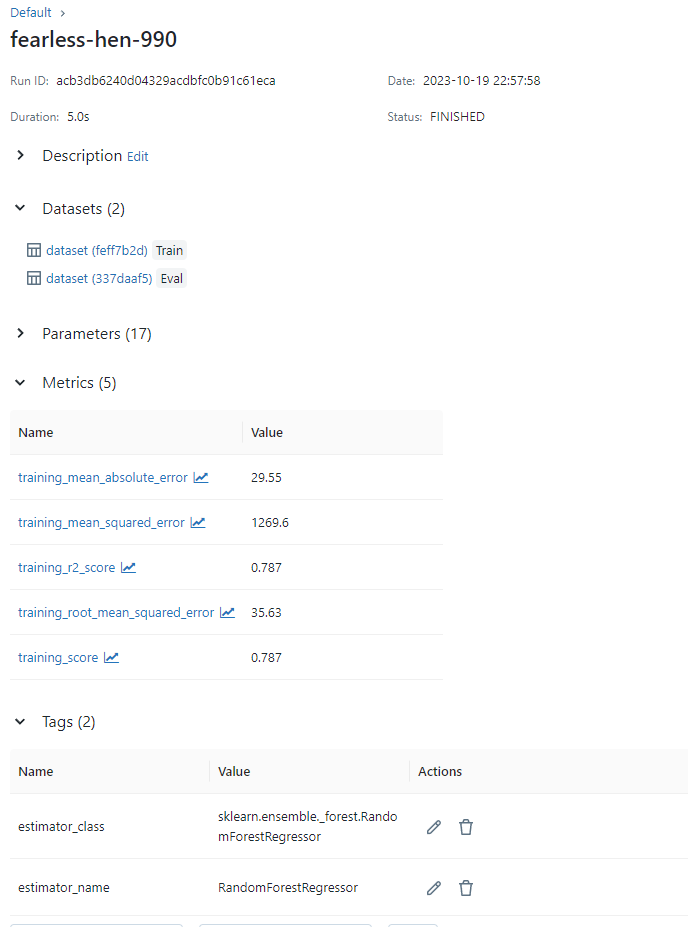
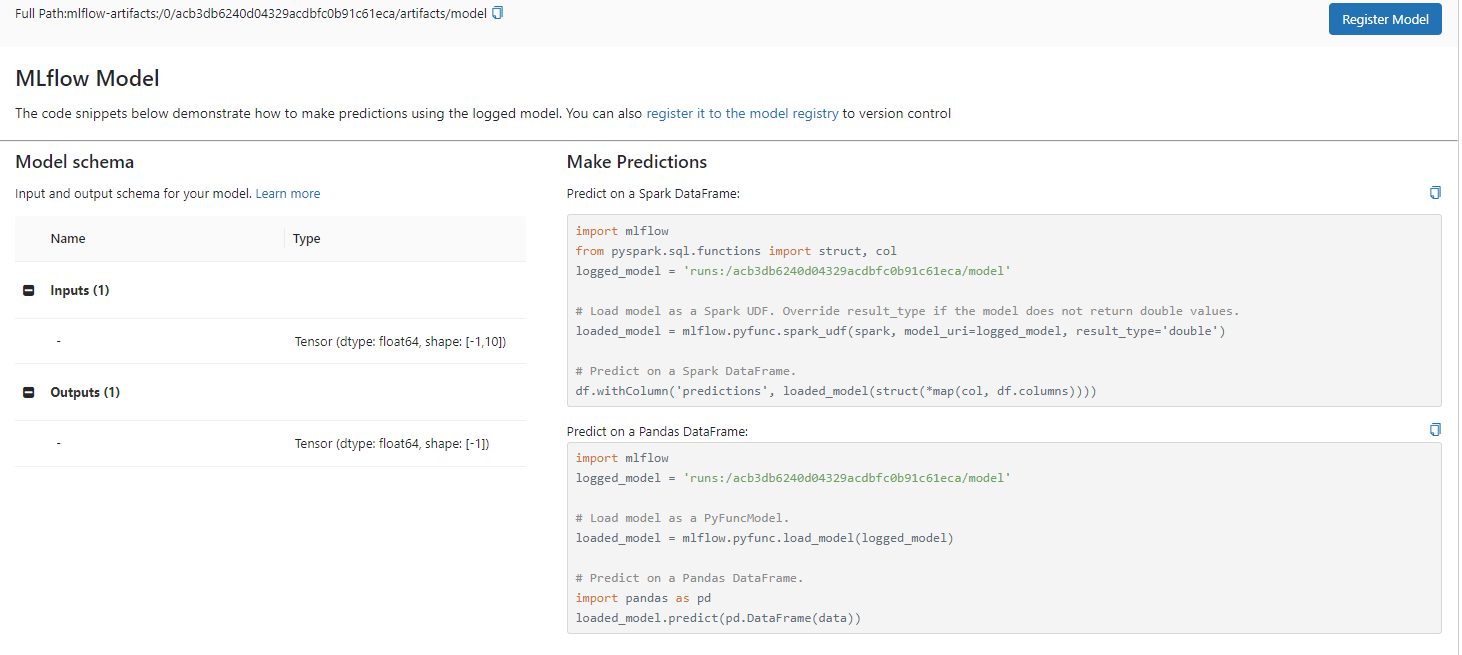
在mlflow server 取出你的模型做测试
import mlflowfrom sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
mlflow.set_tracking_uri("http://localhost:5000")db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)logged_model = 'runs:/acb3db6240d04329acdbfc0b91c61eca/model'# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model)predictions = loaded_model.predict(X_test[0:10])
print(predictions)运行结果
[117.78565758 153.06072713 89.82530357 181.60250404 221.44249587125.6076472 106.04385223 94.37692115 105.1824106 139.17538236]
参考资料
MLflow - A platform for the machine learning lifecycle | MLflow
相关文章:
边写代码边学习之mlflow
1. 简介 MLflow 是一个多功能、可扩展的开源平台,用于管理整个机器学习生命周期的工作流程和工件。 它与许多流行的 ML 库内置集成,但可以与任何库、算法或部署工具一起使用。 它被设计为可扩展的,因此您可以编写插件来支持新的工作流程、库和…...

基于吉萨金字塔建造优化的BP神经网络(分类应用) - 附代码
基于吉萨金字塔建造优化的BP神经网络(分类应用) - 附代码 文章目录 基于吉萨金字塔建造优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.吉萨金字塔建造优化BP神经网络3.1 BP神经网络参数设置3.2 吉萨金字…...

axios的post请求所有传参方式
Axios支持多种方式来传递参数给POST请求。以下是一些常见的方式: 作为请求体: 你可以将参数作为请求体的一部分,通常用于发送表单数据或JSON数据。例如: const data { key1: value1, key2: value2 }; axios.post(/api/endpoint, …...
【c++】向webrtc学比较2: IsNewerSequenceNumber 用于NackTracker及测试
LatestSequenceNumber inline uint16_t LatestSequenceNumber(uint16_t sequence_number1,uint16_t sequence_number2) {return IsNewerSequenceNumber(sequence_number1, sequence_number2)? sequence_number1: sequen...

PRCV 2023:语言模型与视觉生态如何协同?合合信息瞄准“多模态”技术
近期,2023年中国模式识别与计算机视觉大会(PRCV)在厦门成功举行。大会由中国计算机学会(CCF)、中国自动化学会(CAA)、中国图象图形学学会(CSIG)和中国人工智能学会&#…...
)
深度学习硬件配置推荐(kaggle学习)
目录 1. 基础推荐2. GPU显存与内存是一个1:4的配比?3. deep learning 入门和kaggle比赛4. 有些 Kaggle 比赛数据集很大,可能需要更多的 GPU 显存,请推荐显存4. GDDR6和HBM25. HDD 或 SATA SSD 1. 基础推荐 假设您作为一个深度学习入门学者的…...
1019hw
登录窗口头文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QToolBar> #include <QMenuBar> #include <QPushButton> #include <QStatusBar> #include <QLabel> #include <QDockWidget>//浮动窗口…...

两分钟搞懂UiAutomator自动化测试框架
1. UiAutomator简介 UiAutomator是谷歌在Android4.1版本发布时推出的一款用Java编写的UI测试框架,基于Accessibility服务。其最大的特点就是可以跨进程操作,可以使用UiAutomator框架提供的一些方便的API来对安卓应用进行一系列的自动化测试操作…...
Fast DDS之Subscriber
目录 SubscriberSubscriberQosSubscriberListener创建Subscriber DataReaderSampleInfo读取数据 Subscriber扮演容器的角色,里面可以有很多DataReaders,它们使用Subscriber的同一份SubscriberQos配置。Subscriber可以承载不同Topic和数据类型的DataReade…...

测试PySpark
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...

C语言- 原子操作
基本概念 在C语言(尤其是C11标准之后)中,原子操作提供了一种机制,使得程序员可以在并发环境中,不使用互斥或其他同步原语,而直接对数据进行操作,同时确保数据的完整性和一致性。 原子变量和原子操作的核心思想是:无论什么时候,只有一个线程能够看到变量的修改操作。…...
设置hadoop+安装java环境
上一篇 http://t.csdnimg.cn/K3MFS 基本操作 接着上一篇 先导入之前导出的虚拟机 选择导出到对应的文件夹中 这里修改一下保存虚拟机的位置(当然你默认也可以) 改一个名字 新建一个share文件夹用来存放共享软件的文件夹 在虚拟机的设置中找到这个设置…...

阿里云新加坡主机服务器选择
阿里云新加坡主机有哪些选择?可以选择云服务器ECS或轻量应用服务器,都有新加坡地域可以选择,东南亚地区可以选择新加坡、韩国首尔、日本东京等地域,阿里云新加坡主机测试IP地址:161.117.118.93 可以测试下本地到新加坡…...

21天打卡掌握java基础操作
Java安装环境变量配置-day1 参考: https://www.runoob.com/w3cnote/windows10-java-setup.html 生成class文件 java21天打卡-day2 输入和输出 题目:设计一个程序,输入上次考试成绩(int)和本次考试成绩࿰…...
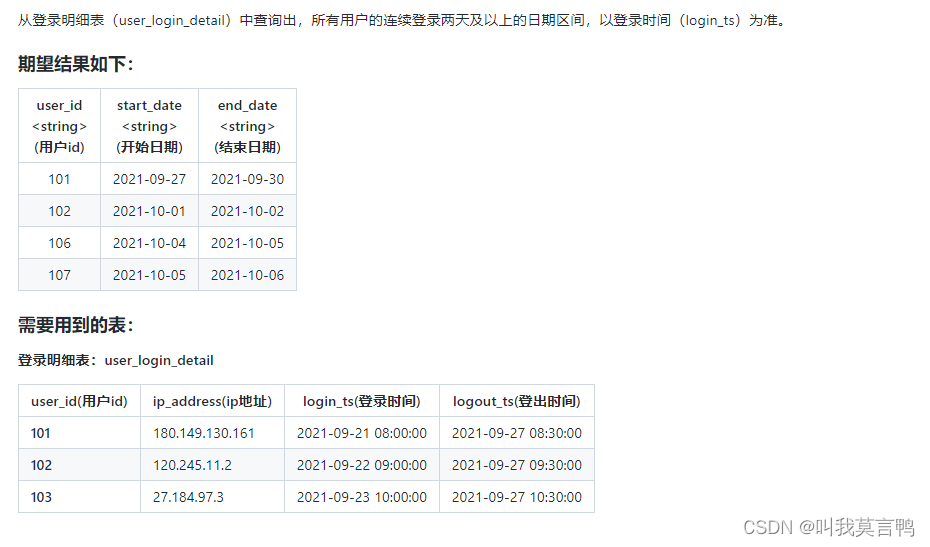
SQL题目记录
1.商品推荐题目 1.思路: 通过取差集 得出要推荐的商品差集的选取:except直接取差集 或者a left join b on where b null 2.知识点 1.except selectfriendship_info.user1_id as user_id,sku_id fromfriendship_infojoin favor_info on friendship_in…...
Linux程序调试器——gdb的使用
gdb的概述 GDB 全称“GNU symbolic debugger”,从名称上不难看出,它诞生于 GNU 计划(同时诞生的还有 GCC、Emacs 等),是 Linux 下常用的程序调试器。发展至今,GDB 已经迭代了诸多个版本,当下的…...

前端打包项目上线-nginx
第一步:下载nginx。 直接下载 nginx/Windows-1.25.2 pgp 第二步:解压zip包 第三步:打开文件夹,把http里的路径打开cmd 第四步:打开你的http-server服务,没有下载去下一次就ok了 打开后就可以访问了 第五步…...
创龙瑞芯微RK3568参数修改(调试口波特率和rootfs文件)
前言 前面写了基本的文件编译、系统编译和系统烧写,差不多前期工作就准备的差不多了。目前的东西能解决大部分入门级的需求。当然如果需要开发的话,还需要修改其他东西,下面一步一步的给小伙伴介绍关键参数怎么修改。 给定波特率 拿到开发板…...
VMware——VMware17安装WindowServer2012R2环境(图解版)
目录 一、WindowServer2012R2镜像百度云下载二、安装 一、WindowServer2012R2镜像百度云下载 下载链接:https://pan.baidu.com/s/1TWnSRJTk0ruGNn4YinzIgA 提取码:e7u0 二、安装 打开虚拟机,点击【创建新的虚拟机】,如下图&…...
ModuleNotFoundError: No module named ‘torch‘
目录 情况1,真的没有安装pytorch情况2(安装了与CUDA不对应的pytorch版本导致无法识别出torch) 情况1,真的没有安装pytorch 虚拟环境里面真的是没有torch,这种情况就easy job了,点击此链接直接安装与CUDA对应的pytorch版本,CTRLF直接搜索对应CUDA版本即可查找到对应的命令.按图…...

如何成为一名出色的SEO优化师
如何成为一名出色的SEO优化师 在当今的数字化时代,搜索引擎优化(SEO)已经成为了每个企业和个人网站获得流量和提升品牌知名度的关键手段。但是,成为一名出色的SEO优化师并非易事,需要掌握一系列专业知识和技能。本文将…...

golang.org/x/net WebSocket开发完全手册:实现实时双向通信
golang.org/x/net WebSocket开发完全手册:实现实时双向通信 【免费下载链接】net [mirror] Go supplementary network libraries 项目地址: https://gitcode.com/gh_mirrors/ne/net 在现代Web应用开发中,实时双向通信已成为提升用户体验的关键技术…...

Linux who命令实现:文件读写与系统编程实践
1. 从零实现Linux who命令:深入理解文件读写与系统编程作为一个常年与Linux打交道的开发者,我始终认为理解系统命令的实现原理是提升编程能力的最佳途径。今天我们就来解剖who这个看似简单却内涵丰富的命令,通过亲手实现它来掌握Linux文件操作…...

引爆企业降本增效的AI革命!生成式AI应用专家亲授,从字节跳动到华为的数字化转型实战秘籍!
本文介绍了资深AI专家Mr. Li在生成式AI应用与数字化转型领域的丰富经验,涵盖其在华为、字节跳动等企业的实践经历,以及在多个国家级标准制定和央企数字化转型项目中的参与。Mr. Li提供了一系列关于生成式AI和企业数字化转型的精品课程,旨在帮…...

并联混合动力船舶能量管理策略与SOC约束优化研究
并联混合动力船舶能量管理策略与SOC约束优化研究 摘要 本文针对并联混合动力船舶能量管理问题,基于等效燃油消耗最小化策略(ECMS),构建了包含柴油机、电动机、电池及船舶动力学系统的仿真模型。通过调整电池荷电状态(SOC)约束范围,分析其对燃油经济性、电池寿命及系统…...

爱诗科技发布PixVerse R1,革新AI视频创作
4月2日,爱诗科技在闪电发布周推出全球首个通用实时世界模型——PixVerse R1,标志AI视频创作转向实时交互。上线后吸引众多创作者,还带来两项功能升级。模型发布意义重大爱诗科技此次推出的PixVerse R1,让AI视频创作从传统“一次性…...

打破设备壁垒:VR-Reversal实现3D内容自由视角全设备适配
打破设备壁垒:VR-Reversal实现3D内容自由视角全设备适配 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_…...
)
CSS动画实战:5分钟搞定微信语音发送震动效果(附完整代码)
CSS动画实战:5分钟实现语音波形震动效果 最近在做一个社交类项目时,产品经理突然提出要在语音消息发送时加入波形动画效果,要求"要有微信那种专业感"。作为前端开发者,我第一反应就是:这得用Canvas吧&#x…...

利用快马ai快速原型开发openclaw类网页数据抓取chrome插件
利用AI快速原型开发OpenClaw类网页数据抓取Chrome插件 最近在做一个数据采集的小项目,需要从电商网站抓取商品信息。传统做法要手动写各种XPath和CSS选择器,费时费力。后来发现用InsCode(快马)平台的AI辅助开发,可以快速实现一个类似OpenCla…...

ABB机器人X6-WAN口多协议共存实战:NFS、Socket、RobotStudio与Profinet如何和谐共处?
ABB机器人X6-WAN口多协议共存实战:NFS、Socket、RobotStudio与Profinet如何和谐共处? 在工业自动化领域,ABB机器人系统的网络配置一直是工程师们关注的焦点。特别是当我们需要在单个X6-WAN口上同时运行NFS文件传输、Socket通信、RobotStudio远…...