2.2 如何使用FlinkSQL读取写入到文件系统(HDFS\Local\Hive)
目录
1、文件系统 SQL 连接器
2、如何指定文件系统类型
3、如何指定文件格式
4、读取文件系统
4.1 开启 目录监控
4.2 可用的 Metadata
5、写出文件系统
5.1 创建分区表
5.2 滚动策略、文件合并、分区提交
5.3 指定 Sink Parallelism
6、示例_通过FlinkSQL读取kafka在写入hive表
6.1、创建 kafka source表用于读取kafka
6.2、创建 hdfs sink表用于写出到hdfs
6.3、insert into 写入到 hdfs_sink_table
6.4、查询 hdfs_sink_table
6.5、创建hive表,指定local
1、文件系统 SQL 连接器
文件系统连接器允许从本地或分布式文件系统进行读写数据
官网链接:文件系统 SQL 连接器

2、如何指定文件系统类型
创建表时通过 'path' = '协议名称:///path' 来指定 文件系统类型
参考官网:文件系统类型
CREATE TABLE filesystem_table (id INT,name STRING,ds STRING
) partitioned by (ds) WITH ('connector' = 'filesystem',-- 本地文件系统'path' = 'file:///URI',-- HDFS文件系统'path' = 'hdfs://URI',-- 阿里云对象存储 'path' = 'oss://URI','format' = 'json'
);3、如何指定文件格式
FlinkSQL 文件系统连接器支持多种format,来读取和写入文件
比如当读取的source格式为 csv、json、Parquet... 可以在建表是指定相应的格式类型
来对数据进行解析后映射到表中的字段中

CREATE TABLE filesystem_table_file_format (id INT,name STRING,ds STRING
) partitioned by (ds) WITH ('connector' = 'filesystem',-- 指定文件格式类型'format' = 'json|csv|orc|raw'
);4、读取文件系统
FlinkSQL可以将单个文件或整个目录的数据读取到单个表中
注意:
1、当读取目录时,对目录中的文件进行 无序的读取
2、默认情况下,读取文件时为批处理模式,只会扫描配置路径一遍后就会停止
当开启目录监控(source.monitor-interval)时,才是流处理模式
4.1 开启 目录监控
通过设置 source.monitor-interval 属性来开启目录监控,以便在新文件出现时继续扫描
注意:
只会对指定目录内新增文件进行读取,不会读取更新后的旧文件
-- 目录监控
drop table filesystem_source_table;
CREATE TABLE filesystem_source_table (id INT,name STRING,`file.name` STRING NOT NULL METADATA
) WITH ('connector' = 'filesystem','path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1016','format' = 'json','source.monitor-interval' = '3' -- 开启目录监控,设置监控时间间隔
);-- 持续读取
select * from filesystem_source_table;
4.2 可用的 Metadata
使用FLinkSQL读取文件系统中的数据时,支持对 metadata 进行读取
注意: 所有 metadata 都是只读的
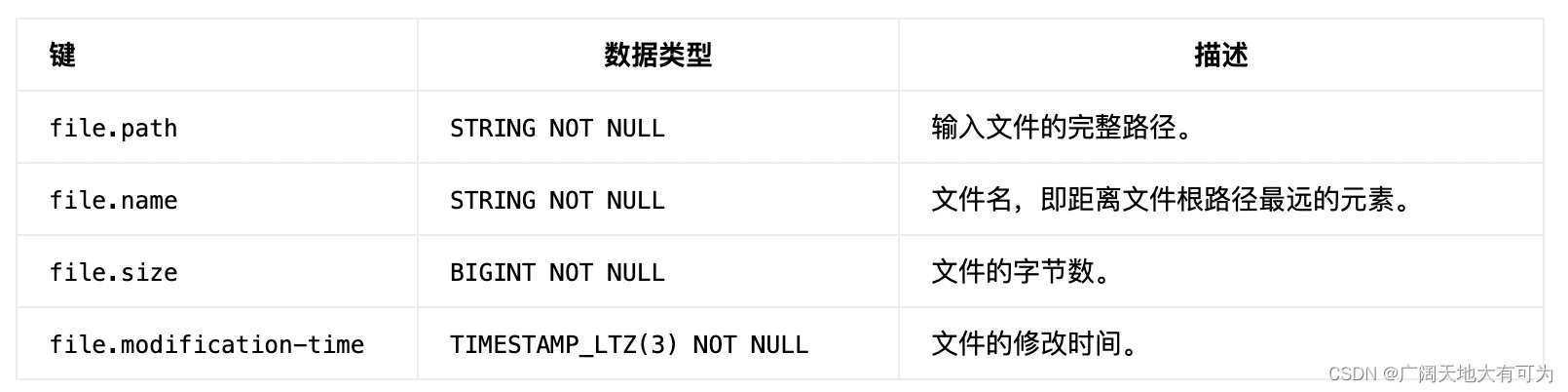
-- 可用的Metadata
drop table filesystem_source_table_read_metadata;
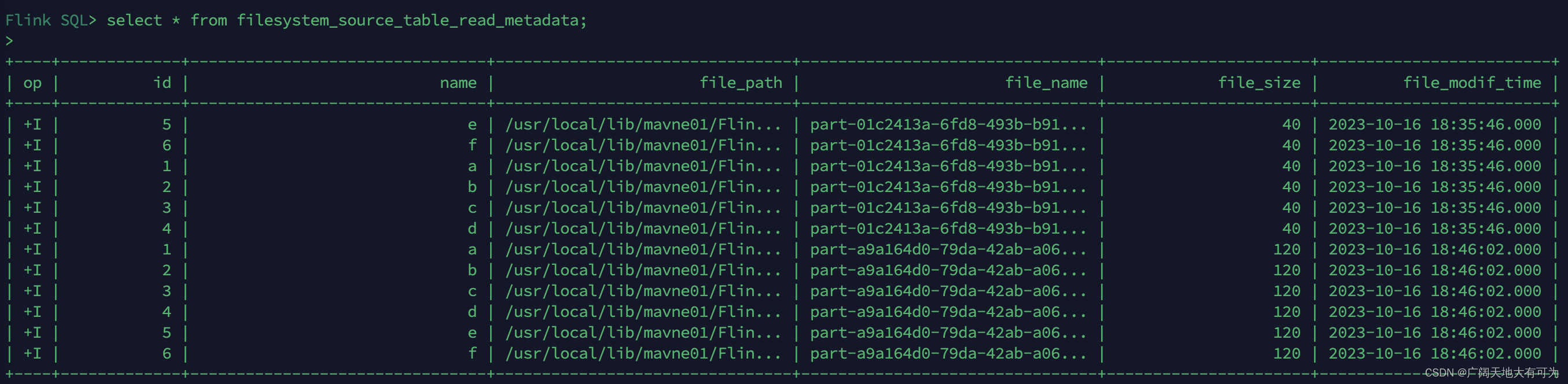
CREATE TABLE filesystem_source_table_read_metadata (id INT,name STRING,`file.path` STRING NOT NULL METADATA,`file.name` STRING NOT NULL METADATA,`file.size` BIGINT NOT NULL METADATA,`file.modification-time` TIMESTAMP_LTZ(3) NOT NULL METADATA
) WITH ('connector' = 'filesystem','path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1012','format' = 'json'
);select * from filesystem_source_table_read_metadata;运行结果:
5、写出文件系统
5.1 创建分区表
FlinkSQL支持创建分区表,并且通过 insert into(追加) 和 insert overwrite(覆盖) 写入数据
-- 创建分区表
drop table filesystem_source_table_partition;
CREATE TABLE filesystem_source_table_partition (id INT,name STRING,ds STRING
) partitioned by (ds) WITH ('connector' = 'filesystem','path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1012','partition.default-name' = 'default_partition','format' = 'json'
);-- 动态分区写入
insert into filesystem_source_table_partition
SELECT * FROM (VALUES(1,'a','20231010')
, (2,'b','20231010')
, (3,'c','20231011')
, (4,'d','20231011')
, (5,'e','20231012')
, (6,'f','20231012')
) AS user1 (id,name,ds);-- 静态分区写入
insert into filesystem_source_table_partition partition(ds = '20231010')
SELECT * FROM (VALUES(1,'a')
, (2,'b')
, (3,'c')
, (4,'d')
, (5,'e')
, (6,'f')
) AS user1 (id,name);-- 查询分区表数据
select * from filesystem_source_table_partition where ds = '20231010';5.2 滚动策略、文件合并、分区提交
可以看之前的博客:flink写入文件时分桶策略
官网链接:官网分桶策略
5.3 指定 Sink Parallelism
当使用FlinkSQL写出到文件系统时,可以通过 sink.parallelism 设置sink算子的并行度
注意:当且仅当上游的 changelog 模式为 INSERT-ONLY 时,才支持配置 sink parallelism。否则,程序将会抛出异常
CREATE TABLE hdfs_sink_table (`log` STRING,`dt` STRING, -- 分区字段,天`hour` STRING -- 分区字段,小时
) partitioned by (dt,`hour`) WITH ('connector' = 'filesystem','path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka','sink.parallelism' = '2', -- 指定sink算子并行度'format' = 'raw'
);6、示例_通过FlinkSQL读取kafka在写入hive表
需求:
使用FlinkSQL将kafka数据写入到hdfs指定目录中
根据kafka的timestamp进行分区(按小时分区)
6.1、创建 kafka source表用于读取kafka
-- TODO 创建读取kafka表时,同时读取kafka元数据字段
drop table kafka_source_table;
CREATE TABLE kafka_source_table(`log` STRING,`timestamp` TIMESTAMP(3) METADATA FROM 'timestamp' -- 消息的时间戳
) WITH ('connector' = 'kafka','topic' = '20231017','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','format' = 'raw'
);6.2、创建 hdfs sink表用于写出到hdfs
drop table hdfs_sink_table;
CREATE TABLE hdfs_sink_table (`log` STRING,`dt` STRING, -- 分区字段,天`hour` STRING -- 分区字段,小时
) partitioned by (dt,`hour`) WITH ('connector' = 'filesystem','path' = 'hdfs://usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka','sink.parallelism' = '2', -- 指定sink算子并行度'format' = 'raw'
);6.3、insert into 写入到 hdfs_sink_table
-- 流式 sql,插入文件系统表
insert into hdfs_sink_table
select log,DATE_FORMAT(`timestamp`,'yyyyMMdd') as dt,DATE_FORMAT(`timestamp`,'HH') as `hour`
from kafka_source_table;6.4、查询 hdfs_sink_table
-- 批式 sql,使用分区修剪进行选择
select * from hdfs_sink_table;6.5、创建hive表,指定local
create table `kafka_to_hive` (
`log` string comment '日志数据')comment '埋点日志数据' PARTITIONED BY (dt string,`hour` string)
row format delimited fields terminated by '\t' lines terminated by '\n' stored as orc
LOCATION 'hdfs://usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka';相关文章:
2.2 如何使用FlinkSQL读取写入到文件系统(HDFS\Local\Hive)
目录 1、文件系统 SQL 连接器 2、如何指定文件系统类型 3、如何指定文件格式 4、读取文件系统 4.1 开启 目录监控 4.2 可用的 Metadata 5、写出文件系统 5.1 创建分区表 5.2 滚动策略、文件合并、分区提交 5.3 指定 Sink Parallelism 6、示例_通过FlinkSQL读取kafk…...

call函数和apply函数的区别
call和apply是 JavaScript 中的两个函数方法,用于调用函数并指定函数内部的this值以及传递参数。它们的主要区别在于参数的传递方式。 call方法:call方法允许你在调用函数时,显式地指定函数内部的this值和参数列表。它的语法为: …...

JavaCV踩坑之路1——Mac上安装OpenCV
Mac无法安装opencv 更新Homebrew: 打开终端并运行以下命令来更新Homebrew: brew update 移除Taps(仓库): 可能与homebrew-services仓库有关。你可以尝试将它移除: brew untap homebrew/services重新安装OpenCV: 在移除…...
es6(三)——常用es6(函数、数组、对象的扩展)
ES6的系列文章目录 第一章 Python 机器学习入门之pandas的使用 文章目录 ES6的系列文章目录0、数值的扩展一、函数的扩展1、函数的默认值2、函数的reset参数 二、数组的扩展1. 将对象转成数组的Array.from()2. 将对象转成数组的Array.from()3. 实例方法 find(),fin…...
API网关与社保模块
API网关与社保模块 理解zuul网关的作用完成zuul网关的搭建 实现社保模块的代码开发 zuul网关 在学习完前面的知识后,微服务架构已经初具雏形。但还有一些问题:不同的微服务一般会有不同的网 络地址,客户端在访问这些微服务时必须记住几十甚至…...

linux 安装 docker
linux 安装 docker docker及版本一键安装docker(本人使用的是手动安装)Docker手动安装 docker及版本 Docker从17.03版本之后分为CE(Community Edition: 社区版)和EE(Enterprise Edition: 企业版)。相对于社区版本,企业…...

整数转罗马数字
题目: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 …...

利用爬虫采集音频信息完整代码示例
以下是一个使用WWW::RobotRules和duoip.cn/get_proxy的Perl下载器程序: #!/usr/bin/perluse strict; use warnings; use WWW::RobotRules; use LWP::UserAgent; use HTTP::Request; use HTTP::Response;# 创建一个UserAgent对象 my $ua LWP::UserAgent->new();#…...

WebSocket: 实时通信的新维度
介绍: 在现代Web应用程序中,实时通信对于提供即时更新和交互性至关重要。传统的HTTP协议虽然适合请求-响应模式,但对于需要频繁数据交换的场景并不理想。而WebSocket技术的出现填补了这个空白,为Web开发者们带来了一种高效、实时的…...
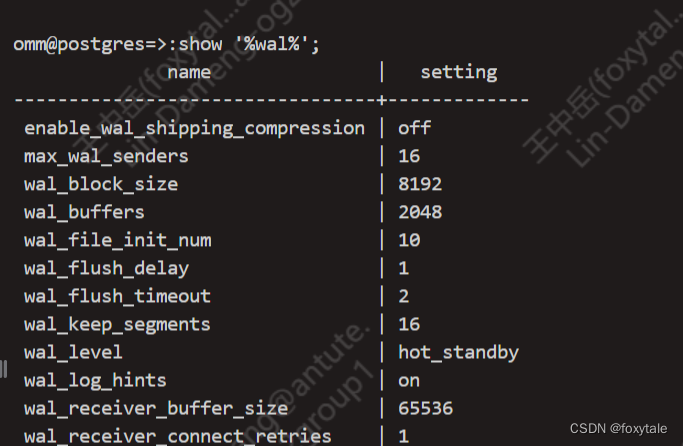
postgresql(openGauss)模糊匹配参数
被pg系这个show要求精准匹配参数恶心的不轻。 原理是用.psqlrc(openGauss用.gsqlrc)文件set一个select常量进去,需要用:调用这个常量。理论上也可以增强其他的各种功能。 我在openGauss做的一个例子 .gsqlrc(.psqlrc…...

jdk 加密 aes jar包解决
JDK1.8.0_151的无限制强度加密策略文件变动 JDK1.8.0_151无需去官网下载 local_policy.jar US_export_policy.jar这个jar包,只需要修改Java\jdk1.8.0_151\jre\lib\security这目录下的java.security文件配置即可。 随着越来越多的第三方工具只支持 JDK8,…...

C++ Primer 第十一章 关联容器 重点解读
1 map自定义排序 #include <map> #include <iostream> #include <functional> using namespace std; int main() {function<bool(pair<int, int>, pair<int, int>)> cmp [&](pair<int, int> p1, pair<int, int> p2) -&g…...

MySQL 8 - 能够成功创建其他用户但无法修改 root 用户的密码
问题: 创建其他用户就可以,为什么修改root 密码不可以? 如果能够成功创建其他用户但无法修改 root 用户的密码,这可能是因为 MySQL 8 及更高版本引入了一个名为"caching_sha2_password"的身份验证插件作为默认设置&…...

k8s kubernetes 1.23.6 + flannel公网环境安装
准备环境,必须是同一个云服务厂商,如:华为,阿里、腾讯等,不要存在跨平台安装K8S,跨平台安装需要处理网络隧道才能实现所有节点在一个网络集群中,这里推荐使用同一家云服务厂商安装即可 这里使用…...
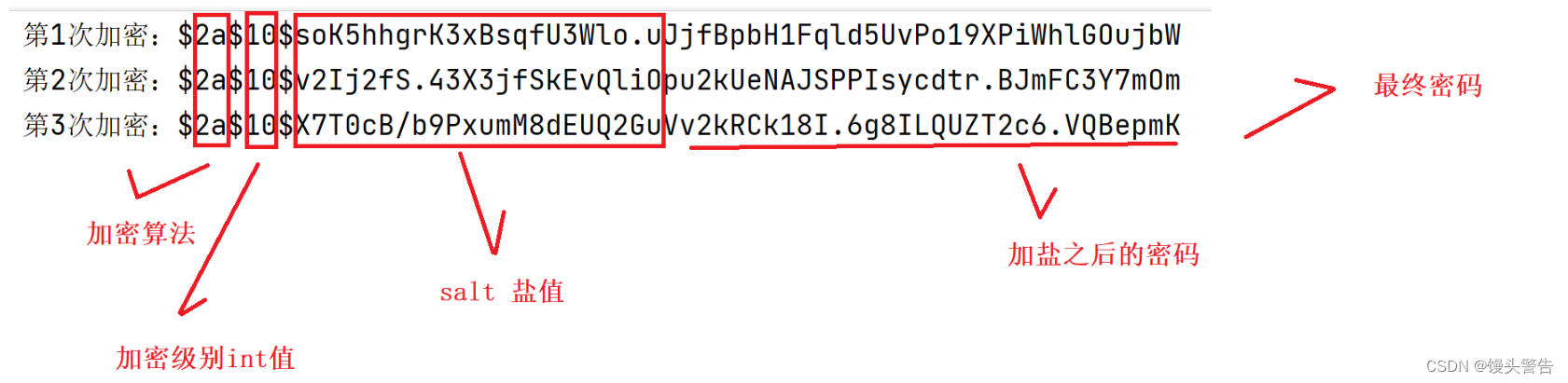
博客系统中的加盐算法
目录 一、为什么要对密码进行加盐加密? 1、明文 2、传统的 MD5 二、加盐加密 1、加盐算法实现思路 2、加盐算法解密思路 3、加盐算法代码实现 三、使用 Spring Security 加盐 1、引入 Spring Security 框架 2、排除 Spring Security 的自动加载 3、调用 S…...
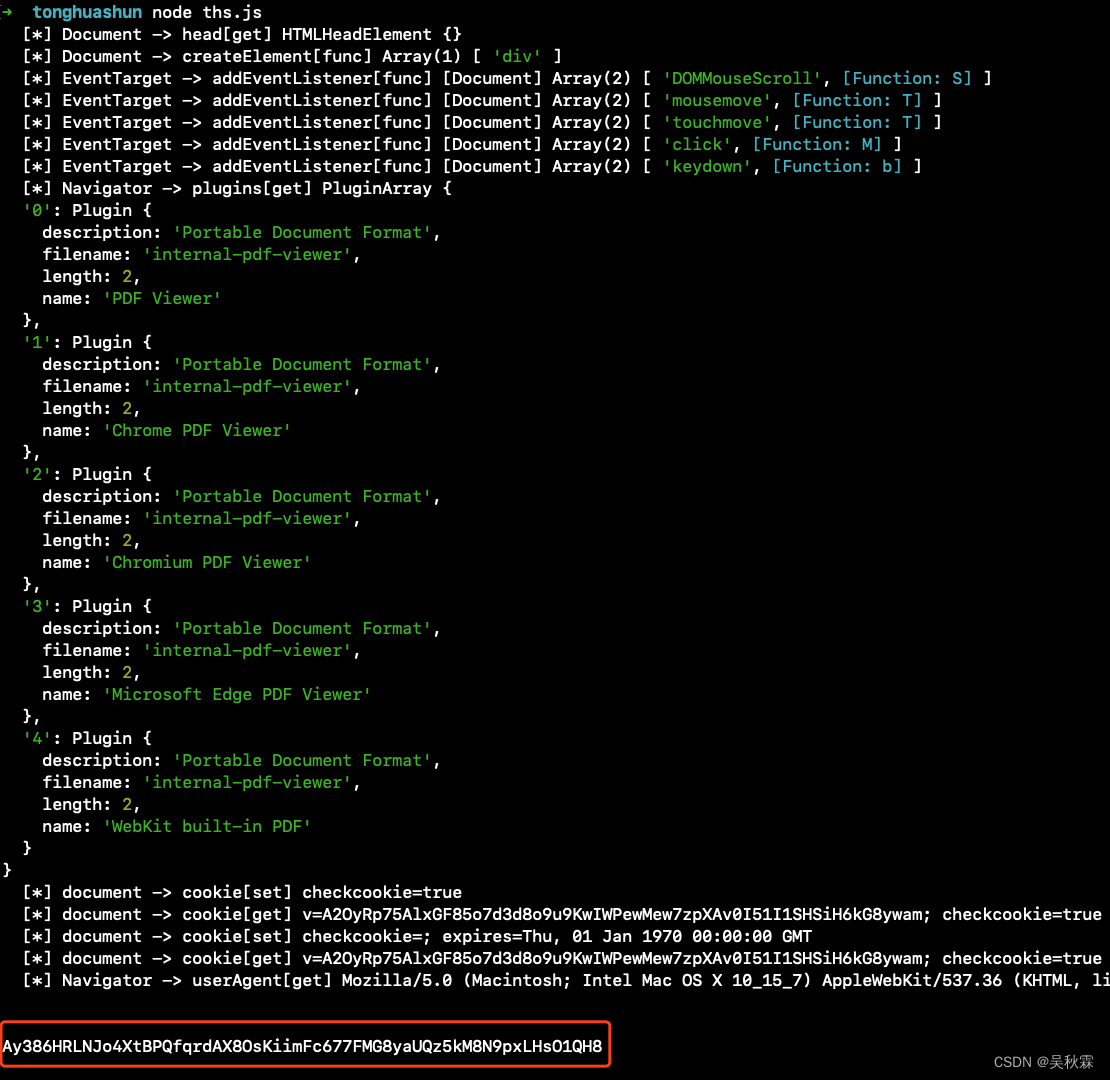
同花顺动态Cookie反爬JS逆向分析
文章目录 1. 写在前面2. 请求分析3. Hook Cookie4. 补环境 1. 写在前面 最近有位朋友在大A失意,突发奇想自己闲来无事想要做一个小工具,监测一下市场行情的数据。自己再分析分析,虽是一名程序员但苦于对爬虫领域相关的技术不是特别熟悉。最后…...

异步加载JS的方法
异步加载 JavaScript (JS) 文件是提高网页性能的一种常用技术,这样可以使页面在等待 JS 文件加载和执行时不会阻塞。以下是一些异步加载 JS 的方法: 使用 <script> 标签的 async 属性 通过将 <script> 标签的 async 属性设为 true…...

IO/NIO交互模拟及渐进式实现
IO IO Server public class SocketServer {public static void main(String[] args) {//server编号和client编号对应,优缺点注释在server端//server1();//server2();server3();}/*** server1的缺点:* 1、accept()方法阻塞了线程,要等客户端…...

springboot+html实现密码重置功能
目录 登录注册: 前端: chnangePssword.html 后端: controller: Mapper层: 逻辑: 登录注册: https://blog.csdn.net/m0_67930426/article/details/133849132 前端: 通过点击忘记密码跳转…...

LeetCode 2525. 根据规则将箱子分类【模拟】1301
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

AI专著写作工具深度剖析,从构思到完稿全程高效助力
创新是学术专著的核心所在,也是写作过程中的一大挑战。一本优秀的专著不仅应当仅仅是以往研究成果的简单集合,而是要提出贯穿整本书的全新观点、理论框架或研究方法。在庞大的学术文献中,发现未被充分研究的空白并不容易——有时是因为选题被…...

从物理层到数据链路:深入解析CAN总线的核心通信机制
1. CAN总线的前世今生:为什么我们需要它? 想象一下你正在组装一辆智能汽车,发动机、变速箱、ABS、仪表盘这些部件都需要互相"对话"。如果每个设备都用独立线路连接,光是布线就能让工程师崩溃。这就是CAN总线诞生的背景—…...

从‘古董’协议到云存储桥梁:聊聊FTP在现代开发中的那些‘真香’应用场景
从‘古董’协议到云存储桥梁:聊聊FTP在现代开发中的那些‘真香’应用场景 当谈到文件传输协议时,很多人第一反应可能是"这不是上个世纪的技术吗?"。确实,FTP(File Transfer Protocol)诞生于1971年,比大多数程…...

FanControl:重新定义你的散热管理体验
FanControl:重新定义你的散热管理体验 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.Rel…...

告别手动配置!用Simulink 2021b生成ARXML,一键导入ISOLAR-A V9.2.1自动生成RTE
从Simulink到ISOLAR-A:ARXML自动化配置RTE的工程实践 在AUTOSAR开发流程中,模型设计与工具链集成往往存在效率瓶颈。传统"自下而上"开发模式下,工程师需要反复在Simulink和ISOLAR-A/B之间切换,手动维护接口定义、端口连…...

VVC/VTM编码分析进阶:如何利用DecoderAnalyserApp深度解读CU划分与语法元素
VVC/VTM编码分析进阶:如何利用DecoderAnalyserApp深度解读CU划分与语法元素 在视频编码领域,VVC(Versatile Video Coding)作为新一代标准,其编码效率相比前代HEVC有显著提升。而VTM(VVC Test Model…...

Android购物商城APP实战:从零到一构建核心功能模块
1. 项目功能模块拆解与实现路径 一个完整的购物商城APP通常包含四大核心模块:用户系统、商品展示、购物车管理和订单处理。这就像搭建一个实体商店,需要先规划好门面(登录注册)、货架(商品展示)、购物篮&am…...

3步解锁ZTE ONU工厂模式:高效实用的网络设备管理完整指南
3步解锁ZTE ONU工厂模式:高效实用的网络设备管理完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾经面对ZTE ONU设备的管理界面感到束手无策?想…...
:Audio HAL 与硬件接口——音频数据的最后一公里)
Android 15 音频子系统(八):Audio HAL 与硬件接口——音频数据的最后一公里
引言:最后一公里的旅程 如果把 Android 音频系统比作一条物流网络,那么 AudioFlinger 是"中央分拣中心",AudioPolicy 是"路由规划师",而 Audio HAL(Hardware Abstraction Layer)就是最终把包裹送到用户手里的"快递员"。 前几篇我们聊了 …...

AI Agent不是你以为的那样
系列:《AI Agent 从原理到实战 —— 解密 Claude Code 背后的工程智慧》 第1篇引言 你大概有过这样的体验:打开 ChatGPT,说一句"帮我写封邮件,拒绝周五的会议邀请,语气委婉一点",几秒钟后一封措辞…...