Redis设计与实现笔记 - 数据结构篇
Redis设计与实现笔记 - 数据结构篇
相信在我们日常使用中,会经常跟 Redis 打交道。数据结构 String、Hash、List、Set 和 ZSet 都是常用的数据类型。对于使用场景,我们可以滔滔不绝地说很多,但是我们从来就没有关心过它们的底层实现,到底它们的数据是怎么存储的,代码是怎么实现的,使用上有什么值得注意的地方。带着这些疑问,我去查看了相关的书籍,对于实现有了大致的认识。希望你看完后也有所收获。
先统一名词:我们常用的 String、Hash、List、Set 和 ZSet 叫做对象(Object)。它们由如 SDS、LinkList、Skiplist 等基础数据结构组成。
数据结构
简单动态字符串 - SDS
struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* 已使用的长度 */uint64_t alloc; /* 分配的长度 不包含头部和空终止符号 */unsigned char flags; /* 3位最低有效位表示类型, 其余5个比特位未被使用 */char buf[];
};-
常数复杂度获取字符串长度。C 语言中的传统字符串类型需要遍历整个字符串才能获取字符串长度,时间复杂度为 O(n),而 SDS 可以直接获取字符串长度,时间复杂度为 O(1)。
-
杜绝缓冲区溢出。SDS 在字符串末尾预留了额外的空间,当字符串长度增加时,可以直接使用预留的空间,避免了缓冲区溢出的问题。
-
减少修改字符串长度时带来的内存重分配次数。SDS 采用了空间预分配和惰性空间释放等策略,可以减少修改字符串长度时带来的内存重分配次数,提高性能。
-
可含有空字符等特殊字符
主要用于字符串对象的底层实现
链表
/* 双端链表节点 */
typedef struct listNode {/* 指向前驱节点的指针 */
struct listNode *prev;/* 指向后继节点的指针 */
struct listNode *next;/* void * 指针,指向具体的元素,节点可以是任意类型 */
void *value;
} listNode;/* 双端链表迭代器 */
typedef struct listIter {/* 指向遍历的下一个节点的指针 */listNode *next;/* 遍历的方向:从表头遍历还是从表尾遍历 */int direction;
} listIter;/* 双端链表* 有记录头尾两节点,支持从链表头部或者尾部进行遍历,是早期列表键 PUSH/POP 实现高效的关键* 每个链表节点有记录前驱节点和后继节点的指针,可以使得列表键支持往后或者往前进行遍历* 有额外用 len 存储链表长度,O(1) 的时间复杂度获取节点个数,是 LLEN 命令高效的关键 */
typedef struct list {/* 指向链表头节点的指针,支持从表头开始遍历 */listNode *head;/* 指向链表尾节点的指针,支持从表尾开始遍历 */listNode *tail;/* 各种类型的链表可以定义自己的复制函数 / 释放函数 / 比较函数 */void *(*dup)(void *ptr);void (*free)(void *ptr);int (*match)(void *ptr, void *key);/* 链表长度,即链表节点数量,O(1) 时间复杂度获取 */unsigned long len;
} list;-
常数复杂度获取链表长度
-
双端链表实现
-
多态实现,各种类型的链表可以自己定义各自的
复制函数 / 释放函数 / 比较函数
主要用于列表对象的底层实现
字典
typedef struct dictEntry {/* void * 类型的 key,可以指向任意类型的键 */void *key;/* 联合体 v 中包含了指向实际值的指针 *val、无符号的 64 位整数、有符号的 64 位整数,以及 double 双精度浮点数。* 这是一种节省内存的方式,因为当值为整数或者双精度浮点数时,由于它们本身就是 64 位的,void *val 指针也是占用 64 位(64 操作系统下),* 所以它们可以直接存在键值对的结构体中,避免再使用一个指针,从而节省内存开销(8 个字节)* 当然也可以是 void *,存储任何类型的数据,最早 redis1.0 版本就只是 void* */union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next; /* Next entry in the same hash bucket. *//* 同一个 hash 桶中的下一个条目.* 通过形成一个链表解决桶内的哈希冲突. */void *metadata[]; /* An arbitrary number of bytes (starting at a* pointer-aligned address) of size as returned* by dictType's dictEntryMetadataBytes(). *//* 一块任意长度的数据 (按 void* 的大小对齐),* 具体长度由 'dictType' 中的* dictEntryMetadataBytes() 返回. */
} dictEntry;typedef struct dict dict;/* 字典类型,因为我们会将字典用在各个地方,例如键空间、过期字典等等等,只要是想用字典(哈希表)的场景都可以用* 这样的话每种类型的字典,它对应的 key / value 肯定类型是不一致的,这就需要有一些自定义的方法,例如键值对复制、析构等 */
typedef struct dictType {/* 字典里哈希表的哈希算法,目前使用的是基于 DJB 实现的字符串哈希算法* 比较出名的有 siphash,redis 4.0 中引进了它。3.0 之前使用的是 DJBX33A,3.0 - 4.0 使用的是 MurmurHash2 */uint64_t (*hashFunction)(const void *key);/* 键拷贝 */void *(*keyDup)(dict *d, const void *key);/* 值拷贝 */void *(*valDup)(dict *d, const void *obj);/* 键比较 */int (*keyCompare)(dict *d, const void *key1, const void *key2);/* 键析构 */void (*keyDestructor)(dict *d, void *key);/* 值析构 */void (*valDestructor)(dict *d, void *obj);/* 字典里的哈希表是否允许扩容 */int (*expandAllowed)(size_t moreMem, double usedRatio);/* Allow a dictEntry to carry extra caller-defined metadata. The* extra memory is initialized to 0 when a dictEntry is allocated. *//* 允许调用者向条目 (dictEntry) 中添加额外的元信息.* 这段额外信息的内存会在条目分配时被零初始化. */size_t (*dictEntryMetadataBytes)(dict *d);
} dictType;/* 通过指数计算哈希表的大小,见下面 exp,哈希表大小目前是严格的 2 的幂 */
#define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp))
/* 计算掩码,哈希表的长度 - 1,用于计算键在哈希表中的位置(下标索引) */
#define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)/* 7.0 版本之前的字典结构
typedef struct dictht {dictEntry **table; // 8 bytesunsigned long size; // 8 bytesunsigned long sizemask; // 8 bytesunsigned long used; // 8 bytes
} dictht;typedef struct dict {dictType *type; // 8 bytesvoid *privdata; // 8 bytesdictht ht[2]; // 32 bytes * 2 = 64 byteslong rehashidx; // 8 bytesint16_t pauserehash; // 2 bytes
} dict;** 做的优化大概是这样的:* 1. 从字典结构里删除 privdata (这个扩展其实一直是个 dead code,会影响很多行,社区里的做法都是想尽量减少 diff 变更,避免说破坏 git blame log)* 2. 将 dictht 字典哈希表结构融合进 dict 字典结构里,相关元数据直接放到了 dict 中* 3. 去掉 sizemark 字段,这个值可以通过 size - 1 计算得到,这样就可以少 8 字节* 4. 将 size 字段转变为 size_exp(就是 2 的 n 次方,指数),因为 size 目前是严格都是 2 的幂,size_exp 存储指数而不是具体数值,size 内存占用从 8 字节降到了 1 字节** 内存方面:* 默认情况下通过 sizeof 我们是可以看到新 dict 是 56 个字节* dict:一个指针 + 两个指针 + 两个 unsigned long + 一个 long + 一个 int16_t + 两个 char,总共实际上是 52 个字节,但是因为 jemalloc 内存分配机制,实际会分配 56 个字节* 而实际上因为对齐,最后的 int16_t pauserehash 和 char ht_size_exp[2] 加起来是占用 8 个字节,代码注释也有说,将小变量放到最后来获得最小的填充。*/struct dict {/* 字典类型,8 bytes */dictType *type;/* 字典中使用了两个哈希表,* (看看那些以 'ht_' 为前缀的成员, 它们都是一个长度为 2 的数组)** 我们可以将它们视为* struct{* ht_table[2];* ht_used[2];* ht_size_exp[2];* } hash_table[2];* 为了优化字典的内存结构,* 减少对齐产生的空洞,* 我们将这些数据分散于整个结构体中.** 平时只使用下标为 0 的哈希表.* 当需要进行 rehash 时 ('rehashidx' != -1),* 下标为 1 的一组数据会作为一组新的哈希表,* 渐进地进行 rehash 避免一次性 rehash 造成长时间的阻塞.* 当 rehash 完成时, 将新的哈希表置入下标为 0 的组别中,* 同时将 'rehashidx' 置为 -1.*/dictEntry **ht_table[2];/* 哈希表存储的键数量,它与哈希表的大小 size 的比值就是 load factor 负载因子,* 值越大说明哈希碰撞的可能性也越大,字典的平均查找效率也越低* 理论上负载因子 <=1 的时候,字典能保持平均 O(1) 的时间复杂度查询* 当负载因子等于哈希表大小的时候,说明哈希表退化成链表了,此时查询的时间复杂度退化为 O(N)* redis 会监控字典的负载因子,在负载因子变大的时候,会对哈希表进行扩容,后面会提到的渐进式 rehash */unsigned long ht_used[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 *//* rehash 的进度.* 如果此变量值为 -1, 则当前未进行 rehash. *//* Keep small vars at end for optimal (minimal) struct padding *//* 将小尺寸的变量置于结构体的尾部, 减少对齐产生的额外空间开销. */int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) *//* 如果此变量值 >0 表示 rehash 暂停* (<0 表示编写的代码出错了). *//* 存储哈希表大小的指数表示,通过这个可以直接计算出哈希表的大小,例如 exp = 10, size = 2 ** 10* 能避免说直接存储 size 的实际值,以前 8 字节存储的数值现在变成 1 字节进行存储 */signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) *//* 哈希表大小的指数表示.* (以 2 为底, 大小 = 1 << 指数) */
};结构体有点长,简单展示就是如下
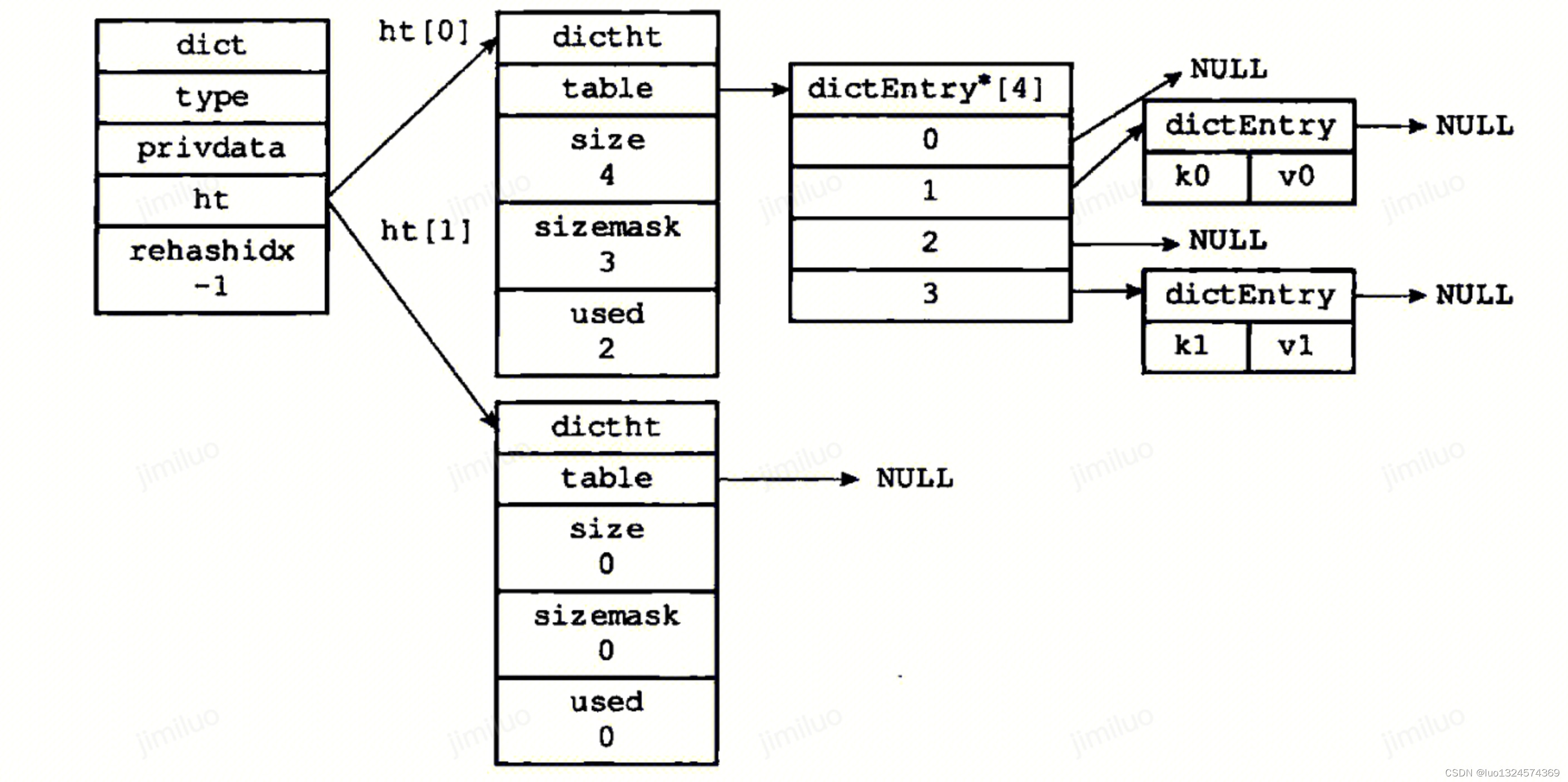
-
dictEntry存的是一个链表,因为redis解决hash冲突的方式是使用链地址法,其他解决方法可参考 解决哈希冲突的常用方法分析 - 腾讯云 -
这里注意一下ht这个字段,正常来说一个ht[1]是不会使用的,只有在rehash过程中才会有值
rehash
字典的负载因子(load factor)超过一定阈值时就会启动rehash, 在过程中对于字典的增删改查都会先查一遍ht[0],然后把值迁移到ht[1],等到ht[0]迁移完毕就会释放ht[0],将ht[1]设置成ht[0]
主要用于哈希对象和数据库的底层实现,对,没错,整个数据库也是一个大哈希实现
跳表
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;-
zskiplist使用双端链表实现 -
在遍历操作时只需要用到
forward前行指针,查找过程-
如果下一个节点比目标节点大,则移动到下一个节点
-
否则移动到下一层
-
重复以上步骤,直到找到目标值
-
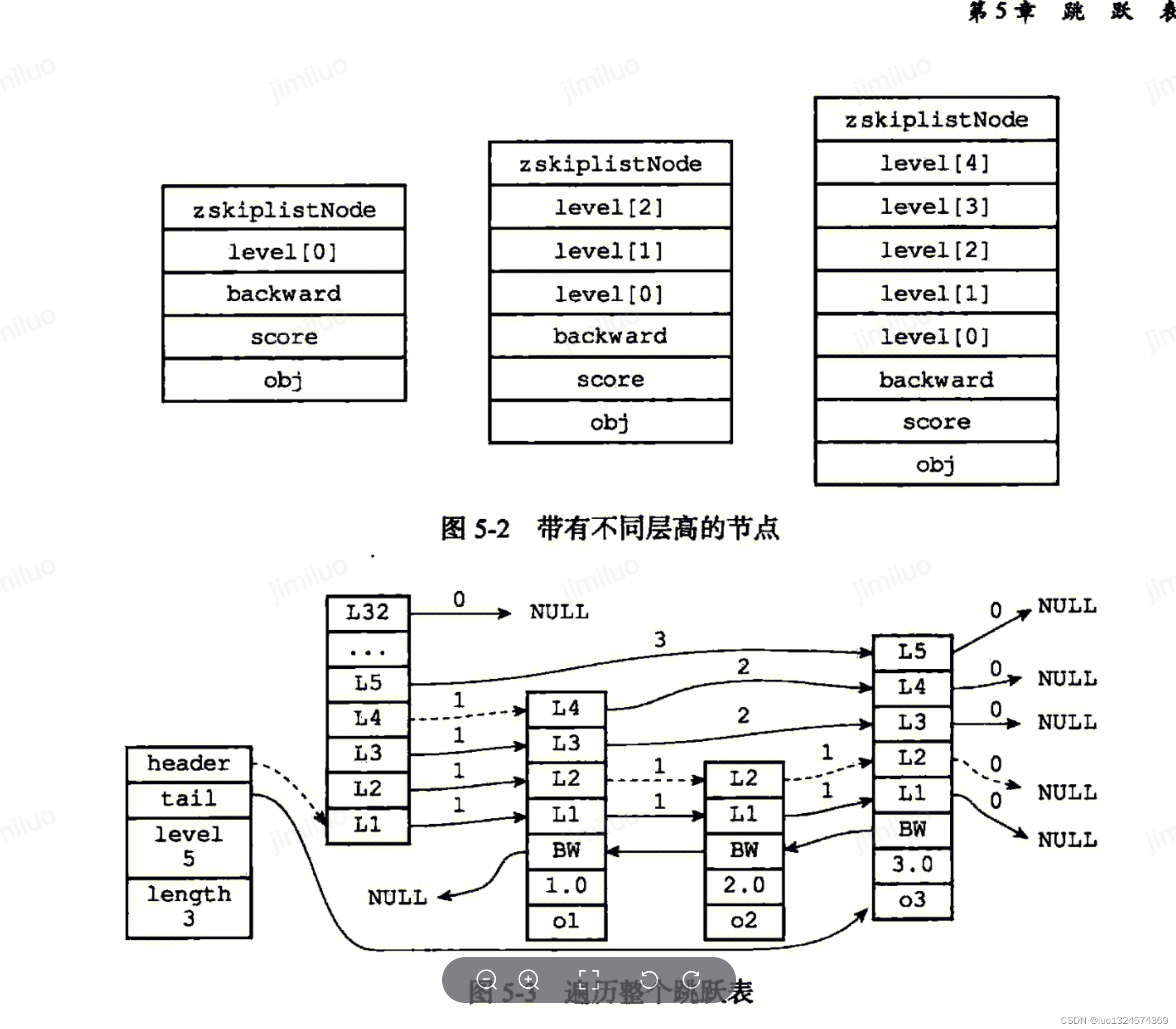
跳表与字典结合作为有序集合的底层实现
整数集合
/* 整数集合 * 记录不包含重复元素的各个整数(由小到大的顺序) * 底层数组默认是 int16_t 类型, 可能随着新增元素的大小升级至 int32_t 或 int64_t 类型*/
typedef struct intset {/* 编码, 记录整数集合底层数组(contents)的类型*/uint32_t encoding;/* 记录整数集合包含的元素个数 */uint32_t length;/* 整数集合的底层实现, 虽声明为 int8_t 类型,但真正的类型取决于 encoding */int8_t contents[];
} intset;-
支持类型 int16_t, int32_t, int64_t
-
在插入一个不同当前编码的值就会触发升级,遍历所有value转换类型,且不支持降级
原本 1, 2, 3
| 位 | 0-15位 | 16-31位 | 32-48位 | 48-127位 |
|---|---|---|---|---|
| 元素 | 1 | 2 | 3 | 新分配空间 |
插入 65535
| 位 | 0-31位 | 32-63位 | 64-95位 | 96-127位 |
|---|---|---|---|---|
| 元素 | 1 | 2 | 3 | 65535 |
用于当value都是整数,并且个数不超过512的集合底层实现
压缩列表
ziplist 压缩列表是由一系列字节数组表示的,每个字节数组可以表示一个节点的信息,包括节点的类型、长度和值等信息。
压缩列表的布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配 |
| zltail | uint32_t | 4字节 | 或者计算zlend 的位置时使用 记录压缩列表表尾节点西商压缩列表的起始地址有多少字节:通过这个 |
| zllen | uint16_t | 2字节 | 记录了压缩列表包含的节点数量:当这个属性的值小于(65535)时,这个属性的值就是压缩列表包含节点的数量:当这个值等于 UINT16_MAx 时,节点的真实数量需要追历整个压缩列表才能计算得出 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint8_t | 1字节 | 特殊值O x FF(十进制255),用于标记压缩列表的末端。 |
entry的布局如下
| 属性 | 用途 |
|---|---|
| previous_entry_iength | 前置节点长度记录了前一个节点的字节数,它的长度可以是 1 个字节或 5 个字节,具体占用的字节数取决于前一个节点的字节数,用于支持列表的反向遍历 |
| encoding | 节点类型记录了该节点存储的数据类型,它的长度为 1 个字节,
|
| content | 节点值记录了该节点存储的数据,它的长度为节点长度所记录的字节数。如果该节点是字符串节点,则节点值存储的是字符串的值;如果该节点是整数节点,则节点值存储的是整数的值。 |
连锁更新
由于previous_entry_length的长度是1或5,取决于前一个节点的长度,如果有个列表,每个节点的长度都是250-253之间,那么当第一个节点增加了长度,后续每一个节点需要增加长度,作者称这种现象为连锁更新,需要o(n)复杂度去更新每一个节点
为了解决这个问题, 后续在Redis7.0全面使用listpack代替了ziplist, 详细参与: Redis7.0代码分析:底层数据结构listpack实现原理 - 掘金
用于列表和哈希的底层实现
后续….
Redis3.2之后引入quicklist
引用
redis7源码中文注释
Redis设计与实现
相关文章:
Redis设计与实现笔记 - 数据结构篇
Redis设计与实现笔记 - 数据结构篇 相信在我们日常使用中,会经常跟 Redis 打交道。数据结构 String、Hash、List、Set 和 ZSet 都是常用的数据类型。对于使用场景,我们可以滔滔不绝地说很多,但是我们从来就没有关心过它们的底层实现…...
线性代数-Python-01:向量的基本运算 -手写Vector -学习numpy的基本用法
文章目录 代码目录结构Vector.py_globals.pymain_vector.pymain_numpy_vector.py 一、创建属于自己的向量1.1 在控制台测试__repr__和__str__方法1.2 创建实例测试代码 二、向量的基本运算2.1 加法2.2 数量乘法2.3 向量运算的基本性质2.4 零向量2.5 向量的长度2.6 单位向量2.7 …...
数字图像处理实验记录二(直方图和直方图均衡化)
文章目录 一、基础知识1,什么是直方图2,直方图有什么用3,直方图均衡化4、原理代码实现 二、实验要求任务1:任务2: 三、实验记录任务1:任务2: 四、结果展示任务1:任务2: 五…...

大数据Flink(九十九):SQL 函数的解析顺序和系统内置函数
文章目录 SQL 函数的解析顺序和系统内置函数 一、SQL 函数...
TODO Vue typescript forEach的bug,需要再核實
forEach 一個string[],只有最後一個匹配條件有效,其它條件無效。 所以,只能替換成普通的for循環。 console.log(taskList)// for (const _task of taskList.value) {// if (_task invoiceSendEmail) {// form.value.invoiceSendEmail…...

简记一个错误
简记一个Flutter错误: Using hardware rendering with device sdk gphone64 x86 64. If you notice graphics artifacts, consider enabling software rendering with “–enable-software-rendering”. Launching lib\main.dart on sdk gphone64 x86 64 in debug …...

第四次作业
1.打印各种图形 A.矩形 a int(input("请输入行数: ")) i 0 while i < a:print("*"*10)i1 结果: B.直角三角形 a int(input("请输入行数: ")) i 0 while i<a:print("*"*(i1))i1 结果: C.反直角三角形 …...

面试问题整理总结
1.自我介绍 2.为什么想转测试 想换一个方向,测试开发在一定程度上也是属于开发,而且站在测试的角度能看到全局的东西更多,对需求的理解需要更深”,之前的开发工作比较专一,测试的视野更加开阔,想要站在更高…...

进阶JAVA篇- Collection 类的常用的API与 Collection 集合的遍历方式
目录 1.0 Collection 类的说明 1.1 Collection 类中的实例方法 2.0 Collection 集合的遍历方式(重点) 2.1 使用迭代器( Iterator )进行遍历 2.2 使用增强型 for 循环进行遍历 2.3 使用 Java 8的 Stream API 进行遍历(使…...
CentOS | 添加普通用户并授权sudo
sudo -i adduser peter passwd peter whereis sudoers nano /etc/sudoers添加一行新用户到root组 ## Allow root to run any commands anywhere root ALL(ALL) ALL peter ALL(ALL) ALL如果提升权限后无法cd到其他目录等,修改 /etc/passwd 文件&…...
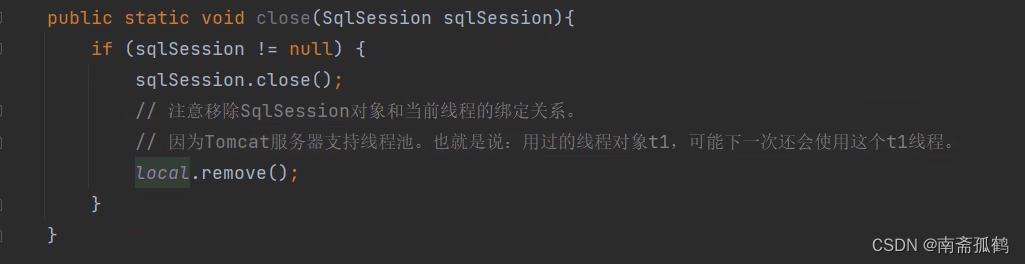
【MyBatis】mybatis工具类迭代
目录 MyBatis工具类的迭代 ThreadLocal使用 mybatis工具类终极版: MyBatis工具类的迭代 public class MyBatisUtil {//工具类构造方法私有化private void MyBatisUtil() {}//方法一public static SqlSession getSqlSession(){try {SqlSessionFactoryBuilder sql…...
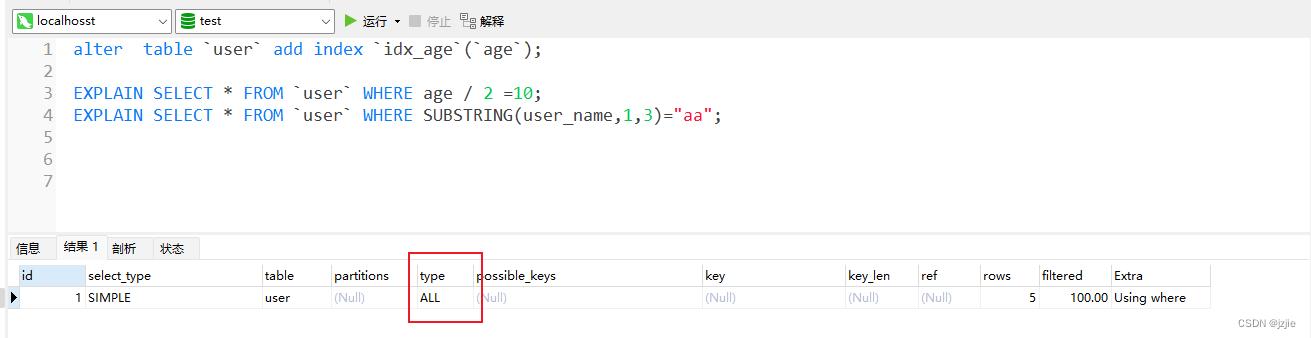
MSQL系列(六) Mysql实战-SQL语句优化
Mysql实战-SQL语句优化 前面我们讲解了索引的存储结构,BTree的索引结构,以及索引最左侧匹配原则,Explain的用法,可以看到是否使用了索引,今天我们讲解一下SQL语句的优化及如何优化 文章目录 Mysql实战-SQL语句优化1.…...

kaggle新赛:UBC卵巢癌亚型分类和异常检测大赛【图像分类】
赛题名称:UBC Ovarian Cancer Subtype Classification and Outlier Detection (UBC-OCEAN) 赛题链接:https://www.kaggle.com/competitions/UBC-OCEAN 赛题背景 卵巢癌是女性生殖系统最致命的癌症。目前,卵巢癌诊断依赖病理学家评估亚型。…...

基于nodejs+vue云旅青城系统
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

《孙哥说Spring5》笔记汇总
时隔两个多月,终于将《孙哥说Spring5》的笔记文章全部整理完了,在这里做个汇总。孙哥的Spring课讲的非常好,深度和广度都有所兼顾,推荐大家去看 点击学习《孙哥说Spring5》 基础铺垫 1️⃣ Spring5应用之基础扫盲2️⃣ Spring5应…...

在使用了spring-cloud-starter-gateway后,为什么还会发生cors问题
//1.需要配置类 import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.cors.CorsConfiguration; import org.springframework.web.cors.reactive.CorsWebFilter; import org.sp…...
CentOS7安装MySQL8.0.28
CentOS7安装MySQL8.0.28 一、下载MySQL安装包二、安装配置mysql 一、下载MySQL安装包 点击以下链接可以自动跳转:MySQL官网 接下来按如图所示依次点击进入。 选择自己所需要版本 此处如需下载历史版本可以点击 二、安装配置mysql 1、登录ssh或其他相关软件上…...
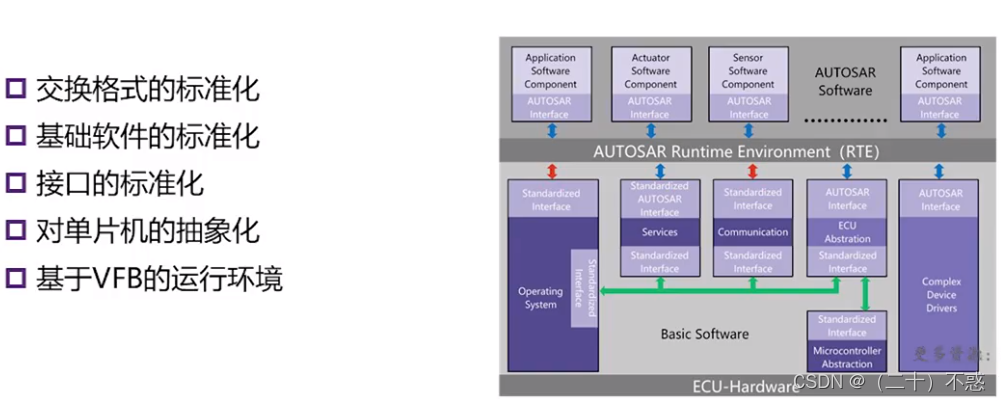
AutoSAR入门:应用背景及简介
1、应用背景 在我们现在的汽车行业里面,汽车电子的发展过程中,我们发现有一些新的趋势汽车电子系统的复杂性不断增长。 我们现在可以看到车辆有越来越多的功能,那么这些功能呢,也在往这个控制器上进行集中,比如说我们现…...
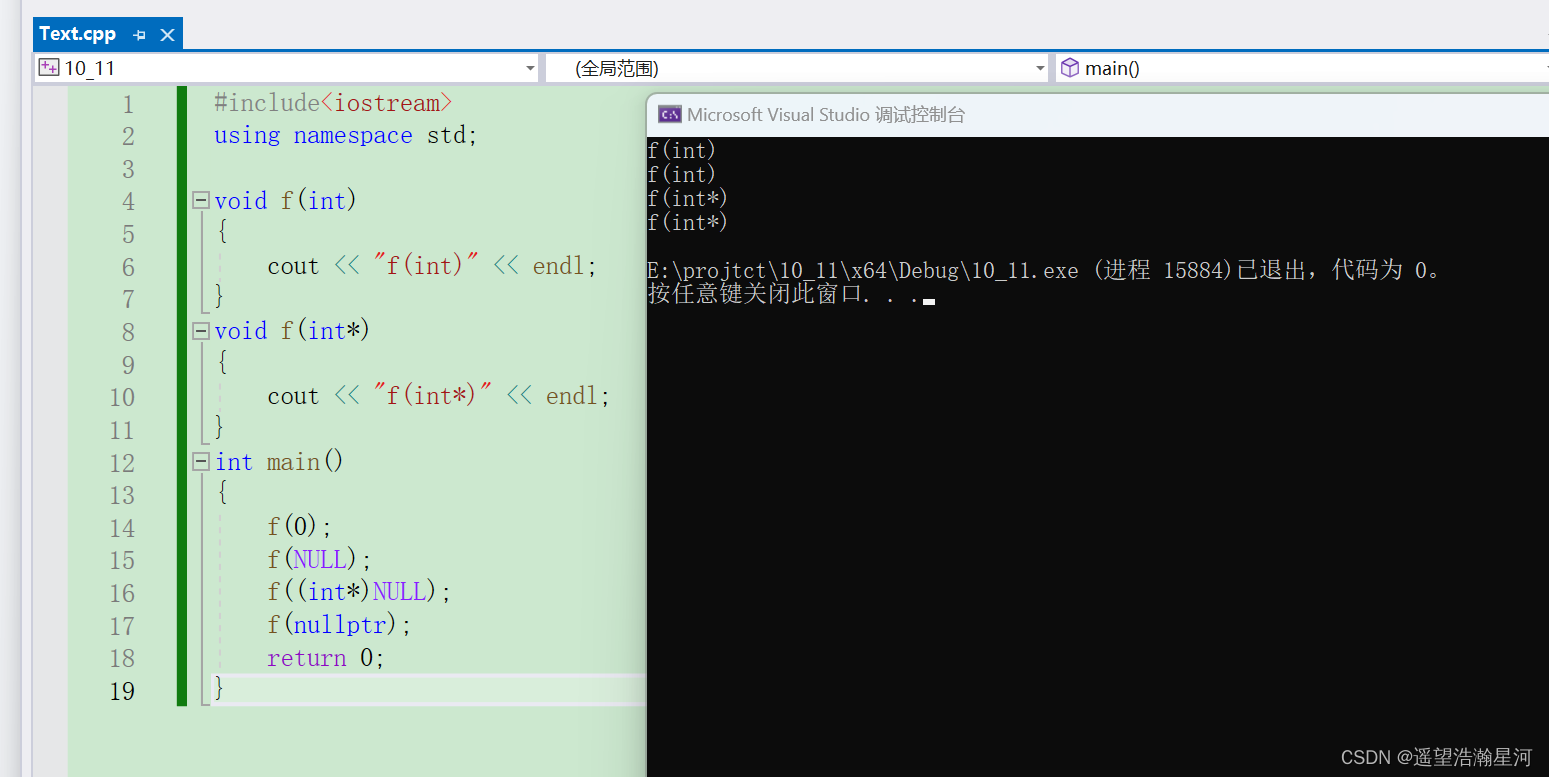
C++初阶(三)
文章目录 一、auto关键字(C11)1、auto简介2、auto使用规则1、 auto与指针和引用结合起来使用2、 在同一行定义多个变量 3、auto不能推导的场景1、 auto不能作为函数的参数2、 auto不能直接用来声明数组3、特性总结 二、基于范围的for循环(C11)1、范围for的语法2、 范围for的使用…...
PHP的学习入门建议
学习入门PHP的步骤如下: 确定学习PHP的目的和需求,例如是为了开发网站还是为了与数据库交互等。学习PHP的基础语法和程序结构,包括变量、数据类型、循环、条件等。学习PHP的面向对象编程(OOP)概念和技术。学习与MySQL…...

Joy-Con Toolkit:任天堂手柄全能管理解决方案
Joy-Con Toolkit:任天堂手柄全能管理解决方案 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 核心价值:重新定义手柄控制体验 Joy-Con Toolkit作为开源手柄管理领域的创新工具࿰…...

HunyuanVideo-Foley性能测试指南:在RTX 4090D上的推理速度与显存占用
HunyuanVideo-Foley性能测试指南:在RTX 4090D上的推理速度与显存占用 1. 前言:为什么需要性能测试 音效生成模型在实际业务场景中的表现,直接影响着用户体验和系统成本。对于企业用户来说,了解模型在特定硬件上的性能表现至关重…...

停止学习新语言!2026年技术人的反内耗宣言
一、技术内耗的困局:语言焦虑与效率陷阱2026年的技术圈,Python稳居TIOBE榜首,Rust强势崛起,TypeScript重构前端生态……语言迭代的速度远超人类学习极限。测试从业者深陷三重内耗漩涡:工具链绑架:70%自动化…...

NASM高级特性详解:条件汇编、上下文栈和宏重载
NASM高级特性详解:条件汇编、上下文栈和宏重载 【免费下载链接】nasm A cross-platform x86 assembler with an Intel-like syntax 项目地址: https://gitcode.com/gh_mirrors/na/nasm NASM(Netwide Assembler)是一款跨平台的x86汇编器…...

GameFramework——FileSystem篇
目录 一、快速入门 1.1 什么是文件系统模块? 1.2 基本使用步骤 1.2.1 创建文件系统 1.2.2 写入文件 1.2.3 读取文件 1.2.4 删除文件 1.2.5 加载已有文件系统 二、文件布局 2.1 HeaderData(文件头) 2.2 BlockData(块数据…...

倒反天罡了!Cursor自研模型反超Opus 4.6!价格脚踝斩,氛围编程沸腾了
因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享点击关注#互联网架构师公众号,领取架构师全套资料 都在这里0、2T架构师学习资料干货分上一篇:2T架构师学习资料干货分享大家好,我是互联网架构师ÿ…...

SonarQube实战:通过pom.xml配置sonar-maven-plugin实现自动化代码扫描
1. 为什么需要自动化代码扫描 在软件开发过程中,代码质量是决定项目成败的关键因素之一。想象一下,你正在建造一栋房子,如果砖块质量不过关,水泥配比不对,即使外观再漂亮,也可能随时倒塌。代码也是如此&…...

硅橡胶资源平台对接的靠谱对接企业哪家强
在深圳这座创新与制造之都,硅橡胶产业上下游企业林立,从原材料、模具设计到制品生产,形成了一个庞大而复杂的产业链。对于许多企业而言,“深圳硅橡胶资源平台对接” 的需求日益迫切——无论是寻找稳定供应商、开拓新客户ÿ…...

如何轻松获取网页媒体资源?猫抓开源工具让资源提取效率提升3倍
如何轻松获取网页媒体资源?猫抓开源工具让资源提取效率提升3倍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾在浏览网页时遇…...
)
Java应用等保三级合规改造:3天完成代码层、配置层、运维层全栈优化(附Checklist)
第一章:Java应用等保三级合规改造全景图等保三级是国家网络安全等级保护制度中面向重要信息系统的核心要求,对Java应用而言,合规改造不是单一技术点的修补,而是一套覆盖开发、运行、运维全生命周期的安全治理工程。其核心目标在于…...