利用InceptionV3实现图像分类
最近在做一个机审的项目,初步希望实现图像的四分类,即:正常(neutral)、涉政(political)、涉黄(porn)、涉恐(terrorism)。有朋友给推荐了个github上面的文章,浏览量还挺大的。地址如下:
https://github.com/xqtbox/generalImageClassification
我导入试了一下,发现博主没有放他训练的模型文件my_model.h5,所以代码trainMyDataWithKerasModel.py不能直接运行。必须先自己训练个模型才行,所以只好自己搞了。我开发电脑上安装的python版本是3.9.12,这个版本通常会遇到兼容性的问题,所以我决定先搭建个虚拟环境来测试一下。虚拟环境就用3.7.16了。
1、执行:conda create -n InceptionV3 python=3.7
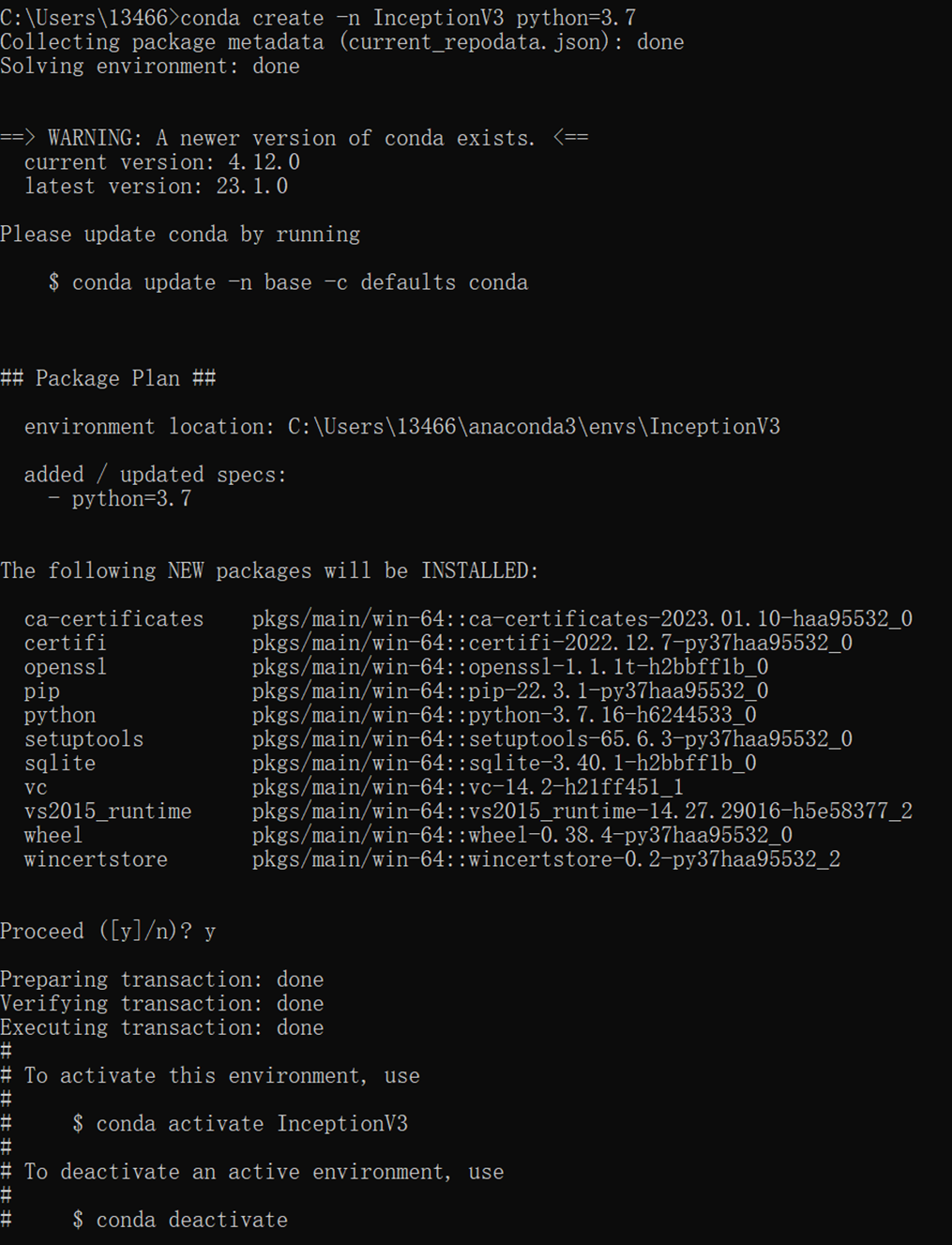
在C:\Users\用户名\anaconda3\envs目录下创建虚拟环境InceptionV3目录。
2、执行:conda activate InceptionV3

启动InceptionV3虚拟环境。
3、执行:pip install -i https://pypi.douban.com/simple/ tensorflow==1.14.0
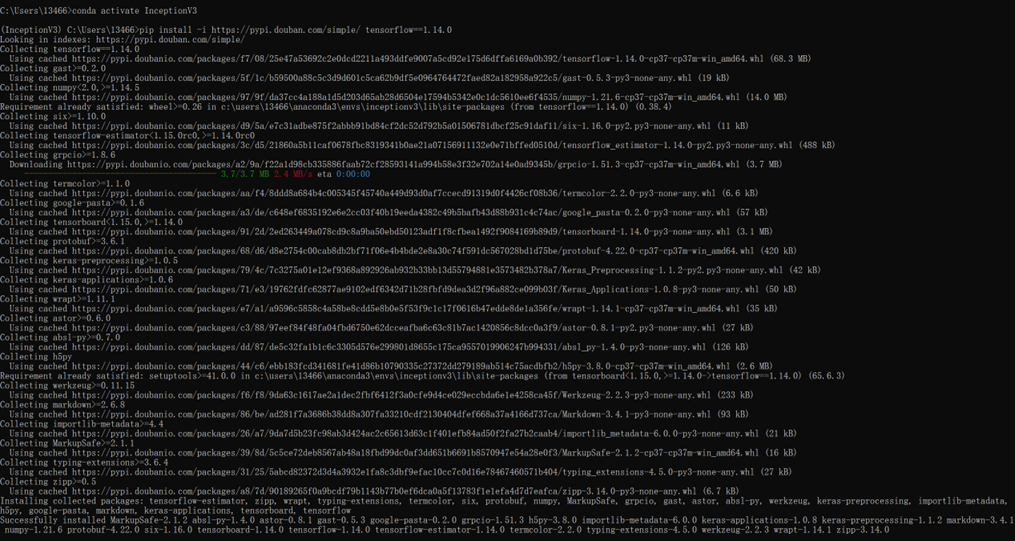
我的显卡是Nvidia GeForce RTX 3060的,CUDA是11.8,Cudnn是8.7.0,查了一下对应的。查了一下对应tensorflow版本是1.14.0,所以就安装这个。
4、执行:pip install -i https://pypi.douban.com/simple/ protobuf==3.19.0

5、执行:pip install -i https://pypi.douban.com/simple/ tensorflow_hub==0.9.0

6、执行:pip install -i https://pypi.douban.com/simple/ opencv-python

7、执行:pip install -i https://pypi.douban.com/simple/ scikit-learn

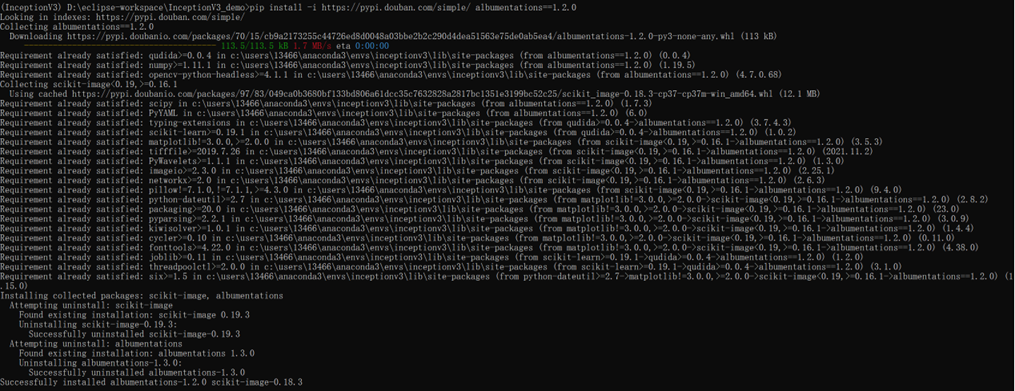
8、执行:pip install -i https://pypi.douban.com/simple/ albumentations==1.2.0
9、执行:pip install -i https://pypi.douban.com/simple/ h5py==2.10.0

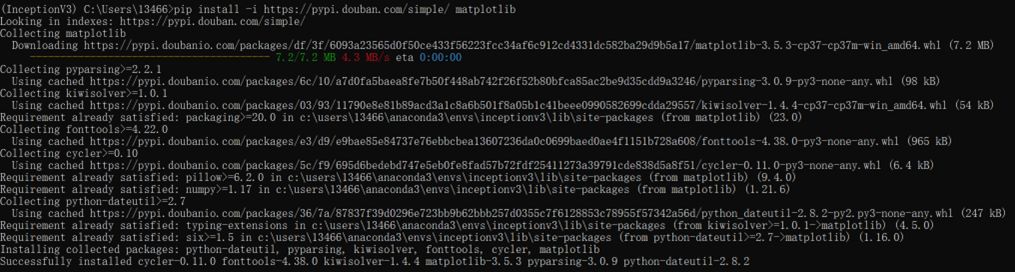
10、执行:pip install -i https://pypi.douban.com/simple/ matplotlib
11、执行:pip install -i https://pypi.douban.com/simple/ Tensorflow-gpu==2.4.0
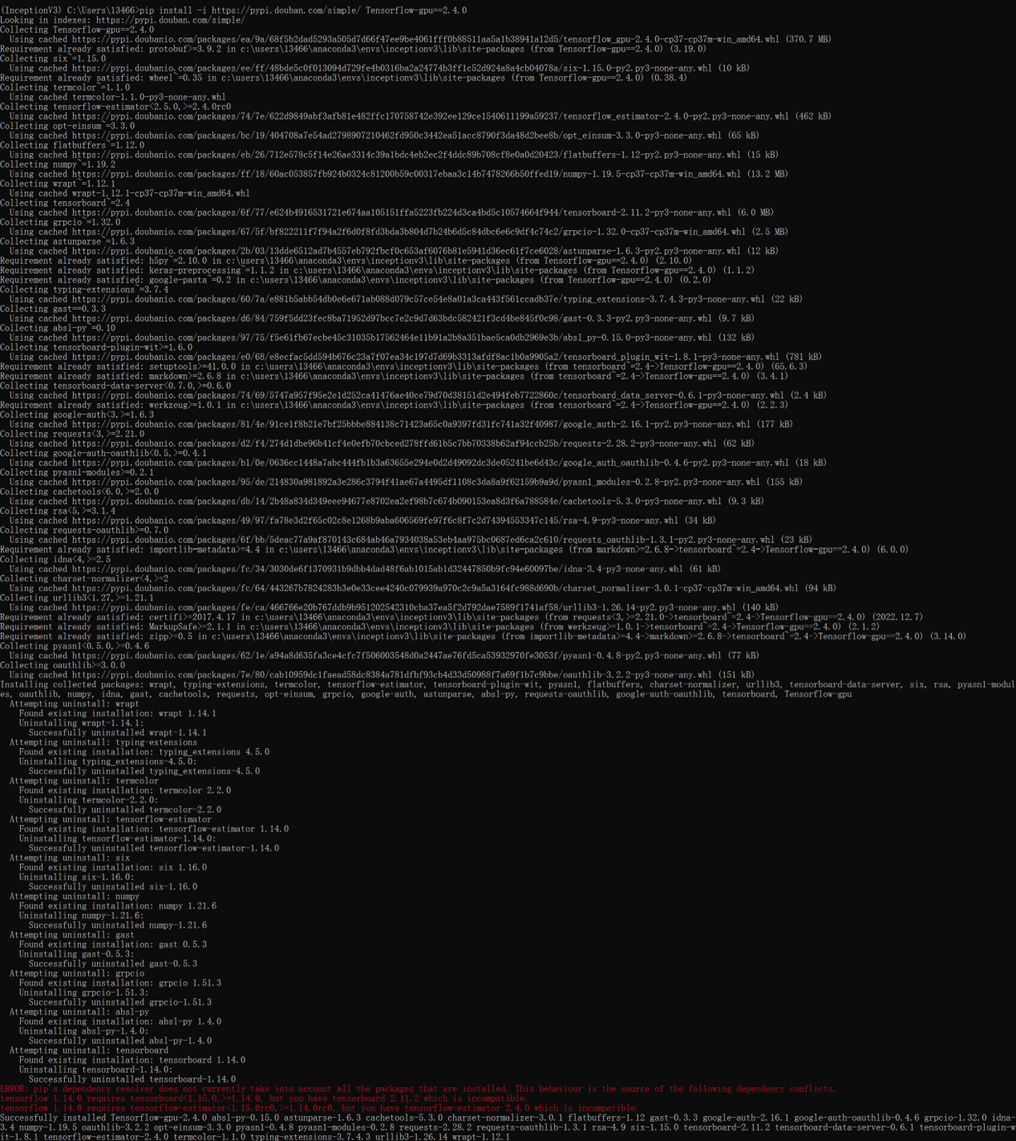
12、执行:pip install -i https://pypi.douban.com/simple/ keras==2.6.0

13、下面是训练代码,文件名是train1.py
import numpy as np
from tensorflow.keras.optimizers import Adamimport cv2
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_splitfrom tensorflow.python.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.applications import InceptionV3
import os
import tensorflow as tffrom tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.models import Sequentialimport albumentations
norm_size = 224
datapath = 'data/train'
EPOCHS = 20
INIT_LR = 3e-4
labelList = []# 这里是分类详情
dicClass = {'neutral':0, 'political':1, 'porn':2, 'terrorism':3}
# 这是分类个数
classnum = 4batch_size = 2
np.random.seed(42)# tf.config.list_physical_devices('GPU')
# tf.test.is_gpu_available()def loadImageData():imageList = []listClasses = os.listdir(datapath) # 类别文件夹print(listClasses)for class_name in listClasses:label_id = dicClass[class_name]class_path = os.path.join(datapath, class_name)image_names = os.listdir(class_path)for image_name in image_names:image_full_path = os.path.join(class_path, image_name)labelList.append(label_id)imageList.append(image_full_path)return imageListprint("开始加载数据")
imageArr = loadImageData()
labelList = np.array(labelList)
print("加载数据完成")
print(labelList)
trainX, valX, trainY, valY = train_test_split(imageArr, labelList, test_size=0.3, random_state=42)train_transform = albumentations.Compose([albumentations.OneOf([albumentations.RandomGamma(gamma_limit=(60, 120), p=0.9),albumentations.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.9),albumentations.CLAHE(clip_limit=4.0, tile_grid_size=(4, 4), p=0.9),]),albumentations.HorizontalFlip(p=0.5),albumentations.ShiftScaleRotate(shift_limit=0.2, scale_limit=0.2, rotate_limit=20,interpolation=cv2.INTER_LINEAR, border_mode=cv2.BORDER_CONSTANT, p=1),albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)])
val_transform = albumentations.Compose([albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)])def generator(file_pathList, labels, batch_size, train_action=False):L = len(file_pathList)while True:input_labels = []input_samples = []for row in range(0, batch_size):temp = np.random.randint(0, L)X = file_pathList[temp]Y = labels[temp]image = cv2.imdecode(np.fromfile(X, dtype=np.uint8), -1)if image.shape[2] > 3:image = image[:,:,:3]if train_action:image = train_transform(image=image)['image']else:image = val_transform(image=image)['image']image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)image = img_to_array(image)input_samples.append(image)input_labels.append(Y)batch_x = np.asarray(input_samples)batch_y = np.asarray(input_labels)yield (batch_x, batch_y)checkpointer = ModelCheckpoint(filepath='best_model.hdf5',monitor='val_acc', verbose=1, save_best_only=True, mode='max')reduce = ReduceLROnPlateau(monitor='val_acc', patience=10,verbose=1,factor=0.5,min_lr=1e-6)model = Sequential()
model.add(InceptionV3(include_top=False, pooling='avg', weights='imagenet'))
model.add(Dense(classnum, activation='softmax'))optimizer = Adam(learning_rate=INIT_LR)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['acc'])# print('trainX = ' + str(trainX))
# print('trainY = ' + str(trainY))model.add(tf.keras.layers.BatchNormalization())history = model.fit(generator(trainX, trainY, batch_size, train_action=True),steps_per_epoch=len(trainX) / batch_size,validation_data=generator(valX, valY, batch_size, train_action=False),epochs=EPOCHS,validation_steps=len(valX) / batch_size,callbacks=[checkpointer, reduce])
model.save('my_model.h5')
print(history)loss_trend_graph_path = r"WW_loss.jpg"
acc_trend_graph_path = r"WW_acc.jpg"
import matplotlib.pyplot as pltprint("Now,we start drawing the loss and acc trends graph...")
# summarize history for acc
fig = plt.figure(1)
plt.plot(history.history["acc"])
plt.plot(history.history["val_acc"])
plt.title("Model acc")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(acc_trend_graph_path)
plt.close(1)
# summarize history for loss
fig = plt.figure(2)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("Model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.savefig(loss_trend_graph_path)
plt.close(2)
print("We are done, everything seems OK...")13.1、norm_size = 224 设置输入图像的大小,InceptionV3默认的图片尺寸是224×224。但是我的图片有300px以上的,好像也没什么问题
13.2、datapath = ‘data/train’ 设置图片存放的路径
13.3、EPOCHS = 20 epochs的数量,关于epoch的设置多少合适,这个问题很纠结,一般情况设置300足够了,如果感觉没有训练好,再载入模型训练。
13.4、INIT_LR = 1e-3 学习率,一般情况从0.001开始逐渐降低,也别太小了到1e-6就可以了。
13.5、classnum = 12 类别数量,数据集有两个类别,所有就分为两类。
13.6、batch_size = 4 batchsize,根据硬件的情况和数据集的大小设置,太小了loss浮动太大,太大了收敛不好,根据经验来,一般设置为2的次方。windows可以通过任务管理器查看显存的占用情况。
14、工程目录的文件如下图:
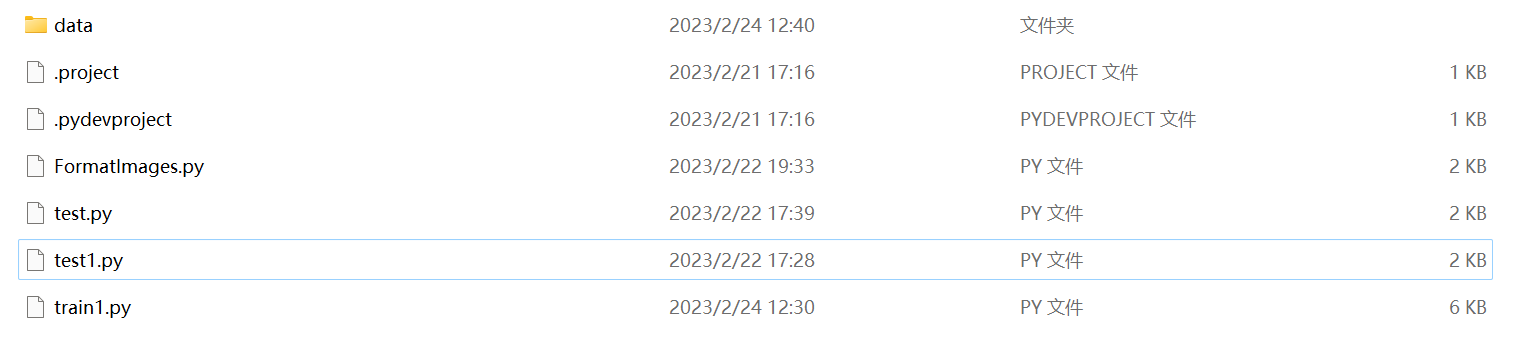
其中train1.py是训练程序;test.py是检测程序,本文后面会再详细讲怎么用;FormatImages.py是格式化图片的程序,功能就是把从网上爬下来比较大的图片等比压缩成300px以内。
data目录存放的就是训练用的数据,如下图:

其中train存放的是训练图片,test存放的是测试图片。train下的目录如下图:
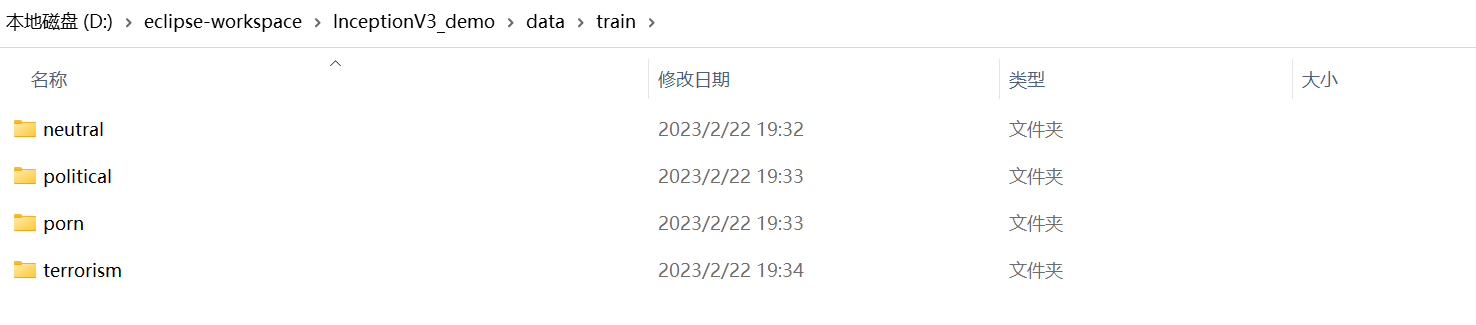
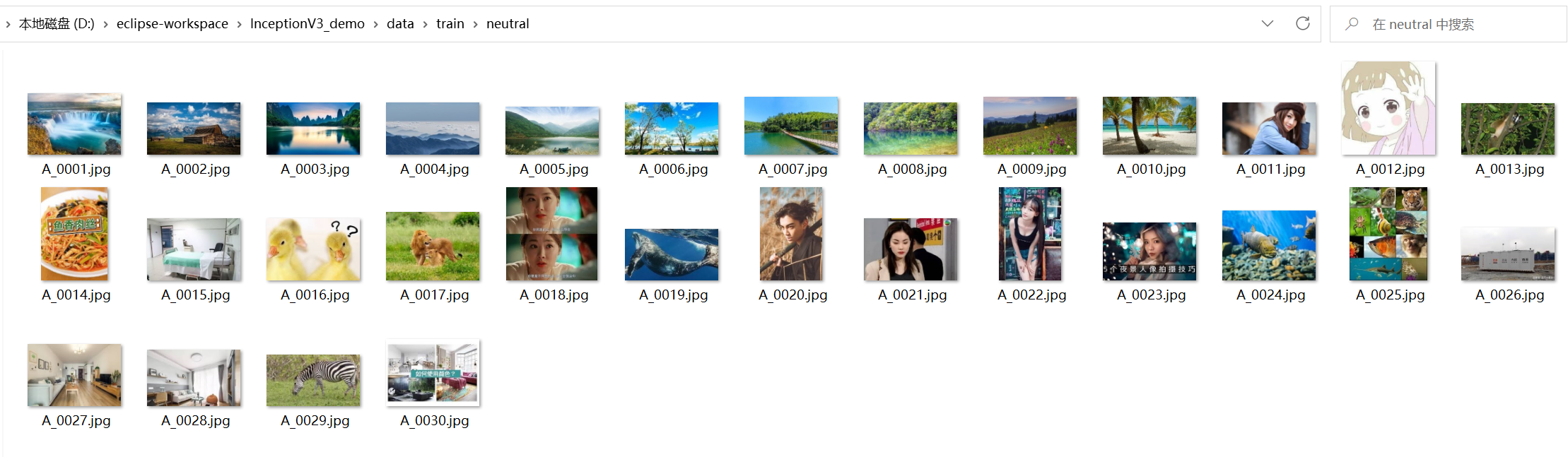
可以看到,图中的train目录中的文件夹名要与train1.py中dicClass的值对应起来,训练数据放到对应目录下就可以了。如下图:
15、下面开始训练了,在训练之前有几个事情要做一下。
首先检查一下自己的cuda安装好没有,方法是在cmd下面输入命令nvcc -V,如果显示版本号就没问题了,如下图:

如果还没有安装也没关系,先看看自己显卡的cuda版本,如下图:
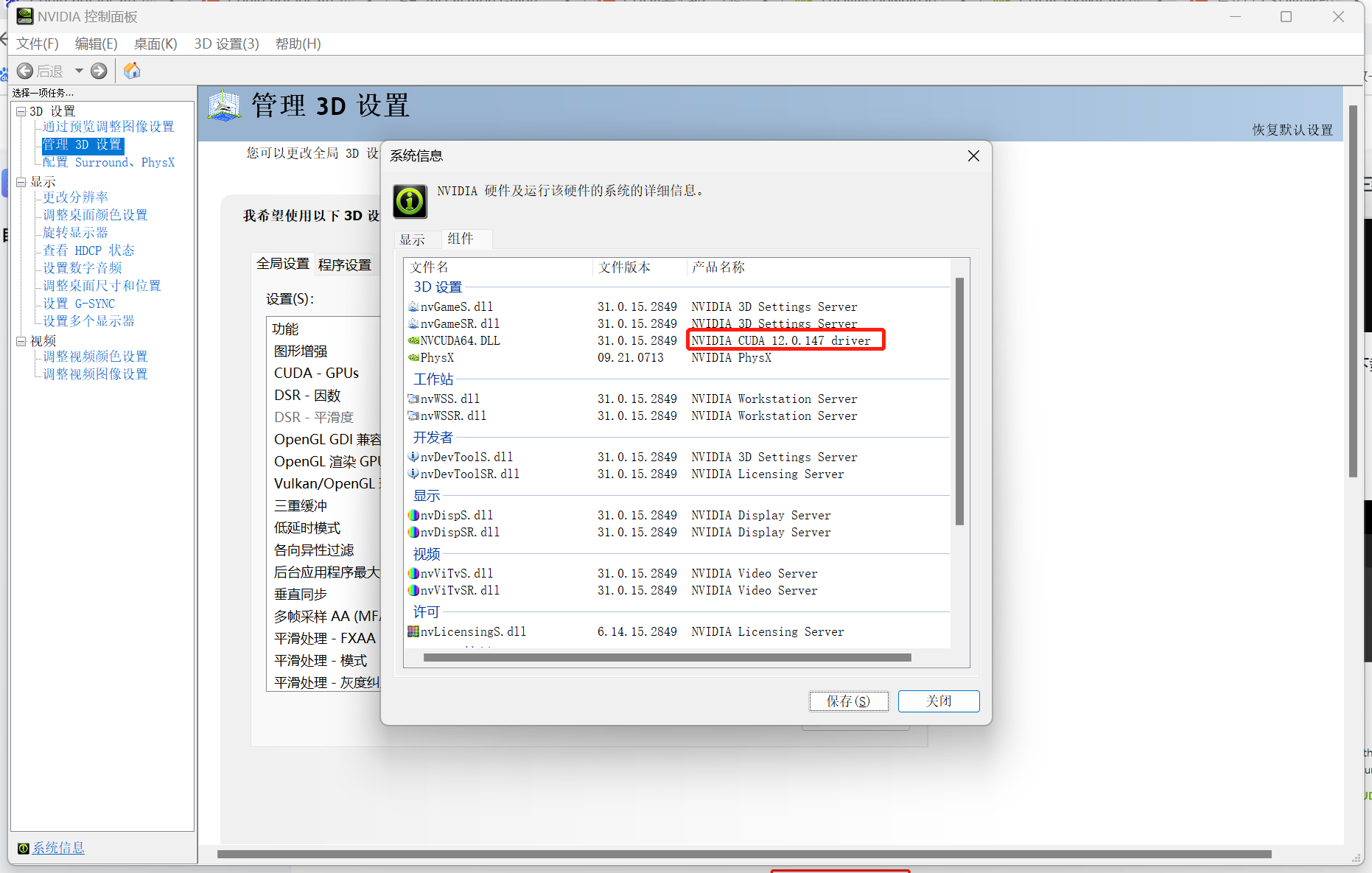
然后去https://developer.nvidia.com/cuda-toolkit-archive下载显卡对应版本的cuda工具包。如下图:
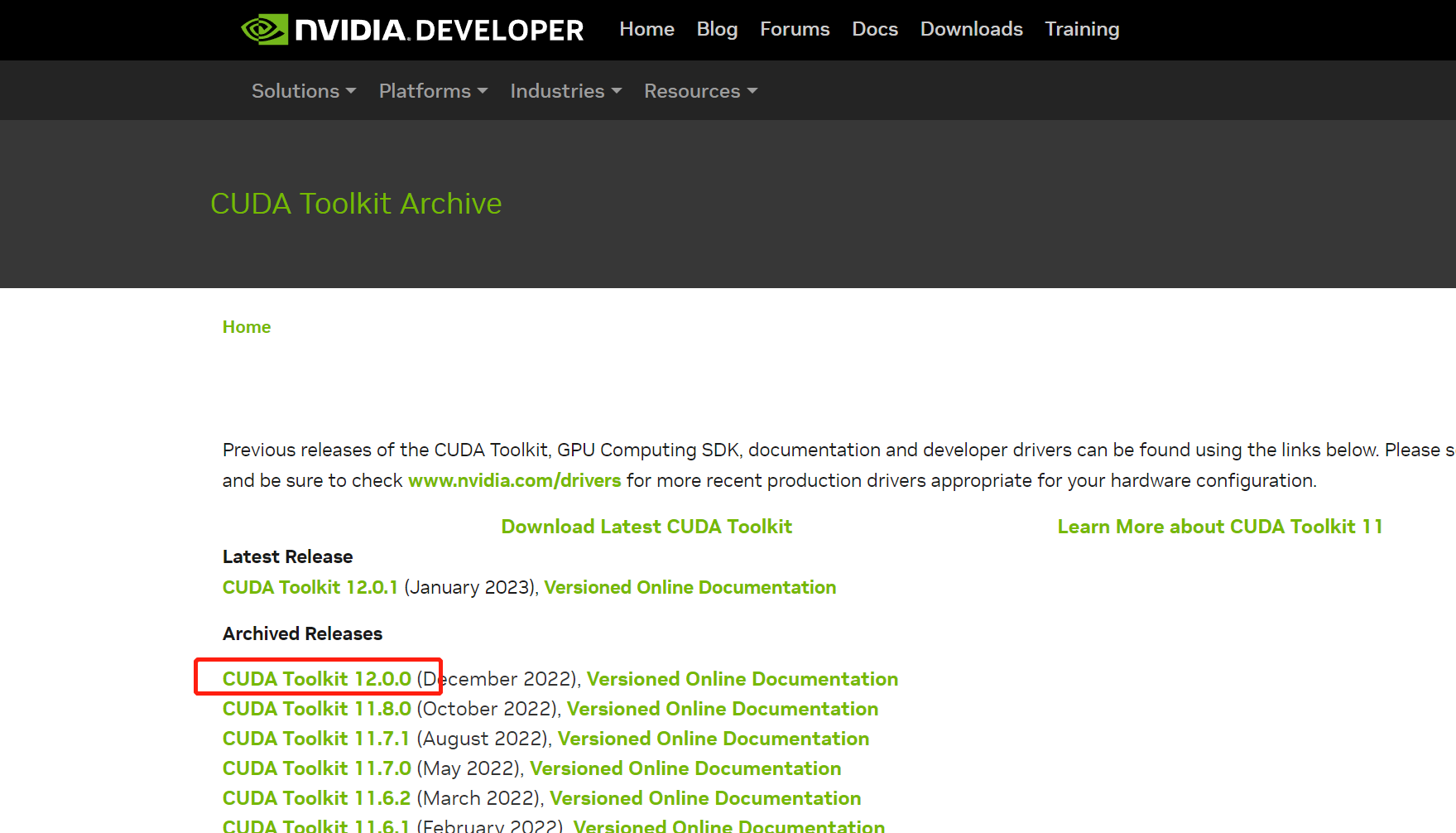
下载完成后安装到默认目录就行,一般是安装在C:\Program Files\NVIDIA GPU Computing Toolkit,如下图:
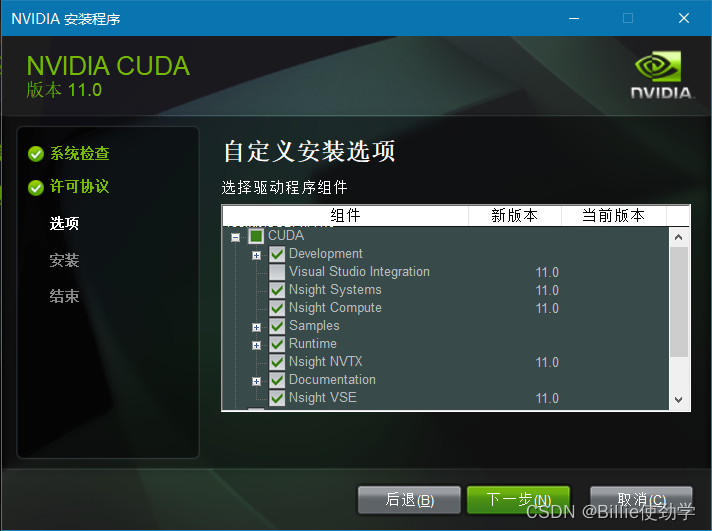
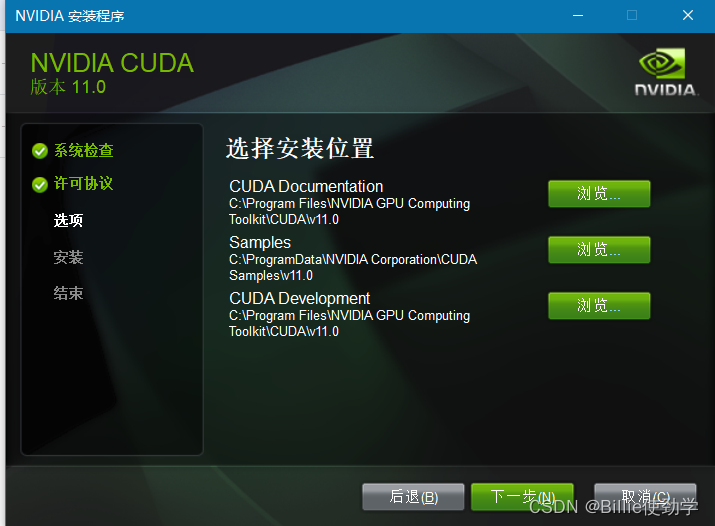
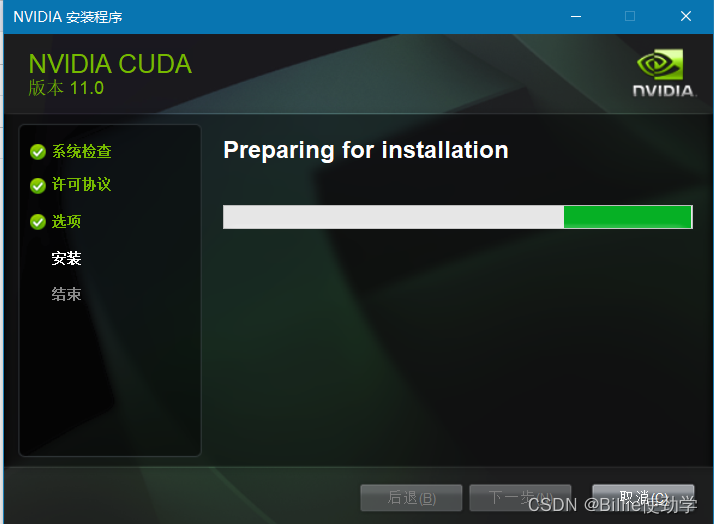
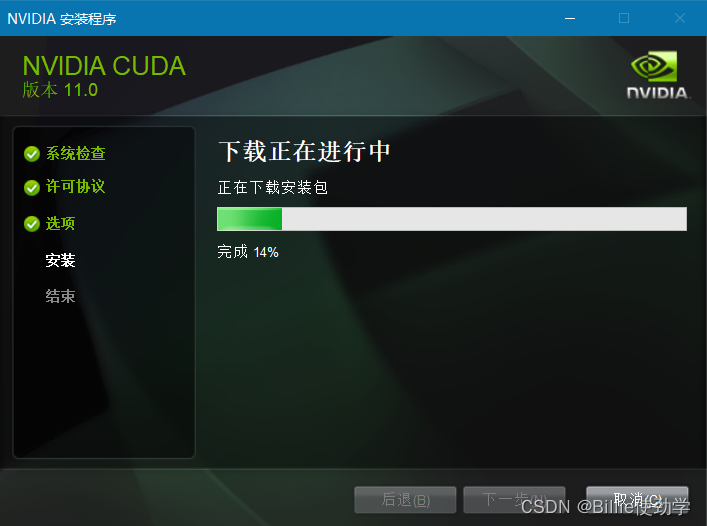
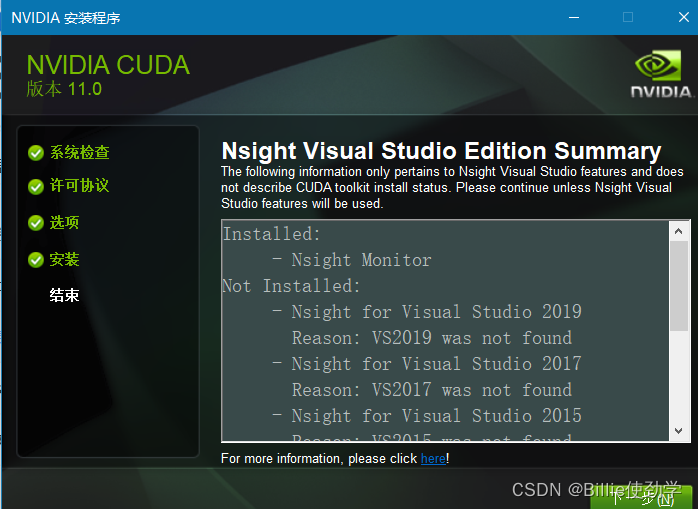
安装完成后在到https://developer.nvidia.com/rdp/cudnn-download去下载cudnn
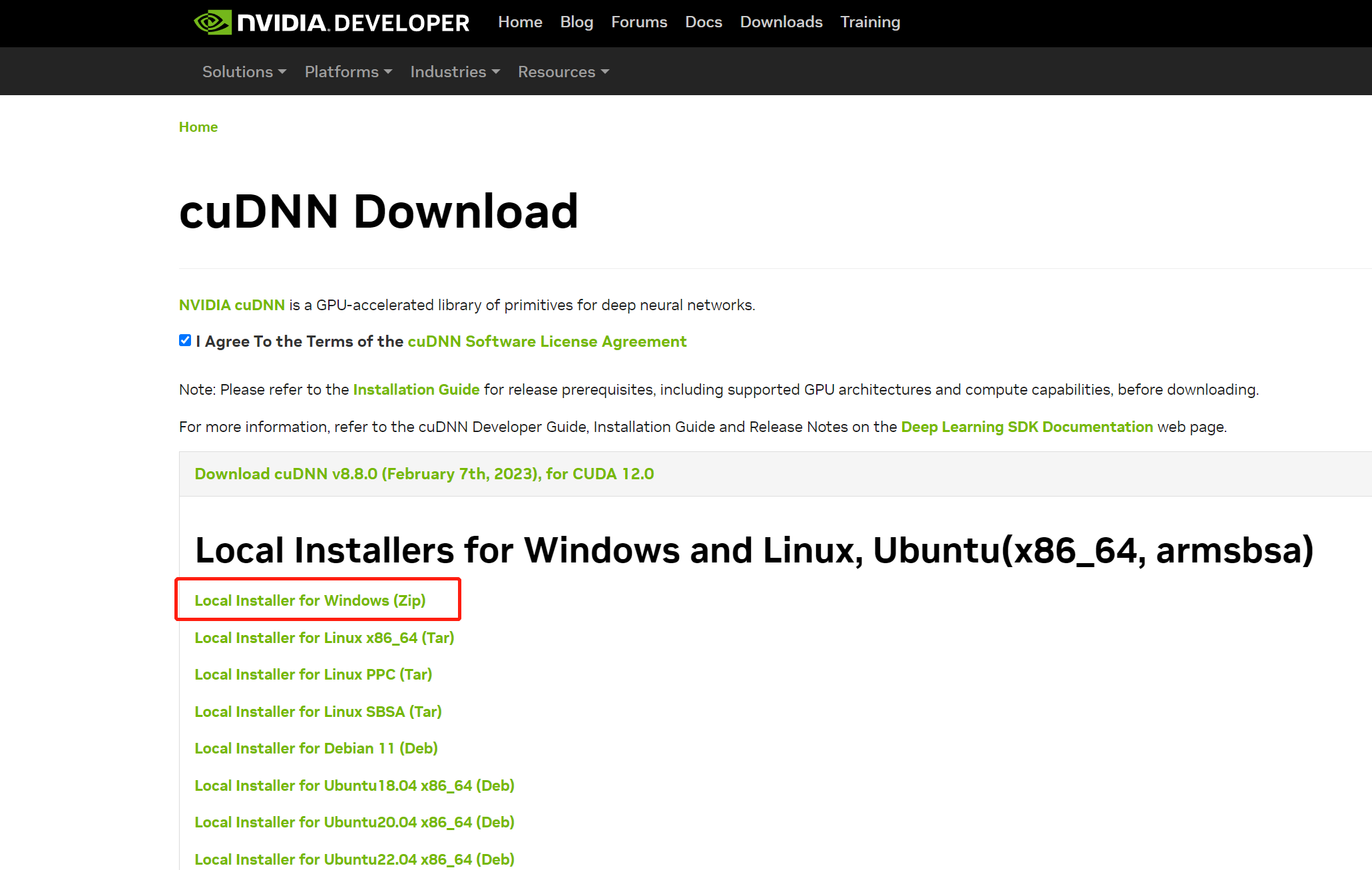
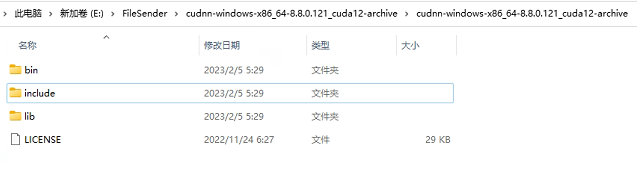
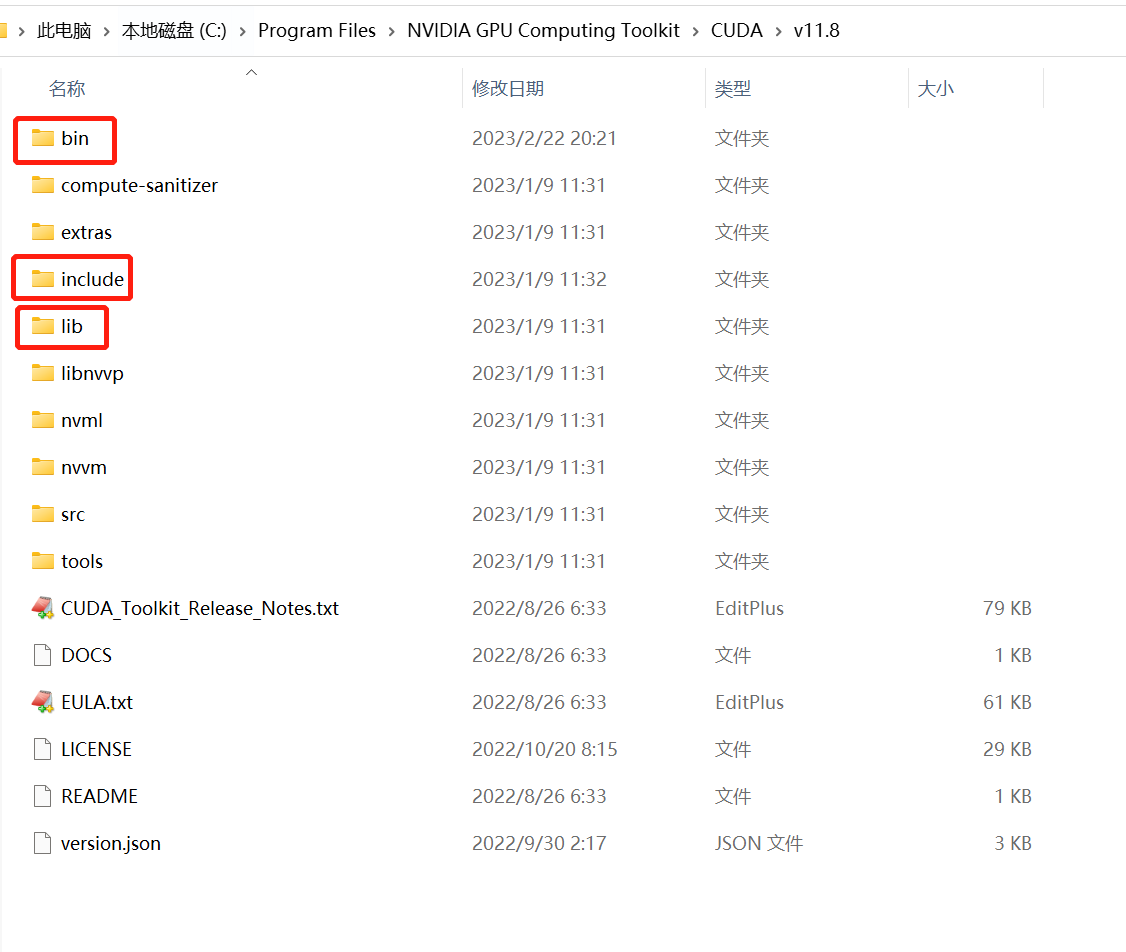
下载完成后解压缩,把解压缩后的目录cudnn-windows-x86_64-8.8.0.121_cuda12-archive下的bin、include、lib三个目录里的文件分别复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8的bin、include、lib三个目录里。如下图:
最后到https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows下载ZLIB.DLL。如下图:
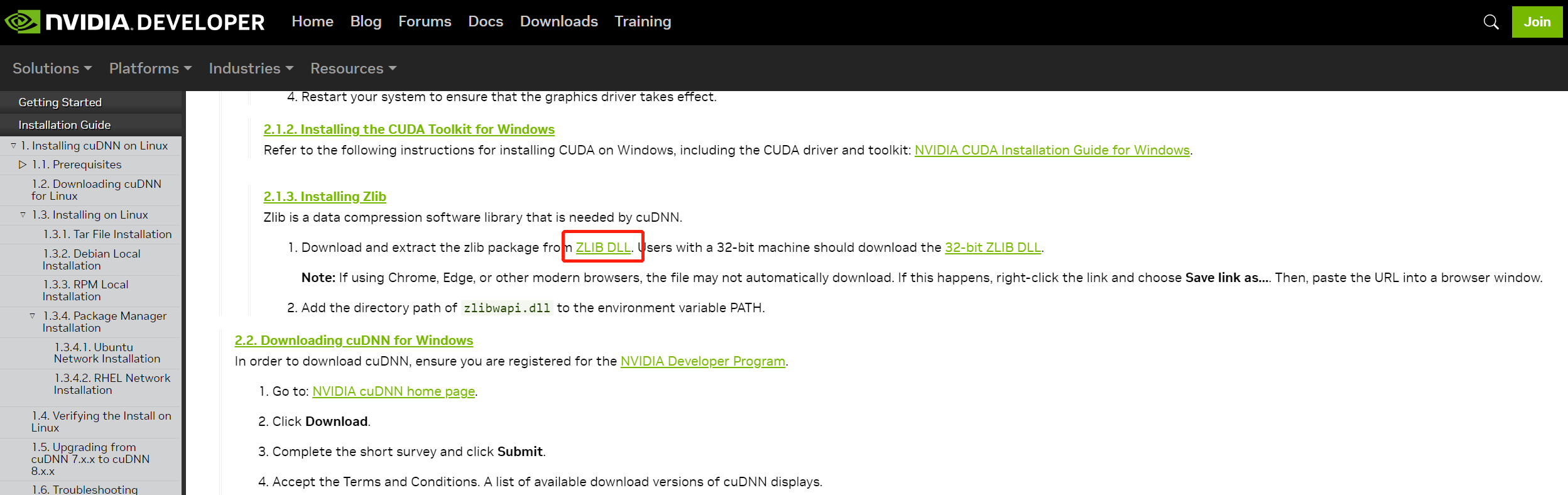
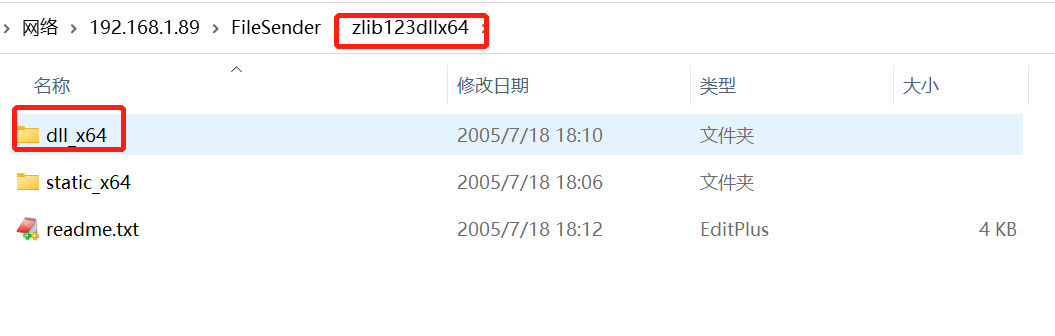
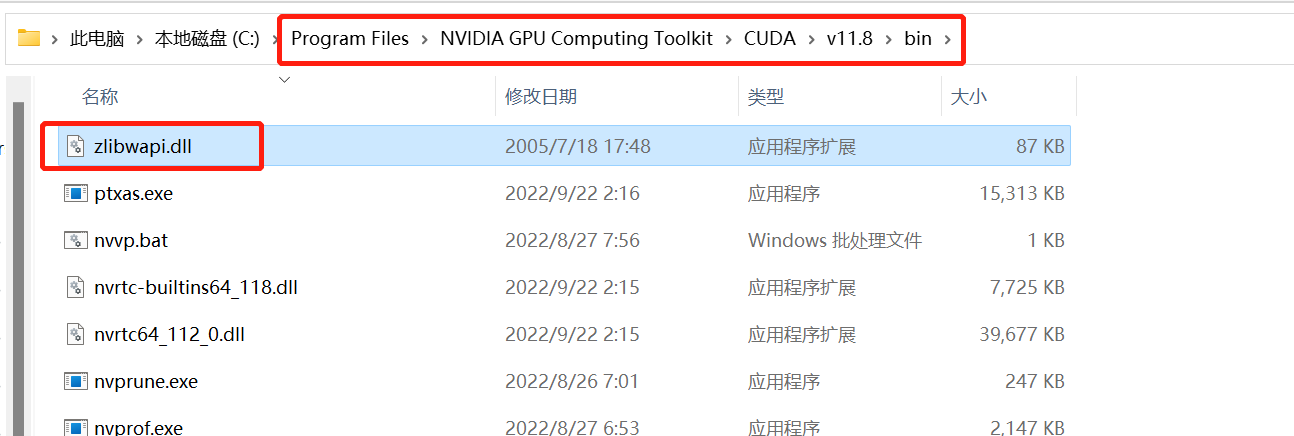
下载完成后解压缩,把解压后zlib123dllx64\dll_x64\zlibwapi.dll文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin目录下

现在,在train1.py目录下执行:python train1.py
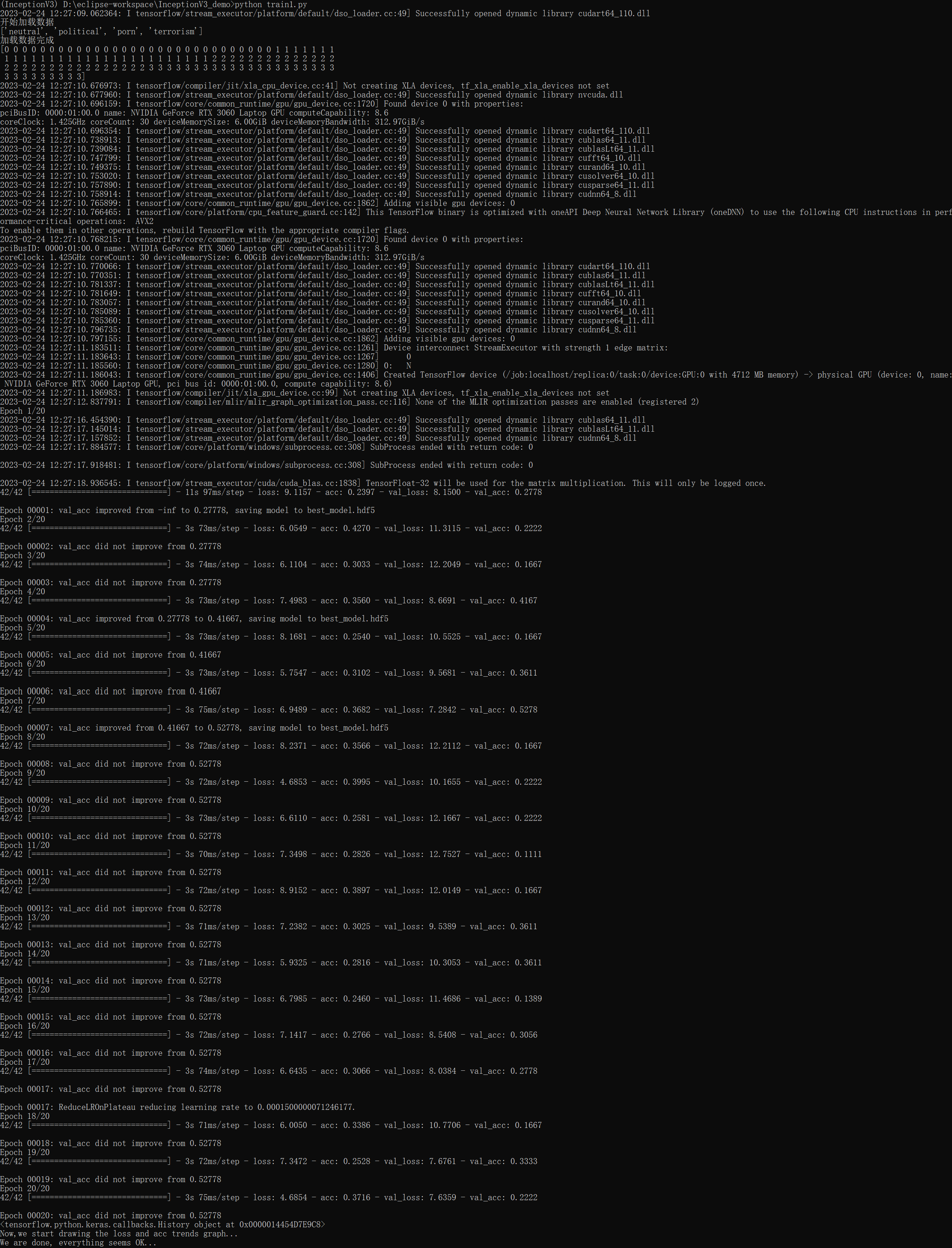
可以看一下任务管理器,压力应该都在GPU上:
16、训练完成后,可以看到train1.py目录下多了几个文件,如下图:
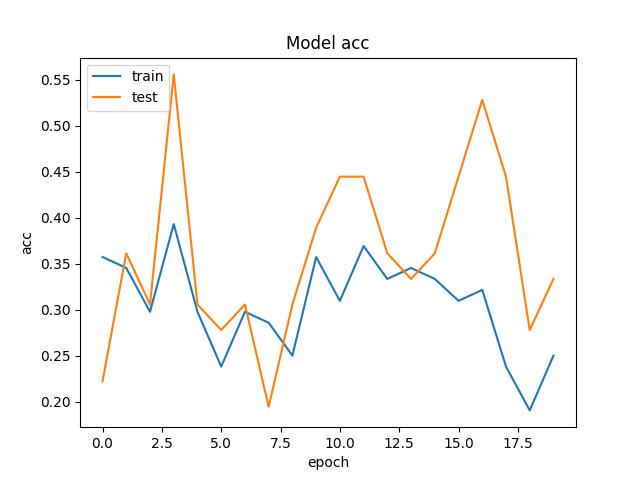
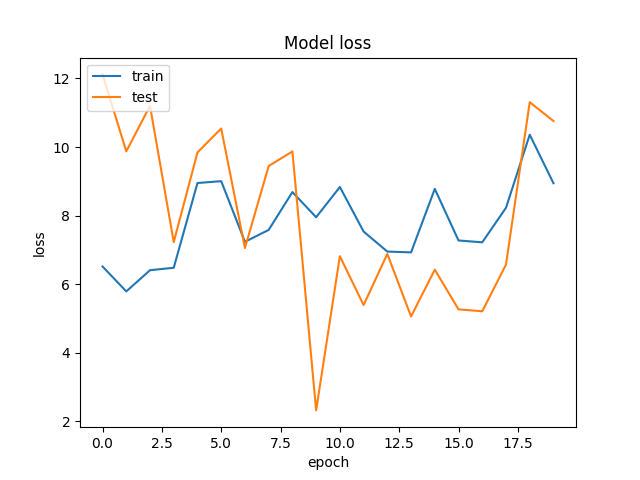
其中my_model.h5就是咱们训练出来的模型文件。WW_acc.jpg和WW_loss.jpg是训练结果保存的图,看了一下觉得还不错。
17、接下来要验证一下模型的效果,现在data\test\放一张用于预测的图。如下图:
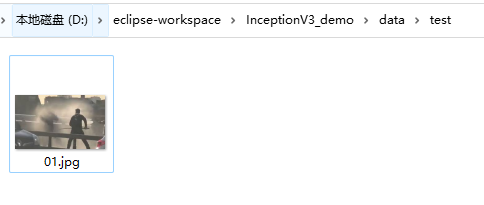
18、下面是测试代码,文件名是test.py:
import cv2
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import time
import albumentations
norm_size = 224
imagelist = []emotion_labels = {0: 'neutral',1: 'political',2: 'porn',3: 'terrorism',
}val_transform = albumentations.Compose([albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)])
emotion_classifier = load_model("best_model.hdf5")
t1 = time.time()
image = cv2.imdecode(np.fromfile('data/test/01.jpg', dtype=np.uint8), -1)
image = val_transform(image=image)['image']
image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)
image = img_to_array(image)
imagelist.append(image)
imageList = np.array(imagelist, dtype="float")
out = emotion_classifier.predict(imageList)
print(out)
pre = np.argmax(out)
emotion = emotion_labels[pre]
t2 = time.time()
print(emotion)
t3 = t2 - t1
print(t3)其中emotion_labels是分类,填上与训练文件中一致的内容。
在image = cv2.imdecode(np.fromfile('data/test/01.jpg', dtype=np.uint8), -1)这行修改路径,指向到用于预测的图片位置。
19、执行python test.py
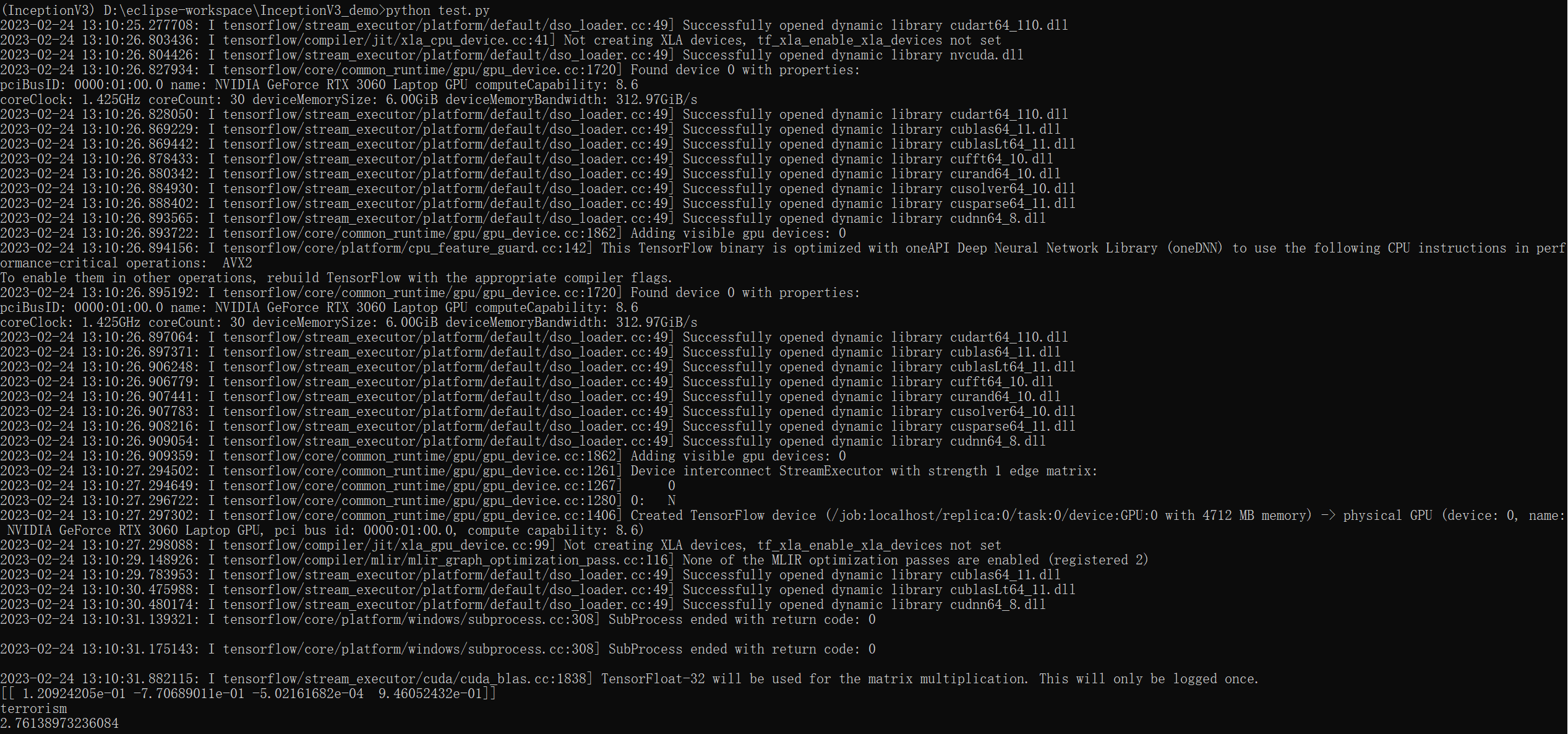
可以看到,data/test/01.jpg被预测成为terrorism,验证正确。至此大功告成。
后记:我是python的领域的新兵,在开发过程中遇到最麻烦的事情就是版本的问题。tensorflow最新版本已经2.11.0了,但是使用起来会有各种问题。我尝试了很多版本,查了不少资料,最后才确定了能用的这个组合。尤其是过程中gpu一直利用不上,程序总是使用cpu在训练,经过一顿折腾总算是能用了,但是为什么这么组合,我也没有找到一个清晰的说明,希望能有大神能给解释一下CUDA、Cudnn、tensorflow、tensorflow-gpu的版本怎么组合最合理。下面把我虚拟环境的配置发上来供大家参考:
Package Version
----------------------- ---------
absl-py 0.15.0
albumentations 1.2.0
astor 0.8.1
astunparse 1.6.3
cachetools 5.3.0
certifi 2022.12.7
charset-normalizer 3.0.1
cycler 0.11.0
flatbuffers 1.12
fonttools 4.38.0
gast 0.3.3
google-auth 2.16.1
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
grpcio 1.32.0
h5py 2.10.0
idna 3.4
imageio 2.25.1
importlib-metadata 6.0.0
joblib 1.2.0
keras 2.6.0
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
kiwisolver 1.4.4
Markdown 3.4.1
MarkupSafe 2.1.2
matplotlib 3.5.3
networkx 2.6.3
numpy 1.19.5
oauthlib 3.2.2
opencv-python 4.7.0.68
opencv-python-headless 4.7.0.68
opt-einsum 3.3.0
packaging 23.0
Pillow 9.4.0
pip 22.3.1
protobuf 3.19.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.9
python-dateutil 2.8.2
PyWavelets 1.3.0
PyYAML 6.0
qudida 0.0.4
requests 2.28.2
requests-oauthlib 1.3.1
rsa 4.9
scikit-image 0.18.3
scikit-learn 1.0.2
scipy 1.7.3
setuptools 65.6.3
six 1.15.0
tensorboard 2.11.2
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorflow 1.14.0
tensorflow-estimator 2.4.0
tensorflow-gpu 2.4.0
tensorflow-hub 0.9.0
termcolor 1.1.0
threadpoolctl 3.1.0
tifffile 2021.11.2
typing-extensions 3.7.4.3
urllib3 1.26.14
Werkzeug 2.2.3
wheel 0.38.4
wincertstore 0.2
wrapt 1.12.1
zipp 3.14.0相关文章:
利用InceptionV3实现图像分类
最近在做一个机审的项目,初步希望实现图像的四分类,即:正常(neutral)、涉政(political)、涉黄(porn)、涉恐(terrorism)。有朋友给推荐了个github上…...
【Java】CAS锁
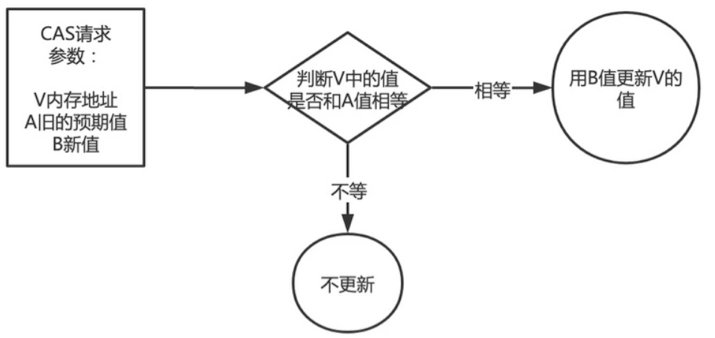
一、什么是CAS机制(compare and swap) 1.概述 CAS的全称为Compare-And-Swap,直译就是对比交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值。经过调查发现,…...

Linux服务器配置系统安全加固方法
1. SSH空闲超时时间建议为: 600-900 解决方案: 在【/etc/ssh/sshd_config】文件中设置【ClientAliveInterval】设置为600到900之间 vim /etc/ssh/sshd_config #将 ClientAliveInterval 参数值设置为 900 2. 修改检查SSH密码修改最小间隔 解决方案: 在【/etc/login.defs】文件…...

Codeforces Round #850 (Div. 2, based on VK Cup 2022 - Final Round)(A~E)
t宝酱紫喜欢出这种分类讨论的题?!A1. Non-alternating Deck (easy version)给出n张牌,按照题目给的顺序分给两人,问最后两人手中各有几张牌。思路:模拟。AC Code:#include <bits/stdc.h>typedef long…...
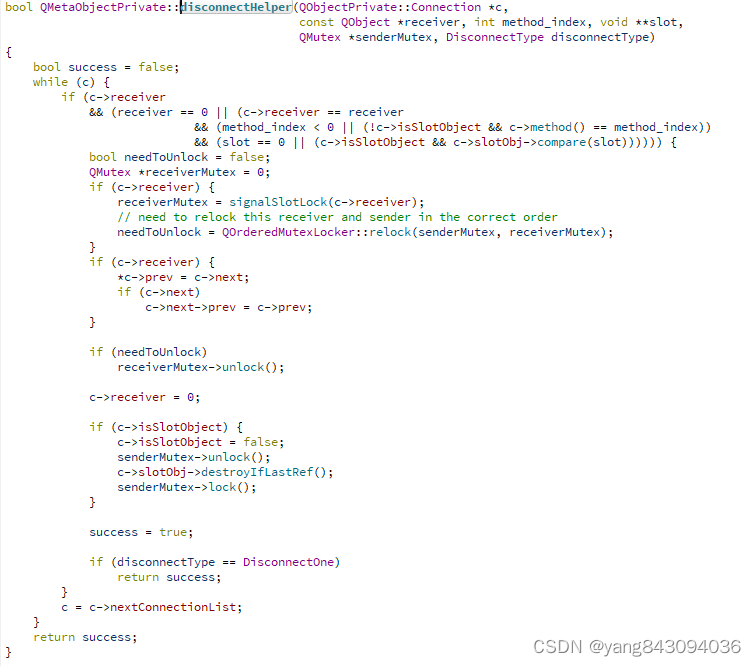
qt源码--信号槽
本篇主要从Qt信号槽的连接、断开、调用、对象释放等方面展开; 1.信号建立连接过程 connect有多个重载函数,主要是为了方便使用者,比较常用的有2种方式: a. QObject::connect(&timer, &QTimer::timeout, &loop, &am…...
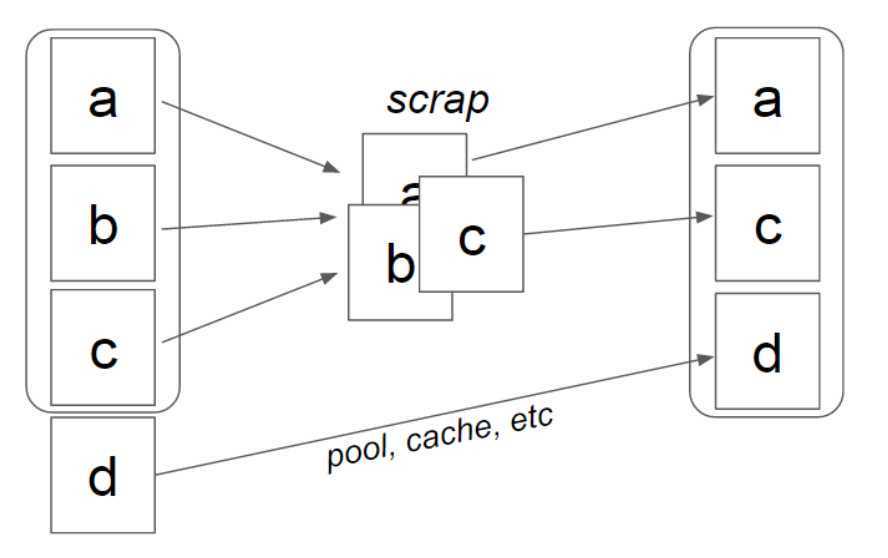
RecycleView详解
listview缓存请看: listview优化和详解RecycleView 和 ListView对比:使用方法上ListView:继承重写 BaseAdapter,自定义 ViewHolder 与 converView优化。RecyclerView: 继承重写 RecyclerView.Adapter 与 RecyclerView.ViewHolder。设置 Layou…...

【算法】最短路算法
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...

< Linux > 进程间通信
目录 1、进程间通信介绍 进程间通信的概念 进程间通信的本质 进程间通信的分类 2、管道 2.1、什么是管道 2.2、匿名管道 匿名管道的原理 pipe函数 匿名管道使用步骤 2.3、管道的读写规则 2.4、管道的特点 2.5、命名管道 命名管道的原理 使用命令创建命名管道 mkfifo创建命名管…...

学习 Python 之 Pygame 开发魂斗罗(二)
学习 Python 之 Pygame 开发魂斗罗(二)魂斗罗的需求开始编写魂斗罗1. 搭建主类框架2. 设置游戏运行遍历和创建窗口3. 获取窗口中的事件4. 创建角色5. 完成角色更新函数魂斗罗的需求 魂斗罗游戏中包含很多个物体,现在要对这些物体进行总结 类…...
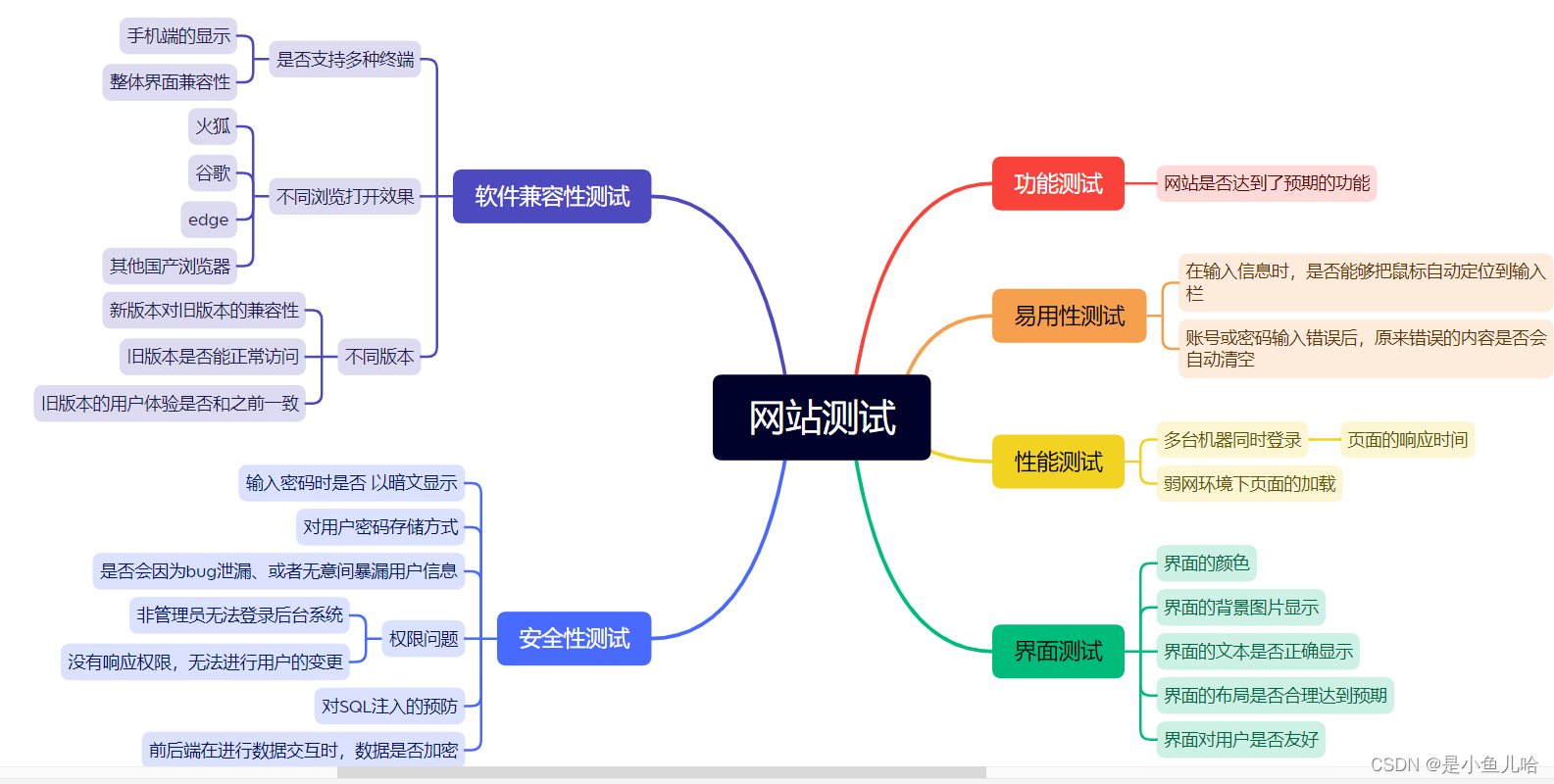
户籍管理系统测试用例
目录 一、根据页面的不同分别设计测试用例 登录页面 用户信息列表 用户编辑页面 用户更新页面 二、根据目的不同分别设计测试用例 一、根据页面的不同分别设计测试用例 上图是针对一个网站的测试,按照页面的不同分别来设计对应的测试用例。 登录页面 用户信息列…...
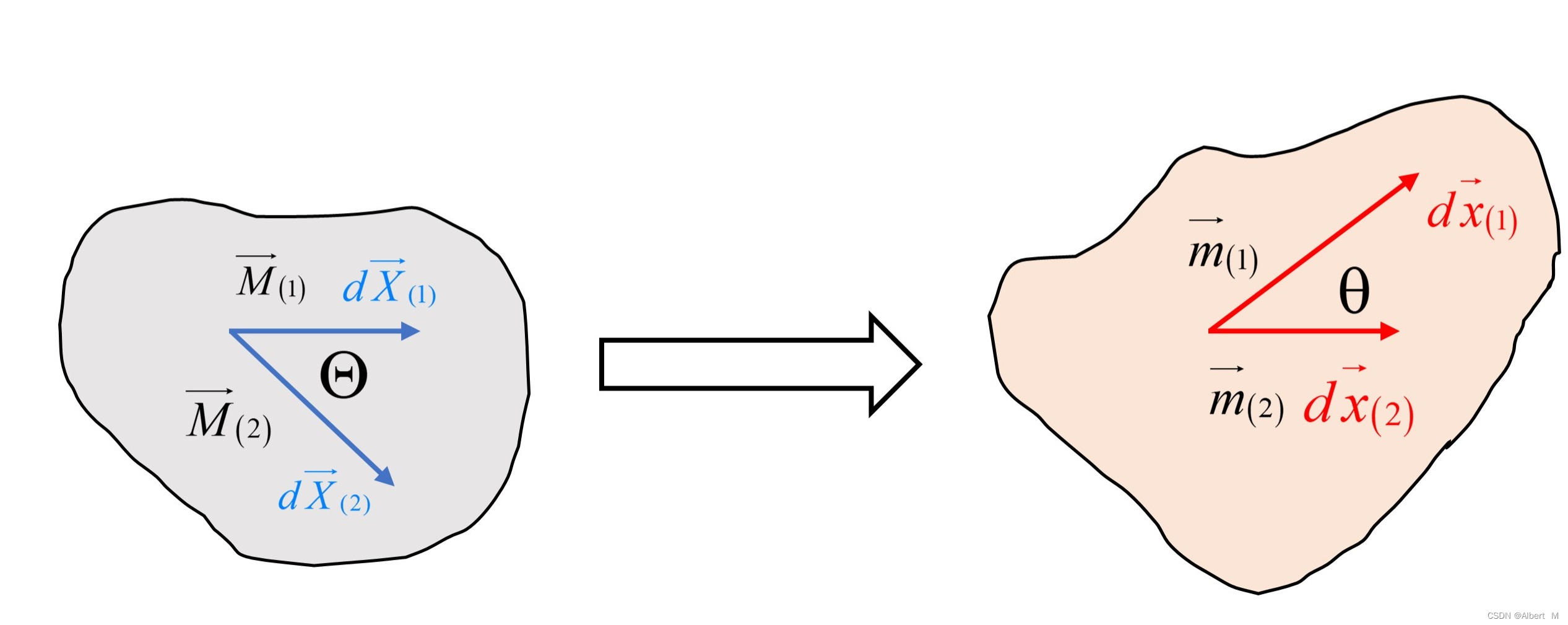
(三)代表性物质点邻域的变形分析
本文主要内容如下:1. 伸长张量与Cauchy-Green 张量2. 线元长度的改变2.1. 初始/当前构型下的长度比2.2. 主长度比与 Lagrange/Euler 主方向2.3. 初始/当前构型下任意方向的长度比3. 线元夹角的改变4. 面元的改变5. 体元的改变1. 伸长张量与Cauchy-Green 张量 由于变…...
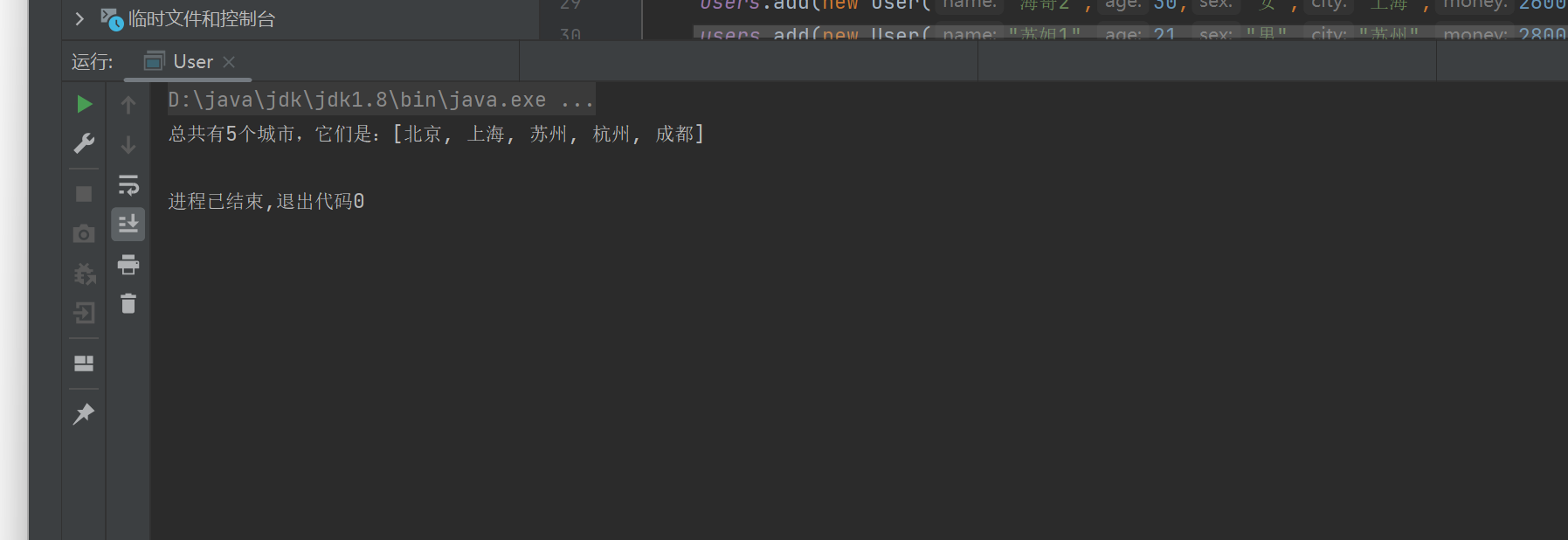
Stream操作流 练习
基础数据:Data AllArgsConstructor NoArgsConstructor public class User {private String name;private int age;private String sex;private String city;private Integer money; static List<User> users new ArrayList<>();public static void m…...

【模拟集成电路】宽摆幅压控振荡器(VCO)设计
鉴频鉴相器设计(Phase Frequency Detector,PFD)前言一、VCO工作原理二、VCO电路设计VCO原理图三、压控振荡器(VCO)测试VCO测试电路图瞬态测试(1)瞬态输出(2)局部放大图&a…...

《英雄编程体验课》第 13 课 | 双指针
文章目录 零、写在前面一、最长不重复子串1、初步分析2、朴素算法3、优化算法二、双指针1、算法定义2、算法描述3、条件1)单调性2)时效性三、双指针的应用1、前缀和问题2、哈希问题3、K 大数问题零、写在前面 该章节节选自 《夜深人静写算法》,主要讲解最基础的枚举算法 ——…...

DS期末复习卷(十)
一、选择题(24分) 1.下列程序段的时间复杂度为( A )。 i0,s0; while (s<n) {ssi;i;} (A) O(n^1/2) (B) O(n ^1/3) © O(n) (D) O(n ^2) 12…xn xn^1/2 2.设某链表中最常用的…...

QT+OpenGL模板测试和混合
QTOpenGL模板测试和混合 本篇完整工程见gitee:QtOpenGL 对应点的tag,由turbolove提供技术支持,您可以关注博主或者私信博主 模板测试 当片段着色器处理完一个片段之后,模板测试会开始执行。和深度测试一样,它可能会丢弃片段&am…...

《英雄编程体验课》第 11 课 | 前缀和
文章目录 零、写在前面一、概念定义1、部分和2、朴素做法3、前缀和4、前缀和的边界值5、边界处理6、再看部分和二、题目描述1、定义2、求解三、算法详解四、源码剖析五、推荐专栏六、习题练习零、写在前面 该章节节选自 《算法零基础100讲》,主要讲解最基础的算法 —— 前缀和…...

Java学习--多线程2
2.线程同步 2.1卖票【应用】 案例需求 某电影院目前正在上映国产大片,共有100张票,而它有3个窗口卖票,请设计一个程序模拟该电影院卖票 实现步骤 定义一个类SellTicket实现Runnable接口,里面定义一个成员变量:privat…...
【Virtualization】Windows11安装VMware Workstation后异常处置
安装环境 Windows 11 专业版 22H2 build 22621.1265 VMware Workstation 17 Pro 17.0.0 build-20800274 存在问题 原因分析 1、BIOS未开启虚拟化。 2、操作系统启用的虚拟化与Workstation冲突。 3、操作系统启用内核隔离-内存完整性保护。 处置思路 1、打开“资源管理器”…...
第四章.神经网络—BP神经网络
第四章.神经网络 4.3 BP神经网络 BP神经网络(误差反向传播算法)是整个人工神经网络体系中的精华,广泛应用于分类识别,逼近,回归,压缩等领域,在实际应用中,大约80%的神经网络模型都采用BP网络或BP网络的变化…...

避坑!STM32CubeIDE偏好设置改了回不去?这份备份与恢复攻略请收好
STM32CubeIDE配置管理实战:从个人备份到团队协作的最佳实践 引言 当你花了整个下午精心调整STM32CubeIDE的代码配色方案,却发现某个关键语法高亮突然失效;当团队新成员反复询问如何统一代码格式化规则;当更换电脑后不得不重新配置…...

极域电子教室破解指南:快速恢复电脑控制权的完整方案
极域电子教室破解指南:快速恢复电脑控制权的完整方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾经在学校的计算机教室中,面对被极域电子教室…...

C++11、C++14、C++17、C++20常用新特性
C11自动类型推断(auto关键字):C11引入了auto关键字,可以根据变量初始值自动推导出变量类型。例如:12auto i 42; // i被推导为int类型auto d 3.14; // d被推导为double类型基于范围的for循环(range-base…...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...

在VS Code中结合Taotoken API快速构建代码辅助工具
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在VS Code中结合Taotoken API快速构建代码辅助工具 对于希望提升编码效率的开发者而言,将AI能力深度集成到日常开发环境…...

为Claude Code配置Taotoken聚合API密钥与Base地址避免封号风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken聚合API密钥与Base地址避免封号风险 在使用Claude Code这类编程助手工具时,开发者有时会遇到…...

Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现
Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug …...

Unitree GO2四足机器人ROS2开发终极指南:从零到自主导航的完整教程
Unitree GO2四足机器人ROS2开发终极指南:从零到自主导航的完整教程 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk 你是否曾经梦想过让四足机器人像真实…...
)
2026毕业季硕士论文AIGC检测率合格标准全汇总(20%还是15%)
2026年硕士论文答辩前,AIGC检测已经和查重一样成了必过流程。但各校对硕士论文AIGC检测率的合格标准并不统一——有的学校要求20%以下,有的15%以下,个别学校甚至要求10%以下。 你的学校硕士论文AIGC检测率多少算合格?超标了怎么快…...
)
40岁IT运维被裁了,换赛道!一切皆有可能(普通人可借鉴)
40岁IT运维被裁了,换赛道!一切皆有可能(普通人可借鉴) 外人总觉得做IT很轻松,敲敲键盘就能赚钱。只有业内人清楚,这行根本藏不住焦虑。技术更新太快。 40岁的职业红线,一直压在所有IT人身上。…...