【Mysql】InnoDB数据页结构(五)
概述
页是InnoDB存储引擎管理存储空间的基本单位,一个页的大小默认是16KB 。InnoDB 为了不同的目的而设计了许多种不同类型的页 ,比如存放记录的索引页,存放表空间头部信息的页,存放 Insert Buffer信息的页,存放 INODE 信息的页,存放 undo 日志信息的页等等。在这我们主要关注的是存放我们表中记录的那种类型的页,官方称这种存放记录的页为索引( INDEX )页,其实这些页中的记录就是我们存储的数据记录 ,所以这种存放记录的页也可以称为数据页。
数据页结构简介
数据页代表的这块默认的16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示:
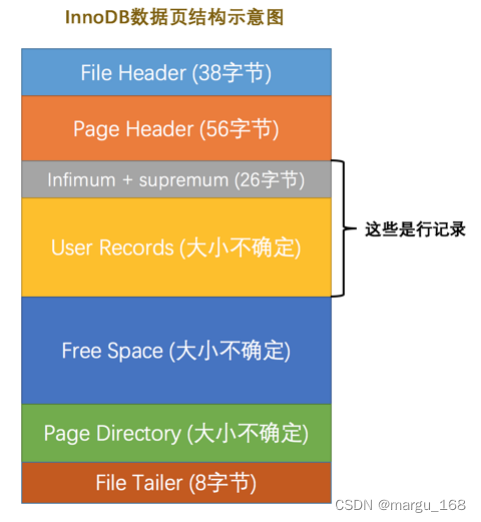
从上图可以看出,一个 InnoDB 数据页的存储空间大致被划分成了 7 个部分,有的部分占用的字节数是确定的,有的部分占用的字节数是不确定的。各部分的介绍如下表:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38 字节 | 页的一些通用信息 |
| Page Header | 页面头部 | 56 字节 | 数据页专有的一些信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26 字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8 字节 | 校验页是否完整 |
记录在页中的存储
在页的7个组成部分中,用户数据会按照我们指定的行格式存储到 User Records 部分。但是在一开始生成页的时候,其实并没有 User Records 这个部分,每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了,这个过程的图示如下: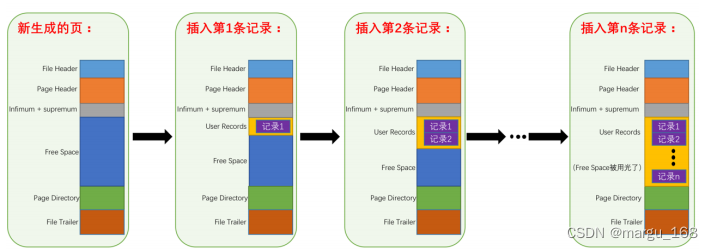
InnoDB如何存放一条一条的记录信息,并能准群的找到它的上一页下一页的位置,这些都是通过记录头信息实现的。
记录头信息分析
为方便测试说明,先创建一个测试表:
mysql> create table page_demo(c1 int,c2 int ,c3 varchar(1000),primary key(c1)) charset=ascii row_format=compact;
Query OK, 0 rows affected (0.09 sec)
这个新创建的表有3个列,其中c1和c2列用来存储整数,c3列用来存储字符串。注意,上面已经把c1列指定为主键,所以在具体的行格式中InnoDB就没必要为再去创建 row_id 这个隐藏列。此外为这个表指定了ascii字符集以及Compact 的行格式。所以这个表中记录的行格式示意图大致如下:
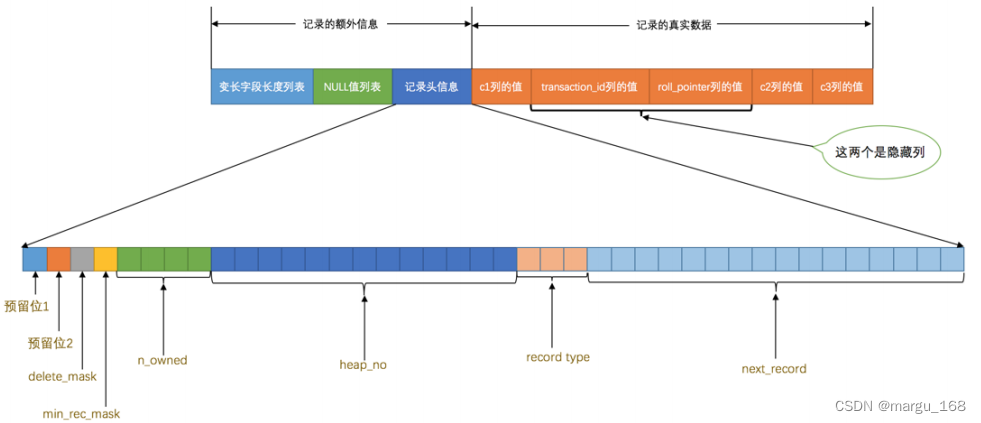
从图中可以看到记录额外信息中记录头信息是5个字节共包括8个属性(以compact 行格式为例),包括的属性大致说明如下:
| 名称 | 大小 | (单位:bit)描述 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数(以组统计最后一行表示) |
| heap_no | 13 | 表示当前记录在记录堆的位置信息 |
| record_type | 3 | 表示当前记录的类型, 0 表示普通记录, 1 表示B+树非叶节点记录, 2 表示最小记录, 3表示最大记录 |
| next_record | 16 | 表示下一条记录的相对位置 |
我们往page_demo 表中插入几条记录:
mysql> insert into page_demo values(1,100,'aaaa'),(2,200,'bbbb'),(3,300,'cccc'),(4, 400, 'dddd');
Query OK, 4 rows affected (0.07 sec)
Records: 4 Duplicates: 0 Warnings: 0
为了方便分析这些记录在页的User Records 部分中是怎么表示的,此处把记录中头信息和实际的列数据都用十进制表示出来了(其实真实是一堆二进制),然后这些记录的示意图如下:

注意,各条记录在 User Records 中存储的时候并没有空隙,这里只是为了观看方便才把每条记录单独画在一行。我们对照着这个图来看看记录头信息中的各个属性的用途:
- delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,0代表记录没有被删除,1代表记录被删除。
注意:如何理解被删除的记录还在页中?这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表 ,在这个链表中的记录占用的空间称之为所谓的可重用空间 ,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。 - min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记,上面自己插入的四条记录的 min_rec_mask 值都是 0 ,意味着它们都不是 B+ 树的非叶子节点中的最小记录。 - n_owned
表示当前记录拥有的记录数,记录以组进行划分,每组最后一行的n_owned表示当前分组的记录数 - heap_no
这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本 页 中的位置分别是: 2 、3 、4 、5 。是不是比较奇怪?是的,怎么不见 heap_no 值为 0 和 1 的记录呢?
这其实是 InnoDB在存储数据时会自动给每个页里边加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录 。这两个伪记录一个代表最小记录 ,一个代表最大记录 。对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是: 1 、2 、3 、4 ,这也就意味着这4条记录的大小从小到大依次递增。
注意:此处是对某一页能够一条完整的记录来说,比较记录的大小就相当于比的是主键的大小。后边我们还会遇到只存储一条记录的部分列的情况,后续再做分享。
但是不管我们向页中插入了多少自己的记录,InnoDB规定他们都会在页中插入两条伪记录分别为最
小记录与最大记录。这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的,如下图所示:
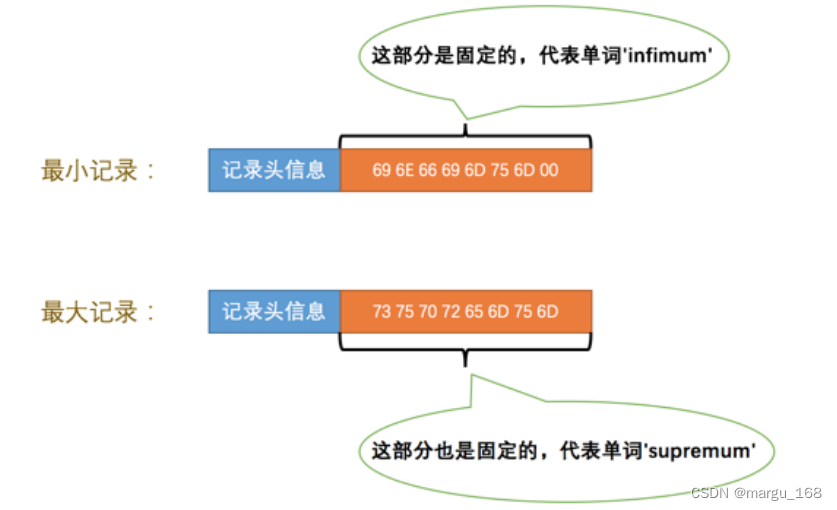
由于这两条记录不是我们自己的数据记录,所以它们并不存放在页的 User Records 部分,他们被单独放在一个称为 Infimum + Supremum 的部分,如图所示:

从上图我们可以看到,最小记录和最大记录的 heap_no 值分别是 0 和 1 ,也就是说它们的位置最靠前。
- record_type
这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3 表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type 值都是 0 ,而最小记录和最大记录的 record_type 值分别为 2 和 3 。record_type 为1是表示目录项记录,我们后续在说索引的时候会详细说明。 - next_record
它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的next_record 值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。所有的数据会构成一个链表 ,可以通过一条记录找到它的下一条记录。但需要注意的是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录,为了更形象的表示一下这个next_record 起到的作用,我们用箭头来替代一下next_record 中的地址偏移量:
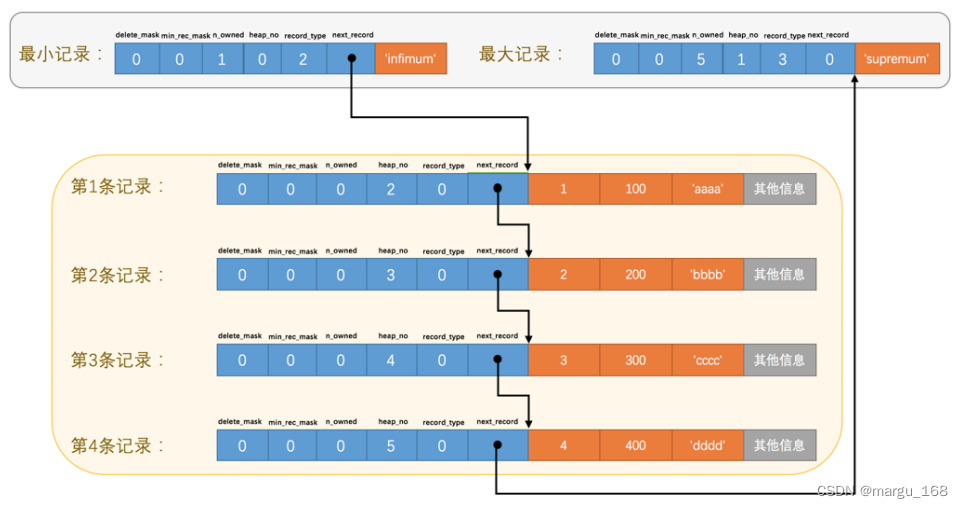
从图中可以看出来,我们的记录按照主键从小到大的顺序形成了一个单链表。最大记录的next_record 的值为 0 ,这也就是说最大记录是没有 下一条记录 了,它是这个单链表中的最后一个节点。如果从中删除掉一条记录,这个链表也是会跟着变化的,比如我们把第2条记录删掉:
mysql> delete from page_demo where c1 = 2;
Query OK, 1 row affected (0.04 sec)
删掉第2条记录后的示意图会变成如下:
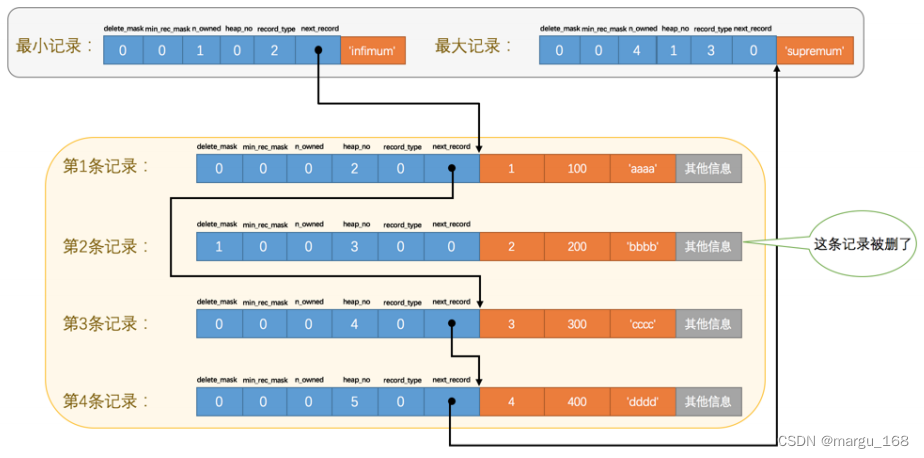
从图中可以看出来,删除第2条记录前后主要发生了这些变化:
- 第2条记录并没有从存储空间中移除,而是把该条记录的 delete_mask 值设置为 1 。
- 第2条记录的 next_record 值变为了0,意味着该记录没有下一条记录了。
- 第1条记录的 next_record 指向了第3条记录。
- 还有一点你可能忽略了,就是最大记录 的 n_owned 值从5变成了4 ,关于这一点的变化后续详细说明的。所以,不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
注意:next_record这个指针为啥是指向记录头信息和真实数据之间的位置呢?为啥不干脆指向整条记录的开头位置,也就是记录的额外信息开头的位置呢? 因为这个位置刚刚好,向左读取就是记录头信息,向右读取就是真实数据。我们前边还说过compact行格式中变长字段长度列表、NULL值列表中的信息都是逆序存放,这样可以使记录中位置靠前的字段和它们对应的字段长度信息在内存中的距离更近,可能会提高高速缓存的命中率。
上面,因为主键值为 2 的记录被我们删掉了,但是存储空间却没有回收,如果我们很快再次把这条记录又插入到表中,会发生什么事呢?
mysql> insert into page_demo values(2, 200, 'bbbb');
Query OK, 1 row affected (0.03 sec)
记录的存储情况会变成如下所示:
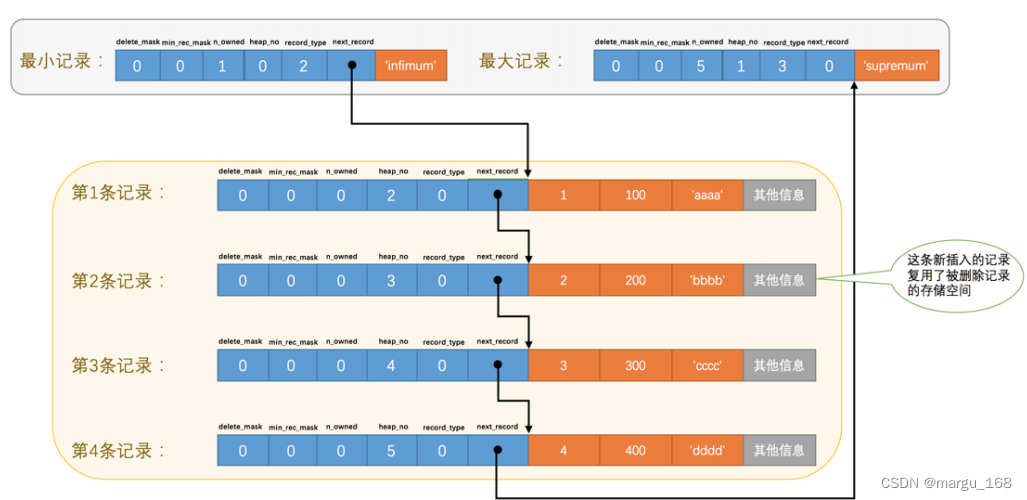
从上图可以看到,InnoDB 并没有因为新记录的插入而为它申请新的存储空间,而是直接复用了原来被删除记录的存储空间。
注意:当数据页中存在多条被删除掉的记录时,这些记录的next_record属性将会把这些被删除掉的记录组成一个垃圾链表,以备之后重用这部分存储空间。
Page Directory(页目录)
现在我们了解了记录在页中按照主键值由小到大顺序串联成一个单链表,那如果我们想根据主键值查找页中的某条记录该咋办呢?比如说这样的查询语句:
select * from page_demo WHERE c1 = 2;
最笨的办法:从 Infimum 记录(最小记录)开始,沿着链表一直往后找,总会找到(或者找不到,本来就没有),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。
这个方法在页中存储的记录数量比较少的情况影响不大,比方现在我们的表里只有 4 条自己插入的记录,所以最多找4次就可以把所有记录都遍历一遍,但是如果一个页中存储了非常多的记录,这么查找对性能来说还是有损耗的,所以我们说这种遍历查找这是一个笨办法。当然InnoDB是不会这样去查找的。
我们平常想从一本书中查找某个内容的时候,一般会先看目录,找到需要查找的内容对应的书的页码,然后到对应的页码查看内容。InnoDB 其实也有一个类似的目录,它的制作过程如下:
1 .将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组(同一页中的)。
2 .每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的 n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录。
3 .将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的 Page Directory (大小不确定),也就是页目录 。页面目录中的这些地址偏移量被称为槽 (英文名: Slot ),所以这个页面目录就是由槽组成的。
比方说现在的 page_demo 表中正常的记录共有6条, InnoDB 会把它们分成两组,第一组中只有一个最小记录,第二组中是剩余的5条记录,看下边的示意图:
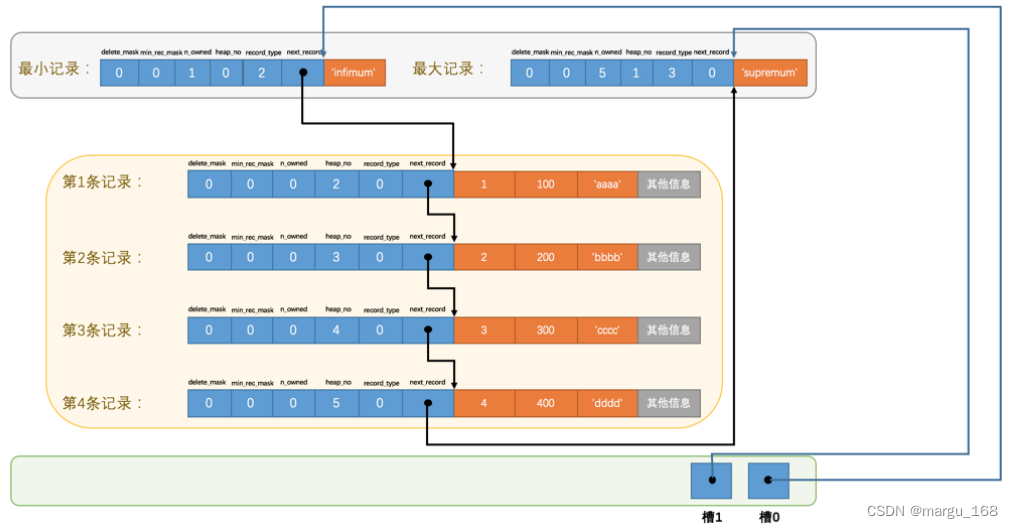
从这个图中我们需要注意这么几点:
-
现在页目录部分中有两个槽,也就意味着我们的记录被分成了两个组,槽0中的值是 99 ,代表最小记录的地址偏移量(就是从页面的0字节开始数,数99个字节);槽1中的值是112 ,代表最大记录的地址偏移量。
-
最小和最大记录的头信息中的 n_owned 属性,也就是各分组中的记录数。
- 最小记录的 n_owned 值为 1 ,这就代表着以最小记录结尾的这个分组中只有1条记录,也就是最小记录本身。
- 最大记录的 n_owned 值为 5 ,这就代表着以最大记录结尾的这个分组中只有5条记录,包括最大记录本身还有我们自己插入的4条记录。
但为什么最小记录的 n_owned 值为1,而最大记录的 n_owned 值为 5 呢,这是怎么得出来的呢?
是由于InnoDB 对每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1 条记录,
最大记录所在的分组拥有的记录条数只能在 1-8条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。
所以分组是按照下边的步骤进行的:
初始情况下一个数据页里只有最小记录和最大记录两条记录,它们分属于两个分组。
之后每插入一条记录,都会从页目录中找到主键值比本记录的主键值大并且差值最小的槽,然后把该槽对应的记录的 n_owned 值加1,表示本组内又添加了一条记录,直到该组中的记录数等于8个。
在一个组中的记录数等于8个后再插入一条记录时,会将组中的记录拆分成两个组,一个组中4条记录,另一个5条记录。这个过程会在页目录中新增一个槽来记录这个新增分组中最大的那条记录的偏移量。由于现在 page_demo 表中的记录太少,无法演示添加了页目录之后加快查找速度的过程,所以再往 page_demo
表中添加一些记录:
mysql> insert into page_demo values(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'),-> (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'l'> lll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp');
Query OK, 12 rows affected (0.02 sec)
Records: 12 Duplicates: 0 Warnings: 0
插入后现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
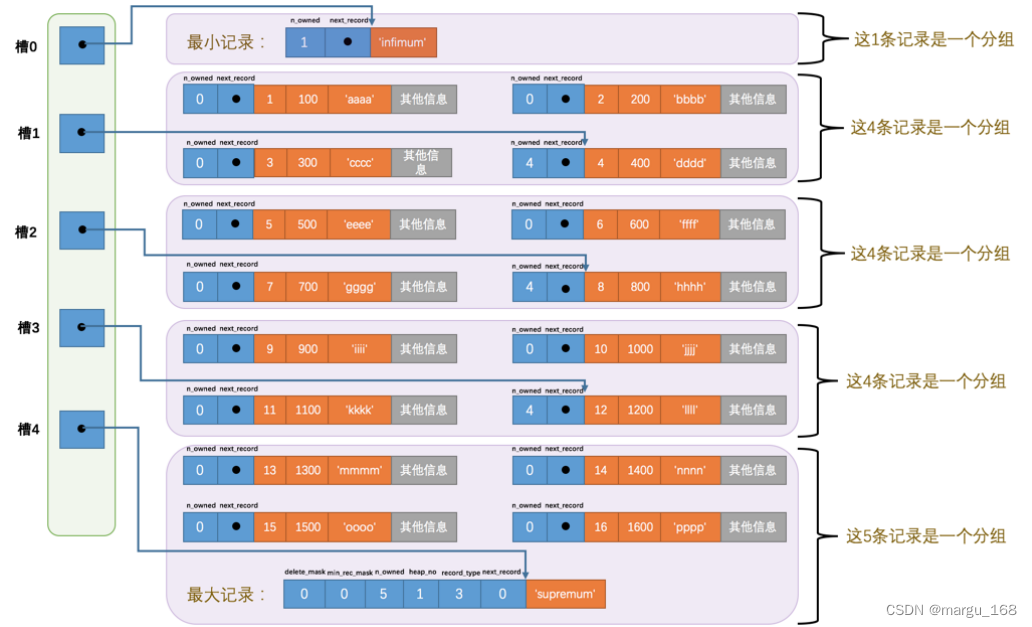
现在看怎么从这个页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的二分法来进行快速查找。4个槽的编号分别是: 0 、1 、2 、3 、4 ,所以初始情况下最低的槽就是 low=0 ,最高的槽就是
high=4 。比方说我们想找主键值为 6 的记录,过程是这样的:
1 . 计算中间槽的位置:(0+4)/2=2 ,所以查看 槽2 对应记录的主键值为8,又因为 8 > 6 ,所以设置
high=2 ,low 保持不变。
2 . 重新计算中间槽的位置:(0+2)/2=1 ,所以查看 槽1 对应的主键值为 4 ,又因为 4 < 6 ,所以置
low=1 ,high 保持不变。
3 . 因为 high - low 的值为1,所以确定主键值为 5 的记录在槽2对应的组中。此刻我们需要找到槽2 中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里 槽2 对应的记录是主键值为 8 的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到槽1对应的记录(主键值为 4 ),该条记录的下一条记录就是槽2中主键值最小的记录,该记录的主键值为 5 。所以我们可以从这条主键值为5的记录出发,遍历槽2中的各条记录,直到找到主键值为6的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以在一个数据页中查找指定主键值的记录的过程分为两步:
- 1 . 通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。
- 2 . 通过记录的 next_record 属性遍历该槽所在的组中的各个记录。
Page Header(页面头部)
InnoDB 为了能得到一个数据页中存储的记录的状态信息,如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽(也就是分了多少个组)等等,特意在页中定义了一个叫 Page Header 的部分,它是页结构的第二部分,这个部分占用固定的 56 个字节,专门存储各种状态信息,具体各个字节作用如下表:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 字节 | 在页目录中的槽数量 |
| PAGE_HEAP_TOP | 2 字节 | 还未使用的空间最小地址,也就是说从该地址之后就是 Free Space |
| PAGE_N_HEAP 2 | 字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE 2 | 字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过 next_record 也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2 字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2 字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 字节 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2 字节 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2 字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8 字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2 字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8 字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10 字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10 字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
其中PAGE_DIRECTION 和 PAGE_N_DIRECTION 的意思如下:
- PAGE_DIRECTION
假如新插入的一条记录的主键值比上一条记录的主键值大,我们说这条记录的插入方向是右边,反之则是左边。用来表示最后一条记录插入方向的状态就是 PAGE_DIRECTION 。 - PAGE_N_DIRECTION
假设连续几次插入新记录的方向都是一致的, InnoDB 会把沿着同一个方向插入记录的条数记下来,这个条数就用 PAGE_N_DIRECTION 这个状态表示。当然,如果最后一条记录的插入方向改变了的话,这个状态的值会被清零重新统计。
File Header(文件头部)
Page Header 是专门针对数据页记录的各种状态信息,比方说页里头有多少个记录,有多少个
槽等。我们现在描述的 File Header 针对各种类型的页都通用,也就是说不同类型的页都会以 File Header 作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是等, 这个部分占用固定的 38 个字节,具体各字节作用如下表:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 字节 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4 字节 | 页号 |
| FIL_PAGE_PREV | 4 字节 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4 字节 | 下一个页的页号 |
| FIL_PAGE_LSN | 8 字节 | 页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number)FIL_PAGE_TYPE |
| FIL_PAGE_FILE_FLUSH_LSN | 8 字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 字节 | 页属于哪个表空间 |
对照着上面表格,我们看几个目前比较重要的参数:
- FIL_PAGE_SPACE_OR_CHKSUM
这个代表当前页面的校验和(checksum)。啥是个校验和?就是对于一个很长很长的字节串来说,我们会通过某种算法来计算一个比较短的值来代表这个很长的字节串,这个比较短的值就称为校验和 。这样在比较两个很长的字节串之前先比较这两个长字节串的校验和,如果校验和都不一样两个长字节串肯定是不同的,所以省去了直接比较两个比较长的字节串的时间损耗。 - FIL_PAGE_OFFSET
每一个页都有一个单独的页号,类似身份证号码, InnoDB通过页号来可以唯一定位一个页 。 - FIL_PAGE_TYPE
这个代表当前页的类型,我们前边说过,InnoDB 为了不同的目的而把页分为不同的类型,我们上边介绍的其实都是存储记录的数据页 ,其实还有很多别的类型的页,具体如下表:
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 最新分配,还没使用 |
| FIL_PAGE_UNDO_LOG | 0x0002 | Undo日志页 |
| FIL_PAGE_INODE | 0x0003 | 段信息节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer空闲列表 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | 表空间头部信息 |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
| FIL_PAGE_INDEX | 0x45BF | 索引页,也就是我们所说的数据页 |
我们存放记录的数据页的类型其实是 FIL_PAGE_INDEX ,也就是所谓的索引页 。
- FIL_PAGE_PREV 和 FIL_PAGE_NEXT
我们前边说过, InnoDB 都是以页为单位存放数据的,有时候我们存放某种类型的数据占用的空间非常大(比方说一张表中可以有成千上万条记录),InnoDB 可能不可以一次性为这么多数据分配一个非常大的存储空间,如果分散到多个不连续的页中存储的话需要把这些页关联起来,FIL_PAGE_PREV 和 FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了。而无需这些页在物理上真正连着。需要注意的是,并不是所有类型的页都有上一个和下一个页的性,我们本章节说的数据页 (也就是类型为FIL_PAGE_INDEX 的页)是有这两个属性的,所以所有的数据页其实是一个双链表。
File Trailer
我们知道 InnoDB 存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计 InnoDB 的大叔们在每个页的尾部都加了一个 File Trailer 部分,这个部分由 8 个字节组成,可以分成2个小部分:
- 前4个字节代表页的校验和
这个部分是和 File Header 中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为 File Header 在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在 File Header 中的校验和就代表着已经修改过的页,而在 File Trialer 中的校验和代表着原先的页,二者不同则意味着同步中间出了错。 - 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,LSN 的意思我们后续再说。
这个 File Trailer 与 File Header 类似,都是所有类型的页通用的。
更多关于mysql的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:
【Mysql】InnoDB数据页结构(五)
概述 页是InnoDB存储引擎管理存储空间的基本单位,一个页的大小默认是16KB 。InnoDB 为了不同的目的而设计了许多种不同类型的页 ,比如存放记录的索引页,存放表空间头部信息的页,存放 Insert Buffer信息的页,存放 INOD…...

Golang中的type关键字
type关键字在Go语言中有五种用法: 定义结构体定义接口类型别名类型定义类型开关其中,定义结构体和定义接口是Go语言中常用的类型定义方式,类型别名和类型定义则是为了方便程序员使用而设计的,而类型开关则是Go语言中比较特殊的一种类型定义方式。 定义结构体 结构体是由一…...
网站管家机器人在为企业获客方面起什么作用?
随着科技的不断进步和人们对便捷服务的需求增加,网站管家机器人成为了现代企业获客的重要工具。作为一种基于人工智能技术的在线助手,网站管家机器人可以与访问企业网站的用户进行智能对话,并提供即时的帮助和解答。 网站管家机器人在为企业获…...

竞赛选题 深度学习交通车辆流量分析 - 目标检测与跟踪 - python opencv
文章目录 0 前言1 课题背景2 实现效果3 DeepSORT车辆跟踪3.1 Deep SORT多目标跟踪算法3.2 算法流程 4 YOLOV5算法4.1 网络架构图4.2 输入端4.3 基准网络4.4 Neck网络4.5 Head输出层 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...

零基础学习HTML5
1. 使用软件 vscode 谷歌浏览器 vscode下载地址:https://code.visualstudio.com/ 谷歌可以使用360软件管家安装 2. 安装插件 在vscode中安装插件:open in browser,点击Extensions后搜索对应插件名然后点击安装Install 安装完成后可在htm…...

Jenkins 部署 Maven项目很慢怎么办?
Jenkins 部署 Maven项目很慢怎么办? 答案是:使用阿里云的Maven仓库 <mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/pub…...

关于刷题时使用数组的小注意事项
💯 博客内容:关于刷题时使用数组的小技巧 😀 作 者:陈大大陈 🚀 个人简介:一个正在努力学技术的准前端,专注基础和实战分享 ,欢迎私信! 💖 欢迎大家&#…...

【MySQL】面试题
引言 :MySQL面试题及答案 【最新版】 目录 1、NOW()和CURRENT_DATE()有什么区别?2、CHAR和VARCHAR的区别?3、主键索引与唯一索引的区别4、MySQL中有哪些不同的表格?5、SQL的生命周期…...

Pytorch训练深度强化学习时CPU内存占用一直在快速增加
最近在用MATD3算法解决多机器人任务,但是在训练过程中,CPU内存一直在增加(注意,不是GPU显存)。我很头疼,以为是算法代码出了问题,导致了内存泄漏,折腾了1天也没解决。后来用memory_p…...

git第一次推送出现推送被拒绝
前言 git 第一次推送出现以下错误 ! [rejected] master -> master (fetch first) error: failed to push some refs to ‘https://gitee.com/fengshangyunwang/iot-front-end.git’ hint: Updates were rejected because the remote contains work that you do hint: not …...
CRC16计算FC(博途SCL语言)
CRC8的计算FC,相关链接请查看下面文章链接: 博途SCL CRC8 计算FC(计算法)_博途怎么计算crc_RXXW_Dor的博客-CSDN博客关于CRC8的计算网上有很多资料和C代码,这里不在叙述,这里主要记录西门子的博途SCL完成CRC8的计算过程, CRC校验算法,说白了,就是把需要校验的数据与多项式…...
函数的用法)
setsockopt()函数的用法
setsockopt() 函数是一个用于设置套接字选项的函数,通常在网络编程中使用。它用于配置套接字的各种参数和选项,以满足特定的需求。setsockopt() 函数的作用是设置指定套接字选项的值。 setsockopt() 函数的一般用法: int setsockopt(int soc…...

【AOP系列】6.缓存处理
在Java中,我们可以使用Spring AOP(面向切面编程)和自定义注解来做缓存处理。以下是一个简单的示例: 首先,我们创建一个自定义注解,用于标记需要进行缓存处理的方法: import java.lang.annotat…...
云函数cron-parser解析时区问题
1、问题 云函数部署后cron-parser解析0点会变成8点 考虑可能是时区的问题 然后看文档发现果然有问题,云函数环境是utc0 2、解决 看了半天cron-parser文档发现 Using Date as an input can be problematic specially when using the tz option. The issue bein…...
Android11修改自动允许连接到建议的WLAN网络
客户的app需要连接指定的wifi,但是会提示下面的对话框(是否允许系统连接到建议的WLAN网络?): 客户需求:不提示这个对话框自动允许。 根据字符串定位到frameworks\opt\net\wifi\service\java\com\android\server\wifi\WifiNetworkSuggestionsManager.java 中的privat…...

基于Qt HTTP应用程序项目案例
文章目录 主项目入口项目子头文件httpwindow.hhttpwindow.h源文件httpwindow.cppui文件效果演示主项目入口 main函数创建对象空间,确认窗口的大小和坐标。 #include <QApplication> #include <QDir> #include...
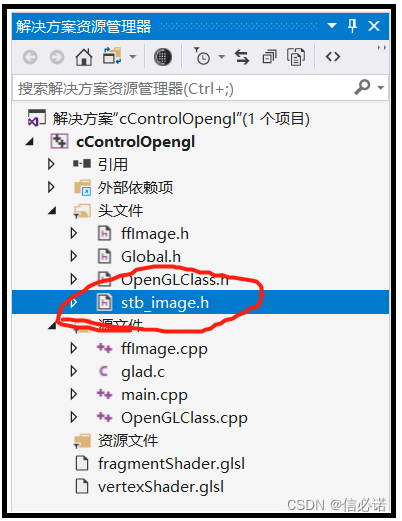
OpenGL —— 2.7、绘制多个自旋转的贴图正方体(附源码,glfw+glad)
源码效果 C源码 纹理图片 需下载stb_image.h这个解码图片的库,该库只有一个头文件。 具体代码: vertexShader.glsl #version 330 corelayout(location 0) in vec3 aPos; layout(location 1) in vec2 aUV;out vec2 outUV;uniform mat4 _modelMatrix; …...
annotate标注)
linux之perf(8)annotate标注
Linux之perf(8)annotate标注 Author:Onceday Date:2023年10月12日 漫漫长路,才刚刚开始… 注:该文档内容采用了GPT4.0生成的回答,部分文本准确率可能存在问题。 参考文档: Tutorial - Perf Wiki (kernel.org)perf…...

【广州华锐互动】VR建筑安全培训体验为建筑行业人才培养提供有力支持
随着建筑行业的快速发展,建筑施工安全问题日益受到广泛关注。然而,传统的安全培训方式往往缺乏实践性和真实性,难以让员工真正掌握安全操作技能。近年来,虚拟现实(VR)技术的广泛应用为建筑施工安全培训提供了新的机遇。 虚拟现实技…...

【Javascript保姆级教程】运算符
文章目录 前言一、运算符是什么二、赋值运算符2.1 如何使用赋值运算符2.2 示例代码12.3 示例代码2 三、自增运算符3.1 运算符3.2 示例代码13.3 示例代码2 四、比较运算符4.1 常见的运算符4.2 如何使用4.3 示例代码14.4 示例代码2 五、逻辑运算符逻辑运算符列举 六、运算符优先级…...
)
C语言文件操作:从键盘输入到文件保存的完整流程(附常见错误排查)
C语言文件操作实战:从键盘输入到文件保存的完整指南 在C语言开发中,文件操作是每个程序员必须掌握的技能。无论是保存用户配置、记录日志还是处理数据,文件读写都扮演着关键角色。本文将带你从零开始,通过一个完整的案例ÿ…...

Anthropic:AI 编程从单打独斗到团队协作的生产关系升级
【导语:在 AI 时代,编程不再是少数人的特权。Anthropic 让 Claude 独自完成项目,从单智能体到多智能体结构,实现了从生成代码到交付成果的跨越,带来了生产关系的升级。】Claude 单枪匹马难交付,多智能体团队…...

如何避免开源项目集成版本管理中的3个常见陷阱?
如何避免开源项目集成版本管理中的3个常见陷阱? 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 当你尝试将Xiaomi Home集成到Home Assistant时,…...

突破网盘下载限制:直链工具全攻略
突破网盘下载限制:直链工具全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷云盘 / 夸…...
CVC/WVC方程揭示可持续性密码)
量化文明:贾子理论(Kucius Theory)CVC/WVC方程揭示可持续性密码
量化文明:贾子理论(Kucius Theory)CVC/WVC方程揭示可持续性密码摘要:贾子理论通过文明方程(CVC/WVC)构建数理模型,量化文明价值与智慧资本。核心公式以意义、能量、时间积分定义CVC,…...

MiniCPM-o-4.5-nvidia-FlagOS跨平台部署:Windows系统配置要点
MiniCPM-o-4.5-nvidia-FlagOS跨平台部署:Windows系统配置要点 想在自己的Windows电脑上跑起来最新的MiniCPM-o-4.5-nvidia-FlagOS,结果被一堆环境问题卡住了?别急,这太正常了。很多朋友在Windows上部署这类AI项目时,总…...

Captain AI vs DeepSeek:Ozon 卖家专属 AI,垂直深耕更懂俄语区
做Ozon跨境,选 AI 工具别只看 “全能”,更要看 “专业”和“精通”。DeepSeek 是通用型跨境AI,覆盖多平台、多场景;而Captain AI是Ozon垂直定制 AI,聚焦俄语区与Ozon规则,四大核心功能精准解决卖家从新品到…...
)
别再问怎么给QQ机器人加功能了!手把手教你用Nonebot2写一个天气查询插件(附完整代码)
NoneBot2实战:从零构建智能QQ机器人天气查询插件 在当今即时通讯生态中,智能机器人已成为提升社群互动效率的利器。本文将深入探讨如何基于Python的NoneBot2框架,为QQ机器人开发一个功能完备的天气查询插件。不同于基础教程,我们聚…...

AO3镜像站使用指南:5分钟轻松访问全球同人创作宝库
AO3镜像站使用指南:5分钟轻松访问全球同人创作宝库 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site 还在为无法访问Archive of Our Own(AO3)而烦恼吗?AO3镜像站项目为你提…...

舰艇推进电机供电流程优化方案
舰艇推进电机供电流程优化方案 第一章 绪论 1.1 背景与意义 现代舰艇(如驱逐舰、潜艇、全电推进船舶)广泛采用综合电力系统。传统的供电流程中,推进电机作为最大的非线性负载,其负载突变(如急加速、倒车、波浪冲击导致的螺旋桨甩尾)会通过直流母线回馈至发电机组,导致…...