Hive知识梳理(好文)
Hive是建立在 Hadoop 上的数据仓库基础构架。可以将SQL查询转换为MapReduce的job在Hadoop集群上执行。
元数据
Hive元数据信息存储在Hive MetaStore中,或者mysql中。
分隔符
Hive默认的分格符有三种,分别是(Ctrl/A)、(Ctrl/B)和(Ctrl/C),即ASCii码的1、2和3,分别用于分隔列,分隔列中的数组元素,和元素Key-Value对中的Key和Value。
数据
Hive 中所有的数据都存储在HDFS中,Hive中包含以下数据模型:Table,External Table,Partition,Bucket。
1)表table:一个表就是hdfs中的一个目录
2)区Partition:表内的一个区就是表的目录下的一个子目录
3)桶Bucket:如果有分区,那么桶就是分区下的一个单位,如果表内没有分区,那么桶直接就是表下的单位,桶一般是文件的形式
hive分区分桶概念
分区
Hive分区又分为单值分区、范围分区。单值分区又分为静态分区和动态分区。
单值分区
单值分区根据插入时是否需要手动指定分区可以分为:单值静态分区:导入数据时需要手动指定分区。单值动态分区:导入数据时,系统可以自动判断目标分区。
单值分区表的建表方式有两种:直接定义列和 CREATE TABLE LIKE。注意,单值分区表不能用 CREATE TABLE AS SELECT 建表。而范围分区表只能通过直接定义列来建表。
1静态分区创建
直接在 PARTITIONED BY 后面跟上分区键、类型即可。(分区键不能和任何列重名)
CREATE [EXTERNAL] TABLE <table_name> (<col_name> <data_type> [, <col_name> <data_type> ...])
-- 指定分区键和数据类型
PARTITIONED BY (<partition_key> <data_type>, ...)
2静态分区写入
-- 覆盖写入
INSERT OVERWRITE TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, ...])
SELECT <select_statement>;
-- 追加写入
INSERT INTO TABLE <table_name>
PARTITION (<partition_key>=<partition_value>[, <partition_key>=<partition_value>, ...])
SELECT <select_statement>;
3动态分区创建
创建方式与静态分区表完全一样,一张表可同时被静态和动态分区键分区,只是动态分区键需要放在静态分区建的后面(因为HDFS上的动态分区目录下不能包含静态分区的子目录),如下 spk 即 static partition key, dpk 即 dynamic partition key。
CREATE TABLE <table_name>
PARTITIONED BY ([<spk> <data_type>, ... ,] <dpk> <data_type>, [<dpk><data_type>,...]);
4动态分区写入
静态分区键要用 <spk>=<value> 指定分区值;动态分区只需要给出分出分区键名称 <dpk>。
-- 开启动态分区支持,并设置最大分区数
set hive.exec.dynamic.partition=true;
set hive.exec.max.dynamic.partitions=2000;
-- <dpk>为动态分区键, <spk>为静态分区键
INSERT (OVERWRITE | INTO) TABLE <table_name>
PARTITION ([<spk>=<value>, ..., ] <dpk>, [..., <dpk>])
SELECT <select_statement>;
范围分区
每个范围分区对应分区键的一个区间,只要落在指定区间内的记录都被存储在对应的分区下。分区范围需要手动指定,分区的范围为前闭后开区间 [最小值, 最大值)。最后出现的分区可以使用 MAXVALUE 作为上限,MAXVALUE 代表该分区键的数据类型所允许的最大值。
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type>, <col_name> <data_type>, ...)
PARTITIONED BY RANGE (<partition_key> <data_type>, ...)
(PARTITION [<partition_name>] VALUES LESS THAN (<cutoff>),
[PARTITION [<partition_name>] VALUES LESS THAN (<cutoff>), ...
]
PARTITION [<partition_name>] VALUES LESS THAN (<cutoff>|MAXVALUE)
)
[ROW FORMAT <row_format>] [STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION '<file_path>']
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)];
eg:多个范围分区键的情况:
DROP TABLE IF EXISTS test_demo;
CREATE TABLE test_demo (value INT)
PARTITIONED BY RANGE (id1 INT, id2 INT, id3 INT)
(
PARTITION p5_105_215 VALUES LESS THAN (5, 105, 215),
PARTITION p5_115_max VALUES LESS THAN (5, 115, MAXVALUE),
PARTITION pall_max values less than (MAXVALUE, MAXVALUE, MAXVALUE)
);
分桶
对Hive表分桶可以将表中记录按分桶键的哈希值分散进多个文件中,这些小文件称为桶。
创建分桶表
我们先看一下创建分桶表的创建,分桶表的建表有三种方式:直接建表,CREATE TABLE LIKE 和 CREATE TABLE AS SELECT ,单值分区表不能用 CREATE TABLE AS SELECT 建表。这里以直接建表为例:
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type> [, <col_name> <data_type> ...])]
[PARTITIONED BY ...]
CLUSTERED BY (<col_name>)
[SORTED BY (<col_name> [ASC|DESC] [, <col_name> [ASC|DESC]...])]
INTO <num_buckets> BUCKETS
[ROW FORMAT <row_format>]
[STORED AS TEXTFILE|ORC|CSVFILE]
[LOCATION '<file_path>']
[TBLPROPERTIES ('<property_name>'='<property_value>', ...)];
分桶键只能有一个即<col_name>。表可以同时分区和分桶,当表分区时,每个分区下都会有<num_buckets>个桶。我们也可以选择使用SORTED BY … 在桶内排序,排序键和分桶键无需相同。ASC为升序选项,DESC为降序选项,默认排序方式是升序。<num_buckets>指定分桶个数,也就是表目录下小文件的个数。
向分桶表写入数据
因为分桶表在创建的时候只会定义Scheme,且写入数据的时候不会自动进行分桶、排序,需要人工先进行分桶、排序后再写入数据。确保目标表中的数据和它定义的分布一致。
目前有两种方式往分桶表中插入数据:
方法一:打开enforce bucketing开关。
SET hive.enforce.bucketing=true;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table> SELECT <select_statement>
[SORT BY <sort_key> [ASC|DESC], [<sort_key> [ASC|DESC], ...]];
方法二:将reducer个数设置为目标表的桶数,并在 SELECT 语句中用 DISTRIBUTE BY <bucket_key>对查询结果按目标表的分桶键分进reducer中。
SET mapred.reduce.tasks = <num_buckets>;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table>
SELECT <select_statement>
DISTRIBUTE BY <bucket_key>, [<bucket_key>, ...]
[SORT BY <sort_key> [ASC|DESC], [<sort_key> [ASC|DESC], ...]]
如果分桶表创建时定义了排序键,那么数据不仅要分桶,还要排序。
如果分桶键和排序键不同,且按降序排列,使用Distribute by … Sort by分桶排序。
如果分桶键和排序键相同,且按升序排列(默认),使用 Cluster by 分桶排序,即如下:
SET mapred.reduce.tasks = <num_buckets>;
INSERT (INTO|OVERWRITE) TABLE <bucketed_table>
SELECT <select_statement>
CLUSTER BY <bucket_sort_key>, [<bucket_sort_key>, ...];
另外补充说明一下,在Hive中,ORC事务表必须进行分桶(为了提高效率)。每个桶的文件大小应在100~200MB之间(ORC表压缩后的数据)。通常做法是先分区后分桶。
hive内部表和外部表
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
窗口函数
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
1) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
2)CURRENT ROW:当前行
3)n PRECEDING:往前n行数据
4) n FOLLOWING:往后n行数据
5)UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
6) LAG(col,n):往前第n行数据
7)LEAD(col,n):往后第n行数据
8) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
Hive UDF函数
【1】编写Hive UDF函数:新建一个类继承UDF类并重写evaluate方法,示列代码如下:
【2】打包编译生成jar包,注册UDF函数。
临时生效,即只在当前hive shell环境生效
hive> add jar hive-1.0.jar;//加入jar包,注意jar包的路径,我这里是当前路径
hive> create temporary function hive_hello as 'com.mycompany.bda.UdfHello';创建临时函数
永久有效,可以在多hive shell会话窗口使用udf函数
把jar包上传到hdfs,路径如下:hdfs://nameservice-ha/tzt/hive-1.0.jar
hive> CREATE FUNCTION addhello AS 'com.mycompany.bda.UdfHello' USING JAR 'hdfs://nameservice-ha/tzt/hive-1.0.jar';
Hive UDTF 函数
用来解决输入一行输出多行
创建方法:
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,
实现initialize, process, close三个方法。
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理
用法:UDTF有两种使用方法,一种直接放到select后面,一种和lateral view一起使用。
create table src(properties String);
vi src.txt
key1:value1;key2:value2;
load data local inpath '/root/hivedata/src.txt' into table src;
1:直接select中使用
select explode_map(properties) as (col1,col2) from src;
不可以添加其他字段使用
select a, explode_map(properties) as (col1,col2) from src;
不可以嵌套调用
select explode_map(explode_map(properties)) from src;
不可以和group by/cluster by/distribute by/sort by一起使用
select explode_map(properties) as (col1,col2) from src group by col1, col2;
2:和lateral view一起使用
select src.id, mytable.col1, mytable.col2 from src lateral view explode_map(properties) mytable as col1, col2;
Hive UDAF函数
UDAF实现多进一出
//UDAF是输入多个数据行,产生一个数据行
//用户自定义的UDAF必须是继承了UDAF,且内部包含多个实现了exec的静态类
public class MaxiNumber extends UDAF {
public static class MaxiNumberIntUDAFEvaluator implements UDAFEvaluator {
// 最终结果
private IntWritable result;
//负责初始化计算函数并设置它的内部状态,result是存放最终结果的
@Override
public void init() {
result = null;
}
//每次对一个新值进行聚集计算都会调用iterate方法
public boolean iterate(IntWritable value) {
if (value == null)
return false;
if (result == null)
result = new IntWritable(value.get());
else
result.set(Math.max(result.get(), value.get()));
return true;
}
//Hive需要部分聚集结果的时候会调用该方法
//会返回一个封装了聚集计算当前状态的对象
public IntWritable terminatePartial() {
return result;
}
//合并两个部分聚集值会调用这个方法
public boolean merge(IntWritable other) {
return iterate(other);
}
//Hive需要最终聚集结果时候会调用该方法
public IntWritable terminate() {
return result;
}
Sortby,orderby,distribute by,cluster by的区别
使用order by会引发全局排序
select * from baidu_click order by click desc;
使用distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
distribute by:按照指定的字段对数据进行划分输出到不同的 reduce 中。
cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。
Hive SQL的编译
Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
1)Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
2)遍历AST Tree,抽象出查询的基本组成单元QueryBlock
3)遍历QueryBlock,翻译为执行操作树OperatorTree
4)逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
5)遍历OperatorTree,翻译为MapReduce任务
6)物理层优化器进行MapReduce任务的变换,生成最终的执行计划。
Hive查看执行计划
可以通过查看explain查看一个一个SQL如何变成MapReduce作业的过程的过程,例如在hive cli中执行:explain sql语句就能看到。
NULL在hive的一般处理
NULL默认的存储都是\N,可以在建表时通过serialization.null.format的设置。
NULL 值的过滤,一般是is null 和 is not null。
multi-group新特性的好处
multi group by 可以将查询中的多个group by操作组装到一个MapReduce任务中,起到优化作用。例如:
from area
insert overwrite table temp1
select Provice,city,county,count(rainfall) from area where data="2018-09-02" group by provice,city,count
insert overwrite table temp2
select Provice,count(rainfall) from area where data="2018-09-02" group by provice
Hive Sql的MapReduce实现原理
hive把复杂sql分解成多个MapReduce chain执行,各MR的中间结果存在为hdfs的临时文件,然后链式跑完即可获得最终结果。因此,只需明白其核心即可见微知著,下面介绍join、group by和distinct原理:
Join的实现原理
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下(这里只是说明最基本的Join的实现,还有其他的实现方式)
Group By的实现原理
select rank, isonline, count(*) from city group by rank, isonline;
将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下(当然这里只是说明Reduce端的非Hash聚合过程
Distinct的实现原理
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去重
Hive文件压缩和文件存储
hive对文件的压缩是对内容的压缩,也就是说对文件的压缩不是先生成文件,再对文件压缩,而是在生成文件时,对其中的内容字段进行压缩,最终压缩后,对外仍体现为某种具体的压缩文件。
常用的压缩编解码器如下表:
常用的文件格式:
Textfile
文本格式,Hive的默认格式,数据不压缩,磁盘开销大、数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。行式存储
对应的hive API为:org.apache.hadoop.mapred.TextInputFormat和org.apache.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SequenceFile
Hadoop提供的一种二进制文件格式是Hadoop支持的标准文件格式,可以直接将对序列化到文件中,所以sequencefile文件不能直接查看,可以通过Hadoop fs -text查看。具有使用方便,可分割,可压缩,可进行切片。压缩支持NONE, RECORD, BLOCK(优先)等格式,可进行切片。行式存储
对应hive API为:org.apache.hadoop.mapred.SequenceFileInputFormat和org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
RCFile
是一种行列存储相结合的存储方式,先将数据按行进行分块再按列式存储,保证同一条记录在一个块上,避免读取多个块,有利于数据压缩和快速进行列存储。列式存储
对应的hive API为:org.apache.hadoop.hive.ql.io.RCFileInputFormat和org.apache.hadoop.hive.ql.io.RCFileOutputFormat
ORCFile
orcfile是对rcfile的优化,可以提高hive的读写、数据处理性能,提供更高的压缩效率(目前主流选择之一)。列式存储
Parquet
一种列格式, 可提供对其他 hadoop 工具的可移植性, 包括Hive, Drill, Impala, Crunch, and Pig
对应的hive API为:org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat和org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Avro
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
对应的hive API为:org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat和org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat
几种文件存储格式的性能测试结果:
存储格式
ORC
Sequencefile
Parquet
RCfile
数据压缩后大小
1.8G
67.0G
11G
63.8G
存储耗费时间
535.7s
625.8s
537.3s
543.48
SQL查询响应速度
19.63s
184.07s
24.22s
88.5s
实践中常用的压缩+存储可以选择(部分)
Textfile+Gzip
SequenceFile+Snappy
ORC+Snappy
Hive建表指定文件格式
[STORED AS file_format]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
Hive建表指定压缩
CREATE EXTERNAL TABLE IF NOT EXISTS tb_test(
id bigint COMMENT 'id',
name string COMMENT 'name'
)
COMMENT 'test table'
PARTITIONED BY (dt string)
STORED AS ORC
tblproperties ('orc.compress'='SNAPPY');
Hive动态设置压缩
压缩格式
Hadoop压缩编码/解码器
Deflate
org.apache.hadoop.io.compress.DeflateCodec
gzip
org.apache.hadoop.io.compress.GzipCodec
bzip2
org.apache.hadoop.io.compress.BZip2Codec
LZO
com.hadoop.compression.lzo.LzopCodec
Lz4
org.apache.hadoop.io.compress.Lz4Codec
Snappy
org.apache.hadoop.io.compress.SnappyCodec
Hive中间数据压缩
hive.exec.compress.intermediate:默认该值为false,设置为true为激活中间数据压缩功能。就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩。在这个阶段,优先选择一个低CPU开销的算法。
set hive.exec.compress.intermediate=true;
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
Hive最终数据压缩
hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
Hive Map和Reduce数量计算
Map数量
Map数量=split数量
Split数量=文件大小/split size
Split size = Math.max(minSize,Math.min(maxSize,blockSize))
Mapred.min.split.size指的是数据的最小分割单元大小。
Mapred.max.split.size指的是数据的最大分割单元大小。
dfs.block.size指的是HDFS设置的数据块大小。
一般来说dfs.block.size这个值是一个已经指定好的值,而且这个参数Hive是识别不到的,所以实际上只有Mapred.min.split.size和Mapred.max.split.size这两个参数来决定Map数量。在Hive中min的默认值是1B,max的默认值是256MB。所以如果不做修改的话,就是1个map task处理256MB数据,我们就以调整max为主。通过调整max可以起到调整Map数的作用,减小max可以增加Map数,增大max可以减少Map数。直接调整Mapred.Map.tasks这个参数是没有效果的。
Reduce数量
这里说的Reduce阶段,是指前面流程图中的Reduce phase(实际的Reduce计算)而非图中整个Reduce task。Reduce阶段优化的主要工作也是选择合适的Reducetask数量,跟上面的Map优化类似。
与Map优化不同的是,Reduce优化时,可以直接设置Mapred。Reduce。tasks参数从而直接指定Reduce的个数。当然直接指定Reduce个数虽然比较方便,但是不利于自动扩展。Reduce数的设置虽然相较Map更灵活,但是也可以像Map一样设定一个自动生成规则,这样运行定时Job的时候就不用担心原来设置的固定Reduce数会由于数据量的变化而不合适。
Hive估算Reduce数量的时候,使用的是下面的公式:
num_Reduce_tasks = min[${Hive.exec.Reducers.max},(${input.size} / ${ Hive.exec.Reducers.bytes.per.Reducer})]
也就是说,根据输入的数据量大小来决定Reduce的个数,默认Hive.exec.Reducers.bytes.per.Reducer为1G,而且Reduce个数不能超过一个上限参数值,这个参数的默认取值为999。所以我们可以调整Hive.exec.Reducers.bytes.per.Reducer来设置Reduce个数。
优化
MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
自动判断
set.hive.auto.convert.join=true;
默认值是25mb,小表小于25mb自动启动mapjoin
手动设置
select /*+mapjoin(A)*/ f.a,f.b from A t join B f on (f.a=t.a)
其中,A为小表,将A表复制到所有节点
行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
采用分桶技术
采用分区技术
合理设置Map数
问题1:map过多
如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
问题2:是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题1和2,我们需要采取两种方式来解决:即减少map数和增加map数;
小文件进行合并
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
设置map输入的小文件合并
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
合理设置Reduce数
Reduce个数并不是越多越好
1)过多的启动和初始化Reduce也会消耗时间和资源;
2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
常用参数
// 输出合并小文件
SET hive.merge.mapfiles = true; --默认true,在map-only任务结束时合并小文件
SET hive.merge.mapredfiles = true; --默认false,在map-reduce任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; --默认256M
SET hive.merge.smallfiles.avgsize = 16777216; --当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
减少数据量
第一原则先降数据量再join
并行化执行
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
hive默认job是顺序进行的,一个HQL拆分成多个job,job之间无依赖关系也没有相互影响可以并行执行
对于同一个sql来说同时可以运行的job的最大值,该参数默认为8.此时最大可以同时运行8个job
开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict
开启JVM重用
set mapred.job.reuse.jvm.num.tasks=10;
jvm的启动过程可能会造成相当大的开销,对于单个执行任务时间较短时候,频繁开启JVM将是很大的开销,开启JVM重用将会一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放
map阶段优化
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
reduce阶段优化
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
方法1
set hive.exec.reducers.bytes.per.reducer=500000000;
调整hive.exec.reducers.bytes.per.reducer参数的值;
方法2
set mapred.reduce.tasks=15;
调整mapred.reduce.tasks参数的值;
参考链接:Hive调优篇_扛麻袋的少年的博客-CSDN博客
常见问题
数据倾斜
定义:由于数据分布不均匀,造成数据热点。
现象:一个或几个key的记录数与平均记录数差异过大,最长时长远大于平均时长。任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。
数据倾斜优化:一般分为join引起和group by引起分别解决。
操作
原因
现象
Group by
分组key集中
处理某key值的reduce非常耗时
Join
关联key集中(例如关联字段空值过多)
处理某key值的reduce非常耗时
Group by引起的数据倾斜
分两方面优化:
第一个:配置map局部聚合
set hive.map.aggr=true;
set hive.groupby.mapaggr.checkinterval=100000;
set hive.map.aggr.hash.min.reduction=0.5;
hive.map.aggr=true(默认)参数控制在group by的时候是否map局部聚合,但也不是都会局部聚合,如果聚合前后差别不是很大,聚合也就没什么意义了。
后两个设置是判断是否需要做map局部聚合,即:预先取100000条数据聚合,如果聚合后的条数/100000>0.5,则不再聚合。
第二个:数据倾斜时负载均衡
set Hive.groupby.skewindata=true;
控制启动两MapReduce Job完成,第一个Job先不按GroupBy字段分发,而是随机分发做一次聚合,然后启动第二个Job,拿前面聚合过的数据按GroupBy字段分发计算出最终结果。
Join引起的数据倾斜
优化主要分两个方向:skew join和重写业务逻辑
skew join
set hive.optimize.skewjoin=true;//该参数通过在hive对物理执行计划优化的时候,添加一个map join。
set hive.skewjoin.key=100000;//记录超过hive.skewjoin.key(默认100000)阈值的key值先写入hdfs,然后再进行一个map join的job任务,最终和其他key值的结果合并为最终结果。
重写业务逻辑
这个需要结合具体的场景重写。
例如:倾斜的数据是空值。在日志表与用户表关联时候(通过user_id关联),直接关联可能导致user_id为null的发生数据倾斜,此时可以把日志表中user_id为null的单独处理,如下:
//Null join 的unin非null的 join
SELECT a.xx, b.yy FROM log a JOIN users b
ON a.user_id IS NOT NULL
AND a.user_id = b.user_id
UNION ALL
SELECT a.xx, NULL AS yy FROM log a WHERE a.user_id IS NULL;
参考链接:Hive中常见的数据倾斜问题的处理_Running-小猛的博客-CSDN博客
相关文章:
)
Hive知识梳理(好文)
Hive是建立在 Hadoop 上的数据仓库基础构架。可以将SQL查询转换为MapReduce的job在Hadoop集群上执行。 元数据 Hive元数据信息存储在Hive MetaStore中,或者mysql中。 分隔符 Hive默认的分格符有三种,分别是(Ctrl/A)、࿰…...

GitHub仓库的README文件无法显示图片问题-非域名污染原因
之前上自己仓库就偶然发现图片不显示现象,当时以为是网络问题就没有留意这事。但是一直不显示就有问题了!于是网上搜了一遭,看见大家遇到此现象的原因普遍归于DNS污染1而我的问题原来是MarkDown格式! 在图片语法前不要加分区语法…...

opencv入门到精通——图片,视频,摄像头的读取与保存
简介 OpenCV是一个流行的开源计算机视觉库,由英特尔公司发起发展。它提供了超过2500个优化算法和许多工具包,可用于灰度、彩色、深度、基于特征和运动跟踪等的图像处理和计算机视觉应用。OpenCV主要使用C语言编写,同时也支持Python、Java、C等…...

Android 13.0 开机动画支持mp4格式视频作为开机动画播放
1.概述 在13.0的系统产品开发中,在系统开机动画这块一般情况下都是播放开机图片,然后绘制多张开机图片形成开机动画模式,而产品需求要求支持开机mp4格式的短视频来作为开机动画播放视频来介绍产品情况,就需要用开机视频来替代开机动画来实现功能 2.开机动画支持mp4格式视频…...
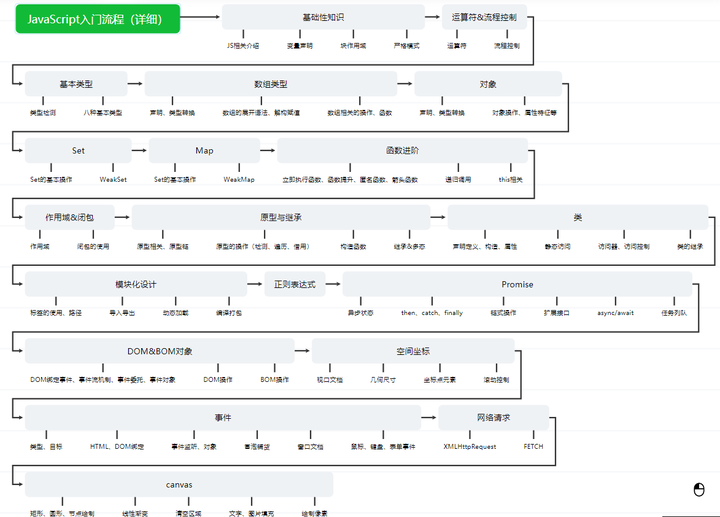
前端自学需要把大量时间放在 HTML、CSS 吗?
前言 html和css其实不需要花费太多的时间,html暂且不说,css各类的属性太多了,平时如果只是简单做一些小网站根本不需要全部掌握,只需要掌握一些基础常用的即可,一般遇到不会的也可以直接查文档,就我个人来…...
Python爬虫如何设置代理服务器(搭建代理服务器教程)
在Python爬虫中使用代理服务器可以提高爬取数据的效率和稳定性。本文将为您提供搭建代理服务器的详细教程,并提供示例代码,帮助您在Python爬虫中设置代理服务器,实现更高效、稳定的数据抓取。 Python爬虫怎么设置代理服务器(搭建代…...
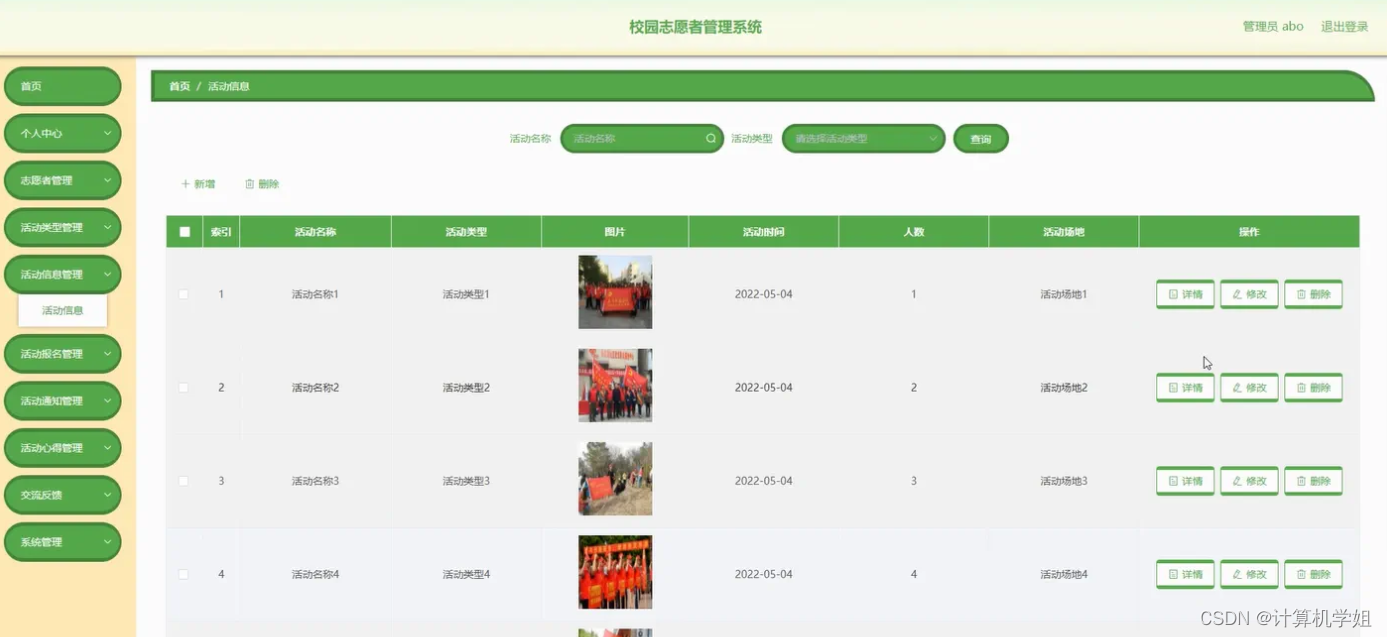
基于SpringBoot的校园志愿者管理系统
基于SpringBoot的校园志愿者管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 活动信息 登录界面 志愿者界面 管理员界面 摘要 校园志愿者管理系统…...
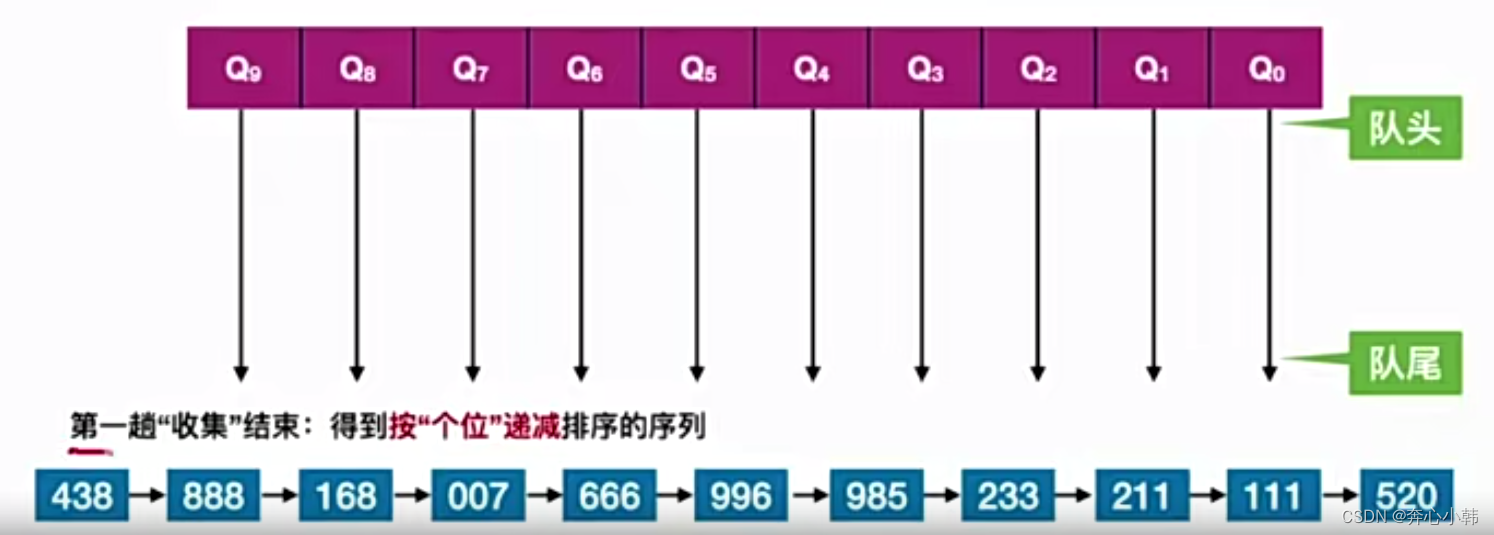
24-数据结构-内部排序-基数排序
基数排序 基数排序,给关键字分成d位(组),,对每一位的情况,可能会出现的值位r(基数)个,然后分成r个队列,对每个对林进行分配耗时O(n),最后按照改位…...
oracle11g安装图解
软件需求 1.安装CentOS6.5的服务器一台 2.Oracle 11g 安装介质: linux.x64_11gR2_database_1of2.zip linux.x64_11gR2_database_2of2.zip 3.命令行客户端工具xshell、crt或者putty 4.图形界面客户端工具Xming 系统配置检查 1.内存检查 grep MemTotal /proc/m…...

CBitmap、CreateCompatibleBitmap、CreateBitmap
一、CBitmap类主要是加载位图资源,或者建立一个空白位图用于存储画面。 BOOL LoadBitmap(UINT nIDResource)从工程资源中加载一张位图BOOL LoadOEMBitmap(UINT nIDBitmap)从系统资源中加载一张位图BOOL CreateBitmap(int nWidth, int nHeigjt, UINT nPlane, UINT n…...

亲测好用教师小程序
作为一名老师,经常需要面对的一大挑战就是如何有效地向学生和家长传达重要的学业信息。而其中,成绩的发布与查询更是重中之重。传统的做法是手动录入数据,或者通过电子邮件发送Excel表格,这样做既繁琐又耗时。幸运的是,…...

第十五章:输入输出流I/O
15.1:输入/输出流 文件类:File 字节流:InputStream:入 OutputStream:出 字符流:Reader:入 Writer:出 15.1.1 输入流 InputStream类是字节输入流的抽象类,所有字节流…...

docker命令实例(举例子学习)
docker命令实例 实例1 docker build -t linksoul/chinese-llama2-chat .实例2 docker run --gpus all --ipchost --ulimit memlock-1 --ulimit stack67108864 --rm -it -v pwd/LinkSoul:/app/LinkSoul -p 7860:7860 linksoul/chinese-llama2-chat实例3 docker run -it -p 78…...

excel常用函数
vlookup函数 ISNA函数 ISNA(value) ISNA 函数用于检查指定的值是否为 #N/A 错误值,并返回 TRUE 或 FALSE。 IF 函数 IF(条件, 如果条件为TRUE的值, 如果条件为FALSE的值)...
使用Portainer图形化工具轻松管理远程Docker环境并实现远程访问
文章目录 前言1. 部署Portainer2. 本地访问Portainer3. Linux 安装cpolar4. 配置Portainer 公网访问地址5. 公网远程访问Portainer6. 固定Portainer公网地址 前言 Portainer 是一个轻量级的容器管理工具,可以通过 Web 界面对 Docker 容器进行管理和监控。它提供了可…...
Git快速安装【附安装包资源】
软件安装包 项目版本管理软件 Git windows版本安装包 安装步骤 双击按照包之后,直接next 安装位置尽量不要选择C盘,如果只有C盘,可以尝试分盘,如果C盘已经很小了,那就没办法了 选择完安装位置之后,直…...

算法进修Day-33
算法进修Day-33 65. 有效数字 难度:困难 题目要求 有效数字(按顺序)可以分成以下几个部分: 一个 小数 或者 整数(可选)一个 e 或 E ,后面跟着一个 整数 小数(按顺序)…...
开发工具分享 - Mybatis SQL日志格式化H5
目录 一、 序言二、代码示例三、部署至Nginx 一、 序言 平时通过IDEA开发,可以直接装相关MybatisLogFormat的插件直接对控制台里的Mybatis SQL日志进行格式化。一旦离开本地环境,到了测试或者线上,就得自己手动拼参数了。 简单的SQL还好&am…...
好用的办公软件有哪些
日常的工作难免和各种各样的软件打交道,除了传统的Office三件套,小编日常还在用着其他的办公软件,借此跟各位分享其中比较好用、堪称办公神器的8款软件! 1.WPS office 2.office2007 3.EasyConnect 4.ToDesk 5.Photoshop 6.A…...

C#中Abstract、Virtual和Override的使用方法
在C#中,abstract、virtual和override是用于处理类和方法的三个重要关键字,它们的用途和用法如下: Abstract(抽象) 抽象方法是一种只有声明而没有实现的方法。抽象方法只定义了方法的名称、返回类型和参数列表&#x…...
实现超快加法器(Vivado实例))
FPGA设计效率翻倍:巧用LUT6与进位链(CARRY4)实现超快加法器(Vivado实例)
FPGA设计效率翻倍:巧用LUT6与进位链(CARRY4)实现超快加法器(Vivado实例) 在FPGA开发中,加法器是最基础却又最关键的运算单元之一。传统上,我们习惯直接使用""运算符让综合工具自动处理,但这种做法…...

MPLAB PM3烧录器搭配LabVIEW避坑指南:从驱动安装到‘Operation Succeeded’全流程
MPLAB PM3烧录器与LabVIEW高效联调实战:从零搭建到工业级稳定烧录 1. 硬件连接与驱动配置的隐藏细节 第一次将MPLAB PM3烧录器从包装盒取出时,多数开发者会直接进入软件配置环节,却忽略了物理连接的稳定性往往决定了整个项目的成败。PM3的ICS…...

数据治理“路线分化”:2026平台选型深度解析
2026年,中国企业的数字化转型正进入“向数据要价值”的攻坚阶段。前些年企业纷纷搭建数据中台、汇聚全域数据,然而当基础设施逐步完善,一个尴尬的现实却浮出水面——平台建好了,数据接入了,但数据标准不统一、指标口径…...

终极完整指南:HS2-HF_Patch如何彻底改变你的Honey Select 2游戏体验
终极完整指南:HS2-HF_Patch如何彻底改变你的Honey Select 2游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在寻找一款能够一键解决…...

收藏|2026年新版春招大变局!后端程序员必看,大模型已成上岸刚需
正值2026年春招黄金爆发阶段,也是全体技术人求职跳槽、职级晋升的关键转折点。对比往年互联网招聘行情,今年后端求职赛道早已全面革新,不管是企业招聘考核逻辑、整体薪资走势,还是人才筛选标准,都迎来了颠覆性调整&…...

LinkSwift:开源网盘直链解析工具的技术实现与应用
LinkSwift:开源网盘直链解析工具的技术实现与应用 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

VibeVoice多角色对话生成实践:基于LSTM的语音风格控制
VibeVoice多角色对话生成实践:基于LSTM的语音风格控制 1. 引言 你有没有想过,输入一段对话脚本,AI就能生成四个不同角色的自然对话音频?不是那种机械的电子音,而是有呼吸感、有情感起伏、角色音色分明的高质量播客内…...

Phi-4-mini-reasoning效果展示:中文数学题→符号计算→自然语言结论全流程
Phi-4-mini-reasoning效果展示:中文数学题→符号计算→自然语言结论全流程 1. 模型能力概览 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题等需要多步分析的场景。与通用聊天模型不同,它更专注于&qu…...

NVIDIA cuQuantum 23.10:量子电路模拟GPU加速技术解析
1. 量子电路模拟加速利器:NVIDIA cuQuantum 23.10深度解析量子计算模拟一直是科研和工业界的计算密集型任务。传统CPU在处理超过30个量子比特的电路模拟时,往往会遇到内存和算力的双重瓶颈。NVIDIA cuQuantum的出现彻底改变了这一局面——这个专为量子计…...

Hugging Face空格处理差异与NLP模型优化实践
1. 项目概述在自然语言处理领域,空格字符的处理看似简单却暗藏玄机。最近我在使用Hugging Face生态时,发现不同模型对空格字符的处理方式存在显著差异,这直接影响了文本预处理的效果和模型输出质量。本文将深入分析Hugging Face工具链中空格字…...