Elasticsearch2.x Doc values
文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/doc-values.html
https://www.elastic.co/guide/en/elasticsearch/guide/2.x/docvalues-intro.html
https://www.elastic.co/guide/en/elasticsearch/guide/2.x/docvalues.html
https://www.elastic.co/guide/en/elasticsearch/guide/2.x/_deep_dive_on_doc_values.html#_deep_dive_on_doc_values
doc_values介绍
doc values是一个我们再三重复的重要话题了,你是否意识到一些东西呢?
搜索时,我们需要一个“词”到“文档”列表的映射
排序时,我们需要一个“文档”到“词“列表的映射,换句话说,我们需要一个在倒排索引的基础上建立的“正排索引”
这里的“正排索引”结构通常在其他系统中(如关系型数据库)被称为“列式存储”。本质上,它是在数据字段的一列上存储所有value,这种结构在某些操作上会表现得很高效,比如排序。
在ES里这种“列式存储”就是我们熟悉的“doc values”,默认情况下它是被启用的,doc values在index-time(索引期)被创建:当一个字段被索引时,ES会把“词”加入到倒排索引中,同时把这些词也加入到面向“列式存储”的doc values中(存储在硬盘上)。
doc values通常被应用在以下几个方面:
基于一个字段排序
基于一个字段聚合
执行某些filter上(如:geolocation filter)
在script(脚本)中引用了一个或多个字段
由于doc values在索引期被序列化到硬盘上,我们可以利用操作系统去快速的访问它们,关于doc values在磁盘上是如何被管理的,后面会讲到。
doc_values
大多数的字段默认情况下都会被索引,这使得他们可以被搜索到,倒排索引允许一个查询基于一个词表排序,也可以快速访问包含某个词的文档列表。
排序、聚合,和在脚本中访问一些字段值时都需要另一种不同的访问方式,因为倒排索引不支持这种访问,所以我们需要一种结构能查询到文档到词的映射。
doc values是在索引期创建基于磁盘的数据结构,这种结构使得上述访问成为可能。doc values支持绝大部分字段类型,除了“analyzed”类型的string字段。
所有的字段都默认支持doc values,如果你确定你不需要在某个字段上排序或者聚合或者在脚本中访问,你可以disable掉:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"status_code": {
"type": "string",
"index": "not_analyzed"
},
"session_id": {
"type": "string",
"index": "not_analyzed",
"doc_values": false
}
}
}
}
}
status_code字段默认开启doc_values
session_id字段禁用了doc_values,虽然被禁用但是还是可以被查询
TIP:doc_values可以在同一个索引的同名字段上设置不同值,它也可以基于一个已存在的字段使用put mapping api来禁用它。
看如下的倒排索引结构
Term Doc_1 Doc_2 Doc_3
------------------------------------
brown | X | X |
dog | X | | X
dogs | | X | X
fox | X | | X
foxes | | X |
in | | X |
jumped | X | | X
lazy | X | X |
leap | | X |
over | X | X | X
quick | X | X | X
summer | | X |
the | X | | X
------------------------------------
如果我们想为每一个包含“brown”的文档编辑一份完整的词列表,我们可能会用如下查询
GET /my_index/_search
{
"query" : {
"match" : {
"body" : "brown"
}
},
"aggs" : {
"popular_terms": {
"terms" : {
"field" : "body"
}
}
}
}
看上面的查询部分。倒排索引通过词条排好了序,所以我们首先找到包含“brown”的词条列表,然后跨列扫描所有包含“brown”的文档,这里我们很幸运的找到了“Doc_1”和“Doc_2”。
然后在聚合部分,我们需要找Doc_1和Doc_2中找到所有的词,在倒排索引的去做这个操作很非常昂贵的:意味着我们不得不迭代索引中的每一个词,看它们是否包含在doc_1和doc_2中,这个过程是非常缓慢的,而且也是非常愚蠢的:因为随着文档词量的增加,我们聚合的执行时间也会增加。
让我们看看下面的结构:
Doc Terms
-----------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
-----------------------------------------------------------------
有了这个结构我们就会很容易得到doc_1和doc_2所包含的词条,我们只需要通过上面的结构把两个集合合并起来就行了。
因此,查询和聚合是非常复杂的,查询文档使用的是倒排索引,聚合文档使用的是正排索引(doc_values)
note:doc values不仅仅是用在聚合中,还被用在排序、脚本、子父文档关系(这里暂不做介绍)。
深入Doc Values
前面讲到的doc values给我们几个印象:快速访问、高效、基于硬盘。现在我们来看看doc values到底是如何工作的?
doc values是在“索引期“随着倒排索引一起生成的,也就是说 doc values是基于每个索引段生成且是不可改变的(immutable),和倒排索引一样,doc values也会被序列化到磁盘上,这使得它具有了高效性和可扩展性。
通过序列化一个数据结构到磁盘上,我们可以依赖操作系统的 file system cache 替代JVM的堆内存,当我们的“工作集”小于OS可用内存时,操作系统会自然的加载这些doc values到内存。这时doc values的性能和在JVM堆内存中表现是一样的。
但是当工作集大于操作系统可用内存时,操作系统将会按需加载doc values,这种情况下的访问速度会明显的慢于全量加载doc values的时候。但这种操作使得我们的服务器内存利用率远超过服务器最大内存限制。试想一下,如果全量加载到doc values到内存中势必会造成ES OutOfMemery。
NOTE:由于doc values不受JVM堆内存管理,所以我们可以把ES对内存设置得小一点,把更多的内存留给操作系统来换出(doc values),同时这也可以使JVM的GC工作在更小的堆内存上,更快更高效的执行GC。
通常,我们配置JVM的堆内存基本和操作系统内存各占一半(50%),由于引进了doc values所以我们可以考虑把JVM的堆内存设置得小一些,比如我们可以在一个64G的服务器上设置JVM堆内存为4 - 16GB比设置堆内存为32G更加高效。
Column-store compression(列式存储压缩)
本质上doc values是一个被序列化的面向“列式储存”的结构,我们前面讨论过列式存储在某些查询操作上是有优势的,不仅如此它们也更擅长数据压缩,特别是数字,这对磁盘存储和快速访问来说是及其重要的。
为了了解它是如何压缩数据的,我们看下面简单的doc values结构
Doc Terms
-----------------------------------------------------------------
Doc_1 | 100
Doc_2 | 1000
Doc_3 | 1500
Doc_4 | 1200
Doc_5 | 300
Doc_6 | 1900
Doc_7 | 4200
-----------------------------------------------------------------
像上面这种每行一条数据的形式,我们可以得到连续的数字块,如:[100,1000,1500,1200,300,1900,4200]。因为我们知道它们都是数字值可以被排列在一起通过一个一致的偏移量。
跟深层次的,这里有几种压缩方法可以运用在这些数字上。你可能知道上面的数字都是100的倍数,如果索引段上所有的的数字都共享一个“最大公约数”,那么就可以用这个最大公约数去压缩数据。如上面的数字我们可以除以100,得到的数据是[1,10,15,12,3,19,42]。这样这些数字会变得小一些,存储时占用的比特数也会小一些。
doc values使用几种手段来压缩数字。
如果所有的数字值都相等(或者缺失),会设置一个标记来表示该值
如果所有数字值的个数小于256个,将会使用一个简单的编码表来压缩
如果大于了256个,看看是否存在最大公约数,存在则使用最大公约数压缩
如果不存在最大公约数,则存储偏移量来压缩数字。
如你看到的,你可能会想“这样做对数值型字段做压缩确实很好,那么对字符串类型呢?”,其实字符串压缩也是和数字压缩一样采用同样的方法通过一个序数表来压缩,字符串被去重、排序后被赋予了一个ID,这些ID就是数字,这样就可以采用上面的方案进行压缩了。对于序数表本身也会采用压缩存储。
————————————————
版权声明:本文为CSDN博主「飞奔的代码」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chennanymy/article/details/52555055
相关文章:

Elasticsearch2.x Doc values
文档地址: https://www.elastic.co/guide/en/elasticsearch/reference/2.4/doc-values.html https://www.elastic.co/guide/en/elasticsearch/guide/2.x/docvalues-intro.html https://www.elastic.co/guide/en/elasticsearch/guide/2.x/docvalues.html https://ww…...
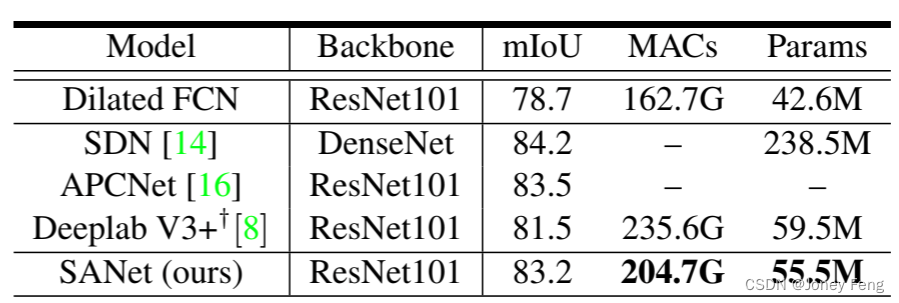
Squeeze-and-Attention Networks for Semantic Segmentation
0.摘要 最近,将注意力机制整合到分割网络中可以通过更重视提供更多信息的特征来提高它们的表征能力。然而,这些注意力机制忽视了语义分割的一个隐含子任务,并受到卷积核的网格结构的限制。在本文中,我们提出了一种新颖的squeeze-a…...
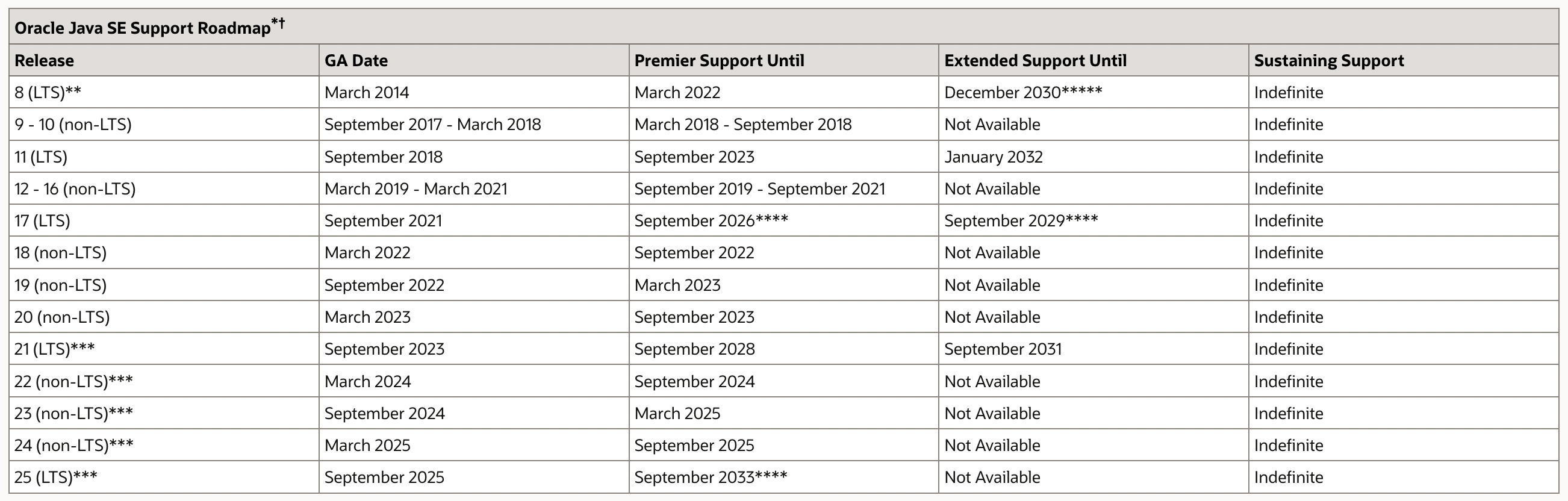
【Java】Java 11 新特性概览
Java 11 新特性概览 1. Java 11 简介2. Java 11 新特性2.1 HTTP Client 标准化2.2 String 新增方法(1)str.isBlank() - 判断字符串是否为空(2)str.lines() - 返回由行终止符划分的字符串集合(3)str.repeat(…...
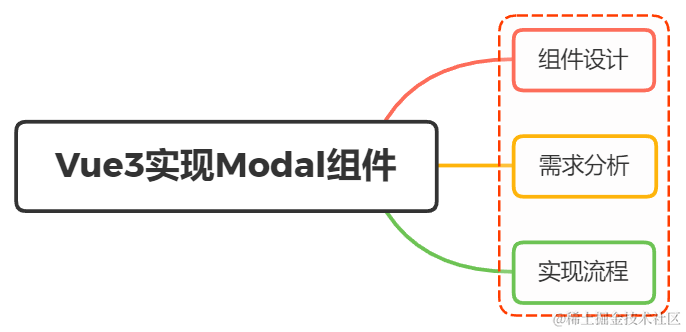
用Vue3.0 写过组件吗?如果想实现一个 Modal你会怎么设计?
一、组件设计 组件就是把图形、非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式 现在有一个场景,点击新增与编辑都弹框出来进行填写,功能上大同小异,可能只是标题内容或者是显示的主体内容稍微不同 …...
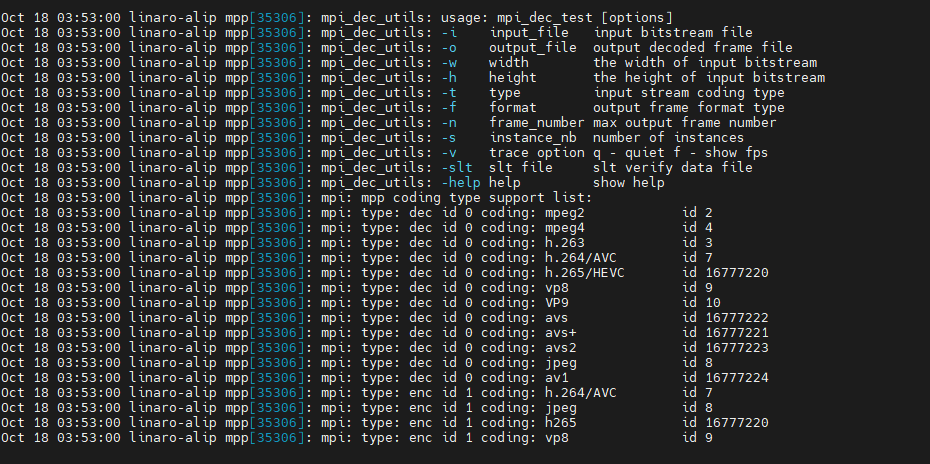
ArmSoM-W3之RK3588硬编解码MPP环境配置
1. 简介 瑞芯微提供的媒体处理软件平台(Media Process Platform,简称 MPP)是适用于瑞芯微芯片系列的 通用媒体处理软件平台。该平台对应用软件屏蔽了芯片相关的复杂底层处理,其目的是为了屏蔽不 同芯片的差异,为使用者…...

源码解析flink文件连接源TextInputFormat
背景: kafka的文件系统数据源可以支持精准一次的一致性,本文就从源码看下如何TextInputFormat如何支持状态的精准一致性 TextInputFormat源码解析 首先flink会把输入的文件进行切分,分成多个数据块的形式,每个数据源算子任务会被分配以读取…...
)
SQL ORDER BY Keyword(按关键字排序)
SQL ORDER BY 关键字 ORDER BY 关键字用于按升序或降序对结果集进行排序。 ORDER BY 关键字默认情况下按升序排序记录。 如果需要按降序对记录进行排序,可以使用DESC关键字。 SQL ORDER BY 语法 SELECT column1, column2, ... FROM table_name ORDER BY column1, …...
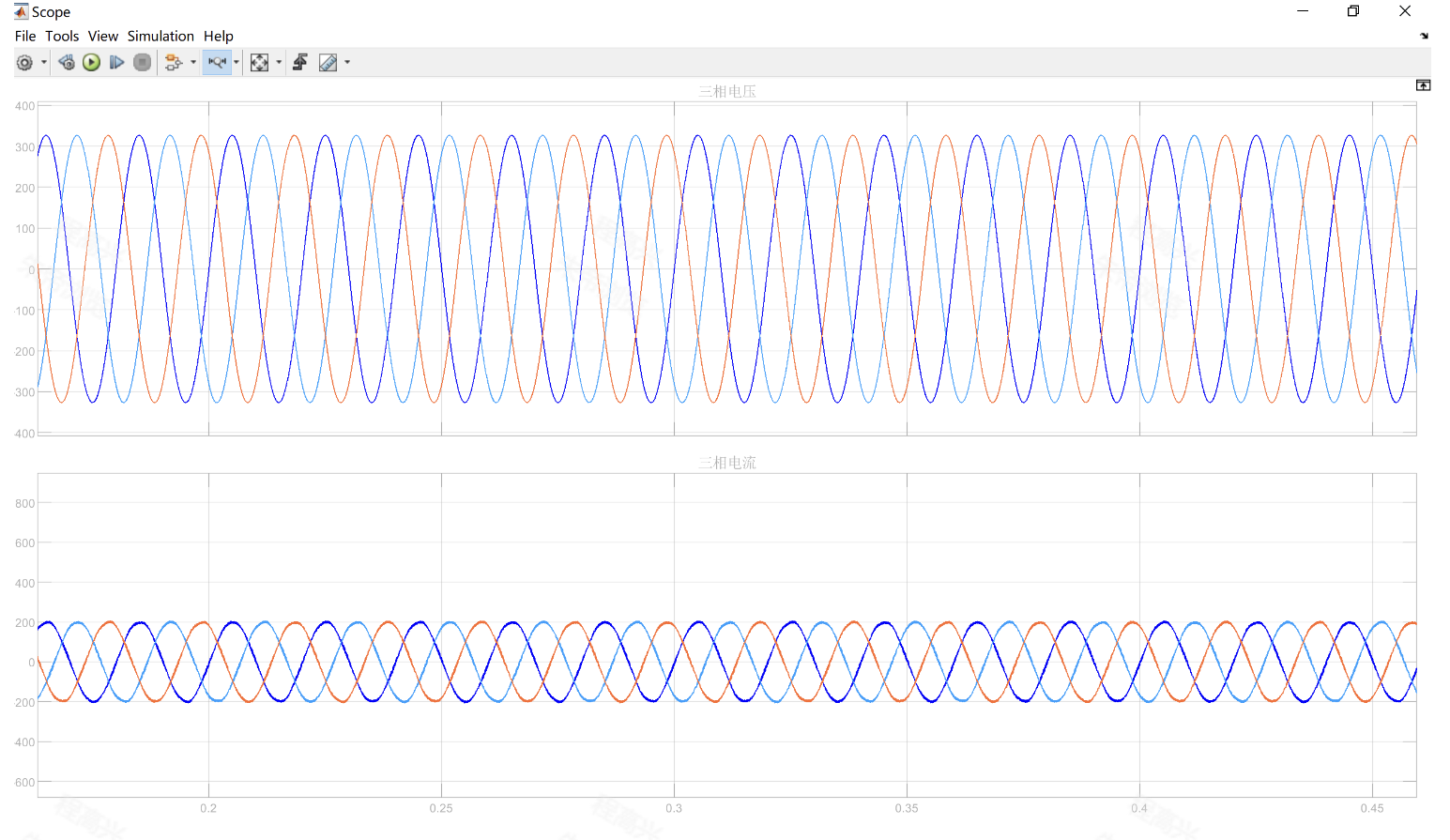
光伏三相并网逆变器的控制策略与性能分析(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【网络安全 --- xss-labs靶场】xss-labs靶场安装详细教程,让你巩固对xss漏洞的理解及绕过技巧和方法(提供资源)
一,资源下载准备 1-1 VMware 16.0 安装请参考以下博客,若已经安装请忽略: 【网络安全 --- 工具安装】VMware 16.0 详细安装过程(提供资源)-CSDN博客【网络安全 --- 工具安装】VMware 16.0 详细安装过程(…...

蓝桥每日一题(day 3: 蓝桥587.约数个数)--数学--easy
题目 解题核心: 分解质因数,每个质因数的次方1的累乘积就是anscode #include <iostream> #include<algorithm> #include<unordered_map> //# #include<> typedef long long LL; const int N 110, MOD 1e9 7;using namespac…...

深入剖析Java类加载过程:探寻类加载器的奥秘
摘要: 一个java文件从被加载到被卸载这个生命过程,总共要经历4个阶段: 加载->链接(验证准备解析)->初始化(使用前的准备)->使用->卸载 其中类加载过程包括加载、验证、准备、解析和初始化五个阶…...
PHP yield
概念: Generator:带 yield的function yield:Generator或task的中断关键字,执行到yield时一次调度周期执行完即阻塞,并返回右侧表达式结果,等待下一次调度器运行next()或迭代遍历才会继续往下执行࿰…...

react antd实现upload上传文件前form校验,同时请求带data
最近的需求,两个下拉框是必填项,点击上传按钮,如果有下拉框没选要有提示,如图 如果直接使用antd的Upload组件,一点击文件选择的窗口就打开了,哪怕在Button里再加点击事件,也只是(几乎…...
echars 设置滚动条演示,
dataZoom: [// 滑动条{zoomLock:true,xAxisIndex: 0, // 这里是从X轴的0刻度开始type: "slider", // 这个 dataZoom 组件是 slider 型 dataZoom 组件startValue: 0, // 从头开始。endValue: 20, // 一次性展示几个。// fillerColor: "#023661", // 选中范围…...

代码随想录算法训练营第五十八天|583.两个字符串的删除操作 、72. 编辑距离
代码随想录算法训练营第五十八天|583.两个字符串的删除操作 、72. 编辑距离 文章目录 代码随想录算法训练营第五十八天|583.两个字符串的删除操作 、72. 编辑距离[toc]583.两个字符串的删除操作求公共部分长度:即最长公共子串 72. 编辑距离 583.两个字符串的删除操作…...
)
1024网络技术命令汇总(第54课)
1024网络技术命令汇总(第54课) 1 查询命令 display ? display current-configuration //查看全部的配置信息 display interface brief //查看接口的信 display ip interface brief //查看IP地址的接口信息状态 display arp all …...
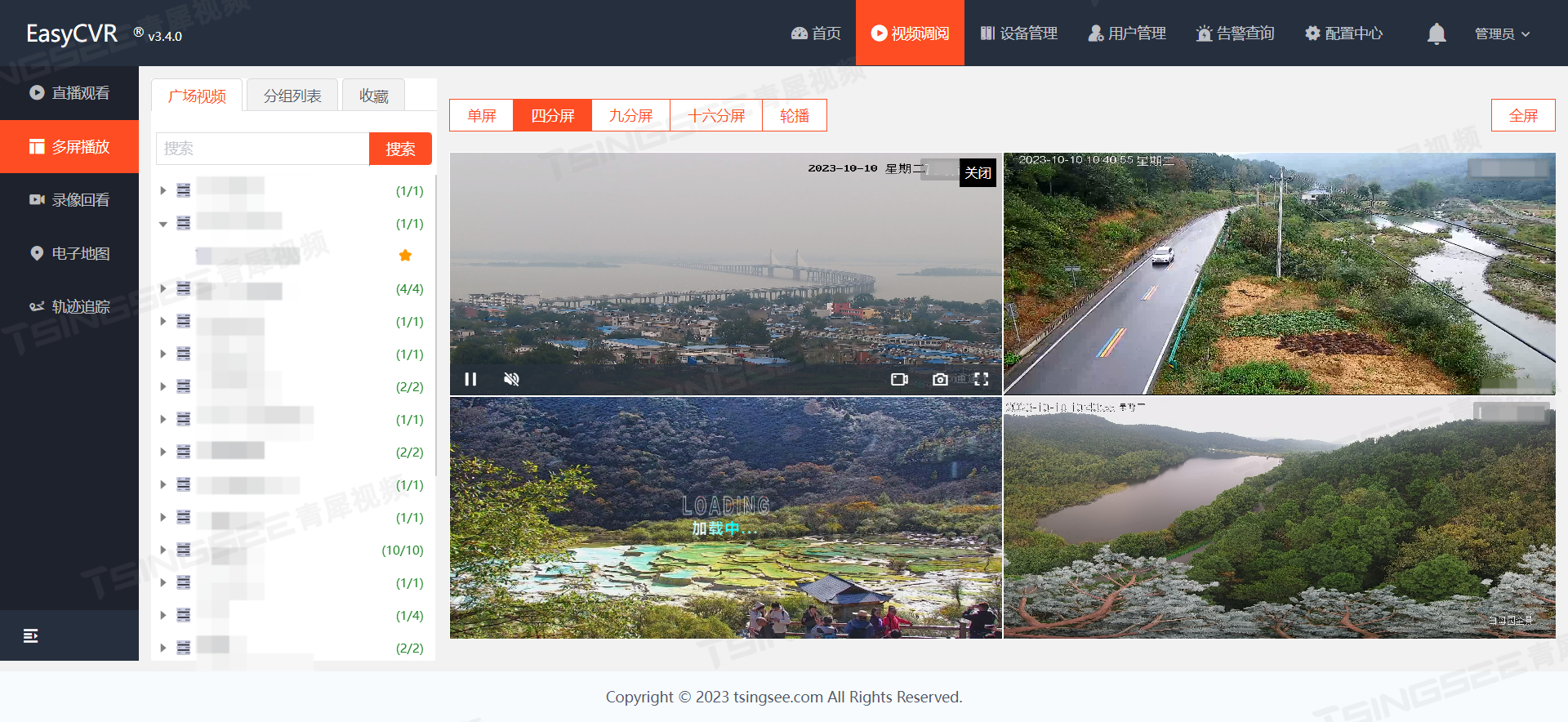
智慧河湖方案:AI赋能水利水务,构建河湖智能可视化监管大数据平台
一、方案背景 我国江河湖泊众多,水系发达。伴随着经济社会快速发展,水生态水环境问题成为群众最关注的民生议题之一。一些河流开发利用已接近甚至超出水环境承载能力,一些地区废污水排放量居高不下,一些地方侵占河道、围垦湖泊等…...
界面组件DevExpress WPF v23.1 - 全面升级文档处理功能
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...

【C语言必知必会 | 第八篇】一文带你精通循环结构
引言 C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。它在编程语言中具有举足轻重的地位。 此文为【C语言必知必会】系列第八篇,进行C语言循环结构的专项练习,结合专题优质题目,带领读者从0开始࿰…...

同一个线程池执行不同类型的任务
1、同一个线程池可以执行不同的任务类型,也可以带返回值,也可以不带返回值的 import com.google.common.util.concurrent.ThreadFactoryBuilder; import com.vip.vman.result.BasicResult; import lombok.extern.slf4j.Slf4j; import org.springframewor…...

wanwu框架:中文AI应用开发全栈解决方案,从RAG到智能体工作流
1. 项目概述:一个面向中文场景的AI应用开发框架最近在AI应用开发领域,一个名为“wanwu”的项目在开发者社区里引起了不小的讨论。这个由UnicomAI团队开源的项目,定位非常清晰:它旨在为中文场景下的AI应用开发,提供一个…...

惯性摩擦焊机早期故障检测与排除技术实现【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,查看文章底部二维码 (1)两重分段威布尔模型与早期故障拐点求解࿱…...

AI上下文管理、上下文机制与强化学习的深度融合:2026工业级实战教程
✅ 核心结论先行:截至2026年,上下文管理(Context Management)已不再是LLM的“辅助能力”,而是智能体决策系统的中枢神经系统;而强化学习(RL)不再仅用于策略优化,已进化为…...

别再只盯着电压电流了!手把手教你读懂USB PD 3.2扩展消息里的‘身份证’与‘体检报告’
解码USB PD 3.2扩展消息:从设备身份到安全性能的全维度解析 当我们拿到一款支持USB PD快充的设备时,大多数人第一反应是查看它的电压和电流规格。这当然没错,但如果你只关注这些基础参数,可能会错过隐藏在协议层中的关键信息。USB…...

Matplotlib 柱形图:老板,这柱不是我画的,是数据自己长的
Matplotlib 柱形图柱形图(Bar Chart) 是一种用矩形柱子的高度(或长度)来表示数据大小的统计图表,是数据可视化中最基础、最常用的图表类型之一。在 Matplotlib 中,柱形图主要通过两个函数实现:函…...
文件,附Pandas和PyTorch实战)
别再乱用JSON存数据了!聊聊Python里更省心的pickle(.pkl)文件,附Pandas和PyTorch实战
Python数据持久化实战:为什么pickle比JSON更值得选择? 当你需要在Python中保存一个嵌套字典、自定义类实例或是Pandas DataFrame时,第一反应可能是用JSON——毕竟它简单通用。但每次遇到datetime对象或自定义类时,JSON的局限性就会…...

终极实战:5个高效微信自动化场景,用wxauto构建你的智能机器人
终极实战:5个高效微信自动化场景,用wxauto构建你的智能机器人 【免费下载链接】wxauto Windows版本微信客户端(非网页版)自动化,可实现简单的发送、接收微信消息,简单微信机器人 项目地址: https://gitco…...

【2026年AI DevOps分水岭】:Docker AI Toolkit全新Agent编排框架上线,支持AutoGen/MetaGPT原生集成——现在不装,下周CI/CD流水线将自动拒绝旧版镜像
更多请点击: https://intelliparadigm.com 第一章:Docker AI Toolkit 2026 最新版功能 Docker AI Toolkit 2026 是面向 AI 工程化部署的下一代容器化工具链,深度集成模型编译、量化推理、分布式训练监控与合规性审计能力。相比 2025 版本&a…...

终极指南:用BthPS3驱动让PS3控制器在Windows上重获新生
终极指南:用BthPS3驱动让PS3控制器在Windows上重获新生 【免费下载链接】BthPS3 Windows kernel-mode Bluetooth Profile & Filter Drivers for PS3 peripherals 项目地址: https://gitcode.com/gh_mirrors/bt/BthPS3 还记得那些年,你满怀期待…...

终极指南:如何快速实现视频号资源批量下载
终极指南:如何快速实现视频号资源批量下载 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为手动下载视频号内…...