理解redis的数据结构
redis为什么快?
首先可以想到内存读写数据本来就快,然后IO复用快,单线程没有静态消耗和锁机制快。
还有就是数据结构的设计快。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是 Redis 快速处理数据的基础。
redis的值的数据类型:就是 String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)。而这里,我们说的数据结构,是要去看看它们的底层实现。
底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。它们和数据类型的对应关系如下图所示:
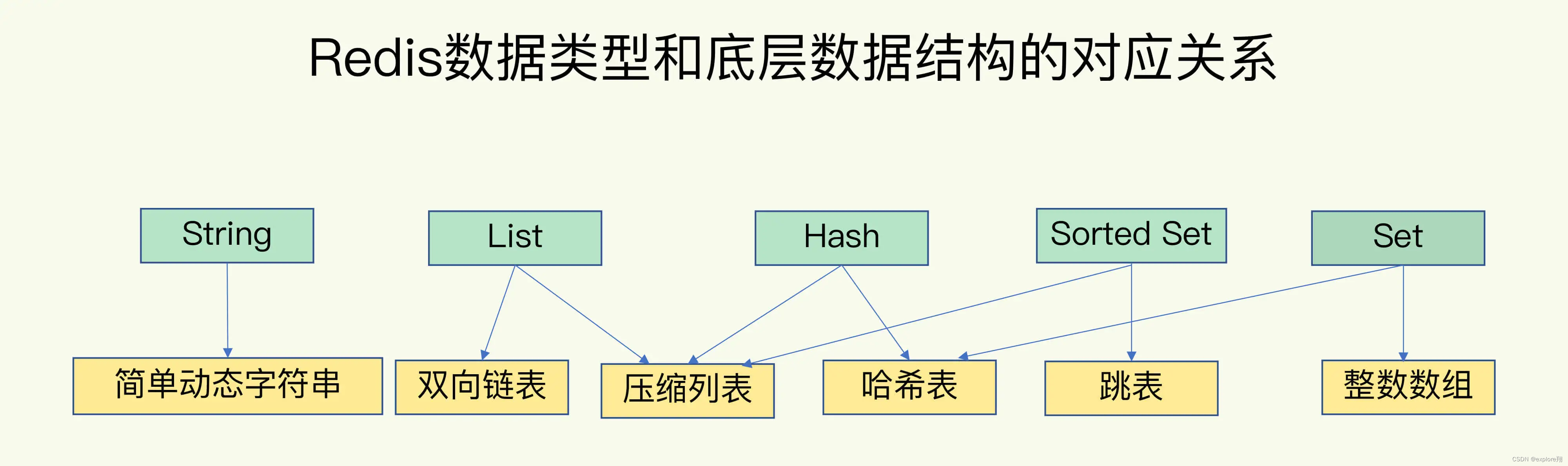
可以看到,String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。(这里应该是错的,有序集合使用了压缩列表、哈希表、跳表三种数据结构,并且哈希表和跳表共存,哈希表是为了点查使用,跳表是为了扫描使用。)
这些都是值的底层结构,那么键和值怎么组织的?
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
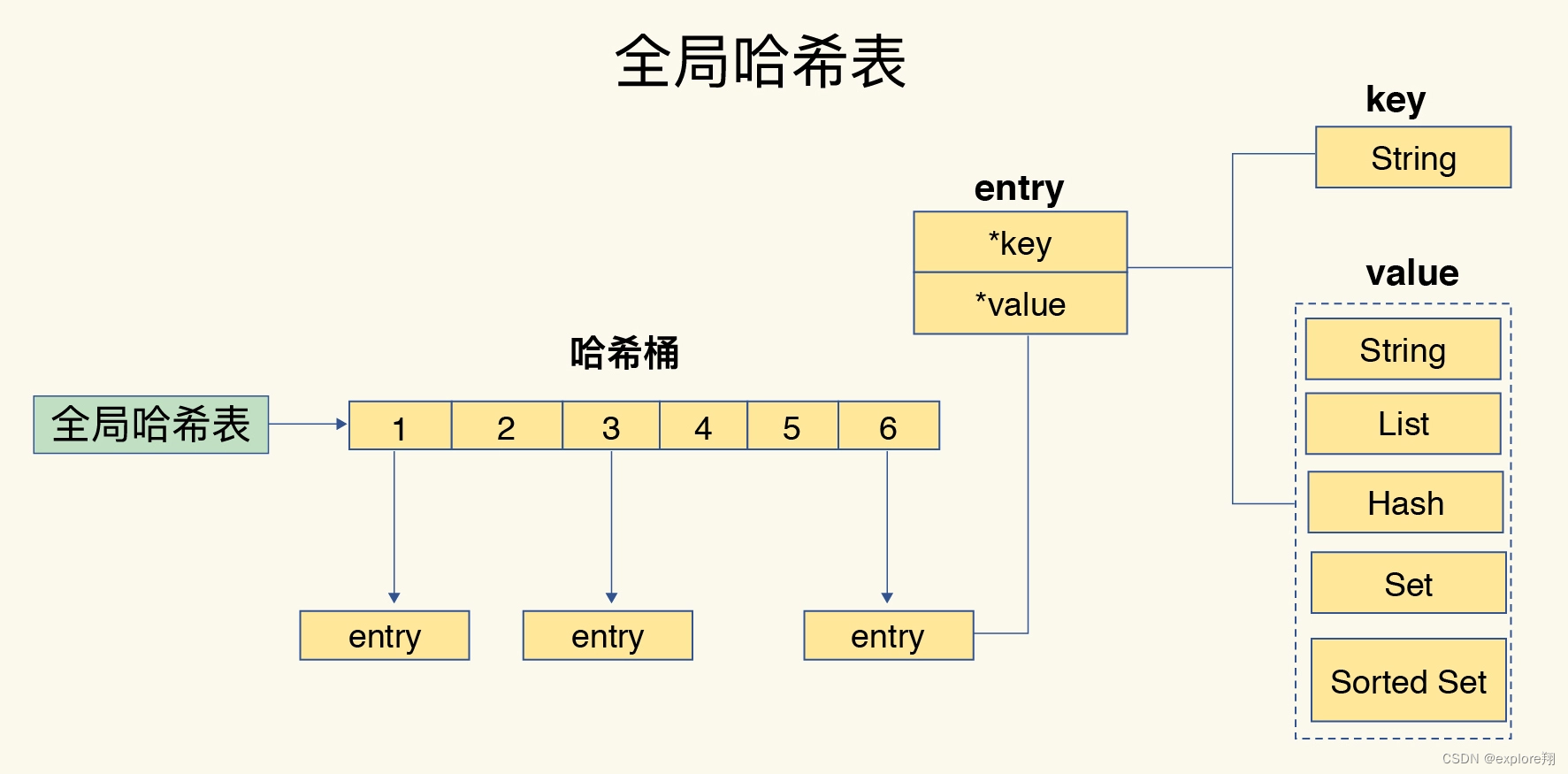
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
为什么哈希表操作变慢了?
这其实是因为你忽略了一个潜在的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
如果采用拉链法的话,数据太多,拉链太长,就会增加查找时间,就不快了。
所以采用的是rehash法。Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;释放哈希表 1 的空间。
第二步设涉及的拷贝操作很多,会造成 Redis 线程阻塞,无法服务其他请求。
所以是渐进式rehash。第二步是每处理一次客户端请求,把一个数组的位置进行转移。
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
跳表
具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:
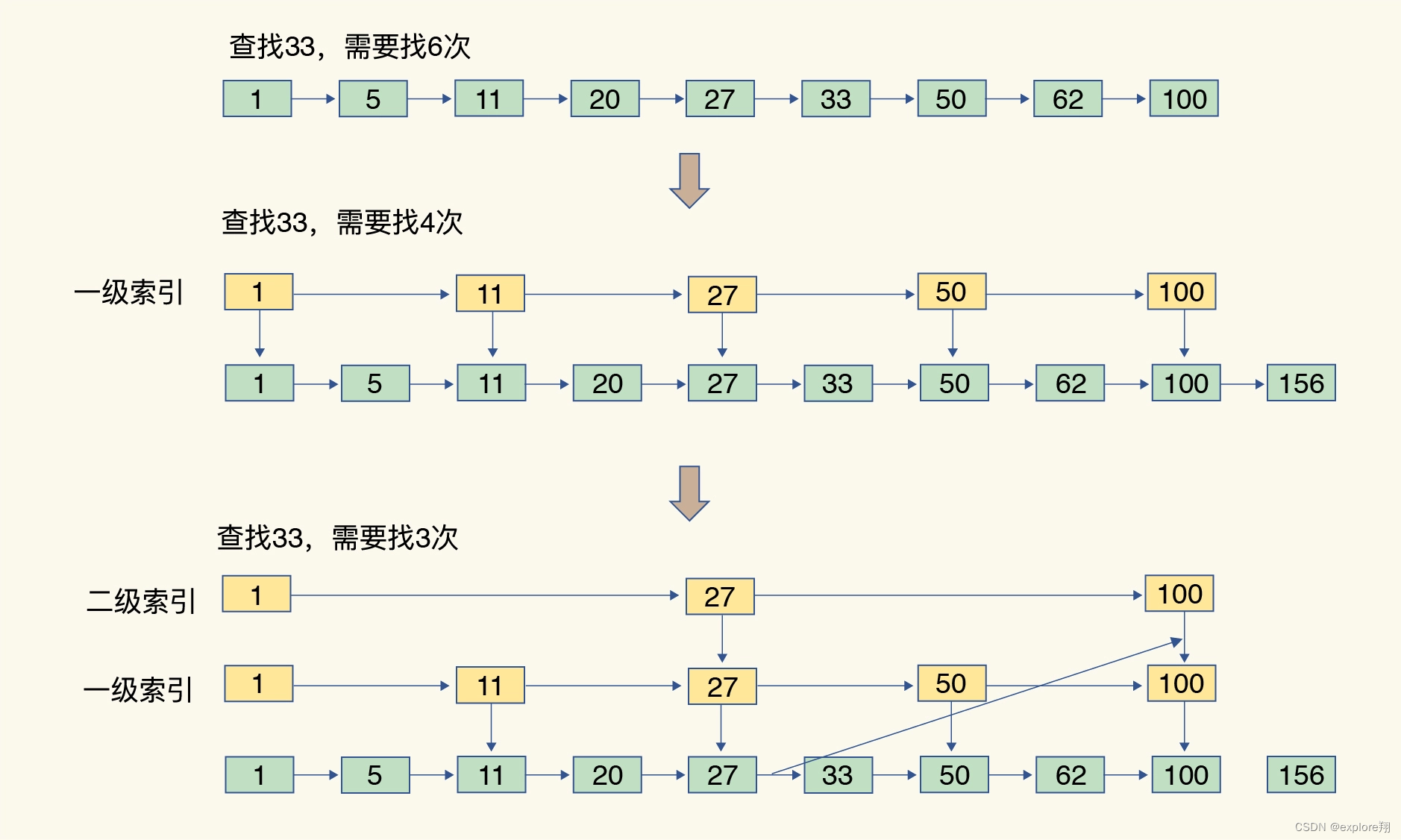
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 O(logN)。
(其实是空间换时间的做法,而且链表必须是有序的)
操作复杂度分析
1.单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
2、范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免(不过,Redis 从 2.8 版本开始提供了 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据。这样一来,相比于 HGETALL、SMEMBERS 这类操作来说,就避免了一次性返回所有元素而导致的 Redis 阻塞。)
3、统计操作,是指集合类型对集合中所有元素个数的记录,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
第四,例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
总结:数据结构为什么快,因为采用了全局哈希表可以快速定位key-value。然后value的数据结构很多采用哈希表实现(比如hash,set,sortedset)。而且有序集合采用了跳表实现logn级别的查找复杂度。当需要遍历时最好用SCAN,比较快。FIFO类型可以用list
问题:整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
**内存利用率,数组和压缩列表都是非常紧凑的数据结构,**它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
(Redis底层的使用数组和压缩链表对数据大小限制在64个字节以下,当大于64个字节会改变存储数据的数据结构,所以随机访问对于CPU高速缓存没啥影响)
相关文章:
理解redis的数据结构
redis为什么快? 首先可以想到内存读写数据本来就快,然后IO复用快,单线程没有静态消耗和锁机制快。 还有就是数据结构的设计快。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操…...
Lecture6 逻辑斯蒂回归(Logistic Regression)
目录 1 常用数据集 1.1 MNIST数据集 1.2 CIFAR-10数据集 2 课堂内容 2.1 回归任务和分类任务的区别 2.2 为什么使用逻辑斯蒂回归 2.3 什么是逻辑斯蒂回归 2.4 Sigmoid函数和饱和函数的概念 2.5 逻辑斯蒂回归模型 2.6 逻辑斯蒂回归损失函数 2.6.1 二分类损失函数 2.…...
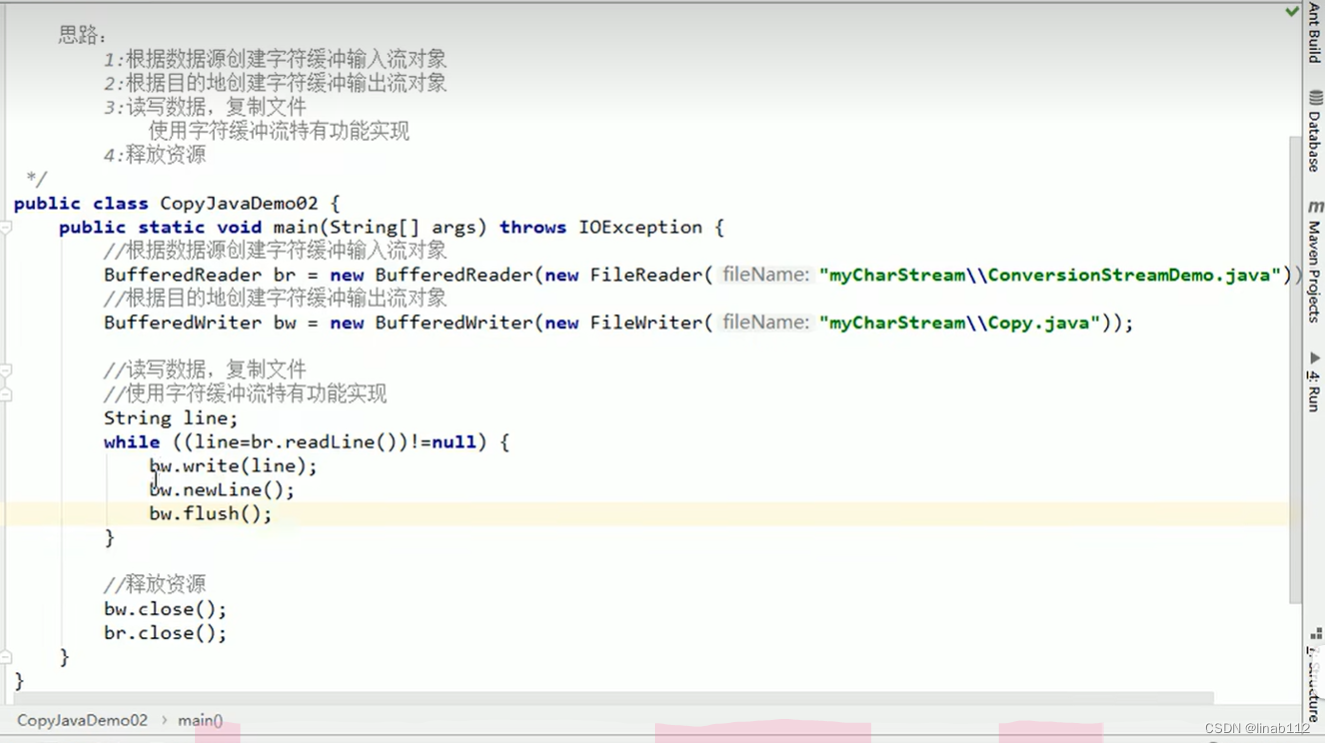
File类及IO流说明
目录 1.File类说明 (1)构造方法创建文件 (2)创建功能 (3)File类的判断和获取功能 (4)文件删除功能 2.I/O流说明 (1).分类 3.字节流写数据 (1)说明 (2)字节流写数据的三种方式 (3)写入时实现换行和追加写入 (4)异常处理中加入finally实现资源的释放 4.字节流读数据 …...

优秀的网络安全工程师应该有哪些能力?
网络安全工程师是一个各行各业都需要的职业,工作内容属性决定了它不会只在某一方面专精,需要掌握网络维护、设计、部署、运维、网络安全等技能。目前稍有经验的薪资在10K-30K之间,全国的网络安全工程师还处于一个供不应求的状态,因…...

[C++11] auto初始值类型推导
背景:旧标准的auto 在旧标准中,auto代表“具有自动存储期的 局部变量” auto int i 0; //具有自动存储期的局部变量 //C98/03,可以默认写成int i0; static int j 0; //静态类型的定义方法实际上,我们很少使用auto,…...

【Java】List集合去重的方式
List集合去重的方式方式一:利用TreeSet集合特性排序去重(有序)方式二:利用HashSet的特性去重(无序)方式三:利用LinkedHashSet去重(有序)方式四:迭代器去重&am…...
每个人都应该知道的5个NLP代码库
在本文中,将详细介绍目前常用的Python NLP库。内容译自网络。这些软件包可处理多种NLP任务,例如词性(POS)标注,依存分析,文档分类,主题建模等等。NLP库的基本目标是简化文本预处理。目前有许多工…...
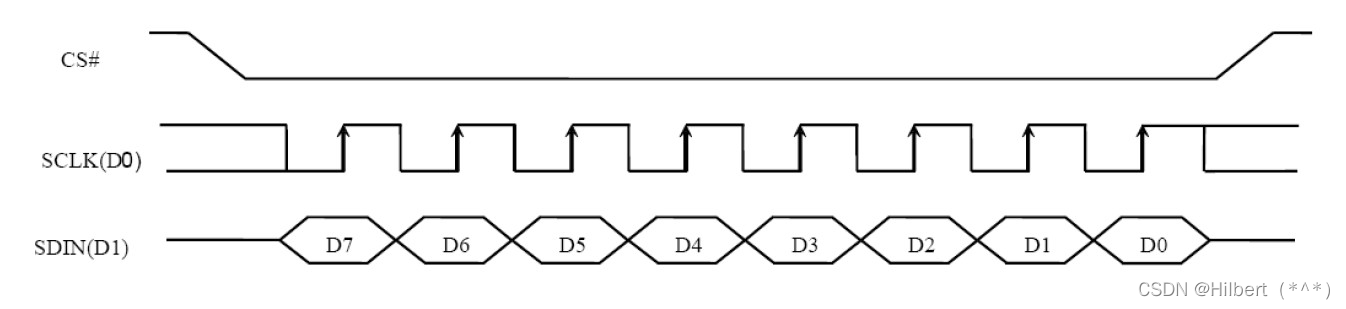
SPI协议介绍
SPI协议介绍 文章目录SPI协议介绍一、 SPI硬件知识1.1 硬件连线1.2 SPI控制器内部结构二、 SPI协议2.1 传输示例2.2 SPI模式致谢一、 SPI硬件知识 1.1 硬件连线 引脚含义如下: 引脚含义DO(MOSI)Master Output, Slave Input,SPI主控用来发出数据&#x…...

MySQL数据库中索引的优点及缺点
一、索引的优点 1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度; 2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性; 3)可以加速表与表之间的链接; 4&#…...
sort函数总结(基础篇))
(q)sort函数总结(基础篇)
1.sort函数 介绍:这是一个C的函数,包含于algorithm头文件中。 基本格式: sort(起始地址(常为变量名),排序终止的地址(变量名加上排序长度),自定义的比较函数) 重点&a…...

【数据库】MongoDB数据库详解
目录 一,数据库管理系统 1, 什么是数据库 2,什么是数据库管理系统 二, NoSQL 是什么 1,NoSQL 简介 2,NoSQL数据库 3,NoSQL 与 RDBMS 对比 三,MongoDB简介 1, MongoDB 是什…...

【linux】进程间通信——system V
system V一、system V介绍二 、共享内存2.1 共享内存的原理2.2 共享内存接口2.2.1 创建共享内存shmget2.2.2 查看IPC资源2.2.3 共享内存的控制shmctl2.2.4 共享内存的关联shmat2.2.5 共享内存的去关联shmdt2.3 进程间通信2.4 共享内存的特性2.5 共享内存的大小三、消息队列3.1 …...

计算机网络的基本组成
计算机网络是由多个计算机、服务器、网络设备(如路由器、交换机、集线器等)通过各种通信线路(如有线、无线、光纤等)和协议(如TCP/IP、HTTP、FTP等)互相连接组成的复杂系统,它们能够在物理层、数…...
【数据结构趣味多】Map和Set
1.概念及场景 Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 在此之前,我还接触过直接查询O(N)和二分查询O(logN),这两个查询有很多不足之出,直接查询的速率太低,而二分查…...

Redis 之企业级解决方案
文章目录一、缓存预热二、缓存雪崩三、缓存击穿四、缓存穿透五、性能指标监控5.1 监控指标5.2 监控方式🍌benchmark🍌monitor🍌slowlog提示:以下是本篇文章正文内容,Redis系列学习将会持续更新 一、缓存预热 1.1 现象…...
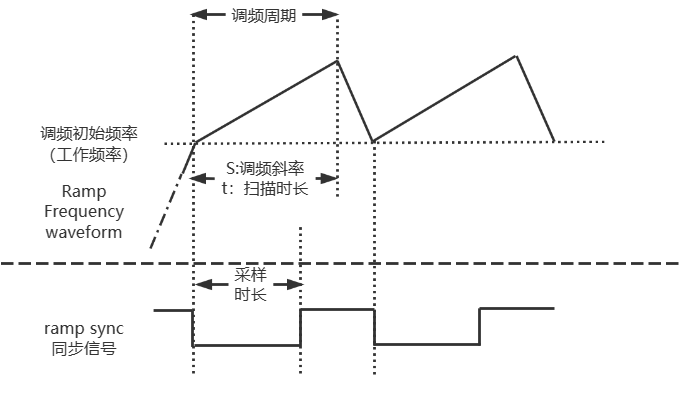
雷达实战之射频前端配置说明
在无线通信领域,射频系统主要分为射频前端,以及基带。从发射通路来看,基带完成语音等原始信息通过AD转化等手段转化成基带信号,然后经过调制生成包含跟多有效信息,且适合信道传输的信号,最后通过射频前端将信号发射出去…...

Android SDK删除内置的触宝输入法
问题 Android 8.1.0, 展锐平台。 过CTA认证,内置的触宝输入法会连接网络,且默认就获取到访问网络的权限,没有弹请求窗口访问用户,会导致过不了认证。 预置应用触宝输入法Go版连网未明示(开启后࿰…...

[202002][Spring 实战][第5版][张卫滨][译]
[202002][Spring 实战][第5版][张卫滨][译] habuma/spring-in-action-5-samples: Home for example code from Spring in Action 5. https://github.com/habuma/spring-in-action-5-samples 第 1 部分 Spring 基础 第 1 章 Spring 起步 1.1 什么是 Spring 1.2 初始化 Spr…...

H5视频上传与播放
背景 需求场景: 后台管理系统: (1)配置中支持上传视频、上传成功后封面缩略图展示,点击后自动播放视频; (2)配置中支持上传多个文件; 前台系统: &#…...
通过OpenAI来做机械智能故障诊断-测试(1)
通过OpenAI来做机械智能故障诊断 1. 注册使用2. 使用案例1-介绍故障诊断流程2.1 对话内容2.2 对话小结3. 使用案例2-写一段轴承故障诊断的代码3.1 对话内容3.2 对话小结4. 对话加载Paderborn轴承故障数据集并划分4.1 加载轴承故障数据集并划分第一次测试4.2 第二次加载数据集自…...

这五家软件许可优化的公司,我直接说结论。
你要是搞工程设计软件的(CAD、SolidWorks、CATIA这些),在国内,闭眼找。 你要是啥软件都有一大堆,不差钱人也多,上OptiCore(优化内核)。 你要是全在云上跑、主用微软全家桶…...

7天职场内耗清零打卡计划
7天职场内耗清零打卡计划(极简好坚持)每天 3 件小事,不累不费脑,7 天稳住心态第一天:断胡思乱想别人随口一句话,当场听完就翻篇,绝不反复琢磨上班只盯自己手头事,不偷看别人忙不忙、…...

制造业数据架构设计顶层规划方案:数据资源规划、基础数据管理、数据分析应用、数据治理体系 、实施路线图
该方案针对企业数据架构空白、缺乏统一模型与治理体系的问题,提出了以数据资源规划、主数据与元数据管理、数据分析应用及数据治理为核心的整体架构。通过明确数据分布与流向、构建企业级数据仓库与治理平台,最终实现数据驱动决策与业务规范化࿰…...

如何快速掌握智能电源管理:macOS用户的完整配置指南
如何快速掌握智能电源管理:macOS用户的完整配置指南 【免费下载链接】SleeperX MacBook prevent idle/lid sleep! Hackintosh sleep on low battery capacity. 项目地址: https://gitcode.com/gh_mirrors/sl/SleeperX SleeperX是一款专为macOS用户设计的开源…...

被遗忘的女程序员沙拉:用模拟程序为互联网奠基,却因家庭放弃编程
为互联网奠基的女程序员沙拉 数学教师沙拉博姆利用暑假编写代码,她之后开发的东西最终演变成了互联网。作者包括凯蒂哈夫纳、萨米亚布齐德、劳拉伊森西以及科学领域被遗忘的女性倡议组织。 沙拉的编程之路 沙拉博姆从加州大学洛杉矶分校获得教学学位后,投…...

3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄
3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 您是否曾经因为缺少游戏手柄而无法畅玩那些只支持手柄操作的游戏?或者需要为特殊软件设计自定…...

【APP分发系统二开版】app打包一键免IOS免签封包分发平台源码 带绿标
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 60gx版APP分发系统在线IOS免签封包分发平台源码免签封装带绿标已对接码支付 这个源码某站卖300,主要是因为他有几个功能比较好。 支持一键IOS在线免签封装。买源码可免费协助…...

B2B制造业如何利用GEO优化获得精准询盘:实战指南
B2B制造业如何利用GEO优化获得精准询盘:实战指南 摘要 :随着AI搜索渗透率超过85%,B2B制造业的获客逻辑正在被重塑。本文详细介绍GEO(Generative Engine Optimization)优化技术如何帮助工业品、机械配件企业获得精准询盘…...

USB PD芯片选型指南:从核心需求到方案对比的工程实践
1. 项目概述:为什么PD芯片选型是个技术活最近在做一个需要USB Type-C接口供电的项目,核心需求是实现完整的PD(Power Delivery)协议通信。这听起来像是个标准化的活儿,市面上芯片那么多,随便选一个不就行了&…...

3分钟学会B站缓存视频永久保存:m4s-converter完整使用指南
3分钟学会B站缓存视频永久保存:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵…...