【django2.0之Rest_Framework框架一】rest_framework序列器介绍
Django RestFramework(简称DRF) 提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST framework还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。
github地址: https://github.com/encode/django-rest-framework
中文文档:https://q1mi.github.io/Django-REST-framework-documentation/#django-rest-framework
1 项目基础搭建
1.1 安装DRF
pip install Django==2.0.13
pip install djangorestframework==3.10.3
pip install PyMySQL==1.0.2
1.2 创建django项目
django-admin startproject drfdemo
# 创建应用
python manage.py startapp students
在settings.py的INSTALLED_APPS中添加'rest_framework'和其他子应用:
INSTALLED_APPS = [...'rest_framework','students',
]
1.3 models和数据库设置
students/models.py 文件内容
class Student(models.Model):# 模型字段name = models.CharField(max_length=100,verbose_name="姓名")sex = models.BooleanField(default=1,verbose_name="性别")age = models.IntegerField(verbose_name="年龄")class_null = models.CharField(max_length=5,verbose_name="班级编号")description = models.TextField(max_length=1000,verbose_name="个性签名")class Meta:db_table="tb_student"verbose_name = "学生"verbose_name_plural = verbose_name
创建本地数据库,并在django项目中进行mysql链接
settings.py文件修改DATABASES内容:
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': "rest_django_stu",'HOST': '127.0.0.1','PORT': 3306,'USER': 'root','PASSWORD': 'root',}
}# 打印每次执行sql时输出 sql语句
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console': {'level': 'DEBUG','class': 'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level': 'DEBUG',},}
}
主引用中__init__.py设置使用pymysql作为数据库驱动
import pymysqlpymysql.install_as_MySQLdb()
在本地创建测试数据库:
# 连接本地mysql后执行
create database rest_django_stu charset=utf8;# 终端下执行数据迁移
python manage.py makemigrations
python manage.py migrate
2 序列化器-Serializer的基础使用
- 序列化:序列化器会把模型对象转换成字典,经过response以后变成json字符串
- 反序列化:把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
- 反序列化可以完成数据校验功能
2.1 定义序列化器
子应用下新建serializer.py文件,内容:
from rest_framework import serializers# 声明序列化器,所有的序列化器都要直接或者间接继承于 Serializer
class StudentSerializer(serializers.Serializer):"""学生信息序列化器"""# 1. 需要进行数据转换的字段id = serializers.IntegerField()name = serializers.CharField()age = serializers.IntegerField()sex = serializers.BooleanField()description = serializers.CharField()
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。 serializer是独立于数据库之外的存在。
常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=‘hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=‘both’, unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
选项参数:
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_length | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最大值 |
| min_value | 最小值 |
通用的选项参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
2.2 配置url路由分发
# 全局urls.py文件
from django.contrib import admin
from django.urls import path,re_path,include # re_path --- django1.11 urlurlpatterns = [path('admin/', admin.site.urls),path('stu/', include('student.urls')),
]# 子应用student/urls.py文件
from django.contrib import admin
from django.urls import path,re_path,include # re_path --- django1.11 url
from ser import views
urlpatterns = [path('students/', views.StudentsView.as_view()), # stu/students/
]
2.3 序列器的序列化功能
在子应用views.py文件中:
from django.http import JsonResponse
from django.views import View
from .serializers import StudentSerializer
from students.models import Student
class StudentView(View):def get(self,request): # [{},]# queryset类型数据# students = models.Student.objects.all() ## serializer_obj = StudentSerializer(instance=students,many=True) # 列表套字典# 序列化单条数据(模型类对象)students = models.Student.objects.get(id=1)serializer_obj = StudentSerializer(instance=students) #--字典print(serializer_obj.data,type(serializer_obj.data))return JsonResponse(serializer_obj.data,safe=False,json_dumps_params={'ensure_ascii':False})
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
- 使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
- 序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
- 序列化器的字段声明类似于我们前面使用过的表单系统。
- 开发restful api时,序列化器会帮我们把模型数据转换成字典.
- drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
2.4 反序列化功能
from rest_framework.views import APIView
class StudentsView(APIView):
# class StudentsView(View): # 基础视图类无法接收json数据。def post(self,request):# print('>>>>>>', request.POST) #由于用户提交的数据可能是json数据,django解析不了,所有我们借助drf来解析,就需要继承drf的APIView类print('>>>>>>', request.data) #{'name': 'chaochaochao', 'age': 18}字典类型数据serializer_obj = StudentSerializer(data=request.data)if serializer_obj.is_valid(): #所有字段校验都没问题,返回True,但凡是有一个字段校验失败,返回Falseprint('校验成功之后的数据',serializer_obj.validated_data)# 然后保存数据return JsonResponse(serializer_obj.validated_data)else:print(serializer_obj.errors)return JsonResponse({'error':'校验失败'},status=400)
2.4.1 数据验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用**is_valid()**方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
from rest_framework import serializers
class StudentSerializer(serializers.Serializer):# 需要转换的字段声明# 小括号里面声明主要提供给反序列化使用的name = serializers.CharField(required=True, max_length=20)age = serializers.IntegerField(max_value=150, min_value=0,required=True)sex = serializers.BooleanField(default=True)description = serializers.CharField(required=False,allow_null=True, allow_blank=True) #required=False,字段都可以不传递给后端,allow_null=True,允许提交过来的数据为空值(null--None),allow_blank=True 允许提交过来的数据为空字符串
如果觉得这些还不够,需要再补充定义验证行为,可以使用以下三种方法:
2.4.2 局部钩子
validate_字段名 方式
对<field_name>字段进行验证,如
class StudentSerializer(serializers.Serializer):"""学生数据序列化器"""...# 序列化器中可以自定义单个字段的验证方法 def validate_<字段名>(用户提交的字段数据):def validate_name(self,data):if(data=="老男孩"):raise serializers.ValidationError("用户名不能是老男孩")# 验证完成以后务必要返回字段值return data
2.4.3 全局钩子
在序列化器中需要同时对多个字段进行比较验证时,可以定义validate方法来验证
class StudentSerializer(serializers.Serializer):"""学生数据序列化器"""...# 方法名时固定的,用于验证多个字段,参数就是实例化序列化器类时的data参数def validate(self,data):name = data.get("name")if(name == "python"):raise serializers.ValidationError("用户名不能是python")age = data.get("age")if(age==0):raise serializers.ValidationError("年龄不能是0")# 验证完成以后务必要返回datareturn data
2.4.4 自定义检验函数
在字段中添加validators选项参数,也可以补充验证行为
def check_age(age):if age ==50:raise serializers.ValidationError("年龄不能刚好是50")return ageclass StudentSerializer(serializers.Serializer):# 需要转换的字段声明# 小括号里面声明主要提供给反序列化使用的name = serializers.CharField(required=True, max_length=20)age = serializers.IntegerField(max_value=150, min_value=0,required=True,validators=[check_age])sex = serializers.BooleanField(default=True)description = serializers.CharField(required=False,allow_null=True, allow_blank=True)
3 序列化器 保存和修改数据库
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象.
3.1 保存和修改方式
首先我们可以在views中直接写上保存数据的代码
# views.py 方式一
from django.http import JsonResponse
from django.views import View
from .serializers import StudentSerializer
from students.models import Student
class StudentView(View):def post(self,request):"""添加一个学生"""# 接受参数post_data = request.POSTdata = {"name":post_data.get('name'),"age":post_data.get('age'),"sex":post_data.get('sex'),"description":post_data.get('description'),}serializer = StudentSerializer(data=data)serializer.errors result = serializer.is_valid(raise_exception=True)print( "验证结果:%s" % result )print( serializer.validated_data ) student = Student.objects.create(name=serializer.validated_data.get("name"),age=serializer.validated_data.get("age"),sex=serializer.validated_data.get("sex"))print(student)return JsonResponse({"message": "ok"})
还可以通过序列化器提供的create()和update()两个方法来实现。
from rest_framework import serializers
from students.models import Studentclass StudentSerializer(serializers.Serializer):# 需要转换的字段声明# 小括号里面声明主要提供给反序列化使用的name = serializers.CharField(required=True, max_length=20)age = serializers.IntegerField(max_value=150, min_value=0,required=True)sex = serializers.BooleanField(default=True)description = serializers.CharField(required=False,allow_null=True, allow_blank=True) #required=False,# 添加和更新代码# 序列化器中会提供了两个方法: create 和 update,方法名是固定的def create(self, validated_data): # validated_data 参数,在序列化器调用时,会自动传递验证完成以后的数据student = Student.objects.create(name=self.validated_data.get("name"),age=self.validated_data.get("age"),sex=self.validated_data.get("sex"))return studentdef update(self,instance,validated_data): #instance表示当前更新的记录对象"""更新学生信息"""instance.name=validated_data.get("name")instance.sex=validated_data.get("sex")instance.age=validated_data.get("age")instance.description=validated_data.get("description")# 调用模型的save更新保存数据instance.save()return instance
实现了上述两个方法后,在视图中调用序列化器进行反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了
from django.http import JsonResponse
from django.views import View
from .serializers import StudentSerializer
from students.models import Student
class StudentView(View):def put(self,request):"""更新学生信息"""# 接受参数data = {"id":9,"name":"abc","age":18,"sex":1,"description":"测试",}# 获取要修改的数据instance = Student.objects.get(pk=data.get("id"))# 调用序列化器serializer = StudentSerializer(instance=instance,data=data)# 验证serializer.is_valid(raise_exception=True)# 转换成模型数据 如果是添加,自动会调用create,更新就自动调用updatestudent = serializer.save()return JsonResponse({"message": "ok"})
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
3.2 说明
1) 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
# request.user 是django中记录当前登录用户的模型对象
serializer.save(owner=user)
2)默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新(只检验传来的数据)
# 更新学生的部分字段信息,当数据库允许为空,但是序列化器要求必须字段填写的时候,可以使用以下方式避开
serializer = StudentSerializer(instance=instance, data=data, partial=True)
把上面序列化器子应用sers和反序列化器子应用users里面的序列化器进行对比。
from rest_framework import serializersclass StudentSerializer(serializers.Serializer):"""学生信息序列化器"""# 1. 需要进行数据转换的字段id = serializers.IntegerField()name = serializers.CharField()age = serializers.IntegerField()sex = serializers.BooleanField()description = serializers.CharField()
from rest_framework import serializers
from students.models import Studentclass StudentSerializer(serializers.Serializer):# 需要转换的字段声明# 小括号里面声明主要提供给反序列化使用的name = serializers.CharField(required=True, max_length=20)age = serializers.IntegerField(max_value=150, min_value=0,required=True)sex = serializers.BooleanField(default=True)description = serializers.CharField(required=False, allow_null=True, allow_blank=True)# 添加和更新代码# 序列化器中会提供了两个方法: create 和 update,方法名是固定的def create(self, validated_data): # validated_data 参数,在序列化器调用时,会自动传递验证完成以后的数据student = Student.objects.create(name=self.validated_data.get("name"),age=self.validated_data.get("age"),sex=self.validated_data.get("sex"))return studentdef update(self,instance,validated_data):"""更新学生信息"""instance.name=validated_data.get("name")instance.sex=validated_data.get("sex")instance.age=validated_data.get("age")instance.description=validated_data.get("description")# 调用模型的save更新保存数据instance.save()return instance
可以发现,反序列化器中的代码会包含了序列化器中的大部分代码,除了ID字段的声明。
所以在开发的时候,我们一般都是直接写在一起,那么有些字段只会出现在序列化器阶段,例如ID。还有些字段只会出现在反序列化阶段,例如:用户密码。
那么, 我们需要在序列化器类中,声明那些字段是在序列化时使用,哪些字段在反序列化中使用了。
最终序列化器中的代码:
from rest_framework import serializers
from students.models import Studentclass StudentSerializer(serializers.Serializer):# 需要转换的字段声明# 小括号里面声明主要提供给反序列化使用的id=serializers.IntegerField(read_only=True) #read_only=True读取数据时能读出来,反序列化校验数据的时候不需要校验。name = serializers.CharField(required=True, max_length=20)age = serializers.IntegerField(max_value=150, min_value=0,required=True)sex = serializers.BooleanField(default=True,write_only=True)#write_only=True读取数据时不能读出来。但是反序列化校验数据保存时,需要传给我们的序列化器description = serializers.CharField(required=True, allow_null=True, allow_blank=True)# 添加和更新代码# 序列化器中会提供了两个方法: create 和 update,方法名是固定的def create(self, validated_data): # validated_data 参数,在序列化器调用时,会自动传递验证完成以后的数据student = Student.objects.create(name=self.validated_data.get("name"),age=self.validated_data.get("age"),sex=self.validated_data.get("sex"))return studentdef update(self,instance,validated_data):"""更新学生信息"""instance.name=validated_data.get("name")instance.sex=validated_data.get("sex")instance.age=validated_data.get("age")instance.description=validated_data.get("description")# 调用模型的save更新保存数据instance.save()return instance
4. 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为
Serializer生成validators,比如unique_together - 包含默认的
create()和update()的实现
子应用下创建一个StudentModelSerializer.py 文件
from rest_framework import serializers
from students.models import Student
class StudentModelSerializer(serializers.ModelSerializer):# 字段声明# 如果模型类序列化器,必须声明本次调用是哪个模型,模型里面的哪些字段class Meta:model = Student # model 指明参照哪个模型类fields = ["id","name","age","description","sex"]# fields = "__all__" # 表示操作模型中的所有字段# 添加额外的验证选项exclude = ['id',] # 排除字段extra_kwargs = {"sex":{"write_only":True,},"id":{"read_only":True,}}
4.1 可用字段
- 使用fields来明确字段,
__all__表名包含所有字段,也可以写明具体哪些字段,如
class StudentModelSerializer(serializers.ModelSerializer):"""学生数据序列化器"""class Meta:model = Studentfields = ['id', 'age', 'name',"description"]
- 使用exclude可以明确排除掉哪些字段
class StudentModelSerializer(serializers.ModelSerializer):"""学生数据序列化器"""class Meta:model = Studentexclude = ['sex']
- 指明只读字段[少用,通过
extra_kwargs更方便一些
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
class StudentModelSerializer(serializers.ModelSerializer):"""学生数据序列化器"""class Meta:model = Studentfields = ['id', 'age', 'name',"description"]read_only_fields = ('id',)#write_only_fields = ('sex',)
- 额外参数
extra_kwargs
我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
from rest_framework import serializers
from students.models import Student
class StudentModelSerializer(serializers.ModelSerializer):# 额外字段声明,必须在fields里面也要声明上去,否则序列化器不会调用password = serializers.CharField(write_only=True,required=True) #加上write_only的字段可以直接删除# 如果模型类序列化器,必须声明本次调用是哪个模型,模型里面的哪些字段class Meta:model = Student# fields = ["id","name","age","description","sex","password"]fields = ["id","name","age","description","sex"]# fields = "__all__" # 表示操作模型中的所有字段# 添加额外的验证选项,比如额外的字段验证extra_kwargs = {"sex":{"write_only":True,},"id":{"read_only":True,}}
示例:接收额外参数,进行检验,但不保存
# serializers.py
from rest_framework import serializers
from ser import models
class StudentModelSerializer(serializers.ModelSerializer):password = serializers.CharField(max_length=5) # 接收额外passwordclass Meta:model = models.Studentfields = ['name', 'age', 'password','class_null','sex', 'description']extra_kwargs = {'id':{'read_only':True},'name':{'max_length':5,# 定制错误信息'error_messages': {'max_length':'name不能超过5个字符',},# 自定义校验函数# 'validators':[]},}# 局部钩子def validate_password(self,data):if '666' in data:raise serializers.ValidationError('密码里不能含有666')return data# views.py
from django.shortcuts import render
from rest_framework.views import APIView
from ser import models
from mser.serializers import StudentModelSerializer
from django.http import JsonResponseclass StudentsView(APIView):def get(self,request):all_student = models.Student.objects.all() #[{},]serializer_obj = StudentModelSerializer(instance=all_student,many=True)return JsonResponse(serializer_obj.data,safe=False)def post(self,request):serializer_obj = StudentModelSerializer(data=request.data)print(serializer_obj.is_valid())if serializer_obj.is_valid():print('>>>>>>>',serializer_obj.validated_data)# 保存之前进行删除serializer_obj.validated_data.pop('password')obj = serializer_obj.save()new_obj = StudentModelSerializer(instance=obj)return JsonResponse(new_obj.data)else:print(serializer_obj.errors)return JsonResponse({'error':'校验失败'})
相关文章:

【django2.0之Rest_Framework框架一】rest_framework序列器介绍
Django RestFramework(简称DRF) 提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST framework还提供了认证、权限、限流、过滤、分页、接口文…...
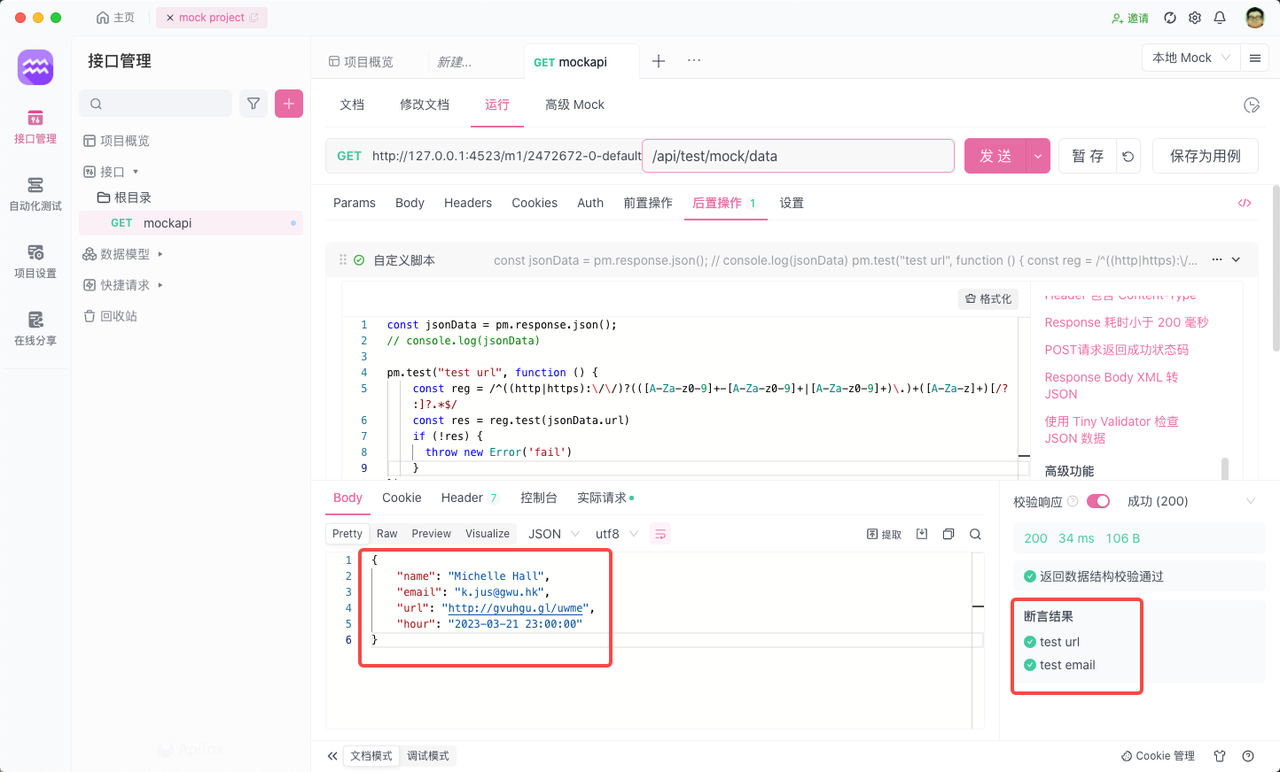
Mock 测试详解:什么是 Mock 测试
Mock测试 什么是 Mock ? Mock 的意思就是,当你很难拿到源数据时,你可以使用某些手段,去获取到跟源数据相似的假数据,拿着这些假数据,前端可以先行开发,而不需要等待后端给了数据后再开发。 Mo…...

Android端自定义铃声
随着移动应用竞争进入红海时代,如何在APP推送中别出心裁显得尤为重要。例如对自己的APP推送赋予独特的推送铃声,能够给用户更加理想的使用体验。 1、个性化提醒铃声有助于当收到特定类型的消息时,用户能够立刻识别出来。 2、不同的推送铃声…...

docker mysql 5.7
1.docker 安装mysql 5.7 docker pull mysql:5.72.配置容器MySQL数据、配置、日志挂载宿主机目录 # 宿主机创建数据存放目录映射到容器 mkdir -p /usr/local/docker_data/mysql/data# 宿主机创建配置文件目录映射到容器 mkdir -p /usr/local/docker_data/mysql/conf #(需要在…...

MySQL中如何进行分库分表的设计和实现?
分库分表是一种常用的数据库扩展方式,可以提高数据库的并发处理能力和扩展性,下面是分库分表的设计和实现的一般步骤: 数据库选择:选择合适的数据库管理系统(DBMS),如MySQL,支持分库…...

linux 安装谷歌浏览器和对应的驱动
创建文件install-google-chrome.sh #! /bin/bash# Copyright 2017-present: Intoli, LLC # Source: https://intoli.com/blog/installing-google-chrome-on-centos/ # # Redistribution and use in source and binary forms, with or without # modification, are permitted p…...

FPGA的通用FIFO设计verilog,1024*8bit仿真,源码和视频
名称:FIFO存储器设计1024*8bit 软件:Quartus 语言:Verilog 本代码为FIFO通用代码,其他深度和位宽可简单修改以下参数得到 reg [7:0] ram [1023:0];//RAM。深度1024,宽度8 代码功能: 设计一个基于FPGA…...
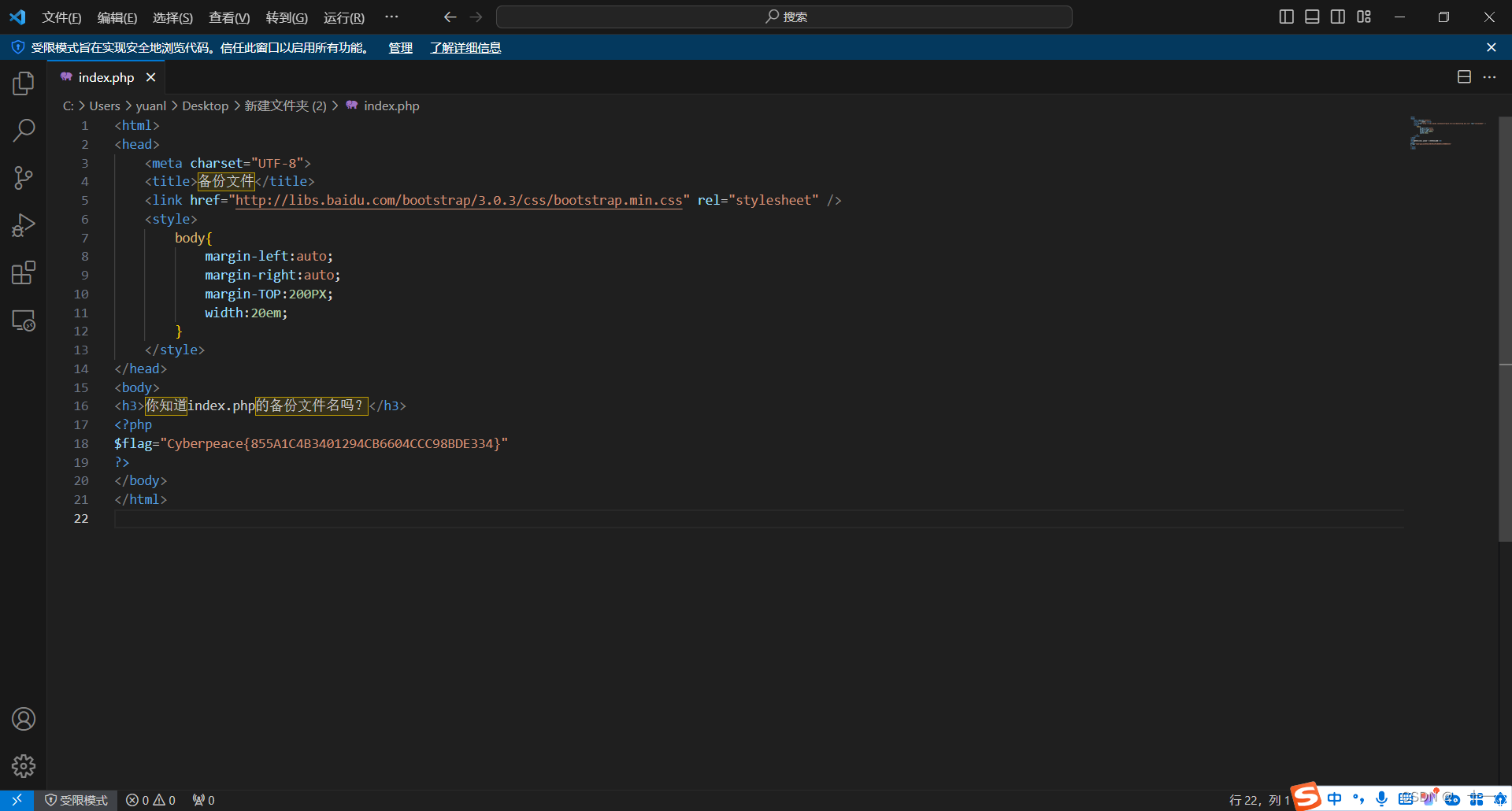
攻防世界web篇-backup
这是链接中的网页,只有一句话 试着使用.bak点缀看看是否有效 这里链接中加上index.php.bak让下在东西 是一个bak文件,将.bak文件改为.php文件试试 打开.php文件后就可以得到flag值...
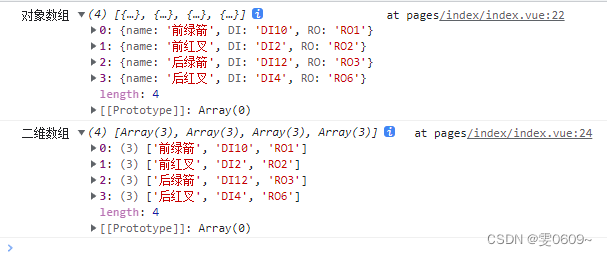
uni-app:js二维数组与对象数组之间的转换
一、二维数组整理成对象数组 效果 [ ["前绿箭","DI10","RO1"], ["前红叉","DI2","RO2"], ["后绿箭","DI12","RO3"], ["后红叉","DI4","RO6"] ] …...

15-bean生命周期,循环依赖
文章目录 1. bean生命周期 1. bean生命周期...

缩短cin时间
std::ios::sync_with_stdio(false);...

【试题030】C语言之关系表达式例题
1.关系表达式是用关系运算符将两个表达式连接起来 错误示例:a<bc (不是关系运算符,是赋值运算符) 2.题目:设int m160,m280,m3100;,表达式m3>m2>m1的值是 ? 3.代码分析: …...
ArGIS Engine专题(14)之GP模型根据导入范围与地图服务相交实现叠置分析
一、结果预览 二、需求简介 前端系统开发时,可能遇到如下场景,如客户给出一个图斑范围,导入到系统中后,需要判断图斑是否与耕地红线等地图服务存在叠加,叠加的面积有多少。虽然arcgis api中提供了相交inserect接口,但只是针对图形几何之间的相交,如何要使用该接口,则需…...
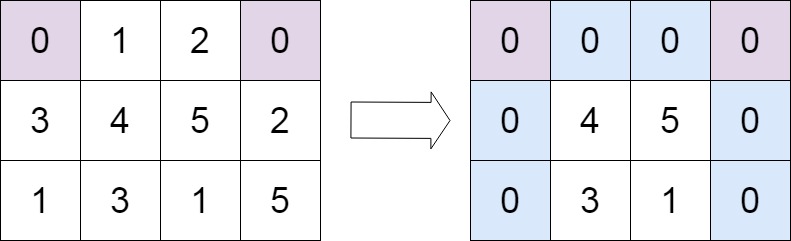
矩阵置零(C++解法)
题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]示例 2: 输入…...

Ansible的debug模块介绍,fact变量采集和缓存相关操作演示
目录 一.debug模块的使用方法 1.帮助文档给出的示例 2.主要用到的参数 (1)msg:主要用这个参数来指定要输出的信息 (2)var:打印指定的变量,一般是通过register注册了的变量 (3&…...
零基础新手也能会的H5邀请函制作教程
随着科技的的发展,H5邀请函已经成为了各种活动、婚礼、会议等场合的常见邀约方式。它们不仅可以提供动态、互动的体验,还能让邀请内容更加丰富多彩。下面,我们将通过乔拓云平台,带领大家一步步完成H5邀请函的制作。 1. 选择可靠的…...

推荐《中华小当家》
《中华小当家!》 [1] 是日本漫画家小川悦司创作的漫画。该作品于1995年至1999年在日本周刊少年Magazine上连载。作品亦改编为同名电视动画,并于1997年发行播出。 时隔20年推出续作《中华小当家!极》,于2017年11月17日开始连载。…...

接口自动化测试持续集成,Soapui接口功能测试参数化
按照自动化测试分层实现的原理,每一层的脚本实现都要进行参数化,自动化的目标就是要实现脚本代码与测试数据分离。当测试数据进行调整的时候不会对脚本的实现带来震荡,从而提高脚本的稳定性与灵活度,降低脚本的维护成本。Soapui最…...
(N-128)基于springboot,vue酒店管理系统
开发工具:IDEA 服务器:Tomcat9.0, jdk1.8 项目构建:maven 数据库:mysql5.7 系统分前后台,项目采用前后端分离 前端技术:vueelementUI 服务端技术:springbootmybatis 本系统功…...

Linux UWB Stack实现——MCPS帧处理
MCPS帧处理 用于处理IEEE 802.15.4中的相关帧,Frame Processing,简写为:fproc。 在实现中,维护了关于帧处理的有限状态机(FSM)。本文从帧处理的数据结构和部分典型处理实现上进行简要的介绍。 1. 数据结构定义 关于帧处理状态…...

LLM论文高效阅读指南:从Awesome列表到知识体系构建
1. 项目概述与核心价值最近在整理自己的知识库,发现一个挺有意思的现象:无论是刚入行的新人,还是像我这样在AI领域摸爬滚打了十来年的老手,面对大语言模型(LLM)这个日新月异的领域,都或多或少会…...

哔咔漫画下载器完整指南:3倍速打造个人离线漫画库
哔咔漫画下载器完整指南:3倍速打造个人离线漫画库 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mirr…...

【深度解析】DeepSeek V4:百万 Token 上下文、MoE 架构与低成本 Agent 工程实践
摘要: 本文从 DeepSeek V4 的模型架构、长上下文能力、成本结构与工程落地角度展开分析,并结合 OpenAI 兼容 API 给出可运行的 Python 实战示例,帮助开发者理解新一代低成本长上下文模型对 AI Agent、代码分析和企业知识处理的影响。背景介绍…...
)
中国高铁航线数据库CRAD(2003-2022年)
01、数据介绍中国高铁航线数据库CRAD(Chinese High-speed Rail and Airline Database)是一个专门收集和管理航空公司和高铁公司交通航线信息的数据仓库。它详细记录了中国各省、市、县所开通的列车站和飞机场的情况,如铁路线路、车站和列车等…...

Windows安卓应用安装革命:APK Installer技术解析与实战指南
Windows安卓应用安装革命:APK Installer技术解析与实战指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在Windows上运行安卓应用时笨重的模…...

避坑指南:HA添加小米设备总提示‘没有设备’?可能是你的小米账号权限不对
智能家居避坑指南:解决HA添加小米设备时"没有设备"的权限陷阱 当你满怀期待地准备将心爱的小米智能设备接入Home Assistant(HA),却在登录小米账号后遭遇冰冷的"该小米账号下没有设备"提示时,那种…...

构建企业级AI驱动测试自动化平台的完整架构实战
构建企业级AI驱动测试自动化平台的完整架构实战 【免费下载链接】testsigma Testsigma is an agentic test automation platform powered by AI-coworkers that work alongside QA teams to simplify testing, accelerate releases and improve quality across web, mobile, de…...

Tool.Net 3.0.0正式版发布:如何用MapApiRoute和AshxRoute特性玩转灵活API路由?
Tool.Net 3.0.0路由革命:MapApiRoute与AshxRoute的实战进阶指南 当ASP.NET Core开发者遇到需要为复杂业务系统设计多层级API路由时,传统配置方式往往显得力不从心。Tool.Net 3.0.0带来的MapApiRoute方法与AshxRoute特性组合,正在改变这一局面…...

第125期《安装指南》:新PC设备、电影、AI应用大分享,手机主屏幕也揭秘!
第125期《安装指南》精彩内容欢迎来到第125期《安装指南》,这里将介绍世界上最棒、最前沿的东西。本周作者读了关于NASA女裁缝、摩擦力、马斯克主义和滑板车的文章,着重阅读了杰夫范德米尔的新短篇小说,收听了《剖析》播客关于傻朋克乐队的新…...

别再死记硬背了!用‘高速公路’和‘物流车队’的比喻,5分钟搞懂DWDM波分复用
高速公路上的光信号物流:用生活化比喻拆解DWDM技术核心 想象一下,你正站在一条横跨大陆的高速公路监控中心,眼前的大屏幕上闪烁着无数彩色光点。这不是普通的交通监控,而是一座承载着全球互联网流量的光信号超级公路——DWDM&…...