用Python解析HTML页面
用Python解析HTML页面
文章目录
- 用Python解析HTML页面
- HTML 页面的结构
- XPath 解析
- CSS 选择器解析
- 简单的总结
在前面的课程中,我们讲到了使用
request三方库获取网络资源,还介绍了一些前端的基础知识。接下来,我们继续探索如何解析 HTML 代码,从页面中提取出有用的信息。之前,我们尝试过用正则表达式的捕获组操作提取页面内容,但是写出一个正确的正则表达式也是一件让人头疼的事情。为了解决这个问题,我们得先深入的了解一下 HTML 页面的结构,并在此基础上研究另外的解析页面的方法。
HTML 页面的结构
我们在浏览器中打开任意一个网站,然后通过鼠标右键菜单,选择“显示网页源代码”菜单项,就可以看到网页对应的 HTML 代码。
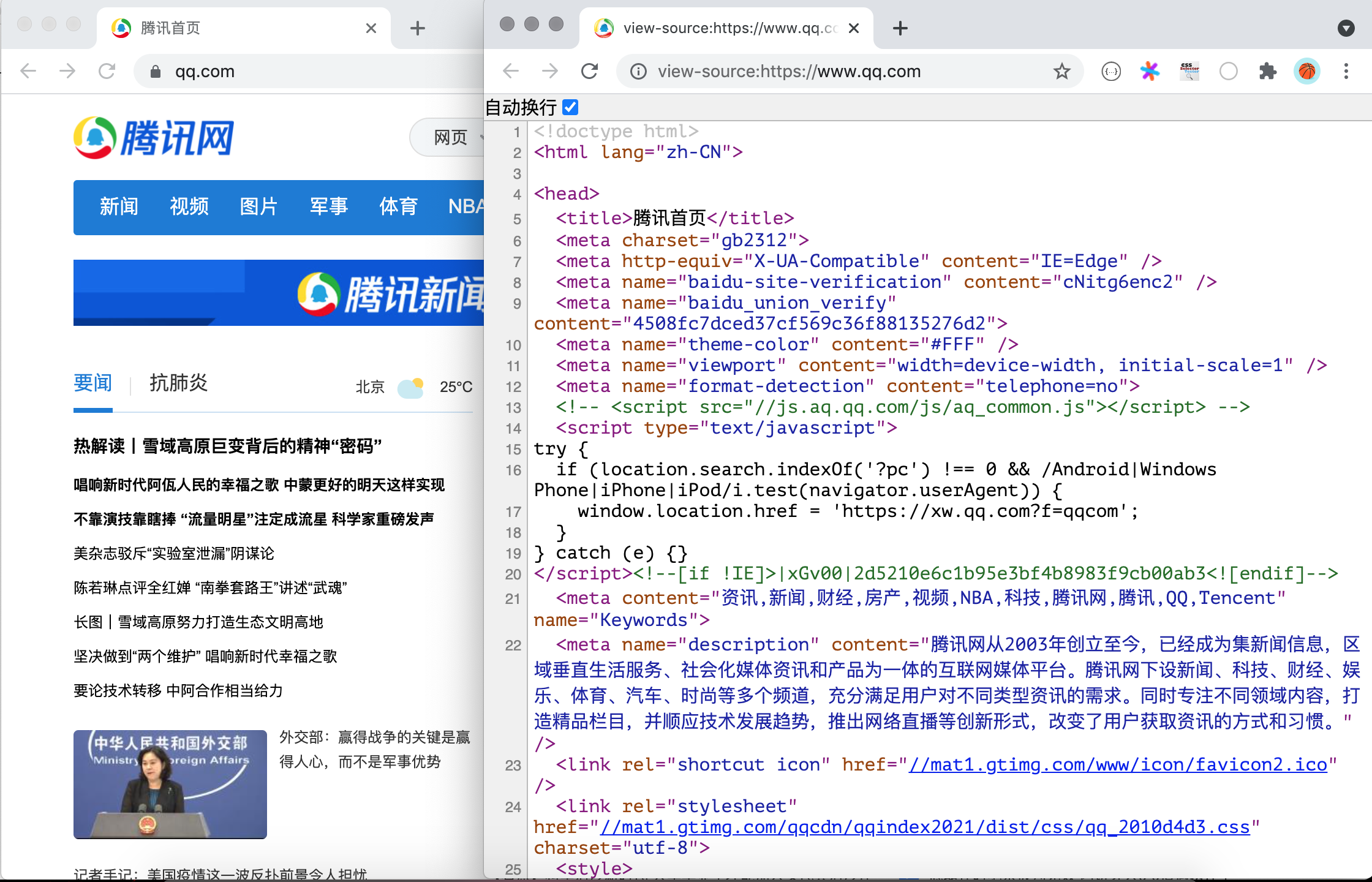
代码的第1行是文档类型声明,第2行的<html>标签是整个页面根标签的开始标签,最后一行是根标签的结束标签</html>。<html>标签下面有两个子标签<head>和<body>,放在<body>标签下的内容会显示在浏览器窗口中,这部分内容是网页的主体;放在<head>标签下的内容不会显示在浏览器窗口中,但是却包含了页面重要的元信息,通常称之为网页的头部。HTML 页面大致的代码结构如下所示。
<!doctype html>
<html><head><!-- 页面的元信息,如字符编码、标题、关键字、媒体查询等 --></head><body><!-- 页面的主体,显示在浏览器窗口中的内容 --></body>
</html>
标签、层叠样式表(CSS)、JavaScript 是构成 HTML 页面的三要素,其中标签用来承载页面要显示的内容,CSS 负责对页面的渲染,而 JavaScript 用来控制页面的交互式行为。要实现 HTML 页面的解析,可以使用 XPath 的语法,它原本是 XML 的一种查询语法,可以根据 HTML 标签的层次结构提取标签中的内容或标签属性;此外,也可以使用 CSS 选择器来定位页面元素,就跟用 CSS 渲染页面元素是同样的道理。
XPath 解析
XPath 是在 XML(eXtensible Markup Language)文档中查找信息的一种语法,XML 跟 HTML 类似也是一种用标签承载数据的标签语言,不同之处在于 XML 的标签是可扩展的,可以自定义的,而且 XML 对语法有更严格的要求。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集,这里所说的节点包括元素、属性、文本、命名空间、处理指令、注释、根节点等。下面我们通过一个例子来说明如何使用 XPath 对页面进行解析。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="zh">Learning XML</title><price>39.95</price></book>
</bookstore>
对于上面的 XML 文件,我们可以用如下所示的 XPath 语法获取文档中的节点。
| 路径表达式 | 结果 |
|---|---|
/bookstore | 选取根元素 bookstore。注意:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
//book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
//@lang | 选取名为 lang 的所有属性。 |
/bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
//title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
//title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
/bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
/bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
XPath还支持通配符用法,如下所示。
| 路径表达式 | 结果 |
|---|---|
/bookstore/* | 选取 bookstore 元素的所有子元素。 |
//* | 选取文档中的所有元素。 |
//title[@*] | 选取所有带有属性的 title 元素。 |
如果要选取多个节点,可以使用如下所示的方法。
| 路径表达式 | 结果 |
|---|---|
//book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
//title | //price | 选取文档中的所有 title 和 price 元素。 |
/bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
说明:上面的例子来自于“菜鸟教程”网站上的 XPath 教程,有兴趣的读者可以自行阅读原文。
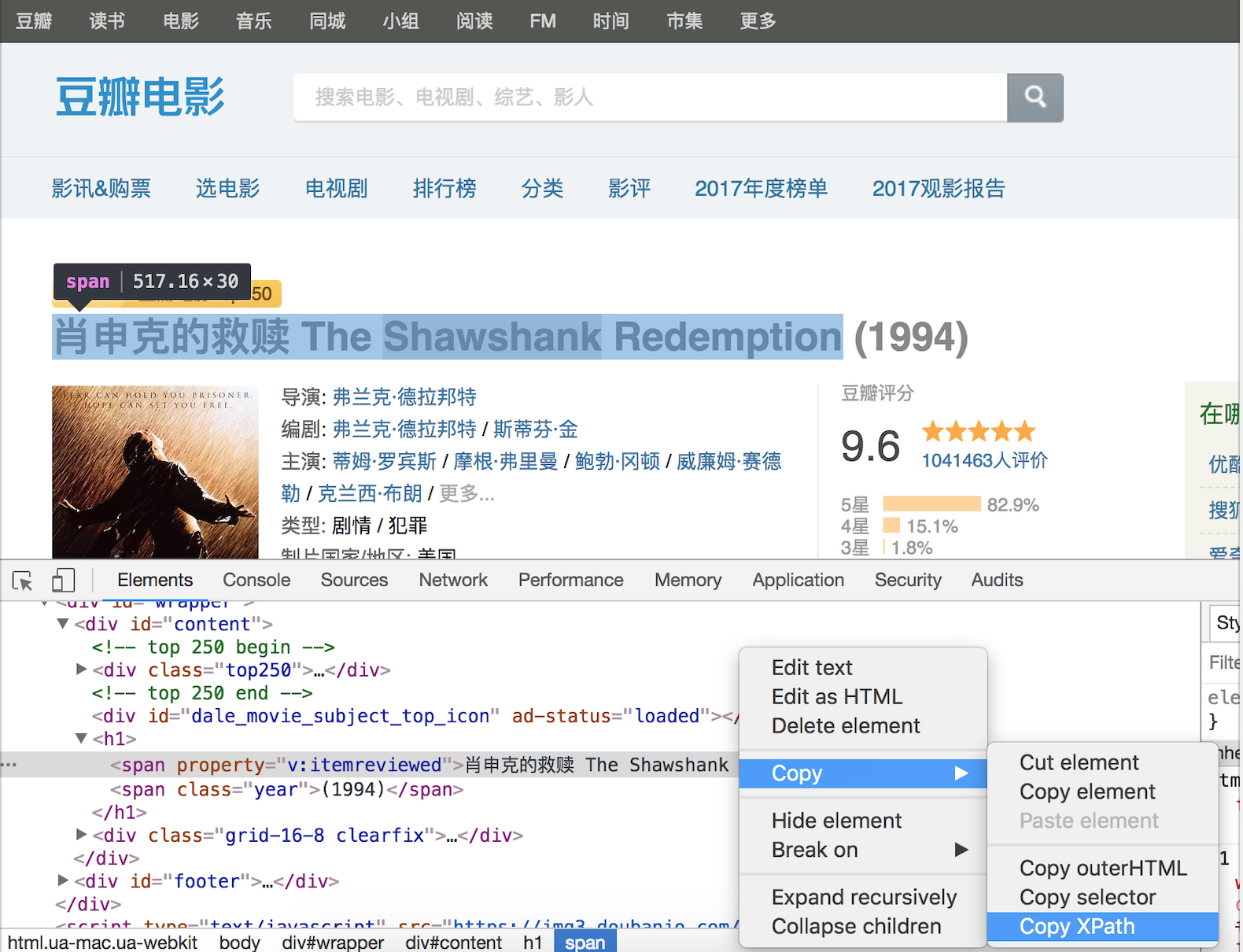
当然,如果不理解或不熟悉 XPath 语法,可以在浏览器的开发者工具中按照如下所示的方法查看元素的 XPath 语法,下图是在 Chrome 浏览器的开发者工具中查看豆瓣网电影详情信息中影片标题的 XPath 语法。
实现 XPath 解析需要三方库lxml 的支持,可以使用下面的命令安装lxml。
pip install lxml
下面我们用 XPath 解析方式改写之前获取豆瓣电影 Top250的代码,如下所示。
from lxml import etree
import requestsfor page in range(1, 11):resp = requests.get(url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',headers={'User-Agent': 'BaiduSpider'})tree = etree.HTML(resp.text)# 通过XPath语法从页面中提取电影标题title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]')# 通过XPath语法从页面中提取电影评分rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]')for title_span, rank_span in zip(title_spans, rank_spans):print(title_span.text, rank_span.text)
CSS 选择器解析
对于熟悉 CSS 选择器和 JavaScript 的开发者来说,通过 CSS 选择器获取页面元素可能是更为简单的选择,因为浏览器中运行的 JavaScript 本身就可以document对象的querySelector()和querySelectorAll()方法基于 CSS 选择器获取页面元素。在 Python 中,我们可以利用三方库beautifulsoup4或pyquery来做同样的事情。Beautiful Soup 可以用来解析 HTML 和 XML 文档,修复含有未闭合标签等错误的文档,通过为待解析的页面在内存中创建一棵树结构,实现对从页面中提取数据操作的封装。可以用下面的命令来安装 Beautiful Soup。
pip install beautifulsoup4
下面是使用bs4改写的获取豆瓣电影Top250电影名称的代码。
import bs4
import requestsfor page in range(1, 11):resp = requests.get(url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',headers={'User-Agent': 'BaiduSpider'})# 创建BeautifulSoup对象soup = bs4.BeautifulSoup(resp.text, 'lxml')# 通过CSS选择器从页面中提取包含电影标题的span标签title_spans = soup.select('div.info > div.hd > a > span:nth-child(1)')# 通过CSS选择器从页面中提取包含电影评分的span标签rank_spans = soup.select('div.info > div.bd > div > span.rating_num')for title_span, rank_span in zip(title_spans, rank_spans):print(title_span.text, rank_span.text)
关于 BeautifulSoup 更多的知识,可以参考它的官方文档。
简单的总结
下面我们对三种解析方式做一个简单比较。
| 解析方式 | 对应的模块 | 速度 | 使用难度 |
|---|---|---|---|
| 正则表达式解析 | re | 快 | 困难 |
| XPath 解析 | lxml | 快 | 一般 |
| CSS 选择器解析 | bs4或pyquery | 不确定 | 简单 |
相关文章:
用Python解析HTML页面
用Python解析HTML页面 文章目录 用Python解析HTML页面HTML 页面的结构XPath 解析CSS 选择器解析简单的总结 在前面的课程中,我们讲到了使用 request三方库获取网络资源,还介绍了一些前端的基础知识。接下来,我们继续探索如何解析 HTML 代码&…...

官方认证:研发效能(DevOps)工程师职业技术认证
培养端到端的研发效能人才 为贯彻落实《关于深化人才发展体制机制改革的意见》,推动实施人才强国战略,促进专业技术人员提升职业素养、补充新知识新技能,实现人力资源深度开发,推动经济社会全面发展,根据《中华人民共…...
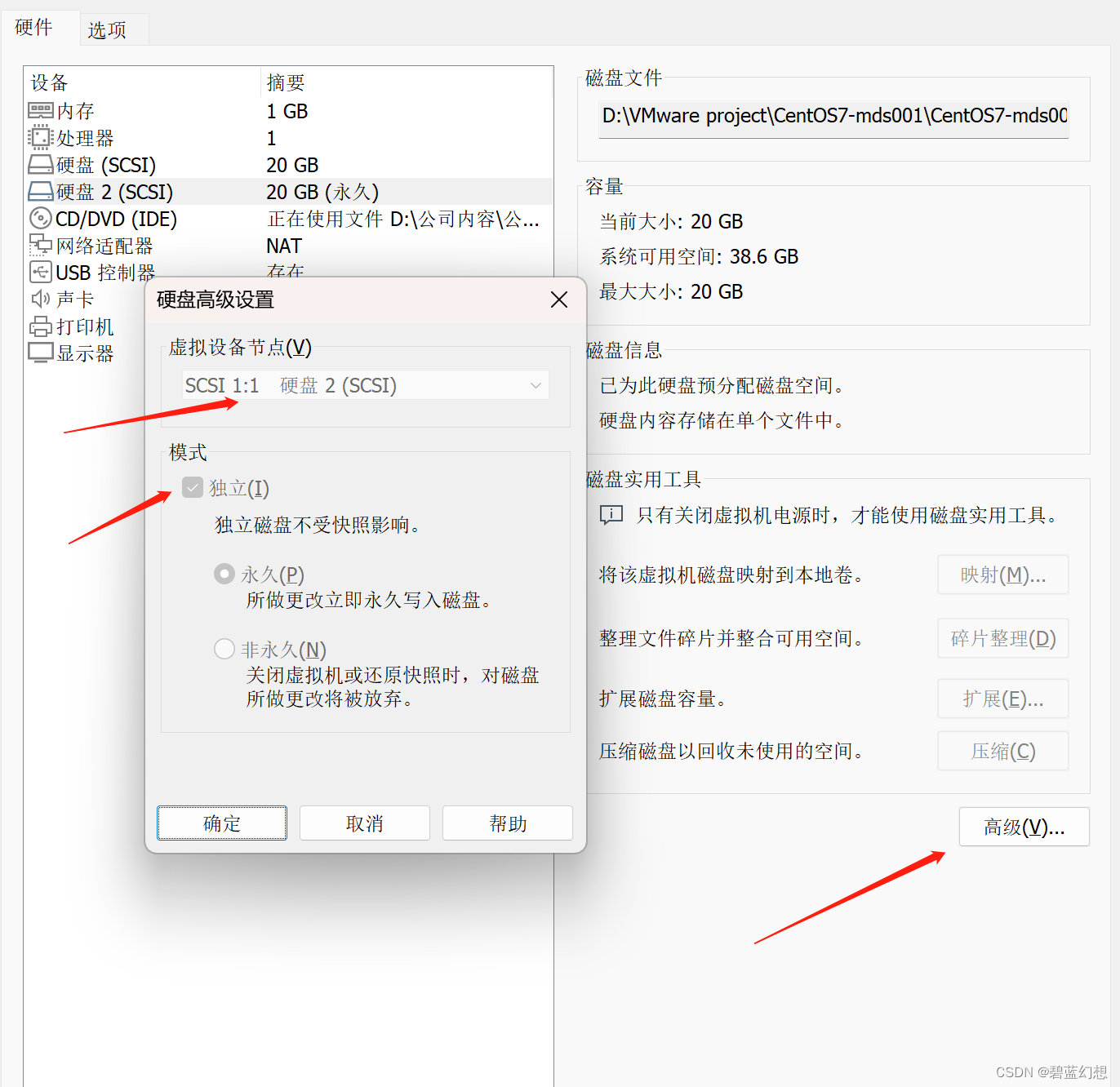
搭建GPFS双机集群
1.环境说明: 系统主机名IP地址内存添加共享磁盘大小Centos7.9gpfs1192.168.10.1012G20GCentos7.9gpfs2192.168.10.1022G20G 2.环境配置: 配置网路IP地址: 修改网卡会话: nmcli connection modify ipv4.method manual ipv4.addre…...

【试题032】C语言关系运算符例题
1.题目:设int a2,b4,c5;,则表达式ab!c>b>a的值为? 2.代码分析: //设int a2,b4,c5;,则表达式ab!c>b>a的值为?int a 2, b 4, c 5;printf("%d\n", (a b ! c > b > a));//分析ÿ…...

系列四、FileReader和FileWriter
一、概述 FileReader 和 FileWriter 是字符流,按照字符来操作IO。 1.1、继承体系 二、FileReader常用方法 new FileReader(File/String)# 每次读取单个字符就返回,如果读取到文件末尾返回-1 read()# 批量读取多个字符到数组,返回读取的字节…...
【C++面向对象】2.构造函数、析构函数
文章目录 【 1. 构造函数 】1.1 带参构造函数--传入数据1.2 无参构造函数--不传入数据1.3 实例1.4 拷贝构造函数 【 2. 析构函数 】 【 1. 构造函数 】 类的构造函数是类的一种特殊的成员函数,它会 在每次创建类的新对象时执行。 构造函数的名称与类的名称是完全相同…...
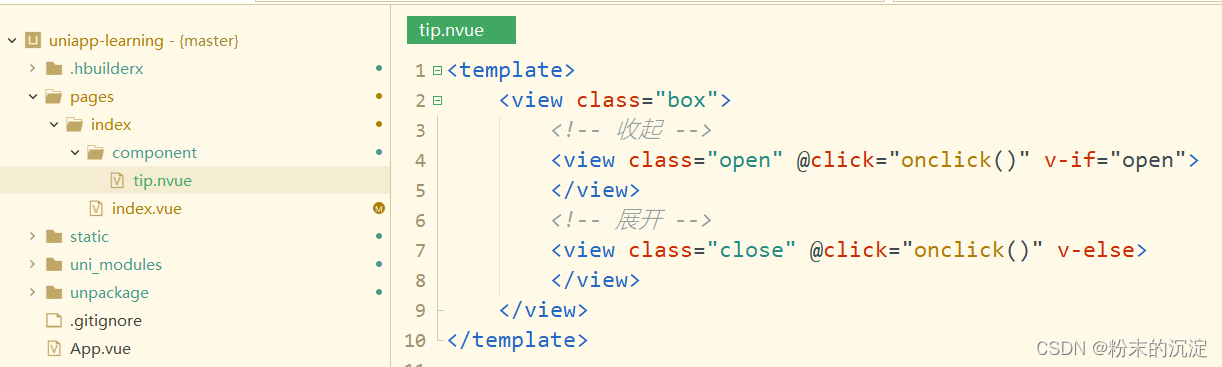
uniapp:使用subNVue原生子窗体在map上层添加自定义组件
我们想要在地图上层添加自定义组件,比如一个数据提示框,点一下会展开,再点一下收起,在h5段显示正常,但是到app端真机测试发现组件显示不出来,这是因为map是内置原生组件,层级最高,自…...
Flutter开发GridView控件详解
GridView跟ListView很类似,Listview主要以列表形式显示数据,GridView则是以网格形式显示数据,掌握ListView使用方法后,会很轻松的掌握GridView的使用方法。 在某种界面设计中,如果需要很多个类似的控件整齐的排列&…...

Vue3.0里为什么要用 Proxy API 替代 defineProperty API ?
一、Object.defineProperty 定义:Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象 为什么能实现响应式 通过defineProperty 两个属性,get及set get 属性的 getter 函…...

pytest利用request fixture实现个性化测试需求详解
这篇文章主要为大家详细介绍了pytest如何利用request fixture实现个性化测试需求,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起了解一下− 前言 在深入理解 pytest-repeat 插件的工作原理这篇文章中,我们看到pytest_repeat源码中有这样一段 import pyt…...
 时间插入、删除和获取随机元素)
算法练习16——O(1) 时间插入、删除和获取随机元素
LeetCode 380 O(1) 时间插入、删除和获取随机元素 实现RandomizedSet 类: RandomizedSet() 初始化 RandomizedSet 对象 bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。 …...

实时数据更新与Apollo:探索GraphQL订阅
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
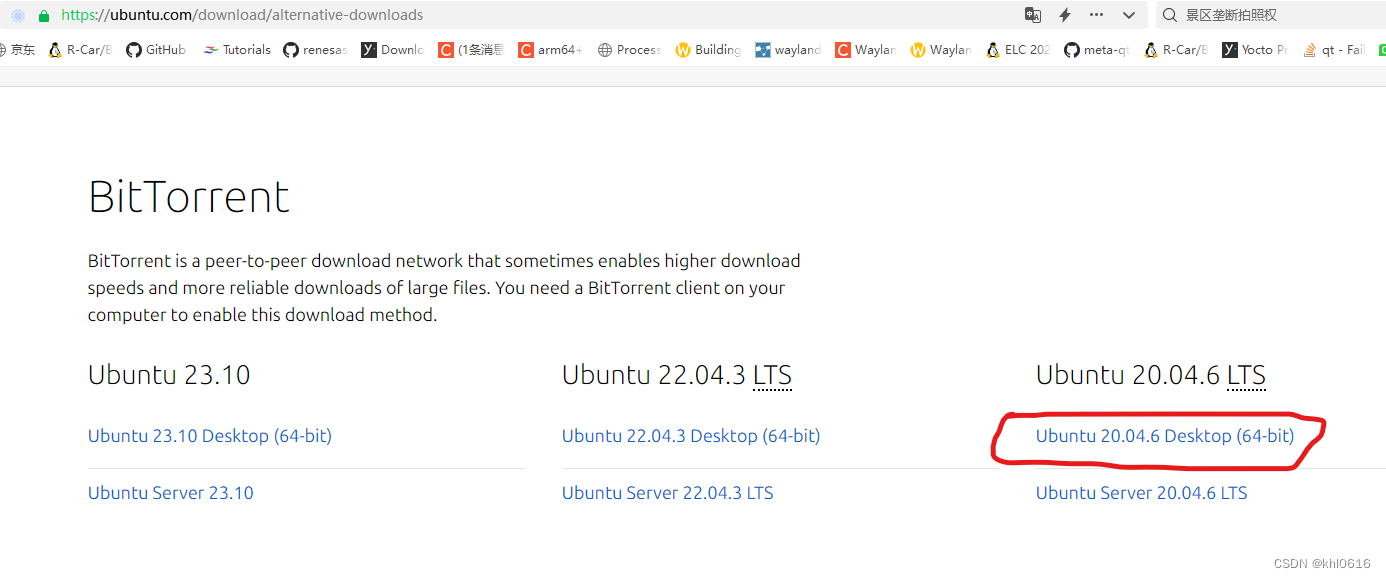
VMware Workstation里面安装ubuntu20.04的流程
文章目录 前言一、获取 desktop ubuntu20.04 安装镜像二、VMware Workstation下安装ubuntu20.041. VMware Workstation 创建一个新的虚拟机2. ubuntu20.04的安装过程3. 登录ubuntu20.044. 移除 ubuntu20.04 安装镜像总结参考资料前言 本文主要介绍如何在PC上的虚拟机(VMware W…...

pnpm的环境安装以及安装成功后无法使用的问题
文章目录 前言1、使用npm 安装2、安装后的注意点3、遇到问题4、配置path的环境变量(1)找到环境变量(2)找到并双击path的系统变量(3)复制第1步中使用npm安装的红框部分的路径(4)将第&…...
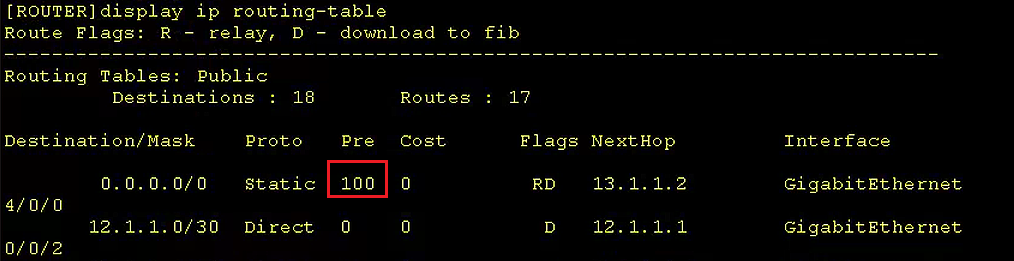
华为eNSP配置专题-浮动路由及BFD的配置
文章目录 华为eNSP配置专题-浮动路由及BFD的配置0、参考文档1、前置环境1.1、宿主机1.2、eNSP模拟器 2、基本环境搭建2.1、基本终端构成和连接2.2、基本终端配置 3、浮动路由配置3.1、浮动路由的基本配置3.2、浮动路由的负载均衡问题3.3、浮动路由的优先级调整 4、BFD的配置4.1…...
光储并网直流微电网simulink仿真模型,光伏采用mppt实现最大功率输出研究
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
:理解Redux及其工作原理)
面试题-React(十六):理解Redux及其工作原理
在现代前端开发中,状态管理是一个关键的问题。Redux是一个广泛使用的状态管理库,可以帮助开发者更有效地管理应用的状态。 一、什么是Redux? Redux是一个JavaScript状态管理库,用于管理应用中的状态(state࿰…...
Crypto(4)NewStarCTF 2023 week2 Crypto Rotate Xor
题目代码: # 导入所需的库和从secret模块加载"flag" from secret import flag from os import urandom from pwn import xor from Cryptodome.Util.number import *# 生成两个随机的 64 位素数,分别存储在变量 k1 和 k2 中 k1 getPrime(64) k2 getPrim…...

小程序-uni-app:将页面(html+css)生成图片/海报/名片,进行下载 保存到手机
一、需要描述 本文实现,uniapp微信小程序,把页面内容保存为图片,并且下载到手机上。 说实话网上找了很多资料,但是效果不理想,直到看了一个开源项目,我知道可以实现了。 本文以开源项目uniapp-wxml-to-can…...

Vue非单文件组件
组件就是用来实现局部特定功能效果的代码集合,为的就是复用编码,简化项目编码,提高运行效率。 组件分为非单文件组件和单文件组件,这里介绍的是非单文件组件。 一、创建组件 创建组件的语法格式如下: const 组件名 …...

douyin-downloader:构建高效抖音内容获取系统的终极解决方案
douyin-downloader:构建高效抖音内容获取系统的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...
做个小项目:手把手打造一个温湿度曲线显示仪)
用STM32 HAL库给1.54寸屏(ST7789V)做个小项目:手把手打造一个温湿度曲线显示仪
STM32 HAL库实战:打造高精度温湿度曲线显示仪 在嵌入式开发领域,能够将传感器数据直观可视化是一个极具实用价值的技能。今天,我们将使用STM32 HAL库和1.54寸ST7789V驱动屏幕,从零开始构建一个功能完整的温湿度曲线显示仪。这个项…...

Rust 性能优化的五个技巧
Rust 作为一门注重安全与性能的系统级编程语言,凭借其零成本抽象和内存安全特性,吸引了众多开发者的关注。即使 Rust 在默认情况下已经具备出色的性能,开发者仍然可以通过一些技巧进一步优化代码效率。本文将介绍五个实用的 Rust 性能优化技巧…...

除了花生壳,还有哪些免费/开源的内网穿透工具能帮你实现SSH远程办公?
5款开源内网穿透工具深度评测:SSH远程办公的替代方案 当我们需要在外网访问公司或家中的服务器时,商业内网穿透服务虽然方便,但往往存在费用高、隐私顾虑等问题。作为一名长期使用开源工具的开发者,我测试了市面上主流的几款开源…...

高效因果卷积实战指南:CUDA加速的深度时序建模利器
高效因果卷积实战指南:CUDA加速的深度时序建模利器 【免费下载链接】causal-conv1d Causal depthwise conv1d in CUDA, with a PyTorch interface 项目地址: https://gitcode.com/gh_mirrors/ca/causal-conv1d 在当今人工智能领域,时间序列数据处…...

CSGO新手必看:保姆级一键配置指南,从启动项到练枪图全搞定
CSGO新手极速上手指南:从零配置到实战训练的全套解决方案 刚接触CSGO的新手玩家往往会被游戏中复杂的设置选项、控制台命令和创意工坊地图搞得晕头转向。作为一名从2012年就开始玩CSGO的老玩家,我深知这些初始障碍会让很多有潜力的新人望而却步。本文将带…...

byp4xx:自动化绕过HTTP 40X状态码的Go语言工具详解
1. 项目概述:byp4xx,一个专为绕过HTTP 40X状态码而生的工具在Web应用安全测试,尤其是渗透测试和漏洞赏金(Bug Bounty)的日常工作中,遇到403 Forbidden或404 Not Found这样的HTTP状态码是家常便饭。很多时候…...

渐进式增长GAN:高分辨率图像生成的突破与实践
1. 渐进式增长GAN基础解析生成对抗网络(GAN)近年来在图像合成领域取得了显著进展,但其生成高分辨率图像的能力一直受限。传统GAN在生成6464像素以上的图像时,往往面临训练不稳定和图像质量下降的问题。2017年NVIDIA团队提出的渐进…...

B站视频下载神器:BilibiliDown 三步轻松保存高清视频的终极指南
B站视频下载神器:BilibiliDown 三步轻松保存高清视频的终极指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

WiMAX技术解析:从原理到部署实战
1. WiMAX技术概述:从标准到应用场景WiMAX(全球微波接入互操作性)这个名词背后,实际上是一组IEEE 802.16系列标准的商业化称谓。作为从业十余年的通信工程师,我见证了这个技术从实验室走向市场的全过程。与常见的Wi-Fi&…...