机器学习tip:sklearn中的pipeline
文章目录
- 1 加载数据集
- 2 构思算法的流程
- 3 Pipeline执行流程的分析
- Reference
- Statement
一个典型的机器学习构建包含若干个过程
- 源数据ETL
- 数据预处理
- 特征选取
- 模型训练与验证
一个典型的机器学习构建包含若干个过程
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,对利用spark进行机器学习的用户来说,流水线式机器学习比单个步骤独立建模更加高效、易用。
管道机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
管道机制实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines)。注意:管道机制更像是编程技巧的创新,而非算法的创新。
接下来我们以一个具体的例子来演示sklearn库中强大的Pipeline用法:
1 加载数据集
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoderdf = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/''breast-cancer-wisconsin/wdbc.data', header=None)# Breast Cancer Wisconsin datasetX, y = df.values[:, 2:], df.values[:, 1]# y为字符型标签# 使用LabelEncoder类将其转换为0开始的数值型
encoder = LabelEncoder()
y = encoder.fit_transform(y)>>> encoder.transform(['M', 'B'])array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
2 构思算法的流程
可放在Pipeline中的步骤可能有:
- 特征标准化是需要的,可作为第一个环节
- 既然是分类器,classifier也是少不了的,自然是最后一个环节
- 中间可加上比如数据降维(PCA)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegressionfrom sklearn.pipeline import Pipelinepipe_lr = Pipeline([('sc', StandardScaler()),('pca', PCA(n_components=2)),('clf', LogisticRegression(random_state=1))])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))# Test accuracy: 0.947
Pipeline对象接受二元tuple构成的list,每一个二元 tuple 中的第一个元素为 arbitrary identifier string,我们用以获取(access)Pipeline object 中的 individual elements,二元 tuple 中的第二个元素是 scikit-learn与之相适配的transformer 或者 estimator。
Pipeline([('sc', StandardScaler()), ('pca', PCA(n_components=2)), ('clf', LogisticRegression(random_state=1))])
3 Pipeline执行流程的分析
Pipeline 的中间过程由scikit-learn相适配的转换器(transformer)构成,最后一步是一个estimator。比如上述的代码,StandardScaler和PCA transformer 构成intermediate steps,LogisticRegression 作为最终的estimator。
当我们执行 pipe_lr.fit(X_train, y_train)时,首先由StandardScaler在训练集上执行 fit 和 transform 方法,transformed后的数据又被传递给Pipeline对象的下一步,也即PCA()。和StandardScaler一样,PCA也是执行 fit 和 transform 方法,最终将转换后的数据传递给 LosigsticRegression。整个流程如下图所示:
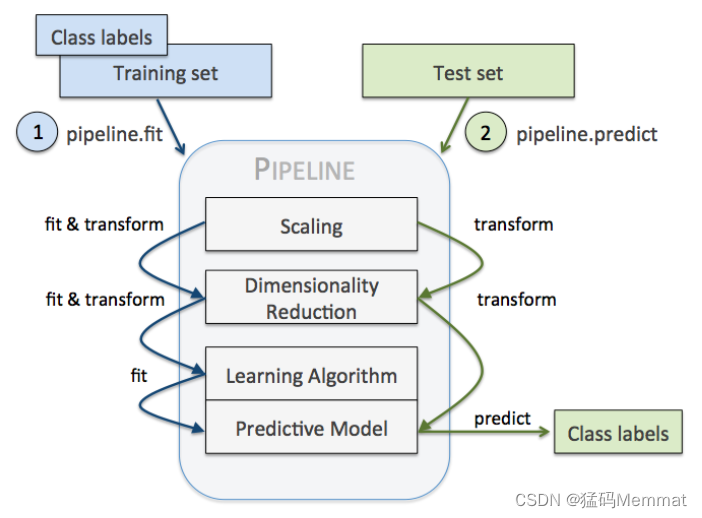
Reference
https://blog.csdn.net/lanchunhui/article/details/50521648
Statement
本文未经系统测试和专业评审,欢迎在评论区反馈和讨论问题。
相关文章:
机器学习tip:sklearn中的pipeline
文章目录 1 加载数据集2 构思算法的流程3 Pipeline执行流程的分析ReferenceStatement 一个典型的机器学习构建包含若干个过程 源数据ETL数据预处理特征选取模型训练与验证 一个典型的机器学习构建包含若干个过程 以上四个步骤可以抽象为一个包括多个步骤的流水线式工作&…...
Jmeter项目实战
一,性能测试流程 性能需求分析 性能方案设计 业务建模 脚本优化 执行测试 收集性能数据 结果分析 性能测试报告 二,性能需求分析 项目管理系统业务:登录 注册 搜索(一般最核心的就是登陆,大多只对登录做压测&a…...
Spring学习笔记注解式开发(3)
Spring学习笔记(3) 一、Bean的注解式开发1.1、注解开发的基本和Component1.2 注解式开发8.3、Component的三个衍生注解 二、Bean依赖注入注解开发2.1、依赖注入相关注解2.2、Autowired扩展 三、非自定义Bean注解开发四、Bean配置类的注解开发五、Spring注…...
vue3后台管理框架之技术栈
vue3全家桶技术 基础构建: vue3vite4TypeScript 代码格式 : eslintprettystylelint git生命周期钩子: husky css预处理器: sass ui库: element-plus 模拟数据: mock 网络请求: axios 路由: vue…...
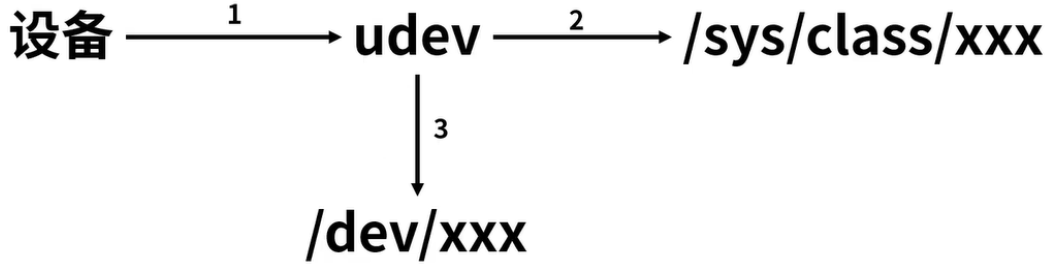
7、Linux驱动开发:设备-自动创建设备节点
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...
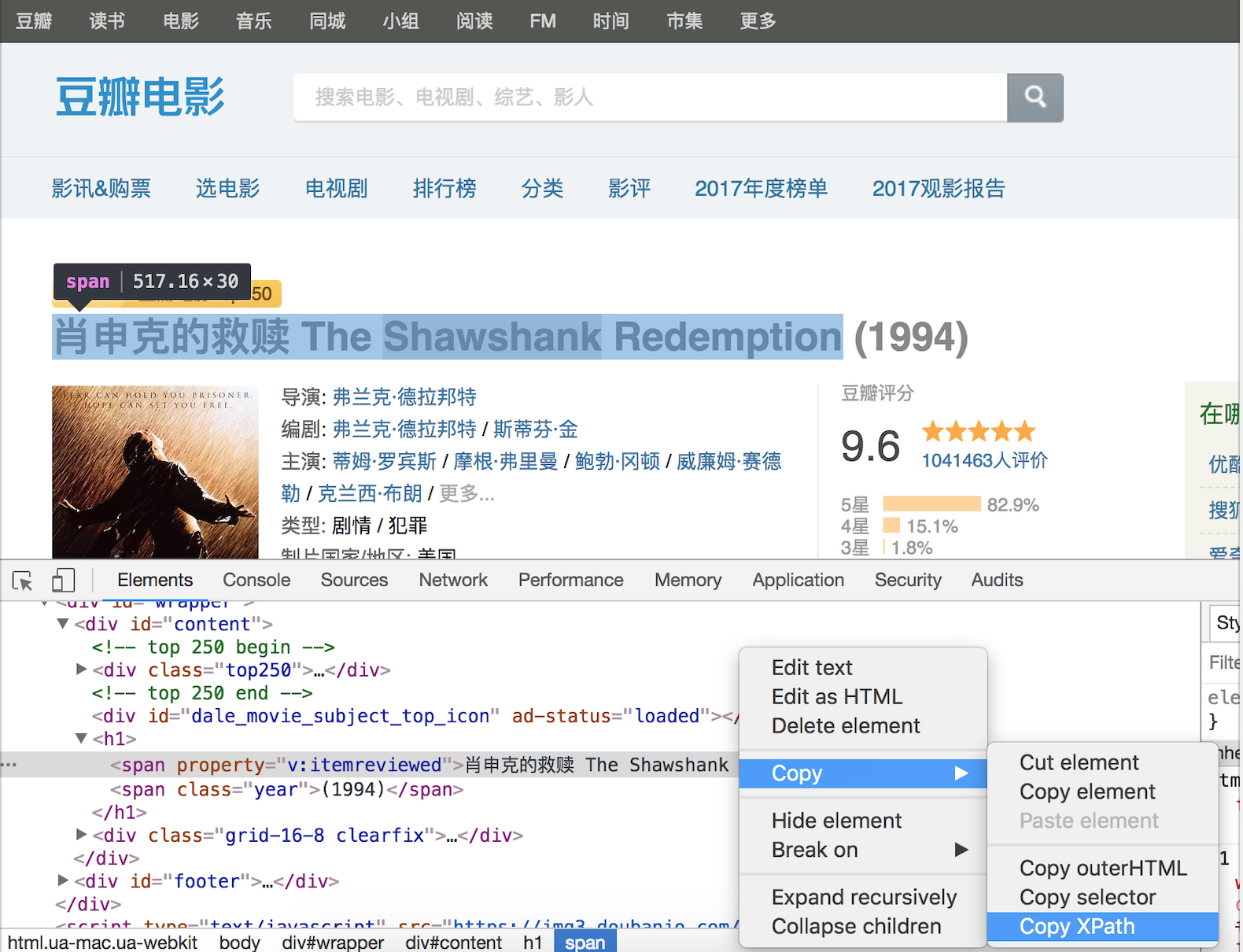
用Python解析HTML页面
用Python解析HTML页面 文章目录 用Python解析HTML页面HTML 页面的结构XPath 解析CSS 选择器解析简单的总结 在前面的课程中,我们讲到了使用 request三方库获取网络资源,还介绍了一些前端的基础知识。接下来,我们继续探索如何解析 HTML 代码&…...

官方认证:研发效能(DevOps)工程师职业技术认证
培养端到端的研发效能人才 为贯彻落实《关于深化人才发展体制机制改革的意见》,推动实施人才强国战略,促进专业技术人员提升职业素养、补充新知识新技能,实现人力资源深度开发,推动经济社会全面发展,根据《中华人民共…...
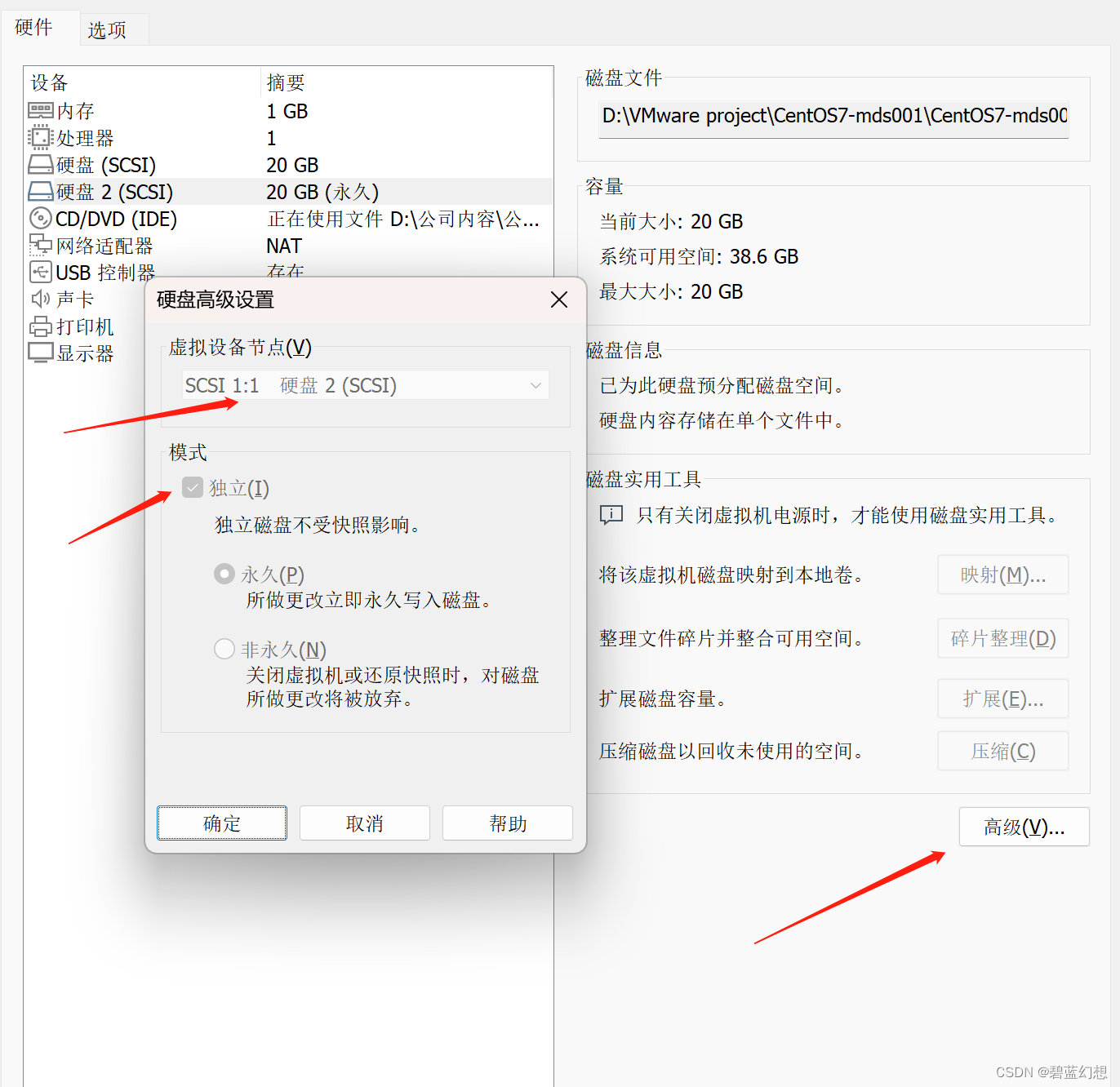
搭建GPFS双机集群
1.环境说明: 系统主机名IP地址内存添加共享磁盘大小Centos7.9gpfs1192.168.10.1012G20GCentos7.9gpfs2192.168.10.1022G20G 2.环境配置: 配置网路IP地址: 修改网卡会话: nmcli connection modify ipv4.method manual ipv4.addre…...

【试题032】C语言关系运算符例题
1.题目:设int a2,b4,c5;,则表达式ab!c>b>a的值为? 2.代码分析: //设int a2,b4,c5;,则表达式ab!c>b>a的值为?int a 2, b 4, c 5;printf("%d\n", (a b ! c > b > a));//分析ÿ…...

系列四、FileReader和FileWriter
一、概述 FileReader 和 FileWriter 是字符流,按照字符来操作IO。 1.1、继承体系 二、FileReader常用方法 new FileReader(File/String)# 每次读取单个字符就返回,如果读取到文件末尾返回-1 read()# 批量读取多个字符到数组,返回读取的字节…...
【C++面向对象】2.构造函数、析构函数
文章目录 【 1. 构造函数 】1.1 带参构造函数--传入数据1.2 无参构造函数--不传入数据1.3 实例1.4 拷贝构造函数 【 2. 析构函数 】 【 1. 构造函数 】 类的构造函数是类的一种特殊的成员函数,它会 在每次创建类的新对象时执行。 构造函数的名称与类的名称是完全相同…...
uniapp:使用subNVue原生子窗体在map上层添加自定义组件
我们想要在地图上层添加自定义组件,比如一个数据提示框,点一下会展开,再点一下收起,在h5段显示正常,但是到app端真机测试发现组件显示不出来,这是因为map是内置原生组件,层级最高,自…...
Flutter开发GridView控件详解
GridView跟ListView很类似,Listview主要以列表形式显示数据,GridView则是以网格形式显示数据,掌握ListView使用方法后,会很轻松的掌握GridView的使用方法。 在某种界面设计中,如果需要很多个类似的控件整齐的排列&…...

Vue3.0里为什么要用 Proxy API 替代 defineProperty API ?
一、Object.defineProperty 定义:Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象 为什么能实现响应式 通过defineProperty 两个属性,get及set get 属性的 getter 函…...

pytest利用request fixture实现个性化测试需求详解
这篇文章主要为大家详细介绍了pytest如何利用request fixture实现个性化测试需求,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起了解一下− 前言 在深入理解 pytest-repeat 插件的工作原理这篇文章中,我们看到pytest_repeat源码中有这样一段 import pyt…...
 时间插入、删除和获取随机元素)
算法练习16——O(1) 时间插入、删除和获取随机元素
LeetCode 380 O(1) 时间插入、删除和获取随机元素 实现RandomizedSet 类: RandomizedSet() 初始化 RandomizedSet 对象 bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。 …...

实时数据更新与Apollo:探索GraphQL订阅
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
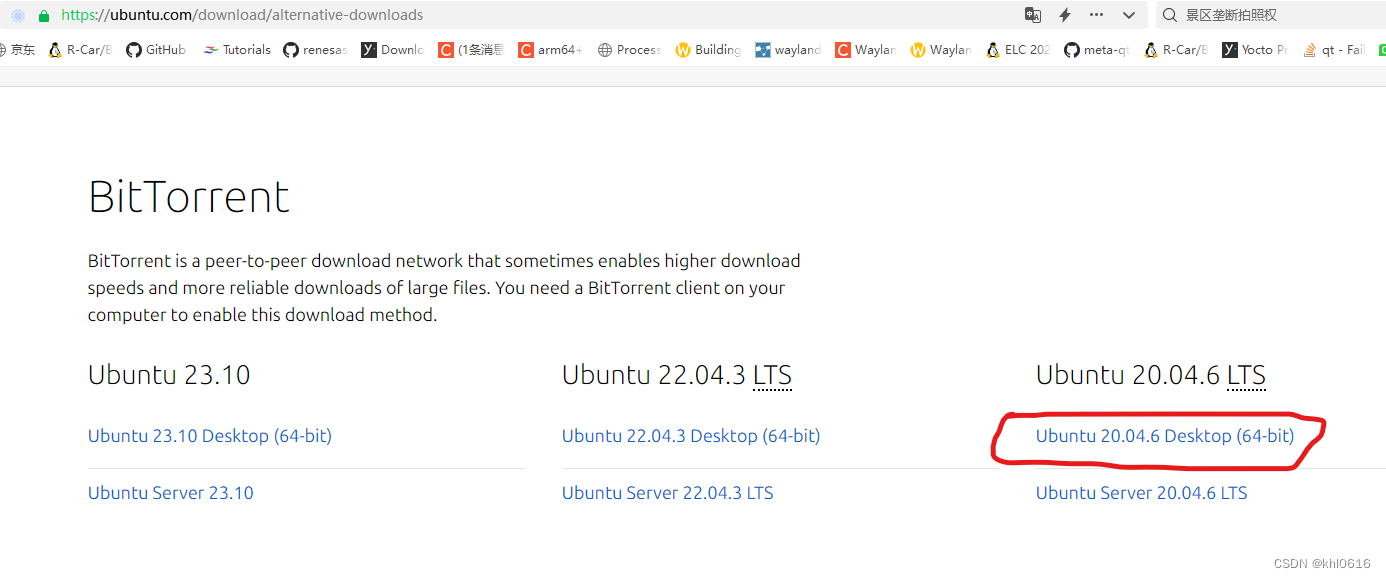
VMware Workstation里面安装ubuntu20.04的流程
文章目录 前言一、获取 desktop ubuntu20.04 安装镜像二、VMware Workstation下安装ubuntu20.041. VMware Workstation 创建一个新的虚拟机2. ubuntu20.04的安装过程3. 登录ubuntu20.044. 移除 ubuntu20.04 安装镜像总结参考资料前言 本文主要介绍如何在PC上的虚拟机(VMware W…...

pnpm的环境安装以及安装成功后无法使用的问题
文章目录 前言1、使用npm 安装2、安装后的注意点3、遇到问题4、配置path的环境变量(1)找到环境变量(2)找到并双击path的系统变量(3)复制第1步中使用npm安装的红框部分的路径(4)将第&…...
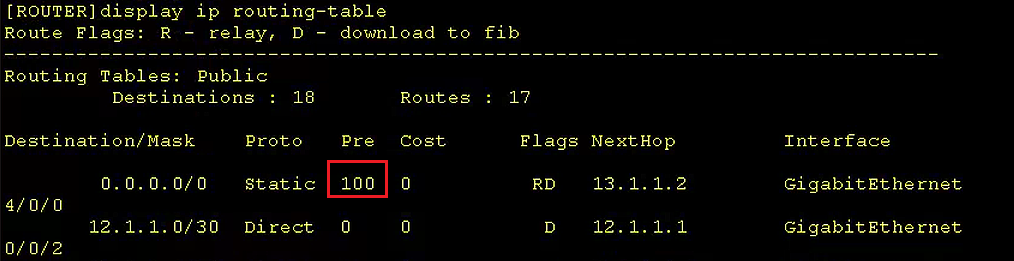
华为eNSP配置专题-浮动路由及BFD的配置
文章目录 华为eNSP配置专题-浮动路由及BFD的配置0、参考文档1、前置环境1.1、宿主机1.2、eNSP模拟器 2、基本环境搭建2.1、基本终端构成和连接2.2、基本终端配置 3、浮动路由配置3.1、浮动路由的基本配置3.2、浮动路由的负载均衡问题3.3、浮动路由的优先级调整 4、BFD的配置4.1…...

Blender 3MF插件:让3D打印从设计到成品零误差 [特殊字符]
Blender 3MF插件:让3D打印从设计到成品零误差 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D打印时材质信息丢失而烦恼吗?…...
)
手把手教你用C#和ClawPDF二次开发:打造自己的跨网段打印机共享服务(附KKPrinter源码)
基于ClawPDF与C#构建企业级跨网段打印服务实战指南 在分布式办公成为常态的今天,企业常常面临跨地域打印机共享的技术挑战。商业解决方案往往价格昂贵且缺乏定制灵活性,而传统Windows共享打印又受限于网络拓扑。本文将揭示如何基于ClawPDF开源框架&#…...

开源AI金融智能体FinRobot:架构解析与实战构建财报分析助手
1. 项目概述:当金融遇上开源AI,FinRobot想做什么?如果你在金融科技圈子里待过几年,就会明显感觉到一个趋势:传统金融分析的门槛正在被AI技术迅速拉低。过去,一个量化研究员可能需要精通Python、R࿰…...

别再只用默认用户了!手把手教你为SpringBoot项目配置独立的RabbitMQ用户和Virtual Host
企业级RabbitMQ隔离实战:SpringBoot多项目安全配置指南 当微服务架构遇上消息队列,数据隔离便成为保障系统稳定性的第一道防线。去年某电商平台因消息队列权限混乱导致的订单与库存数据交叉污染事件,让行业深刻认识到:生产环境中的…...

STM32 HAL库实战:用I2C+DMA连续读取AS5600角度,解放CPU的保姆级教程
STM32 HAL库实战:I2CDMA连续读取AS5600角度的高效方案 在实时控制系统中,如云台稳定、机器人关节控制等场景,对编码器角度数据的实时采集有着极高的要求。传统轮询方式会大量占用CPU资源,而中断方式在高频率读取时又会产生显著的性…...

SonarQube生产环境部署实录:Docker Compose编排PostgreSQL 12与SonarQube 8.9.10的黄金组合
SonarQube生产环境部署实战:从技术选型到高可用架构设计 在当今快速迭代的软件开发周期中,代码质量管理已成为企业技术栈中不可或缺的一环。作为静态代码分析领域的标杆工具,SonarQube凭借其全面的质量门禁规则、多语言支持以及直观的仪表盘&…...

D2DX宽屏补丁终极指南:让暗黑破坏神2在现代PC上焕发新生
D2DX宽屏补丁终极指南:让暗黑破坏神2在现代PC上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否怀…...

MATLAB integral函数实战:从分段函数到无穷积分,一个函数搞定所有数值积分难题
MATLAB integral函数全攻略:解锁复杂积分计算的终极方案 在工程计算和科学研究的战场上,数值积分就像一把瑞士军刀——当你面对那些解析解难以捉摸的函数时,它总能从工具箱里跳出来拯救你。MATLAB的integral函数正是这样一把多功能利器&#…...

Godot PCK文件解包终极指南:5分钟学会提取游戏资源
Godot PCK文件解包终极指南:5分钟学会提取游戏资源 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你想提取Godot游戏中的精美素材吗?想要学习游戏开发或进行逆向分析吗&…...
5分钟极速上手:Translumo实时屏幕翻译工具完整指南
5分钟极速上手:Translumo实时屏幕翻译工具完整指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 想要打破语…...