分类网络-类别不均衡问题之FocalLoss

有训练和测代码如下:(完整代码来自CNN从搭建到部署实战)
train.py
import torch
import torchvision
import time
import argparse
import importlib
from loss import FocalLossdef parse_args():parser = argparse.ArgumentParser('training')parser.add_argument('--batch_size', default=128, type=int, help='batch size in training')parser.add_argument('--num_epochs', default=5, type=int, help='number of epoch in training')parser.add_argument('--model', default='lenet', help='model name [default: mlp]')return parser.parse_args()if __name__ == '__main__':args = parse_args()batch_size = args.batch_sizenum_epochs = args.num_epochsmodel = importlib.import_module('models.'+args.model) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')net = model.net.to(device)loss = torch.nn.CrossEntropyLoss()if args.model == 'mlp':optimizer = torch.optim.SGD(net.parameters(), lr=0.5)else:optimizer = torch.optim.Adam(net.parameters(), lr=0.001)train_path = r'./Datasets/mnist_png/training'test_path = r'./Datasets/mnist_png/testing'transform_list = [torchvision.transforms.Grayscale(num_output_channels=1), torchvision.transforms.ToTensor()]if args.model == 'alexnet' or args.model == 'vgg':transform_list.append(torchvision.transforms.Resize(size=224))if args.model == 'googlenet' or args.model == 'resnet':transform_list.append(torchvision.transforms.Resize(size=96))transform = torchvision.transforms.Compose(transform_list)train_dataset = torchvision.datasets.ImageFolder(train_path, transform=transform)test_dataset = torchvision.datasets.ImageFolder(test_path, transform=transform)train_iter = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)test_iter = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)for epoch in range(num_epochs):train_l, train_acc, test_acc, m, n, batch_count, start = 0.0, 0.0, 0.0, 0, 0, 0, time.time()for X, y in train_iter:X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)optimizer.zero_grad()l.backward()optimizer.step()train_l += l.cpu().item()train_acc += (y_hat.argmax(dim=1) == y).sum().cpu().item()m += y.shape[0]batch_count += 1with torch.no_grad():for X, y in test_iter:net.eval() # 评估模式test_acc += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()net.train() # 改回训练模式n += y.shape[0]print('epoch %d, loss %.6f, train acc %.3f, test acc %.3f, time %.1fs'% (epoch, train_l / batch_count, train_acc / m, test_acc / n, time.time() - start))torch.save(net, args.model+".pth")
test.py
import cv2
import torch
import argparse
import importlib
from pathlib import Path
import torchvision.transforms.functionaldef parse_args():parser = argparse.ArgumentParser('testing')parser.add_argument('--model', default='lenet', help='model name [default: mlp]')return parser.parse_args()if __name__ == '__main__':args = parse_args()model = importlib.import_module('models.' + args.model) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')net = model.net.to(device)net = torch.load(args.model+'.pth')net.eval()with torch.no_grad():imgs_path = Path(r"./Datasets/mnist_png/testing/6/").glob("*")acc = 0count = 0for img_path in imgs_path:img = cv2.imread(str(img_path), 0)if args.model == 'alexnet' or args.model == 'vgg': img = cv2.resize(img, (224,224))if args.model == 'googlenet' or args.model == 'resnet':img = cv2.resize(img, (96,96))img_tensor = torchvision.transforms.functional.to_tensor(img)img_tensor = torch.unsqueeze(img_tensor, 0)#print(net(img_tensor.to(device)).argmax(dim=1).item())if(net(img_tensor.to(device)).argmax(dim=1).item()==6):acc += 1count+=1print(acc/count)
数据集为mnist手写数字识别,其中训练集中数字0~9的数量分别为:0(5923张),1(6472张),2(5985张),3(6131张),4(5842张),5(5421张),6(5918张),7(6265张),8(5851张),9(5949张), 测试集中数字0~9的数量分别为:0(980张),1(1135张),2(1032张),3(1010张),4(982张),5(892张),6(958张),7(1028张),8(974张),9(1009张)。可见各个类别的数量基本上平衡。测试代码仅测试数字6的准确率,因为后面我们要改变训练集中数字6的数量来进行对比。为了节省时间,仅训练5个epoch。
训练结果:
epoch 0, loss 1.443379, train acc 0.529, test acc 0.877, time 23.4s
epoch 1, loss 0.314123, train acc 0.913, test acc 0.939, time 22.1s
epoch 2, loss 0.174050, train acc 0.949, test acc 0.960, time 21.9s
epoch 3, loss 0.122714, train acc 0.963, test acc 0.971, time 21.8s
epoch 4, loss 0.096798, train acc 0.971, test acc 0.975, time 21.8s
测试结果:
0.9780793319415448
现在将训练集中数字6的数量减少到59张(原来的1/100),来模拟某个类别的数据不平衡的情况。
训练结果:
epoch 0, loss 2.200247, train acc 0.131, test acc 0.373, time 20.8s
epoch 1, loss 0.579792, train acc 0.840, test acc 0.855, time 20.5s
epoch 2, loss 0.177890, train acc 0.950, test acc 0.872, time 20.3s
epoch 3, loss 0.128251, train acc 0.963, test acc 0.880, time 20.5s
epoch 4, loss 0.103937, train acc 0.969, test acc 0.888, time 20.7s
测试结果:
0.04801670146137787
可以看到,训练的准确率下降9%,而测试集直接下降了93%惨不忍睹。
引入FocalLoss模块:(参考https://github.com/QunBB/DeepLearning/blob/main/trick/unbalance/loss_pt.py)
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Optional, Unionclass FocalLoss(nn.Module):def __init__(self, alpha: Union[List[float], float], gamma: Optional[int] = 2, with_logits: Optional[bool] = True):""":param alpha: 每个类别的权重:param gamma::param with_logits: 是否经过softmax或者sigmoid"""super(FocalLoss, self).__init__()self.gamma = gammaself.alpha = torch.FloatTensor([alpha]) if isinstance(alpha, float) else torch.FloatTensor(alpha)self.smooth = 1e-8self.with_logits = with_logitsdef _binary_class(self, input, target):prob = torch.sigmoid(input) if self.with_logits else inputprob += self.smoothalpha = self.alpha.to(target.device)loss = -alpha * torch.pow(torch.sub(1.0, prob), self.gamma) * torch.log(prob)return lossdef _multiple_class(self, input, target):prob = F.softmax(input, dim=1) if self.with_logits else inputalpha = self.alpha.to(target.device)alpha = alpha.gather(0, target)target = target.view(-1, 1)prob = prob.gather(1, target).view(-1) + self.smooth # avoid nanlogpt = torch.log(prob)loss = -alpha * torch.pow(torch.sub(1.0, prob), self.gamma) * logptreturn lossdef forward(self, input: torch.Tensor, target: torch.Tensor) -> torch.Tensor:""":param input: 维度为[bs, num_classes]:param target: 维度为[bs]:return:"""if len(input.shape) > 1 and input.shape[-1] != 1:loss = self._multiple_class(input, target)else:loss = self._binary_class(input, target)return loss.mean()
并将train.py的第26行修改成
loss = FocalLoss([1, 1, 1, 1, 1, 1, 100, 1, 1, 1])
其中列表的数字代表10个类别的权重值。
训练结果:
epoch 0, loss 2.045273, train acc 0.137, test acc 0.467, time 20.7s
epoch 1, loss 0.510476, train acc 0.810, test acc 0.907, time 21.3s
epoch 2, loss 0.148246, train acc 0.922, test acc 0.941, time 21.1s
epoch 3, loss 0.099026, train acc 0.944, test acc 0.953, time 21.2s
epoch 4, loss 0.075481, train acc 0.954, test acc 0.959, time 21.3s
测试结果:
0.9196242171189979
对比看出,FocalLoss可以有效缓解类别不均衡问题(当然并不能完全消除,有足够平衡的高质量数据集肯定更好啦~)。
相关文章:
分类网络-类别不均衡问题之FocalLoss
有训练和测代码如下:(完整代码来自CNN从搭建到部署实战) train.py import torch import torchvision import time import argparse import importlib from loss import FocalLossdef parse_args():parser argparse.ArgumentParser(training)parser.add_argument(-…...

记录一下ComboBox在listview中的问题,后面再解决。
在listview的ComboBox,ViewModel类得不到ComboBox的 SelectedModeIndex 和 SelectionChanged事件。 问题描述: 1. 在listview中有ComboBox 2. 数据源类 InspectionInfo ,其中有ComboBox的绑定数据源 ModelList,代码如下&#…...

手写一个PrattParser基本运算解析器1: 编译原理概述
点击查看 基于Swift的PrattParser项目 编译原理概述 编译原理是我们每一个程序猿必须要了解的技能, 编译原理实际上并没有啥高深的技术, 我们如果在做业务开发, 也很少会用到编译开发的知识, 但是编译原理又是我们必备的基础知识之一. 所以我们需要对编译原理的内容有一个大概的…...

ZKP3.2 Programming ZKPs (Arkworks Zokrates)
ZKP学习笔记 ZK-Learning MOOC课程笔记 Lecture 3: Programming ZKPs (Guest Lecturers: Pratyush Mishra and Alex Ozdemir) 3.3 Using a library ( tutorial) R1CS Libraries A library in a host language (Eg: Rust, OCaml, C, Go, …)Key type: constraint system Mai…...
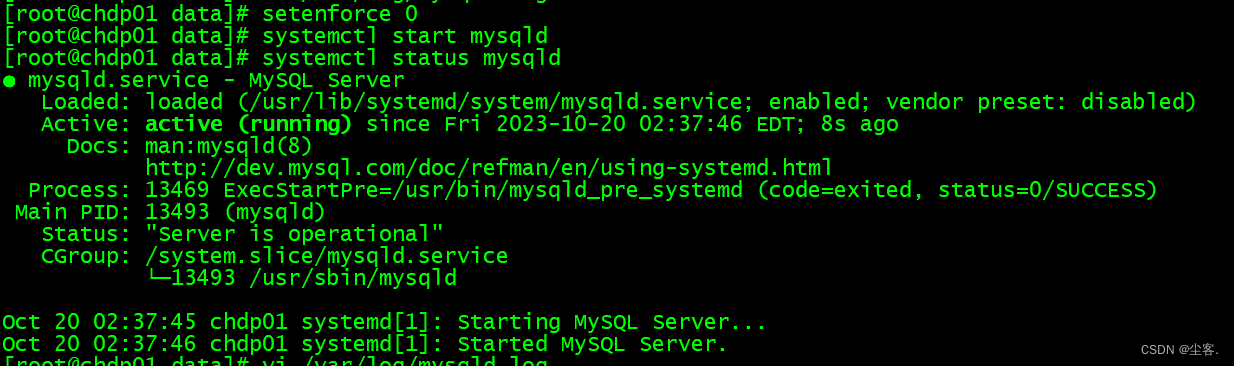
mysqld: File ‘./binlog.index‘ not found (OS errno 13 - Permission denied) 问题解决
问题背景 Centos7 安装Mysql 8后启动时遇到的问题,看了好几个博客方案无效,搞了半小时才找到正解,在此次进行记录。 在此假设你已经修改了对应目录的权限,比如配置的mysql data目录初始化后已经执行了chown -R mysql:mysql /XXX/…...

Python 环境构建最佳实践:Mamba + Conda + PIP
此前,我们单独介绍过 PIP 和 Conda,在后续的实际应用中,还是遇到了不少 Python 环境构建的问题,特别是在 Windows 系统上,最突出的表现是:虽然PIP的包依赖解析和下载都很快,但在 Windows 上经常会因为缺失底层依赖的程序库(例如某些dll文件)而导致 Python 程序启动时报…...
【java】A卷+B卷)
华为OD 最多团队(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

2023“龙芯杯”信创攻防赛 | 赛宁网安技术支持
2023年10月19日,为深入贯彻国家网络强国战略思想,宣传国家网络安全顶层设计,落实《网络安全法》《数据安全法》等法律法规。由大学生网络安全尖锋训练营主办,龙芯中科技术股份有限公司承办,山石网科通信技术股份有限公…...

代码随想录算法训练营第五十八天| 583. 两个字符串的删除操作 72. 编辑距离
今日学习的文章链接和视频链接 两个字符串的删除操作 https://programmercarl.com/0583.%E4%B8%A4%E4%B8%AA%E5%AD%97%E7%AC%A6%E4%B8%B2%E7%9A%84%E5%88%A0%E9%99%A4%E6%93%8D%E4%BD%9C.html 编辑距离 https://programmercarl.com/0072.%E7%BC%96%E8%BE%91%E8%B7%9D%E7%A6%BB…...

leetcode做题笔记191. 位1的个数
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 1 的个数(也被称为汉明重量)。 提示: 请注意,在某些语言(如 Java)中…...

Git基本命令和使用
文章目录 1、Git本地库命令1.1、初始化本地库1.2、设置用户签名1.3、查看本地库状态1.4、将工作区的修改添加到暂存区1.5、将暂存区的修改提交到本地库1.6、历史版本1.7、取消commit1.8、取消暂存文件 2、分支操作2.1、查看分支2.2、创建分支2.3、分支合并时产生冲突 3、Gitee远…...
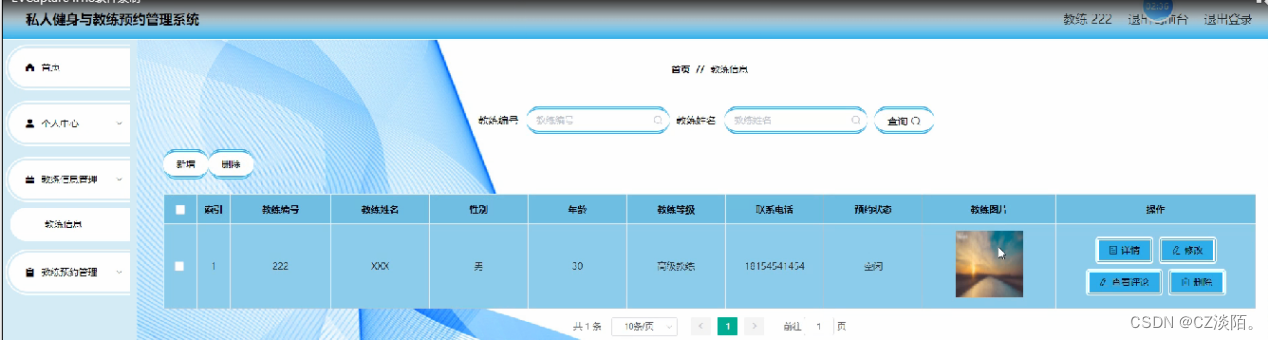
50springboot私人健身与教练预约管理系统
大家好✌!我是CZ淡陌。一名专注以理论为基础实战为主的技术博主,将再这里为大家分享优质的实战项目,本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目,希望你能有所收获,少走一些弯路…...

测试Android webview 加载本地html
最近开发一个需要未联网功能的App, 不熟悉使用Java原生开发界面,于是想使用本地H5做界面,本文测试了使用本地html加载远程数据。直接上代码: MainActivity.java package com.alex.webviewlocal;import androidx.appcompat.app.AppCompatAct…...

ubuntu安装pgsql
ubuntu安装postgresSQL 官网地址: https://www.postgresql.org/download/ 1.安装 # 添加源 sudo sh -c echo "deb https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list # 安装数字签名 w…...
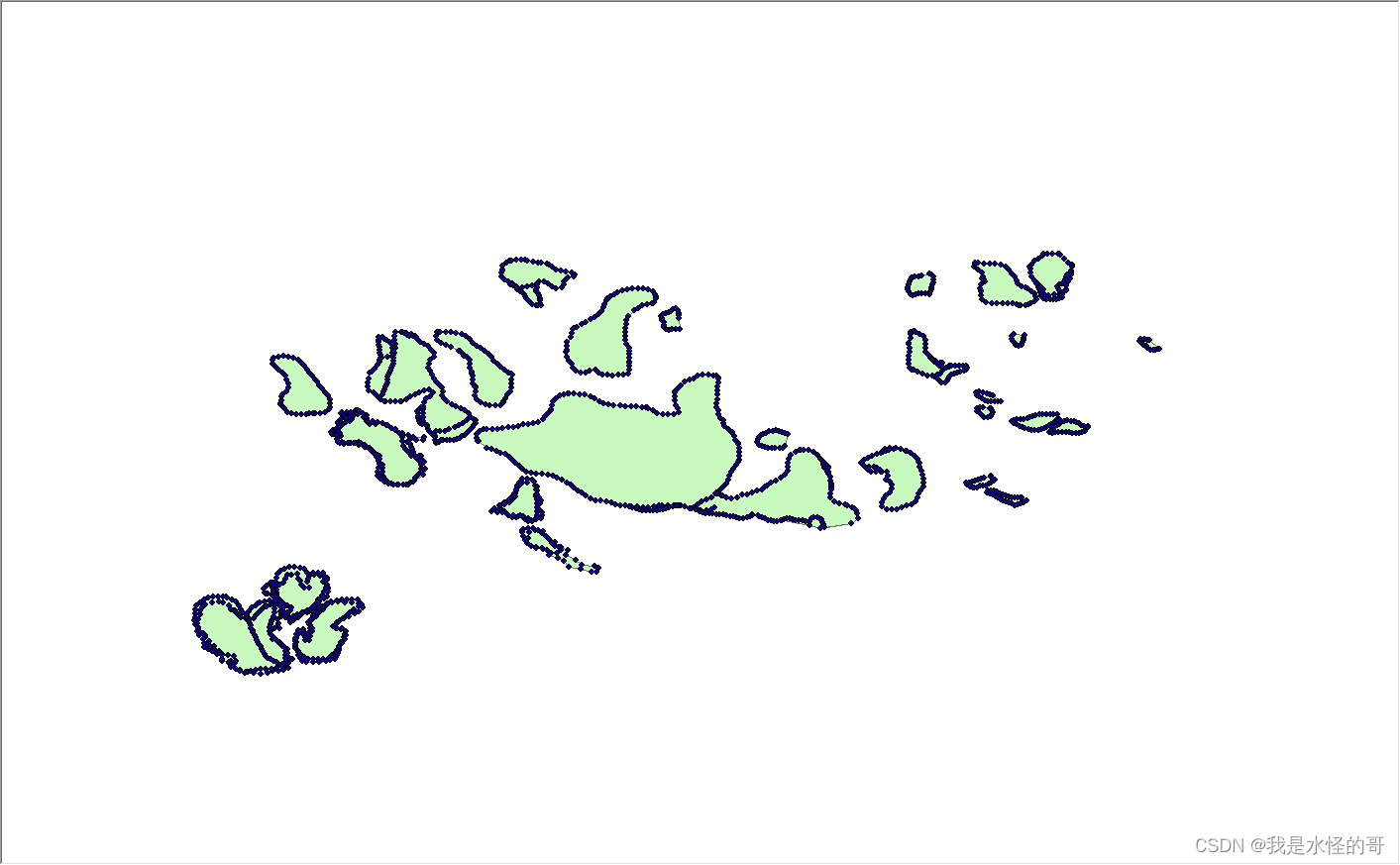
利用ArcGIS获取每一个冰川的中心位置经纬度坐标:要素转点和要素折点转点的区别
问题概述:下图是天山地区的冰川的分布,我们可以看到每一条冰川是一个面要素,要求得到每一个冰川(面要素)的中心经纬度坐标。 1.采用要素转点功能 选择工具箱的【数据管理工具】-【要素】-【要素转点】。完成之后再采用…...
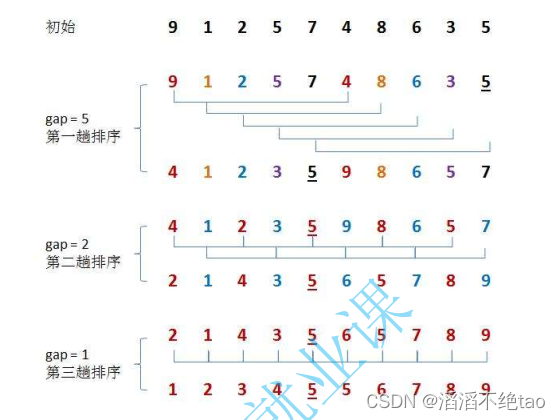
数据结构中的七大排序(Java实现)
目录 一、直接插入排序 二、希尔排序 三、直接选择排序 四、堆排序 五、冒泡排序 六、快速排序 七、归并排序 一、直接插入排序 思想: 定义i下标之前的元素全部已经有序,遍历一遍要排序的数组,把i下标前的元素全部进行排序࿰…...

深度学习基础算法
算法 1.K近邻算法 机器学习--K-近邻算法(KNN)_k近邻-CSDN博客 2. 数据库样本: CIFAR-10 CIFAR-10数据集(介绍、下载读取、可视化显示、另存为图片)_cifar10数据集-CSDN博客...
-- ir - 红外遥控)
LuatOS-SOC接口文档(air780E)-- ir - 红外遥控
ir.sendNEC(pin, addr, cmd, repeat, disablePWM)# 发送NEC数据 参数 传入值类型 解释 int 使用的GPIO引脚编号 int 用户码(大于0xff则采用Extended NEC模式) int 数据码 int 可选,引导码发送次数(110ms一次࿰…...
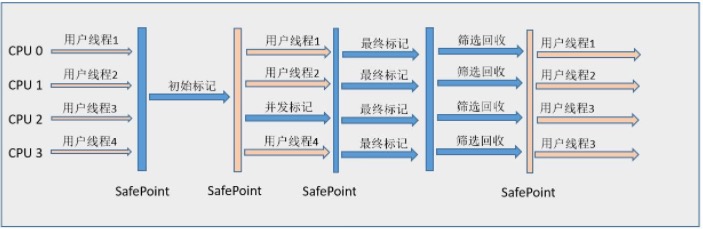
Java虚拟机常见面试题总结
梳理Java虚拟机相关的面试题,主要参考《深入理解Java虚拟机 JVM高级特性与最佳实践》(第2版, 周志明 著)一书,其余部分整合网络相关内容。注意,关于Java并发编程的面试题因为内容较多,单独整理。Java基础相关的面试题可以参考Java…...
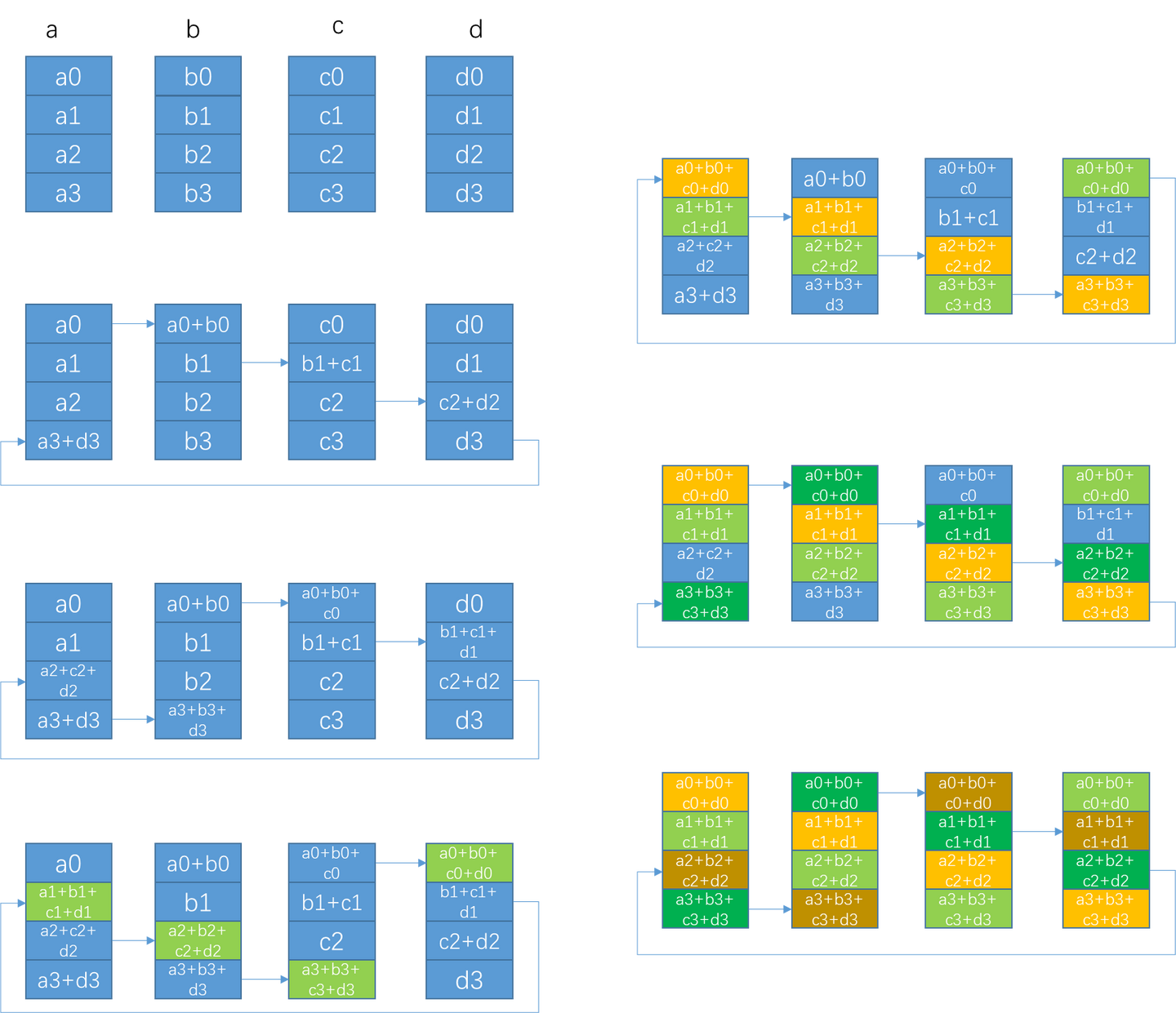
NVIDIA NCCL 源码学习(十一)- ring allreduce
之前的章节里我们看到了nccl send/recv通信的过程,本节我们以ring allreduce为例看下集合通信的过程。整体执行流程和send/recv很像,所以对于相似的流程只做简单介绍,主要介绍ring allreduce自己特有内容。 单机 搜索ring 在nccl初始化的过…...
)
避坑指南:PX4飞控遥控器校准、舵机设置与通道切换的那些‘坑’(附QGC参数详解)
PX4飞控深度调参手册:从遥控器校准到舵机控制的实战避坑指南 当你的无人机在加装舵机后突然无法解锁,或是切换飞行模式时遥控器毫无反应,又或者无人车死活不肯倒车——这些看似简单的功能异常背后,往往隐藏着PX4参数系统中那些鲜为…...

告别混乱!用Qt的.pri子模块重构你的大型项目,让代码复用和团队协作更丝滑
告别混乱!用Qt的.pri子模块重构你的大型项目,让代码复用和团队协作更丝滑 当Qt项目从几百行Demo膨胀成数万行企业级应用时,每个开发者都会遇到这样的噩梦:修改一个通用组件需要同步修改十几个文件;新人入职两周还理不清…...

Venera漫画源自动更新终极指南:如何让漫画库永远保持最新状态
Venera漫画源自动更新终极指南:如何让漫画库永远保持最新状态 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 你是否曾经遇到过这样的情况:刚刚找到一个喜欢的漫画网站,但没过几天就发现无…...

Android车机开发避坑:CarLauncher与地图Activity同时Resumed?多窗口模式源码解析
Android车机多窗口模式源码解析:为何CarLauncher与地图Activity能同时Resumed? 在车载Android系统开发中,一个看似违反常识的现象经常困扰开发者:当使用WINDOWING_MODE_MULTI_WINDOW模式时,CarLauncher主界面与地图导航…...

别再只会用轮询了!STM32CubeMX串口中断接收实战:从HAL_UART_Receive_IT到回调函数详解
STM32CubeMX串口中断实战:从轮询到中断的思维跃迁 当传感器数据以毫秒级频率涌入,或上位机指令需要即时响应时,轮询方式就像用显微镜观察流星雨——既低效又容易丢失关键信息。本文将揭示如何通过STM32CubeMX构建真正的异步通信框架ÿ…...

[具身智能-451]:深度神经网络、概率、相似度与创业的本质关联
深度神经网络的本质,既是概率,也是相似度,模糊性,概率分布的本质是反应现实世界的多样性和连续性,相似度是一种牺牲精确性换取效率的策略和思维模式,是人类演进变化与进化的产物,精确的规则缺乏…...
Pixel Agents:将AI编程助手可视化为像素办公室的VS Code扩展
1. 项目概述:当AI智能体走进像素办公室如果你和我一样,每天在VS Code里和Claude Code这类AI编程助手打交道,看着它在终端里一行行地输出代码、执行命令,你可能会觉得这个过程虽然高效,但总有点……冷冰冰的。我们与AI的…...

告别高延迟!3步掌握billd-desk开源远程控制,实现跨平台无缝协作
告别高延迟!3步掌握billd-desk开源远程控制,实现跨平台无缝协作 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制、游戏串流 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 还在为远程控制软件的卡顿…...

ARM RealView Debugger多核同步调试技术详解
1. ARM RealView Debugger多核调试技术解析在嵌入式系统开发领域,多核处理器调试一直是工程师面临的主要技术挑战之一。随着SoC设计复杂度的提升,如何有效协调多个处理核心的调试操作成为关键问题。ARM RealView Debugger提供的SYNCHEXEC命令正是为解决这…...

如何在MATLAB中快速进行翼型气动分析:XFOILinterface完整指南
如何在MATLAB中快速进行翼型气动分析:XFOILinterface完整指南 【免费下载链接】XFOILinterface 项目地址: https://gitcode.com/gh_mirrors/xf/XFOILinterface 想象一下,你是一名航空航天工程师,需要分析不同翼型的气动性能ÿ…...