2、Kafka 生产者
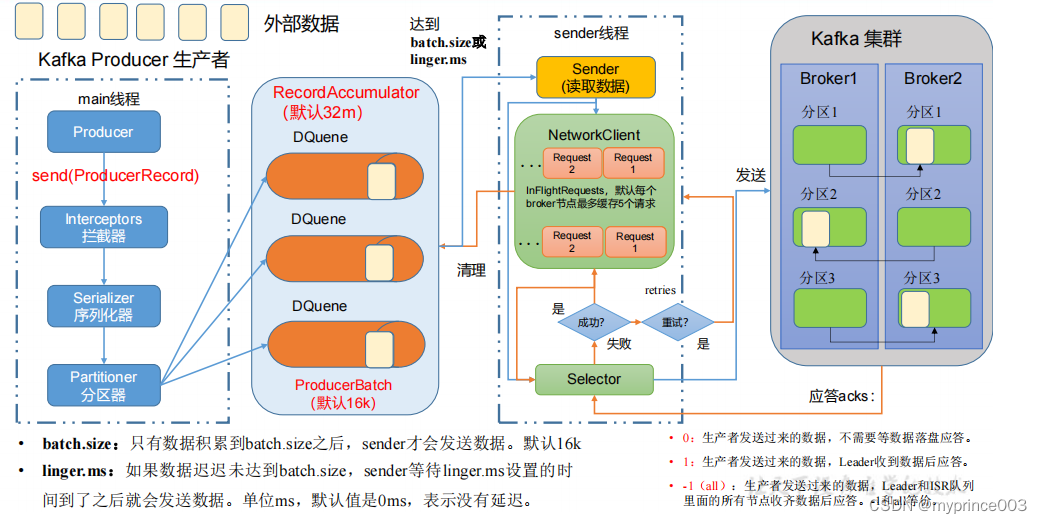
3.1 生产者消息发送流程
3.1.1 发送原理
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程
中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,
Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
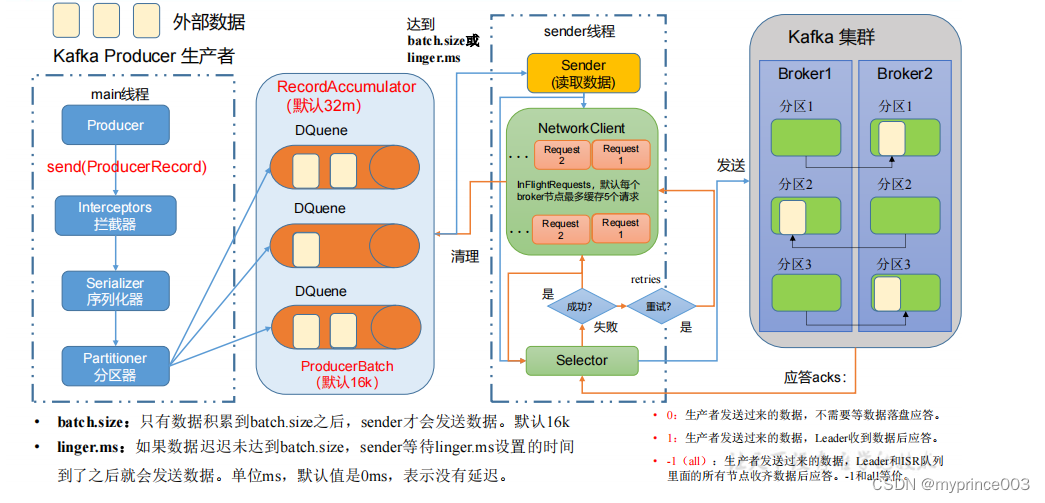
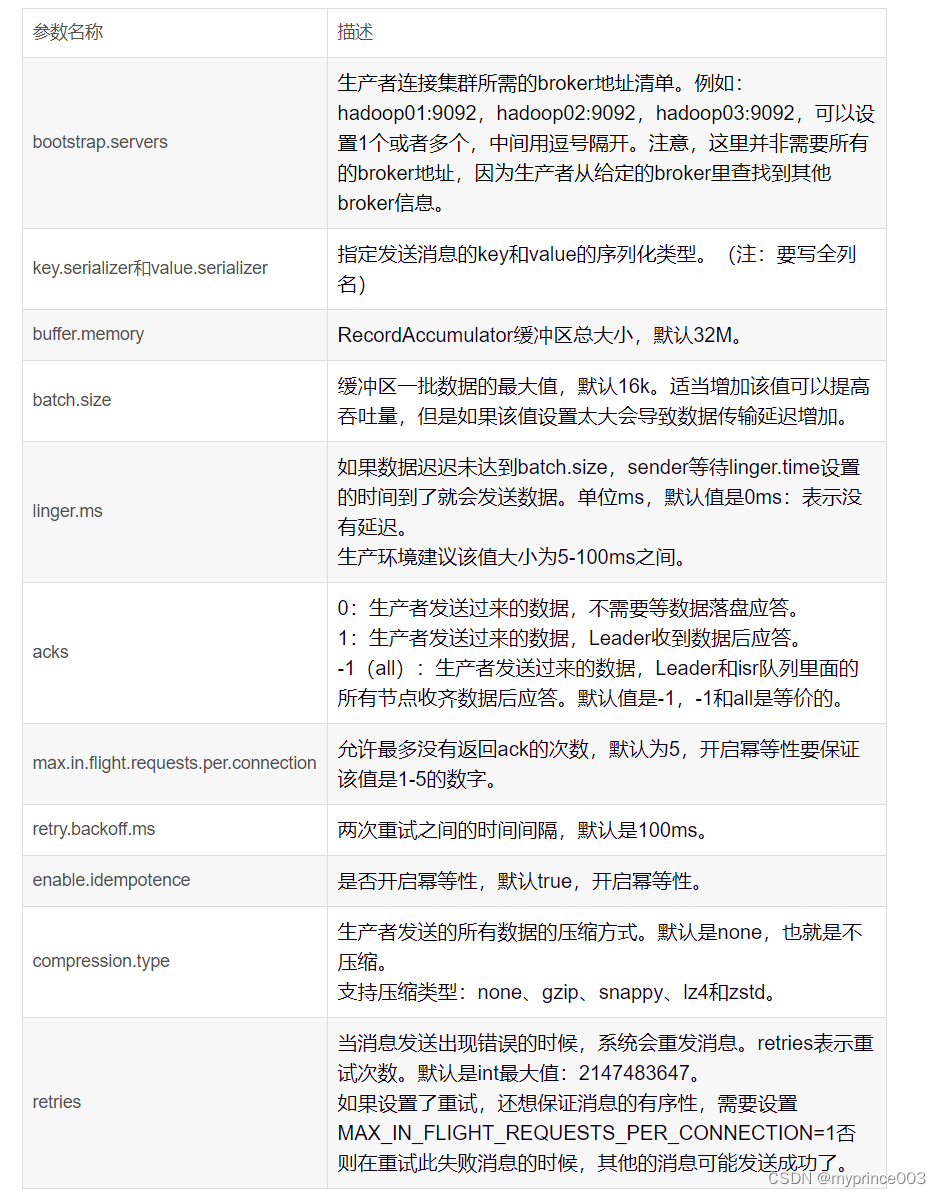
3.1.2 生产者重要参数列表
3.2 异步发送 API
3.2.1 普通异步发送
1)需求:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
2)代码编写
(1)创建工程 kafka
(2)导入依赖
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency>
</dependencies>
(3)创建包名:com.atguigu.kafka.producer
(4)编写不带回调函数的 API 代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer {public static void main(String[] args) throws
InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new
ProducerRecord<>("first","atguigu " + i));}// 5. 关闭资源kafkaProducer.close();}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
3.2.2 带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元
数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发
送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallback {public static void main(String[] args) throws
InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {// 添加回调kafkaProducer.send(new ProducerRecord<>("first",
"prince " + i), new Callback() {
// 该方法在 Producer 收到 ack 时调用,为异步调用@Overridepublic void onCompletion(RecordMetadata metadata,
Exception exception) {if (exception == null) {// 没有异常,输出信息到控制台System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());} else {// 出现异常打印exception.printStackTrace();}}});// 延迟一会会看到数据发往不同分区Thread.sleep(2);}// 5. 关闭资源kafkaProducer.close();}
}测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
③在 IDEA 控制台观察回调信息。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
3.3 同步发送 API
只需在异步发送的基础上,再调用一下 get()方法即可。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducerSync {public static void main(String[] args) throws
InterruptedException, ExecutionException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. 调用 send 方法,发送消息for (int i = 0; i < 10; i++) {// 异步发送 默认
// kafkaProducer.send(new
ProducerRecord<>("first","kafka" + i));// 同步发送kafkaProducer.send(new
ProducerRecord<>("first","kafka" + i)).get();}// 5. 关闭资源kafkaProducer.close();}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
3.4 生产者分区
3.4.1 分区好处
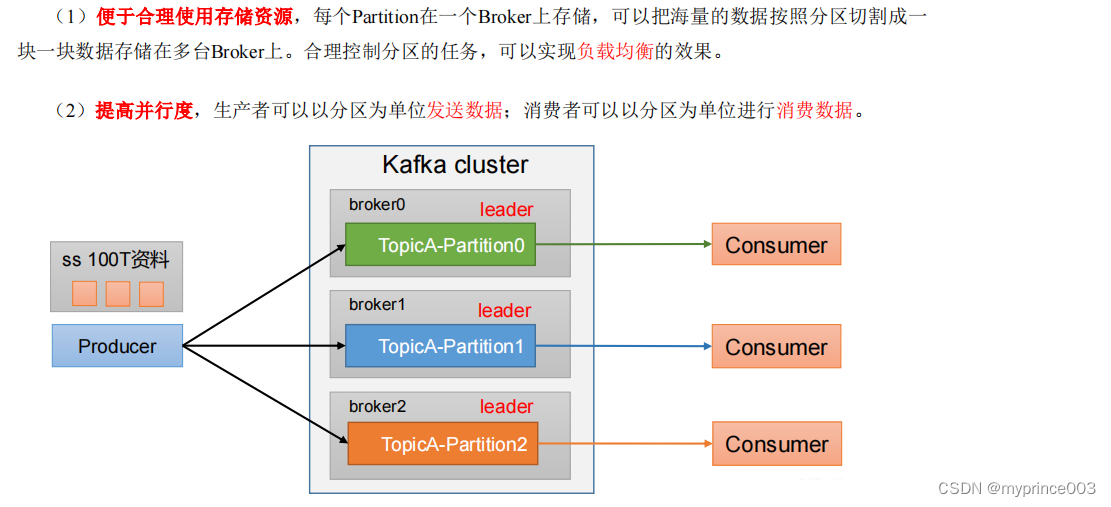
3.4.2 生产者发送消息的分区策略
1)默认的分区器 DefaultPartitioner
在 IDEA 中 ctrl +n,全局查找 DefaultPartitioner。
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a
partition based on a hash of the key
* <li>If no partition or key is present choose the sticky
partition that changes when the batch is full.
*
* See KIP-480 for details about sticky partitioning.
*/
public class DefaultPartitioner implements Partitioner {… …
}

2)案例一
将数据发往指定 partition 的情况下,例如,将所有数据发往分区 1 中。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {public static void main(String[] args) {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {// 指定数据发送到 1 号分区,key 为空(IDEA 中 ctrl + p 查看参数)kafkaProducer.send(new ProducerRecord<>("first",
1,"","prince " + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata,
Exception e) {if (e == null){System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());}else {e.printStackTrace();}}});}kafkaProducer.close();}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
③在 IDEA 控制台观察回调信息。
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
3)案例二
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取
余得到 partition 值。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallback {public static void main(String[] args) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {// 依次指定 key 值为 a,b,f ,数据 key 的 hash 值与 3 个分区求余,
分别发往 1、2、0kafkaProducer.send(new ProducerRecord<>("first",
"a","prince " + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata,
Exception e) {if (e == null){System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());}else {e.printStackTrace();}}});}kafkaProducer.close();}
}
测试:
①key="a"时,在控制台查看结果。
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
②key="b"时,在控制台查看结果。
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
③key="f"时,在控制台查看结果。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
3.4.3 自定义分区器
如果研发人员可以根据企业需求,自己重新实现分区器。
1)需求
例如我们实现一个分区器实现,发送过来的数据中如果包含 atguigu,就发往 0 号分区,
不包含 atguigu,就发往 1 号分区。
2)实现步骤
(1)定义类实现 Partitioner 接口。
(2)重写 partition()方法。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 1. 实现接口 Partitioner
* 2. 实现 3 个方法:partition,close,configure
* 3. 编写 partition 方法,返回分区号
*/
public class MyPartitioner implements Partitioner {/* 返回信息对应的分区* @param topic 主题* @param key 消息的 key* @param keyBytes 消息的 key 序列化后的字节数组* @param value 消息的 value* @param valueBytes 消息的 value 序列化后的字节数组* @param cluster 集群元数据可以查看分区信息* @return*/@Overridepublic int partition(String topic, Object key, byte[]
keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取消息String msgValue = value.toString();// 创建 partitionint partition;// 判断消息是否包含 atguiguif (msgValue.contains("atguigu")){partition = 0;}else {partition = 1;}// 返回分区号return partition;}// 关闭资源@Overridepublic void close() {}// 配置方法@Overridepublic void configure(Map<String, ?> configs) {}
}
(3)使用分区器的方法,在生产者的配置中添加分区器参数。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {public static void main(String[] args) throws
InterruptedException {
Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());// 添加自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atgui
gu.kafka.producer.MyPartitioner");KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first",
"prince " + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata,
Exception e) {if (e == null){System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());}else {e.printStackTrace();}}});}kafkaProducer.close();}
}
(4)测试
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 控制台观察回调信息。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
3.5 生产经验——生产者如何提高吞吐量

import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerParameters {public static void main(String[] args) throws
InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");// batch.size:批次大小,默认 16Kproperties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// linger.ms:等待时间,默认 0properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// RecordAccumulator:缓冲区大小,默认 32M:buffer.memoryproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// compression.type:压缩,默认 none,可配置值 gzip、snappy、
lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new
ProducerRecord<>("first","prince " + i));}// 5. 关闭资源kafkaProducer.close();}
} 测试
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
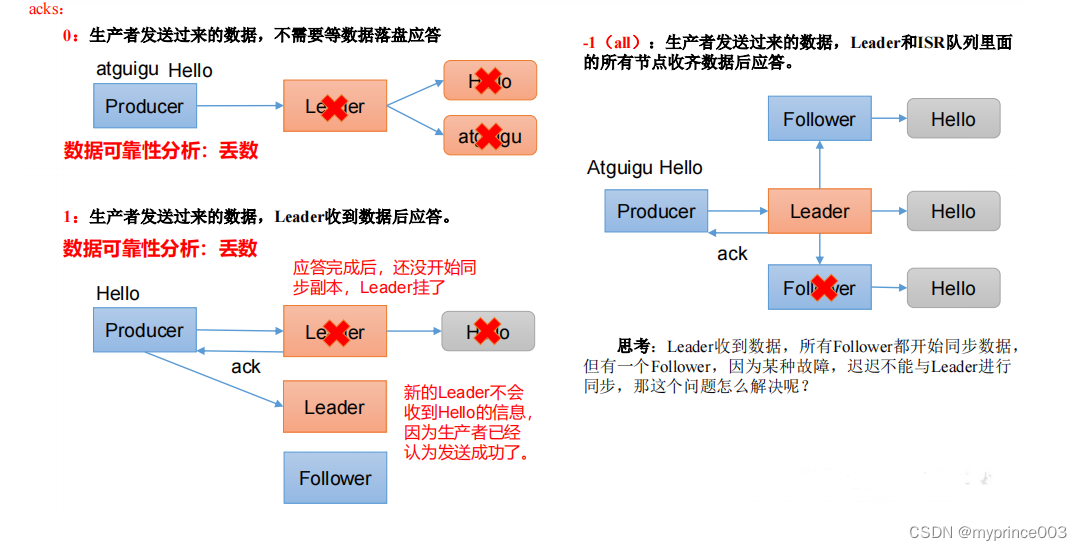
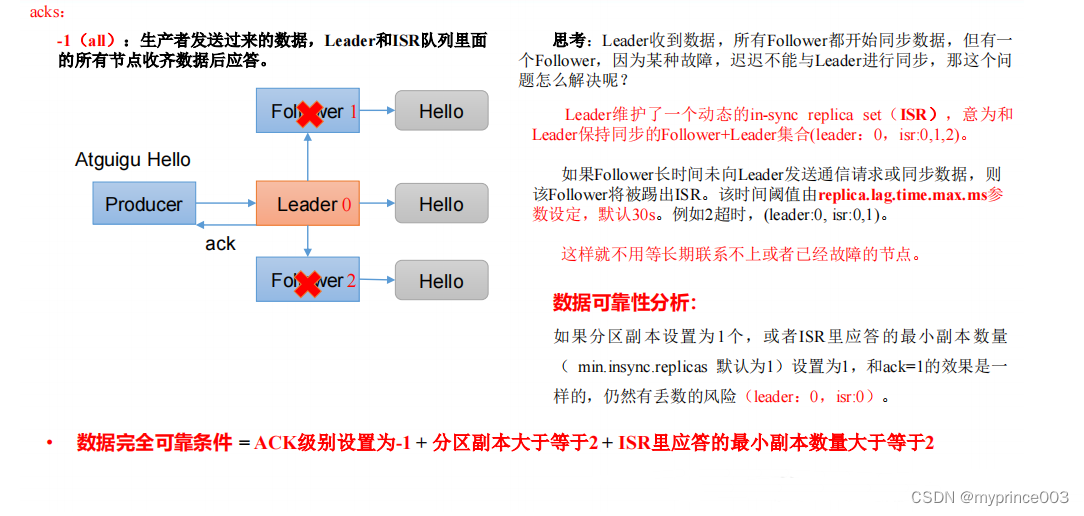
3.6 生产经验——数据可靠性
1)ack 应答原理

2)代码配置
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerAck {public static void main(String[] args) throws
InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers102:9092");// key,value 序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());// 设置 acksproperties.put(ProducerConfig.ACKS_CONFIG, "all");// 重试次数 retries,默认是 int 最大值,2147483647properties.put(ProducerConfig.RETRIES_CONFIG, 3);// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new
ProducerRecord<>("first","prince " + i));}// 5. 关闭资源kafkaProducer.close();}
}
3.7 生产经验——数据去重
3.7.1 数据传递语义

3.7.2 幂等性
1)幂等性原理

2)如何使用幂等性
开启参数 enable.idempotence 默认为 true,false 关闭。
3.7.3 生产者事务
1)Kafka 事务原理
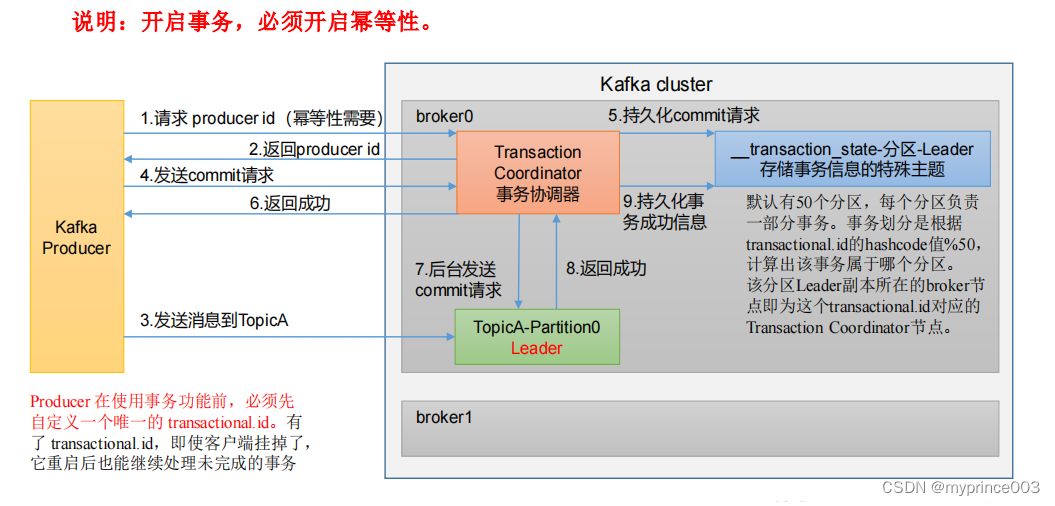
2)Kafka 的事务一共有如下 5 个 API
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
3)单个 Producer,使用事务保证消息的仅一次发送
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {public static void main(String[] args) throws
InterruptedException {// 1. 创建 kafka 生产者的配置对象Properties properties = new Properties();// 2. 给 kafka 配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value 序列化properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());// 设置事务 id(必须),事务 id 任意起名properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,
"transaction_id_0");// 3. 创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);// 初始化事务kafkaProducer.initTransactions();// 开启事务kafkaProducer.beginTransaction();try {// 4. 调用 send 方法,发送消息for (int i = 0; i < 5; i++) {// 发送消息kafkaProducer.send(new ProducerRecord<>("first",
"prince " + i));}
// int i = 1 / 0;// 提交事务kafkaProducer.commitTransaction();} catch (Exception e) {// 终止事务kafkaProducer.abortTransaction();} finally {// 5. 关闭资源kafkaProducer.close();}}
}
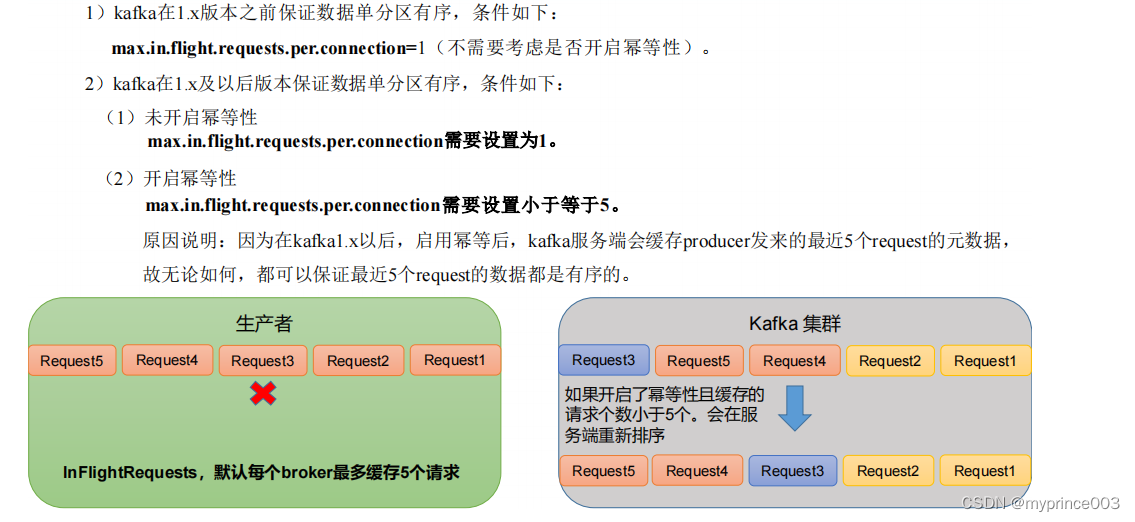
3.8 生产经验——数据有序
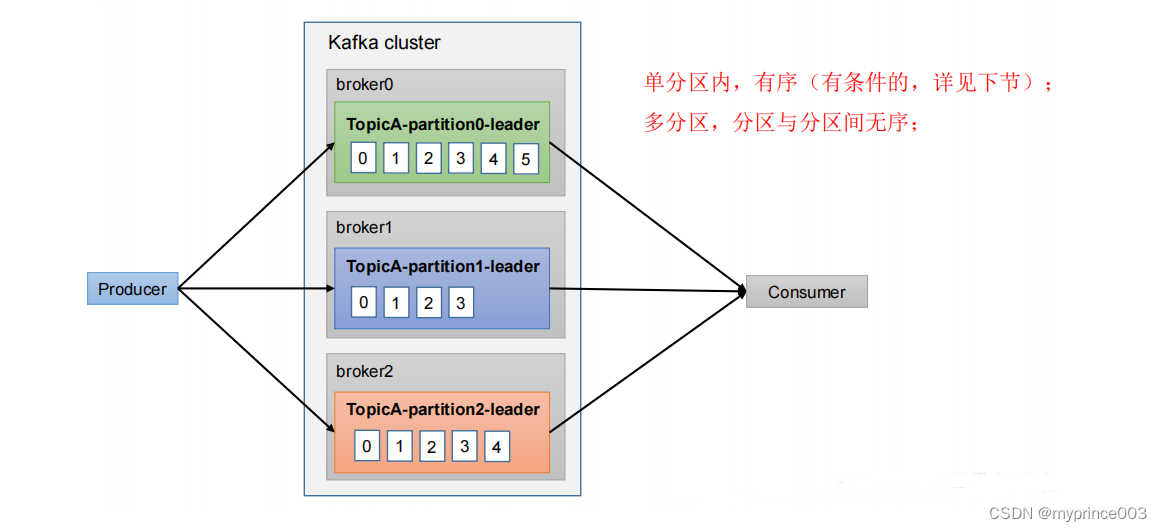
3.9 生产经验——数据乱序
相关文章:
2、Kafka 生产者
3.1 生产者消息发送流程 3.1.1 发送原理 在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程 中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中…...
使用CDN构建读取缓存设计
在构建需要高吞吐量和最小响应时间的系统的API时,缓存几乎是不可避免的。每个在分布式系统上工作的开发人员都曾在某个时候使用过某种缓存机制。在本文中,我们将探讨如何使用CDN构建读取缓存设计,不仅可以优化您的API,还可以降低基…...
windows上下载github上的linux内核项目遇到的问题
问题一:clone的时候报错 Cloning into G:\github\linux... POST git-upload-pack (gzip 27925 to 14032 bytes) remote: Counting objects: 6012062, done. remote: Compressing objects: 100% (1031/1031), done. remote: Total 6012062 (delta 893), reused 342 (…...

Leetcode 15:三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 解题思…...
npm常用命令与操作篇
npm简介 npm是什么 npm 的英文是,node package manager,是 node 的包管理工具 为什么需要npm 类比建造汽车一样,如果发动机、车身、轮胎、玻璃等等都自己做的话,几十年也做不完。但是如果有不同的厂商,已经帮我们把…...

Go 语言的垃圾回收机制:自动化内存管理
在编程的世界中,内存管理一直是一个重要的问题。不正确的内存管理可能导致内存泄漏和程序崩溃。Go 语言以其高效的垃圾回收机制而闻名,使开发者从手动内存管理的烦恼中解脱出来。本文将深入探讨Go语言的垃圾回收机制,介绍它的工作原理以及如何…...

java-各种成员变量初始化过程-待完善
前置条件 一、本文章讨论的成员变量 public static final String aa "aa";public static final Integer bb 1;public static final Students cc new Students();public static String aa1 "aa";public static Integer bb1 1;public static String bb2…...

059:mapboxGL监听键盘事件,通过eastTo控制左右旋转
第059个 点击查看专栏目录 本示例是介绍演示如何在vue+mapbox中监听键盘事件,通过eastTo控制左右旋转。 本例通过easeTo方法来加减一定数值的bearing角度,通过.addEventListener的方法来监听键盘的按键动作。这里一定要设置interactive: false, 否则展现不出来旋转效果。 直…...

jdk对linux cgroup v2容器化环境识别情况
Linux各发行版将cgroups v2作为默认的情况如下: Container-Optimized OS(从 M97 开始)Ubuntu(从 21.10 开始,推荐 22.04)Debian GNU/Linux(从 Debian 11 Bullseye 开始)Fedora&…...
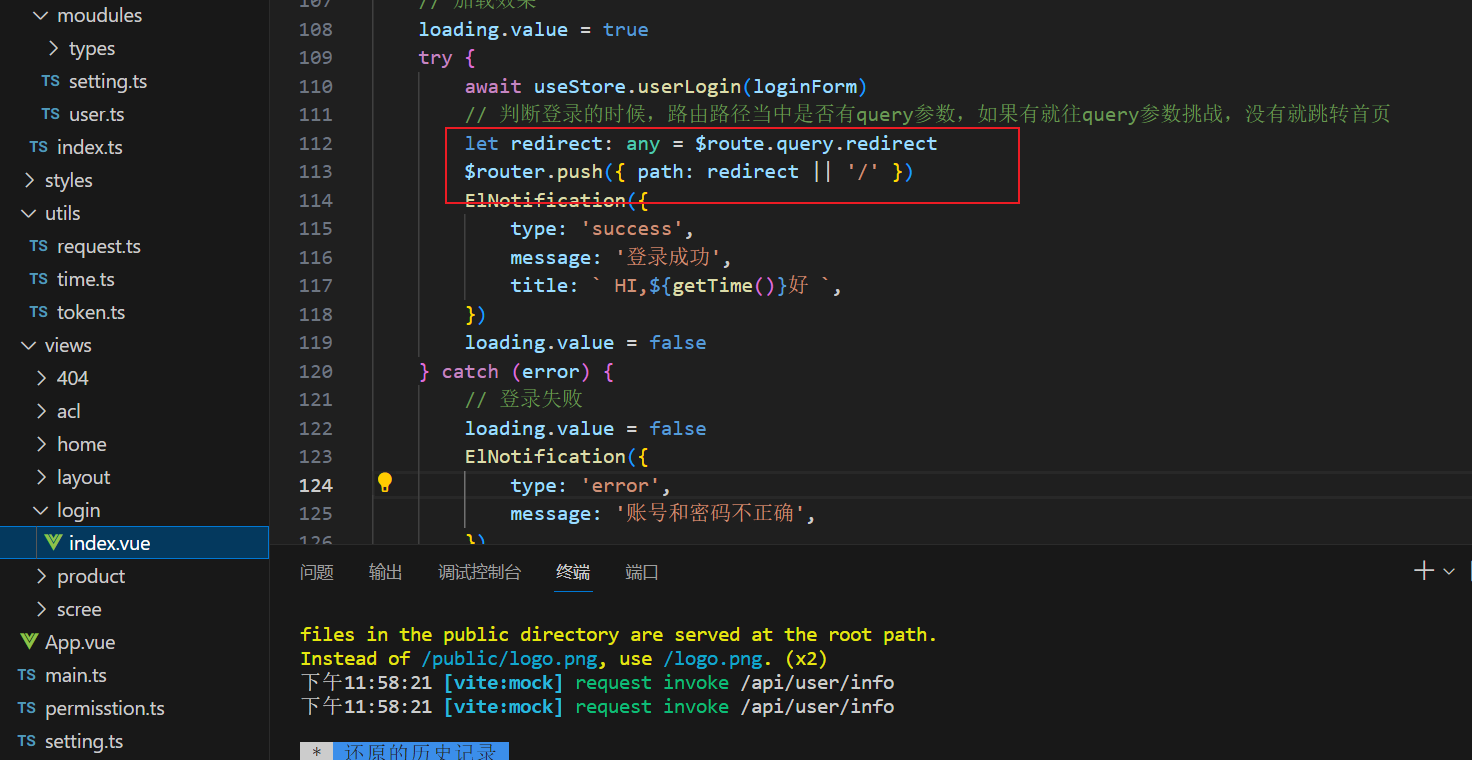
vue3后台管理系统之顶部tabbar组件搭建
1.1静态页面搭建 <template><div class"tabbar"><div class"tabbar_left"><!-- 面包屑 --><Breadcrumb /></div><div class"tabbar_right"><!-- 设置 --><Setting /></div></di…...

安装Apache2.4
二、安装配置Apache: 中文官网:Apache 中文网 官网 (p2hp.com) 我下的是图中那个版本,最新的64位 下载下后解压缩。如解压到D:\tool\Apache24 PS:特别要注意使用的场景和64位还是32位版本 2、修改Apcahe配置文件 2.1配置Apache…...
)
KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(9)
接前一篇文章:KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(8) 上一回讲完了drm_internal_framebuffer_create函数中的framebuffer_check函数中的drm_get_format_info函数,本文继续讲解framebuffer_check函数中的余下步骤。为了便于理解,再次贴出framebuffer_ch…...
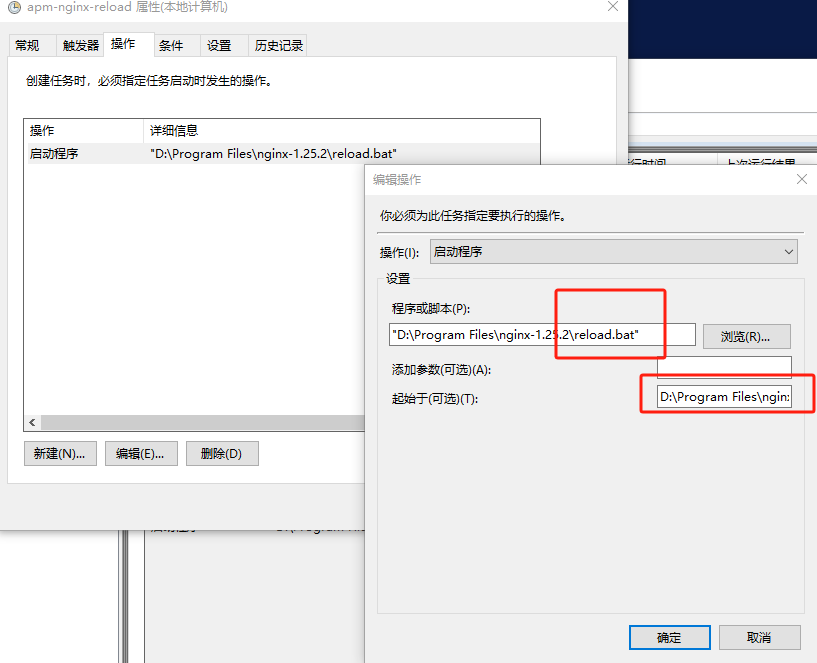
Win10使用nginx,注册到服务设置自启与后台运行,解决 Access is denied 问题
安装 nginx 下载 nginx 官网下载页面:https://nginx.org/en/download.html直接选择当前最新 window 版本的或找到自己需要的版本下载即可 安装使用 下载完成后是有一个压缩包文件,直接解压到自己需要的目录下即可。是免安装的,解压即用简…...
短视频矩阵系统源头开发
一、智能剪辑、矩阵分发、无人直播、爆款文案于一体独立应用开发 抖去推----主要针对本地生活的----移动端(小程序软件系统,目前是全国源头独立开发),开发功能大拆解分享,功能大拆解: 7大模型剪辑法(数学阶乘&#x…...
《windows核心编程》第1章 错误处理
一、错误信息的获取 1.1 C库错误信息 1、获取错误信息 #include <stdio.h> #include <stdlib.h> #include <string.h>int main() {fopen("D:\\ASC", "r");printf("%s\n", strerror(errno));getchar();return 0; } 2、设置错…...
解剖—单链表相关OJ练习题
目录 一、移除链表元素 二、找出链表的中间节点 三、合并两个有序链表 四、反转链表 五、求链表中倒数第k个结点 六、链表分割 七、链表的回文结构 八、判断链表是否相交 九、判断链表中是否有环(一) 十、 判断链表中是否有环(二) 注:第六题和第七题牛…...

php对接飞书机器人
有同事接到对接飞书机器人任务,开发中遇到响应错误: {"code": 19021,"msg": "sign match fail or timestamp is not within one hour from current time" } 意思应该就是签名错误或者时间戳不在有效范围内等,…...
中间件安全-CVE复现IISApacheTomcatNginx漏洞复现
目录 中间件安全&CVE复现&IIS&Apache&Tomcat&Nginx漏洞复现中间件-IIS安全问题中间件-Nginx安全问题漏洞复现Nginx 解析漏洞复现Nginx 文件名逻辑漏洞 中间件-Apache-RCE&目录遍历&文件解析等安全问题漏洞复现漏洞复现CVE_2021_42013 RCE代码执行&…...

@ResponseBodyAdvice @RequestBodyAdivce失效
背景 最近项目要有向外部提供服务的能力,但是考虑到数据安全问题,要对接口进行加解密;实现加解密的方案有很多,比如过滤器、拦截器、继承RequestResponseBodyMethodProcessor什么的,不过我最近正在了解ResponseBodyAd…...

【c#】Quartz开源任务调度框架学习及练习Demo
Quartz开源任务调度框架学习及练习Demo 1、定义、作用 2、原理 3、使用步骤 4、使用场景 5、Demo代码参考示例 6、注意事项 7、一些Trigger属性说明 1、定义、作用 Quartz是一个开源的任务调度框架,作用是支持开发人员可以定时处理业务,比如定时…...

MAA助手:明日方舟终极自动化解决方案的技术架构与实践指南
MAA助手:明日方舟终极自动化解决方案的技术架构与实践指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https:/…...

UnityFigmaBridge解决方案:重塑设计开发协作的战略价值
UnityFigmaBridge解决方案:重塑设计开发协作的战略价值 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBridge 在当今快速迭代…...

小白转行AI大模型工程师?收藏这份独家学习路线,3个月带你从0到1实操落地!
文章分享作者从计算机小白成功转行AI大模型工程师的经历,指出转行AI大模型的关键在于掌握能落地的技能而非死磕算法公式。作者提供了一套为期三个月的学习路线,包括打牢Python基础、建立大模型认知、掌握Prompt技巧、攻克RAG技术、学习Agent搭建和LangCh…...

量子投票协议:原理、实现与噪声分析
1. 量子投票协议的基本原理与实现量子投票协议是一种利用量子力学特性来优化传统投票系统的新型决策机制。在经典投票系统中,每个选民独立表达自己的偏好,而量子投票则通过量子态的叠加和纠缠特性,实现了选民偏好之间的量子关联。这种关联性为…...

2024年CSDN技术趋势全景图
CSDN年度技术趋势预测技术文章大纲引言技术趋势预测的背景和重要性CSDN作为技术社区的影响力文章结构和主要内容概述人工智能与机器学习生成式AI的持续突破与应用场景扩展多模态模型的商业化落地边缘AI与轻量化模型的普及云计算与分布式系统混合云与多云架构的标准化Serverless…...

七十六、Fluent初始化进阶:Patch与UDF实战指南
1. Patch操作:流场精准修正的艺术 想象一下你正在组装一台精密仪器,所有零件都已就位,但某个关键齿轮的尺寸偏差了0.1毫米。这时候你不会拆掉整台机器重新组装,而是会用一个垫片进行微调——这正是Patch操作在CFD仿真中的角色。作…...

魔兽争霸III终极优化指南:WarcraftHelper完整配置与应用手册
魔兽争霸III终极优化指南:WarcraftHelper完整配置与应用手册 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典的即时战…...

免费精灵图打包工具:游戏与网页开发者的性能优化利器 [特殊字符]
免费精灵图打包工具:游戏与网页开发者的性能优化利器 🚀 【免费下载链接】free-tex-packer Free texture packer 项目地址: https://gitcode.com/gh_mirrors/fr/free-tex-packer 还在为游戏加载缓慢而烦恼?或者网页上几十个小图标让页…...

Google Cloud Next 26: 定义 “智能体企业“ 新纪元
以下文章来源于谷歌云服务,作者 Google CloudThomas KurianGoogle Cloud 首席执行官本周,我们在 Next 26 大会上宣布了一系列创新技术,包括全新统一的 AI 技术栈、第八代 TPU (Tensor Processing Unit),以及在数据、安全和生产力领…...

终极指南:AMD显卡用户如何轻松玩转kohya_ss AI模型训练
终极指南:AMD显卡用户如何轻松玩转kohya_ss AI模型训练 【免费下载链接】kohya_ss 项目地址: https://gitcode.com/GitHub_Trending/ko/kohya_ss 你是否拥有AMD显卡,却苦于找不到好用的AI模型训练工具?好消息来了!kohya_s…...