Elasticsearch实践:ELK+Kafka+Beats对日志收集平台的实现
可以在短时间内搜索和分析大量数据。
Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。
本文将介绍 ELK+Kafka+Beats 对日志收集平台的实现。
文章目录
- 1、关于ELK与BKELK
- 1.1、ELK架构及其影响
- 1.2、基于BKLEK架构的日志分析系统实现
- 2、利用ELK+Kafka+Beats来实现一个统一日志平台
- 2.1、应用场景
- 2.2、环境准备
- 2.3、基于Docker的ES部署
- 2.4、基于Docker的kibana部署
- 2.5、基于Docker的Zookeeper部署
- 2.6、基于Docker的Kafka部署
- 2.7、基于Docker的Logstash部署
- 2.8、基于Docker的Filebeat部署
1、关于ELK与BKELK
1.1、ELK架构及其影响
当我们在开源日志分析系统的领域,谈及 ELK 架构可谓是家喻户晓。然而,这个生态系统并非 Elastic 有意为之,毕竟 Elasticsearch 的初衷是作为一个分布式搜索引擎。其广泛应用于日志系统,实则是一种意料之外,这是社区用户的推动所致。如今,众多云服务厂商在推广自己的日志服务时,往往以 ELK 作为参照标准,由此可见,ELK 的影响力之深远。
ELK 是 Elasticsearch、Logstash 和 Kibana 的首字母缩写,这三个产品都是 Elastic 公司的开源项目,通常一起使用以实现数据的搜索、分析和可视化。
-
Elasticsearch:一个基于 Lucene 的搜索服务器。它提供了一个分布式、多租户的全文搜索引擎,具有 HTTP 网络接口和无模式 JSON 文档。
-
Logstash:是一个服务器端数据处理管道,它可以同时从多个来源接收数据,转换数据,然后将数据发送到你选择的地方。
-
Kibana:是一个用于 Elasticsearch 的开源数据可视化插件。它提供了查找、查看和交互存储在 Elasticsearch 索引中的数据的方式。你可以使用它进行高级数据分析和可视化你的数据等。
这三个工具通常一起使用,以便从各种来源收集、搜索、分析和可视化数据。
1.2、基于BKLEK架构的日志分析系统实现
实际上,在流行的架构中并非只有 ELKB。当我们利用 ELKB 构建一套日志系统时,除了 Elasticsearch、Logstash、Kibana、beats 之外,还有一个被广泛应用的工具 —— Kafka。在这个体系中,Kafka 的角色尤为重要。作为一个中间件和缓冲区,它能够提升吞吐量,隔离峰值影响,缓存日志数据,快速落盘。同时,通过 producer/consumer 模式,使得 Logstash 能够进行横向扩展,还能用于数据的多路分发。因此,大多数情况下,我们看到的实际架构,按照数据流转的顺序排列,应该是 BKLEK 架构。
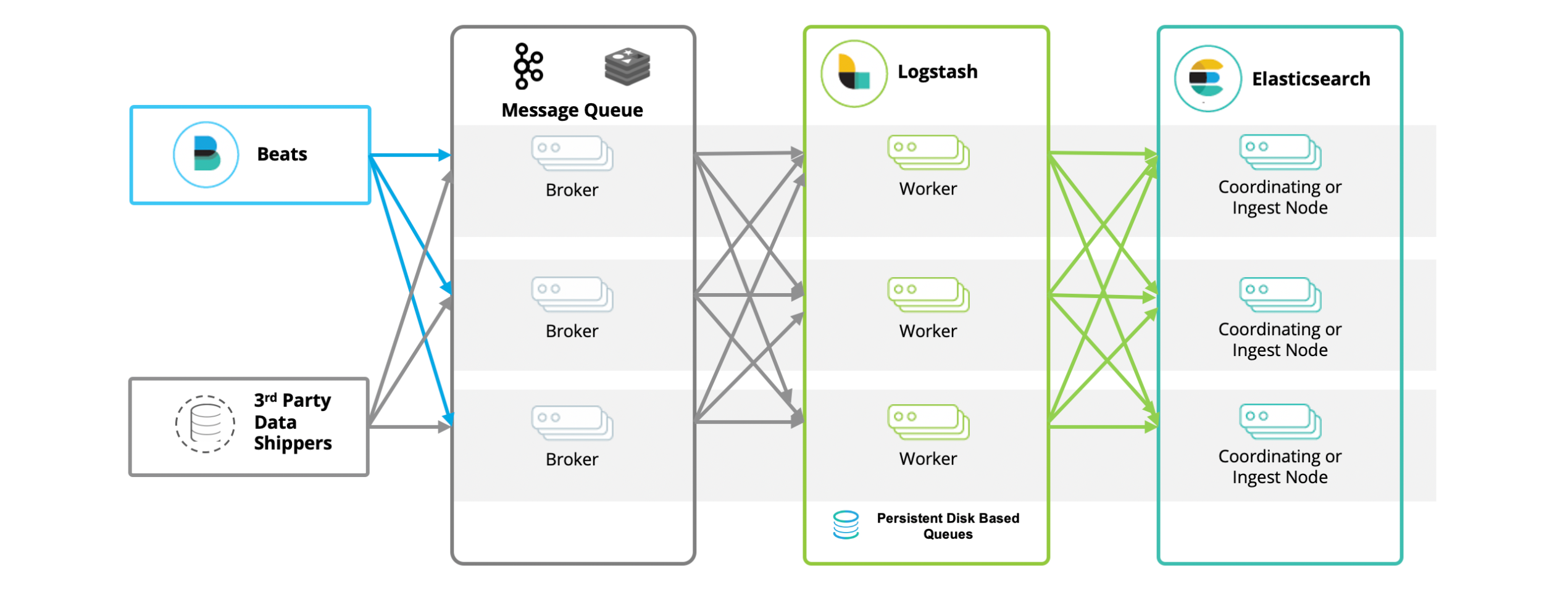
BKLEK 架构即 ELK+Kafka+Beats ,这是一种常见的大数据处理和分析架构。在这个架构中:
-
Beats:是一种轻量级的数据采集器,用于从各种源(如系统日志、网络流量等)收集数据,并将数据发送到 Kafka 或 Logstash。
-
Kafka:是一个分布式流处理平台,用于处理和存储实时数据。在这个架构中,Kafka 主要用于作为一个缓冲区,接收来自 Beats 的数据,并将数据传输到 Logstash。
-
Logstash:是一个强大的日志管理工具,可以从 Kafka 中接收数据,对数据进行过滤和转换,然后将数据发送到 Elasticsearch。
-
Elasticsearch:是一个分布式的搜索和分析引擎,用于存储、搜索和分析大量数据。
-
Kibana:是一个数据可视化工具,用于在 Elasticsearch 中搜索和查看存储的数据。
这种架构的优点是:
- 可以处理大量的实时数据。
- Kafka 提供了一个强大的缓冲区,可以处理高速流入的数据,保证数据的完整性。
- Logstash 提供了强大的数据处理能力,可以对数据进行各种复杂的过滤和转换。
- Elasticsearch 提供了强大的数据搜索和分析能力。
- Kibana 提供了直观的数据可视化界面。
这种架构通常用于日志分析、实时数据处理和分析、系统监控等场景。
2、利用ELK+Kafka+Beats来实现一个统一日志平台
2.1、应用场景
利用 ELK+Kafka+Beats 来实现一个统一日志平台,这是一个专门针对大规模分布式系统日志进行统一采集、存储和分析的 APM 工具。在分布式系统中,众多服务部署在不同的服务器上,一个客户端的请求可能会触发后端多个服务的调用,这些服务可能会互相调用或者一个服务会调用其他服务,最终将请求结果返回并在前端页面上展示。如果在这个过程中的任何环节出现异常,开发和运维人员可能会很难准确地确定问题是由哪个服务调用引起的。统一日志平台的作用就在于追踪每个请求的完整调用链路,收集链路上每个服务的性能和日志数据,从而使开发和运维人员能够快速发现并定位问题。
统一日志平台通过采集模块、传输模块、存储模块、分析模块实现日志数据的统一采集、存储和分析,结构图如下:
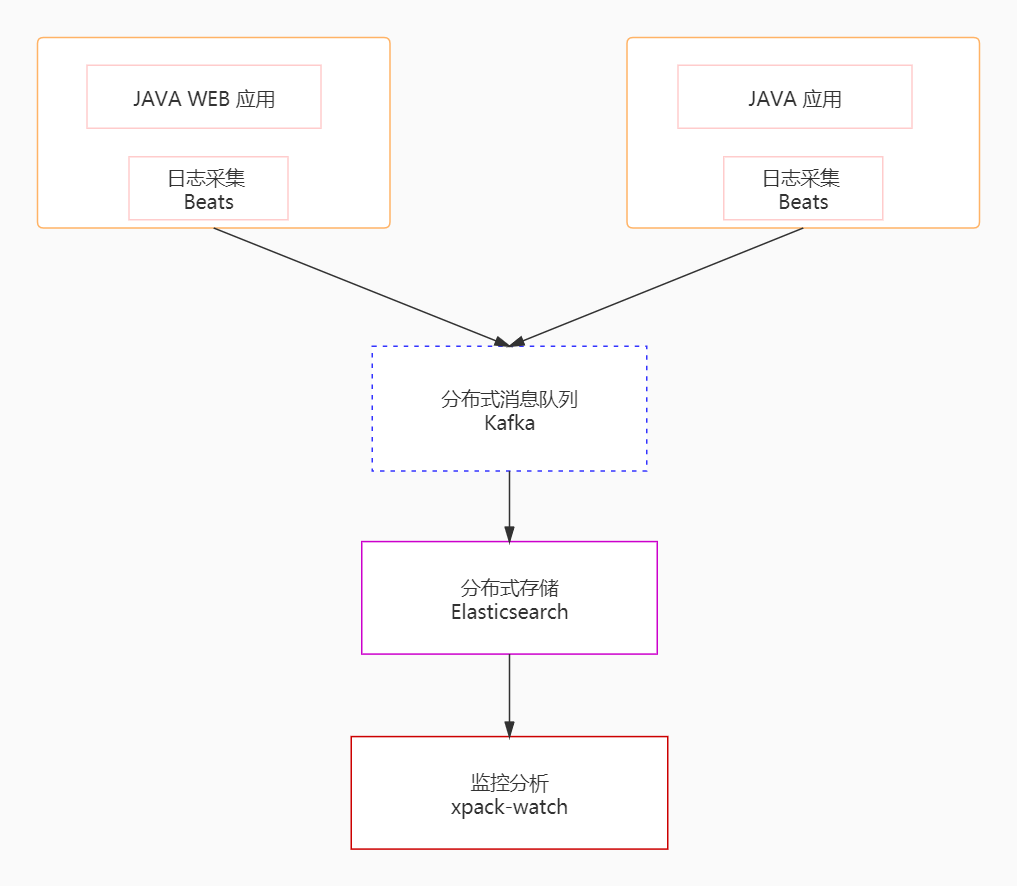
为了实现海量日志数据的收集和分析,首先需要解决的是如何处理大量的数据信息。在这个案例中,我们使用 Kafka、Beats 和 Logstash 构建了一个分布式消息队列平台。具体来说,我们使用 Beats 采集日志数据,这相当于在 Kafka 消息队列中扮演生产者的角色,生成消息并发送到 Kafka。然后,这些日志数据被发送到 Logstash 进行分析和过滤,Logstash 在这里扮演消费者的角色。处理后的数据被存储在 Elasticsearch 中,最后我们使用 Kibana 对日志数据进行可视化展示。
2.2、环境准备
本地
- Kafka
- ES
- Kibana
- filebeat
- Java Demo 项目
我们使用 Docker 创建以一个 名为 es-net 的网络
在 Docker 中,网络是连接和隔离 Docker 容器的方式。当你创建一个网络,我们定义一个可以相互通信的容器的网络环境。
docker network create es-net
docker network create 是 Docker 命令行界面的一个命令,用于创建一个新的网络。在这个命令后面,你需要指定你想要创建的网络的名称,在这个例子中,网络的名称是 “es-net”。
所以,docker network create es-net 这句命令的意思就是创建一个名为 “es-net” 的 Docker 网络。
2.3、基于Docker的ES部署
加载镜像:
docker pull elasticsearch:7.12.1
运行容器:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1-v es-data:/Users/lizhengi/elasticsearch/data \-v es-plugins:/Users/lizhengi/elasticsearch/plugins \
这个命令是使用 Docker 运行一个名为 “es” 的 Elasticsearch 容器。具体参数的含义如下:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name es:设置容器的名称为 “es”。 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置环境变量ES_JAVA_OPTS,这是 JVM 的参数,用于控制 Elasticsearch 使用的最小和最大内存。这里设置的是最小和最大内存都为 512MB。 -
-e "discovery.type=single-node":设置环境变量discovery.type,这是 Elasticsearch 的参数,用于设置集群发现类型。这里设置的是单节点模式。 -
-v es-data:/Users/lizhengi/elasticsearch/data和-v es-plugins:/Users/lizhengi/elasticsearch/plugins:挂载卷(volume)。这两个参数将主机上的es-data和es-plugins目录挂载到容器的/Users/lizhengi/elasticsearch/data和/Users/lizhengi/elasticsearch/plugins目录。 -
--privileged:以特权模式运行容器。这将允许容器访问宿主机的所有设备,并且容器中的进程可以获取任何 AppArmor 或 SELinux 的权限。 -
--network es-net:将容器连接到es-net网络。 -
-p 9200:9200和-p 9300:9300:端口映射。这两个参数将容器的 9200 和 9300 端口映射到主机的 9200 和 9300 端口。 -
elasticsearch:7.12.1:要运行的 Docker 镜像的名称和标签。这里使用的是版本为 7.12.1 的 Elasticsearch 镜像。
运行结果验证:随后便可以去访问 IP:9200,结果如图:
2.4、基于Docker的kibana部署
加载镜像:
docker pull kibana:7.12.1
运行容器:
docker run -d \--name kibana \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=es-net \-p 5601:5601 \
kibana:7.12.1
这是一个 Docker 命令,用于运行一个 Kibana 容器。下面是每个参数的解释:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name kibana:设置容器的名称为 “kibana”。 -
-e ELASTICSEARCH_HOSTS=http://es:9200:设置环境变量ELASTICSEARCH_HOSTS,这是 Kibana 的参数,用于指定 Elasticsearch 服务的地址。这里设置的是http://es:9200,表示 Kibana 将连接到同一 Docker 网络中名为 “es” 的容器的 9200 端口。 -
--network=es-net:将容器连接到es-net网络。 -
-p 5601:5601:端口映射。这个参数将容器的 5601 端口映射到主机的 5601 端口。 -
kibana:7.12.1:要运行的 Docker 镜像的名称和标签。这里使用的是版本为 7.12.1 的 Kibana 镜像。
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

运行结果验证:随后便可以去访问 IP:9200,结果如图:
也可以浏览器访问:
2.5、基于Docker的Zookeeper部署
加载镜像:
docker pull zookeeper:latest
运行容器:
以下是一个基本的 Docker 命令,用于运行一个 Zookeeper 容器:
docker run -d \--name zookeeper \--network=es-net \-p 2181:2181 \
zookeeper:latest
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name zookeeper:设置容器的名称为 “zookeeper”。--network=es-net:将容器连接到es-net网络。-p 2181:2181:端口映射。这个参数将容器的 2181 端口映射到主机的 2181 端口。zookeeper:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Zookeeper 镜像。
2.6、基于Docker的Kafka部署
加载镜像:
docker pull confluentinc/cp-kafka:latest
运行容器:
以下是一个基本的 Docker 命令,用于运行一个 Kafka 容器:
docker run -d \--name kafka \--network=es-net \-p 9092:9092 \-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 \
confluentinc/cp-kafka:latest
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name kafka:设置容器的名称为 “kafka”。--network=es-net:将容器连接到es-net网络。-p 9092:9092:端口映射。这个参数将容器的 9092 端口映射到主机的 9092 端口。-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181:设置环境变量KAFKA_ZOOKEEPER_CONNECT,这是 Kafka 的参数,用于指定 Zookeeper 服务的地址。这里设置的是zookeeper:2181,表示 Kafka 将连接到同一 Docker 网络中名为 “zookeeper” 的容器的 2181 端口。-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092:设置环境变量KAFKA_ADVERTISED_LISTENERS,这是 Kafka 的参数,用于指定 Kafka 服务对外公布的地址和端口。这里设置的是PLAINTEXT://localhost:9092。confluentinc/cp-kafka:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Confluent 平台的 Kafka 镜像。
2.7、基于Docker的Logstash部署
加载镜像:
docker pull docker.elastic.co/logstash/logstash:7.12.1
创建配置文件:
首先,你需要创建一个 Logstash 配置文件,例如 logstash.conf,内容如下:
input {kafka {bootstrap_servers => "kafka:9092"topics => ["logs_topic"]}
}output {elasticsearch {hosts => ["es:9200"]index => "logs_index"}
}
这个配置文件定义了 Logstash 的输入和输出。输入是 Kafka,连接到 kafka:9092,订阅的主题是 your_topic。输出是 Elasticsearch,地址是 es:9200,索引名是 logs_index。
运行容器:
然后,我们使用以下命令运行 Logstash 容器:
docker run -d \--name logstash \--network=es-net \-v /Users/lizhengi/test/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
docker.elastic.co/logstash/logstash:7.12.1
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name logstash:设置容器的名称为 “logstash”。--network=es-net:将容器连接到es-net网络。-v /path/to/your/logstash.conf:/usr/share/logstash/pipeline/logstash.conf:挂载卷(volume)。这个参数将主机上的logstash.conf文件挂载到容器的/usr/share/logstash/pipeline/logstash.conf。docker.elastic.co/logstash/logstash:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Logstash 镜像。
请注意,你需要将 /path/to/your/logstash.conf 替换为你的 logstash.conf 文件所在的实际路径。
2.8、基于Docker的Filebeat部署
加载镜像:
docker pull docker.elastic.co/beats/filebeat:7.12.1
运行容器:
首先,你需要创建一个 Filebeat 配置文件,例如 filebeat.yml,内容如下:
filebeat.inputs:
- type: logenabled: truepaths:- /usr/share/filebeat/logs/*.logoutput.kafka:enabled: truehosts: ["kafka:9092"]topic: "logs_topic"
这个配置文件定义了 Filebeat 的输入和输出。输入是文件 /usr/share/filebeat/Javalog.log,输出是 Kafka,连接到 kafka:9092,主题是 logs_topic。
然后,你可以使用以下命令运行 Filebeat 容器:
docker run -d \--name filebeat \--network=es-net \-v /Users/lizhengi/test/logs:/usr/share/filebeat/logs \-v /Users/lizhengi/test/filebeat.yml:/usr/share/filebeat/filebeat.yml \
docker.elastic.co/beats/filebeat:7.12.1
这个命令的参数解释如下:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name filebeat:设置容器的名称为 “filebeat”。 -
--network=es-net:将容器连接到es-net网络。 -
-v /Users/lizhengi/test/Javalog.log:/usr/share/filebeat/Javalog.log:挂载卷(volume)。这个参数将主机上的/Users/lizhengi/test/Javalog.log文件挂载到容器的/usr/share/filebeat/Javalog.log。 -
-v /path/to/your/filebeat.yml:/usr/share/filebeat/filebeat.yml:挂载卷(volume)。这个参数将主机上的filebeat.yml文件挂载到容器的/usr/share/filebeat/filebeat.yml。 -
docker.elastic.co/beats/filebeat:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Filebeat 镜像。
请注意,你需要将 /path/to/your/filebeat.yml 替换为你的 filebeat.yml 文件所在的实际路径。
相关文章:
Elasticsearch实践:ELK+Kafka+Beats对日志收集平台的实现
可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等…...

离线语音与IoT结合:智能家居发展新增长点
离线语音控制和物联网(IoT)相结合在家居中具有广泛的应用和许多优势。离线语音控制是指在设备在本地进行语音识别和处理,而不需要依赖云服务器进行处理。IoT是指借助网络,通过手机APP、小程序远程控制家居设备。 启英泰伦基于AI语…...

STM32MP135和STM32MP157的区别
本文介绍了STMicroelectronics公司推出的两款多核处理器STM32MP135和STM32MP157之间的区别,包括主频、集成硬件模块数量、内存大小和电压调节模块等方面。 STMicroelectronics是一家领先的半导体解决方案提供商,在嵌入式系统领域有着丰富的经验。他们…...

微信小程序文本横向无缝滚动
背景: 微信小程序中列表宽度不够长,其中某字段显示不完整,因此要使其自动滚动。 (最初看网上很多用定时器实现,但他们的案例中都只是一个横幅、用定时器也无所谓。但是我的需求中是一个上下无限滚动的列表,…...
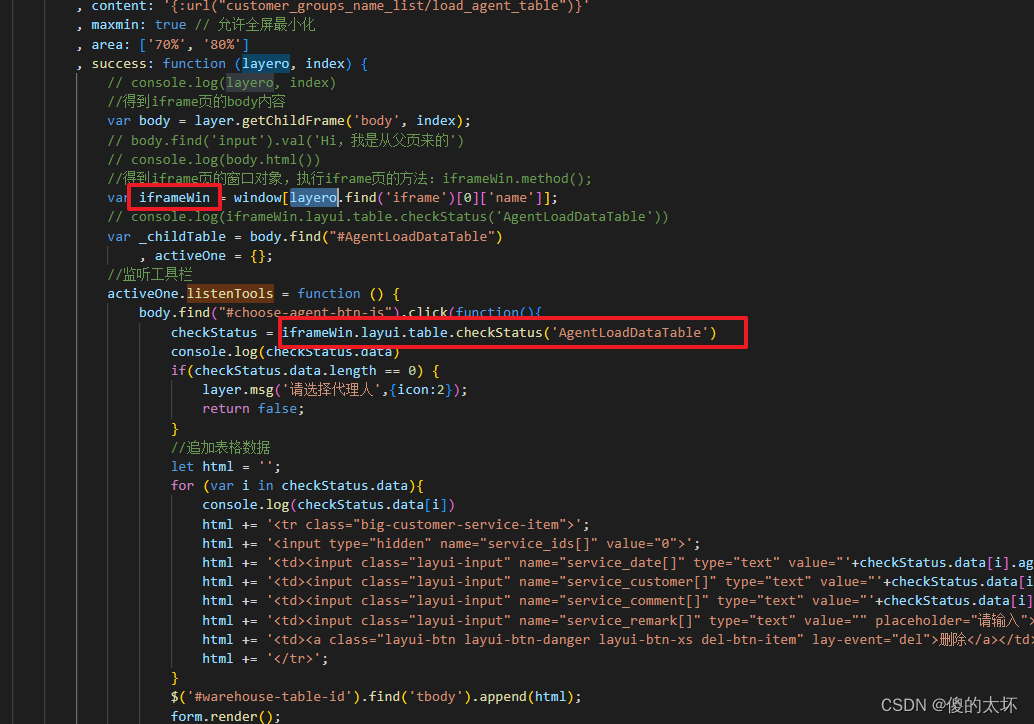
Layui 主窗口调用 iframe 弹出框模块,获取控件的相应值
var iframeWindow window[layui-layer-iframe index]; iframeWindow.layui.tree............(这里就可以操作tree里面的内容了)。var chrild layero.find(iframe).contents(); chrild.layui.tree (这样是调用不到的)。var child layer.getChildFrame(); child.layui.tree(这…...

镜头边缘的解析力通常比中心差很多的原因是什么?
1、问题背景 之前有总结过一篇文章,“ 相机出图画面一半清晰,一半模糊的原因是什么?”里面有描述到关于镜头边缘的清晰度通常比中心要差的原因主要是光的折射导致的,有读者指出问题,折射率是和传输介质相关࿰…...

“控制情绪,理性交流”刍议
今天,本“人民体验官”还是回避推广人民日报官方微博文化产品《走出低谷期的9个习惯》。 截图:来源“人民体验官”推广平台 之前,由于笔者读过《人民日报》曾经发表过的关于“学会管理情绪 ”的文章,对文章中这些观点深表认同&…...

UI基础之插画分类优漫动游
一、UI插画分类 UI基础之插画分类 1.扁平插画 优点∶快速上手,同时画风简洁明了,突出重 点,能够快速的让用户了解内容 缺点:过于简洁,运用的也比较普遍,视觉上难以让用户记住 2.肌理插…...

Vue 3.0中Treeshaking特性是什么?
一、是什么 Tree shaking 是一种通过清除多余代码方式来优化项目打包体积的技术,专业术语叫 Dead code elimination 简单来讲,就是在保持代码运行结果不变的前提下,去除无用的代码 如果把代码打包比作制作蛋糕,传统的方式是把鸡…...

SQL union all的使用
背景: 公司业务开发需要将两个取出两个相同表结构(原料、辅料)的数据,组成一个新视图,使用了UNION ALL SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GOCREATE view vw_rawmaterial_ny_list as ( select id,ccode,cc…...

docker 安装 Centos7
1. 从docker 安装 Centos7 查看有哪些 centos7 系统:docker search centos72. 安装 centos7 docker pull docker.io/ansible/centos7-ansible3.使用镜像创建容器 docker run -itd -p 8022:22 --namevm01 -v /bodata:/bodata -h vm01 --privilegedtrue 688353a31…...

Kubernetes技术与架构-Ingress
Ingress是一个流量网关,其根据配置的URI路径路由规则,为运行在Kubernetes集群中的Service分发流量,从系统架构设计的角度看,Ingress位于Service的上层,本文主要描述Ingress的基本使用方式。 如上所示,clien…...
基于Java的文物管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding) 代码参考数据库参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者&am…...

uniapp图片加水印
1、uniapp加水印 1.1、创建画布容器 <canvas class"watermark-canvas" id"watermark-canvas" canvas-id"watermark-canvas":style"{ width: canvasWidth, height: canvasHeight }" /> 1.2、获取水印内容 async getLocation(…...
react中JSX基础与useState的基本使用 + 评论显示删除需求案例
参考视频:https://www.bilibili.com/video/BV1ZB4y1Z7o8/?p3&spm_id_frompageDriver&vd_source5c584bd3b474d579d0bbbffdf0437c70 如果没有安装create-react-app需要先全局安装 命令:npm i -g create-react-app1.快速搭建开发环境 create-re…...
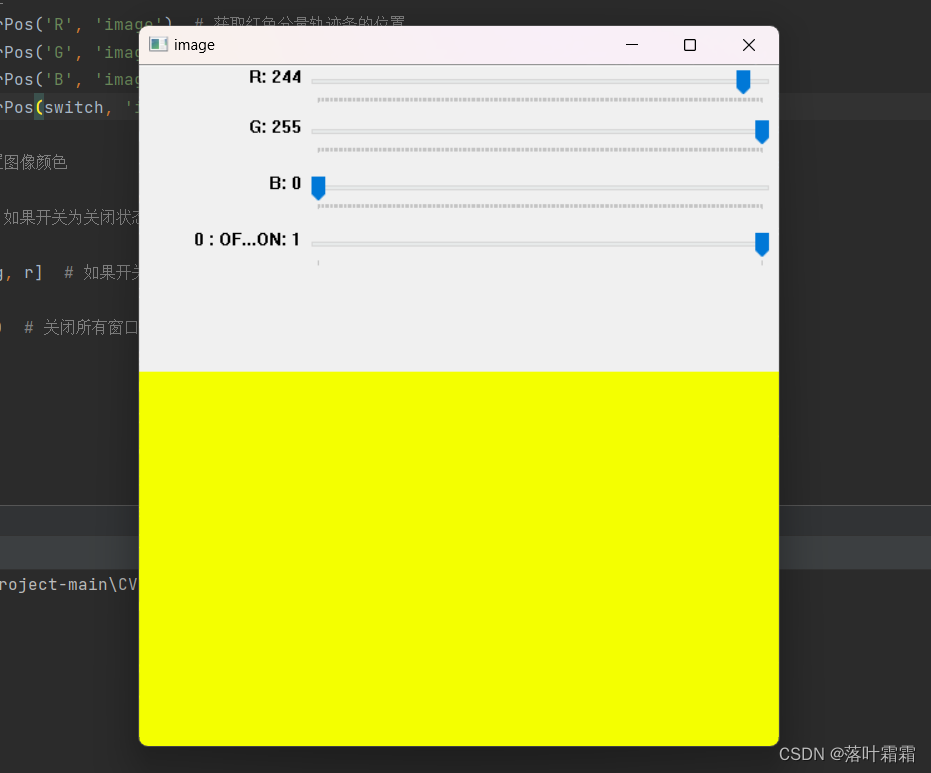
【OpenCV实现鼠标绘图,轨迹栏做调色板,图像的基本操作】
文章目录 鼠标绘图轨迹栏做调色板图像的基本操作 鼠标绘图 在OpenCV中操作鼠标事件 函数:cv.setMouseCallback() 目的是在鼠标双击的地方画一个圆。首先,我们需要创建一个鼠标回调函数,该函数会在鼠标事件发生时执行。鼠标事件包括左键按下…...

2023年中国自动排气阀产业链、市场规模及存在问题分析]图[
自动排气阀是一种用于排除管道、容器或设备中累积的空气或气体的装置。在液体流动系统中,气体或空气可能会积聚在管道或容器中,影响流体流动、导致气锁和能效降低。自动排气阀的作用是在系统中的气体达到一定压力时,自动地释放气体࿰…...
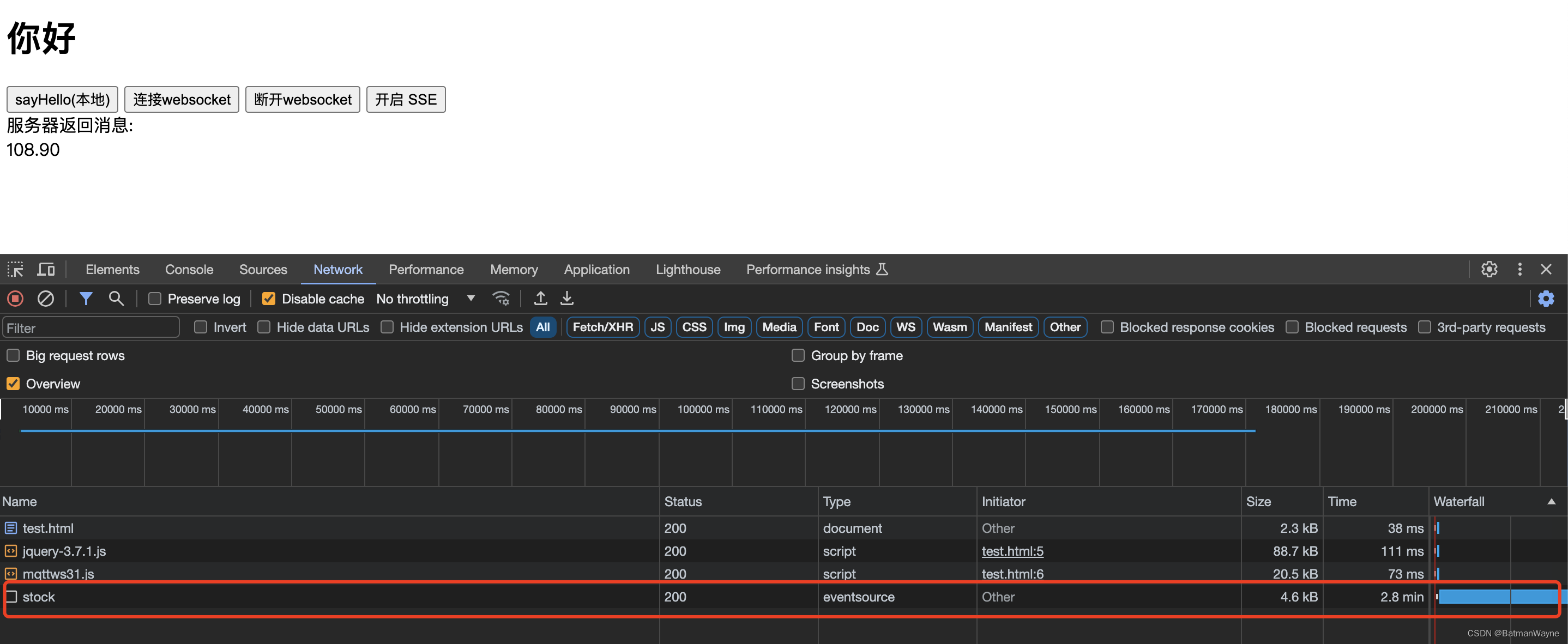
服务器往浏览器推消息(SSE)应用
1,SSE 和 WebSocket 对比 SSE(服务器发送事件) SSE是一种基于HTTP的单向通信机制,用于服务器向客户端推送数据。它的工作原理如下: 建立连接:客户端通过发送HTTP请求与服务器建立连接。在请求中ÿ…...

Choreographer
系统面试的时候常会遇到,比如它是什么,是用来做什么用的。或许我们大概清楚,但不一定能表达清楚。 在Android框架中,Choreographer(舞台监督)是一个用于管理和协调UI线程上的动画和绘制操作的系统组…...
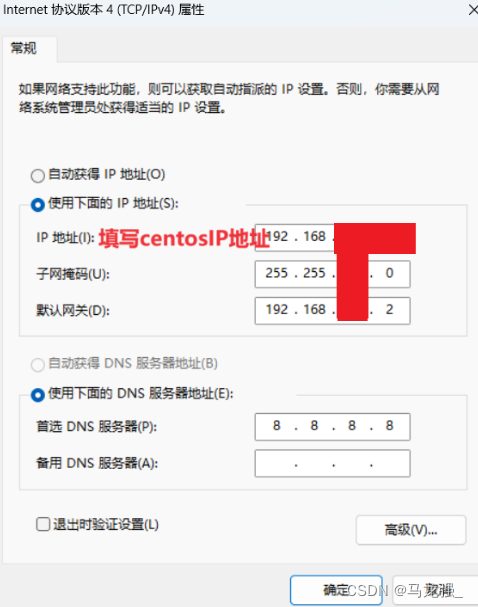
CentOS有IP地址,连接不上Xshell或使用Xshell时突然断开
问题原因:未在电脑主机的网络中进行IP地址配置 解决办法: 1.打开控制面板,选择‘网络与共享中心’ 2.选择“更改适配器设置” 3.右键点击以太网3“属性” 4.选择协议版本4,点击属性 5.IP地址填写CentOS的IP地址:192.…...

PVC卡企业
在当今数字化与智能化飞速发展的时代,PVC卡以其广泛的应用场景和独特优势,成为了众多领域不可或缺的重要工具。无论是企业的门禁系统、商场的会员卡,还是交通领域的乘车卡,PVC卡都发挥着重要作用。然而,市场上PVC卡企业…...

为什么选择QFT:重新定义点对点文件传输的架构范式
为什么选择QFT:重新定义点对点文件传输的架构范式 【免费下载链接】qft Quick Peer-To-Peer UDP file transfer 项目地址: https://gitcode.com/gh_mirrors/qf/qft 在分布式系统架构中,点对点文件传输一直是技术实现的核心挑战。传统方案要么依赖…...

DDrawCompat:让经典Windows游戏在现代系统上完美运行的终极兼容方案
DDrawCompat:让经典Windows游戏在现代系统上完美运行的终极兼容方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirr…...

如何快速掌握农历计算?lunar-javascript终极指南
如何快速掌握农历计算?lunar-javascript终极指南 【免费下载链接】lunar-javascript 日历、公历(阳历)、农历(阴历、老黄历)、佛历、道历,支持节假日、星座、儒略日、干支、生肖、节气、节日、彭祖百忌、每日宜忌、吉神宜趋凶煞宜忌、吉神(喜神/福神/财神…...

基于Java+Spring Boot的在线客服系统源码,实时数据统计管理后台,高效对话处理功能...
Java在线客服系统源码 企业网站客服聊天源码 网页客服源码开发环境:Java Spring boot mysql 通信技术:netty框架后台管理首页-工作绩效(会话、邀请、拒绝、已接待、平均会话时长)统计首页-在线客服业务概况(访客&am…...
)
把Snort当“网络监控摄像头”:5分钟教你用嗅探模式分析本地网络流量(Windows实操)
用Snort打造你的网络流量监控台:Windows实战指南 每次看到网络监控设备上闪烁的指示灯,总让我想起城市路口的交通摄像头——它们无声地记录着每一辆车的通行状态。而在数字世界里,Snort就是这样一个"网络监控摄像头",它…...

15分钟搞定Ncorr 2D数字图像相关软件:材料力学位移测量的终极指南
15分钟搞定Ncorr 2D数字图像相关软件:材料力学位移测量的终极指南 【免费下载链接】ncorr_2D_matlab 2D Digital Image Correlation Matlab Software 项目地址: https://gitcode.com/gh_mirrors/nc/ncorr_2D_matlab 还在为复杂的数字图像相关软件安装而烦恼吗…...

高校…实验室环境应用lims实验动物中心智能化管理系统设计建设哪个好?
不同行业类型的智慧实验室系统哪个好?建设与设计一套专属于自己的lims,是增强实验室各方面能力的有效方式,其中盛元广通实验动物中心智能化管理系统是当前先进AI与大数据融合物联网的合规化管控平台,应用于高校实验室管理系统分类…...

别再只用@keydown.enter了!盘点Vue表单交互中回车键监听的5个实用场景与避坑点
Vue表单交互中回车键的高级应用:5个实战场景与深度优化 在Web应用开发中,表单交互占据了用户操作的重要部分。虽然大多数开发者都熟悉基础的keydown.enter用法,但回车键在不同场景下的精细控制往往能显著提升用户体验。本文将深入探讨五个典型…...

Vue+SpringBoot项目实战:如何把Kettle引擎‘搬’到浏览器里运行?
VueSpringBoot全栈实战:浏览器端Kettle引擎的架构设计与实现 技术选型背后的思考 当我们决定将Kettle这样的传统桌面应用引擎迁移到浏览器环境时,技术栈的选择直接决定了项目的可维护性和扩展性。VueSpringBoot的组合在这个场景下展现出独特的优势&…...