MySQL的索引——索引的介绍及其数据结构B+树 索引的类型 索引的使用及其失效场景 相关名词解释
前言
索引是存储引擎用于快速查找数据纪录的一种数据结构,索引是数据库中经常提及的一个词,究竟什么是索引,索引的数据结构是什么,索引有什么类型?
本篇博客尝试阐述数据库索引的相关内容,涉及什么是索引,索引的数据结构;对比了聚集索引和非聚集索引,分析了索引的类型以及使用原则,对于MySQL中关于索引的技术名词进行了解释。
本系列文章合集如下:
【合集】MySQL的入门进阶强化——从 普通人 到 超级赛亚人 的 华丽转身
目录
- 前言
- 引出
- 一、索引介绍
- 1、什么是索引
- 2、索引的优缺点
- 二、索引的数据结构
- 1、MySQL索引的数据结构
- 2、二叉查找树
- 3、平衡二叉树
- 4、B树
- 5、B+树
- 三、聚集索引与非聚集索引
- 1、聚集索引(聚簇索引)
- 2、非聚集索引(非聚簇索引)
- 3、利用聚集索引查找数据
- 4、利用非聚集索引查找数据
- 四、索引的类型
- 1、主键索引
- 2、唯一索引
- 3、组合索引
- 五、索引的使用原则
- 1、什么情况下不建索引
- 2、索引失效场景
- 六、MySQL技术名词
- 1、回表
- 2、索引覆盖
- 3、最左匹配
- 4、索引下推
- 总结
引出
1.索引是存储引擎用于快速查找数据纪录的一种数据结构;
2.索引的数据结构,B+树;
3.主键作为B+树索引的键值称为聚集索引;以主键以外的列值作为键值构建的B+树索引称为非聚集索引;
4.索引不满足左前缀,select *,or分割的条件,order by 非主键;
5.%开头的Like模糊查询–> 解决:select和where条件中的字段都出现在索引;
6.回表,先查到主键,再通过主键查数据,查了B+树两次;
7.索引覆盖:输出的列就是索引列,无需回表;
一、索引介绍
1、什么是索引
索引是存储引擎用于快速查找数据纪录的一种数据结构。
- 最典型的例子就是查新华字典,通过查找目录快速定位到要查找的字。
- 数据是存储在磁盘上的,查询数据时,如果没有索引,会加载所有的数据到内存,依次进行检索,读取磁盘次数较多。
- 使用索引,就不需要加载所有数据,MySQL是以B+数的数据结构存储索引,B+树的高度一般在2-4层,最多只需要读取2-4次磁盘,查询速度大大提升。
2、索引的优缺点
(1)优点
- 避免进行数据库全表的扫描,大多数情况,只需要扫描较少的索引页和数据页,提升查询语句的执行效率
- 在使用分组和排序语句进行数据检索时,可以显著减少查询中分组和排序的时间
- 多表连接查询,提高从其他表检测行数据的性能
- 如果表具有多列索引,则优化器可以使用索引的最左匹配前缀来查找,提升数据检索的性能
(2)缺点
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引
二、索引的数据结构
1、MySQL索引的数据结构
MySQL索引常见的数据存储结构有哈希结构,B+树结构,R树结构。其中R树结构用于空间索引,不常见。
要介绍B+树索引,就不得不提二叉查找树,平衡二叉树和B树这三种数据结构。B+树就是在此基础上演化而来的。
2、二叉查找树
首先,让我们先看一张图
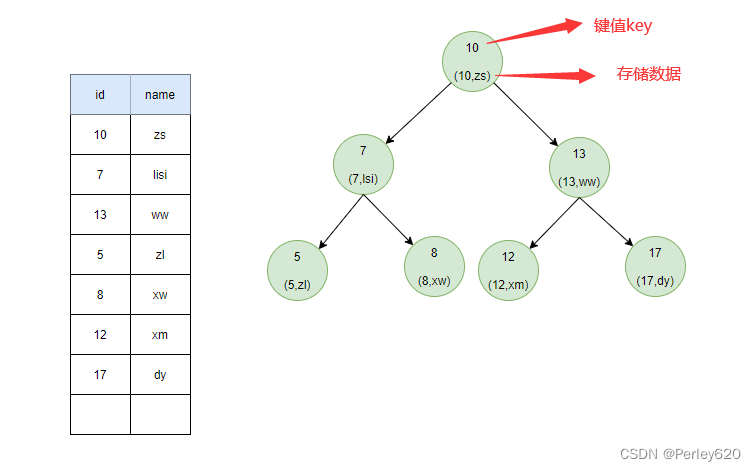
从图中可以看到,我们为user表(用户信息表)建立了一个二叉查找树的索引。图中的圆为二叉查找树的节点,节点中存储了键(key)和数据(data)。键对应user表中的id,数据对应user表中的行数据。
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。 顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
二叉查找树的演示动画图解,可通过如下网址进行操作演示:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
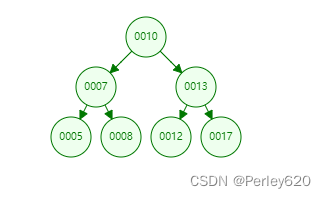
如果我们需要查找id=12的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
- 将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来把比当前节点大的右子节点作为当前节点。
- 继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。
- 把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data,即id=12,name=xm。
利用二叉查找树我们只需要3次即可找到匹配的数据。如果在表中一条条的查找的话,我们需要6次才能找到。
3、平衡二叉树
上面我们讲解了利用二叉查找树可以快速的找到数据。但是,如果上面的二叉查找树是这样的构造:

这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找id=17的用户信息,我们需要查找7次,也就相当于全表扫描了。导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。
为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。
平衡二叉树又称AVL树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过1。
平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。
4、B树
(1)因为内存的易失性。一般情况下,我们都会选择将user表中的数据和索引存储在磁盘这种外围设备中。如果我们采用平衡二叉树这种数据结构作为索引的数据结构,每查找一次数据就需要从磁盘中读取一个节点,即我们说的一个磁盘块。平衡二叉树每个节点只存储一个键值和数据,也就是说每个磁盘块仅仅存储一个键值和数据。如果要存储海量的数据,二叉树的节点将会非常多,高度也会很高,查找数据时就会进行很多次磁盘IO,查找数据的效率降低。
(2)为了解决平衡二叉树的这个弊端,我们应该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的B树。
(3)B树(Balance Tree)即为平衡树的意思,下图即是一颗B树。
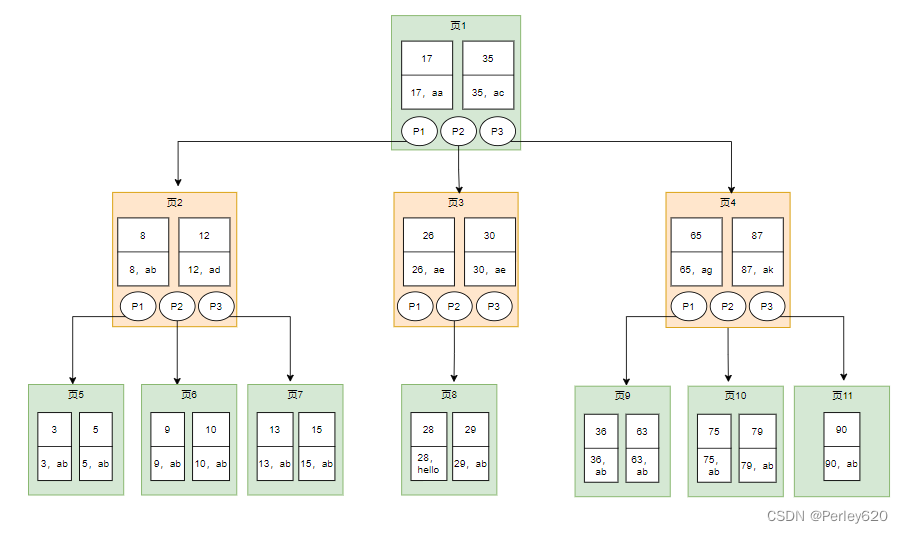
- 图中的p节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,图中的每个节点称为页,页就是我们上面说的磁盘块,在mysql中数据读取的基本单位都是页。
- 从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。
- 基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
(4)假如我们要查找id=28的用户信息,那么我们在上图B树中查找的流程如下:
- 先找到根节点也就是页1,判断28在键值17和35之间,我们那么我们根据页1中的指针p2找到页3。
- 将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8。
- 将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为 (28,hello)
5、B+树
B+树是对B树的进一步优化。让我们先来看下B+树的结构图:
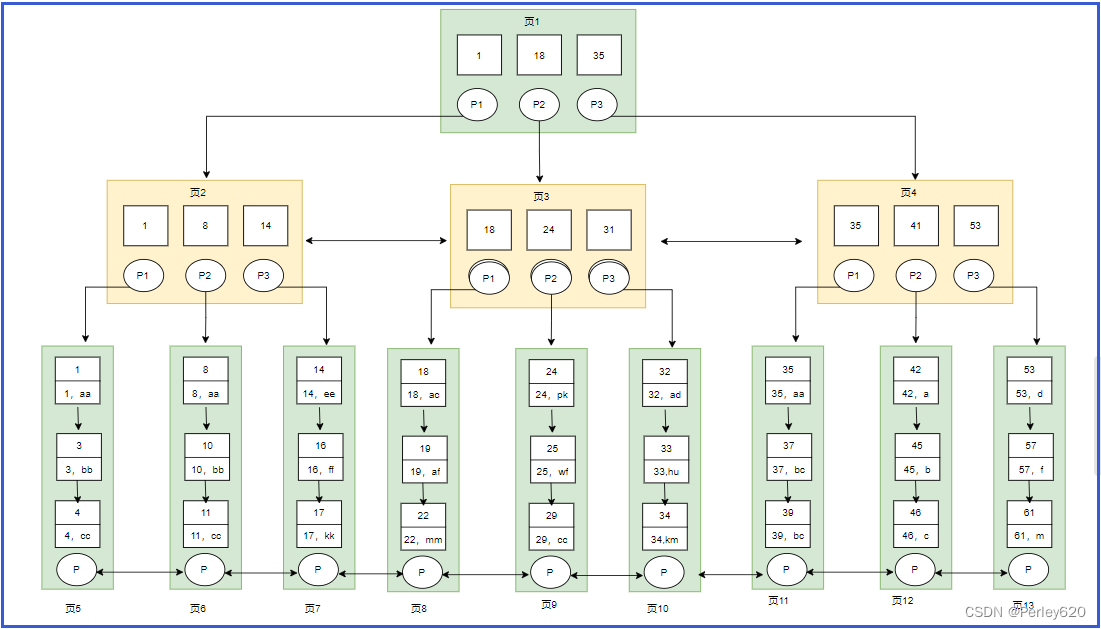
(1)B+树非叶子节点上是不存储数据的,仅存储键值,这么做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少。
(2)B+树的阶数是等于键值的数量,如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO。
(3)因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得非常简单。
(4)B+树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。上图中的B+树索引就是innodb中B+树索引的实现方式,准确的说应该是聚集索引,在MyISAM中,B+树索引的叶子节点并不存储数据,而是存储数据的文件地址。
三、聚集索引与非聚集索引
在MySQL中,B+树索引按照存储方式的不同分为聚集索引和非聚集索引
1、聚集索引(聚簇索引)
以innodb作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为innodb是把数据存放在B+树中的,而B+树的键值就是主键,在B+树的叶子节点中存储了行数据,可以直接在聚集索引中查找到想要的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。
2、非聚集索引(非聚簇索引)
(1)以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。
(2)非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
(3)如果使用了覆盖索引,则不需要回表,直接通过辅助索引就可以查找到想要的数据。覆盖索引就是指select查询的数据只需要在索引中就能取得,而不必读取数据行,换句话说就是,查询列要被所建的索引覆盖。
3、利用聚集索引查找数据
查找id>=18并且id<40的用户数据。对应的sql语句为select * from user where id>=18 and id <40,其中id为主键。具体的查找过程如下:
(1)根节点是常驻内存的,也就是说页1已经在内存中了,此时不需要到磁盘中读取数据,直接从内存中读取即可。从内存中读取到页1,要查找这个id>=18 and id <40或者范围值,我们首先需要找到id=18的键值。从页1中我们可以找到键值18,此时我们需要根据指针p2,定位到页3。
(2)要从页3中查找数据,我们就需要拿着p2指针去磁盘中进行读取页3。从磁盘中读取页3后将页3放入内存中,然后进行查找,我们可以找到键值18,然后再拿到页3中的指针p1,定位到页8。
(3)同样的页8页不在内存中,我们需要再去磁盘中将页8读取到内存中。将页8读取到内存中后。因为页中的数据是链表进行连接的,而且键值是按照顺序存放的,此时可以根据二分查找法定位到键值18。
(4)因为是范围查找,而且此时所有的数据又都存在叶子节点,并且是有序排列的,那么我们就可以对页8中的键值依次进行遍历查找并匹配满足条件的数据。我们可以一直找到键值为22的数据,然后页8中就没有数据了,此时我们需要拿着页8中的p指针去读取页9中的数据。因为页9不在内存中,就又会加载页9到内存中,并通过和页8中一样的方式进行数据的查找,直到将页12加载到内存中,发现41大于40,此时不满足条件。那么查找到此终止。
4、利用非聚集索引查找数据
(1)非聚集索引叶子节点中,不再存储所有的数据,存储的是键值和主键。非聚集索引也称之为辅助索引(普通索引、二级索引),一个表中只有一个聚集索引可以有多个非聚集索引。
(2)辅助索引的搜索过程:
- 比如我们给name字段建立索引,InnoDB 都会给每个加了索引的字段生成索引树,此时会建立name字段的索引B+树,节点中存储的是name索引字段的数据,叶子节点中存储了索引字段的数据和主键的值。
- 拿到主键 KEY 后,InnoDB 才会去主键索引树里根据刚在name 索引树找到的主键 KEY 查找到对应的数据。【两次查询,回表操作】
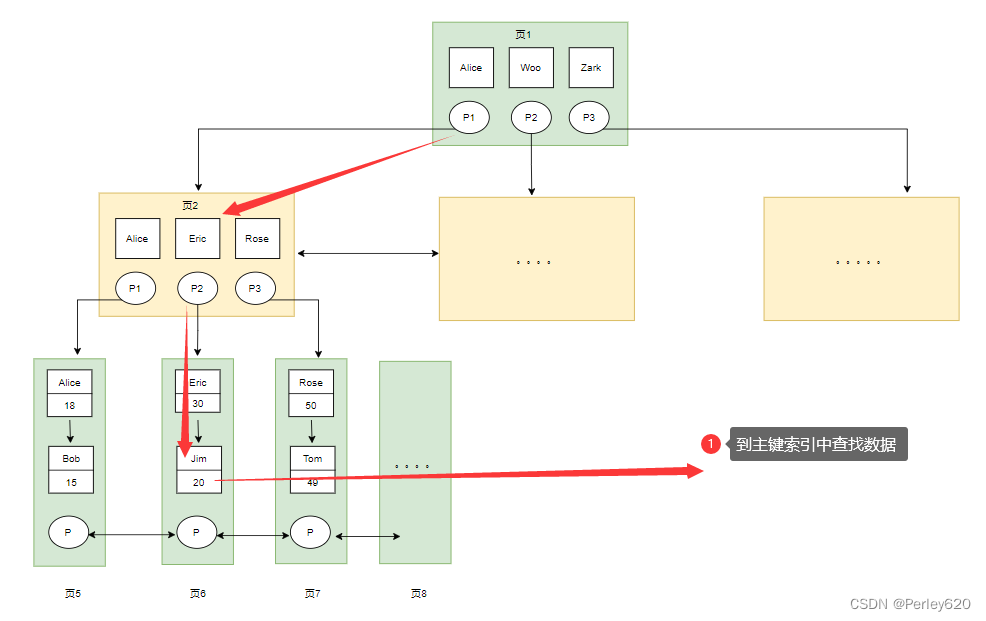
(3)执行select * from user where name = ‘jim’ 的执行过程
- 根节点是常驻内存的,也就是说页1已经在内存中了,从内存中读取到页1,根据指针P1定位到页2
- 根据页2中的P2指针定位到页6
- 比较找到索引对应的值为jim,同时获取到主键为20
- 在根据20这个主键到主键索引中获取到这个叶子节点中存储的行数据。
四、索引的类型
1、主键索引
- 在创建表的时候,添加了主键PRIMARY KEY 的字段,会在该字段上默认创建主键索引。
创建表employee:
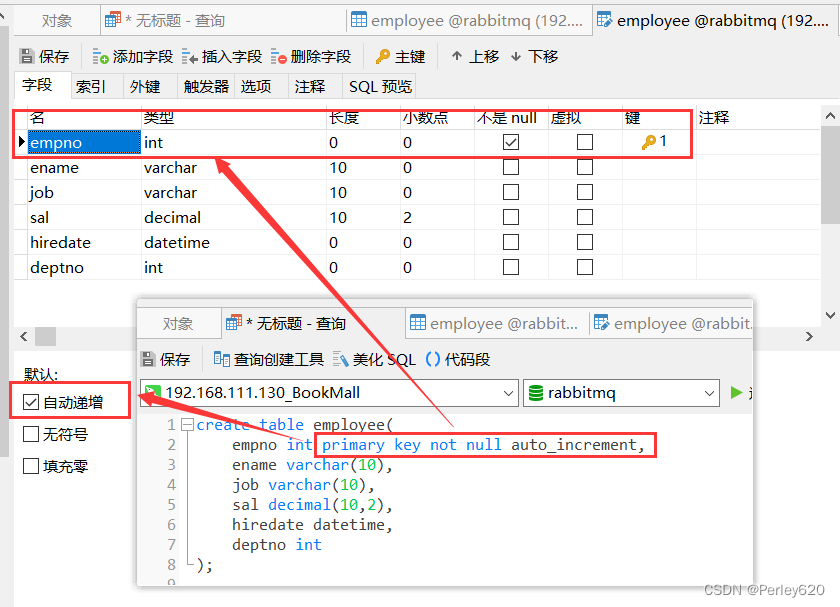
create table employee(empno int primary key not null auto_increment,ename varchar(10),job varchar(10),sal decimal(10,2),hiredate datetime,deptno int
);
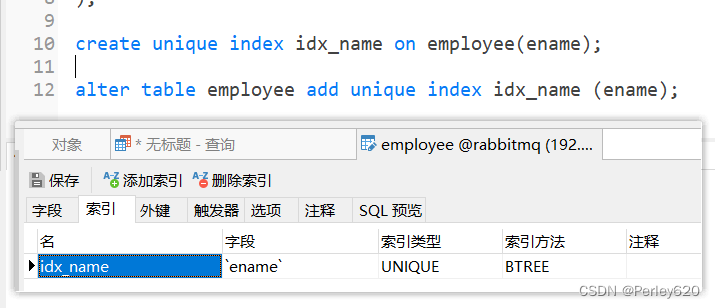
2、唯一索引
- 唯一索引,索引列的值必须唯一
- 唯一索引和主键索引的区别就是,唯一索引允许出现空值,而主键索引不能为空
-- 创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))-- 修改表结构的方式创建索引
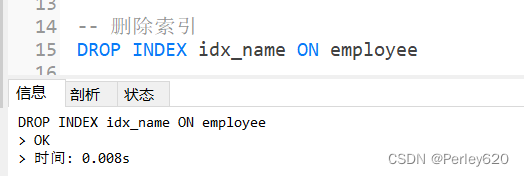
ALTER TABLE table_name ADD UNIQUE index indexName (column(length))-- 删除索引
DROP INDEX index_name ON table
创建索引
删除索引
create table employee(empno int primary key not null auto_increment,ename varchar(10),job varchar(10),sal decimal(10,2),hiredate datetime,deptno int
);create unique index idx_name on employee(ename);alter table employee add unique index idx_name (ename);-- 删除索引
DROP INDEX idx_name ON employee
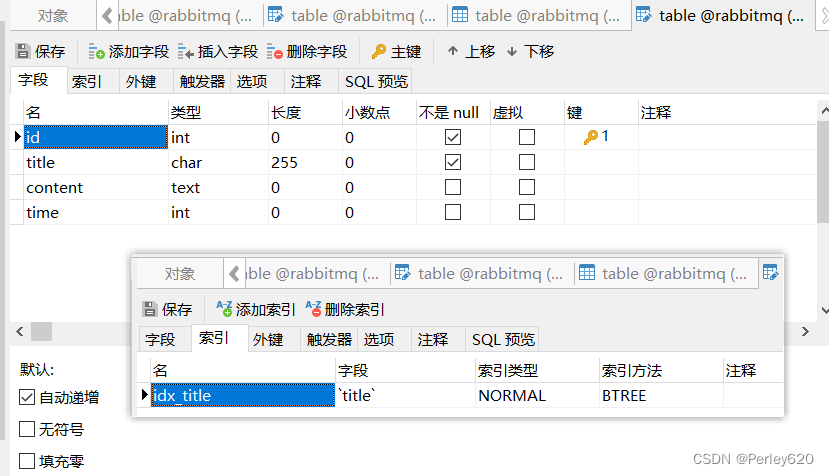
-- 创建表的时候同时创建索引
CREATE TABLE `table` (`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,`title` CHAR ( 255 ) NOT NULL,`content` text NULL,`time` INT ( 10 ) NULL DEFAULT NULL,PRIMARY KEY ( `id` ),index idx_title (title)
);
3、组合索引
- 在多个列上创建的索引,就是组合索引。
alter table t add index index_name(a,b,c);
示例:
alter table employee add index idx_name_job_sal(ename,job,sal);
- 组合索引的用处,假设我现在表有个多个字段:id、name、age、gender,然后我经常使用以下的查询条件
select * from user where name = 'xx' and age = xx
这个时候,我们就可以通过组合 name 和 age 来建立一个组合索引,加快查询效率。
- 在多个字段上创建索引,遵循最左匹配原则。
五、索引的使用原则
1、什么情况下不建索引
- 表记录太少
- 区分度不高的字段不适合建立索引,如性别等
- where条件中用不到的字段不适合建立索引
- 经常插入、删除、修改的表要减少索引
- text,image 等类型不适合建立索引。
- MySQL能估计出全表扫描比使用索引更快的时候,不使用索引
- 参与列计算的列不适合建索引
2、索引失效场景
(1)不满足最左前缀
所谓最左前缀,可以想象成依次执行的过程,假设我们有一个复合索引【ename,sal,job】,那这个依次顺序是:ename,sal,job。
create index idx_ename_job_sal on employee(ename,sal,job)
- 以下sql会走索引
select * from employee where ename='zs' and sal=1000 and job='sales'
- 最左前缀,出现跳跃的情况,会导致索引失效。
select * from employee where job='sales'
select * from employee where job='sales' and sal>1000
- 出现跳跃的情况,满足最左前缀会走索引
select * from employee where ename='zs' and sal>1000
select * from employee where ename='zs' and job='sales'
select * from employee where sal>1000 and ename='zs' -- 内部优化器会进行调整
(2)范围查询之后
范围查询之后的索引字段,会失效,但本身用来范围查询的那个索引字段依然有效。
以下示例,job列的索引失效,通过长度可以看出。
select * from employee where ename='zs' and sal>1000 and job='sales'
(3)索引字段做运算
对索引字段做运算,使用函数等都会导致索引失效。
select * from employee where substring(ename,2,3)='aa';
(4)隐式类型转换
索引字段为字符串类型,由于在查询时,没有对字符串加单引号,MySQL的查询优化器,会自动的进行类型转换,造成索引失效。
select * from employee where ename=11
(5)避免使用select *
无法使用覆盖索引,消耗更多的 CPU 和 IO 以网络带宽资源。
(6)or分割的条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
select * from employee where ename='zs' or deptno=20
(7) 以%开头的Like模糊查询
解决方法:使用覆盖索引
如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。(即select和where条件中的字段都出现在索引中,即为覆盖索引)
select ename from employee where ename like '%A%'
(8)order by导致索引失效
在基于order by和limit进行使用时,是否走索引涉及到数据库版本。
主键使用order by时,可以正常走索引。
六、MySQL技术名词
1、回表
首先我们需要知道,建立几个索引,就会生成几棵B+Tree,但是带有原始数据行的B+Tree只有一棵,另外一棵树上的叶子节点存储的是主键值。
例如,我们通过主键建立了主键索引,在叶子节点上存放的是行数据。
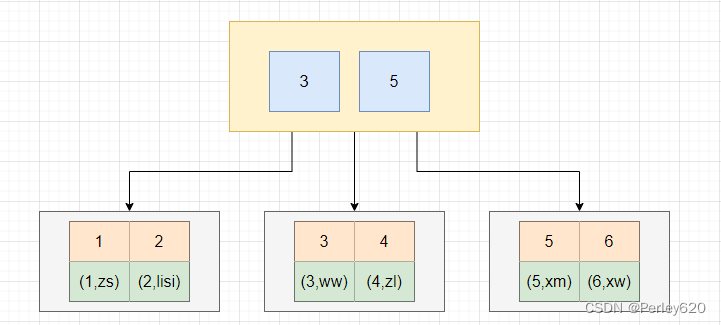
当我们创建了两个索引时,一个是主键,一个是name,此时会在生成两棵B+Tree。name索引这棵树的叶子节点存放的是name列的值和主键值,当我们通过name进行查找数据时,会得到一个主键,然后在通过主键再去上面的这个主键B+Tree中进行查找数据,这个操作称之为回表
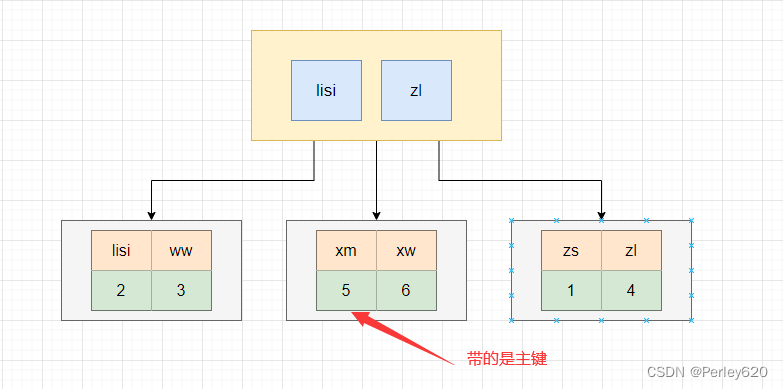
当执行下面的SQL语句时,会查找第一颗树,直接返回数据。
select * from tb where id = 1
当执行下面的SQL查询时,会先查找第二棵树得到主键的值,然后根据主键的值再去主键索引的B+Tree中查找数据。
select * from tb where name = 'xm'
2、索引覆盖
我们看下面的两个SQL语句,看看它们的查询过程是一样的么?
select * from tb where id = 1
select name from tb where name = 'zs'
答案是不一样的,首先我们看第二个语句,输出的列就是索引列。当我们通过name建立的B+Tree进行查询时,此时叶子节点就已经包含要查找的name数据,无需再到主键索引B+Tree上进行数据查找,这样的查询称之为索引覆盖。索引覆盖不需要进行回表查询,大大提示性能。
3、最左匹配
这里提到的 最左匹配 和 索引下推 都是针对于组合索引的。
例如,我们有这样一个索引
name age:组合索引`
必须要先匹配name,才能匹配到age。这个我们就被称为最左匹配。
例如下面的几条SQL语句,那些语句不会使用组合索引?
where name = ? and age = ?
where name = ?
where age = ?
where age = ? and name = ?
根据最左匹配原则,第 3条SQL 不会使用组合索引。
那为什么4的顺序不一样,也会使用组合索引呢?
其实内部的优化器会进行调整,例如下面的一个连表操作
select * from tb1 join tb2 on tb1.id = tb2.id
其实在加载表的时候,并不一定是先加载tb1,在加载tb2,而是根据表的大小决定的,小的表优先加载进内存中。
4、索引下推
索引下推(index condition pushdown )简称ICP,意思是解析索引列找到符合条件的数据。
在Mysql5.6的版本上推出,用于优化查询。索引下推在非主键索引上的优化,可以有效减少回表的次数,大大提升了查询的效率。
- 先使用where条件过滤索引
- 过滤完索引后找到所有符合索引条件的数据行,然后用 WHERE 子句中的其他条件去过滤这些数据行。
创建表:
create table student(id int not null auto_increment,name varchar(10),age int,sex char(1),address varchar(20),primary key(id),key idx_name_age (name,age)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8explain select * from student where name like '王%' and age=20
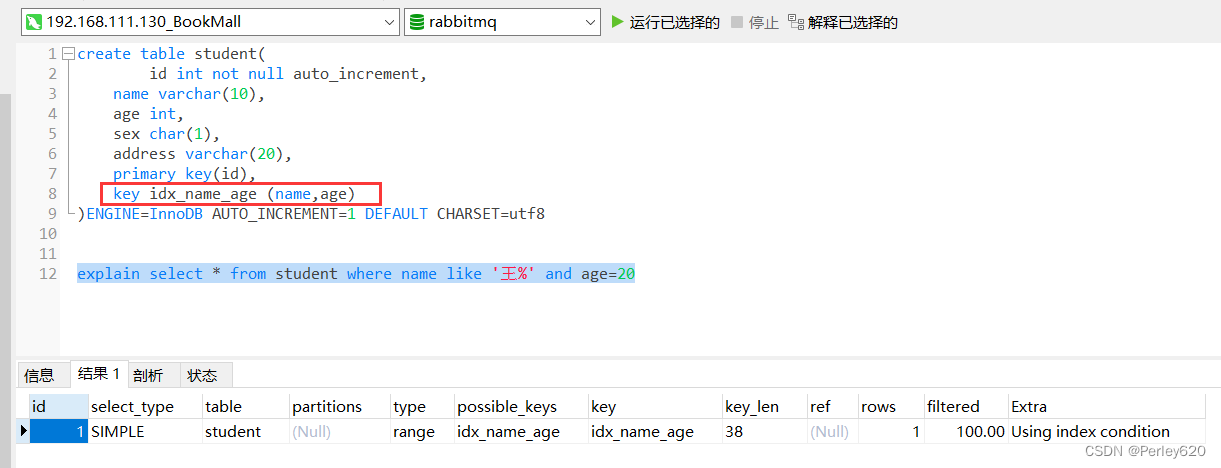
执行如下SQL
explain select * from student where name like '王%' and age=20

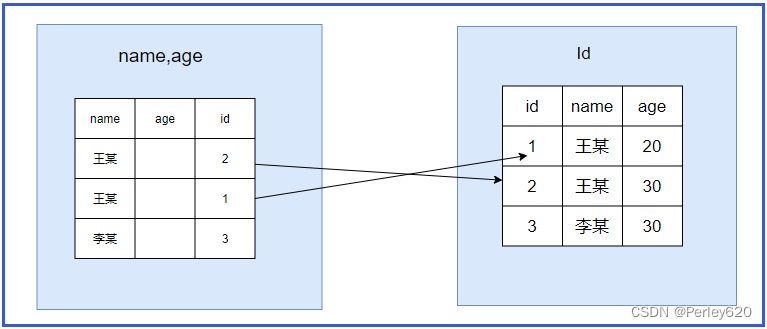
- 5.6之前的版本是没有索引下推优化,执行的过程如下图:
会忽略age这个字段,直接通过name进行查询,在(name,age)这课树上查找到了两个结果,id分别为2,1,然后拿着取到的id值一次次的回表查询,因此这个过程需要回表两次。
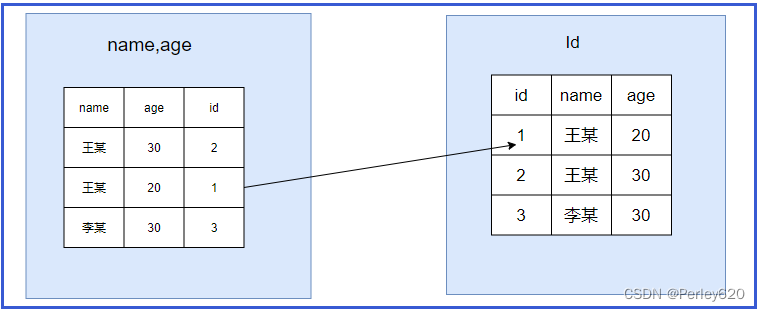
- 5.6版本添加了索引下推这个优化,执行的过程如下图:
InnoDB并没有忽略age这个字段,而是在索引内部就判断了age是否等于20,对于不等于20的记录直接跳过,因此在(name,age)这棵索引树中只匹配到了一个记录,此时拿着这个id去主键索引树中回表查询全部数据,这个过程只需要回表一次。
总结
1.索引是存储引擎用于快速查找数据纪录的一种数据结构;
2.索引的数据结构,B+树;
3.主键作为B+树索引的键值称为聚集索引;以主键以外的列值作为键值构建的B+树索引称为非聚集索引;
4.索引不满足左前缀,select *,or分割的条件,order by 非主键;
5.%开头的Like模糊查询–> 解决:select和where条件中的字段都出现在索引;
6.回表,先查到主键,再通过主键查数据,查了B+树两次;
7.索引覆盖:输出的列就是索引列,无需回表;
相关文章:
MySQL的索引——索引的介绍及其数据结构B+树 索引的类型 索引的使用及其失效场景 相关名词解释
前言 索引是存储引擎用于快速查找数据纪录的一种数据结构,索引是数据库中经常提及的一个词,究竟什么是索引,索引的数据结构是什么,索引有什么类型? 本篇博客尝试阐述数据库索引的相关内容,涉及什么是索引…...

第十六届中国智慧城市大会 | 国产化三维重建技术服务智慧城市建设
2023年10月13日,由武汉大势智慧科技有限公司、飞燕航空遥感技术有限公司主办的第十六届智慧城市大会-实景三维技术创新与应用论坛在广州成功举办。 来自实景三维、自然资源、数字孪生、AI大数据、航空遥感等多个领域的专家,深度分享各自的智慧城市建设经…...

通过数组的指针获得数组个数
这几天学习智能指针时,自己在练习写个管理数组指针的类时碰到了通过数组指针获取数组个数的问题 1.在网上查询了通过数组指针获取数组个数的方法,对于自定义数据在前四个节点保存了数组个数 Student* pAry new Student[3];size_t num *((size_t*)pAry - 1);//3测试是成功的…...
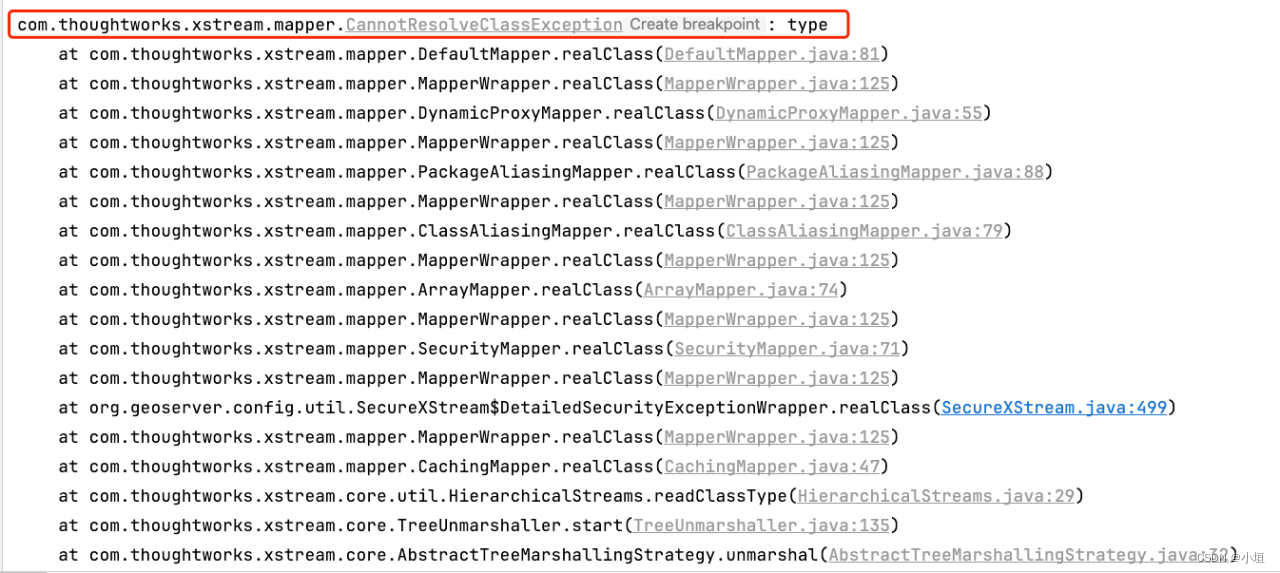
GeoServer改造Springboot启动四(解决post接口方法无法用@requestbody为入参的请求)
1、修改源码4 解决问题:解决Controller接口post方法(如图 19)无法用@requestbody为入参的 json数据进行请求,用swagger请求示例如图 20,具体错误呈现如图 21。 图 19Controller接口示例 图 20post接口请求示例 图 21post接...

C#,数值计算——分类与推理Phylagglomnode的计算方法与源程序
1 文本格式 using System; using System.Collections.Generic; namespace Legalsoft.Truffer { public class Phylagglomnode { public int mo { get; set; } public int ldau { get; set; } public int rdau { get; set; } public …...

mysql、oracle 构建数据
mysql 构建数据 --创建表 set sql_modeONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,ALLOW_INVALID_DATES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION CREATE TABLE vote_records_memory ( id int(10) unsigned NOT NULL AUTO_INCRE…...

二叉树;二叉树的前序、中序、后序遍历及查找;顺序存储二叉树;线索化二叉树
数组、链表和树存储方式分析 对于树结构,不论是查找修改还是增加删除,效率都比较高,结合了链表和数组的优点,如以下的二叉树: 1、数组的第一个元素作为第一个节点 2、数组的第二个元素3比7小,放在7的左边…...

有手就会做!保姆级Jmeter分布式压测操作流程(图文并茂)
分布式压测原理 分布式压测操作 保证本机和执行机的JDK和Jmeter版本一致配置Jmeter环境变量配置Jmeter配置文件 上传每个执行机服务jmeter chmod -R 755 apache-jmeter-5.1.1/ 执行机配置写自己的ip 控制机配置所有执行机ip,把server.rmi.ssl.disable改成true 将本机也作为压…...

澳洲谷揽GRANAR谷物分析仪维修GR-1800蛋白检测仪
澳洲GRANAR谷揽GR-1800谷物分析仪应用领域:大豆、油菜籽、亚麻籽 常用分析指标:蛋白质、芥酸、水分、灰分 、油脂等 分析时间:<3min 使用场景:谷物收购、生产加工、实验室 GR-1800i型号特点 1.检测时间由3分钟缩短…...
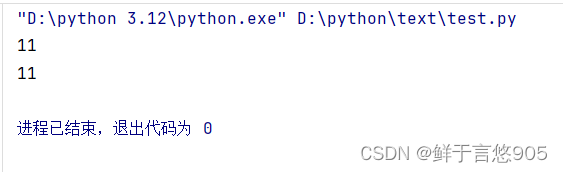
python基础语法(1)
基础语法 前言一、常量和表达式二、变量和类型变量是什么变量的语法(1)定义变量(2) 使用变量 变量的类型(1) 整数(2) 浮点数(小数)(3)字符串(string)可以使用单引号或双引号创建字符串(4) 布尔(5) 其他(1)类型决定了数据在内存中占…...
Web前端开发——新年倒计实时刷新
Web前端开发——年倒计实时刷新 H5(HTML5)前端开发是指使用HTML5、CSS3和JavaScript等技术进行网页和移动应用的开发。HTML5是最新的HTML标准,提供了丰富的语义化标签和功能,使得网页可以更加优雅和多样化。CSS3是用于样式表的升级版本,提供了更多的样式效果和布局控制能…...

ubuntu20.4 执行sudo apt-get update出现错误 libnettle.so.6 动态链接库错误
一、错误描述 sudo apt-get update 报错提示 libnettle.so.6 动态链接库错误 $ sudo apt update /usr/lib/apt/methods/https: error while loading shared libraries: libnettle.so.6: cannot open shared object file: No such file or directory /usr/lib/apt/methods/ht…...
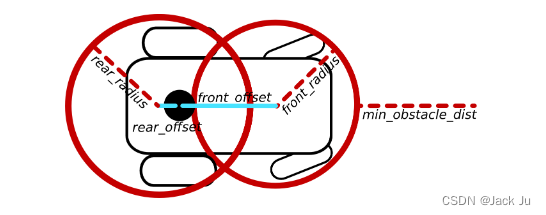
机器人控制算法——TEB算法—Obstacle Avoidance and Robot Footprint Model(避障与机器人足迹模型)
1.How Obstacle Avoidance works 1.1处罚条款 避障是作为整体轨迹优化的一部分来实现的。显然,优化涉及到找到指定成本函数(目标函数)的最小成本解(轨迹)。简单地说:如果一个计划的(未来&…...
谷歌浏览器报错:VM108:5 crbug/1173575, non-JS module files deprecated.
报错 解决 控制台调整为fast 3G...
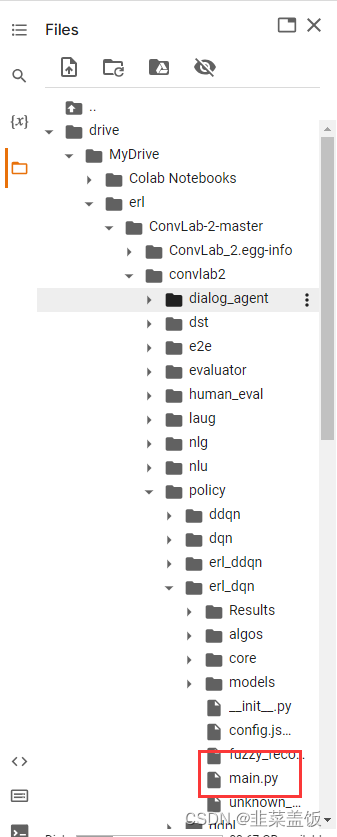
Google Colab免费GPU使用教程
目录 前言一、Google Colab介绍二、使用步骤1、创建谷歌云盘2、创建一个新的Colab Notebook3、设置免费的GPU4、挂载Google Drive5、运行代码 三、防止掉线措施四、参考 前言 有时候本地跑代码可能耗时比较久,而且还会耽误你本地电脑的使用,购买云服务器…...
- 类型支持 (数值极限,C 数值极限接口))
C++标准模板(STL)- 类型支持 (数值极限,C 数值极限接口)
C 数值极限接口 参阅 std::numeric_limits 接口 定义于头文件 <cstdint> PTRDIFF_MIN (C11) std::ptrdiff_t 类型对象的最小值 (宏常量) PTRDIFF_MAX (C11) std::ptrdiff_t 类型对象的最大值 (宏常量) SIZE_MAX (C11) std::size_t 类型对象的最大值 (宏常量) SIG_ATOMI…...
Eclipse Xtext 实现PLC ST 语言到C的转换
Eclipse Xtext 是开发领域专用语言(DSL)的工具。例如数据库的SQL 语言,PLC 的ST 语言都是一种领域专用语言。在开放自动化领域,提倡基于模型的设计方法。DSL 是描述模型的强有力工具。 在开发PLC 程序IDE时,开发ST编译…...

Django中ORM框架的各个操作
我们会好奇,python这么简洁的语言,数据查询是如何做的呢?我将进一步详细和深入地介绍Django中ORM框架的各个方面,包括MySQL的增删改查和复杂查询。让我们分步骤进行。 ORM框架介绍 Django的ORM框架是一个用于与数据库进行交互的工…...

leetcode 583. 两个字符串的删除操作、72. 编辑距离
两个字符串的删除操作 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 示例 1: 输入: word1 "sea", word2 "eat" 输出: 2 解释: 第一步将 "sea…...
flutter 创建插件
资料: flutter与原生通信的方式简介 - 简书 完整流程 Flutter 集成 Golang 多语言跨端开发基础案例 - 知乎 https://www.cnblogs.com/webabcd/p/flutter_lib_plugin_plugin_ios.html 步骤1、创建插件 我创建的插件名字是konnect_im_sdk 选择的语言是 java和swi…...

微信网页版访问技术范式:wechat-need-web的逆向工程实现机制
微信网页版访问技术范式:wechat-need-web的逆向工程实现机制 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 在浏览器生态中实现微信网页版…...

LM文生图WebUI源码浅析:Gradio封装逻辑与参数映射关系
LM文生图WebUI源码浅析:Gradio封装逻辑与参数映射关系 1. 平台架构概述 LM文生图镜像基于Tongyi-MAI/Z-Image底座构建,采用Gradio框架封装Web界面,实现了从文本描述到高质量图像生成的完整流程。该系统特别适合角色设计、时尚人像等场景&am…...

DRAM RowHammer攻击防御:流算法与硬件优化实践
1. DRAM RowHammer攻击的本质与威胁演变现代DRAM芯片的物理特性决定了其存储单元在密集访问下会出现电荷干扰现象。RowHammer攻击正是利用这一物理弱点,通过高频次访问特定内存行(称为"攻击行"),导致相邻行(…...

免费AI图像放大终极指南:Upscayl如何让低分辨率图片秒变高清
免费AI图像放大终极指南:Upscayl如何让低分辨率图片秒变高清 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl Upsc…...
)
Zustand和Pinia的对比(谁更好用)
先给结论:没有绝对更好,只看你用什么框架、项目规模、开发需求;Vue项目:无脑pinia(官方原生、生态、调试全拉满)React项目:Zustand几乎全方位吊打旧方案,比Pinia更适配React两者框架…...

告别屏幕撕裂和亮度不均:手把手教你用ILI9341的B组命令优化显示效果
告别屏幕撕裂和亮度不均:手把手教你用ILI9341的B组命令优化显示效果 在嵌入式显示项目中,ILI9341驱动芯片凭借其出色的色彩表现和灵活的接口配置,成为中小尺寸TFT-LCD的首选方案。但许多开发者在完成基础驱动后,常会遇到屏幕撕裂、…...

PCIe Gen4/Gen5高速链路不稳?手把手教你排查均衡协商失败问题
PCIe Gen4/Gen5高速链路不稳?手把手教你排查均衡协商失败问题 当PCIe Gen4/Gen5设备出现链路训练失败、速率协商异常或数据传输不稳定时,均衡(EQ)协商问题往往是罪魁祸首。本文将深入剖析PCIe均衡技术在实际工程中的故障排查方法,提供从现象分…...

追觅:从清洁电器到太空卫星,俞浩的科技野心能否实现?
【追觅超级碗的惊人承诺】追觅(Dreame,发音类似 "dreamy")利用超级碗半分钟曝光时间,承诺带来令人眼花缭乱的产品进化,从扫地机器人、割草机到超级跑车、人形机器人,甚至迈向太空。变形金刚风格的…...

别再拍脑袋估工时了!手把手教你用FPA功能点分析法,给软件项目算笔明白账
告别拍脑袋估算:FPA功能点分析法实战指南 估算软件项目工作量时,你是否也经历过这样的场景?老板或客户拿着模糊的需求文档问:"这个功能多久能做完?"你心里没底,只能硬着头皮给出一个数字…...

新款悄悄偷工减料、改名涨价,这是要玩坏旗舰手机?国内消费者应该感谢苹果!
国产手机在3月份的涨价失败了,但是4月份不少手机企业玩了些手段,改名、缩减配置等手段都用上了,而价格还是涨了,特别是那些旗舰手机玩的手段相当隐蔽,只是网友中不乏火眼金睛的,迅速发现这些新款手机的区别…...