二叉树;二叉树的前序、中序、后序遍历及查找;顺序存储二叉树;线索化二叉树
数组、链表和树存储方式分析

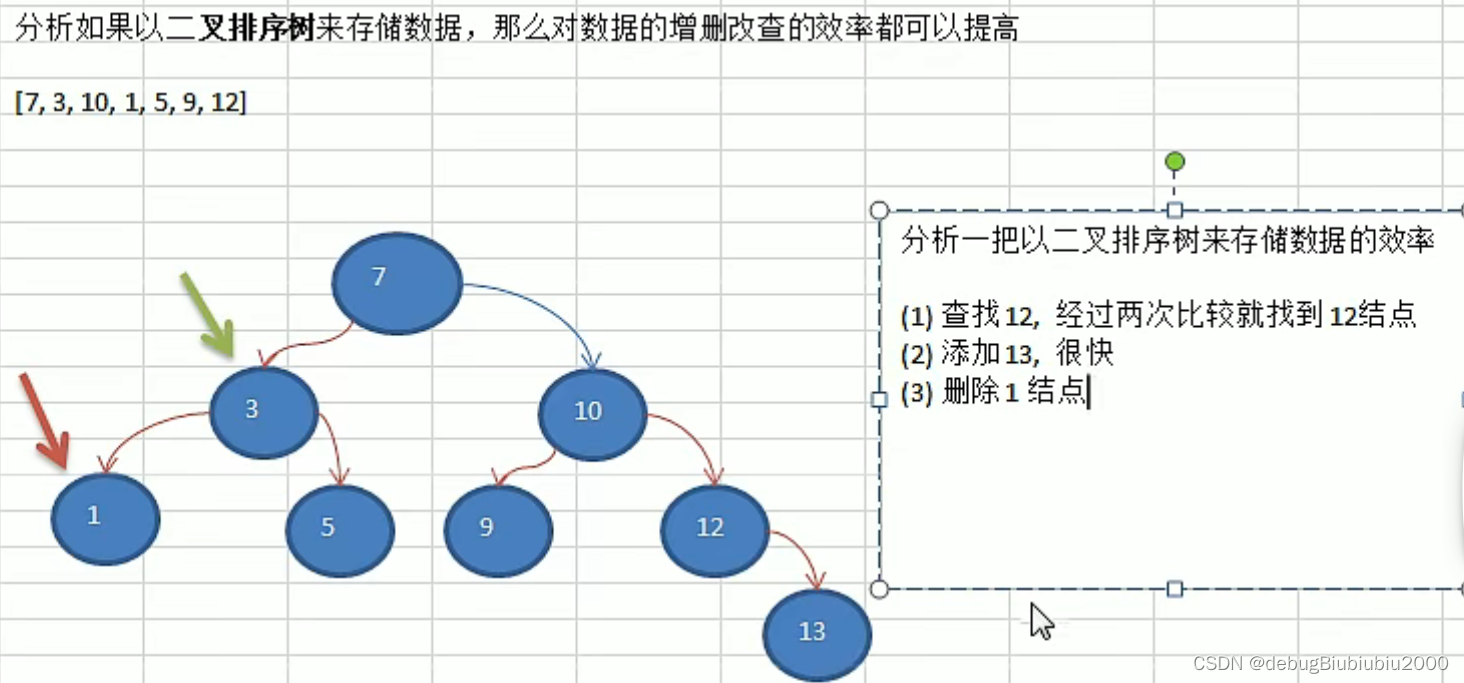
对于树结构,不论是查找修改还是增加删除,效率都比较高,结合了链表和数组的优点,如以下的二叉树:
1、数组的第一个元素作为第一个节点
2、数组的第二个元素3比7小,放在7的左边
3、数组的第三个元素10比7大,放在7的右边
4、数组的第四个元素1比7小,也比3小,放在3的左边
5、数组的第五个元素5比7小,但比3大,放在3的右边
6、数组的第六个元素9比7大,但比10小,放在10的左边
7、数组的第七个元素12比7大,比10大,放在10的右边
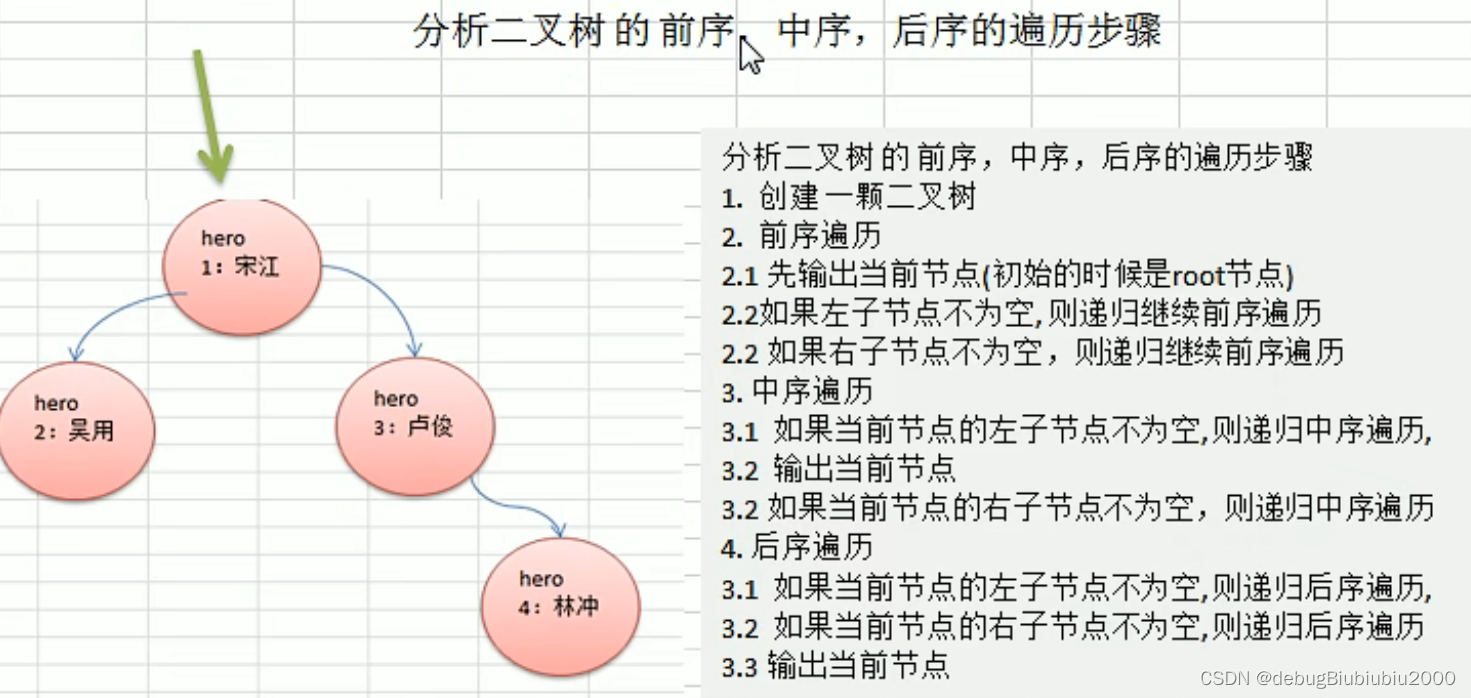
二叉树的前中后序遍历
思路分析

代码实现
# 创建 HeroNode 节点
class HeroNode:def __init__(self, no: int, name: str):self.no = noself.name = nameself.left = Noneself.right = Nonedef __str__(self):return f"no={self.no}, name={self.name}"# 前序遍历def pre_order(self):# 先输出父节点print(self, end=' => ')# 左子树不为空则递归左子树if self.left is not None:self.left.pre_order()# 右子树不为空则递归右子树if self.right is not None:self.right.pre_order()# 中序遍历def infix_order(self):# 左子树不为空则递归左子树if self.left is not None:self.left.infix_order()# 输出父节点print(self, end=' => ')# 右子树不为空则递归右子树if self.right is not None:self.right.infix_order()# 后序遍历def post_order(self):# 左子树不为空则递归左子树if self.left is not None:self.left.post_order()# 右子树不为空则递归右子树if self.right is not None:self.right.post_order()# 输出父节点print(self, end=' => ')# 建立 HeroNode 二叉树
class BinaryTree:root: HeroNode = None# 前序遍历def pre_order(self):if self.root is not None:self.root.pre_order()else:print("二叉树为空...")# 前序遍历def infix_order(self):if self.root is not None:self.root.infix_order()else:print("二叉树为空...")# 前序遍历def post_order(self):if self.root is not None:self.root.post_order()else:print("二叉树为空...")def test_binary_tree():# 手动创建二叉树binary_tree = BinaryTree()root = HeroNode(1, '宋江')node2 = HeroNode(2, '吴用')node3 = HeroNode(3, '卢俊义')node4 = HeroNode(4, '林冲')root.left = node2root.right = node3node3.right = node4binary_tree.root = root# 前序print("前序遍历:", end=" ")binary_tree.pre_order()print()# 中序print("中序遍历:", end=" ")binary_tree.infix_order()print()# 后序print("后序遍历:", end=" ")binary_tree.post_order()print()test_binary_tree()二叉树的前中后序查找
思路分析


代码实现
""" 前中后序遍历查找 """
# 创建 HeroNode 节点
class HeroNode:def __init__(self, no: int, name: str):self.no = noself.name = nameself.left = Noneself.right = Nonedef __str__(self):return f"no={self.no}, name={self.name}"# 前序遍历查找def pre_order_search(self, no: int):"""前序遍历查找某个节点:param no: 要查找节点的 id:return: 找到的 HeroNode 节点或 None"""print("进入前序遍历...")if self.no == no: # 如果当前节点是,直接返回return selffind_node = None# 如果左子节点不为空,则向左子节点继续递归查找# 找到则返回,找不到则看右子节点if self.left is not None:find_node = self.left.pre_order_search(no)if find_node: # 说明在左子树上找到,直接返回return find_node# 否则判断右子节点,若不为空,向右子树递归查找if self.right is not None:find_node = self.right.pre_order_search(no)# 如果右子树找到,则find_node有值,否则find_node为空return find_node# 中序遍历查找def infix_order_search(self, no: int):"""中序遍历查找某个节点:param no: 要查找节点的 id:return: 找到的 HeroNode 节点或 None"""find_node = None# 如果左子节点不为空,则向左子节点继续递归查找# 找到则返回,找不到则看右子节点if self.left is not None:find_node = self.left.infix_order_search(no)if find_node: # 说明在左子树上找到,直接返回return find_nodeprint("进入中序遍历...")if self.no == no: # 如果当前节点是,直接返回return self# 否则判断右子节点,若不为空,向右子树递归查找if self.right is not None:find_node = self.right.infix_order_search(no)# 如果右子树找到,则find_node有值,否则find_node为空return find_node# 后序遍历查找def post_order_search(self, no: int):"""后序遍历查找某个节点:param no: 要查找节点的 id:return: 找到的 HeroNode 节点或 None"""find_node = None# 如果左子节点不为空,则向左子节点继续递归查找# 找到则返回,找不到则看右子节点if self.left is not None:find_node = self.left.post_order_search(no)if find_node: # 说明在左子树上找到,直接返回return find_node# 否则判断右子节点,若不为空,向右子树递归查找if self.right is not None:find_node = self.right.post_order_search(no)# 如果右子树找到,则find_node有值,否则find_node为空if find_node:return find_nodeprint("进入后序遍历...")if self.no == no: # 如果当前节点是,直接返回return selfreturn None# 建立 HeroNode 二叉树
class BinaryTree:root: HeroNode = None# 前序查找def pre_order_search(self, no):if self.root is not None:return self.root.pre_order_search(no)else:return None# 中序查找def infix_order_search(self, no):if self.root is not None:return self.root.infix_order_search(no)else:return None# 后序查找def post_order_search(self, no):if self.root is not None:return self.root.post_order_search(no)else:return Nonedef test_binary_tree():# 手动创建二叉树binary_tree = BinaryTree()root = HeroNode(1, '宋江')node2 = HeroNode(2, '吴用')node3 = HeroNode(3, '卢俊义')node4 = HeroNode(4, '林冲')node5 = HeroNode(5, "关胜")root.left = node2root.right = node3node3.right = node4node3.left = node5binary_tree.root = rootprint("前序遍历查找:") # 比较了4次(看输出得到的结果)res = binary_tree.pre_order_search(5)if res:print("找到了,节点信息为:", res)else:print("找不到编号为5的节点")print()print("中序遍历查找:") # 比较了3次(看输出得到的结果)res = binary_tree.infix_order_search(5)if res:print("找到了,节点信息为:", res)else:print("找不到编号为5的节点")print()print("后序遍历查找:") # 比较了2次(看输出得到的结果)res = binary_tree.post_order_search(5)if res:print("找到了,节点信息为:", res)else:print("找不到编号为5的节点")test_binary_tree()二叉树删除节点
思路分析
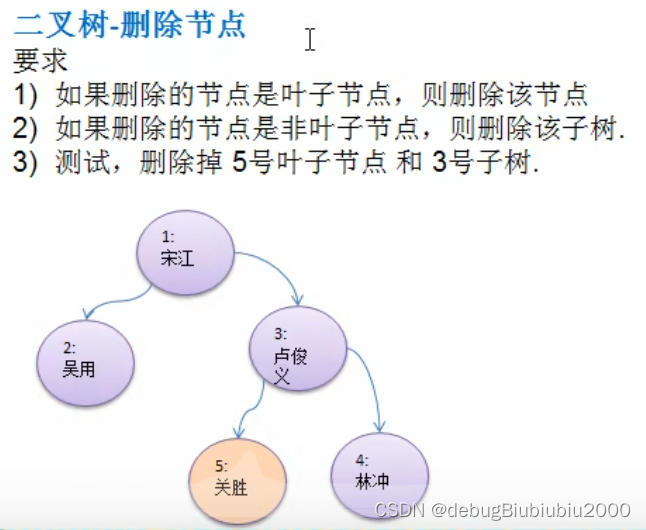

代码实现
""" 递归删除二叉树节点 """
# HeroNode 节点
class HeroNode:def __init__(self, no: int, name: str):self.no = noself.name = nameself.left = Noneself.right = Nonedef __str__(self):return f"no={self.no}, name={self.name}"# 前序遍历def pre_order(self):# 先输出父节点print(self, end=' => ')# 左子树不为空则递归左子树if self.left is not None:self.left.pre_order()# 右子树不为空则递归右子树if self.right is not None:self.right.pre_order()def delete_node(self, no: int):"""递归删除节点规则:如果删除的节点是叶子节点,则直接删除如果删除的节点不是叶子节点,则删除该节点及其左右子树:param no: 要删除的节点编号:return:"""# 如果左子节点不为空,且左子节点是要删除的节点,则删除左子节点及其子树,并返回if self.left and self.left.no == no:self.left = None # 相当于删除左子节点及其子树return# 如果右子节点不为空,且右子节点是要删除的节点,则删除右子节点及其子树,并返回if self.right and self.right.no == no:self.right = None # 相当于删除右子节点及其子树return# 如果左右子节点都不是要删除的节点,则首先向左子节点递归删除if self.left:self.left.delete_node(no)# 如果递归完左子节点还没找到要删除的节点,则继续向右子节点递归删除if self.right:self.right.delete_node(no)# 建立 HeroNode 二叉树
class BinaryTree:root: HeroNode = None# 前序遍历def pre_order(self):if self.root is not None:self.root.pre_order()else:print("二叉树为空...")# 删除树节点def delete_node(self, no: int):if self.root:if self.root.no == no: # 如果根节点是要删除的节点self.root = None # 则把根节点置空else:self.root.delete_node(no)else:print("树空,不能删除节点...")def test_binary_tree():# 手动创建二叉树binary_tree = BinaryTree()root = HeroNode(1, '宋江')node2 = HeroNode(2, '吴用')node3 = HeroNode(3, '卢俊义')node4 = HeroNode(4, '林冲')node5 = HeroNode(5, "关胜")root.left = node2root.right = node3node3.right = node4node3.left = node5binary_tree.root = rootprint("删除前:", end='')binary_tree.pre_order()print()binary_tree.delete_node(5)print("删除后:", end='')binary_tree.pre_order()print()test_binary_tree()顺序存储二叉树
思路分析
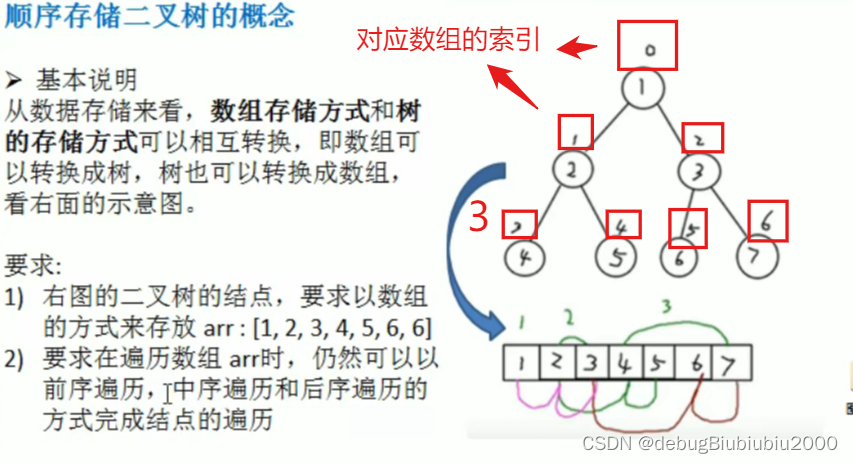

代码实现
需求如下:

"""顺序存储二叉树"""
# 顺序存储二叉树就是用数组结构存储二叉树节点数据,
# 要求用数组存储后,可以对该数组进行前序遍历、中序遍历、后序遍历
# 其实就是将二叉树从左到右,从上到下的节点依次存入数组中,如下:
"""
假设有如下一棵二叉树,它对应的顺序存储就是:arr = [1, 2, 3, 4, 5, 6, 7]12 34 5 6 7
"""
class ArrayBinaryTree:def __init__(self, arr):self.arr = arrdef pre_order(self, index: int):"""以前序遍历方式访问数组元素:param index: 数组下标:return:"""n = len(self.arr) # n为数组长度if self.arr and n > 0:# 输出当前元素print(f"arr[{index}]={self.arr[index]}", end=" ")# 向左子树递归if 2 * index + 1 < n:self.pre_order(2 * index + 1)# 向右子树递归if 2 * index + 2 < n:self.pre_order(2 * index + 2)else:print("数组为空!")def infix_order(self, index: int):"""以中序遍历方式访问数组元素:param index: 数组下标:return:"""n = len(self.arr)if self.arr and n > 0:if 2 * index + 1 < n: # 向左子树递归self.infix_order(2 * index + 1)print(f"arr[{index}]={self.arr[index]}", end=" ")if 2 * index + 2 < n: # 向右子树递归self.infix_order(2 * index + 2)else:print("数组为空")def post_order(self, index: int):"""以后序遍历方式访问数组元素:param index: 数组下标:return:"""n = len(self.arr)if self.arr and n > 0:if 2 * index + 1 < n: # 向左子树递归self.post_order(2 * index + 1)if 2 * index + 2 < n: # 向右子树递归self.post_order(2 * index + 2)print(f"arr[{index}]={self.arr[index]}", end=" ")arr_binary_tree = ArrayBinaryTree([1, 2, 3, 4, 5, 6, 7])
print("前序遍历:")
arr_binary_tree.pre_order(0)
print()
print("中序遍历:")
arr_binary_tree.infix_order(0)
print()
print("后序遍历:")
arr_binary_tree.post_order(0)
print()线索化二叉树
简单介绍
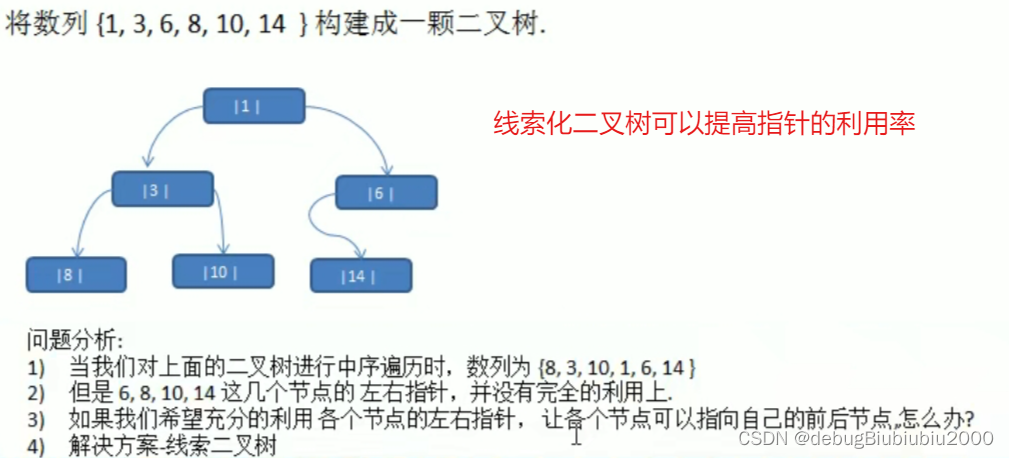

思路分析
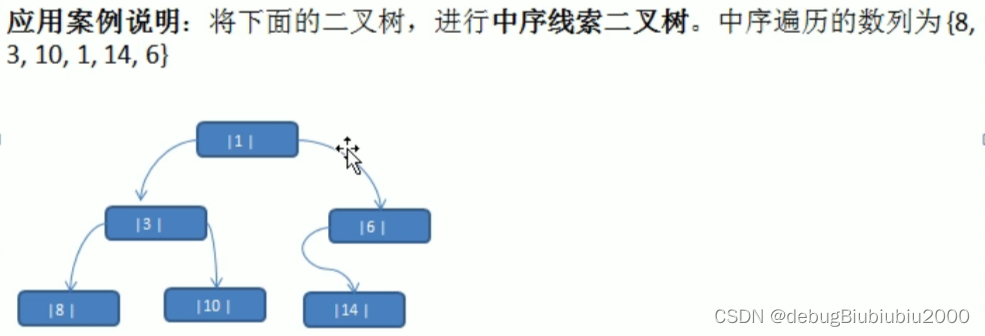
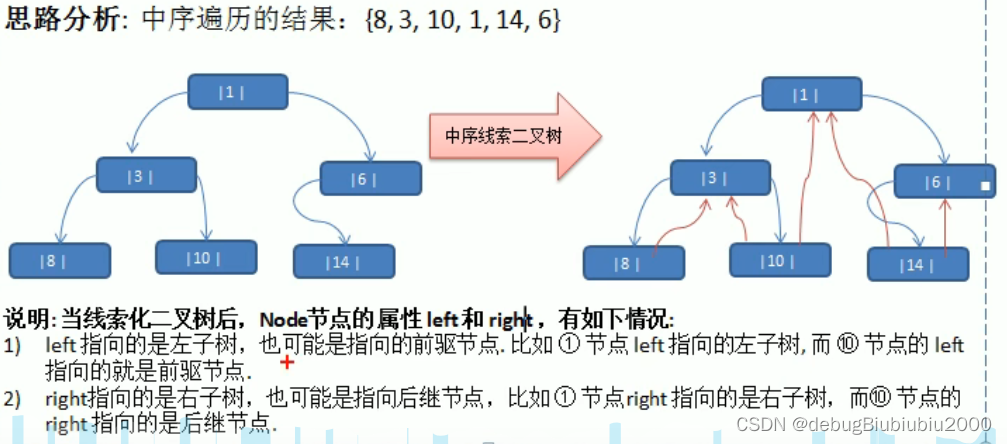
遍历线索化二叉树

线索化二叉树和遍历线索化二叉树的代码实现
""" 线索化二叉树 """
# 创建 Node 节点
class Node:no: int = Noneleft = Noneright = None# left_type/right_type 表示指针类型# 值为0时表示指向的是左子树/右子树,为1时表示指向的是前驱节点/后继节点left_type: int = 0right_type: int = 0def __init__(self, no: int):self.no = noself.left = Noneself.right = Nonedef __str__(self):return f"no={self.no}"# 建立线索化 Node 二叉树
class ThreadedBinaryTree:root: Node = None# 为了实现线索化,需要一个指针(变量)指向当前节点的前驱节点# 如中序线索化中,需要一个指针(变量)指向当前节点在中序遍历结果中的前驱节点# 在递归进行线索化时, pre 总指向当前节点按某种遍历方式结果的前驱节点pre: Node = None# 建立中序线索化二叉树def threaded_infix_tree(self, node: Node):"""建立中序线索化二叉树:param node: 要线索化的节点:return:"""if node is None: # 节点为空,不需要线索化return# 先线索化左子树self.threaded_infix_tree(node.left)# 线索化当前节点# 结合图形理解代码,第一个要线索化的节点是8# 先处理当前节点的左子节点if node.left is None: # 如果当前节点的左指针为空,则让左指针指向当前节点的前驱节点prenode.left = self.prenode.left_type = 1 # 设置指针类型为1,表示该指针指向的是前驱节点# 处理后继节点if self.pre and self.pre.right is None:self.pre.right = nodeself.pre.right_type = 1 # 设置指针类型为1,表示该指针指向的是后继节点# 每处理一个节点后,让当前节点成为下一个节点的前驱节点self.pre = node# 后线索化右子树self.threaded_infix_tree(node.right)# 遍历中序线索化二叉树def for_in_tree(self):node = self.rootwhile node:# 循环找到 left_type = 1 的节点,该节点就是中序遍历的第一个节点,即图中的节点8while node.left_type == 0:node = node.left# 输出当前节点print(node, end=" ")# 如果当前节点的右指针指向的是后继节点,则一直输出while node.right_type == 1:node = node.rightprint(node, end=" ")# 替换要遍历的节点,具体过程通过debug和结合图来看会更容易理解node = node.rightdef test_binary_tree():# 手动创建二叉树binary_tree = BinaryTree()root = Node(1)node2 = Node(3)node3 = Node(6)node4 = Node(8)node5 = Node(10)node6 = Node(14)root.left = node2root.right = node3node2.left = node4node2.right = node5node3.left = node6threaded_binary_tree = ThreadedBinaryTree()threaded_binary_tree.root = root# 测试线索化print(f"线索化前:10的left={node5.left},right={node5.right}")threaded_binary_tree.threaded_infix_tree(root)# 以10号节点,即node5测试print(f"线索化后:10的前驱节点={node5.left},后继节点={node5.right}")# 测试遍历线索化二叉树threaded_binary_tree.for_in_tree()test_binary_tree()相关文章:
二叉树;二叉树的前序、中序、后序遍历及查找;顺序存储二叉树;线索化二叉树
数组、链表和树存储方式分析 对于树结构,不论是查找修改还是增加删除,效率都比较高,结合了链表和数组的优点,如以下的二叉树: 1、数组的第一个元素作为第一个节点 2、数组的第二个元素3比7小,放在7的左边…...

有手就会做!保姆级Jmeter分布式压测操作流程(图文并茂)
分布式压测原理 分布式压测操作 保证本机和执行机的JDK和Jmeter版本一致配置Jmeter环境变量配置Jmeter配置文件 上传每个执行机服务jmeter chmod -R 755 apache-jmeter-5.1.1/ 执行机配置写自己的ip 控制机配置所有执行机ip,把server.rmi.ssl.disable改成true 将本机也作为压…...

澳洲谷揽GRANAR谷物分析仪维修GR-1800蛋白检测仪
澳洲GRANAR谷揽GR-1800谷物分析仪应用领域:大豆、油菜籽、亚麻籽 常用分析指标:蛋白质、芥酸、水分、灰分 、油脂等 分析时间:<3min 使用场景:谷物收购、生产加工、实验室 GR-1800i型号特点 1.检测时间由3分钟缩短…...
python基础语法(1)
基础语法 前言一、常量和表达式二、变量和类型变量是什么变量的语法(1)定义变量(2) 使用变量 变量的类型(1) 整数(2) 浮点数(小数)(3)字符串(string)可以使用单引号或双引号创建字符串(4) 布尔(5) 其他(1)类型决定了数据在内存中占…...
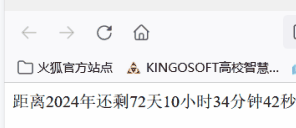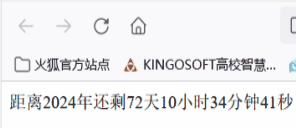
Web前端开发——新年倒计实时刷新
Web前端开发——年倒计实时刷新 H5(HTML5)前端开发是指使用HTML5、CSS3和JavaScript等技术进行网页和移动应用的开发。HTML5是最新的HTML标准,提供了丰富的语义化标签和功能,使得网页可以更加优雅和多样化。CSS3是用于样式表的升级版本,提供了更多的样式效果和布局控制能…...

ubuntu20.4 执行sudo apt-get update出现错误 libnettle.so.6 动态链接库错误
一、错误描述 sudo apt-get update 报错提示 libnettle.so.6 动态链接库错误 $ sudo apt update /usr/lib/apt/methods/https: error while loading shared libraries: libnettle.so.6: cannot open shared object file: No such file or directory /usr/lib/apt/methods/ht…...
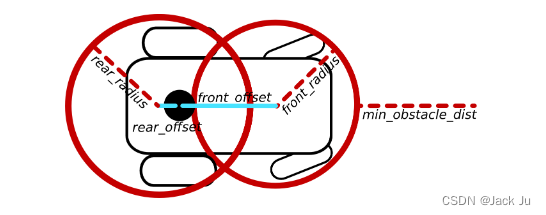
机器人控制算法——TEB算法—Obstacle Avoidance and Robot Footprint Model(避障与机器人足迹模型)
1.How Obstacle Avoidance works 1.1处罚条款 避障是作为整体轨迹优化的一部分来实现的。显然,优化涉及到找到指定成本函数(目标函数)的最小成本解(轨迹)。简单地说:如果一个计划的(未来&…...
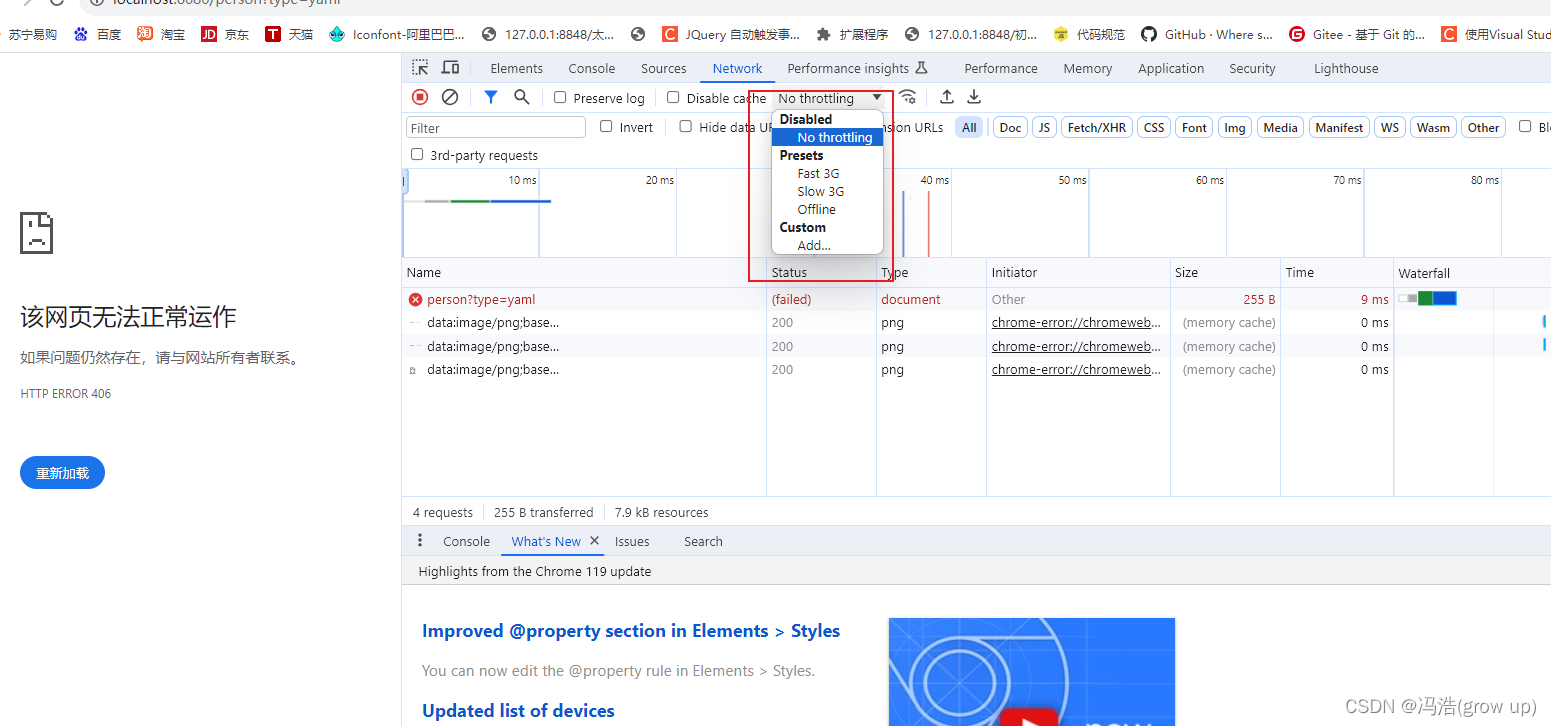
谷歌浏览器报错:VM108:5 crbug/1173575, non-JS module files deprecated.
报错 解决 控制台调整为fast 3G...
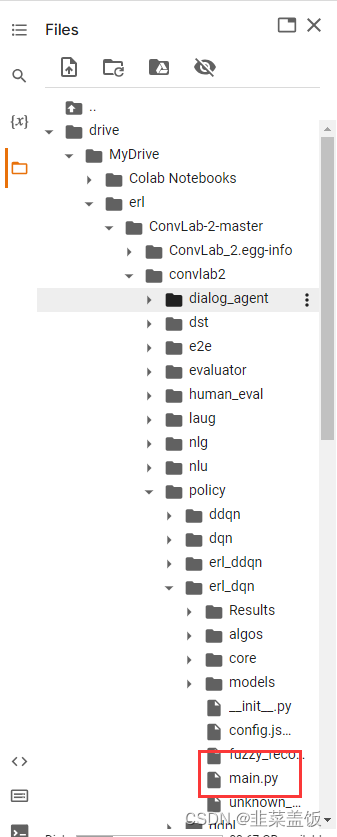
Google Colab免费GPU使用教程
目录 前言一、Google Colab介绍二、使用步骤1、创建谷歌云盘2、创建一个新的Colab Notebook3、设置免费的GPU4、挂载Google Drive5、运行代码 三、防止掉线措施四、参考 前言 有时候本地跑代码可能耗时比较久,而且还会耽误你本地电脑的使用,购买云服务器…...
- 类型支持 (数值极限,C 数值极限接口))
C++标准模板(STL)- 类型支持 (数值极限,C 数值极限接口)
C 数值极限接口 参阅 std::numeric_limits 接口 定义于头文件 <cstdint> PTRDIFF_MIN (C11) std::ptrdiff_t 类型对象的最小值 (宏常量) PTRDIFF_MAX (C11) std::ptrdiff_t 类型对象的最大值 (宏常量) SIZE_MAX (C11) std::size_t 类型对象的最大值 (宏常量) SIG_ATOMI…...
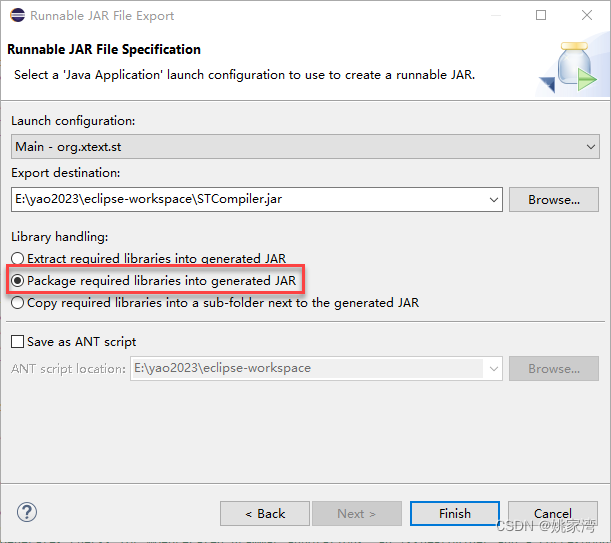
Eclipse Xtext 实现PLC ST 语言到C的转换
Eclipse Xtext 是开发领域专用语言(DSL)的工具。例如数据库的SQL 语言,PLC 的ST 语言都是一种领域专用语言。在开放自动化领域,提倡基于模型的设计方法。DSL 是描述模型的强有力工具。 在开发PLC 程序IDE时,开发ST编译…...

Django中ORM框架的各个操作
我们会好奇,python这么简洁的语言,数据查询是如何做的呢?我将进一步详细和深入地介绍Django中ORM框架的各个方面,包括MySQL的增删改查和复杂查询。让我们分步骤进行。 ORM框架介绍 Django的ORM框架是一个用于与数据库进行交互的工…...

leetcode 583. 两个字符串的删除操作、72. 编辑距离
两个字符串的删除操作 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 示例 1: 输入: word1 "sea", word2 "eat" 输出: 2 解释: 第一步将 "sea…...
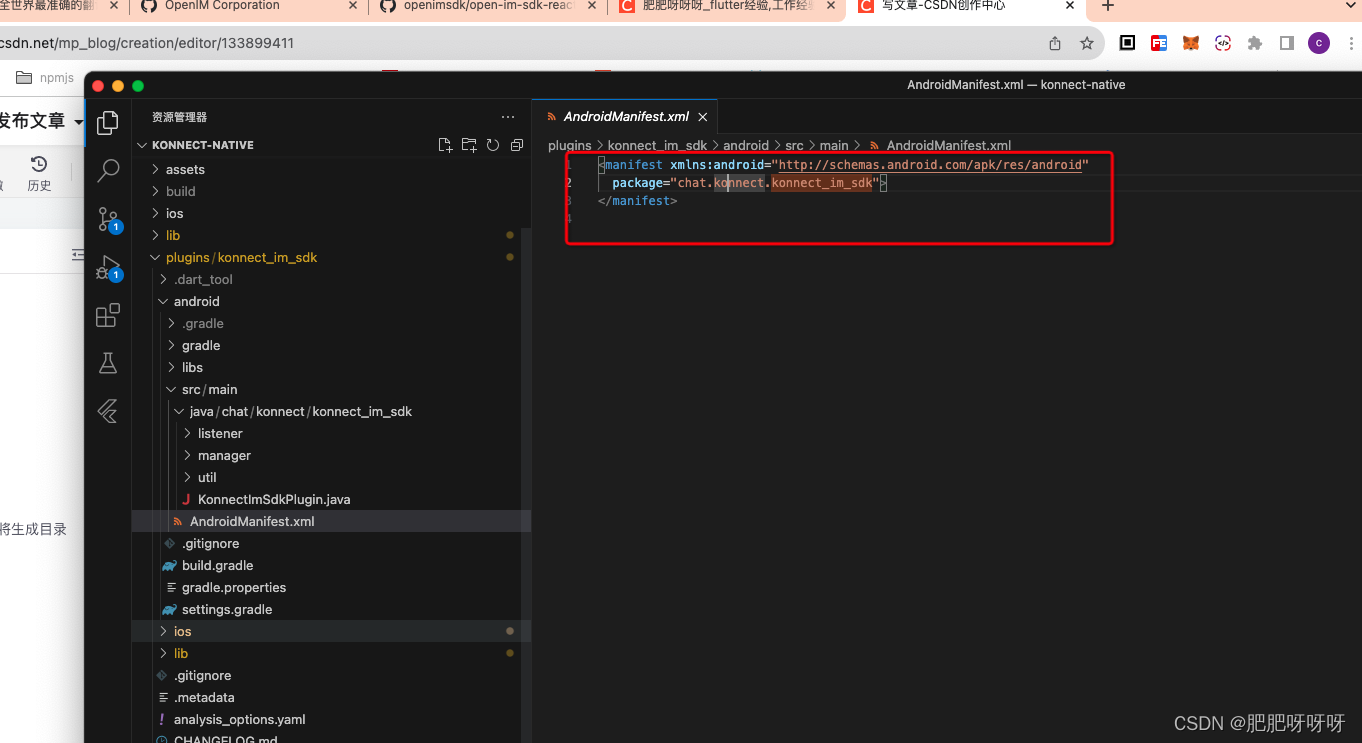
flutter 创建插件
资料: flutter与原生通信的方式简介 - 简书 完整流程 Flutter 集成 Golang 多语言跨端开发基础案例 - 知乎 https://www.cnblogs.com/webabcd/p/flutter_lib_plugin_plugin_ios.html 步骤1、创建插件 我创建的插件名字是konnect_im_sdk 选择的语言是 java和swi…...

Framework之旅 -- 后台Recent基础扫盲篇
如果想了解一个事物,是需要展开然后在优化记忆结构的,优化记忆在于后期的个人领悟能力,展开流水账如下,仅为个人记忆笔记,梳理结构有待优化。 TaskDescription,直译看就是task相关的说明了。 看看包含什么…...

全光谱护眼灯有哪些?2023全光谱护眼台灯推荐
随着电子设备的不断普及,手机、平板电脑、显示器、电视机等几乎是家家户户的必备品,也正因为眼睛有那么多时间、那么多机会去盯着屏幕,所以如今近视低龄化现象也越来越严重了。随着科技的不断发展,台灯的发展也越来越多样化&#…...
【JavaEE初阶】 定时器详解与实现
文章目录 🌴定时器是什么🎋Java标准库中的定时器🌲模拟实现定时器🚩定时器的构成📌第一步:MyStack类的建立📌第二步:创建MyTimer类📌第三步:解决相关问题 &am…...
基于YOLOv8模型和WiderPerson数据集的行人目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和WiderPerson数据集的行人目标检测系统可用于日常生活中检测与定位行人目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标…...

COSCon'23 开源社文创丨 给开源人一点“color see see”
成都城市限定 “小O在成都”行李箱贴纸 成都限定行李箱贴纸把小O和特色元素相融合 当小O遇到成都 在云端漫步的蓝色小章鱼 掉落到这座热情似火的城市, 结识了大熊猫朋友 学会了四川麻将 吃到了红油串串... 快带着小O来一场自由的旅游吧! “你也要尝尝竹子…...

C++前缀和算法的应用:从仓库到码头运输箱子原理、源码、测试用例
本文涉及的基础知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 双指针 单调双向队列 题目 你有一辆货运卡车,你需要用这一辆车把一些箱子从仓库运送到码头。这辆卡车每次运输有 箱子数目的限制 和 总重量的限制 。 给你…...

拆解一台VPX-305加固机箱:聊聊3U VPX背板设计、电源选型与散热那些坑
3U VPX加固机箱设计实战:从背板拓扑到散热优化的工程密码 当军用电子设备遇上戈壁滩的沙尘暴,或是舰载系统遭遇高盐雾腐蚀环境,普通商用硬件往往会在几小时内宣告罢工。这正是VPX加固机箱存在的意义——它不仅是一层金属外壳,更是…...

云环境LLC缓存争用检测与优化实践
1. 云虚拟机缓存争用问题概述在云计算环境中,多个虚拟机(VM)共享物理主机的最后一级缓存(LLC)是常态。这种资源共享机制虽然提高了硬件利用率,但也带来了严重的缓存争用问题。当多个虚拟机频繁访问LLC时&am…...

从快递路线规划到电路板布线:欧拉图在实际开发中的两种应用场景与代码实战
从快递路线规划到电路板布线:欧拉图在实际开发中的两种应用场景与代码实战 快递员老张每天清晨6点准时出现在物流站点,他的三轮车上堆满了待派送的包裹。过去两年里,他总要在同一条街道上来回穿梭,有时甚至因为漏掉某个小巷而不得…...

AndroidX迁移指南:如何将XBanner适配到最新Android项目
AndroidX迁移指南:如何将XBanner适配到最新Android项目 【免费下载链接】XBanner :fire:【图片轮播】支持图片无限轮播,支持AndroidX、自定义指示点、显示提示文字、切换动画、自定义布局,一屏多显、视频图片混合轮播等功能 项目地址: http…...

Abseil线程安全终极指南:多线程环境下的高效并发编程实践
Abseil线程安全终极指南:多线程环境下的高效并发编程实践 【免费下载链接】abseil-cpp Abseil Common Libraries (C) 项目地址: https://gitcode.com/GitHub_Trending/ab/abseil-cpp Abseil C库提供了全面的线程安全解决方案,帮助开发者在多线程环…...

WinUtil架构解析:模块化Windows系统管理框架的技术实现
WinUtil架构解析:模块化Windows系统管理框架的技术实现 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 项目定位与技术背景 在Wi…...

Aspose.Words 24.2 升级踩坑记:从目录页码错乱到表格跨页,我的Java自动化报告修复实战
Aspose.Words 24.2 升级实战:Java自动化报告生成中的目录页码与表格跨页问题深度解析 当项目依赖的文档处理库迎来重大版本更新时,开发团队往往既期待新功能带来的效率提升,又担忧潜在兼容性问题。作为长期使用Aspose.Words进行Java自动化报告…...

Bilibili视频转文字神器:3步实现高效智能的文字提取方案
Bilibili视频转文字神器:3步实现高效智能的文字提取方案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text bili2text是一个专业的Bilibili视频转文字…...

高效论文降重方案:2026年TOP10平台极限抗压对比与自救建议
先导章:当“查AI率”成为悬顶之剑,你还在用上个时代的破铜烂铁拼命? 就在两周前,某双一流高校下发了一则通报,直接让今年的硕士求生圈哀鸿遍野。有4名即将参与盲审的研三学生,因为在学术不端审核中&#x…...

零成本解锁VMware Workstation Pro 17:从虚拟化新手到专家的完整指南
零成本解锁VMware Workstation Pro 17:从虚拟化新手到专家的完整指南 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major versio…...