机器学习基础之《回归与聚类算法(4)—逻辑回归与二分类(分类算法)》
一、什么是逻辑回归
1、逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛
2、叫回归,但是它是一个分类算法
二、逻辑回归的应用场景
1、应用场景
广告点击率:预测是否会被点击
是否为垃圾邮件
是否患病
金融诈骗:是否为金融诈骗
虚假账号:是否为虚假账号
均为二元问题
2、看到上面的例子,我们可以发现其中的特点,那就是都属于两个类别之间的判断。逻辑回归就是解决二分类问题的利器
会有一个正例,和一个反例
三、逻辑回归的原理
1、逻辑回归的输入
线性回归的输出,就是逻辑回归的输入![]()
逻辑回归的输入就是一个线性回归的结果
2、怎么用输入来分类
要进行下一步处理,带入到sigmoid函数当中,我们把它叫做激活函数
3、sigmoid函数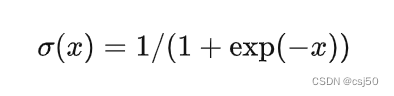
可以理解为,f(x)=1/(1+e^(-x)),1加上e的负x次方分之1
sigmoid函数又称S型函数,它是一种非线性函数,可以将任意实数值映射到0-1之间的值,通常用于分类问题。它的表达式为:f(x)=1/(1+e^(-x)),其中e为自然对数的底数。它的输出值均位于0~1之间,当x趋向正无穷时,f(x)趋向1;当x趋向负无穷时,f(x)趋向0
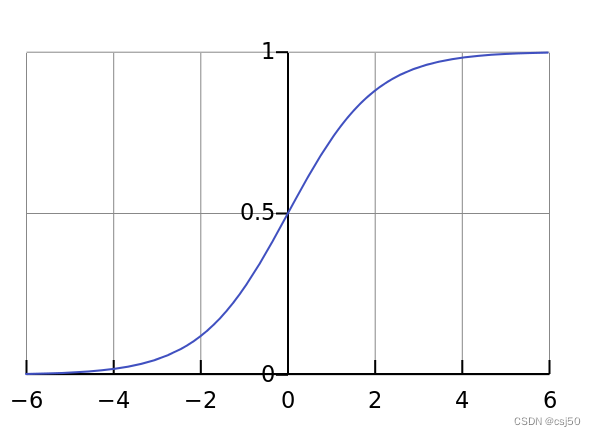
4、分析
将线性回归的输出结果,代入到x的部分
输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
5、假设函数/线性模型
1/(1 + e^(-(w1x1 + w2x2 + w3x3 + ... + wnxn +b)))
如何得出权重和偏置,使得这个模型可以准确的进行分类预测呢?
6、损失函数(真实值和预测值之间的差距)
我们可以用求线性回归的模型参数的方法,来构建一个损失函数
线性回归的损失函数:(y_predict - y_true)平方和/总数,它是一个值
而逻辑回归的真实值和预测值,是否属于某个类别
所以就不能用均方误差和最小二乘法来构建
要使用对数似然损失
7、优化损失(正规方程和梯度下降)
用一种优化方法,将损失函数取得最小值,所对应的权重值就是我们求的模型参数
四、对数似然损失
1、公式
逻辑回归的损失,称之为对数似然损失
(1)它是一个分段函数
(2)如果y=1,真实值是1,属于这个类别,损失就是 -log(y的预测值)
(3)如果y=0,真实值是0,不属于这个类别,损失就是 -log(1-y的预测值)
2、怎么理解单个的式子呢?这个要根据log的函数图像来理解
当y=1时:(横坐标是y的预测值)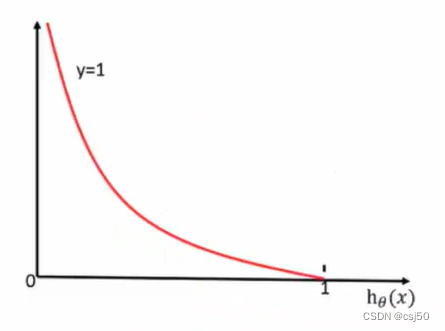
前提真实值是1,如果预测值越接近于1,则损失越接近0。如果预测值越接近于0,则损失越大
当y=0时:(横坐标是y的预测值)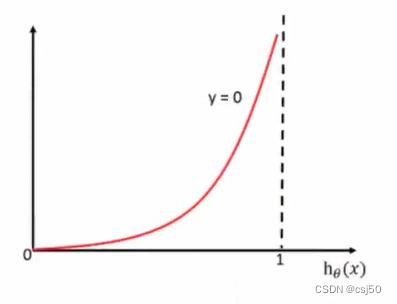
前提真实值是0,如果预测值越接近1,则损失越大
3、综合完整损失函数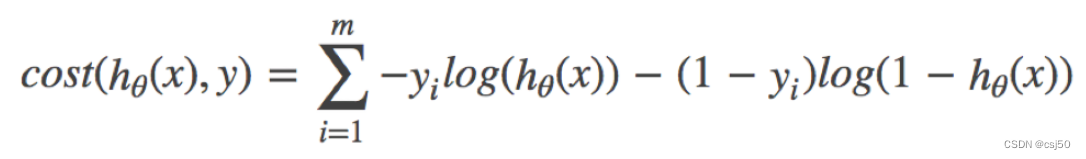
损失函数:-(y真实*logy预测+(1-y真实)*log(1-y预测)),求和
![]() 是线性回归的输出,经过sigmoid函数映射之后的一个概率值
是线性回归的输出,经过sigmoid函数映射之后的一个概率值
4、计算样例
五、优化损失
同样使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率
六、逻辑回归API
1、sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C=1.0)
solver:优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
auto:根据数据集自动选择,随机平均梯度下降
penalty:正则化的种类
C:正则化力度
2、LogisticRegression方法相当于SGDClassifier(loss="log", penalty=" ")
SGDClassifier是一个分类器
SGDClassifier实现了一个普通的随机梯度下降学习,也支持平均随机梯度下降法(ASGD),可以通过设置average=True
而使用LogisticRegression它的优化器已经可以使用SAG
七、案例:癌症分类预测-良 / 恶性乳腺癌肿瘤预测
1、数据集
数据:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
数据的描述:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.names
2、数据的描述
# Attribute Domain-- -----------------------------------------1. Sample code number id number2. Clump Thickness 1 - 103. Uniformity of Cell Size 1 - 104. Uniformity of Cell Shape 1 - 105. Marginal Adhesion 1 - 106. Single Epithelial Cell Size 1 - 107. Bare Nuclei 1 - 108. Bland Chromatin 1 - 109. Normal Nucleoli 1 - 1010. Mitoses 1 - 1011. Class: (2 for benign, 4 for malignant)第一列:样本的编号
第二到十列:特征
第十一列:分类(2代表良性,4代表恶性)
3、流程分析
(1)获取数据
读取的时候加上names
(2)数据处理
处理缺失值
(3)数据集划分
(4)特征工程
无量纲化处理—标准化
(5)逻辑回归预估器
(6)模型评估
4、代码
import pandas as pd
import numpy as np# 1、读取数据
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column_name)data# 2、缺失值处理
# 1)?替换为np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失样本
data.dropna(inplace=True)data# 不存在缺失值
data.isnull().any()# 3、划分数据集
from sklearn.model_selection import train_test_split# 筛选特征值和目标值
x = data.iloc[:, 1:-1] # 行都要,列从1到-1
y = data["Class"]x.head()y.head()x_train, x_test, y_train, y_test = train_test_split(x, y)# 4、标准化
from sklearn.preprocessing import StandardScalertransfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)x_trainfrom sklearn.linear_model import LogisticRegression# 5、预估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)# 逻辑回归的模型参数:回归系数和偏置
# 有几个特征,就有几个回归系数
estimator.coef_estimator.intercept_# 6、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
5、运行结果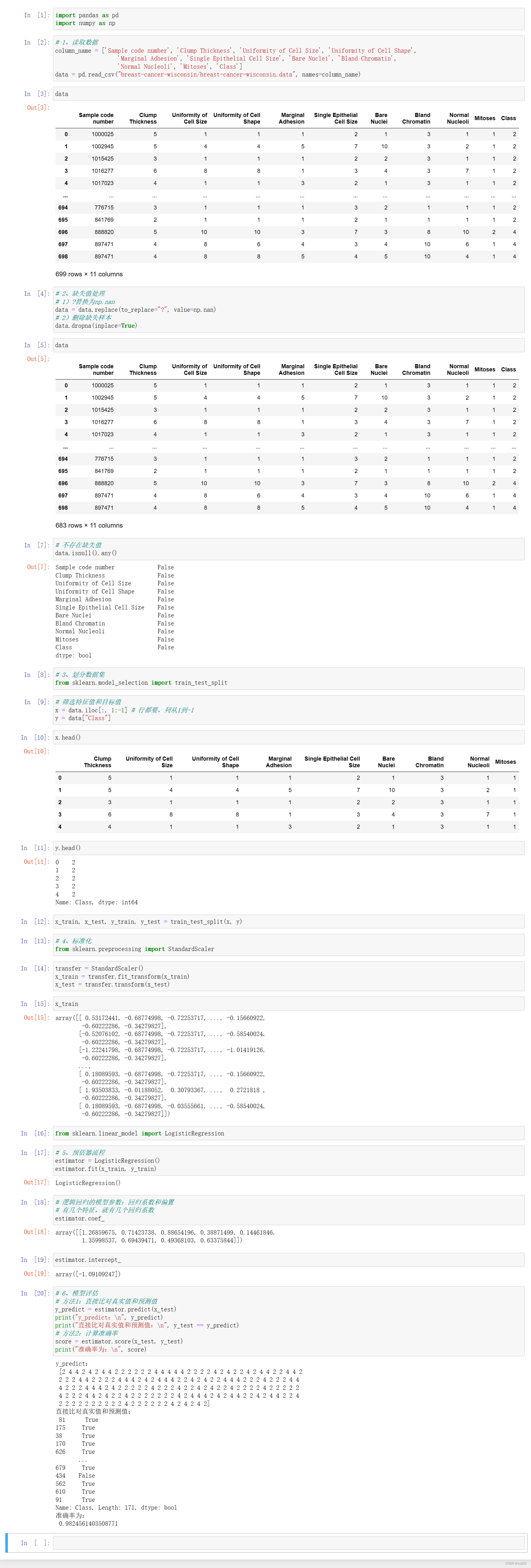
相关文章:
机器学习基础之《回归与聚类算法(4)—逻辑回归与二分类(分类算法)》
一、什么是逻辑回归 1、逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广…...
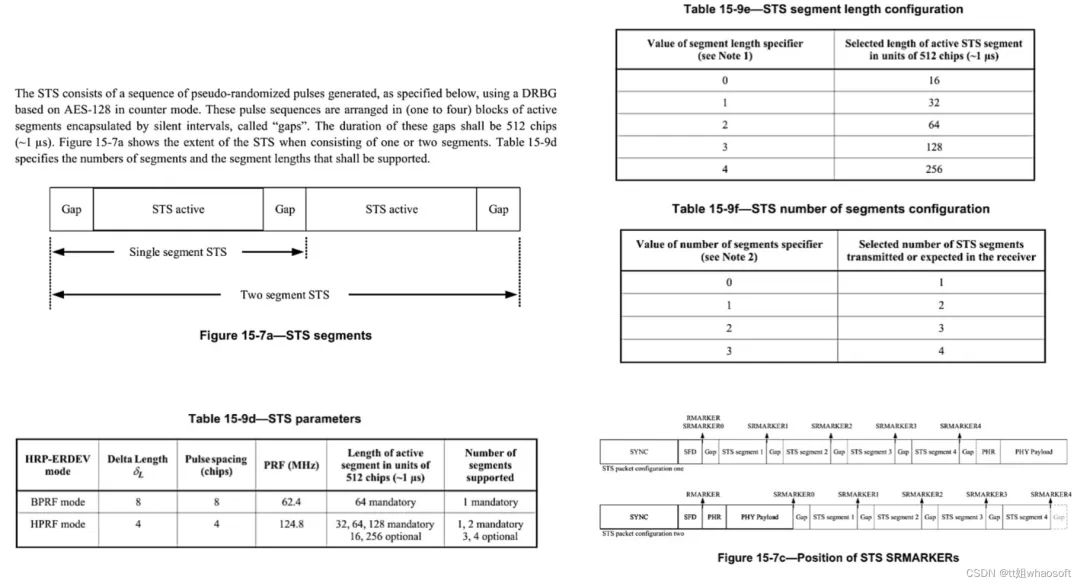
UWB安全数据通讯STS-加密、身份认证
DW3000系列才能支持UWB安全数据通讯,DW1000不支持 IEEE 802.15.4a没有数据通讯安全保护机制,IEEE 802.15.4z中指定的扩展得到增强(在PHY/RF级别):增添了一个重要特性“扰频时间戳序列(STS)”&a…...

vue3中去除eslint严格模式
vue3中去除eslint严格模式 1、全局搜索:extends 2、一般在package.json或者vue.config.js中,直接删除掉vue/standard,重启项目。(在package.json文件中,编译不允许有注释,所以直接删掉)...
Win10如何彻底关闭wsappx进程?
Win10如何彻底关闭wsappx进程?在Win10电脑中,用户看到了wsappx进程占用了大量的系统资源,所以想结束wsappx进程,提升电脑的运行速度。但是,用户们不知道彻底关闭掉wsappx进程的方法,那么接下来小编就给大家…...
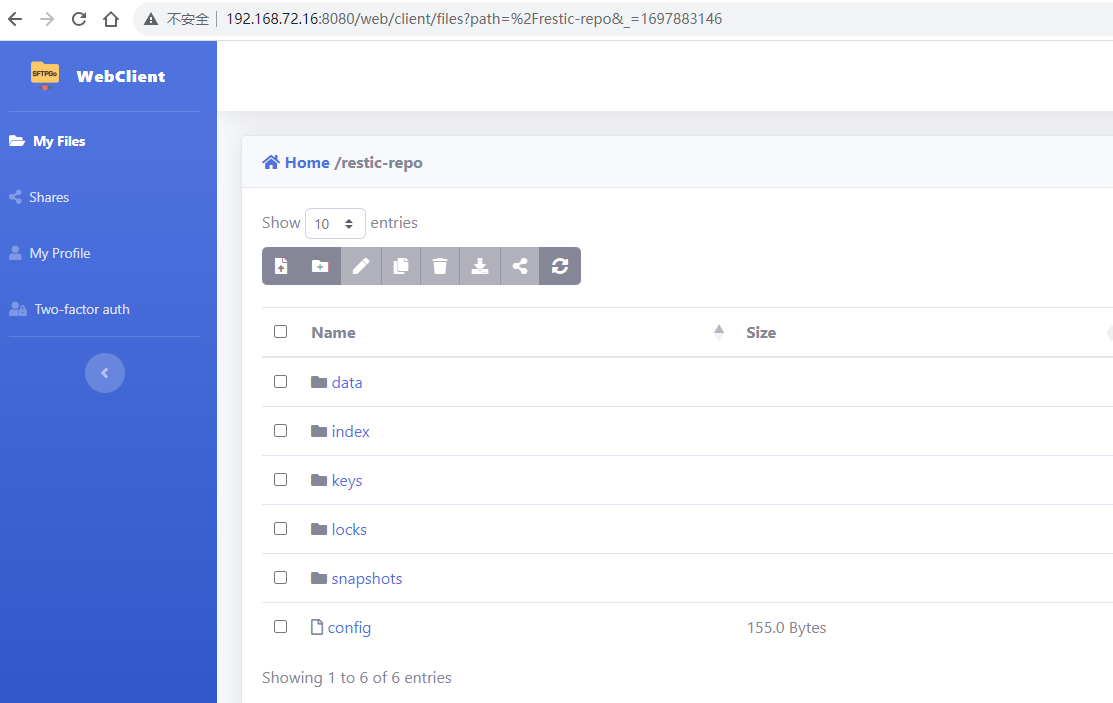
docker 安装 sftpgo
sftpgo 简介 sftpgo 是一个功能齐全且高度可配置的 SFTP 服务器,具有可选的 HTTP/S、FTP/S 和 WebDAV 支持。支持多种存储后端:本地文件系统、加密本地文件系统、S3(兼容)对象存储、Google 云存储、Azure Blob 存储、SFTP。 官…...
 创建一个场景)
threejs (一) 创建一个场景
引入 npm install three import * as THREE from three;const scene new THREE.Scene();或者使用bootCDN复制对应的版本连接 <script src"https://cdn.bootcdn.net/ajax/libs/three.js/0.156.1/three.js"></script>基础知识 场景、相机、渲染器 通过…...

二分查找,求方程多解
1.暴力遍历: 解为两位小数,故0.001的范围肯定可以包含(零点存在) 2.均分为区间长度为1的小区间(由于两解,距离不小于1),一个区间最多一个解 1.防止两边端点都为解 2&…...

代码随想录算法训练营第二十九天 | 回溯算法总结
代码随想录算法训练营第二十九天 | 回溯算法总结 1. 组合问题 1.1 组合问题 在77. 组合中,我们开始用回溯法解决第一道题目:组合问题。 回溯算法跟k层for循环同样是暴力解法,为什么用回溯呢?回溯法的魅力,用递…...
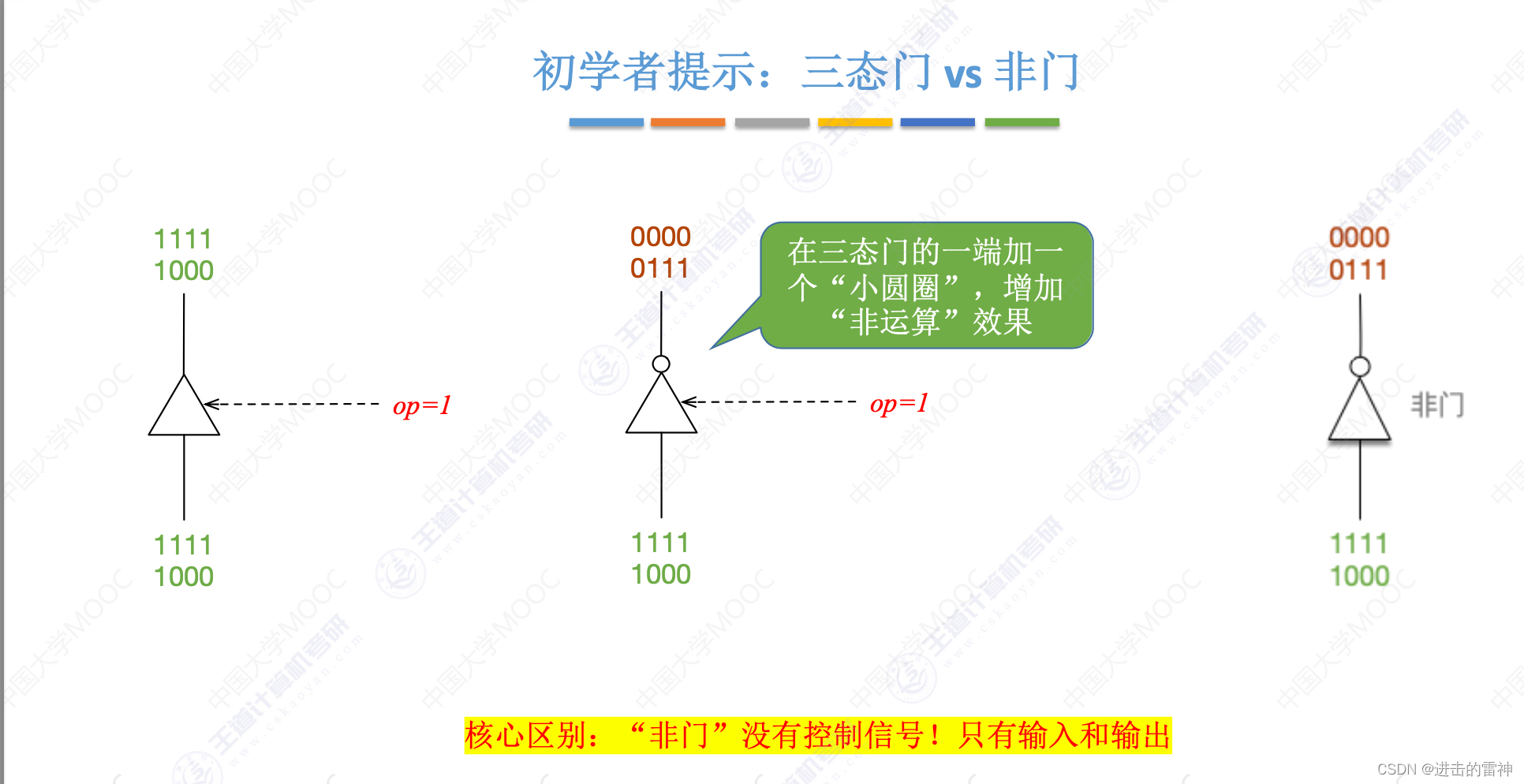
运算方法和运算电路
一、逻辑门电路 1、逻辑门电路基础总结 2、异或运算妙用 3、逻辑常用公式 二、加法器(重点) 1、标志位的生成原理 2、加法器总结 三、多路门选择器,三态门...
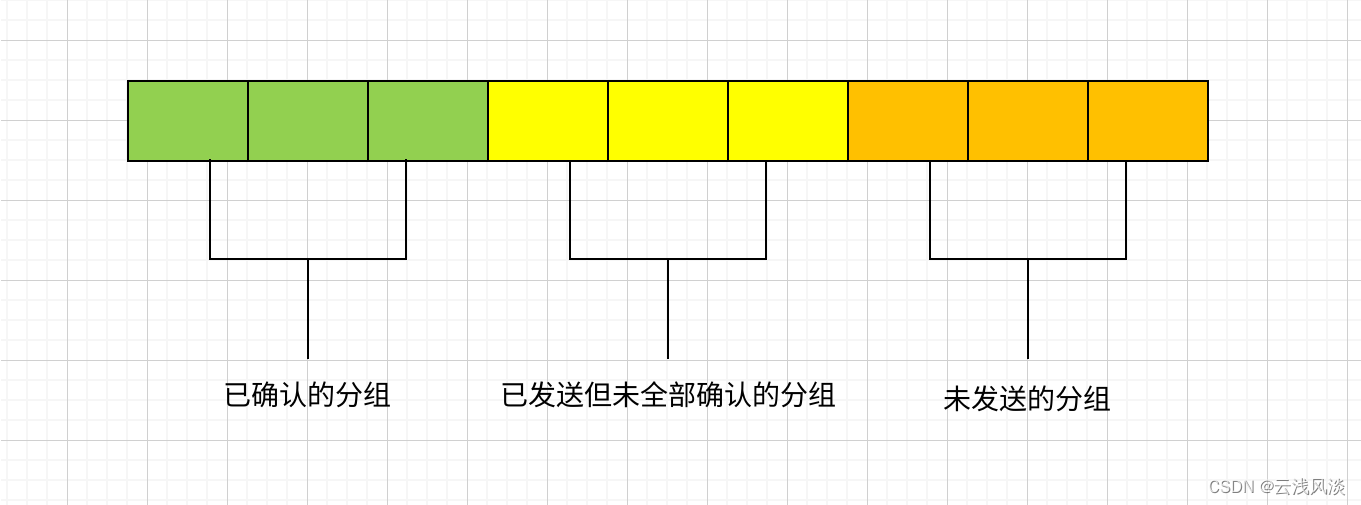
计算机网络篇之TCP滑动窗口
文章目录 前言概述 前言 在网络数据传输时,若传输的原始数据包比较大,会将数据包分解成多个数据包进行发送。需要对数据包确认后,才能发送下一个数据包。在等待确认包的这个过程浪费了大量的时间,不过还好TCP引入了滑动窗口的概念…...

本地安装telepresence,访问K8S集群 Mac(m1) 非管理員
kubeconfig 一.安装telepresence 1.安装 Telepresence Quickstart | Telepresence (1)brew install datawire/blackbird/telepresence 2.配置 目录kubectl 将使用默认的 kubeconfig 文件:$HOME/.kube/config 创建文件夹&…...
 — 训练机器学习模型用GPU还是NUP更有优势(基于文心一言的回答))
今日思考(2) — 训练机器学习模型用GPU还是NUP更有优势(基于文心一言的回答)
前言 深度学习用GPU,强化学习用NPU。 1.训练深度学习模型,强化学习模型用NPU还是GPU更有优势 在训练深度学习模型时,GPU相比NPU有优势。GPU拥有更高的访存速度和更高的浮点运算能力,因此更适合深度学习中的大量训练数据、大量矩阵…...

8.3 C++ 定义并使用类
C/C语言是一种通用的编程语言,具有高效、灵活和可移植等特点。C语言主要用于系统编程,如操作系统、编译器、数据库等;C语言是C语言的扩展,增加了面向对象编程的特性,适用于大型软件系统、图形用户界面、嵌入式系统等。…...

Git学习笔记——超详细
Git笔记 安装git: apt install git 创建版本库: git init 添加文件到版本库: git add 文件 提交文件到仓库: git commit -m “注释” 查看仓库当前的状态信息: git status 查看修改内容和之前版本的区别&am…...
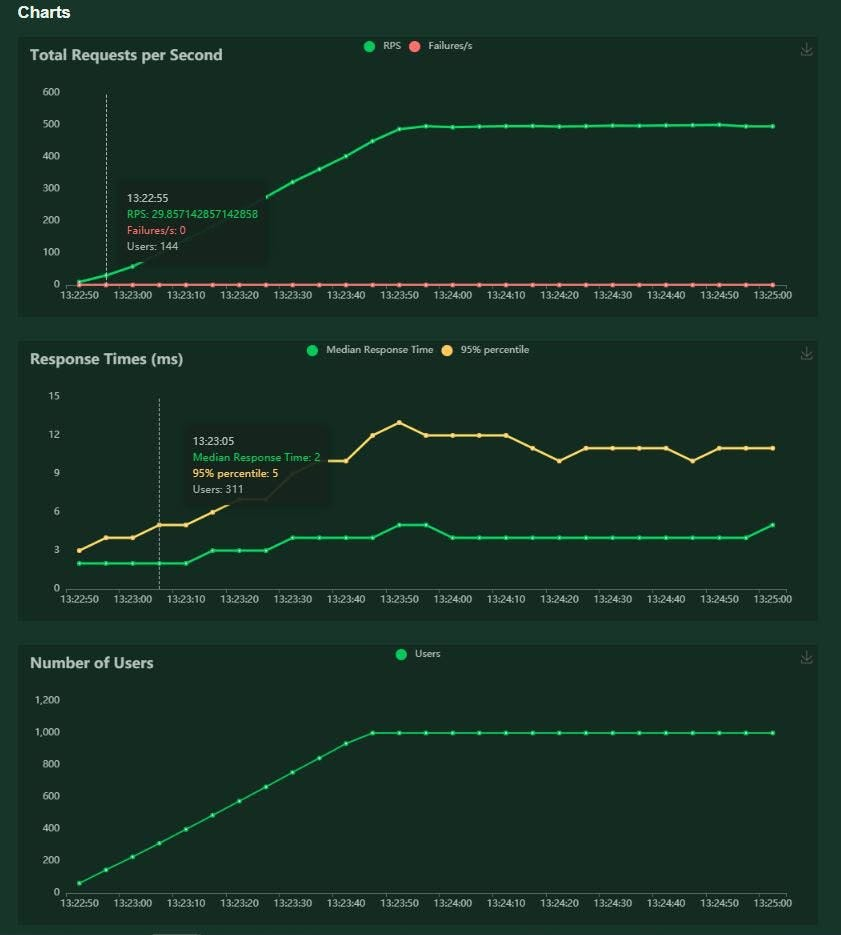
Locust负载测试工具实操
本中介绍如何使用Locust为开发的服务/网站执行负载测试。 Locust 是一个开源负载测试工具,可以通过 Python 代码构造来定义用户行为,避免混乱的 UI 和臃肿的 XML 配置。 步骤 设置Locust。 在简单的 HTTP 服务上模拟基本负载测试。 准备条件 Python…...
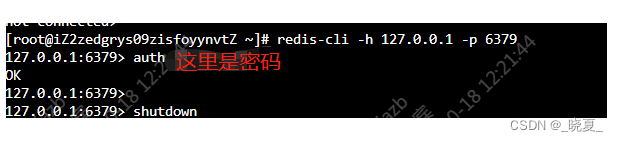
关闭mysql,关闭redis服务
1. 关闭redis服务: 查询redis安装目录: whereis redis which redis find / -name redis 关闭redis服务: redis-cli -h 127.0.0.1 -p 6379 auth 输入密码 shutdown 关闭redis服务 2. 关闭mysql服务: 查询mysql安装目录&…...

微机原理:汇编语言语句类型与格式
文章目录 壹、语句类型1、语句分类2、常用伪代码和运算符2.1数据定义伪指令2.1.1字节定义伪指令DB(8位)2.1.2字定义伪指令DW(16位)2.1.3双字节伪指令DD2.1.4 多字节定义DF/DQ/DT(了解) 2.2 常用运算符2.2.1…...

iOS Flutter Engine源码调试和修改
iOS Flutter Engine源码调试和修改 1. 前提:2. 步骤:3. 参考资料 1. 前提: 已将成功安装deop_tools工具已经通过gclient命令同步好flutter engine源码 2. 步骤: 进入engine/src目录 创建flutter engine构建文件 真机文件debug模式: ./flu…...
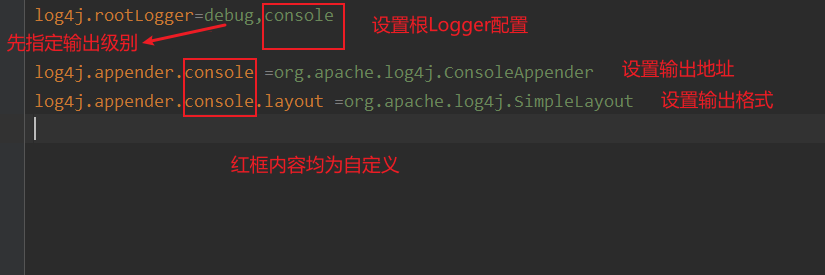
Java日志系统之Log4j
目录 Log4J Log4j的简单使用 日志级别 Log4j的组件 Loggers Appenders Layout Layout格式 设置配置文件加载 配置文件解析 Log4J 是Apache下开源的日志框架 Log4j的简单使用 Testpublic void testLog4J(){Logger logger Logger.getLogger(Log4jTest.class);logger…...

Windows11系统安装WSL教程
WSL,全称Windows Subsystem for Linux,是微软官方提供的可以在Windows上直接运行的Linux环境,包括大多数命令行工具、程序和应用,由系统底层虚拟机平台支持。 开启相关服务 1、控制面板-启用或关闭Windows功能 2、勾选以下两个…...

别再手动敲代码了!用STM32CubeMX图形化配置STM32F103C8T6,5分钟点亮你的第一个LED
5分钟极速入门STM32开发:用CubeMX图形化点亮LED的完整指南 第一次拿到STM32开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为从51单片机转型过来的开发者,面对STM32复杂的时钟树和寄存器配置,曾经连续三天都没能让一个LED闪烁…...

ALLWEONE Plate编辑器集成教程:打造专业文本编辑体验
ALLWEONE Plate编辑器集成教程:打造专业文本编辑体验 【免费下载链接】presentation-ai ALLWEONE Open source AI presentation generator Gamma Alternative. Create professional slides with customizable themes and AI-generated content in minutes. 项目地…...

Qwen3.5-9B-GGUF镜像部署:Supervisor配置autostart=true生效验证
Qwen3.5-9B-GGUF镜像部署:Supervisor配置autostarttrue生效验证 1. 项目背景与技术特点 Qwen3.5-9B-GGUF是基于阿里云通义千问3.5开源模型(2026年3月发布)的量化版本,采用GGUF格式进行优化。该模型具有以下核心特性:…...
)
CentOS 7上Spark 3.2.3单机版安装保姆级教程(附Python3.8.5和Hadoop2.10.2环境检查清单)
CentOS 7下Spark 3.2.3单机环境全流程部署指南 在当今数据驱动的时代,掌握大数据处理框架已成为开发者的必备技能。Apache Spark凭借其内存计算优势和丰富的生态支持,成为众多企业构建数据处理平台的首选。本文将带领初学者在CentOS 7系统上完成Spark 3.…...

如何快速突破百度网盘限速:Python直链解析工具的完整实战指南
如何快速突破百度网盘限速:Python直链解析工具的完整实战指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘直链解析工具(baidu-wangpan-par…...
)
SpringBoot + JAIN-SIP 实战:手把手教你搭建国标GB28181摄像头管理后台(附完整代码)
SpringBoot与JAIN-SIP构建国标GB28181平台实战指南 1. 国标视频监控平台的技术架构解析 GB28181标准作为国内视频监控领域的核心协议,定义了设备互联的完整规范体系。这套标准主要包含三个关键组成部分: SIP信令控制层:负责设备注册、会话…...

模型审计师崛起:AI可解释性需求
从黑盒到白盒,测试专业的新疆域在人工智能技术以前所未有的深度渗透到软件研发全流程的今天,传统的软件测试边界正在被重新定义。过去,测试工程师的核心职责是验证代码逻辑、保障功能正确性与系统稳定性。然而,随着AI模型从辅助工…...

一键下载网页视频:Video Download Helper 高效实用指南
一键下载网页视频:Video Download Helper 高效实用指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页视频而…...

VisionMaster通讯配置避坑指南:从TCP/IP到Modbus,手把手搞定设备连接与数据解析
VisionMaster工业通讯实战:从协议配置到故障排查的全链路指南 工业视觉系统的通讯链路如同神经网络,任何一处信号阻滞都可能导致整个生产线瘫痪。上周在汽车零部件检测项目中,我们遇到PLC与VisionMaster之间频繁断连的问题——产线每运行37分…...

5分钟掌握Diff Checker:免费跨平台文本差异对比神器
5分钟掌握Diff Checker:免费跨平台文本差异对比神器 【免费下载链接】diff-checker Desktop application to compare text differences between two files (Windows, Mac, Linux) 项目地址: https://gitcode.com/gh_mirrors/di/diff-checker 还在为代码修改、…...