Detr源码解读(mmdetection)
Detr源码解读(mmdetection)
1、原理简要介绍
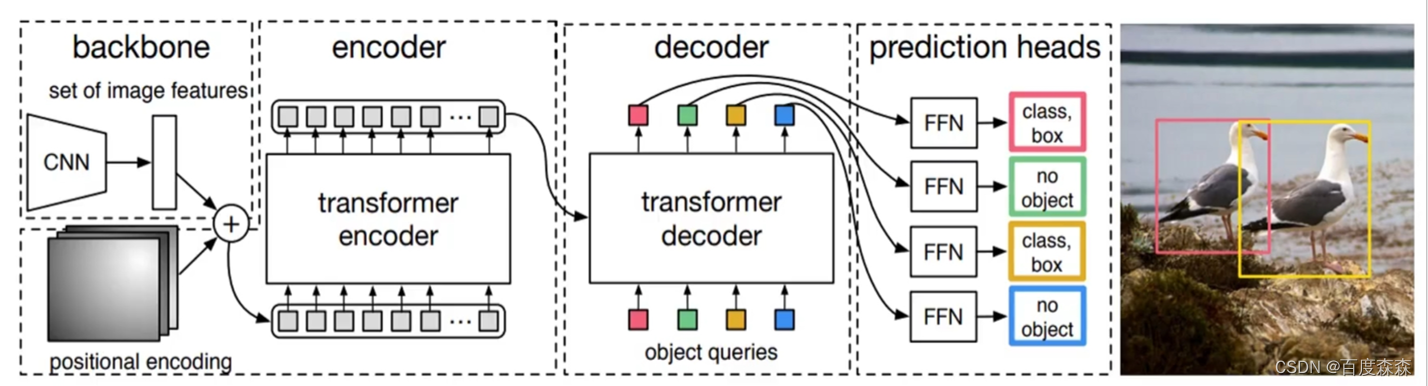
整体流程: 在给定一张输入图像后,1)特征向量提取: 首先经过ResNet提取图像的最后一层特征图F。注意此处仅仅用了一层特征图,是因为后续计算复杂度原因,另外,由于仅用最后一层特征图,故对小目标检测不友好,这也是后续deformable detr改进的原因。 2)添加位置编码信息: 经F拉平成一维张量并添加上位置编码信息得到I。3)Transformer中encoder部分4)Transformer中decoder部分,学习位置嵌入object queries。5)FFN部分:6)后续匈牙利匹配+损失计算。
2、mmdetection中源码介绍
2.1. 整体逻辑
Detr的内部逻辑如下:在mmdet/models/detector/single_stage.py。即首先提取图像特征向量,之后经过DetrHead来计算最终的损失。img[b,3,224,224] x[b,2048,7,7]
def forward_train(self,img,img_metas,gt_bboxes,gt_labels,gt_bboxes_ignore=None):super(SingleStageDetector, self).forward_train(img, img_metas)# img[b,3,224,224] x[b,2048,7,7]x = self.extract_feat(img) # 提取图像特征向量 # 经过DetrHead得到loss losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,gt_labels, gt_bboxes_ignore)return losses
forward_train
跟其他的检测头差不多,先是调用自己,也就是自身的 forward 函数,得到输出的 class label 和 reg coordinate,再调用自身的 loss 函数,不过这里是重载了一下,将 img_meta 传输进了 forward 函数的参数。执行完outs = self(x, img_metas)跳转到forward的num_levels = len(feats)
def forward_train(self,x,img_metas,gt_bboxes,gt_labels=None,gt_bboxes_ignore=None,proposal_cfg=None,**kwargs):"""Forward function for training mode.Args:x (list[Tensor]): Features from backbone.img_metas (list[dict]): Meta information of each image每个图像的元信息, e.g.,image size, scaling factor, etc.gt_bboxes (Tensor): Ground truth bboxes of the image,图像的地面真相框shape (num_gts, 4).gt_labels (Tensor): Ground truth labels of each box,shape (num_gts,).gt_bboxes_ignore (Tensor): Ground truth bboxes to be ignored,要忽略的基本事实框,shape (num_ignored_gts, 4).proposal_cfg (mmcv.Config): Test / postprocessing configuration,测试/后处理配置if None, test_cfg would be used.Returns:dict[str, Tensor]: A dictionary of loss components.损失成分词典。"""assert proposal_cfg is None, '"proposal_cfg" must be None'outs = self(x, img_metas) #x[b,2048,7,7]if gt_labels is None:loss_inputs = outs + (gt_bboxes, img_metas)else:loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)return losses
执行完outs = self(x, img_metas)跳转到forward的num_levels = len(feats)。feats[b,2048,7,7]
def forward(self, feats, img_metas):#这里默认为1,因为DETR默认用最后一层特征图num_levels = len(feats)img_metas_list = [img_metas for _ in range(num_levels)]return multi_apply(self.forward_single, feats, img_metas_list)
执行完return multi_apply(self.forward_single, feats, img_metas_list)跳转到forward_single函数
2.2. 图像特征向量提取
mmdet中提取图像特征向量的config配置文件如下,可以发现用ResNet50并只提取了最后一层特征层,即out_indices=(3,)。骨干网络会输出特征图的1/32,输入为【2,3,224,224】。通过backbone后得到图像大小为【2, 2048, 7, 7】和mask大小为【2,7,7】
backbone=dict(type='ResNet',depth=50,num_stages=4,out_indices=(3, ), # detr仅要resnet50的最后一层特征图,并不需要FPNfrozen_stages=1,norm_cfg=dict(type='BN', requires_grad=False),norm_eval=True,style='pytorch',init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'))
2.3. 给图像特征向量添加位置编码信息(forward_single函数,里面是 head 前向的逻辑)。
本部分代码来自mmdet/models/dense_heads/detr_head.py的 forward_single函数中。
mmdet中生成位置编码信息借助的是mask矩阵(所谓的mask就是为了统一批次大小而对图像进行了pad,被填充的部分在后续计算多头注意力时应该舍弃)故需要一个mask矩阵遮挡住,具体形状为[batch, h,w]这里先贴下生成mask的过程:
batch_size = x.size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']# 一个批次图像大小
# 先将 mask 设置为全 1
masks = x.new_ones((batch_size, input_img_h, input_img_w)) # [b,224,224]
# 对每一张图来说,在原来图片有像素的地方把 mask 置 0
# 因此 mask 中 padding 的地方才是 1
for img_id in range(batch_size):img_h, img_w, _ = img_metas[img_id]['img_shape'] # 创建了一个mask,非0代表无效区域, 0 代表有效区域masks[img_id, :img_h, :img_w] = 0 # 将pad部分置为1,非pad部分置为0.
输入图像的经过resnet50下采样后hw已经变了,所以还需进一步将mask下采样成和图像特征向量一样的shape。代码如下:
# 将每一层的特征图先投影到指定的特征维度,2048通道太多了转成256通道
x = self.input_proj(x) #Conv2d(self.in_channels, self.embed_dims, kernel_size=1)#[b,256,7,7]
# interpolate masks to have the same spatial shape with x
masks = F.interpolate( #masks[b,7,7]masks.unsqueeze(1), size=x.shape[-2:]).to(torch.bool).squeeze(1) # masks和x的shape一样:[b,2,2]
后续便可以生成位置编码部分(mmdet/models/utils/position_encoding.py),代码里采用了sine位置编码,该函数给masks的每个像素位置生成了一个256维的唯一的位置向量。shape:[B, 256, 7, 7]
# position encoding
pos_embed = self.positional_encoding(masks)
2.4 送入Transformer
4.1. 整体逻辑
在得到图像特征向量x=[b,256,7,7]、masks[b,7,7]矩阵以及位置编码pos_embed[b,256,7,7]后,便可送入Transformer。进入transformer的之前四个变量维度分别为, x->[2, 256, 7, 7],mask->[2, 7, 7],query_embed->[100, 256],pos_embed->[2, 256, 7, 7]
# outs_dec: [nb_nb_decdec, bs, num_query, embed_dim]
outs_dec, _ = self.transformer(x, masks, self.query_embedding.weight,pos_embed)
在进入transformer之前,定义了一个query_embed(就是后边的object query),其第一个维度为num_queries(原文解释为一张图片里的最大检测数量),第二个维度为hidden_dim,就是256。
self.query_embedding = nn.Embedding(self.num_query, self.embed_dims)
关键是理清encoder和decoder的QKV分别指啥, 本部分代码来自mmdet\models\utils\transformer.py的 Transformer函数中。看代码:
bs, c, h, w = x.shape# use `view` instead of `flatten` for dynamically exporting to ONNXx = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c] [49,2,256]pos_embed = pos_embed.view(bs, c, -1).permute(2, 0, 1) # [49,2,256]query_embed = query_embed.unsqueeze(1).repeat( #[100,b,256]1, bs, 1) # [num_query, dim] -> [num_query, bs, dim]mask = mask.view(bs, -1) # [bs, h, w] -> [bs, h*w] [2,49]"""经过变换后的四个变量维度分别为, img->[49, 2, 256],mask->[2, 49],query_embed->[100, 2, 256],pos_embed->[49, 2, 256]"""memory = self.encoder(query=x, # [49,b,256]key=None,value=None,query_pos=pos_embed, # [49,b,256]query_key_padding_mask=mask) # [b,49]target = torch.zeros_like(query_embed) # decoder初始化全0# out_dec: [num_layers, num_query, bs, dim]out_dec = self.decoder(query=target, # 全0的target, 后续在MultiHeadAttn中执行了key=memory, # query = query + query_pos又加回去了。value=memory,key_pos=pos_embed,query_pos=query_embed, # [num_query, bs, dim]key_padding_mask=mask)# outs_dec: [nb_nb_decdec, bs, num_query, embed_dim] [6,2,100,256]out_dec = out_dec.transpose(1, 2)memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)return out_dec, memory
其中encoder中q就是x,kv分别为None,query_pos代表位置编码,而query_key_padding_mask就是mask。decoder的q是全0的target,后续decoder会迭代更新q,而kv则 是memory,即encoder的输出;key_pos依旧是k的位置信息;query_embed即论文中Object query,可学习位置信息;key_padding_mask依然是mask。
4.2. encoder部分
先看下encoder初始化部分,内部循环调用了6次BaseTransformerLayer,因此只需讲解一层EncoderLayer即可。将img,mask,pos_embed送入transformer encoder中,进行注意力操作。得到[49, 2, 256]的输出
encoder=dict(type='DetrTransformerEncoder',num_layers=6, # 经过6层Layertransformerlayers=dict( # 每层layer内部使用多头注意力type='BaseTransformerLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256, num_heads=8,dropout=0.1)],feedforward_channels=2048, # FFN中间层的维度 ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'ffn', 'norm'))), # 定义运算流程
先跳转到mmdet\models\utils\transformer.py的DetrTransformerEncoder函数。再来看下BaseTransformerLayer的forward部分。该部分可以损失detr的核心部分了,因为本质上mmdet内部只是封装了pytorch现有的nn.MultiHeadAtten函数。所以,需要理解nn.MultiHeadAttn中两种mask参数的含义,限于篇幅原因,这里可参考nn.Transformer来理解这两个mask。 不过简单理解就是:attn_mask在detr中没用到,仅用key_padding_mask。attn_mask是为了遮挡未来文本信息用的,而图像可以看到全部的信息,因此不需要用attn_mask。
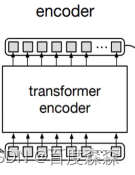
def forward(self,query,key=None,value=None,query_pos=None,key_pos=None,attn_masks=None,query_key_padding_mask=None,key_padding_mask=None,**kwargs):#Forward function for `TransformerDecoderLayer`.norm_index = 0attn_index = 0ffn_index = 0identity = queryif attn_masks is None:attn_masks = [None for _ in range(self.num_attn)]elif isinstance(attn_masks, torch.Tensor):attn_masks = [copy.deepcopy(attn_masks) for _ in range(self.num_attn)]warnings.warn(f'Use same attn_mask in all attentions in 'f'{self.__class__.__name__} ')else:assert len(attn_masks) == self.num_attn, f'The length of ' \f'attn_masks {len(attn_masks)} must be equal ' \f'to the number of attention in ' \f'operation_order {self.num_attn}'for layer in self.operation_order: # 遍历config文件的顺序if layer == 'self_attn':temp_key = temp_value = query query = self.attentions[attn_index]( # 内部调用nn.MultiHeadAttnquery,temp_key,temp_value,identity if self.pre_norm else None,query_pos=query_pos, # 若有位置编码信息则和query相加 key_pos=query_pos, # 若有位置编码信息则和key相加 attn_mask=attn_masks[attn_index],key_padding_mask=query_key_padding_mask,**kwargs)attn_index += 1identity = queryelif layer == 'norm':query = self.norms[norm_index](query) # 层归一化norm_index += 1elif layer == 'cross_attn': # decoder用到query = self.attentions[attn_index]( query,key,value,identity if self.pre_norm else None,query_pos=query_pos, # 若有位置编码信息则和query相加 key_pos=key_pos, # 若有位置编码信息则和key相加 attn_mask=attn_masks[attn_index],key_padding_mask=key_padding_mask,**kwargs)attn_index += 1identity = queryelif layer == 'ffn': # 残差连接加全连接层query = self.ffns[ffn_index](query, identity if self.pre_norm else None)ffn_index += 1return query
decoder部分和encoder流程类似,只是多了交叉注意力。decoder部分将[49,2,256]的输出和query_embed[100,2,256]输入到transformer decoder中,得到[6, 2, 100, 256]的输出。这里是合并了6个不同层级解码层的输出,其实只需要最后一层即可。
decoder这里其实是将query_embed和feature做了注意力机制,q为query_embed[100, 2, 256],k为memory也就是feature[49, 2, 256],v也是memory[49, 2, 256]。
**
总结
**
decoder的输出经过Prediction feed-forward networks (FFNs)生成最终的预测。即[6,2,100,256]经过线性层生成[6,2,100,92]的类别预测,经过线性层生成[6, 2, 100, 4]的框坐标预测。
由于后续在detr上改进的论文对匈牙利算法以及loss计算改动不大,因此这部分代码就不讲解了。
相关文章:
Detr源码解读(mmdetection)
Detr源码解读(mmdetection) 1、原理简要介绍 整体流程: 在给定一张输入图像后,1)特征向量提取: 首先经过ResNet提取图像的最后一层特征图F。注意此处仅仅用了一层特征图,是因为后续计算复杂度原因,另外&am…...
一个.Net Core开发的,撑起月6亿PV开源监控解决方案
更多开源项目请查看:一个专注推荐.Net开源项目的榜单 项目发布后,对于我们程序员来说,项目还不是真正的结束,保证项目的稳定运行也是非常重要的,而对于服务器的监控,就是保证稳定运行的手段之一。对数据库、…...
C语言数据结构初阶(2)----顺序表
目录 1. 顺序表的概念及结构 2. 动态顺序表的接口实现 2.1 SLInit(SL* ps) 的实现 2.2 SLDestory(SL* ps) 的实现 2.3 SLPrint(SL* ps) 的实现 2.4 SLCheckCapacity(SL* ps) 的实现 2.5 SLPushBack(SL* ps, SLDataType x) 的实现 2.6 SLPopBack(SL* ps) 的实现 2.7 SLP…...
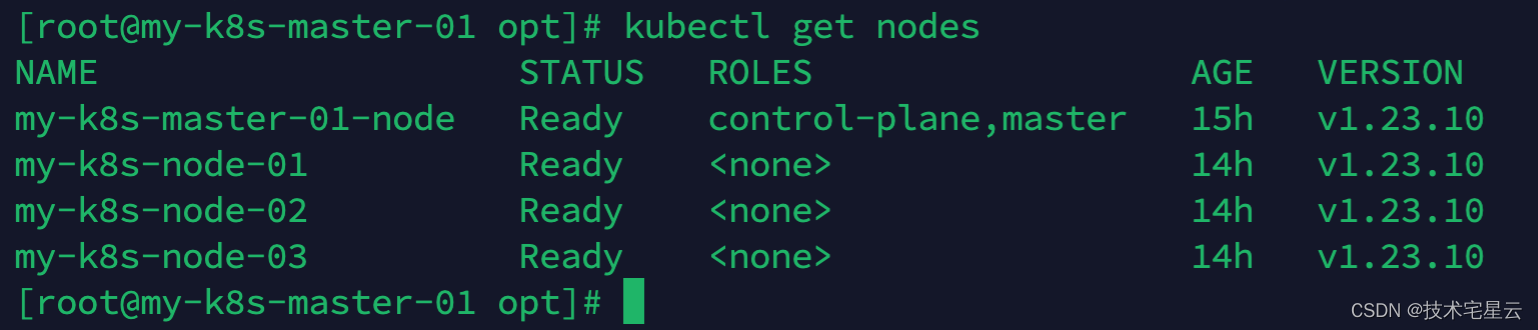
K8S常用命令速查手册
K8S常用命令速查手册一. K8S日常维护常用命令1.1 查看kubectl版本1.2 启动kubelet1.3 master节点执行查看所有的work-node节点列表1.4 查看所有的pod1.5 检查kubelet运行状态排查问题1.6 诊断某pod故障1.7 诊断kubelet故障方式一1.8 诊断kubelet故障方式二二. 端口策略相关2.1 …...

Linux系统下命令行安装MySQL5.6+详细步骤
1、因为想在腾讯云的服务器上创建自己的数据库,所以我在这里是通过使用Xshell 7来连接腾讯云的远程服务器; 2、Xshell 7与服务器连接好之后,就可以开始进行数据库的安装了(如果服务器曾经安装过数据库,得将之前安装的…...
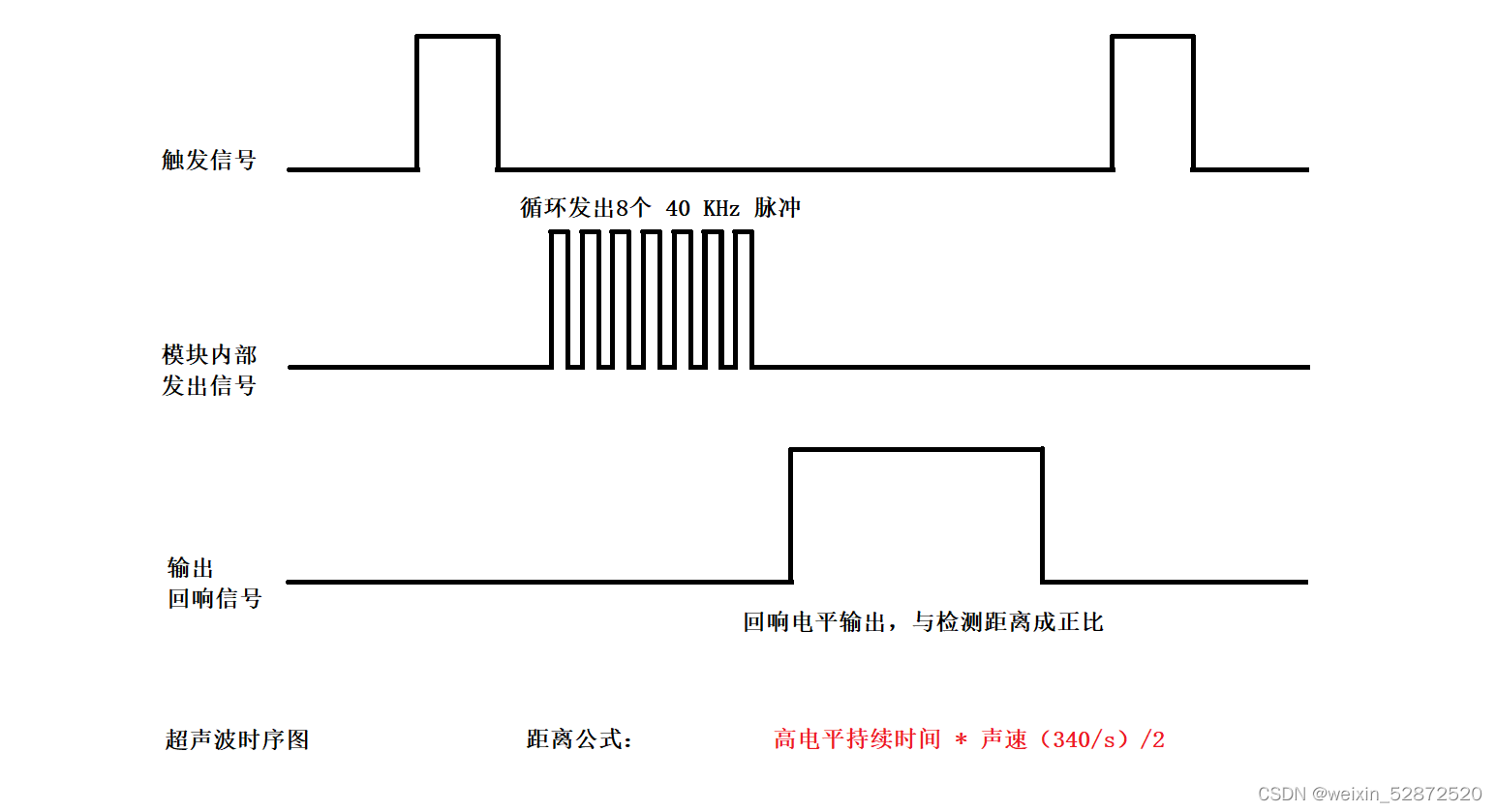
13.STM32超声波模块讲解与实战
目录 1.超声波模块讲解 2.超声波时序图 3.超声波测距步骤 4.项目实战 1.超声波模块讲解 超声波传感器模块上面通常有两个超声波元器件,一个用于发射,一个用于接收。电路板上有4个引脚:VCC GND Trig(触发)ÿ…...

逆向之Windows PE结构
写在前面 对于Windows PE文件结构,个人认为还是非常有必要掌握和了解的,不管是在做逆向分析、免杀、病毒分析,脱壳加壳都是有着非常重要的技能。但是PE文件的学习又是一个非常枯燥过程,希望本文可以帮你有一个了解。 PE文件结构…...

ACL是什么
目录 一、ACL是什么 二、ACL的使用:setacl与getacl 1)针对特定使用者的方式: 1. 创建acl_test1后设置其权限 2. 读取acl_test1的权限 2)针对特定群组的方式: 3)针对有效权限 mask 的设置方式…...
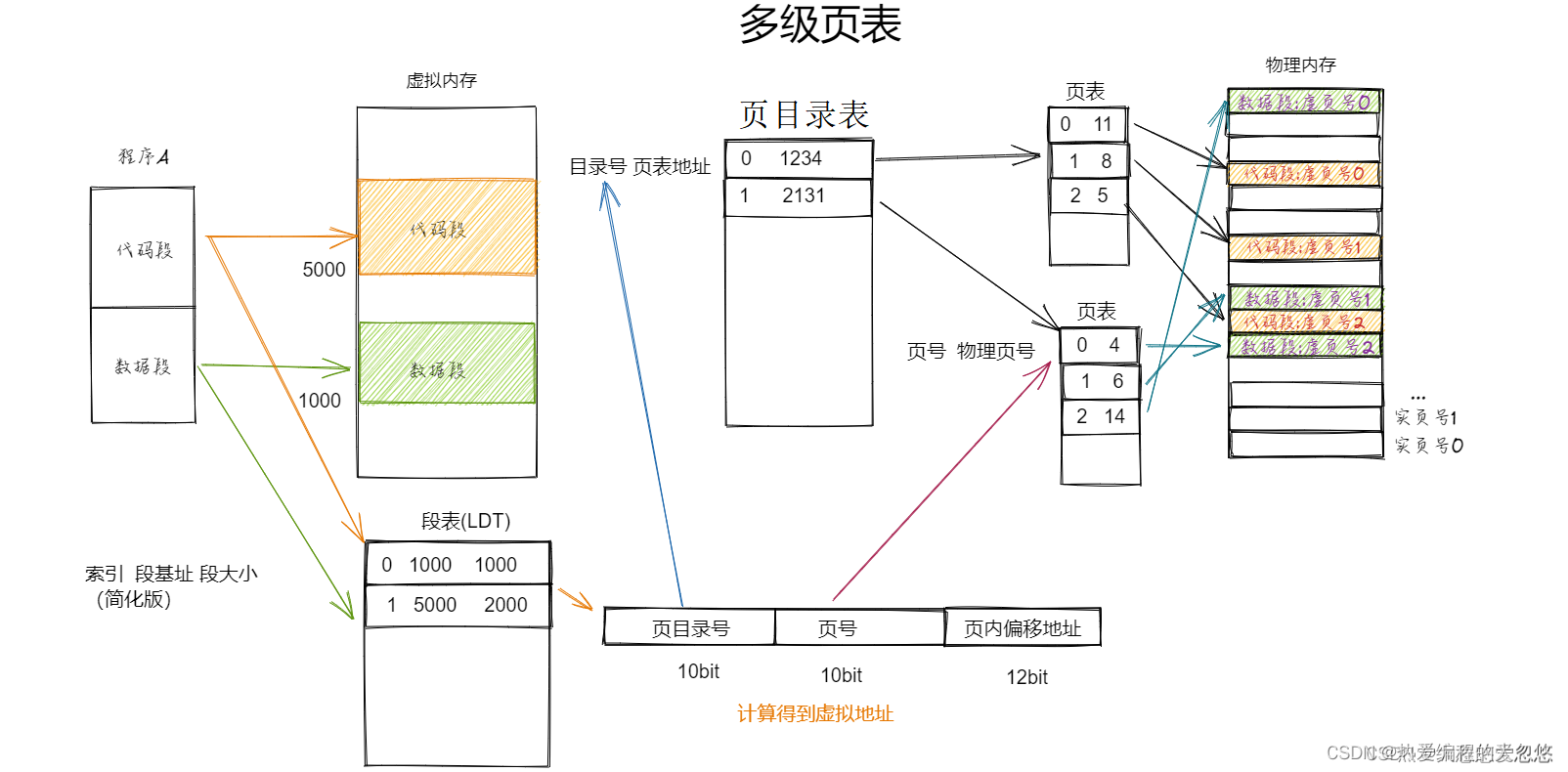
操作系统核心知识点整理--内存篇
操作系统核心知识点整理--内存篇按段对内存进行管理内存分区内存分页为什么需要多级页表TLB解决了多级页表什么样的缺陷?TLB缓存命中率高的原理是什么?段页结合: 为什么需要虚拟内存?虚拟地址到物理地址的转换过程段页式管理下程序如何载入内存?页面置…...
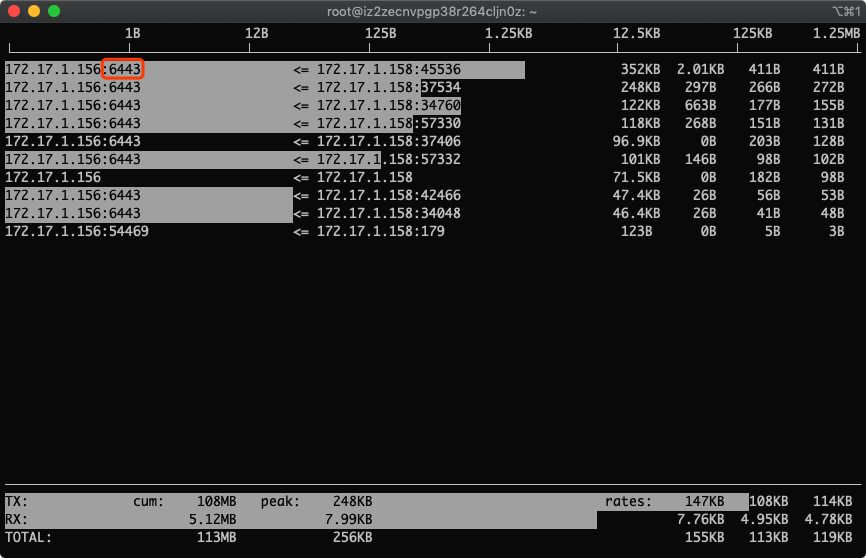
从零开始学习iftop流量监控(找出服务器耗费流量最多的ip和端口)
一、iftop是什么iftop是类似于top的实时流量监控工具。作用:监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等官网:http://www.ex-parrot.com/~pdw/iftop/二、界面说明>代表发送数据,< 代表接收数…...

第一篇博客------自我介绍篇
目录🔆自我介绍🔆学习目标🔆如何学习单片机Part 1 基础理论知识学习Part 2 单片机实践Part 3 单片机硬件设计🔆希望进入的公司🔆结束语🔆自我介绍 Hello!!!我是一名即已经步入大二的计算机小白。 --------…...
)
No suitable device found for this connection (device lo not available(网络突然出问题)
当执行 ifup ens33 出现错误:[rootlocalhost ~]# ifup ens33Error: Connection activation failed: No suitable device found for this connection (device lo not available because device is strictly unmanaged).1解决办法:[rootlocalhost ~]# chkc…...
【算法设计技巧】分治算法
分治算法 用于设计算法的另一种常用技巧为分治算法(divide and conquer)。分治算法由两部分组成: 分(divide):递归解决较小的问题(当然,基准情况除外)治(conquer):然后,从子问题的解构建原问题的解。 传统上&#x…...

已解决kettle新建作业,点击保存抛出异常Invalid state, the Connection object is closed.
已解决kettle新建作业,点击保存进资源数据库抛出异常Invalid state, the Connection object is closed.的解决方法,亲测有效!!! 文章目录报错问题报错翻译报错原因解决方法联系博主免费帮忙解决报错报错问题 一个小伙伴…...

【设计模式】 工厂模式介绍及C代码实现
【设计模式】 工厂模式介绍及C代码实现 背景 在软件系统中,经常面临着创建对象的工作;由于需求的变化,需要创建的对象的具体类型经常变化。 如何应对这种变化?如何绕过常规的对象创建方法(new),提供一种“封装机制”来…...

深入浅出PaddlePaddle函数——paddle.arange
分类目录:《深入浅出PaddlePaddle函数》总目录 相关文章: 深入浅出TensorFlow2函数——tf.range 深入浅出Pytorch函数——torch.arange 深入浅出PaddlePaddle函数——paddle.arange 语法 paddle.arange(start0, endNone, step1, dtypeNone, nameNone…...

X86 ATT常用寄存器及其操作指令
X86 AT&T常用寄存器及其操作指令 常用寄存器 esp寄存器:当我们需要访问堆栈帧中的变量时,可以使用esp寄存器来获取堆栈帧的基址,以便能够正确地访问堆栈帧中的变量。ebp寄存器:当我们需要调用一个函数时,可以使用…...

Kotlin 高端玩法之DSL
如何在 kotlin 优雅的封装匿名内部类(DSL、高阶函数)匿名内部类在 Java 中是经常用到的一个特性,例如在 Android 开发中的各种 Listener,使用时也很简单,比如://lambda button.setOnClickListener(v -> …...

理光M2701复印机载体初始化方法
理光M2701基本参数: 产品类型:数码复合机 颜色类型:黑白 复印速度:单面:27cpm 双面:16cpm 涵盖功能:复印、打印、扫描 网络功能:支持无线、有线网络打印 接口类型:USB2.0…...
2.25Maven的安装与配置
一.Mavenmaven是一个Java世界中,非常知名的"工程管理工具"/构建工具"核心功能:1.管理依赖在进行一个A 操作之前,要先进行一个B操作.依赖有的时候是很复杂的,而且是嵌套的2.构建/编译(也是在调用jdk)3. 打包把java代码给构建成jar或者warjar就是一个特殊的压缩包…...

Wand-Enhancer:完全免费解锁WeMod Pro功能的终极解决方案
Wand-Enhancer:完全免费解锁WeMod Pro功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的付费限制而烦恼…...

VSCode Log Viewer插件进阶:除了看syslog,还能这样监控你的Nginx/Docker应用日志
VSCode Log Viewer插件进阶:全栈日志监控实战指南 当你同时维护着系统服务、Web服务器和容器化应用时,日志往往散落在不同角落。每次排查问题都要在多个终端窗口间切换,既低效又容易遗漏关键线索。今天我们就来解锁VSCode Log Viewer插件的高…...
)
Python 实现电脑垃圾自动清理工具(附完整源码)
最近很多朋友都在问:为什么电脑明明配置不差, 但用久了还是越来越卡?其实很多时候,并不是硬件问题。而是:临时文件过多缓存堆积回收站没清理系统垃圾越来越多于是我用 Python 写了一个:“电脑垃圾自动清理工…...
)
告别手动调时!用ESP8266+STM32F103ZET6打造自动校时RTC时钟(附完整代码)
基于ESP8266与STM32的智能时钟系统:从NTP同步到RTC校时的全链路实践 在物联网和嵌入式系统开发中,精确的时间同步往往是许多应用的基础需求。无论是数据记录、事件触发还是用户界面显示,一个"永不走时"的时钟系统都能显著提升产品的…...

夹矸煤层采煤机螺旋滚筒工作性能优化【附代码】
✨ 长期致力于夹矸煤层、螺旋滚筒、工作性能、可靠性、多目标优化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)离散元-有限元耦合截割模型与煤岩参…...

Agent 与 Chat 的区别及常见工具详解
1. 引言 在人工智能和大语言模型(LLM)快速发展的今天,我们经常听到“Chat”(聊天机器人)和“Agent”(智能体)这两个概念。虽然它们都基于大模型与用户进行交互,但在设计理念、能力边…...

XUnity.AutoTranslator:打破游戏语言障碍的终极解决方案
XUnity.AutoTranslator:打破游戏语言障碍的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏内容而苦恼吗?XUnity.AutoTranslator让语言障碍不再是问题&…...

合同系统业务功能
合同管理系统的核心是实现合同全生命周期管控,其生命周期主要分为五大环节:签订前管理、审批流程管理审批管理、合同签订、合同信息与文本管理、合同履约执行。 不同环节对应不同的功能需求,需结合企业业务特点灵活适配,以下是各环…...

嵌入式MCU流数据统计:Welford在线算法与定点数优化实践
1. 项目概述与核心挑战在嵌入式开发领域,尤其是面对那些主频几十兆赫兹、内存仅以KB计的低算力MCU时,我们常常需要处理来自传感器的连续数据流。计算这些数据的均值和方差,听起来像是统计学入门课的第一章,简单到让人几乎要忽略其…...

APK Installer终极指南:在Windows上轻松安装Android应用的完整解决方案
APK Installer终极指南:在Windows上轻松安装Android应用的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行An…...