Hadoop3教程(二十九):(生产调优篇)集群扩容及缩容(白名单与黑名单)
文章目录
- (150)添加白名单
- (151)服役新服务器
- (152)服务器间数据均衡
- (153)黑名单退役服务器
- 参考文献
这一章还算是比较重要的。
(150)添加白名单
白名单:在白名单里的主机IP地址,就可以用来存储数据以及互相之间的通信等。一般企业都会配置集群白名单,防止黑客攻击。
相应的,集群里也有黑名单,下几节会讲。
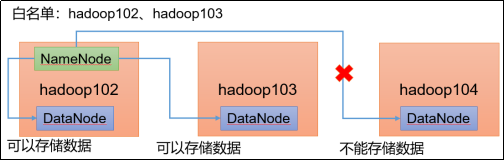
配置白名单步骤如下,仅做了解,所以直接复制的教程内容:
1)在NameNode节点的/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist和blacklist文件
(1)创建白名单
[atguigu@hadoop102 hadoop]$ vim whitelist
在whitelist中添加如下主机名称,假如集群正常工作的节点为102 103 :
hadoop102
hadoop103
(2)创建黑名单
[atguigu@hadoop102 hadoop]$ touch blacklist
暂时保持空的就可以
2)在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 白名单 --><property><name>dfs.hosts</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property><!-- 黑名单 --><property><name>dfs.hosts.exclude</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
3)分发配置文件whitelist,hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4)第一次添加白名单必须重启集群,如果不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
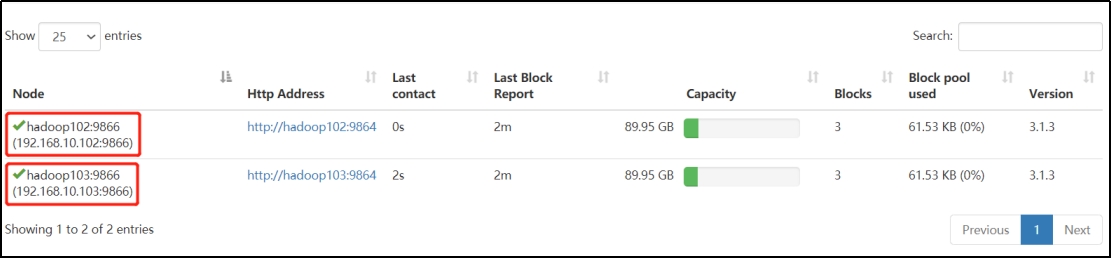
5)在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode\
6)在hadoop104上执行上传数据,失败
[atguigu@hadoop104 hadoop-3.1.3]$ hadoop fs -put NOTICE.txt /
7)二次修改白名单,增加hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容:
hadoop102
hadoop103
hadoop104
8)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
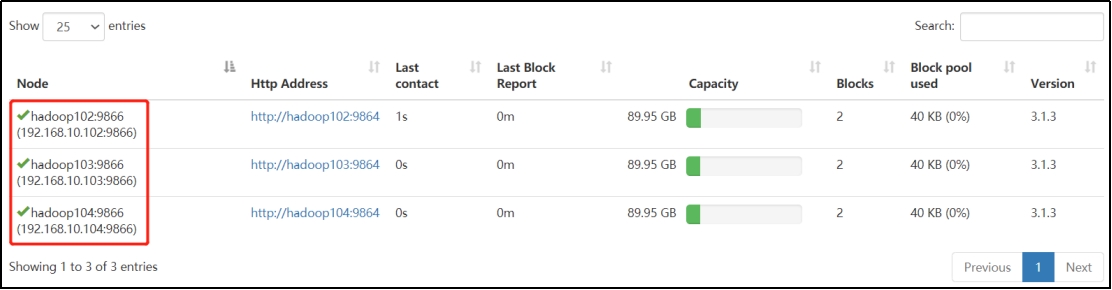
9)在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode\
(151)服役新服务器
这个场景还是很重要的,因为随着公司业务的增长,数据量越来越大,对计算资源的需求也越来越大,所以原有的节点可能已经不能满足现有的需求,因此往往需要在原有集群基础上,动态添加新的数据节点。可以参照淘宝双11。
下面内容也仅做了解。
首先需要准备一台新的节点:
- 在hadoop100主机上再克隆一台hadoop105主机;
- 修改IP地址和主机名称
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop105 ~]# vim /etc/hostname
- 拷贝hadoop102的/opt/module目录和/etc/profile.d/my_env.sh到hadoop105
[atguigu@hadoop102 opt]$ scp -r module/* atguigu@hadoop105:/opt/module/[atguigu@hadoop102 opt]$ sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/my_env.sh[atguigu@hadoop105 hadoop-3.1.3]$ source /etc/profile
- 删除hadoop105上Hadoop的历史数据,data和log数据
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
- 配置hadoop102和hadoop103到hadoop105的ssh无密登录
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop105[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop105
接下来就是把这台新节点动态加入当前集群:
直接启动DataNode,即可关联到集群(所谓的动态,要的就是不需要重启集群):
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
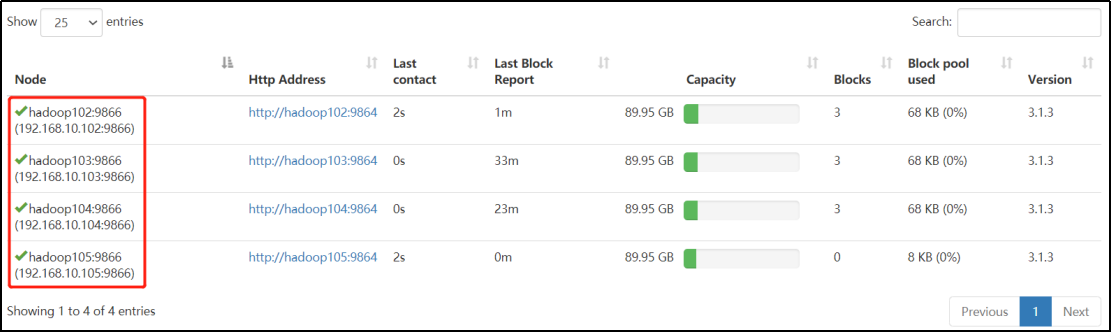
如果集群没有配置白名单的话,到上一步就结束了,如图可以看到节点已经加进去了。
但是如果配置了白名单,则还需要在白名单中增加新的节点:
(1)在白名单whitelist中增加hadoop104、hadoop105,并重启集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容:
hadoop102
hadoop103
hadoop104
hadoop105
(2)分发
[atguigu@hadoop102 hadoop]$ xsync whitelist
(3)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
最后可以测试下,往105节点上上传文件:
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /
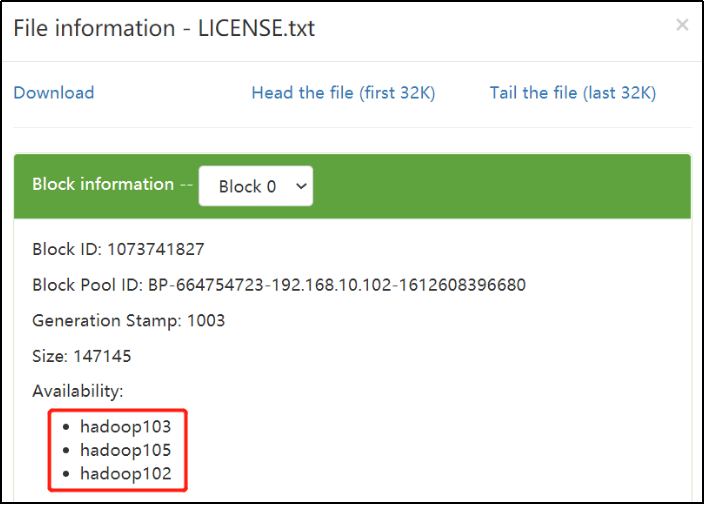
可以看到,成功,且共有3个副本。
(152)服务器间数据均衡
基于数据本地性原则,如果在102上提交数据的话,102上一般会保留该数据一个副本,然后其他副本会分散在其他节点上。既然如此,那我如果经常在102上提交数据,那102上存储的数据势必会比其他节点更多,这种情况下就需要进行服务器间的数据均衡。
还有一种情况,就是新服役的节点,存储的数据量自然会比老节点要少,这时候也需要做服务器间的数据均衡。
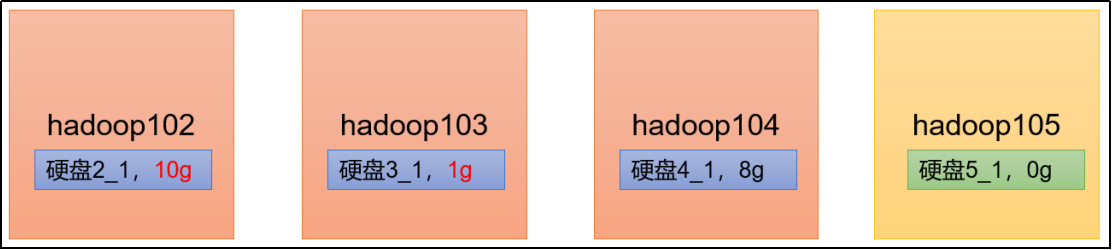
开启数据均衡的命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停用数据均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
需要注意,由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以尽量不要在NameNode所在节点执行start-balancer.sh,去找一台集群内比较空闲的机器,以免影响集群正常使用。
(153)黑名单退役服务器
什么是黑名单呢?
黑名单里的主机IP地址是不可以存储数据的。
相比白名单,黑名单的力度要弱一些,企业中一般是通过配置黑名单,用来动态退役服务器的(不需要重启集群)。
下面仅做了解,直接复制教程:
黑名单配置步骤如下:
1)编辑/opt/module/hadoop-3.1.3/etc/hadoop目录下的blacklist文件
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop105
注意:如果白名单中没有配置,需要在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 黑名单 --><property><name>dfs.hosts.exclude</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value></property>
2)分发配置文件blacklist,hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3)第一次添加黑名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodesRefresh nodes successful
4)检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点


5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意: 如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役

[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
stopping nodemanager
6)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(二十九):(生产调优篇)集群扩容及缩容(白名单与黑名单)
文章目录 (150)添加白名单(151)服役新服务器(152)服务器间数据均衡(153)黑名单退役服务器参考文献 这一章还算是比较重要的。 (150)添加白名单 白名单&#…...
NET7下用WebSocket做简易聊天室
NET7下用WebSocket做简易聊天室 步骤: 建立NET7的MVC视图模型控制器项目创建websocket之间通信的JSON字符串对应的实体类一个房间用同一个Websocketwebsocket集合类,N个房间创建websocket中间件代码Program.cs中的核心代码,使用Websocket聊…...

详解API基础知识
目录 什么是API: API 的设计原则包括: API 的开发流程包括以下几个步骤: API 的使用场景包括: API 的优势包括: 然而,API 也存在一些挑战和问题,例如: 什么是API: API(应用程…...
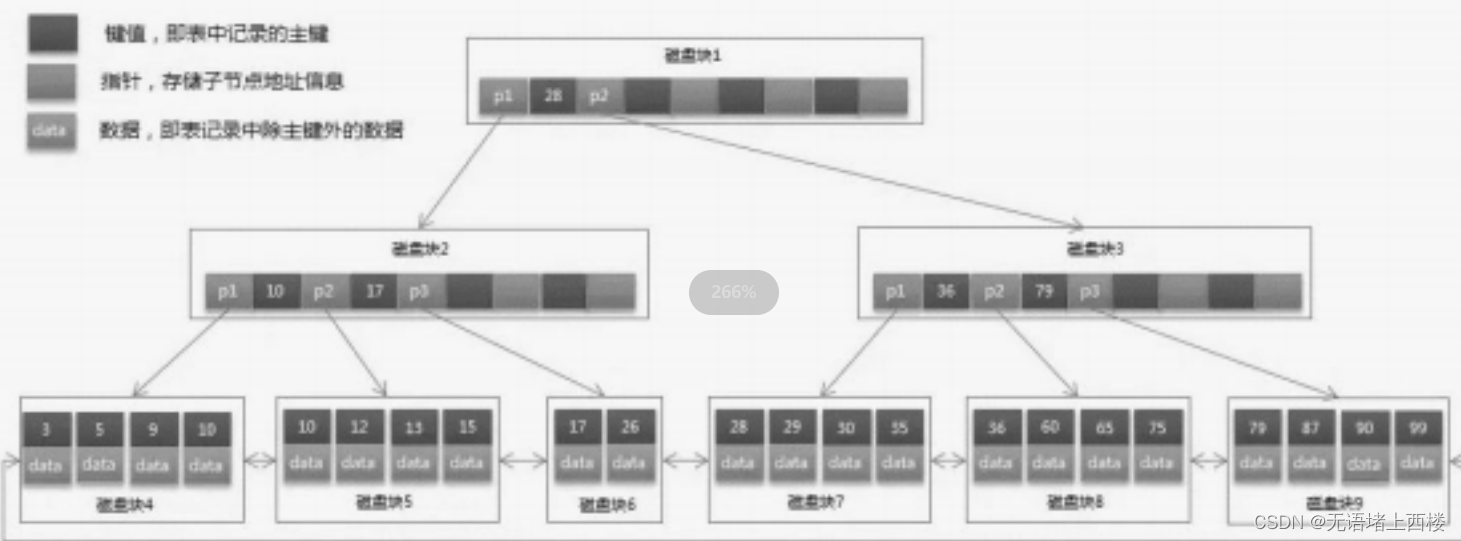
b树和b+树
二叉树和平衡二叉树 二叉树,每个节点支持两个分支的树结构,相比于单向链表,多了一个分支。 二叉查找树,在二叉树的基础上增加了一个规则,左子树的所有节点的值都小于它的根 节点,右子树的所有子节点都大于它…...
Linux 下 Java 安装字体方法
因上线访问图字体乱码了,因为在windows下设置的微软雅黑,linux默认是没有的,所以需要给jdk安装一个微软雅黑字体。按照步骤来,so easy! 1)首先找到windows下面的字体,不用去其他地方下了&#…...

敏捷开发的实施要素和实现敏捷的实际改进
敏捷开发的实施要素如下: 个体和交互:胜过过程和工具。可以工作的软件:胜过面面俱到的文档。客户合作:胜过合同谈判。响应变化:胜过遵循计划。 敏捷开发过程是一个增量的、迭代的过程,责任人、开发人…...
学会使用Pandas进行数据清洗
大家好,如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语,本文将向你介绍使用Pandas进行数据清洗的过程。我们的数据通常来自多个资源,而且并不干净,它可能包含缺失值、重复值、错误或不需要的格式等…...
Stable Diffusion WebUI扩展a1111-sd-webui-tagcomplete之Booru风格Tag自动补全功能详细介绍
安装地址 直接附上地址先: Ranting8323 / A1111 Sd Webui Tagcomplete GitCodeGitCode——开源代码托管平台,独立第三方开源社区,Git/Github/Gitlabhttps://gitcode.net/ranting8323/a1111-sd-webui-tagcomplete.git上面是GitCode的地址,下面是GitHub的地址,根据自身情…...

Linux中iostat命令
iostat命令是IO性能分析的常用工具,其是input/output statistics的缩写。 一、安装 yum install sysstat -y二、参数说明 -c: 显示CPU使用情况-d: 显示磁盘使用情况--dec{ 0 | 1 | 2 }: 指定要使用的小数位数,默认为 2-g GROUP_NAME { DEVICE [...] | A…...
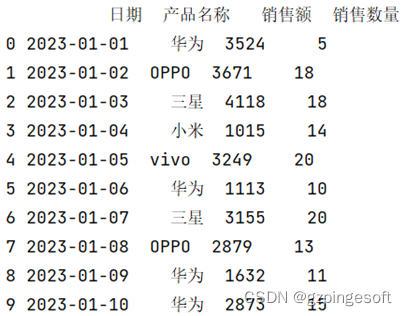
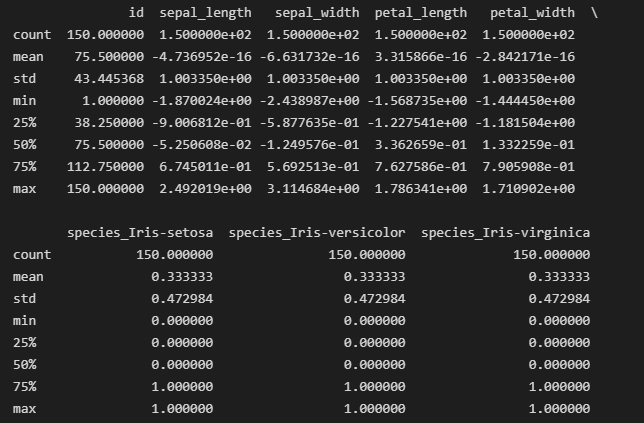
Pandas数据处理分析系列3-数据如何预览
Pandas-数据预览 Pandas 导入数据后,我们通常需要对数据进行预览,以便更好的进行数据分析。常见数据预览的方法如下: ①head() 方法 功能:读取数据的前几行,默认显示前5行 语法结构:df.head(行数) df1=pd.read_excel("销售表.xlsx",sheet_name="手机销…...

【汇编语言-王爽】第二章:寄存器
知识点 (一)寄存器 一个典型的CPU由运算器、控制器、寄存器等器件构成,这些器件靠内部总线相连。8086CPU有14个寄存器:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。其中AX、BX、CX、DX为通用寄存器,可…...
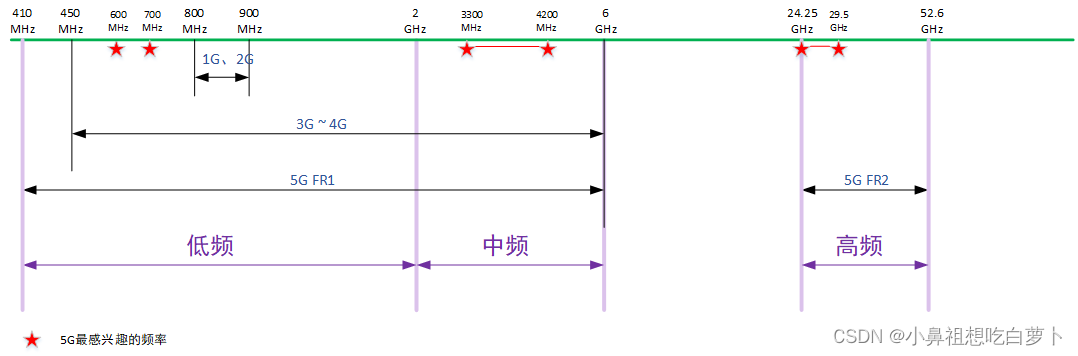
5G学习笔记之5G频谱
参考:《5G NR通信标准》1. 5G频谱 1G和2G移动业务的频段主要在800MHz~900MHz,存在少数在更高或者更低频段;3G和4G的频段主要在450MHz ~ 6GHz;5G主要是410MHz ~ 6GHz,以及24GHz ~ 52GHz。 5G频谱跨度较大,可…...

CSS 浮动布局
本文参考 https://blog.csdn.net/ZhangJiWei_2019/article/details/114669722 文档流简介 正常文档流 正常文档流,又称为“普通文档流”或“普通流”,也就是W3C标准所说的“normal flow”。 我们先来看一下正常文档流的简单定义:正常文档…...

CentOS 系统安装和使用Docker服务
系统环境 使用下面的命令,可以查看CentOS系统的版本。 lsb_release -a结果: 说明我的系统是7.9.2009版本的 安装Docker服务 依次执行下面的指令: yum install -y yum-utilsyum install -y docker即可安装docker服务 如果这样安装不成功…...
Docker-镜像的备份迁移及私有仓库的搭建
一、Docker-备份与迁移 A服务器系统配置 B服务器系统配置 1.用命令将容器保存为镜像。 案例,将A服务器的Docker容器迁移到另外一台服务器B,A服务器的容器配置过对应的文件,不想在B服务器重新搭建,可以使用该案例。 docker c…...
SQL数据库管理工具RazorSQL mac中文版特点与功能
RazorSQL mac是一款功能强大的SQL数据库管理工具,它支持多种数据库,包括MySQL、Oracle、Microsoft SQL Server、SQLite、PostgreSQL等。 RazorSQL mac 软件特点和功能 多种数据库支持:RazorSQL支持多种数据库,用户可以通过一个工…...

Unigui可以使用WebSocket进行客户端之间的实时互相发消息
Unigui可以使用WebSocket进行客户端之间的实时互相发消息。WebSocket是一种支持双向通信的网络协议,可以使客户端和服务器之间实时地进行数据交换。 实现步骤: 1. 在Unigui项目中添加WebSocket组件。 2. 在WebModule的OnCreate事件中开启WebSocket服务。 proced…...
Win32 简单日志实现
简单实现日志保存, 支持设置日志文件数量, 单个日志文件大小上限, 自动超时保存日志, 日志缓存超限保存 CLogUtils.h #pragma once#include <string> #include <windows.h> #include <vector> #include <map> #include <mutex> #include <tc…...

保姆级阿里云ESC服务器安装nodejs或Linux安装nodejs
1. 创建node文件夹 默认 /opt 下边 /opt/node 也可建到其他地方,如/usr/local/node 等 创建后切换到文件夹下 cd /opt/node cd /opt/node2. 下载node并解压 使用命令下载node wget https://nodejs.org/dist/v18.12.0/node-v18.12.0-linux-x64.tar.xz wget https…...

《动手学深度学习 Pytorch版》 9.3 深度循环神经网络
将多层循环神经网络堆叠在一起,通过对几个简单层的组合,产生一个灵活的机制。其中的数据可能与不同层的堆叠有关。 9.3.1 函数依赖关系 将深度架构中的函数依赖关系形式化,第 l l l 个隐藏层的隐状态表达式为: H t ( l ) ϕ l …...

**Shader优化实战:从冗余计算到性能跃升的极致之旅**在图形渲染领域,**Shader性能优化**早已不是锦上添花的技术
Shader优化实战:从冗余计算到性能跃升的极致之旅 在图形渲染领域,Shader性能优化早已不是锦上添花的技术点,而是决定项目成败的核心环节。尤其是在移动端、VR/AR或高帧率游戏开发中,一个低效的着色器可能直接导致掉帧、发热甚至崩…...

ionic 列表:全面解析与最佳实践
ionic 列表:全面解析与最佳实践 引言 随着移动应用的日益普及,开发高效、美观的移动应用界面变得尤为重要。Ionic 是一个开源的移动端应用开发框架,它基于 Angular、HTML5 和 CSS3,允许开发者使用 Web 技术快速构建跨平台的原生移…...

RS-485 以太网 CAN总线 应用场景差异
结论RS‑485:低成本、远距离、低速、半双工、简单工控,小设备点对点 / 小组网CAN 总线:多主、抗干扰、高可靠、实时性强,汽车、工业现场总线首选以太网:高速、大带宽、通用互联,大数据、远程、IT/OT 融合、…...

魔兽争霸III终极优化指南:用WarcraftHelper让经典游戏在现代电脑完美运行
魔兽争霸III终极优化指南:用WarcraftHelper让经典游戏在现代电脑完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽…...

从《流浪地球2》到实战:聊聊多无人机‘蜂群’任务分配的那些坑与最佳实践
从《流浪地球2》到实战:聊聊多无人机‘蜂群’任务分配的那些坑与最佳实践 科幻电影中无人机群如蜂群般协同作战的场景令人震撼,但现实中要让数百架无人机像训练有素的士兵一样默契配合,却远非按下启动键那么简单。去年参与某电网巡检项目时&a…...

三步解锁硬件隐藏性能:Universal x86 Tuning Utility完全指南
三步解锁硬件隐藏性能:Universal x86 Tuning Utility完全指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 你是…...

OptiSystem应用:光放大器EDFA的仿真
Optisystem可以设计和模拟光纤放大器和光纤激光器。此处展示的案例可在Optisystem安装文件夹samplesOptical amplifiers中找到。该教程将会介绍光放大器库这一部分。光放大器全局参数使用Optisystem的第一步是设置全局参数。我们都知道,主要的一个参数是time window…...

DJI Osmo Nano 4/5评测:小巧便携功能强,成冒险家与vlogger新宠!
优点- 设计紧凑轻便:适合冒险和日常使用。- 出色的视频录制:支持 4K/120fps 录制,搭配 D-Log M 配置文件,提供卓越的视频质量和编辑灵活性。- 内置存储与快充电池:内置存储方便使用,快充电池节省时间。缺点…...

高效论文降重方案:2026年TOP5平台极限功能对比,实测AIGC率降至5%以下!
CSDN 极客专栏 | AI与学术大撞击2026毕业季终极自救指南 博主前言: 距离今年各大高校的最终盲审提交只剩不到20天,每天都有同门私信问我:“学长,知网现在不仅查重,还查AIGC疑似率,我用降重软件改完后被判定…...

SAP ABAP开发避坑指南:BP业务伙伴的地址、银行、角色BAPI到底该怎么选?
SAP ABAP开发实战:BP业务伙伴BAPI选择策略与避坑技巧 每次打开SE37准备调用BP相关BAPI时,那些以BAPI_BUPA_开头的函数列表总让人眼花缭乱。上周刚踩过一个坑——用BAPI_BUPA_ADDRESS_CHANGE更新地址时,系统莫名其妙清空了邮政编码后三位。后来…...