lstm 回归实战、 分类demo
预备知识
- lstm 参数 输入、输出格式
nn.LSTM(input_dim,hidden_dim,num_layers); imput_dim = 特征数
input:(样本数、seq, features_num)
h0,c0 (num_layers,seq, hidden_num)
output: (样本数、seq, hidden_dim)
再加一个全连接层,将 output 中最后一维变成 目标输出的类别数 (样本数、seq、类别数)
参考:https://zhuanlan.zhihu.com/p/128927771
"""
https://github.com/yhannahwang/stock-prediction-on-lstm
https://zhuanlan.zhihu.com/p/128927771
"""# 回归
# 导入相关包
import numpy as np
import random
import pandas as pd
import matplotlib.pyplot as plt
from pandas import datetime
import math,time
import itertools
from sklearn import preprocessing
from sklearn.preprocessing import MinMaxScaler
import datetime
from operator import itemgetter
from sklearn.metrics import mean_squared_error
from math import sqrt
import torch
import torch.nn as nn
from torch.autograd import Variableclass LSTM(nn.Module):def __init__(self,input_dim,hidden_dim,num_layers,output_dim):super(LSTM,self).__init__()# Hidden dimensionsself.hidden_dim = hidden_dim# Number of hidden layersself.num_layers = num_layers# Building LSTM#batch_first=True #causes input/output tensors to be of shape (batch_dim, seq_dim, feature_dim)# DataLoader返回数据时候一般第一维都是batch,pytorch的LSTM层默认输入和输出都是batch在第二维self.lstm = nn.LSTM(input_dim,hidden_dim,num_layers,batch_first=True)# 最后一个输出层self.fc = nn.Linear(hidden_dim,output_dim) # 使用LSTM 时,最后一个全连接输出层另外写def forward(self,x):# initial hidden state with zeros#h0 = torch.zeros(self.num_layers,x.size(0),self.hidden_dim) # 什么情况下要初始化h0 ,什么情况下不用h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()# Initialize cell statec0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()# One time step# We need to detach as we are doing truncated backpropagation through time (BPTT)# If we don't, we'll backprop all the way to the start even after going through another batchout, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))out = self.fc(out)#lstm_out, _ = self.lstm(x)#out = self.fc(lstm_out) # out:(num,seq,target) # 初始化与不初始化有啥区别呢return out
# 4. 根据LSTM需要的数据格式来创造数据集。 Lstm 需要的输入是一个 3D array [x,y,z]。 其中x是样本数,y是seq length,即需要看多少天的数据,z是特征数。 ???
def create_seq_data(data_raw, seq):data_feat, data_target = [], []for index in range(len(data_raw) - seq):# 构建数据集data_feat.append(data_raw[['Open', 'High', 'Low', 'Close']][index:index + seq])# 构建target集data_target.append(data_raw['target'][index:index + seq])data_feat = np.array(data_feat) # (1808,20,4)data_target = np.array(data_target) # 转变成ndarraay 格式转出 转变成 (1808,20)data_target = data_target[:, :, np.newaxis] # 转变成 (1808,20,1)return data_feat, data_target# 5. 划分数据集 8:2
def train_test(data_feat, data_target, test_set_size, seq):train_size = data_feat.shape[0] - (test_set_size)trainX = torch.from_numpy(data_feat[:train_size].reshape(-1, seq, 4)).type(torch.Tensor) # 为了确认数据格式统一,再做一次 reshapetrainY = torch.from_numpy(data_target[:train_size].reshape(-1, seq, 1)).type(torch.Tensor)testX = torch.from_numpy(data_feat[train_size:].reshape(-1, seq, 4)).type(torch.Tensor)testY = torch.from_numpy(data_target[train_size:].reshape(-1, seq, 1)).type(torch.Tensor)return trainX, trainY, testX, testYdef TransformerToDataloader(trainX, trainY, testX, testY,batch_size):"""将数据转变成dataloader格式将X 和 y放在一起tranin_loader的大小 = 长度/batch_size"""# trainX trainY 放在一起变换train = torch.utils.data.TensorDataset(trainX, trainY) # 把feature 和 target 放在一起 # TensorDataset:1442test = torch.utils.data.TensorDataset(testX, testY) # TensorDataset:366train_loader = torch.utils.data.DataLoader(dataset=train,batch_size=batch_size,shuffle=False)# train_loader: DataLoader :46 1442/32test_loader = torch.utils.data.DataLoader(dataset=test,batch_size=batch_size,shuffle=False)# test_loader: DataLoader :12 366/32return train_loader,test_loaderif __name__ == '__main__':# 1. 加载数据dates = pd.date_range('2010-10-11','2017-10-11',freq ='B') # Q: 季度 Y:年 B:工作日df_main = pd.DataFrame(index=dates) # (1828,0)df_aaxj = pd.read_csv("C:\WORK\\xuxiu\learn\AI\stock-prediction-on-lstm-master\stock-prediction-on-lstm-master\data_stock\ETFs\\aaxj.us.txt", parse_dates=True, index_col=0) #(2325,6)df_main = df_main.join(df_aaxj) #(1828,6) # 只要目标范围内的数据sel_col = ['Open', 'High', 'Low', 'Close']df_main = df_main[sel_col] #(1828,4)# 2.归一化 两种方式,一种数据转换为 ndarry 的格式, 另外一种仍保持 dataframe的格式df_main = df_main.fillna(method='ffill') # pad/ffill:用前一个非缺失值去填充该缺失值 backfill/bfill:用下一个非缺失值填充该缺失值scaler = MinMaxScaler(feature_range=(-1,1))#df_main = scaler.fit_transform(df_main) # 目标项也会送进去训练,所以所有值都要进行归一化 数据格式变成了 ndarryfor col in sel_col:df_main[col] = scaler.fit_transform(df_main[col].values.reshape(-1, 1)) # 这种方法, df_main 还是 dataFrame的格式# 3. 创建需要预测的序列 target 因为我们要预测下一个时间的收盘价,所以把close向上shift1个单位df_main['target'] = df_main['Close'].shift(-1) # (1828,5) Index(['Open', 'High', 'Low', 'Close', 'target'], dtype='object')df_main.dropna()df_main = df_main.astype(np.float32)seq = 20test_set_size = int(np.round(0.2*df_main.shape[0]))# 4data_feat, data_target = create_seq_data(df_main,seq) # 所设定的每个时间区间是20天,通过高开低收4个来预测,datafeat的维度是(1808,20,4),对应的data_target的维度是(1808,20,1)# data_feat : (1808,20,4) data_target: (1808,20,1)# 5trainX, trainY, testX, testY = train_test(data_feat, data_target, test_set_size, seq) # ([1442,20,4])# 6 将数据转换成pytorch 可以接受的格式 通过dataloader 来读取数据,其中batch_size 等于要训练的样本树n_steps = seqbatch_size = 32num_epochs = 100train_loader,test_loader = TransformerToDataloader(trainX, trainY, testX, testY,batch_size)# 7 建立Lstm model#LSTM的参数主要有input_dim, hidden_dim, num_layers, output_dim.#其中input_dim可以看成是输入的特征数,在我们这里就是4;hidden_dim这里我们选了32,num_layers是有几层的lstm层,# output_dim是最后输出几维,由于最后我们的target只是一维所以output_dim = 1.input_dim = 4hidden_dim = 32num_layers = 2output_dim = 1model = LSTM(input_dim=input_dim,hidden_dim=hidden_dim,output_dim=output_dim,num_layers=num_layers)print(model)# 8 定义loss function 和优化函数loss_fn = torch.nn.MSELoss(size_average=True)optimiser = torch.optim.Adam(model.parameters(),lr=0.01)# 9 训练模型hist = np.zeros(num_epochs)seq_dim = seqfor t in range(num_epochs):# Initialise hidden state# Don't do this if you want your LSTM to be stateful# model.hidden = model.init_hidden()y_train_pred = model(trainX) # 为啥是trainX, train_loader 怎么使用?loss =loss_fn(y_train_pred,trainY)if t%10 ==0 and t!=0:print('Epoch',t,"MSE",loss.item())hist[t] = loss.item()# Zero out gradient, else they will accumulate between epochsoptimiser.zero_grad()# Backward passloss.backward()# Update parametersoptimiser.step()# 10 预测# make predictionsy_test_pred = model(testX)# 下面进行比较。因为我们所拿到的最后的预测结果其实还是(num_sample,20, 1)# 这样一个状态,但我们想要的是每个sample只要最后一个时期的预测,# 所以我们就只拿每个sample的20天的预测结结果的最后一天的进行和真实的target比较就好,# 即下面的y_test_pred.detach().numpy()[:,-1,0]y_train_pred = scaler.inverse_transform(y_train_pred.detach().numpy()[:,-1,0].reshape(-1,1)) # 上面采用循环的方式进行scaler, 最后scaler是针对close进行的,所以这边可以直接拿来用。否则repeat 为5维再反归一化
# y_train_pred = scaler.inverse_transform(y_train_pred.detach().numpy()[:, -1, 0].reshape(-1, 1))y_train = scaler.inverse_transform(trainY.detach().numpy()[:,-1,0].reshape(-1,1))y_test_pred = scaler.inverse_transform(y_test_pred.detach().numpy()[:, -1, 0].reshape(-1, 1))y_test = scaler.inverse_transform(testY.detach().numpy()[:, -1, 0].reshape(-1, 1))# calculate root mean squared errortrainScore = math.sqrt(mean_squared_error(y_train, y_train_pred))print('Train Score: %.2f RMSE' % (trainScore)) #0.68testScore = math.sqrt(mean_squared_error(y_test, y_test_pred))print('Test Score: %.2f RMSE' % (testScore)) # 0.85# 绘图 训练集比较plt.plot(y_train_pred, label="Preds")plt.plot(y_train, label="Data")plt.legend()plt.show()plt.plot(hist, label="Training loss")plt.legend()plt.show()# 测试集比较df_test_final = pd.DataFrame(y_test, columns=['y_test']).join(pd.DataFrame(y_test_pred, columns=['y_test_pred']))df_test_final[['y_test', 'y_test_pred']].plot()plt.ylabel("ETFs_price")plt.show()# shift train predictions for plottinglook_back = seqtrainPredictPlot = np.empty_like(df_main)trainPredictPlot[:, :] = np.nantrainPredictPlot[look_back:len(y_train_pred) + look_back, :] = y_train_pred# shift test predictions for plottingtestPredictPlot = np.empty_like(df_main)testPredictPlot[:, :] = np.nantestPredictPlot[len(y_train_pred) + look_back - 1:len(df_main) - 1, :] = y_test_pred# plot baseline and predictionsplt.figure(figsize=(15, 8))plt.plot(scaler.inverse_transform(df_main))plt.plot(trainPredictPlot)plt.plot(testPredictPlot)plt.show()分类
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader# 定义LSTM分类模型
class LSTMClassifier(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LSTMClassifier, self).__init__()self.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_dim, hidden_dim)self.fc = nn.Linear(hidden_dim, output_dim) # 最后加一个全连接层def forward(self, x):lstm_out, _ = self.lstm(x)out = self.fc(lstm_out[:, -1, :]) # 这个-1是什么意思return out# 准备数据
input_dim = 10 # 是序列长度还是 单个的特征个数? -- > 特征的个数
hidden_dim = 20
output_dim = 2 # outputdim 怎么确定? 这是一个二分类问题, 0/1 所以输出维度是2
num_epochs = 10
batch_size = 32# 生成随机数据
data = torch.randn(100, 10, input_dim) # (100,10,10)
labels = torch.randint(0, 2, (100,)) #(100,)# 创建数据加载器
dataset = torch.utils.data.TensorDataset(data, labels) #(TensorDataset:100)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 创建模型和优化器
model = LSTMClassifier(input_dim, hidden_dim, output_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(num_epochs):for batch_data, batch_labels in dataloader:optimizer.zero_grad()output = model(batch_data)loss = F.cross_entropy(output, batch_labels)loss.backward()optimizer.step()print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}")# 使用模型进行预测
test_data = torch.randn(10, 10, input_dim)
predictions = model(test_data)
predicted_labels = torch.argmax(predictions, dim=1)
print("Predicted Labels:", predicted_labels)
相关文章:

lstm 回归实战、 分类demo
预备知识 lstm 参数 输入、输出格式 nn.LSTM(input_dim,hidden_dim,num_layers); imput_dim 特征数 input:(样本数、seq, features_num) h0,c0 (num_layers,seq, hidden_num) output: (样本数、seq, hidden_dim) 再加一个全连接层,将 outpu…...

实践DDD模拟电商系统总结
目录 一、事件风暴 二、系统用例 三、领域上下文 四、架构设计 (一)六边形架构 (二)系统分层 五、系统实现 (一)项目结构 (二)提交订单功能实现 (三࿰…...
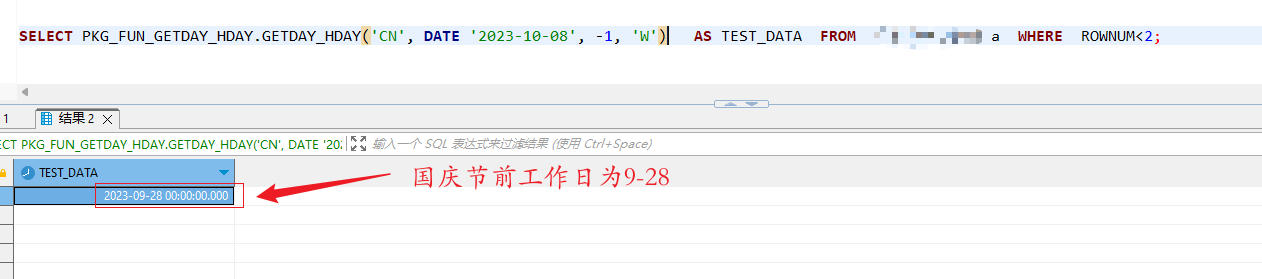
`SQL`编写判断是否为工作日函数编写
SQL编写判断是否为工作日函数编写 最近的自己在写一些功能,遇到了对于工作日的判断,我就看了看sql,来吧!~(最近就是好疲惫) 我们一起看看(针对ORACLE) 1.声明: CREATE OR REPLACE PACKAGE GZYW_2109_1214.PKG_FUN_GETDAY_HDAY AS /** * 通过节假日代码获取指定的日期[查找基…...
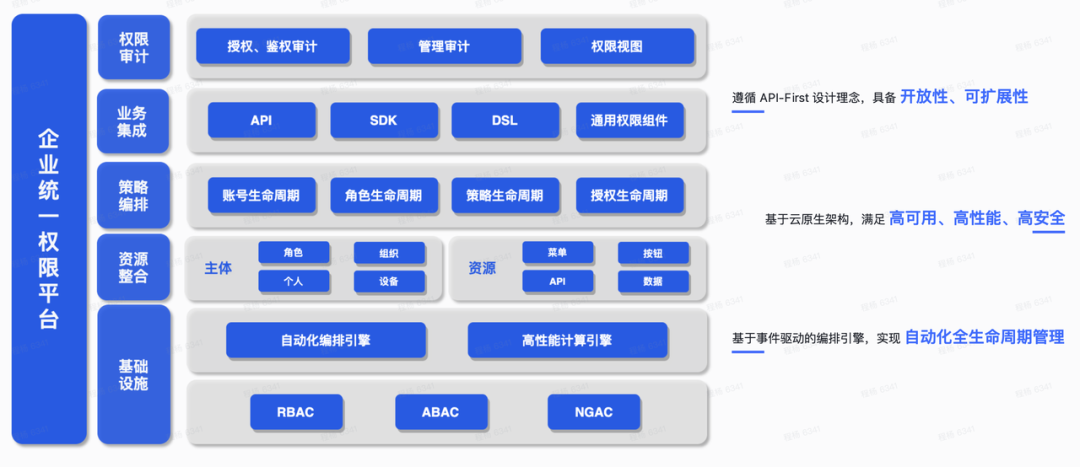
零信任身份管理平台,构建下一代网络安全体系
随着数字化时代的到来,网络安全已成为企业和组织面临的一项重要挑战。传统的网络安全方法已经无法满足不断演变的威胁和技术环境。近期,中国信息通信研究院(简称“中国信通院”)发布了《零信任发展研究报告( 2023 年&a…...

《数据结构、算法与应用C++语言描述》使用C++语言实现链表队列
《数据结构、算法与应用C语言描述》使用C语言实现链表队列 定义 队列的定义 队列(queue)是一个线性表,其插入和删除操作分别在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一端称…...
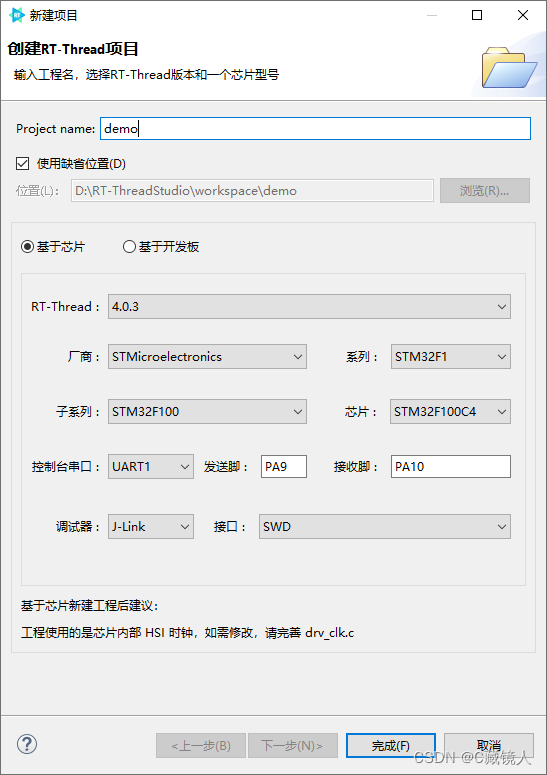
RT-Thread学习笔记(四):RT-Thread Studio工具使用
RT-Thread Studio工具使用 官网详细资料实用操作1. 查看 RT-Thread RTOS API 文档2.打开已创建的工程3.添加头文件路径4. 如何设置生成hex文件5.新建工程 官网详细资料 RT-Thread Studio 用户手册 实用操作 1. 查看 RT-Thread RTOS API 文档 2.打开已创建的工程 如果打开项目…...
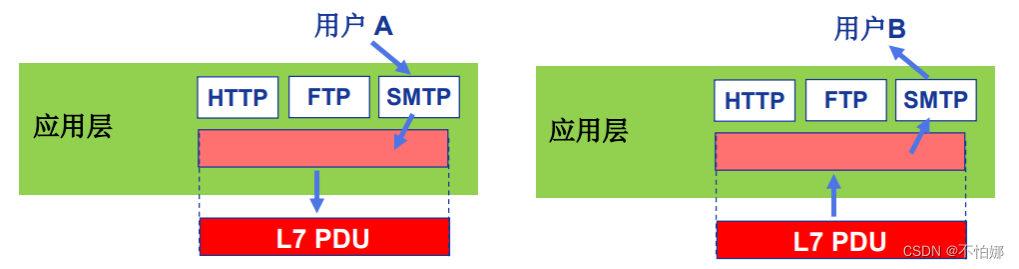
【计算机网络笔记】OSI参考模型中端-端层(传输层、会话层、表示层、应用层)功能介绍
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

RabbitMQ高级知识点
以下是一些 RabbitMQ 的高级知识点: 1. Exchange: RabbitMQ 中的 Exchange 是消息路由器,用来接收消息并且转发到对应的 Queue 中。Exchange 有四种类型:Direct Exchange、Fanout Exchange、Topic Exchange 和 Headers Exchange。…...

Node直接执行ts文件
Node直接执行ts文件 1、常规流程 node 执行 【ts 文件】 流程: 1、编写ts代码 2、编译成js代码 [命令如 :tsc xx.ts] 3、执行js代码 [node xx.js]2、直接执行 想要直接执行 ts 文件,需要安装如下依赖工具。 执行如下命令: # 安装…...

log4j的级别的说明
一 log4j的级别 1.1 级别类型 TRACE 》DEBUG 》 INFO 》 WARN 》 ERROR 》 FATAL 级别高低顺序为: trace级别最低 ,Fatal级别最高。由左到右,从低到高 1.2 包含范围 原则: 本级别包含本级别以及大于本级别的内容,…...

头脑风暴之约瑟夫环问题
一 问题的引入 约瑟夫问题的源头完全可以命名为“自杀游戏”。本着和谐友爱和追求本质的目的,可以把问题描述如下: 现有n个人围成一桌坐下,编号从1到n,从编号为1的人开始报数。报数也从1开始,报到m人离席,…...
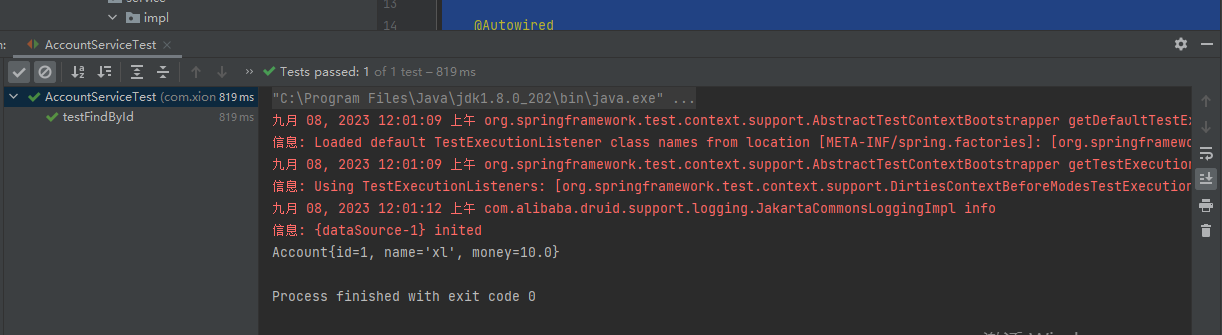
【四:Spring整合Junit】
目录 相同点不同点1、导入依赖增加2、编写的位置不同。。路径一定要与实现类一致 相同点 前面都一样和Spring整合mybatis(基于注解形式)一样Spring整合Mybatis 不同点 1、导入依赖增加 <!-- 单元测试 --><dependency><groupId>junit&…...
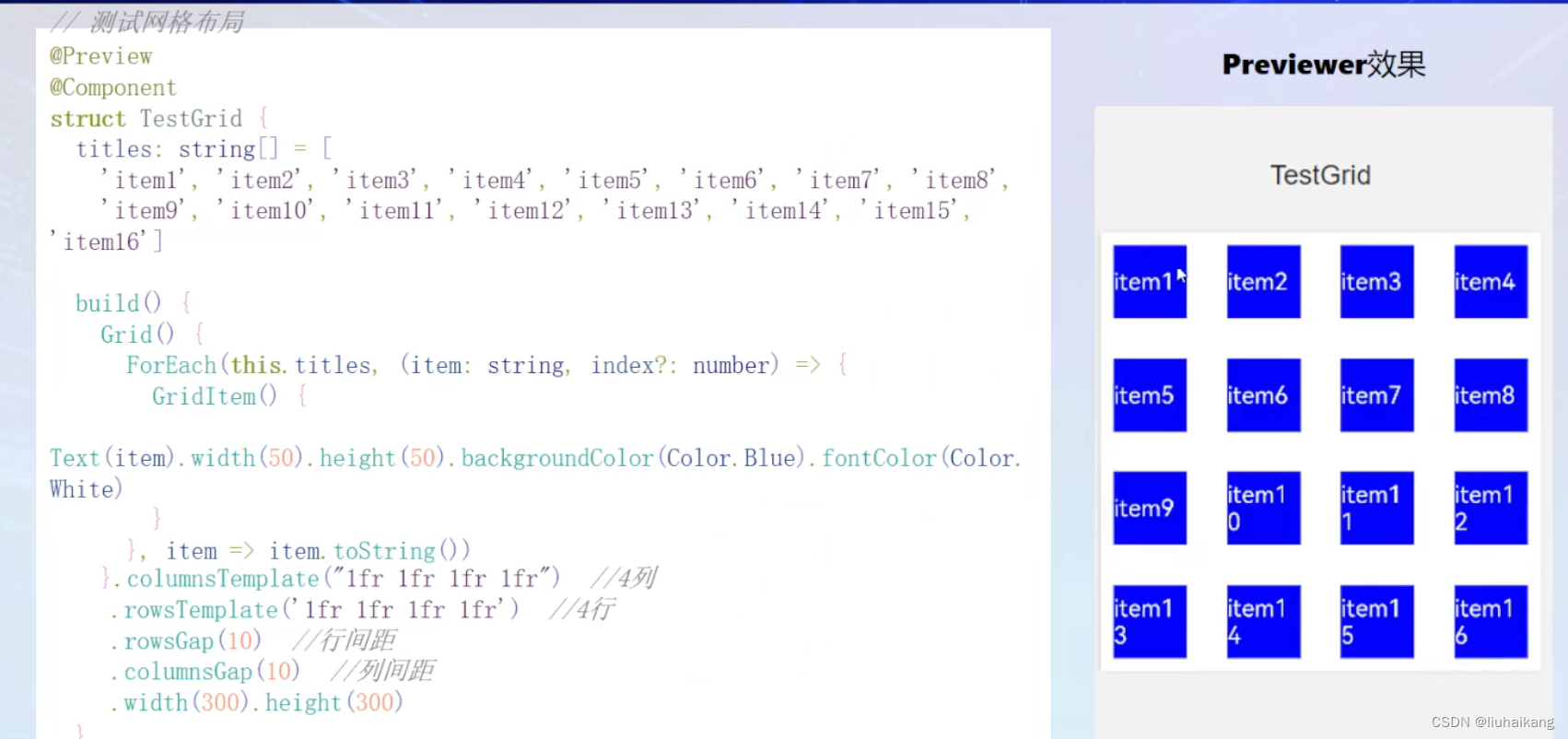
openHarmony UI开发
常用组件和布局方式 组件 ArkUI有丰富的内置组件,包括文本、按钮、图片、进度条、输入框、单选框、多选框等。和布局一样,我们也可以将基础组件组合起来,形成自定义组件。 按钮: Button(Ok, { type: ButtonType.Normal, stateEf…...
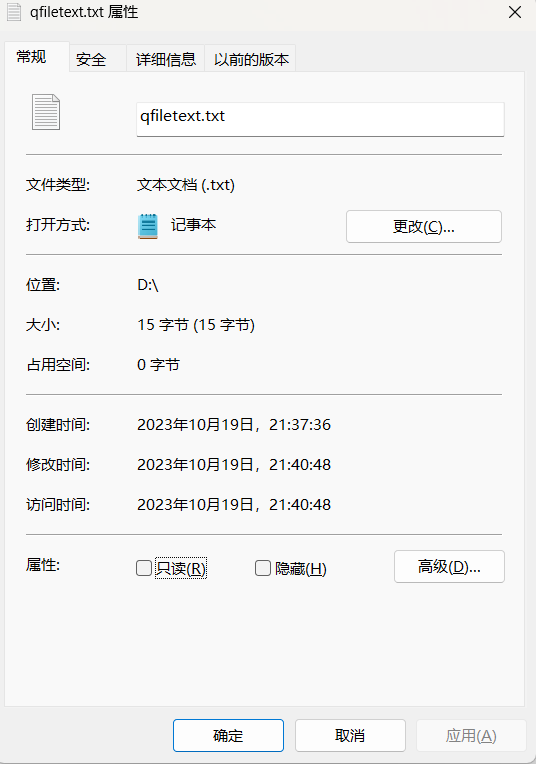
Qt 目录操作(QDir 类)及展示系统文件实战 QFilelnfo 类介绍和获取文件属性项目实战
一、目录操作(QDir 类) QDir 类提供访问系统目录结构 QDir 类提供对目录结构及其内容的访问。QDir 用于操作路径名、访问有关路径和文件的信息以及操作底层文件系统。它还可以用于访问 Qt 的资源系统 Qt 使用“/”作为通用目录分隔符,与“/”在 URL 中用作路径分…...

2023-9-12 阿里健康2024秋招后端开发-体检及泛医疗二面
1 自我介绍 2 快手实习 2.1 说说你在实习期间遇到的挑战、收获 (1)在设计模式的应用能力上,有了很大的提高,使用模板设计模式,架构实例反向同步到架构定义,使用了策略模式 (2) …...
Qt扫盲-QBrush理论使用总结
Q 理论使用总结 一、概述1. 填充模式2. 笔刷颜色3. 纹理 二、 Qt::GlobalColor 一、概述 QBrush类定义了由 QPainter 绘制的形状的填充模式。画笔有样式、颜色、渐变和纹理。 brush style() 使用Qt::BrushStyle 枚举定义填充模式。默认的笔刷样式是 Qt::NoBrush(取决于你如何…...

互联网Java工程师面试题·Java 面试篇·第三弹
目录 39、JRE、JDK、JVM 及 JIT 之间有什么不同? 40、解释 Java 堆空间及 GC? 41、你能保证 GC 执行吗? 42、怎么获取 Java 程序使用的内存?堆使用的百分比? 43、Java 中堆和栈有什么区别? 44、“ab”…...

如何使用VSCode将iPad Pro转化为功能强大的开发工具?
文章目录 前言1. 本地环境配置2. 内网穿透2.1 安装cpolar内网穿透(支持一键自动安装脚本)2.2 创建HTTP隧道 3. 测试远程访问4. 配置固定二级子域名4.1 保留二级子域名4.2 配置二级子域名 5. 测试使用固定二级子域名远程访问6. iPad通过软件远程vscode6.1 创建TCP隧道 7. ipad远…...

将用友U8的数据可视化需要哪些工具?
将金蝶U8的数据可视化需要一个奥威BI数据可视化工具,以及一套专为用友U8打造的标准化BI数据分析方案。 奥威BI SaaS平台:一键链接用友U8,立得报表 别的BI软件围绕用友U8的数据做可视化:1、准备配置环境;2、下载安装配…...

DOS常用指令
一、dir显示目录 dir命令是Windows系统常用的命令,用于显示目录的文件和子目录的列表。如果不使用参数,此命令将显示磁盘的卷标和序列号,然后是磁盘上的目录和文件列表(包括它们的名称以及每个文件最后修改的日期和时间ÿ…...

用CubeIDE搞定LCD12864:手把手教你移植字库并显示自定义汉字
STM32CubeIDE实战:LCD12864自定义字库开发全指南 在嵌入式设备的人机交互界面开发中,LCD12864液晶屏因其高性价比和良好的显示效果被广泛应用。但当我们需要显示特殊符号、罕见汉字或自定义图形时,内置字库往往无法满足需求。本文将带你从零开…...

C++编程语言基础与核心特性详解
1. C语言概述与基础语法C是一种通用编程语言,由Bjarne Stroustrup于1980年代在贝尔实验室开发。作为C语言的扩展,C在保持高效性的同时引入了面向对象编程(OOP)特性。它广泛应用于系统/应用软件开发、游戏引擎、高频交易等领域&…...

别再死记硬背了!用MobileNet里的Depthwise Convolution,我彻底搞懂了轻量化网络的设计精髓
深度可分离卷积实战:从MobileNet看轻量化网络的底层逻辑 第一次接触MobileNet时,我被它的轻量化设计震撼了——在保持相当精度的前提下,参数量只有传统卷积网络的几分之一。直到拆解了Depthwise Convolution(深度可分离卷积&#…...
)
别再手动找数据集了!用Python的openml库5分钟搞定机器学习数据加载(附实战代码)
用Python的openml库5分钟搞定机器学习数据加载(附实战代码) 还在为找数据集发愁?每次开始新项目都要花半天时间在Kaggle上筛选、下载、解压、清洗数据?今天介绍一个能让你彻底告别这些繁琐步骤的神器——openml库。这个Python库能…...

不止于错误捕获:深入Tcl的catch命令,玩转break、continue和return的异常流
深入解析Tcl的catch命令:掌控脚本流程的终极武器 在Tcl脚本编程中,异常处理是构建健壮应用程序的关键。大多数开发者对catch命令的理解停留在简单的错误捕获层面,却忽略了它作为流程控制枢纽的强大潜力。本文将带你重新认识这个被低估的语言特…...

Android Profiler 内存分析实战:从卡顿溯源到泄漏定位
1. Android Profiler内存分析器入门指南 第一次打开Android Studio的Profiler面板时,很多开发者都会被那些跳动的曲线和复杂的数据搞得一头雾水。记得我刚接触内存分析时,盯着那些上上下下的折线图看了半天,完全不知道从何下手。其实Android …...

天龙八部单机版GM工具:5分钟上手,告别复杂数据库操作
天龙八部单机版GM工具:5分钟上手,告别复杂数据库操作 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 你是否曾为修改《天龙八部》单机版游戏数据而烦恼?是否面对复…...

从Python打包exe到逆向分析:一次搞定pyinstxtractor和uncompyle6的使用
Python逆向工程实战:从打包exe到源码还原的完整指南 逆向分析Python打包的exe文件是一项兼具挑战性和实用性的技能。无论是安全研究人员、开发者还是技术爱好者,掌握这项技术都能让你在面对未知Python程序时游刃有余。本文将带你深入探索Python逆向工程的…...

Qwen3-4B-Thinking作品分享:碳足迹核算标准解读+企业减排路径推理生成
Qwen3-4B-Thinking作品分享:碳足迹核算标准解读企业减排路径推理生成 1. 模型介绍 Qwen3-4B-Thinking-2507-Gemini-2.5-Flash-Distill是基于通义千问Qwen3-4B官方模型开发的专业推理模型。这个4B参数的稠密模型具有原生256K tokens的上下文处理能力,并…...

华为OD机试真题 新系统 2026-04-19 JavaGo 实现【8位LED控制器】
目录 题目 思路 Code 题目 有一个8位LED控制器,包含8个LED灯(编号0-7),初始状态全灭,用8位二进制表示为:00000000。控制器可以接收以下三种指令: Lx:L表示点亮操作,x表示LED的编号(0一7),操作得到的结果是:点亮第x个LED灯,把状态设为1。 Dx:D表示熄灭操作,x表示LED的…...