【C++】一些C++11特性
C++特性
- 1. 列表初始化
- 1.1 {}初始化
- 1.2 initializer_list
- 2. 声明
- 2.1 auto
- 2.2 typeid
- 2.3 decltype
- 2.4 nullptr
- 3. STL
- 3.1 新容器
- 3.2 新接口
- 4. 右值引用
- 5. 移动构造与移动赋值
- 6. lambda表达式
- 7. 可变参数模板
- 8. 包装器
- 9. bind
1. 列表初始化
1.1 {}初始化
C++11支持所有内置类型和自定义类型使用{}初始化,并且可以不写=。
struct A
{A(int a, int b):_a(a),_b(b){}int _a;int _b;
};
int main()
{int a = 0;int b = { 1 };int c{ 2 };int d[] = { 1,2,3,4 };int e[]{ 5,6,7,8 };//本质都是调用构造函数,多参数的构造函数支持隐式类型转换。A aa(1, 2);A bb = { 3,4 };A cc{ 5,6 };return 0;
}
但为了一定的可读性,在日常定义中,还是不要省略=。
问题
vector<int> v = {1,2};
这是{}初始化吗?显然不是,这是vector的构造。那为什么vector支持{}这种构造,这与initializer_list有关。
1.2 initializer_list
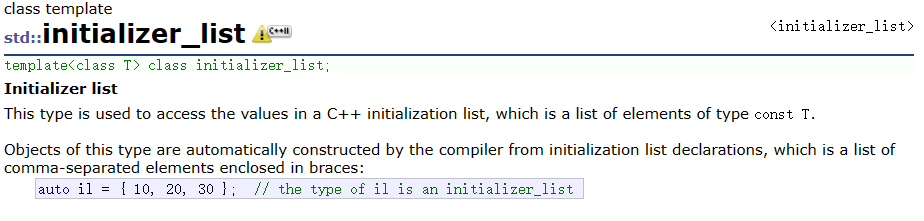
C++11新增一个类initializer_list,它用常量数组来初始化。此类型的对象由编译器根据初始化列表声明自动构建,初始化列表声明是一个用逗号分隔的元素列表,用大括号括起来:initializer_list< int > il = { 1 , 2 }。本质还是调用initializer_list的构造函数。
C++11后,一些容器增加了initializer_list为参数的构造,这样初始化容器更方便,如:
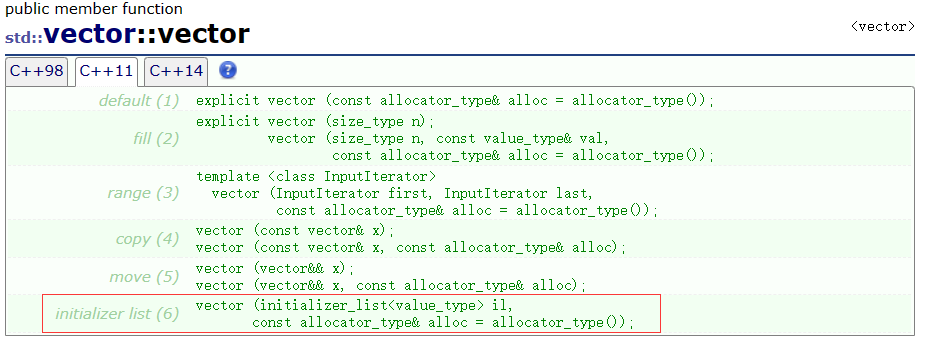
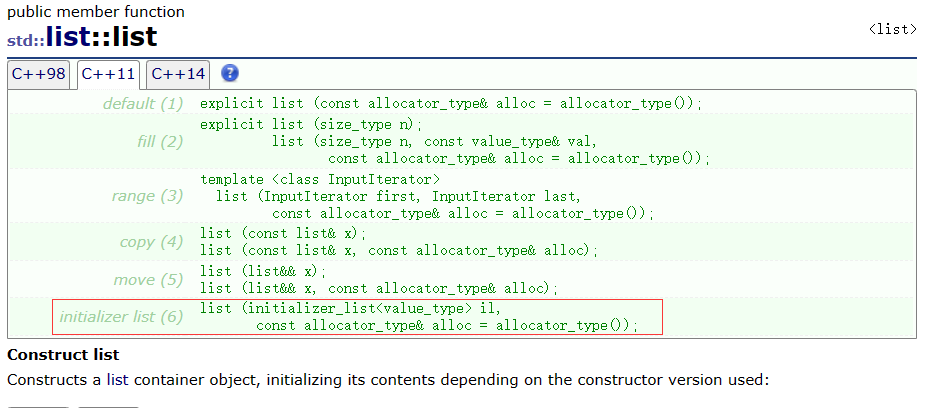
这也是为什么vector支持{1,2}直接构造。因为vector有一个构造支持initializer_list构造,所以v调用的是initializer_list的构造。
2. 声明
2.1 auto
auto可以实现自动类型推断,这就意味着auto定义的变量必须初始化。
2.2 typeid
typeid(变量).name();//得到变量类型,但只是字符串,只能看不能用。
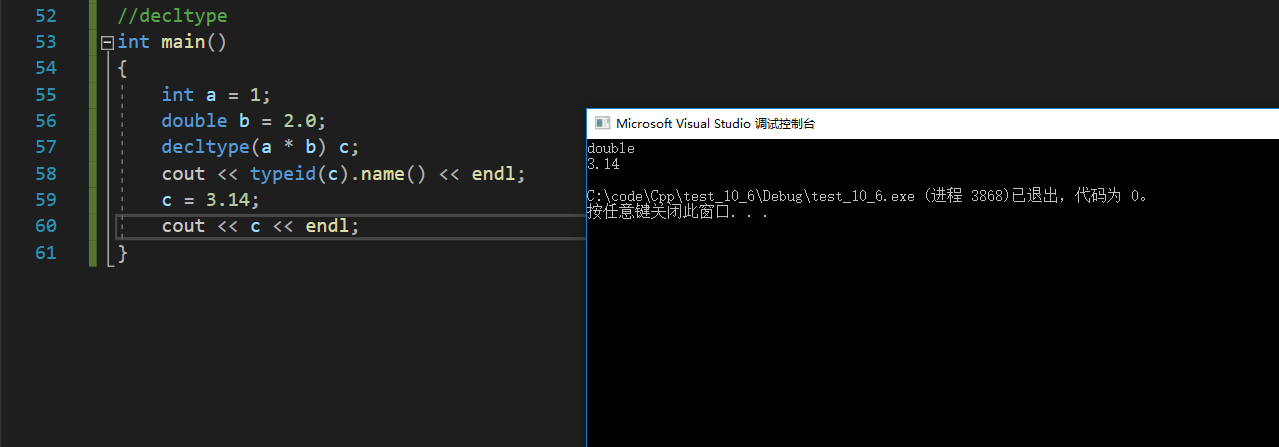
2.3 decltype
当想单纯定义一个变量而不想初始化时,就可以用decltype。decltype可以推导出对象或者表达式的类型,可以再定义变量。
综上
typeid推出的类型是字符串,只能看不能用;decltype可以推出对象的类型,可以再定义变量,或者作为模板实参;auto通过赋值自动推到类型。
2.4 nullptr
C++中NULL既可以是0,也可以是空指针。
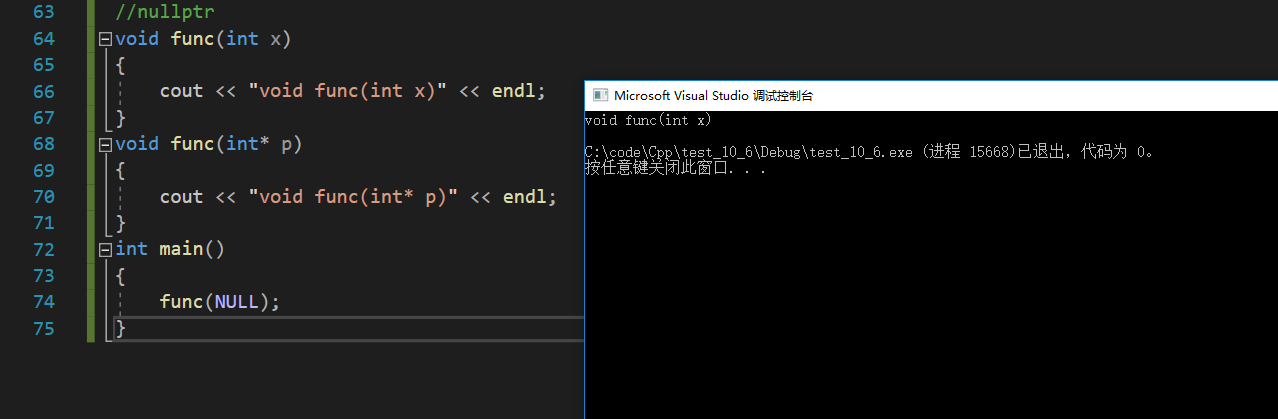
func调用的是第一个func,在预处理阶段被替换成0。
为了解决这个问题,C++11新增了nullptr表示空指针。
3. STL
3.1 新容器
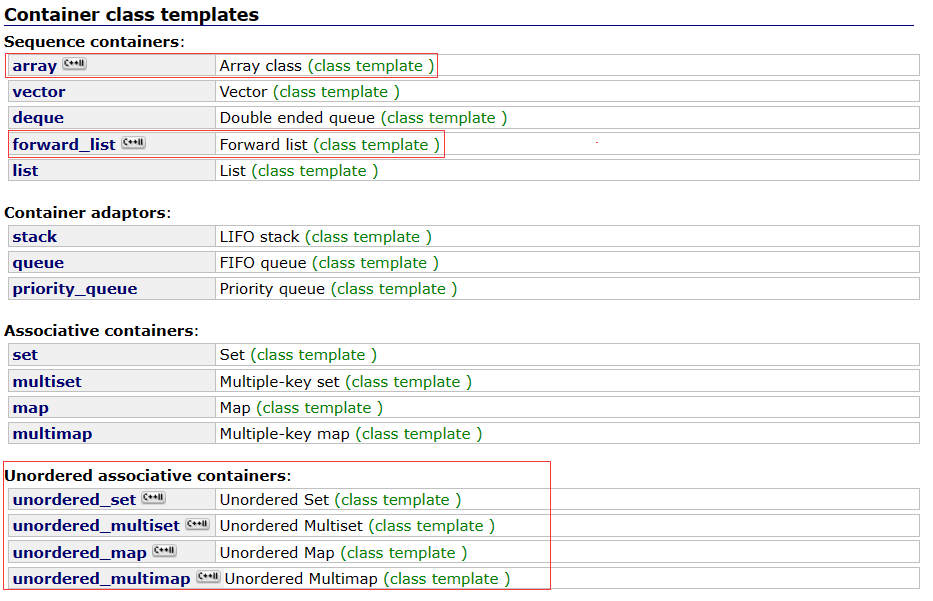
- array(静态数组)
int main()
{int arr1[10] = { 0,1,2,3,4,5,6,7,8,9 };array<int, 10> arr2 = { 0,1,2,3,4,5,6,7,8,9 };//数组和静态数组的真正区别在于对越界的处理arr1[12] = 0;//指针+解引用arr2[12] = 0;//调用operator[],函数内部会检查,会报错
}
同样是会对越界报错,vector也可以进行扩容,所以这个array有点鸡肋。
-
forward_list(单链表)

forward_list支持在任何位置的下一个节点的插入和删除,因为它是单链表,不如list有前后指针。这也是它唯一的优点:节省一个指针。 -
unordered_set和unordered_map已经介绍过,这里就不赘述。
3.2 新接口
- 迭代器

const修饰的正向迭代器和反向迭代器,但是普通迭代器也可以返回const修饰的迭代器,所以这几个接口还是用处不大。
- 所有容器均支持{}列表初始化的构造函数。
- 所有容器均新增了emplace系列。
- 新容器增加了移动构造和移动赋值。
4. 右值引用
- 什么是左值引用?什么是右值引用?
可以获得它的地址就是左值,不可以获得它的地址就是右值。左值引用就是给左值取别名,右值引用就是给右值取别名。左值可以在等号左边,也可以在等号右边,右值不可以在等号左边。
int main()
{//a,b,c都是左值int* a = new int(0);int b = 1;const int c = 2;//以下就是右值10;//常量b + c;//表达式add(b , c);//函数返回值(不是左值引用返回)//左值引用int& r1 = b;//右值引用int&& r2 = 10;int&& r3 = b + c;return 0;
}
拓展
内置类型的右值叫做纯右值,自定义类型的右值叫做将亡值(生命周期要结束)。
- 左值引用能否给右值取别名?右值引用能否给左值取别名?
int main()
{//int& r1 = 10;//(×)const int& r1 = 10;//(√)double x = 0.1;double y = 0.2;const double& r2 = x + y;//(√)//左值引用可以给右值取别名,但必须+constint a = 1;//int&& r3 = a;//(×)int&& r3 = move(a);//(√)//右值引用可以给左值取别名,但必须+move
}
拓展
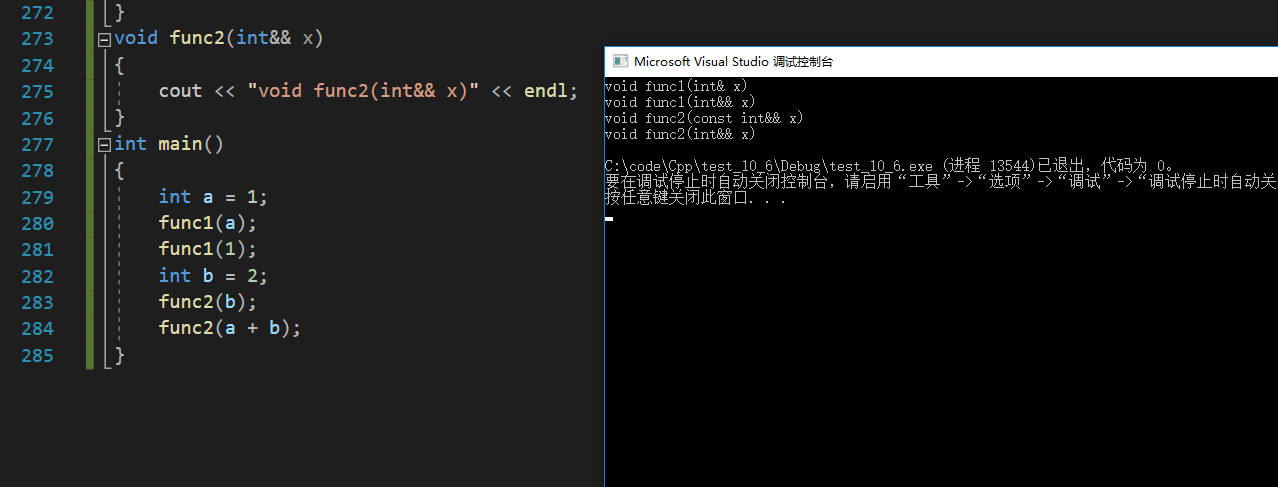
//重载和调用歧义问题
void func1(int& x)
{cout << "void func1(int& x)" << endl;
}
void func1(int&& x)
{cout << "void func1(int&& x)" << endl;
}
void func2(const int& x)
{cout << "void func2(const int&& x)" << endl;
}
void func2(int&& x)
{cout << "void func2(int&& x)" << endl;
}
int main()
{int a = 1;func1(a);func1(1);int b = 2;func2(b);func2(a + b);
}
func1构成重载,func2也构成重载且不存在调用歧义,编译器会调用更匹配的,有右值引用就会调用右值引用版本。
- 左值引用的应用和缺点
左值引用可以用来做参数和返回值,可以减少拷贝提高效率。
string& func(string& s)
{for (auto& e : s){++e;}return s;
}
int main()
{string str("1234");string ret = func(str);cout << str << endl;
}
但如果func返回的是一个局部变量(出了作用域就销毁),就不能左值引用返回,只能传值返回,这样就得调用拷贝构造。如何减少拷贝?用右值引用。
- 右值引用的应用
(1)以一个简洁的string(库的string太复杂了)为例
namespace zn
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};
}
zn::string func()
{zn::string ret("nihao");return ret;
}
int main()
{zn::string str;str = func();return 0;
}
移动赋值
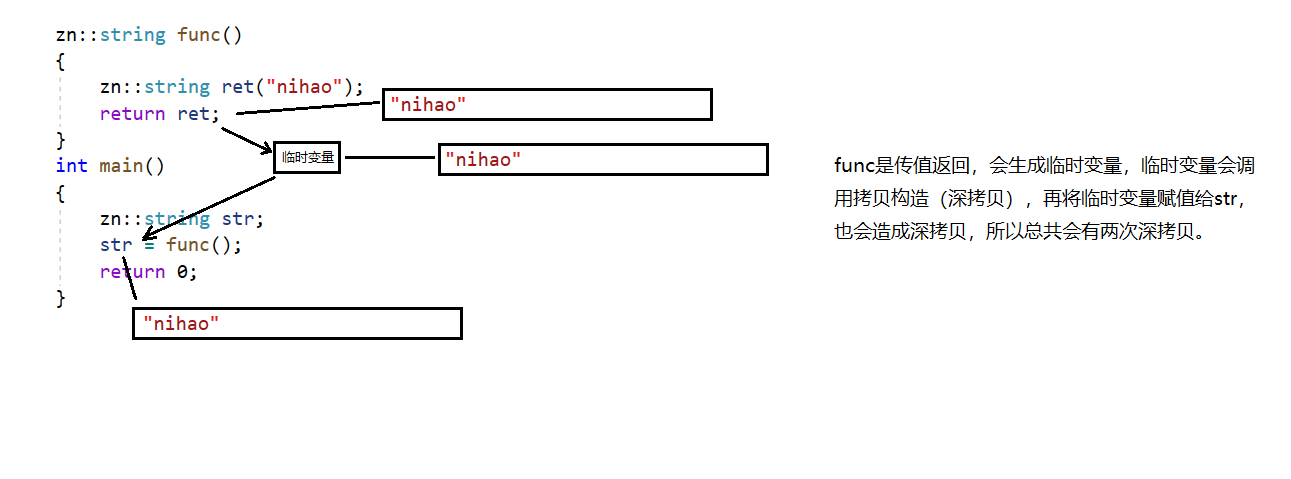
func函数传值返回,返回的ret是右值将亡值(生命周期结束),所以可以重载赋值,用右值引用接受参数。
// 赋值重载
string& operator=(const string& s)
{cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;
}
// 移动赋值
// 为什么叫移动赋值?因为是将别人的资源转移过来,同时将自己的资源转移过去。
string& operator=(string&& s)
{cout << "string& operator=(string&& s) -- 移动赋值" << endl;swap(s);return *this;
}
func如果返回左值就调用赋值,如果返回右值就调用移动赋值。移动拷贝交换了资源,旧资源会被将亡值释放,减少了拷贝,提高了效率。
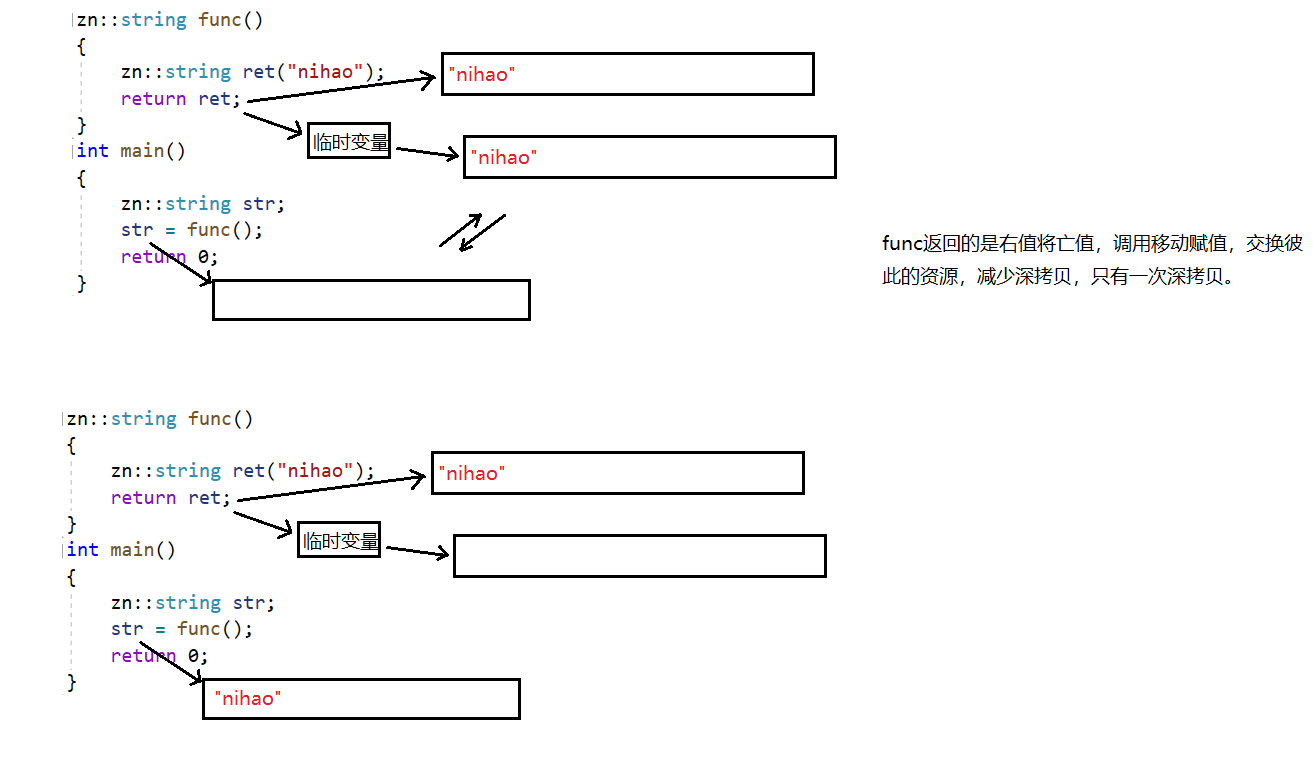
移动拷贝
// 拷贝构造
string(const string& s):_str(nullptr)
{cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);
}
a. 拷贝构造

在拷贝构造的情况下,如果编译器优化就只有一次深拷贝,如果不优化就有两次深拷贝。
如果想要再减少拷贝次数,提高效率,可以使用移动构造来实现。
b. 移动构造
// 移动构造
string(string&& s):_str(nullptr), _size(0), _capacity(0)
{cout << "string(string&& s) -- 移动语义" << endl;swap(s);
}
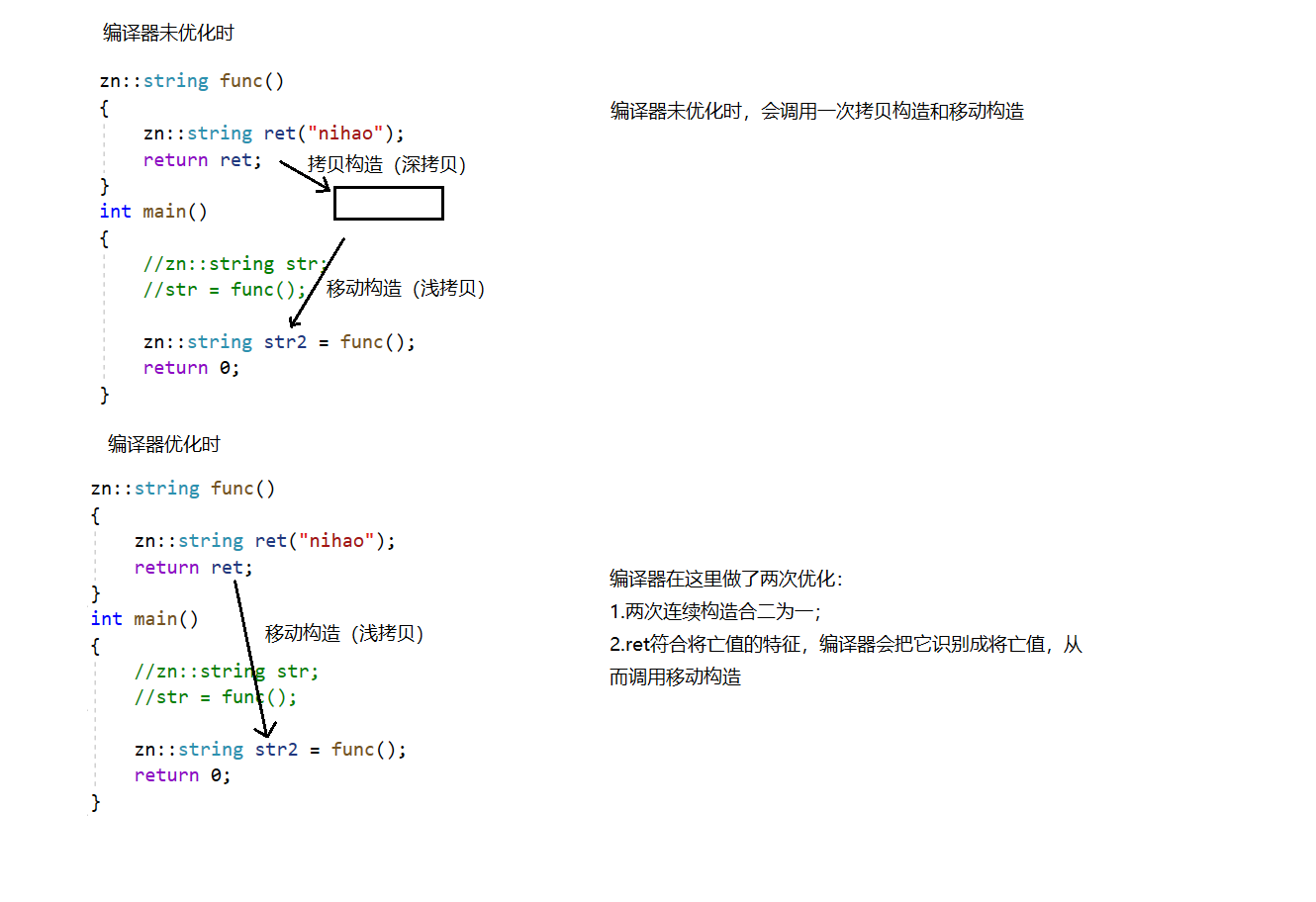
编译器优化后,直接交换将亡值的内容,让它顺便释放旧的资源。以上的优化都是基于传值返回,如果函数是传引用返回,就没有这些优化。
既然有了移动拷贝,我们再来看看移动赋值的例子,发现它还可以再优化。

(2)场景二:move函数将左值变成右值
int main()
{zn::string str("nihao");zn::string str2(str);
}
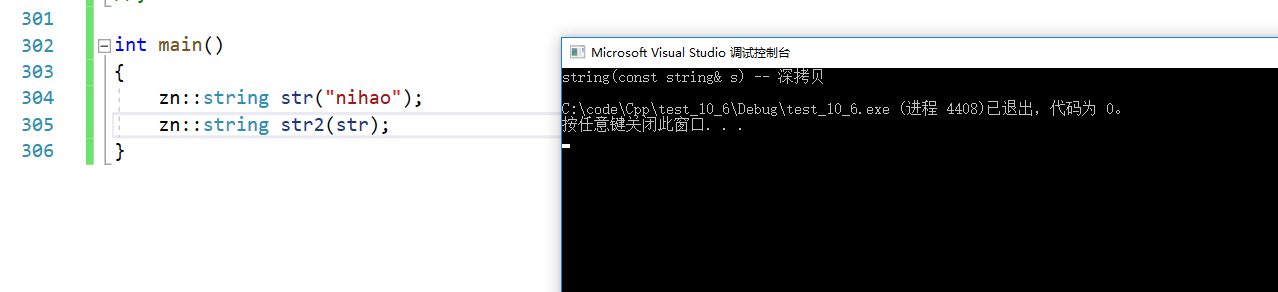
str是左值,str2会调用拷贝构造。但我想要让其调用移动构造,抢走str的资源,该如何做?用move修饰str2。
int main()
{zn::string str("nihao");zn::string str2(move(str));
}

str被move强制转换成右值,右值调用移动构造。
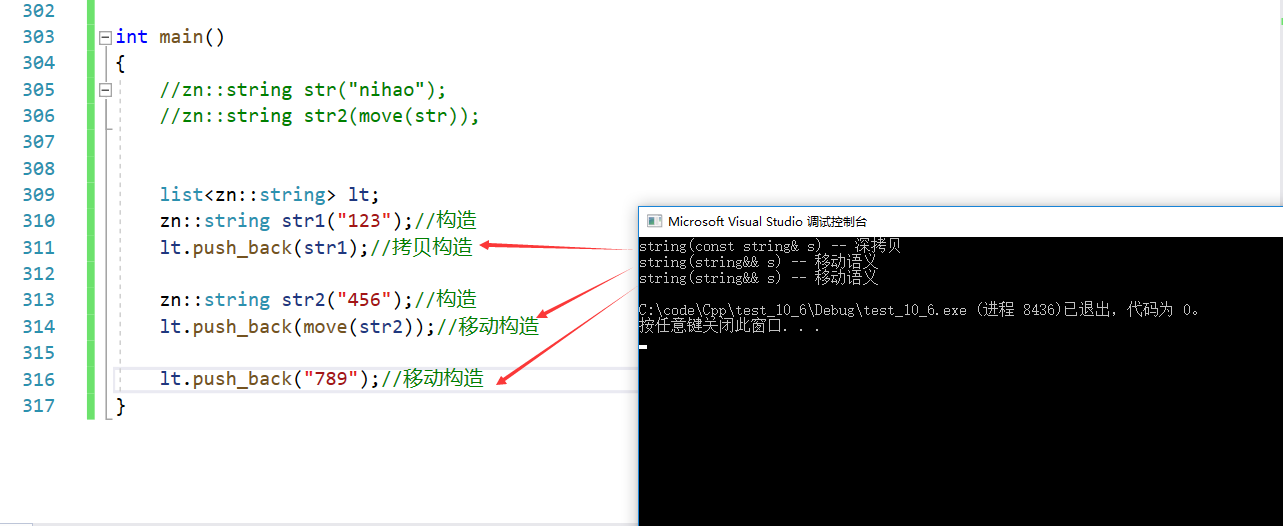
(3)场景三:STL容器插入接口函数也增加了右值引用版本,容器的插入接口如果插入对象是右值,可以利用移动构造转移资源给数据结构中的对象,也可以减少。
- 完美转发
引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值。不理解这句话,没关系先看例子。
首先介绍下什么是万能引用?模板中的&&不是接收右值的意思,其代表万能引用,既可以接收右值,也可以接收左值。实参是左值,它就是左值引用,实参是右值,它就是右值引用。
例子
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{Fun(t);
}
int main()
{PerfectForward(10);// 右值int a;PerfectForward(a);// 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b);// const 左值PerfectForward(std::move(b)); // const 右值return 0;
}
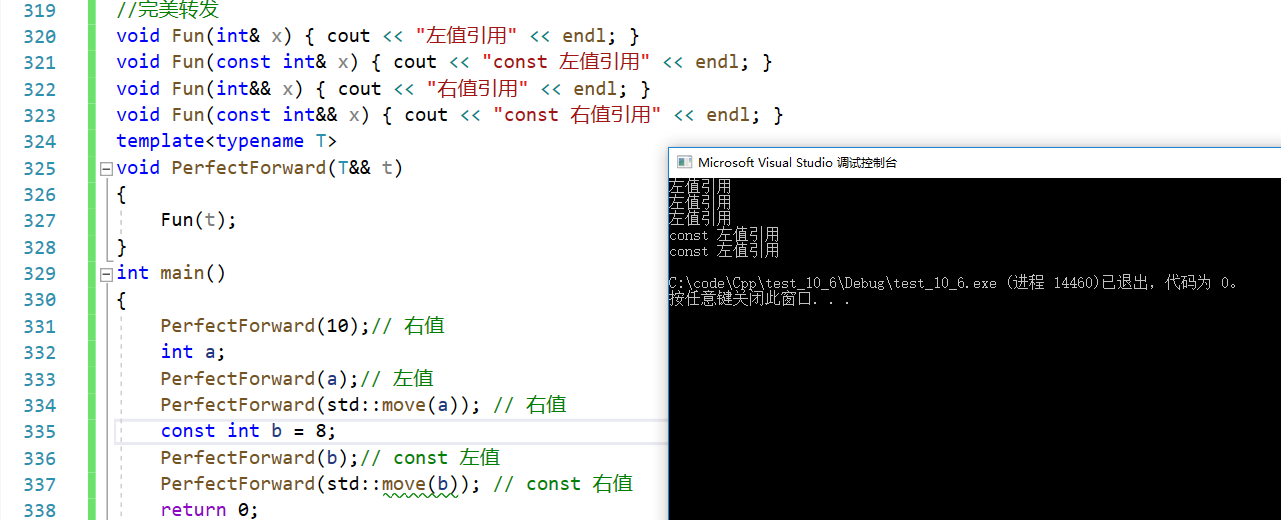
为什么会出现这种情况?我们平时都忽略了右值的另一种特征:不能修改。既然右值不可修改,那么在移动构造和移动赋值的时候是如何交换资源的?答案是在用右值引用接收时,右值的属性就发生了变化,它可以被修改,所以此时的右值是左值属性的。

rr能取地址,且地址和r的地址相同,但rr却是右值引用(对右值取别名)。原因是右值引用变量的属性会被编译器识别成左值。
回到例子,Func接收的参数虽然是右值,但它的属性早已变成左值属性,所以调用的函数是左值引用。
结论
由此,我们可以得出结论:模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值。
问题
那如何保持住右值的右值属性?那就得用到完美转发。
完美转发
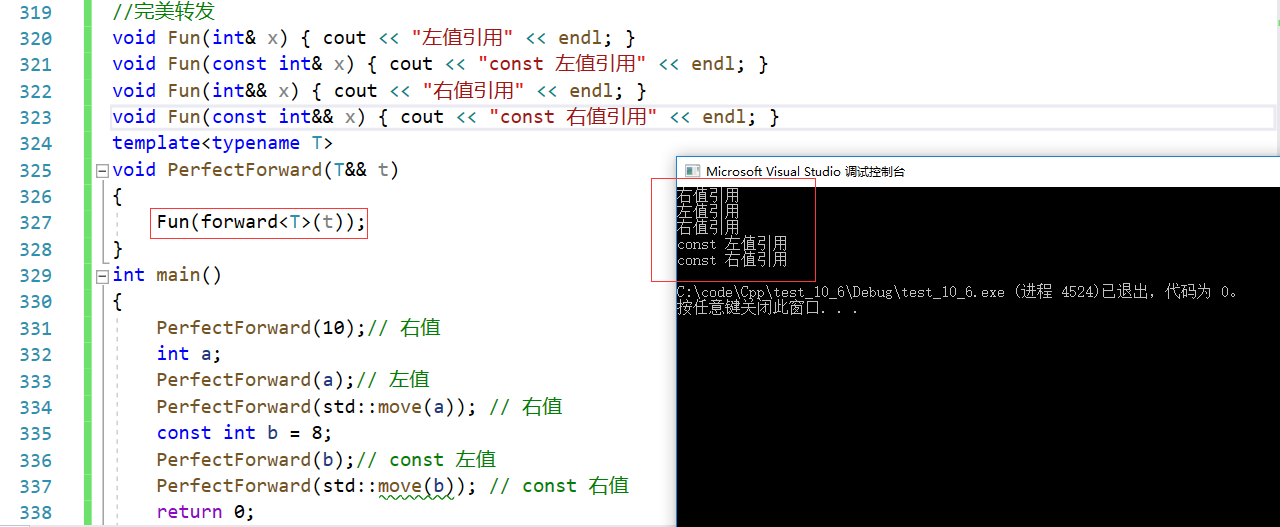
forward完美转发在对象的传参过程保持对象原生类型的属性。
// std::forward<T>(t)在传参的过程中保持了t的原生类型属性。
template<typename T>
void PerfectForward(T&& t)
{Fun(std::forward<T>(t));
}
在传参过程中保持t的属性,t是左值引用就保持左值属性;t是右值属性就保持右值属性。
应用场景
在一些容器的插入中,我们通常需要保持插入数据的右值属性,这样就可以调用移动构造和移动赋值,或者就不用深拷贝,就可以减少拷贝提高效率。
template<class T>
class List
{//...void PushBack(T&& x){//Insert(_head, x);Insert(_head, std::forward<T>(x));}void Insert(Node* pos, T&& x){Node* prev = pos->_prev;Node* newnode = new Node;newnode->_data = std::forward<T>(x); // 关键位置// prev newnode posprev->_next = newnode;newnode->_prev = prev;newnode->_next = pos;pos->_prev = newnode;}void Insert(Node* pos,const T& x){//……}
}5. 移动构造与移动赋值
C++11新增了两个默认成员函数:移动构造和移动赋值。在上面我们已经了解到它们的原理,现在来了解它们的一些细节。
- 深拷贝的类需要实现自己实现移动构造和移动赋值,浅拷贝的类就不需要自己实现。
- 如果没有自己实现移动构造和移动赋值,且没有实现析构、拷贝构造、赋值重载中任一个,编译器就会默认生成移动构造和移动赋值。默认生成的移动构造和移动赋值,对于内置类型实现值拷贝,对于自定义类型,如果有移动构造和移动赋值就调用其移动 构造和移动赋值,没有就调用拷贝构造和赋值重载。
- 一个类要写这三个函数:析构函数 、拷贝构造、拷贝赋值重载,说明这个类是深拷贝的类,这三个函数是三位一体的,通常一起实现。如果没有实现这三个,说明是浅拷贝的类,那就用编译器默认生成的析构、拷贝构造、赋值重载和移动构造和移动赋值;如果手动实现这三个,说明是深拷贝的类就需要自己手动实现移动构造和移动赋值。
- 强制生成成员函数,可以用=default修饰。
string(string&& p) = default;
6. lambda表达式
- 为什么会有lambda表达式?
如果我们要对自定义类型进行排序,我们可以根据自定义类型的成员进行排序,且可以排升序也可以排降序。
struct book
{string _name;int _id;double _price;
};
struct CompareByIdGreater
{bool operator()(const book& b1, const book& b2){return b1._id < b2._id;}
};
struct CompareByIdLess
{bool operator()(const book& b1, const book& b2){return b1._id > b2._id;}
};
int main()
{vector<book> lib = { {"活着",1,30.4},{"皮囊",2,24.9},{"我与地坛",3,33.5}};//要求对书按照_id进行排升序,需要写仿函数sort(lib.begin(), lib.end(), CompareByIdGreater());//要求对书按照_id进行排降序,需要写仿函数sort(lib.begin(), lib.end(), CompareByIdLess());//要求对书按照价格进行排降序,需要写仿函数//……//要求对书按照价格进行排升序,需要写仿函数//……//要求对书按照书名进行排降序,需要写仿函数//……//……return 0;
}
对一个自定义类型的各个成员排序,得专门写多个类进行排序,而且还得排升序和降序,还得再实现多个类。这样实现太复杂了,所以就有lambda表达式。
//按照_id进行排降序
sort(lib.begin(), lib.end(), [](const book& b1, const book& b2) {return b1._id > b2._id; });
//按照_id进行排升序
sort(lib.begin(), lib.end(), [](const book& b1, const book& b2) {return b1._id < b2._id; });
//按照价格进行排降序
sort(lib.begin(), lib.end(), [](const book& b1, const book& b2) {return b1._price > b2._price; });
//按照价格进行排升序
sort(lib.begin(), lib.end(), [](const book& b1, const book& b2) {return b1._price < b2._price; });
- lambda表达式怎么用?

捕捉列表
(1)[ var ]:传值捕捉变量var。因为是传值捕捉,捕捉列表中的var是外面var的拷贝;又因为lambda函数是const函数,捕捉过来的变量不能修改,如果想要修改,必须+mutable,但修改的也是var的拷贝。
(2)[ &var ]:传引用捕捉变量var。
(3)[ = ]:传值捕捉父作用域所有的变量(包括this)。这里的父作用域是指包含lambda表达式的代码块。
(4)[ & ]:传引用捕捉父作用域所有的变量(包括this)。
(5)在捕捉列表中,可以多次捕捉,然后用逗号分隔开。[ &,var ]:传值捕捉var,传引用捕捉其他变量。[ =,&var ]:传引用捕捉var,传值捕捉其他变量。不能重复捕捉,如[ =,var ]。
(6)lambda表达式只能捕捉父作用域的局部变量,不能捕捉父作用域以外的变量。
- 例子以及一些重要事项
int Add(int x, int y)
{return x + y;
}
int main()
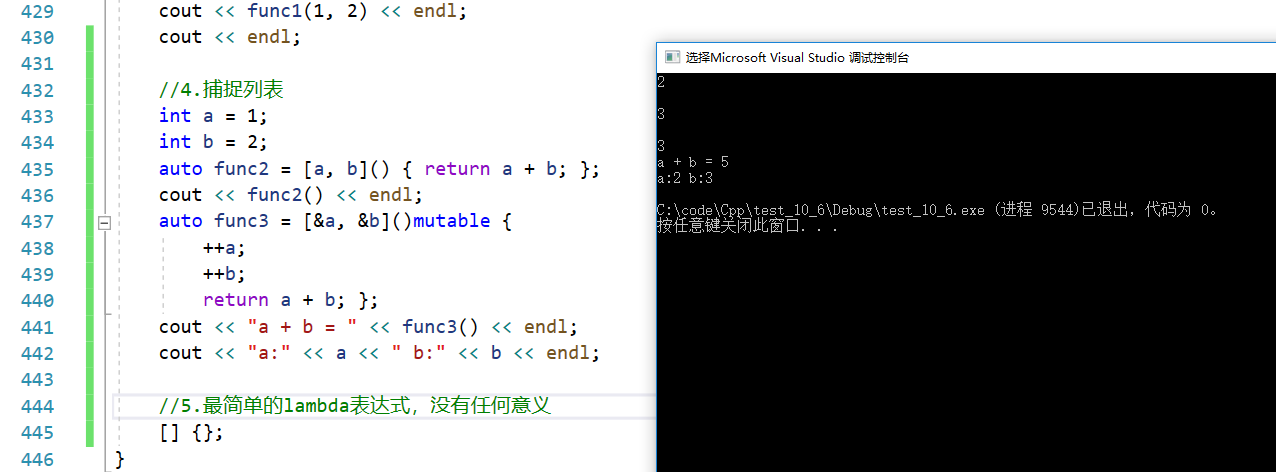
{//1.lambda表达式是匿名函数对象,和函数指针、仿函数一样,都可以作为对象使用。auto add = [](int x, int y)->int {return x + y; };cout << add(1, 1) << endl;cout << endl;//2.函数体内可以有多条语句auto swap = [](int& x, int& y) {int temp = x;x = y;y = temp;};//3.在lambda函数体内不能调用局部函数,如add,但可以调用全局函数。//如果想要调用局部变量,就用捕捉列表捕捉。//auto func1 = [](int x, int y) {return add(x, y); }; (×)auto func1 = [](int x, int y) {return Add(x, y); };//auto func1 = [ = ](int x, int y) {return add(x, y); }; (√)cout << func1(1, 2) << endl;cout << endl;//4.捕捉列表int a = 1;int b = 2;auto func2 = [a, b]() { return a + b; };cout << func2() << endl;auto func3 = [&a, &b]()mutable {++a;++b;return a + b; };cout << "a + b = " << func3() << endl;cout << "a:" << a << " b:" << b << endl;//5.最简单的lambda表达式,没有任何意义[] {};
}
结果
- lambda表达式的原理
在前面我们已经发现lambda表达式与仿函数的使用方法一样,现在就来看看它与仿函数的关系。
class CompareGreater
{
public:bool operator()(const int& x, const int& y){return x > y;}
};
int main()
{CompareGreater cg;//cg是仿函数,也叫函数对象,本质是类对象,通过重载(),可以像函数一样使用int x = 1;int y = 2;int ret1 = cg(x, y);auto func = [](int x, int y) {return x > y; };//lambda表达式int ret2 = func(x, y);
}
查看lambda表达式的底层代码后发现,有一个类调用operator()。
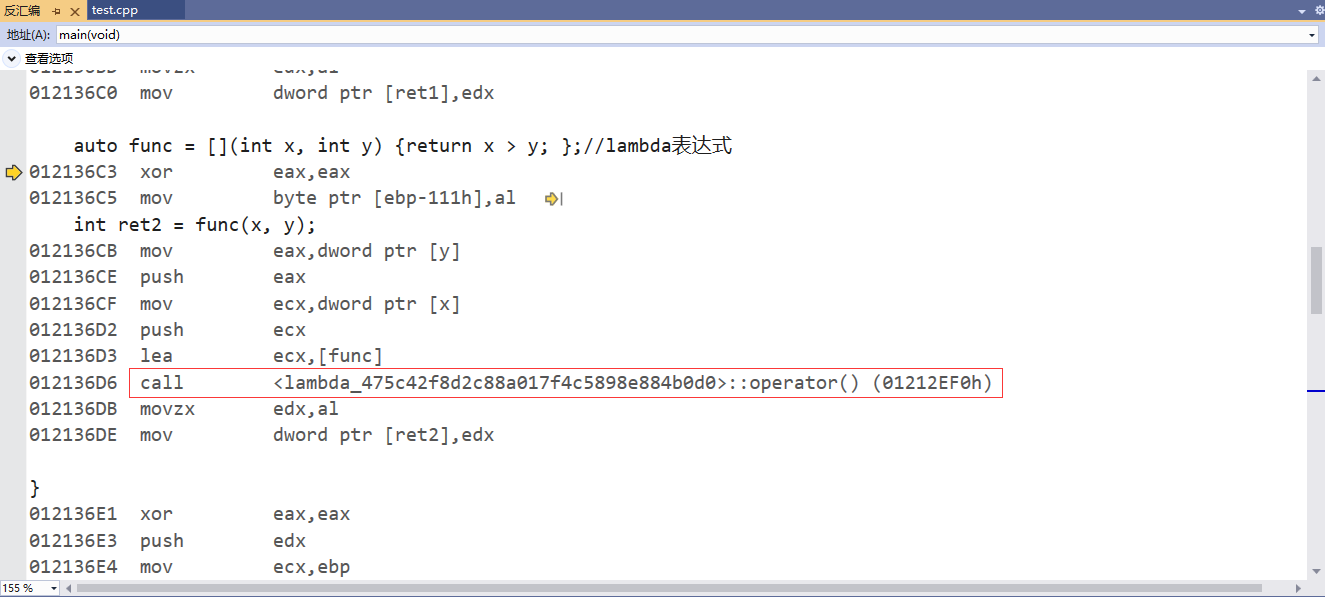
也就是说lambda表达式的底层其实是仿函数,编译器在我们定义lambda表达式时自动生成一个类,并且重载了operator()。
问题
如果lambda表达式相同,编译器生成的类是否相同?
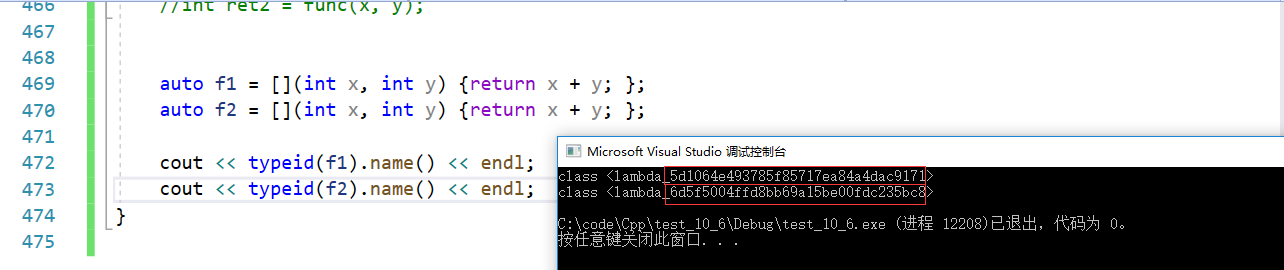
如图,由相同的lambda表达式生成的类是不同的,因为后面的那串字符串。圈起来的字符串是UUID(通用唯一识别码),每个lambda都会自动生成,且通过UUID被识别为不同的类。
7. 可变参数模板
- 在以前C++只支持固定数目的模板参数,C++11有了可变参数模板就可以实现类模板参数和函数参数的传参自由,想传多少就传多少。
//1.Args/args是参数的意思。
//2.Args是模板参数包,args是函数参数包
//3.参数包内可以有任意个参数(0到N)
//4.第一个参数会被T提取,剩余的参数会形成参数包,没有T也是可以的
template<class T,class ...Args>
void Print(T value,Args ...args)//利用模板参数包定义一个函数参数包
{cout << value << endl;
}
- 那如何将参数包内的参数解析出来。args本质是将参数放入一个数组,但不能通过args[i]提取。
template<class T, class ...Args>
void Print(T value, Args ...args)
{cout << value << endl;//这个写法很奇怪,但是它的作用是获得参数包的参数个数,Print传4个实参,一个被value接收,剩下三个放到参数包中cout << sizeof...(args) << endl;for (size_t i = 0; i < sizeof...(args); i++){cout << args[i] << endl;}}
int main()
{Print(1,3.14,'x',"nihao");
}
但是我们发现好像不能直接获得参数包的参数。
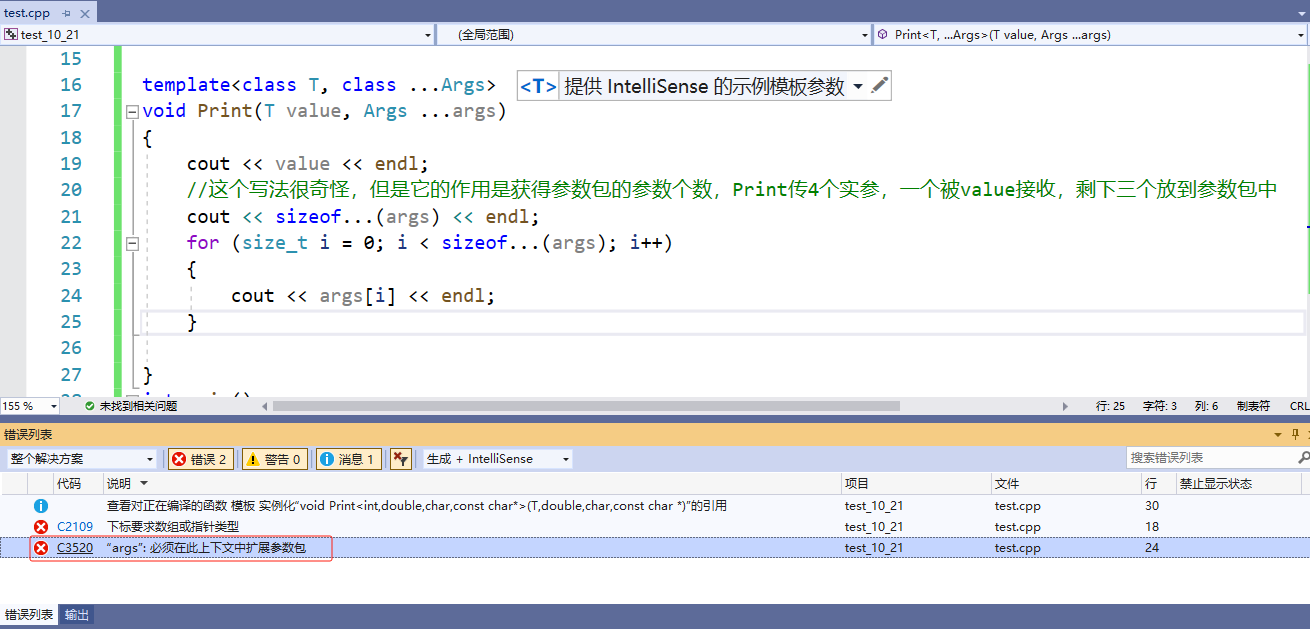
(1)通过递归方式展开参数包
template<class T>
void Print(T value)
{//这个函数的作用是接受参数包的最后一个参数,同时作为递归结束条件。cout << value << endl;
}
template<class T, class ...Args>//加一个参数T,通过T,将参数包的参数一个一个取出来
void Print(T value, Args ...args)
{cout << value << " ";Print(args...);//这个传参也很奇怪
}
int main()
{Print(1,3.14,'x',"nihao");
}
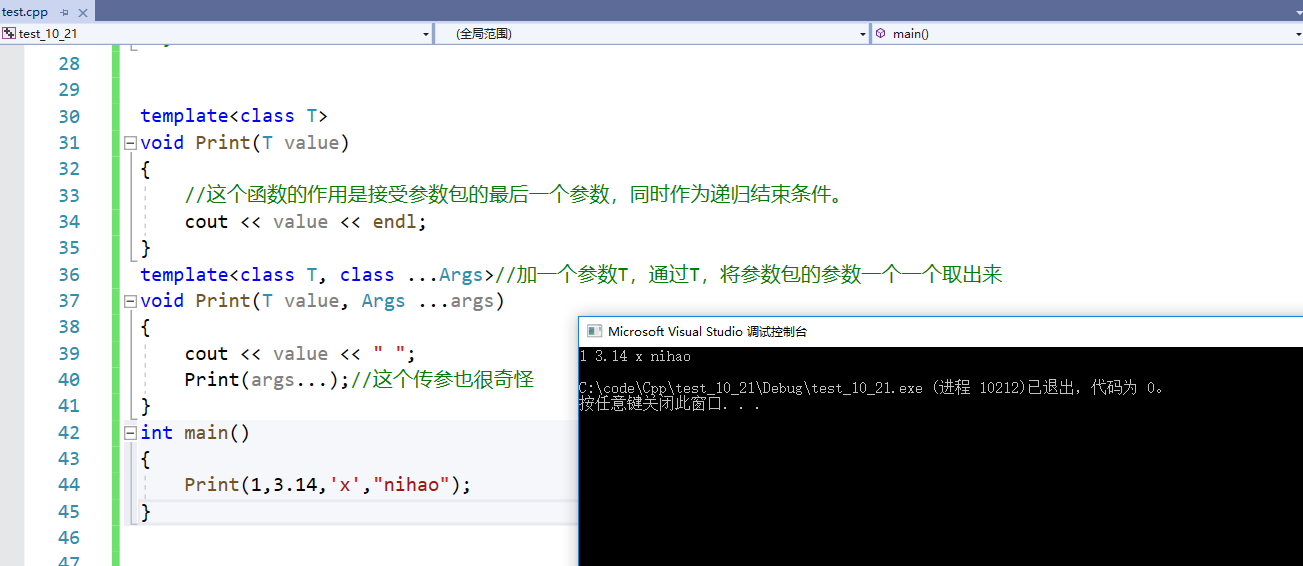
如果不传参数,该怎么办?
//不传参数,就直接调用这个函数;同时如果参数包参数个数为0,也会调用这个函数作为递归结束的标志
void Print()
{cout << endl;
}
template<class T, class ...Args>
void Print(T value, Args ...args)
{cout << value << " ";Print(args...);
}
int main()
{Print();Print(1,3.14,'x',"nihao");
}
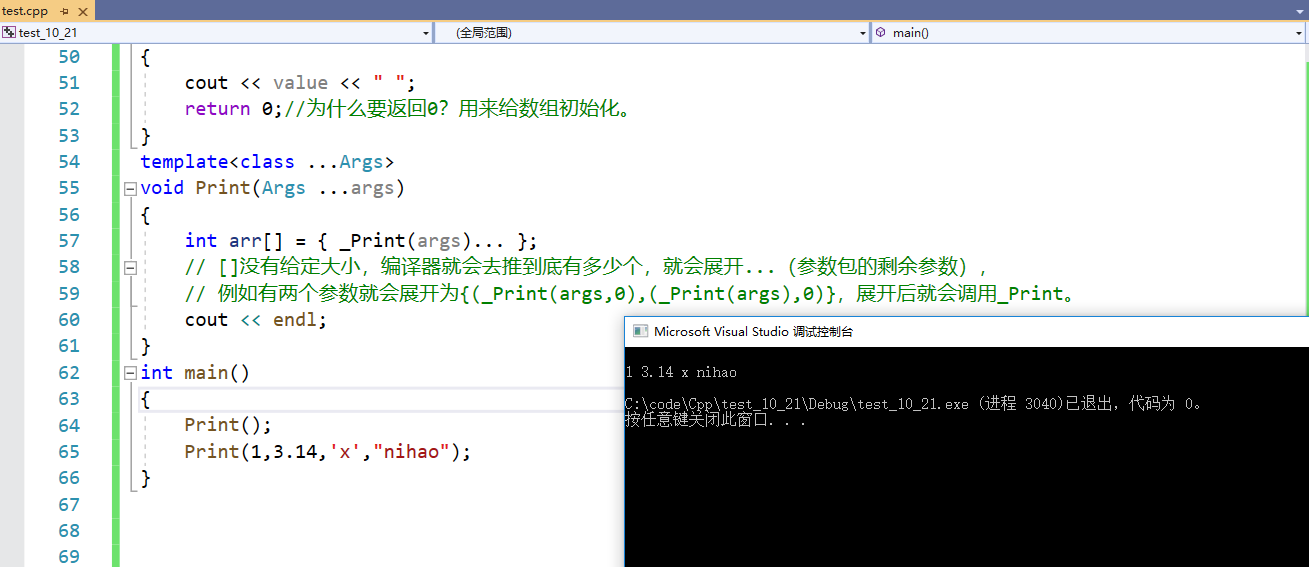
(2)逗号表达式
这是在网上看到的大佬的写法
void Print()//应付不传参数的情况
{cout << endl;
}
template<class T>
int _Print(T value)
{cout << value << " ";return 0;//为什么要返回0?用来给数组初始化。
}
template<class ...Args>
void Print(Args ...args)
{int arr[] = { _Print(args)... };// []没有给定大小,编译器就会去推到底有多少个,就会展开...(参数包的剩余参数),// 例如有两个参数就会展开为{(_Print(args,0),(_Print(args),0)},展开后就会调用_Print。cout << endl;
}
int main()
{Print();Print(1,3.14,'x',"nihao");
}
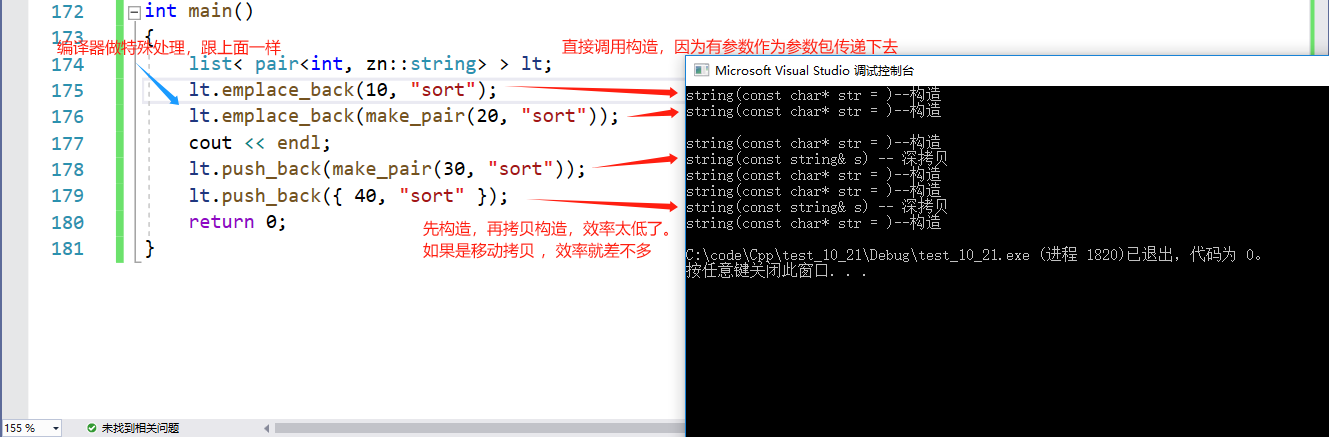
- emplace和emplace_back就应用到参数包


以list为例,这两个函数的作用都是构造+插入元素。
int main()
{list< pair<int, zn::string> > lt;lt.emplace_back(10, "sort");lt.emplace_back(make_pair(20, "sort"));lt.push_back(make_pair(30, "sort"));lt.push_back({ 40, "sort" });return 0;
}
8. 包装器
-
什么是包装器?function是一个类模板,实例化出的对象可以用来包装可调用对象(函数指针、仿函数、lambda表达式)。

-
为什么要有包装器?它是如何进行包装的?
//包装器
//f是可调用对象,可以是函数指针,可以是仿函数,也可以是lambda表达式
template<class F,class T>
void func(F f,T x,T y)
{static int count = 0;//用来标记func是否有实例化多份cout << ++count << endl;f(x, y);
}
//函数
int Add1(int x, int y)
{return x + y;
}
//仿函数
struct Add2
{int operator()(int x, int y){return x + y;}
};
int main()
{//lamda表达式auto Add3 = [](int x, int y) {return x + y; };//函数指针func(Add1, 1, 1);//仿函数func(Add2(), 1, 1);//lambda表达式func(Add3, 1, 1);cout << endl;
};
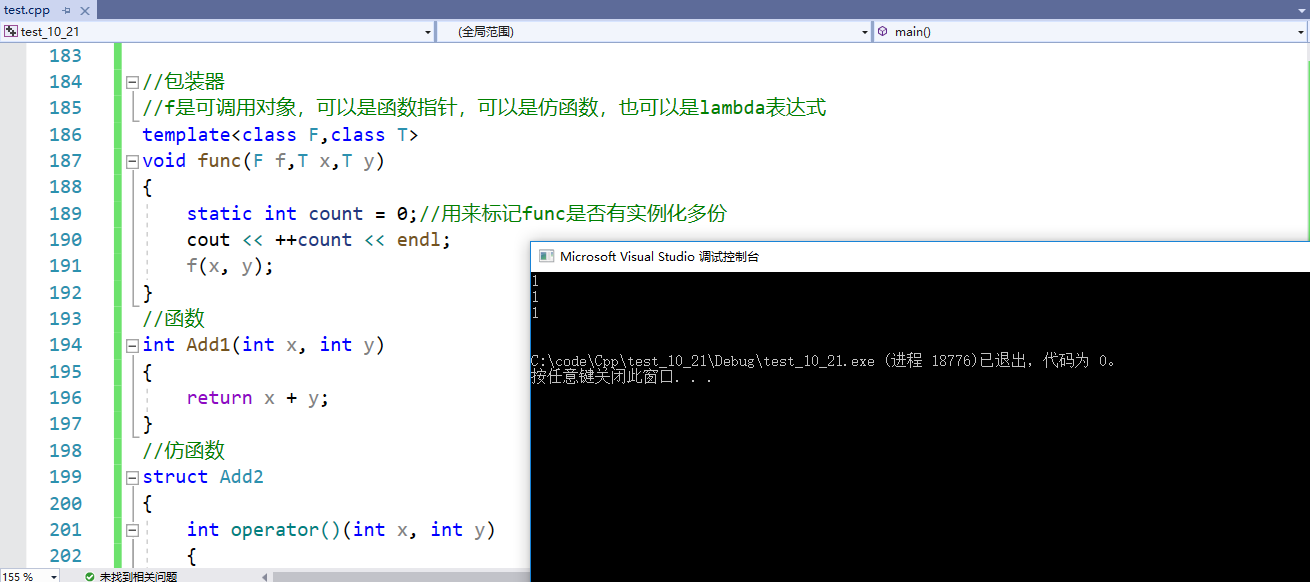
func会被实例化出3份,效率较低。如果我只想实例化一份func,该怎么办?用到function。
function<int(int, int)> add1 = Add1;function<int(int, int)> add2 = Add2();function<int(int, int)> add3 = Add3;func(add1, 2, 2);func(add2, 2, 2);func(add3, 2, 2);
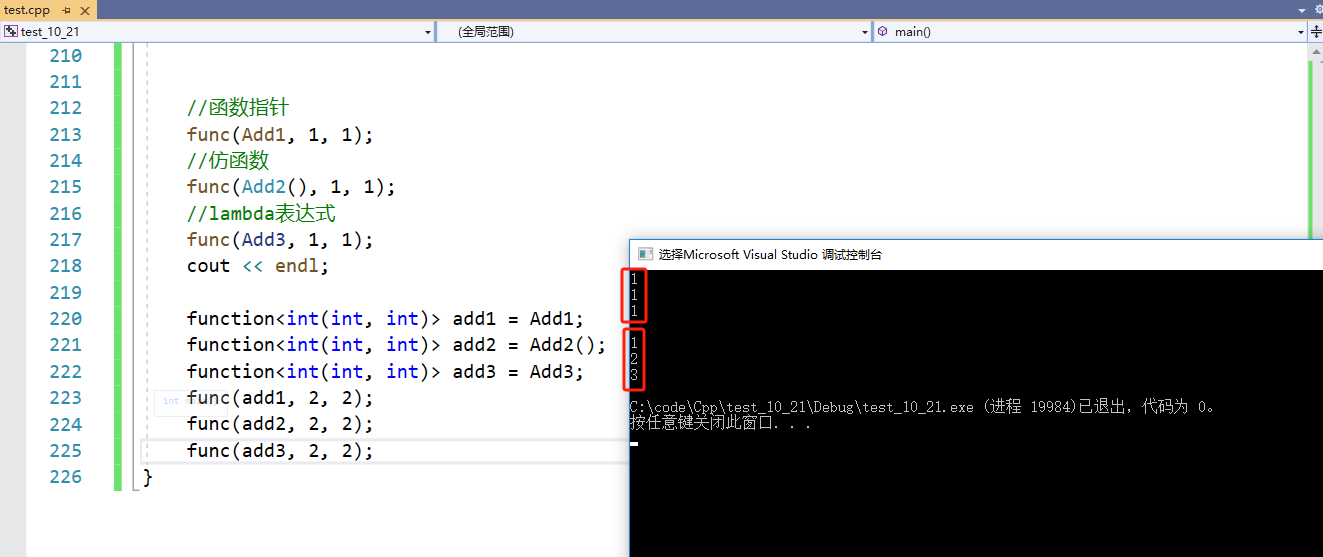
如图,func被实例化成一份,因为是传参是传包装器。
9. bind
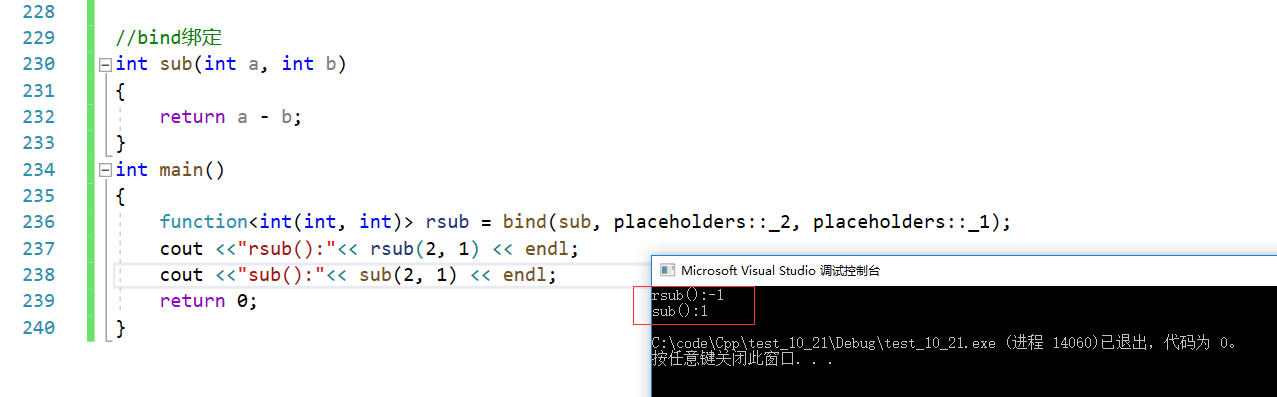
- band绑定是一个函数模板,是一个函数适配器。它接收可调用对象和可变参数,返回可调用对象。它可以用来调整函数的参数顺序和增加函数参数等。

- 一般格式
auto newCallable = bind(callable,arg_list);
newCallable是适配出的可调用对象,它的参数绑定了callable的参数,在arg_list中newCallable的占位符绑定了callable的参数。这个格式看不出什么,直接看例子。
- 例子(bind的作用)
(1)调整函数参数顺序

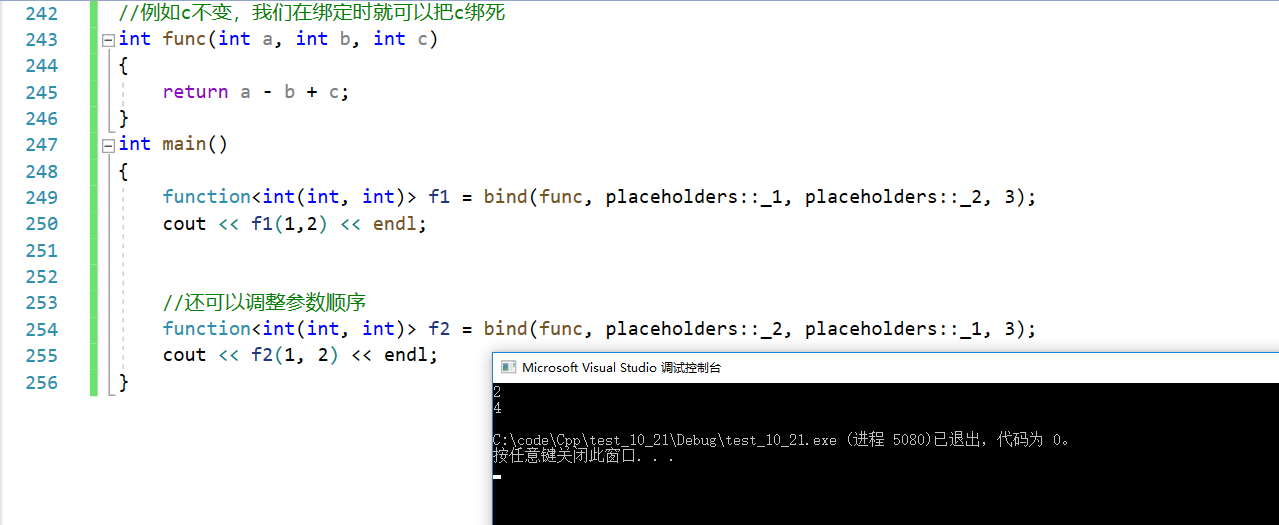
(2)减少函数参数
当一个函数有多个参数,且一些参数是固定的,这时我们就可以把这些参数绑死,适配出少参数的可调用对象。
//例如c不变,我们在绑定时就可以把c绑死
int func(int a, int b, int c)
{return a - b + c;
}
int main()
{function<int(int, int)> f1 = bind(func, placeholders::_1, placeholders::_2, 3);cout << f1(1,2) << endl;//还可以调整参数顺序function<int(int, int)> f2 = bind(func, placeholders::_2, placeholders::_1, 3);cout << f2(1, 2) << endl;
}

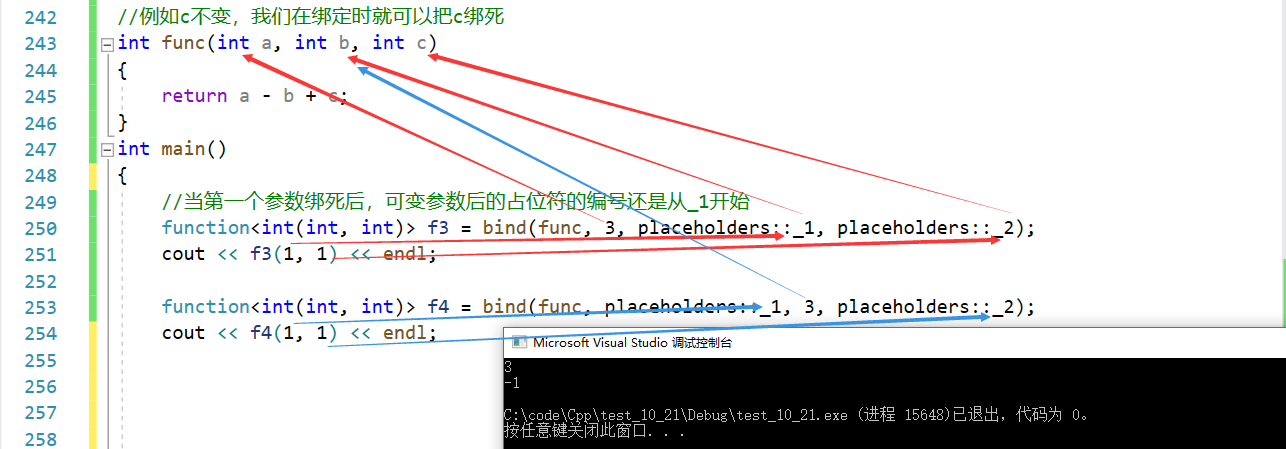
(3)绑定成员函数
class Sub
{
public:static int sub(int a, int b){return a - b;}int ssub(int a, int b){return a - b;}
};
int main()
{// 绑定静态成员函数,需要指定类域function<int(int, int)> func3 = bind(&Sub::sub,placeholders::_1, placeholders::_2);// 绑定成员函数,需要一个具体的可调用对象,需要创建一个类对象,Sub s;//function<int(int, int)> func4 = bind(&Sub::ssub, placeholders::_1, placeholders::_2);//(×)function<int(int, int)> func4 = bind(&Sub::ssub, s , placeholders::_1, placeholders::_2);function<int(int, int)> func5 = bind(&Sub::ssub, Sub(), placeholders::_1, placeholders::_2);
}
相关文章:
【C++】一些C++11特性
C特性 1. 列表初始化1.1 {}初始化1.2 initializer_list 2. 声明2.1 auto2.2 typeid2.3 decltype2.4 nullptr 3. STL3.1 新容器3.2 新接口 4. 右值引用5. 移动构造与移动赋值6. lambda表达式7. 可变参数模板8. 包装器9. bind 1. 列表初始化 1.1 {}初始化 C11支持所有内置类型和…...

leetcode 647. 回文子串、516. 最长回文子序列
647. 回文子串 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成&#…...

Vue Router 刷新当前页面
Vue项目, 在实际工作中, 有些时候需要在 加载完某些数据之后对当前页面进行刷新, 以期 onMounted 等生命周期函数, 或者 数据重新加载. 总之是期望页面可以重新加载一次. 目前总结有三种途径可实现以上需求: 一, reload 直接刷新页面 window.location.reload(); $router.go(…...

lstm 回归实战、 分类demo
预备知识 lstm 参数 输入、输出格式 nn.LSTM(input_dim,hidden_dim,num_layers); imput_dim 特征数 input:(样本数、seq, features_num) h0,c0 (num_layers,seq, hidden_num) output: (样本数、seq, hidden_dim) 再加一个全连接层,将 outpu…...

实践DDD模拟电商系统总结
目录 一、事件风暴 二、系统用例 三、领域上下文 四、架构设计 (一)六边形架构 (二)系统分层 五、系统实现 (一)项目结构 (二)提交订单功能实现 (三࿰…...
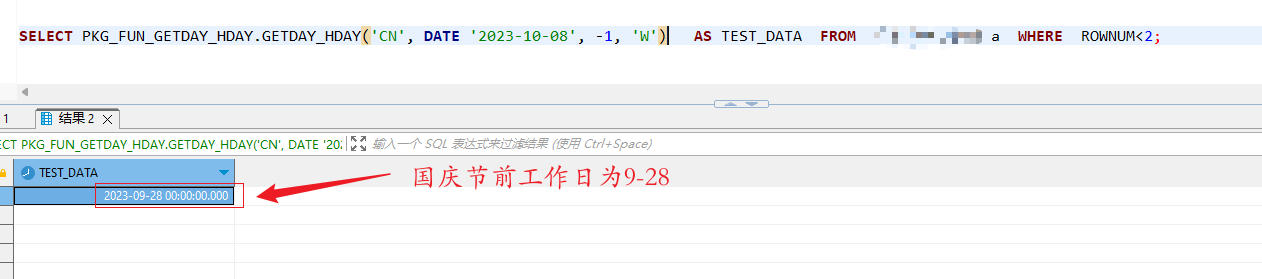
`SQL`编写判断是否为工作日函数编写
SQL编写判断是否为工作日函数编写 最近的自己在写一些功能,遇到了对于工作日的判断,我就看了看sql,来吧!~(最近就是好疲惫) 我们一起看看(针对ORACLE) 1.声明: CREATE OR REPLACE PACKAGE GZYW_2109_1214.PKG_FUN_GETDAY_HDAY AS /** * 通过节假日代码获取指定的日期[查找基…...
零信任身份管理平台,构建下一代网络安全体系
随着数字化时代的到来,网络安全已成为企业和组织面临的一项重要挑战。传统的网络安全方法已经无法满足不断演变的威胁和技术环境。近期,中国信息通信研究院(简称“中国信通院”)发布了《零信任发展研究报告( 2023 年&a…...

《数据结构、算法与应用C++语言描述》使用C++语言实现链表队列
《数据结构、算法与应用C语言描述》使用C语言实现链表队列 定义 队列的定义 队列(queue)是一个线性表,其插入和删除操作分别在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一端称…...
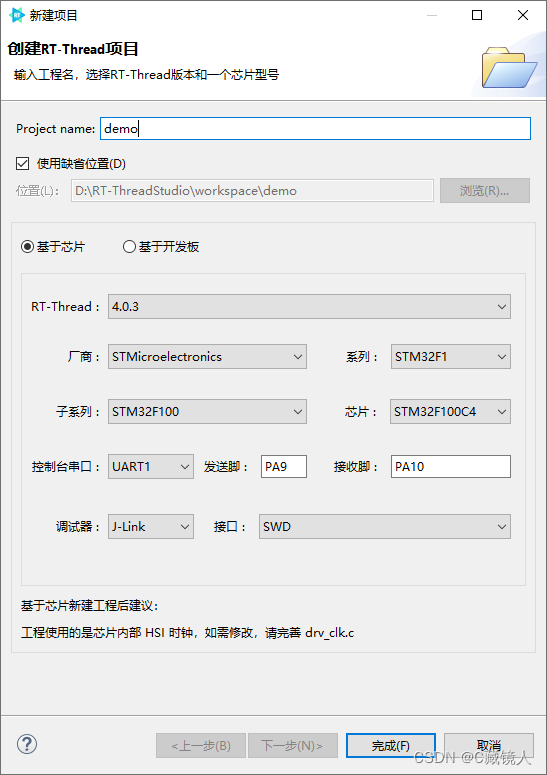
RT-Thread学习笔记(四):RT-Thread Studio工具使用
RT-Thread Studio工具使用 官网详细资料实用操作1. 查看 RT-Thread RTOS API 文档2.打开已创建的工程3.添加头文件路径4. 如何设置生成hex文件5.新建工程 官网详细资料 RT-Thread Studio 用户手册 实用操作 1. 查看 RT-Thread RTOS API 文档 2.打开已创建的工程 如果打开项目…...
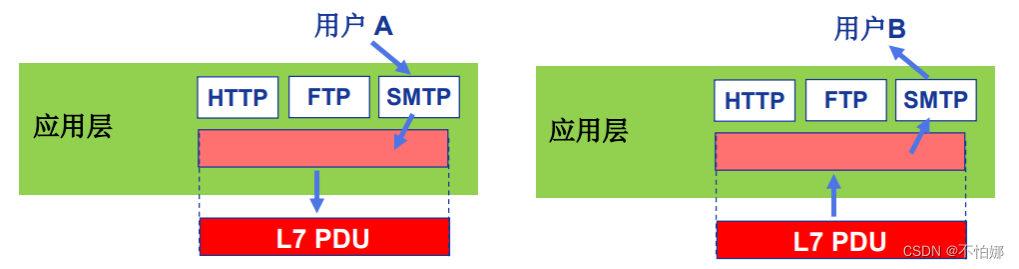
【计算机网络笔记】OSI参考模型中端-端层(传输层、会话层、表示层、应用层)功能介绍
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

RabbitMQ高级知识点
以下是一些 RabbitMQ 的高级知识点: 1. Exchange: RabbitMQ 中的 Exchange 是消息路由器,用来接收消息并且转发到对应的 Queue 中。Exchange 有四种类型:Direct Exchange、Fanout Exchange、Topic Exchange 和 Headers Exchange。…...

Node直接执行ts文件
Node直接执行ts文件 1、常规流程 node 执行 【ts 文件】 流程: 1、编写ts代码 2、编译成js代码 [命令如 :tsc xx.ts] 3、执行js代码 [node xx.js]2、直接执行 想要直接执行 ts 文件,需要安装如下依赖工具。 执行如下命令: # 安装…...

log4j的级别的说明
一 log4j的级别 1.1 级别类型 TRACE 》DEBUG 》 INFO 》 WARN 》 ERROR 》 FATAL 级别高低顺序为: trace级别最低 ,Fatal级别最高。由左到右,从低到高 1.2 包含范围 原则: 本级别包含本级别以及大于本级别的内容,…...

头脑风暴之约瑟夫环问题
一 问题的引入 约瑟夫问题的源头完全可以命名为“自杀游戏”。本着和谐友爱和追求本质的目的,可以把问题描述如下: 现有n个人围成一桌坐下,编号从1到n,从编号为1的人开始报数。报数也从1开始,报到m人离席,…...
【四:Spring整合Junit】
目录 相同点不同点1、导入依赖增加2、编写的位置不同。。路径一定要与实现类一致 相同点 前面都一样和Spring整合mybatis(基于注解形式)一样Spring整合Mybatis 不同点 1、导入依赖增加 <!-- 单元测试 --><dependency><groupId>junit&…...
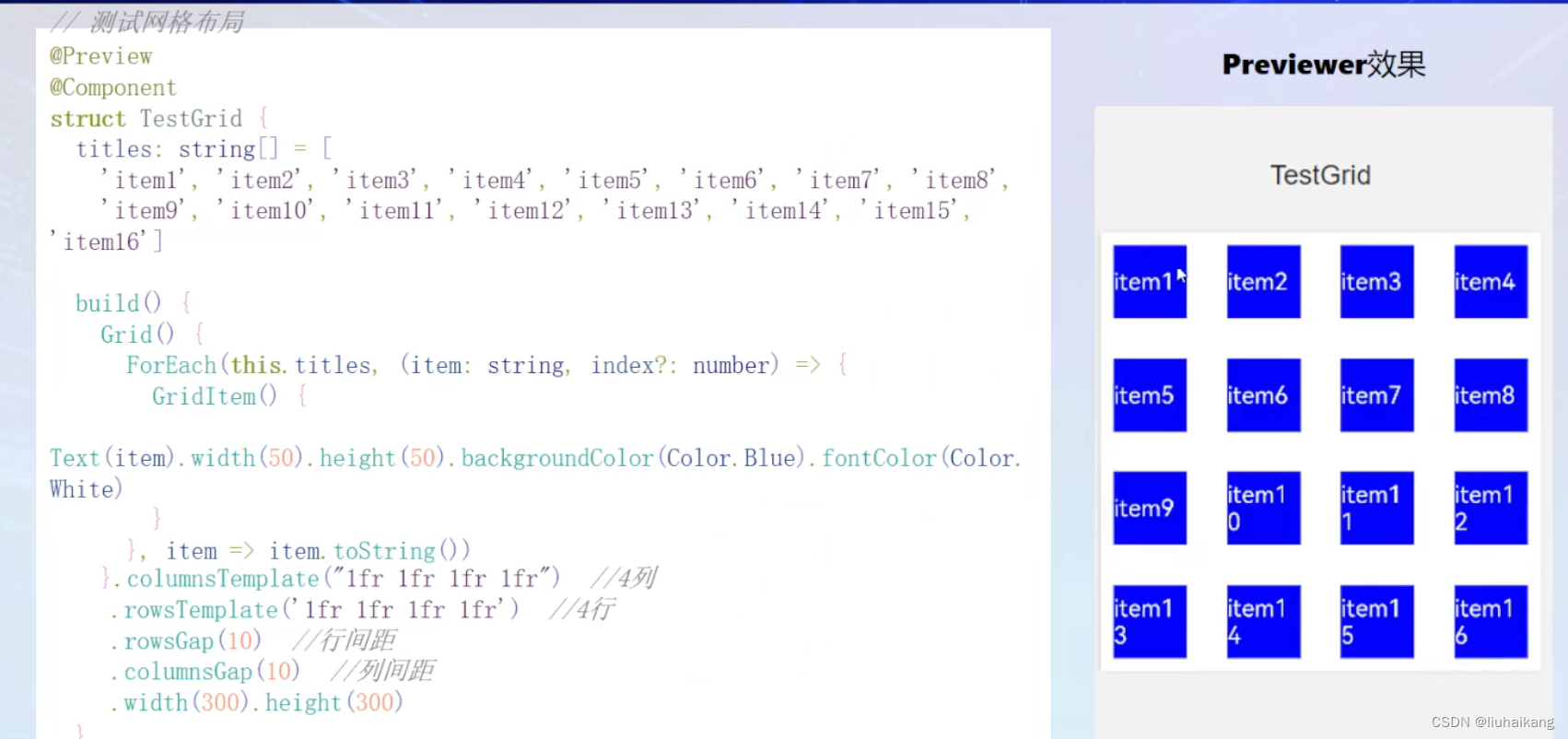
openHarmony UI开发
常用组件和布局方式 组件 ArkUI有丰富的内置组件,包括文本、按钮、图片、进度条、输入框、单选框、多选框等。和布局一样,我们也可以将基础组件组合起来,形成自定义组件。 按钮: Button(Ok, { type: ButtonType.Normal, stateEf…...
Qt 目录操作(QDir 类)及展示系统文件实战 QFilelnfo 类介绍和获取文件属性项目实战
一、目录操作(QDir 类) QDir 类提供访问系统目录结构 QDir 类提供对目录结构及其内容的访问。QDir 用于操作路径名、访问有关路径和文件的信息以及操作底层文件系统。它还可以用于访问 Qt 的资源系统 Qt 使用“/”作为通用目录分隔符,与“/”在 URL 中用作路径分…...

2023-9-12 阿里健康2024秋招后端开发-体检及泛医疗二面
1 自我介绍 2 快手实习 2.1 说说你在实习期间遇到的挑战、收获 (1)在设计模式的应用能力上,有了很大的提高,使用模板设计模式,架构实例反向同步到架构定义,使用了策略模式 (2) …...
Qt扫盲-QBrush理论使用总结
Q 理论使用总结 一、概述1. 填充模式2. 笔刷颜色3. 纹理 二、 Qt::GlobalColor 一、概述 QBrush类定义了由 QPainter 绘制的形状的填充模式。画笔有样式、颜色、渐变和纹理。 brush style() 使用Qt::BrushStyle 枚举定义填充模式。默认的笔刷样式是 Qt::NoBrush(取决于你如何…...

互联网Java工程师面试题·Java 面试篇·第三弹
目录 39、JRE、JDK、JVM 及 JIT 之间有什么不同? 40、解释 Java 堆空间及 GC? 41、你能保证 GC 执行吗? 42、怎么获取 Java 程序使用的内存?堆使用的百分比? 43、Java 中堆和栈有什么区别? 44、“ab”…...

当你的无人机被厂商“绑架“:如何用DankDroneDownloader夺回控制权
当你的无人机被厂商"绑架":如何用DankDroneDownloader夺回控制权 【免费下载链接】DankDroneDownloader A Custom Firmware Download Tool for DJI Drones Written in C# 项目地址: https://gitcode.com/gh_mirrors/da/DankDroneDownloader 你是否…...

3分钟轻松上手:RPG Maker加密文件解密实战指南
3分钟轻松上手:RPG Maker加密文件解密实战指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMaker…...
)
别再死记硬背了!用这5个生活化例子,轻松搞定对数公式(附Markdown速查表)
别再死记硬背了!用这5个生活化例子,轻松搞定对数公式(附Markdown速查表) 数学公式之所以让人望而生畏,往往不是因为它们本身有多复杂,而是缺乏与现实世界的连接。对数运算尤其如此——当它从抽象的符号变成…...

Amazon速卖通双平台卖家必看:在线图片翻译工具帮你批量搞定多语言商品上架
【一、同时做Amazon和速卖通,商品图翻译的麻烦翻了一倍】 很多跨境电商卖家同时经营Amazon和速卖通两个平台。两个平台的买家群体不同、市场定位不同,但有一个共同点:商品图上的文字需要翻译成目标语言,否则海外买家看不懂。 问题…...
)
别再死记硬背了!用Python+Qiskit动手模拟RX、RY、RZ旋转门(附代码)
用PythonQiskit可视化量子旋转门:从布洛赫球到代码实现 量子计算正在从实验室走向现实应用,而理解量子逻辑门是掌握这一前沿技术的关键。对于初学者来说,传统教学中复杂的矩阵运算和抽象数学推导往往成为学习障碍。本文将带你用Python和Qiski…...

暴雨“钉”在桂北第6天:兴安296mm特大暴雨,桂林柳州风电场正在经历什么?
4月的广西,本不该这样下雨。过去几天,一条强降雨带稳稳盘踞在桂北一带,桂林、柳州相继出现成片的大暴雨区。桂林兴安县更是下出了296毫米的特大暴雨——相当于一天之内把北京半年的雨量倒在了这座县城。广西气象台的预报显示,这场…...

DCT-Net人像卡通化简单教程:拍好原图,一键生成完美卡通头像
DCT-Net人像卡通化简单教程:拍好原图,一键生成完美卡通头像 1. 为什么选择DCT-Net进行人像卡通化? 在众多人像卡通化工具中,DCT-Net凭借其出色的效果和易用性脱颖而出。这个基于深度学习的模型能够智能分析人脸特征,…...

MySQL存储过程如何实现循环打印日志_调试信息输出技巧
MySQL存储过程调试首选建临时日志表INSERT记录,或用SELECT CONCAT输出(仅开发环境手动调用有效);禁用SIGNAL抛异常打日志,因其中断执行且低版本不支持;循环内应批量拼接日志再插入以提升性能。MySQL存储过程…...
规模创新高,资金持续净流入布局有色矿业)
有色ETF华安(512940.SH)规模创新高,资金持续净流入布局有色矿业
4月20日,有色ETF华安(512940.SH)震荡上行,截至收盘报0.959元,涨幅0.63%,同步跟踪的中证有色金属矿业指数上涨0.64%,日内走势与标的指数高度贴合,呈现出良好的跟踪效果。据红色火箭数…...

077、代码实战十九:扩散模型生成结果的偏见与多样性分析
一、从一次深夜调试说起 上周团队 review 生成结果时,发现一个诡异现象:连续生成 100 张“医生”图片,89 张是男性戴眼镜的白大褂形象;生成“护士”则 94 张是女性。数据组同事把统计结果扔过来时,我背后一凉——这模型怕不是从训练数据里学到了全套社会刻板印象。 更麻…...