Hive篇面试题+详解
Hive篇面试题
1.什么是Hive?它的主要功能是什么?
Hive是一个基于Hadoop的数据仓库工具,它提供了一个类SQL的查询语言(HiveQL)来查询和分析存储在Hadoop集群中的大规模数据。Hive的主要功能是将结构化数据映射到Hadoop的分布式文件系统(HDFS)上,并提供高级查询和分析功能。
2.Hive与传统关系型数据库的区别是什么?
Hive与传统关系型数据库的主要区别在于数据存储和查询方式。传统关系型数据库使用表格格式存储数据,并使用SQL语言进行查询,而Hive使用HDFS存储数据,并使用类SQL的HiveQL语言进行查询。此外,Hive适用于大规模数据的批处理和分析,而传统关系型数据库更适用于实时事务处理。
3.Hive的架构是什么样的?请解释各个组件的作用。
Hive的架构包括三个主要组件:Hive客户端、Hive服务和Hive Metastore。
- Hive客户端:Hive客户端是用户与Hive交互的界面,用户可以使用HiveQL语言向Hive发送查询和命令。
- Hive服务:Hive服务包括Hive查询执行引擎和Hive驱动程序。它负责解析HiveQL查询,生成查询计划,并将查询发送到底层的执行引擎(如MapReduce、Tez等)执行。
- Hive Metastore:Hive Metastore负责管理和存储Hive表的元数据,包括表的结构、分区信息等。它通常使用关系型数据库(如MySQL、PostgreSQL)来存储元数据。
4.Hive Metastore是什么?它的作用是什么?它如何管理和存储Hive表的元数据?
Hive Metastore是Hive的一个组件,用于管理和存储Hive表的元数据。元数据包括表的结构、分区信息、表位置等。Hive Metastore使用关系型数据库来存储元数据,它提供了一组API和服务,用于查询、更新和管理Hive表的元数据。通过Hive Metastore,不同的用户和进程可以共享和访问相同的元数据,从而协调和共享表的结构和属性。
5.Hive表的存储格式有哪些?请介绍它们的特点和适用场景。
Hive支持多种存储格式,包括文本文件、序列文件、RC文件、ORC文件和Parquet文件等。
- 文本文件:适用于存储结构简单的数据,易于读写和处理,但性能较差。
- 序列文件:适用于大规模数据的读写操作,提供高压缩率和高性能。
- RC文件:适用于大规模数据的读取操作,提供更好的数据压缩和查询性能。
- ORC文件:适用于大规模数据的读取和查询操作,提供更高的压缩率和查询性能。
- Parquet文件:适用于大规模数据的读取和查询操作,提供更高的压缩率和列式存储优势。
6.Hive的分区是什么?它的作用是什么?如何创建和管理分区?
Hive的分区是将表的数据按照某个列(通常是时间或地区等)划分为多个子目录或文件。分区的作用是提高查询性能和过滤效率,同时可以更灵活地管理和组织数据。可以使用PARTITIONED BY子句在创建表时定义分区列,或者使用ALTER TABLE命令来添加、修改和删除分区
7.Hive的Bucketing是什么?它的作用是什么?如何创建和使用Bucketing?
Hive的Bucketing是一种数据分桶技术,它将表的数据根据某个列的哈希值分成固定数量的桶(buckets)。Bucketing的作用是提高查询性能,通过将相关数据存储在同一个桶中,可以减少数据的扫描量。
可以使用CLUSTERED BY子句在创建表时定义Bucketing列,并使用SORTED BY子句来指定排序列。例如,创建一个具有Bucketing的表可以使用以下语法:
CREATE TABLE table_name (col1 data_type, col2 data_type, ...)
CLUSTERED BY (bucket_column) SORTED BY (sort_column) INTO num_buckets BUCKETS;
在查询时,可以使用CLUSTER BY子句指定按照Bucketing列进行聚类,以提高查询性能。
8.Hive的数据类型有哪些?分别介绍它们的特点和使用场景。
Hive支持多种数据类型,包括基本类型(如整数、字符串、布尔值等)和复杂类型(如数组、结构体、映射等)。
- 基本类型:包括整数、浮点数、字符串、布尔值等。这些类型用于存储简单的数据,支持各种常见的操作和函数。
- 复杂类型:包括数组、结构体、映射等。数组用于存储可变长度的有序元素,结构体用于存储多个字段的组合,映射用于存储键值对。这些类型适用于存储和处理复杂的数据结构。
9.Hive的查询语言是什么?请提供一些常见的Hive查询语句示例。
Hive的查询语言是HiveQL,它类似于SQL语言。以下是一些常见的Hive查询语句示例:
- 查询表中的所有数据:
SELECT * FROM table_name; - 查询表中的特定字段:
SELECT col1, col2 FROM table_name; - 带有过滤条件的查询:
SELECT * FROM table_name WHERE col1 > 10; - 聚合查询:
SELECT COUNT(*) FROM table_name; - 使用JOIN操作进行表连接:
SELECT * FROM table1 JOIN table2 ON table1.col1 = table2.col1; - 分组和聚合操作:
SELECT col1, COUNT(*) FROM table_name GROUP BY col1;
10.Hive支持的内置函数有哪些?请举例说明它们的用法。
Hive支持多种内置函数,包括数学函数、字符串函数、日期函数、聚合函数等。以下是一些常见的内置函数及其用法示例:
- 数学函数:
ABS(value)计算绝对值,ROUND(value, digits)对值进行四舍五入。 - 字符串函数:
LENGTH(str)返回字符串的长度,SUBSTR(str, start, length)返回字符串的子串。 - 日期函数:
YEAR(date)返回日期的年份,MONTH(date)返回日期的月份。 - 聚合函数:
COUNT(*)计算行数,SUM(col)计算列的总和。
11.Hive支持的连接方式有哪些?请说明它们的特点和适用场景。
Hive支持多种连接方式,包括内连接、外连接和交叉连接。
- 内连接(INNER JOIN):内连接返回两个表中匹配的行,即只返回两个表中共有的行。适用于需要获取两个表中共有的数据的场景。
- 左外连接(LEFT OUTER JOIN):左外连接返回左表中所有的行以及与右表匹配的行。如果右表中没有匹配的行,将返回NULL值。适用于需要获取左表所有行以及与右表匹配的行的场景。
- 右外连接(RIGHT OUTER JOIN):右外连接返回右表中所有的行以及与左表匹配的行。如果左表中没有匹配的行,将返回NULL值。适用于需要获取右表所有行以及与左表匹配的行的场景。
- 全外连接(FULL OUTER JOIN):全外连接返回两个表中所有的行,并将不匹配的行填充为NULL值。适用于需要获取两个表中所有行的场景。
12.Hive的索引是什么?它的作用是什么?Hive支持哪些类型的索引?
Hive的索引是一种数据结构,用于加快查询和过滤操作的速度。它可以提供快速的数据定位,减少数据扫描的量。
Hive支持两种类型的索引:B树索引和位图索引。
- B树索引:B树索引适用于等值查询和范围查询,它通过构建一棵平衡的B树来存储索引数据。B树索引可以加速等值查询和范围查询的速度,但对于模糊查询和排序操作的效果较差。
- 位图索引:位图索引适用于低基数列的等值查询,它通过为每个不同的值创建一个位图来存储索引数据。位图索引可以提供非常快速的等值查询速度,但对于范围查询和排序操作的效果较差。
13.如何在Hive中创建索引?请提供一个创建索引的示例。
在Hive中,可以使用CREATE INDEX语句来创建索引。以下是一个创建B树索引的示例:
CREATE INDEX index_name ON TABLE table_name (column_name) AS 'btree' WITH DEFERRED REBUILD;
该语句创建一个名为index_name的B树索引,将其应用于table_name表的column_name列。WITH DEFERRED REBUILD选项表示索引在创建后不会立即构建,而是在之后的时间点进行构建。
14.Hive的分区和索引有什么区别?它们是如何共同作用的?
Hive的分区和索引是用于提高查询性能和过滤效率的两种不同的技术。
- 分区通过将数据划分为多个子目录或文件,可以提高查询性能和过滤效率。分区可以根据某个列(通常是时间或地区等)进行划分,从而使查询只需要处理符合特定条件的数据。
- 索引通过创建特定的数据结构,可以加快查询和过滤操作的速度。索引可以提供快速的数据定位,减少数据扫描的量。
分区和索引可以共同作用,从而进一步提高查询性能。通过在分区列上创建索引,可以在进行查询时更快地定位到特定分区,从而减少数据扫描的范围,提高查询效率。
15.Hive的动态分区是什么?它与静态分区有何区别?
Hive的动态分区是一种动态分区是指在插入数据时,根据插入语句中的列值动态创建分区。动态分区可以根据插入的数据自动创建分区目录,无需预先定义分区。
16.Hive支持的连接方式有哪些?请说明它们的特点和适用场景。
Hive支持多种连接方式,包括内连接、外连接和交叉连接。
- 内连接(INNER JOIN):内连接返回两个表中匹配的行,即只返回两个表中共有的行。适用于需要获取两个表中共有的数据的场景。
- 左外连接(LEFT OUTER JOIN):左外连接返回左表中所有的行以及与右表匹配的行。如果右表中没有匹配的行,将返回NULL值。适用于需要获取左表所有行以及与右表匹配的行的场景。
- 右外连接(RIGHT OUTER JOIN):右外连接返回右表中所有的行以及与左表匹配的行。如果左表中没有匹配的行,将返回NULL值。适用于需要获取右表所有行以及与左表匹配的行的场景。
- 全外连接(FULL OUTER JOIN):全外连接返回两个表中所有的行,并将不匹配的行填充为NULL值。适用于需要获取两个表中所有行的场景。
17.Hive的索引是什么?它的作用是什么?Hive支持哪些类型的索引?
Hive的索引是一种数据结构,用于加快查询和过滤操作的速度。它可以提供快速的数据定位,减少数据扫描的量。
Hive支持两种类型的索引:B树索引和位图索引。
- B树索引:B树索引适用于等值查询和范围查询,它通过构建一棵平衡的B树来存储索引数据。B树索引可以加速等值查询和范围查询的速度,但对于模糊查询和排序操作的效果较差。
- 位图索引:位图索引适用于低基数列的等值查询,它通过为每个不同的值创建一个位图来存储索引数据。位图索引可以提供非常快速的等值查询速度,但对于范围查询和排序操作的效果较差。
18.如何在Hive中创建索引?请提供一个创建索引的示例。
在Hive中,可以使用CREATE INDEX语句来创建索引。以下是一个创建B树索引的示例:
CREATE INDEX index_name ON TABLE table_name (column_name) AS 'btree' WITH DEFERRED REBUILD;
该语句创建一个名为index_name的B树索引,将其应用于table_name表的column_name列。WITH DEFERRED REBUILD选项表示索引在创建后不会立即构建,而是在之后的时间点进行构建。
19.Hive的分区和索引有什么区别?它们是如何共同作用的?
Hive的分区和索引是用于提高查询性能和过滤效率的两种不同的技术。
- 分区通过将数据划分为多个子目录或文件,可以提高查询性能和过滤效率。分区可以根据某个列(通常是时间或地区等)进行划分,从而使查询只需要处理符合特定条件的数据。
- 索引通过创建特定的数据结构,可以加快查询和过滤操作的速度。索引可以提供快速的数据定位,减少数据扫描的量。
分区和索引可以共同作用,从而进一步提高查询性能。通过在分区列上创建索引,可以在进行查询时更快地定位到特定分区,从而减少数据扫描的范围,提高查询效率。
20.Hive的动态分区是什么?它与静态分区有何区别?
Hive的动态分区是一种动态分区是指在插入数据时,根据插入语句中的列值动态创建分区。动态分区可以根据插入的数据自动创建分区目录,无需预先定义分区。
与之相反,静态分区是在创建表时就定义好的分区。在插入数据时,需要明确指定插入的分区。
动态分区的优势在于可以根据实际的数据动态创建分区目录,灵活性更高,适用于数据量较大且需要频繁插入的场景。而静态分区适用于分区结构相对固定、不需要频繁插入的场景。
21.Hive中的压缩是什么?它的作用是什么?Hive支持哪些压缩算法?
在Hive中,压缩是一种将数据以更高效的方式存储的技术。压缩可以减少磁盘空间的使用,提高数据的读写效率。
压缩的主要作用是减少磁盘空间的占用,从而节省存储成本。同时,压缩还可以提高数据的读写效率,减少磁盘IO和网络传输的数据量,提高查询性能。
Hive支持多种压缩算法,包括:
- Gzip:Gzip是一种通用的压缩算法,可以提供较高的压缩比,但对于查询性能的影响较大。
- Snappy:Snappy是一种较为快速的压缩算法,压缩比相对较低,但对于查询性能的影响较小。
- LZO:LZO是一种高性能的压缩算法,压缩比和查询性能都相对较好,但需要额外的配置和安装。
22.如何在Hive中启用压缩?请提供一个启用压缩的示例。
在Hive中,可以使用SET语句来启用压缩。以下是一个启用Snappy压缩的示例:
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
以上示例中,第一行设置Hive输出压缩为true,第二行设置MapReduce输出压缩为true,第三行设置压缩编解码器为SnappyCodec。
23.Hive中的分桶是什么?它与分区和索引有何区别?*
Hive中的分桶是一种将数据划分为多个桶的技术。每个桶包含的数据量相对均衡,可以提高查询效率。
与分区相比,分桶是将数据按照某种规则划分为多个桶,而不是按照列的值进行划分。分桶可以更细粒度地控制数据的划分,适用于需要更细粒度的数据过滤和查询的场景。
与索引相比,分桶是通过将数据分散在不同的桶中来提高查询效率,而索引是通过构建特定的数据结构来加速查询。分桶可以在一定程度上提高查询性能,但对于某些查询操作(如范围查询)的效果可能不如索引。
与之相反,静态分区是在创建表时就定义好的分区。在插入数据时,需要明确指定插入的分区。
动态分区的优势在于可以根据实际的数据动态创建分区目录,灵活性更高,适用于数据量较大且需要频繁插入的场景。而静态分区适用于分区结构相对固定、不需要频繁插入的场景。
24.Hive中的压缩是什么?它的作用是什么?Hive支持哪些压缩算法?
在Hive中,压缩是一种将数据以更高效的方式存储的技术。压缩可以减少磁盘空间的使用,提高数据的读写效率。
压缩的主要作用是减少磁盘空间的占用,从而节省存储成本。同时,压缩还可以提高数据的读写效率,减少磁盘IO和网络传输的数据量,提高查询性能。
Hive支持多种压缩算法,包括:
- Gzip:Gzip是一种通用的压缩算法,可以提供较高的压缩比,但对于查询性能的影响较大。
- Snappy:Snappy是一种较为快速的压缩算法,压缩比相对较低,但对于查询性能的影响较小。
- LZO:LZO是一种高性能的压缩算法,压缩比和查询性能都相对较好,但需要额外的配置和安装。
25.如何在Hive中启用压缩?请提供一个启用压缩的示例。
在Hive中,可以使用SET语句来启用压缩。以下是一个启用Snappy压缩的示例:
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
以上示例中,第一行设置Hive输出压缩为true,第二行设置MapReduce输出压缩为true,第三行设置压缩编解码器为SnappyCodec。
26.Hive中的分桶是什么?它与分区和索引有何区别?
Hive中的分桶是一种将数据划分为多个桶的技术。每个桶包含的数据量相对均衡,可以提高查询效率。
与分区相比,分桶是将数据按照某种规则划分为多个桶,而不是按照列的值进行划分。分桶可以更细粒度地控制数据的划分,适用于需要更细粒度的数据过滤和查询的场景。
与索引相比,分桶是通过将数据分散在不同的桶中来提高查询效率,而索引是通过构建特定的数据结构来加速查询。分桶可以在一定程度上提高查询性能,但对于某些查询操作(如范围查询)的效果可能不如索引。
27.Hive支持的数据导入和导出方式有哪些?请介绍它们的用法和适用场景。
Hive支持的数据导入和导出方式有多种,包括:
- 通过HiveQL语句进行数据导入和导出:可以使用
LOAD DATA语句将本地或HDFS上的数据导入到Hive表中,也可以使用INSERT INTO语句将Hive表中的数据导出到本地或HDFS上的文件中。 - 使用Hive的外部表进行数据导入和导出:可以创建外部表,然后将数据文件放置在外部表指定的位置,这样就可以直接访问外部表中的数据。
- 使用Hive的ETL工具,如Sqoop和Flume,进行数据导入和导出:Sqoop用于将关系型数据库中的数据导入到Hive表中,Flume用于实时地将数据流导入到Hive表中。
不同的数据导入和导出方式适用于不同的场景。如果数据量较小且对性能要求较高,可以使用HiveQL语句进行导入和导出。如果数据量较大或需要实时导入数据,可以考虑使用外部表或ETL工具进行数据导入和导出。
28.Hive的性能优化有哪些方面?请列举一些常见的性能优化技巧。*
Hive的性能优化可以从多个方面进行,包括:
- 数据分区和分桶:通过将数据划分为多个分区和桶,可以减少数据扫描的范围,提高查询效率。
- 压缩:使用压缩算法可以减少磁盘空间的使用,提高数据的读写效率。
- 数据倾斜处理:对于存在数据倾斜的情况,可以采取一些优化措施,如使用动态分区、调整分桶数量等。
- 合理的数据类型选择:选择合适的数据类型可以减少存储空间的占用和数据的序列化/反序列化开销。
- 合理的查询优化:如使用合适的Join类型、合理的Join顺序、适当的过滤条件等。
- 使用合适的硬件配置:如调整内存、磁盘和网络等参数,以提高查询性能。
这只是一些常见的性能优化技巧,具体的优化策略还应根据具体的场景和需求进行调整。
29.Hive中的“SerDe”是什么?
在Hive中,SerDe(Serializer/Deserializer)是指用于处理数据序列化和反序列化的组件。它是Hive的一个重要概念,用于将数据在Hive表和底层存储格式之间进行转换。
SerDe允许Hive读取和写入不同的数据格式,例如文本、CSV、JSON、Avro等。它负责将表中的数据与存储格式之间进行转换,使得Hive可以与各种不同的数据源进行交互。
当Hive读取数据时,SerDe将数据从底层存储格式(如HDFS文件)中反序列化为Hive表的列,并将它们转换为Hive可以理解和处理的格式。
当Hive写入数据时,SerDe将Hive表的列序列化为底层存储格式,以便将其写入到文件或其他数据源中。
30.说说Hive Metastore
Hive Metastore是Hive的元数据存储和管理组件,负责存储和管理Hive表的结构、分区信息等元数据。它允许多个Hive客户端和服务共享和访问相同的元数据,提供了元数据的查询、更新、管理和权限控制等功能。
31.默认的“Hive Metastore”可以被多个用户(进程)同时使用吗?
Hive Metastore使用关系型数据库(如MySQL、PostgreSQL等)来存储元数据。大多数关系型数据库都采用悲观锁机制,即在写操作期间锁定数据,以防止并发访问导致的数据不一致性。因此,默认情况下,Hive Metastore在写操作期间会锁定元数据,阻塞其他用户/进程的访问。
当一个用户/进程正在执行写操作(例如创建表、修改表结构等)时,其他用户/进程可能会被阻塞,直到该写操作完成。这意味着默认情况下,Hive Metastore不支持并发的写操作。
然而,默认情况下,Hive Metastore是支持并发的读操作的。多个用户/进程可以同时进行元数据的读取操作,例如查询表结构、分区信息等。
如果需要支持并发的写操作,可以考虑使用Hive Metastore的分布式模式,如Hive Metastore Server(HMS)和Apache ZooKeeper等。这些解决方案可以提供更好的并发性和扩展性,以满足高并发的需求。
32.“Hive”存储表数据的默认位置是什么?
Hive存储表数据的默认位置是由${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定的。
默认情况下,Hive会将表数据存储在HDFS的/user/hive/warehouse。
更多内容请看主页~
如对您有帮助,欢迎点赞收藏!!!
👍👍👍
相关文章:

Hive篇面试题+详解
Hive篇面试题 1.什么是Hive?它的主要功能是什么? Hive是一个基于Hadoop的数据仓库工具,它提供了一个类SQL的查询语言(HiveQL)来查询和分析存储在Hadoop集群中的大规模数据。Hive的主要功能是将结构化数据映射到Hadoop…...

Mysql批量插入更新如何拆分大事务?
拆分大事务 一、解决方案二、遇到问题之前在运行Mysql任务的时候报错:binlog(1610646347 bytes) write threshold exceeded,原因是Mysql任务提交的是个大事务,超出binlog设定阈值,使得系统自动终止事务 一、解决方案 使用limit分页拆分大事务 CREATE PROCEDURE `split_tran…...
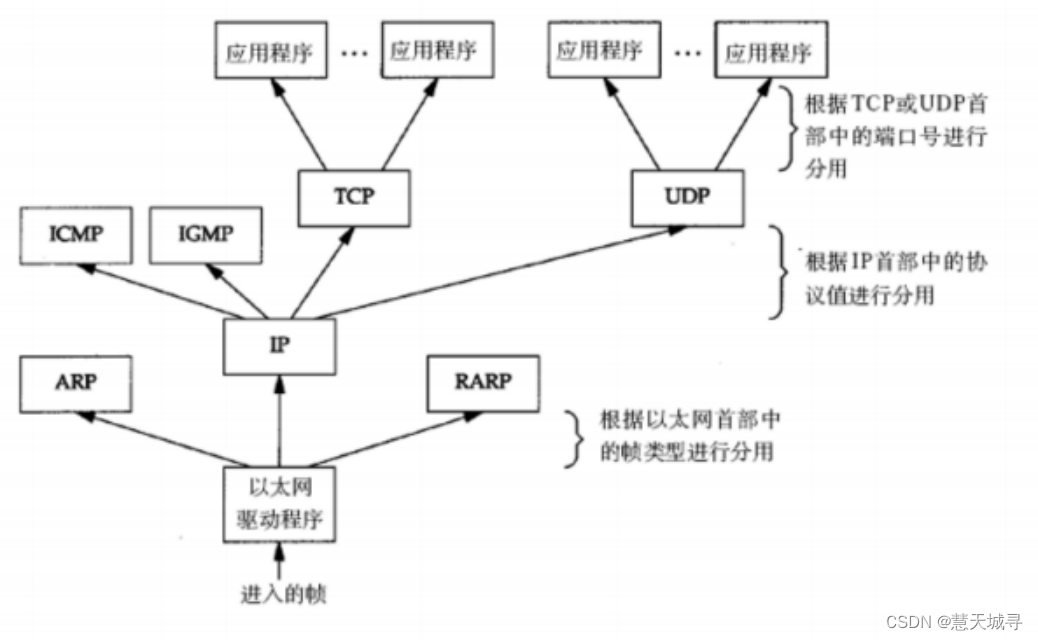
【计算机网络原理】初始网络基础
文章目录 1. 网络发展史1.1 单机时代1.2 网络互连局域网 LAN广域网 WAN 2. 网络通信基础2.1 IP 地址2.2 端口号2.3 协议2.4 五元组2.5 协议分层2.5.1 OSI七层模型2.5.2 TCP/IP五层模型 2.6 封装和分用2.6.1 数据封装(发送方情况)2.6.2 数据分用(接收方情况) 总结 1. 网络发展史…...
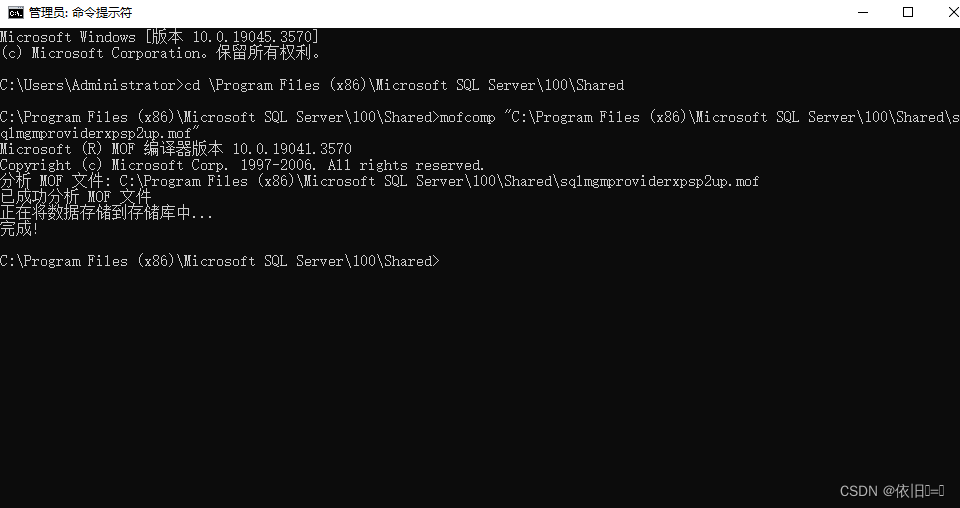
【sqlserver】配置管理器打不开
问题描述 无法连接到 WMI 提供程序。您没有权限或者该服务器无法访问。请注意,您只能使用SQL Server 配置管理器来管理 SQL Server 2005 和更高版本的服务 器。无效类[0x80041010] 解决方式: 命令提示符-右键-以管理员身份运行,再把以下代码执行一遍&…...
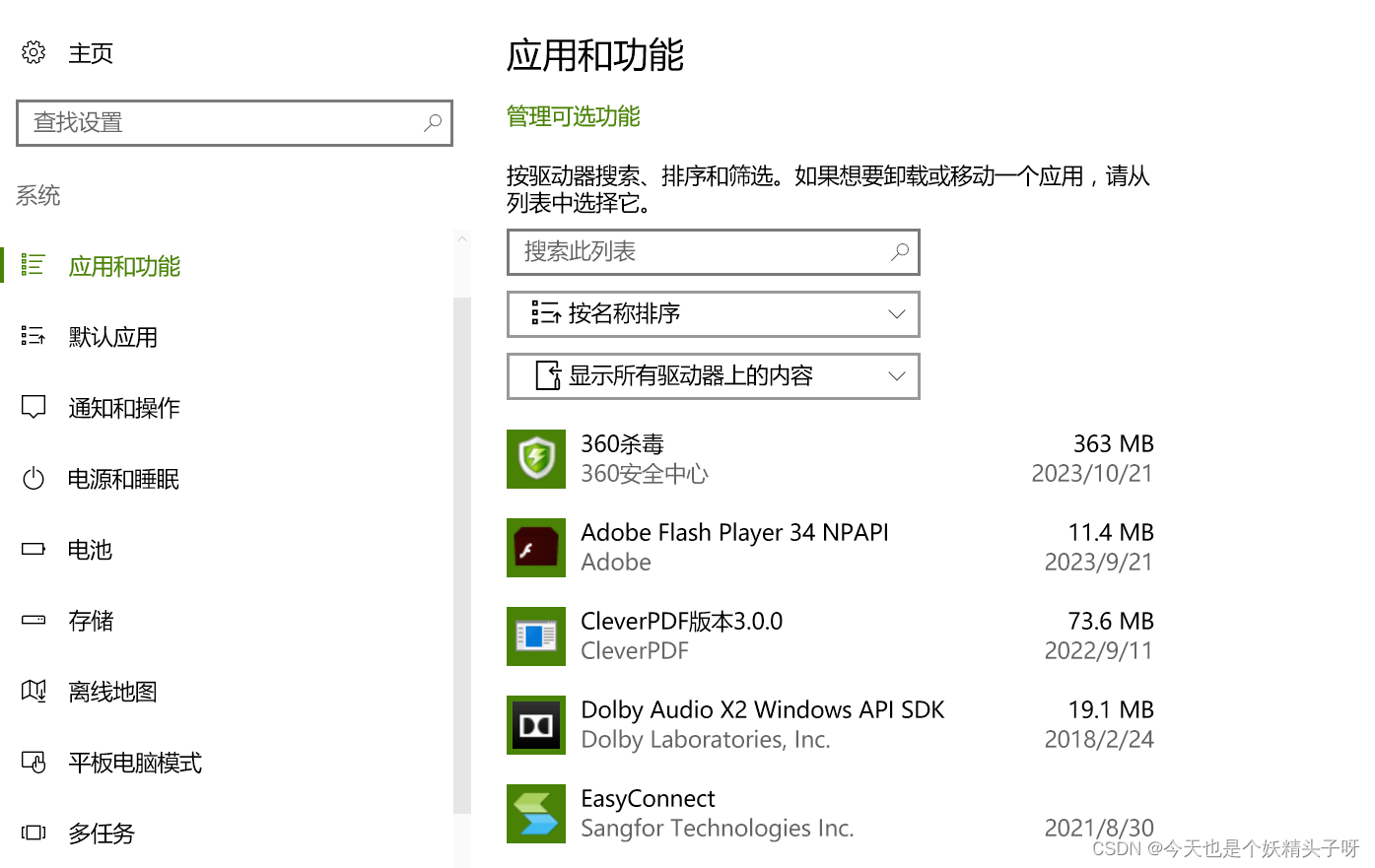
磁盘清理 | 已经卸载的软件还出现在应用和功能里怎么办?
一句话总结解决方法: 安装Geek Uninstaller,删除卸载残留。 问题描述: 最近磁盘满了,需要删除一些平时不常用的软件,但是发现一个问题。就是已经删除的软件,仍然会出现在“应用与功能”中。并且显示卸载图标为灰色&am…...
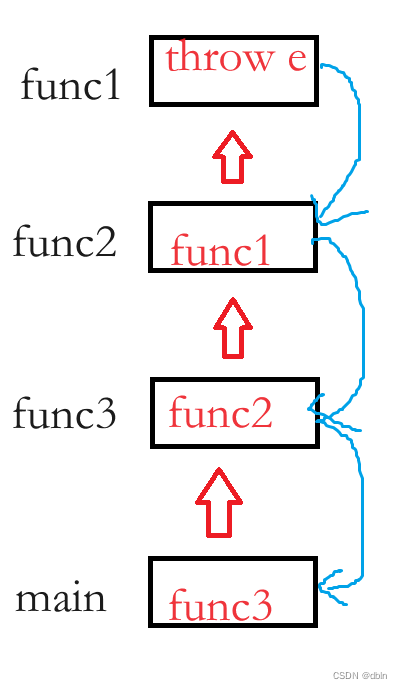
C++之异常
目录 一、C语言传统的处理错误的方式 二、C的异常 1、概念 2、关键字 3、基本格式 三、异常的抛出和捕获 1、异常的抛出和匹配原则 2、 在函数调用链中异常栈展开匹配原则 四、异常抛派生类,基类捕获 五、异常的重新抛出 六、异常安全 七、异常的优缺点…...
动态天气预报:Living Weather HD for Mac
Living Weather HD能够为Mac用户提供及时、准确、个性化的天气信息,并提供了丰富的定制选项,使用户能够更加方便地查看天气状况。 具有以下特点: 显示世界各地的准确天气预报和当地时间。自动探测出用户所在的首个地点,并通过搜…...

深度神经网络时与协方差矩阵
平时训练深度神经网络时,什么时候用到了协方差矩阵 在深度神经网络的平时训练过程中,一般情况下不直接使用协方差矩阵。然而,协方差矩阵的概念和相关性的考虑在某些情况下可以对网络的训练和优化起到一定的指导作用。 下面是一些与协方差矩…...
idea中java类属性(字段)链式赋值
很多人看到标题可能会想到 lombok 的 Builder,lombok 在国内用的挺多的,开源的组件中 mybatis-plus 中用到了这个,使用这个有一个问题就是通过对应 get 和 set 方法找不到对应的赋值方法,因为 lombok 使用了 apt 在编译期生成了相…...
)
vue通知(滚动)
1. li宽度不顾定 <template><div id"app"><div id"box" mouseover"clearLeft" mouseleave"setLeft"><ul :style"{ transform: translateX( left px) }" ref"cmdlist"><li v-for&qu…...

linux安装新版本git2、配置github-ssh。(centos、aws)
一、安装Git 1、yum默认版本git #1.安装git sudo yum install git -y #2.确认Git已经安装成功 git --version如果要安装较新版本,可以安装一个repo ,但是我这第一次尝试失败了,执行完提示找不到git2u,ius repo也连不上。而且每次…...

毅速丨3D打印结合拓扑优化 让轻量化制造更容易
制造轻量化对于提高能源利用效率、提高产品性能和减少环境影响,推动制造业的绿色化、高质量发展具有重要的促进作用。 轻量化设计对许多领域都有着重要影响,尤其是那些需要降低能源消耗、提高运输效率或减少对环境影响的领域。如航空航天,轻量…...
)
6252: 【C1】【分支】比较大小(一)
目录 题目描述 输入 输出 样例输入 样例输出 提示 来源 C代码: 题目描述 输入两个整数,输出较大数(两数相等输出任意一个) 输入 两行 第一行一个整数:m 第二行一个整数:n ( -30000 < m , n…...
网工实验手册:RSTP如何配置?
1. 实验目的 熟悉RSTP的应用场景掌握RSTP的配置方法 想要华为数通配套实验拓扑和配置笔记的朋友们点赞关注,评论区留下邮箱发给你! 2. 实验拓扑 实验拓扑如图所示: 图:RSTP的配置 3. 实验步骤 (1) …...
uniapp开发h5引入第三方js(sdk)
manifest.json 应用配置 | uni-app官网 根据文档上描述需要自定义模板的场景为: 方法一: 起初以为是在原有的index.html基础上再新建一个html文件,在项目根目录建立一个template.h5.html(仿照hello-uni-app项目)&…...

Could not find artifact com.sleepycat;je:jar:7.3.7 in aliyunmaven
在编译inlong源码时报的错误,去本地库里发现只有lastupdate的文件,就又去maven库里看了一下Maven Repository: com.sleepycat je (mvnrepository.com),发现没有这个版本,将版本进行修改错误解决...

rust学习—— 控制流if 表达式
控制流 根据条件是否为真来决定是否执行某些代码,或根据条件是否为真来重复运行一段代码,是大部分编程语言的基本组成部分。Rust 代码中最常见的用来控制执行流的结构是 if 表达式和循环。 if 表达式 if 表达式允许根据条件执行不同的代码分支。你提供…...

POSIX信号量
目录 信号量的原理 信号量函数 使用信号量实现线程互斥功能 基于环形队列的生产消费模型 生产者和消费者必须遵守的两个规则 信号量的原理 通过之前的学习,我们知道有的资源可能会被多个执行流同时申请访问,我们将这种资源叫做临界资源,…...

stable diffusion和midjourney哪个好
midjourney和stable diffusion哪个好?midjourney和stable diffusion的区别?那么今天就从这2款软件入手,来探索一下他们的功能的各项区别吧,让你选择更适合你的一款ai软件。 截至目前,我们目睹了生成式人工智能工具的在…...

固件签名的安全解决方案 安当加密
在汽车行业中,加密机常用于对固件进行签名,以增加固件的安全性和完整性。以下是几个可能的使用场景: 固件验证:当汽车制造商或供应商需要对固件进行验证时,可以使用加密机来验证固件的来源和完整性。通过使用公钥和私…...

题解:洛谷 P1914 小书童——凯撒密码
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大家订阅我的专栏:算法…...

5分钟掌握Windows和Office一键激活:KMS_VL_ALL_AIO智能激活工具终极指南
5分钟掌握Windows和Office一键激活:KMS_VL_ALL_AIO智能激活工具终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Off…...

AArch64系统指令集解析与性能优化实践
1. AArch64系统指令概述AArch64是ARMv8架构的64位执行状态,其系统指令集为操作系统和底层软件开发提供了丰富的硬件控制能力。作为ARM架构的重大革新,AArch64不仅扩展了寄存器位宽,更在内存管理、虚拟化支持和安全隔离等方面引入了全新机制。…...

TFCalc软件视频教程
1. TFCALC初级入门教程001-产品为什么要镀膜2. TFCALC初级入门教程002-设计膜系前准备3. TFCALC初级入门教程003-TFC菜单认识4. TFCALC初级入门教程004-软件基本操作15. TFCALC初级入门教程005-软件基本操作26. TFCALC初级入门教程006-软件基本操作37. TFCALC初级入门教程007-设…...

保姆级教程:人脸分析系统API调用全解析,小白也能玩转自动化
保姆级教程:人脸分析系统API调用全解析,小白也能玩转自动化 1. 为什么你需要学习API调用 当你第一次使用Face Analysis WebUI时,可能会被它直观的图形界面所吸引——上传图片、点击按钮、查看结果,一切都那么简单。但当你需要处…...

二叉树的遍历和线索二叉树--中序线索二叉树的遍历
一、遍历特点 1. 不需要递归 2. 不需要栈 3. 顺着线索指针,依次访问 4. 遍历顺序依然:左 → 根 → 右二、先回顾结点标记 - ltag 0:left 是左孩子 - ltag 1:left 是前驱线索- rtag 0:right 是右孩子 - rtag 1&…...

轻量的C++命令行交互器2.0
上次写了一个C命令行交互器(基于GNU g),简介看上一篇文章。这次主要增加一点新功能和修复bug。新功能:1.上下键回溯,回溯的内容仅限已经输入并使用回车提交的内容,可在普通模式、全模式、半编辑器模式&…...

幻境·流金多场景落地:支持教育课件配图、科研论文插图、展览海报
幻境流金多场景落地:支持教育课件配图、科研论文插图、展览海报 1. 引言:让专业视觉创作变得简单高效 在日常工作和学习中,我们经常需要制作各种视觉材料——老师需要为课件配图,研究人员需要为论文制作插图,策展人员…...

终极Degrees of Lewdity中文汉化配置指南:3步快速解决游戏语言障碍
终极Degrees of Lewdity中文汉化配置指南:3步快速解决游戏语言障碍 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Local…...

西门子S7-1500暖通空调冷水机组PLC程序案例, 硬件采用西门子1500CPU+ET200...
西门子S7-1500暖通空调冷水机组PLC程序案例, 硬件采用西门子1500CPUET200SP接口IO模块,HMI采用西门子触摸屏 程序采用SCL控制程序编程,系统水泵采用一用一备,通过程序实现了加减机控制,根据压差控制开启的水泵台数以及…...