【API篇】五、Flink分流合流API
文章目录
- 1、filter算子实现分流
- 2、分流:使用侧输出流
- 3、合流:union
- 4、合流:connect
- 5、connect案例
分流,很形象的一个词,就像一条大河,遇到岸边有分叉的,而形成了主流和测流。对于数据流也一样,不过是一个个水滴替换成了一条条数据。
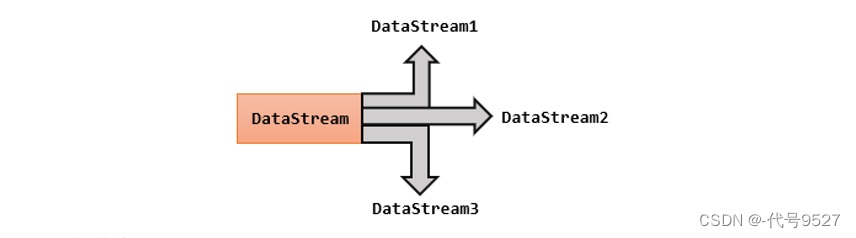
将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
1、filter算子实现分流
Demo案例:读取一个整数数字流,将数据流划分为奇数流和偶数流。
实现思路:针对同一个流,多次条用filter算子来拆分
public class SplitStreamByFilter {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();SingleOutputStreamOperator<Integer> ds = env.socketTextStream("node01", 9527).map(Integer::valueOf);//将ds 分为两个流 ,一个是奇数流,一个是偶数流//使用filter 过滤两次SingleOutputStreamOperator<Integer> ds1 = ds.filter(x -> x % 2 == 0);SingleOutputStreamOperator<Integer> ds2 = ds.filter(x -> x % 2 == 1);ds1.print("偶数");ds2.print("奇数");env.execute();}
}以上实现的明显缺陷是,同一条数据,被多次处理。以上其实是将原始数据流stream复制两份,然后对每一份分别做筛选,冗余且低效。
2、分流:使用侧输出流
基本步骤为:
- 使用process算子(Flink分层API中的最底层的处理函数)
- 定义OutputTag对象,即输出标签对象,用于后面标记和提取侧流
- 调用上下文ctx的.output()方法
- 通过主流获取侧流
案例:实现将WaterSensor按照Id类型进行分流
先定义下MapFunction的转换规则,用来将输入的数据转为自定义的WaterSensor对象:
public class WaterSensorMapFunction implements MapFunction<String,WaterSensor>{@Overridepublic WaterSensor map(String value) throws Exception {String[] strArr = value.split( regex: ",");//String组装对象return new WaterSensor(strArr[0],Long.value0f(strArr[1]),Integer.value0f(strArr[2]));}
}
使用侧流:
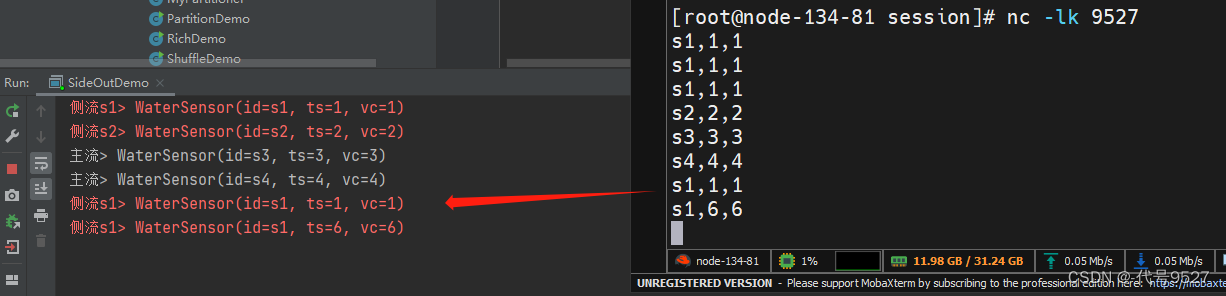
public class SplitStreamByOutputTag { public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();SingleOutputStreamOperator<WaterSensor> ds = env.socketTextStream("node01", 9527).map(new WaterSensorMapFunction());//定义两个输出标签对象,用于后面标记和提取侧流OutputTag<WaterSensor> s1 = new OutputTag<>("s1", Types.POJO(WaterSensor.class));OutputTag<WaterSensor> s2 = new OutputTag<>("s2", Types.POJO(WaterSensor.class));//返回的都是主流SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction<WaterSensor, WaterSensor>(){@Override//形参为别为:流中的一条数据、上下文对象、收集器public void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {if ("s1".equals(value.getId())) {ctx.output(s1, value);} else if ("s2".equals(value.getId())) {ctx.output(s2, value);} else {//主流out.collect(value);}}});ds1.print("主流");SideOutputDataStream<WaterSensor> s1DS = ds1.getSideOutput(s1);SideOutputDataStream<WaterSensor> s2DS = ds1.getSideOutput(s2);s1DS.printToErr("侧流s1"); //区别主流,让控制台输出标红s2DS.printToErr("侧流s2");env.execute();}
}相关传参说明,首先是创建OutputTag对象时的传参:
- 第一个参数为标签名,用于区分是哪一个侧流
- 第二个是放入侧流中的数据的类型,且必须是Flink的类型(TypeInfomation,借助Types类)
- OutputTag的泛型,是流到对应的侧流的数据类型
ProcessFunction接口的泛型中:
- 第一个是输入的数据类型
- 第二个是输出到主流上的数据类型
ctx.output方法的形参:
- 第一个为outputTag对象
- 第二个为数据,上面代码中传value即直接输出数据本身,也可输出处理后的数据,主流侧流数据类型不用一致
看下运行效果:
3、合流:union
将来源不同的多条流,合并成一条来联合处理,即合流。最简单的合流操作,就是直接将多条流合在一起,叫作流的联合(union)
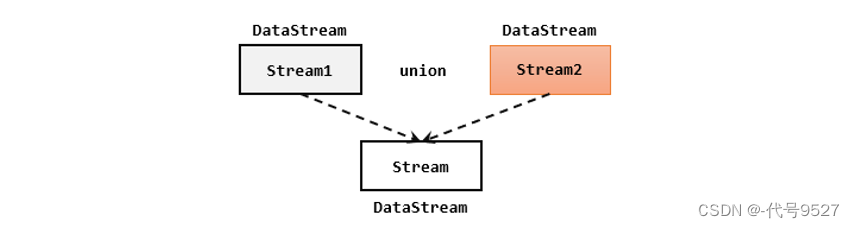
union的条件是:
- 每条流中要合并的数据类型必须相同(原始不同,可先借助map,在union)
- 合并之后的新流会包括所有流中的元素,数据类型不变
stream1.union(stream2, stream3, ...) //可变长参数
public class UnionExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Integer> ds1 = env.fromElements(1, 2, 3);DataStreamSource<Integer> ds2 = env.fromElements(2, 2, 3);DataStreamSource<String> ds3 = env.fromElements("2", "2", "3");ds1.union(ds2,ds3.map(Integer::valueOf)).print();env.execute();}
}
//输出:
1
2
3
2
2
3
2
2
3
4、合流:connect
union合并流受限于数据类型,因此还有另一种合流操作:connect
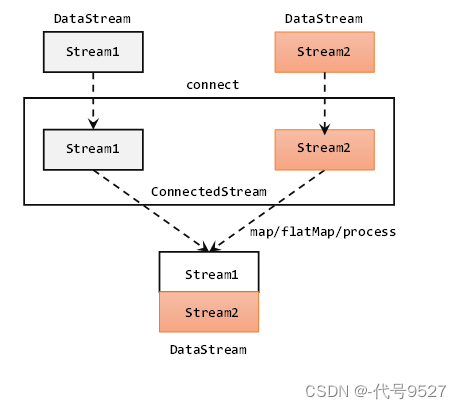
public class ConnectDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//Integer流SingleOutputStreamOperator<Integer> source1 = env.socketTextStream("node01", 9527).map(i -> Integer.parseInt(i));//String流DataStreamSource<String> source2 = env.socketTextStream("node01", 2795);/*** 总结: 使用 connect 合流* 1、一次只能连接 2条流* 2、流的数据类型可以不一样* 3、 连接后可以调用 map、flatmap、process来处理,但是各处理各的*/ConnectedStreams<Integer, String> connect = source1.connect(source2);SingleOutputStreamOperator<String> result = connect.map(new CoMapFunction<Integer, String, String>() {@Overridepublic String map1(Integer value) throws Exception {return "来源于原source1流:" + value.toString();}@Overridepublic String map2(String value) throws Exception {return "来源于原source2流:" + value;}});result.print();env.execute(); }
}使用 connect 合流的总结:
- 一次只能连接 2条流,因为connect返回的是一个ConnectedStreams对象,不再是DataStreamSource或其子类了
- 两条流中的数据类型可以不一样
- 连接后可以调用 map、flatmap、process来处理,但是各处理各的
以map为例,其形参是一个CoMapFuntion接口类型,泛型则分别是流1的数据类型、流2的数据类型、合并及处理后输出的数据类型。两个map方法可以看出,虽然两个流合并成一个了,但处理数据时还是各玩各的。
- .map1()就是对第一条流中数据的map操作
- .map2()则是针对第二条流
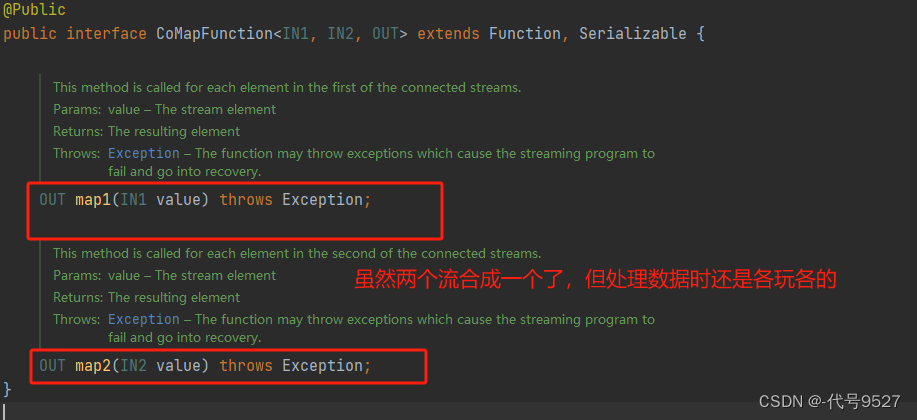
connect 就类比被逼相亲后结婚,两个人看似成一家了,但实际上各自玩各自的。往大了举例就相当于一国两制。
5、connect案例
和connect以后的map传CoMapFunction一样,process算子也不再传ProcessFunction,而是CoProcessFunction,实现两个方法:
- processElement1():针对第一条流
- processElement2():针对第二条流
connect合并后得到的ConnectedStreams也可以直接调用.keyBy()进行按键分区,分区后返回的还是一个ConnectedStreams
connectedStreams.keyBy(keySelector1, keySelector2);
//keySelector1和keySelector2,是两条流中各自的键选择器
ConnectedStreams进行keyBy操作,其实就是把两条流中key相同的数据放到了一起,然后针对来源的流再做各自处理
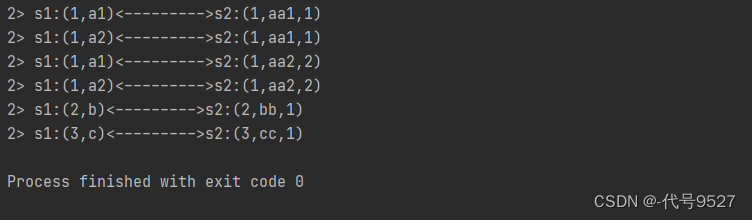
案例需求:连接两条流,输出能根据id匹配上的数据,即两个流里元组f0相同的数据(类似inner join效果)
public class ConnectKeybyDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);//二元组流DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(Tuple2.of(1, "a1"),Tuple2.of(1, "a2"),Tuple2.of(2, "b"),Tuple2.of(3, "c"));//三元组流DataStreamSource<Tuple3<Integer, String, Integer>> source2 = env.fromElements(Tuple3.of(1, "aa1", 1),Tuple3.of(1, "aa2", 2),Tuple3.of(2, "bb", 1),Tuple3.of(3, "cc", 1));ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2);// 多并行度下,需要根据 关联条件 进行keyby,才能保证key相同的数据到一起去,才能匹配上ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connectKey = connect.keyBy(s1 -> s1.f0, s2 -> s2.f0);SingleOutputStreamOperator<String> result = connectKey.process(new CoProcessFunction<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>, String>() {// 定义 HashMap,缓存来过的数据,key=id,value=list<数据>Map<Integer, List<Tuple2<Integer, String>>> s1Cache = new HashMap<>();Map<Integer, List<Tuple3<Integer, String, Integer>>> s2Cache = new HashMap<>();@Overridepublic void processElement1(Tuple2<Integer, String> value, Context ctx, Collector<String> out) throws Exception {Integer id = value.f0;// TODO 1.来过的s1数据,都存起来if (!s1Cache.containsKey(id)) {// 1.1 第一条数据,初始化 value的list,放入 hashmapList<Tuple2<Integer, String>> s1Values = new ArrayList<>();s1Values.add(value);s1Cache.put(id, s1Values);} else {// 1.2 不是第一条,直接添加到 list中s1Cache.get(id).add(value);}//TODO 2.根据id,查找s2的数据,只输出 匹配上 的数据if (s2Cache.containsKey(id)) {for (Tuple3<Integer, String, Integer> s2Element : s2Cache.get(id)) {out.collect("s1:" + value + "<--------->s2:" + s2Element);}}}@Overridepublic void processElement2(Tuple3<Integer, String, Integer> value, Context ctx, Collector<String> out) throws Exception {Integer id = value.f0;// TODO 1.来过的s2数据,都存起来if (!s2Cache.containsKey(id)) {// 1.1 第一条数据,初始化 value的list,放入 hashmapList<Tuple3<Integer, String, Integer>> s2Values = new ArrayList<>();s2Values.add(value);s2Cache.put(id, s2Values);} else {// 1.2 不是第一条,直接添加到 list中s2Cache.get(id).add(value);}//TODO 2.根据id,查找s1的数据,只输出 匹配上 的数据if (s1Cache.containsKey(id)) {for (Tuple2<Integer, String> s1Element : s1Cache.get(id)) {out.collect("s1:" + s1Element + "<--------->s2:" + value);}}}});result.print();env.execute();}
}运行效果:
相关文章:
【API篇】五、Flink分流合流API
文章目录 1、filter算子实现分流2、分流:使用侧输出流3、合流:union4、合流:connect5、connect案例 分流,很形象的一个词,就像一条大河,遇到岸边有分叉的,而形成了主流和测流。对于数据流也一样…...
flutter开发的一个小小小问题,内网依赖下不来
问题 由于众所周知的原因,flutter编译时,经常出现Could not get resource https://storage.googleapis.com/download.flutter.io…的问题,如下: * What went wrong: Could not determine the dependencies of task :app:lintVit…...
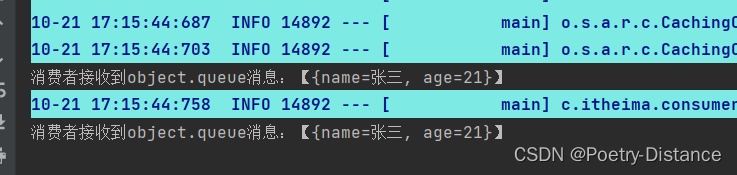
RabbitMQ队列及交换机的使用
目录 一、简单模型 1、首先控制台创建一个队列 2、父工程导入依赖 3、生产者配置文件 4、写测试类 5、消费者配置文件 6、消费者接收消息 二、WorkQueues模型 1、在控制台创建一个新的队列 2、生产者生产消息 3、创建两个消费者接收消息 4、能者多劳充分利用每一个消…...

分布式唯一Id,它比GUID好
分布式唯一Id,它比GUID好 一、前言 分布式唯一Id,顾名思义,是指在全世界任何一台计算机上都不会重复的唯一Id。 在单机/单服务器/单数据库的小型应用中,不需要用到这类东西。但在高并发、海量数据、大型分布式应用中,…...

计算机服务器中了勒索病毒怎么解决,勒索病毒解密流程,数据恢复
计算机服务器中了勒索病毒是一件非常令人头疼的事情,勒索病毒不仅会加密企业服务器中的数据,还会对企业计算机系统带来损害,严重地影响了企业的正常运转。最近,云天数据恢复中心工程师总结了,今年以来网络上流行的勒索…...

【NPM】vuex 数据持久化库 vuex-persistedstate
在 GitHub 上找到:vuex-persistedstate。 安装 npm install --save vuex-persistedstate使用 import { createStore } from "vuex"; import createPersistedState from "vuex-persistedstate";const store createStore({// ...plugins: [cr…...

英语——分享篇——每日200词——2601-2800
2601——resistant——[rɪzɪstənt]——adj.抵抗的——resistant——resi热死(拼音)st石头(拼音)ant蚂蚁(熟词)——热死了石头上的蚂蚁还在抵抗——The body may be less resistant if it is cold. ——天冷时,身体的抵抗力会下降。 2602——prospect——[prɒspe…...

SpringCloud-Sentinel
一、介绍 (1)提供界面配置配置服务限流、服务降级、服务熔断 (2)SentinelResource的blockHandler只处理后台配置的异常,运行时异常fallBack处理,且资源名为value时才生效,走兜底方法 二、安装…...
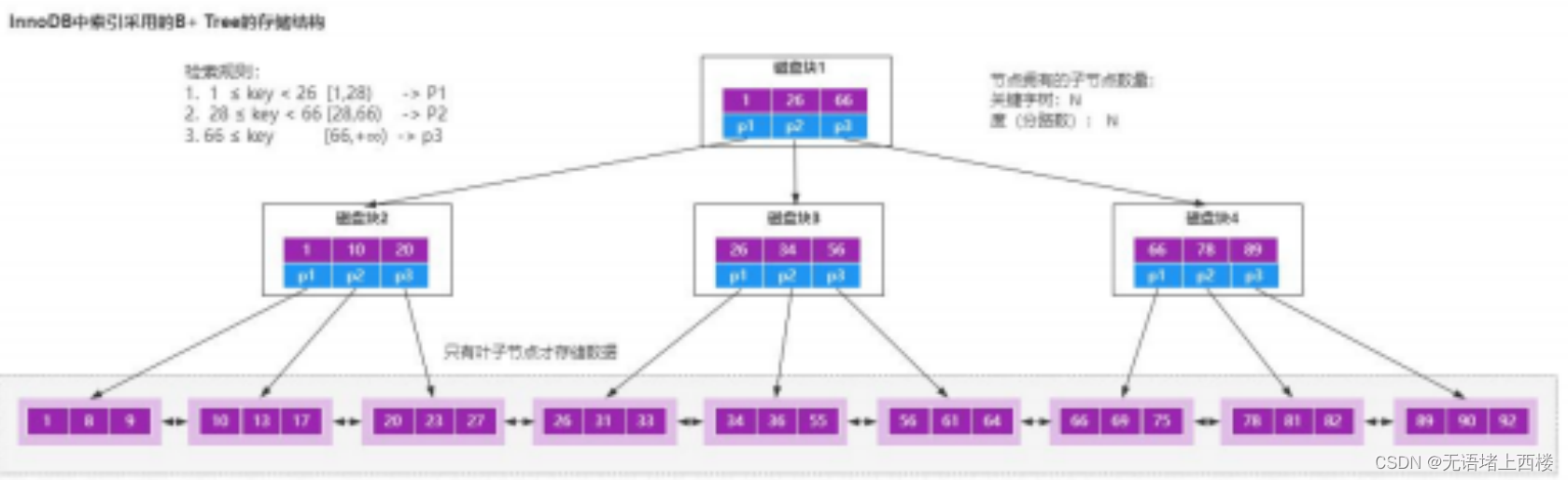
为什么索引要用B+树来实现呢,而不是B树
首先,常规的数据库存储引擎,一般都是采用 B 树或者 B树来实现索引的存储。 B树 因为 B 树是一种多路平衡树,用这种存储结构来存储大量数据,它的整个高度会相比二叉树来说,会矮很多。 而对于数据库来说,所有…...

使用vue3前端开发的一些知识点
Vue 3 是一种流行的 JavaScript 框架,用于构建用户界面。它是 Vue.js 框架的第三个主要版本,具有许多新特性和性能改进。下面是 Vue 3 的一些常用语法和概念的详细介绍: 创建 Vue 实例: 在 Vue 3 中,你可以通过创建一个…...
零基础Linux_20(进程信号)内核态和用户态+处理信号+不可重入函数+volatile
目录 1. 内核态和用户态 1.1 内核态和用户态概念 1.2 内核态和用户态转化 2. 处理信号 2.2 捕捉信号 2.2 系统调用sigaction 3. 不可重入函数 4. volatile关键字 5. SIGCHLD信号(了解) 6. 笔试选择题 答案及解析 本篇完。 1. 内核态和用户态…...

vite+vue3+elementPlus+less+router+pinia+axios
1.创建项目2.按需引入elementplus3.引入less安装vue-router安装 axios安装 piniapinia的持久化配置(用于把数据放在localStorage中)---另外增加的配置 1.创建项目 npm init vitelatest2.按需引入elementplus npm install element-plus --save//按需引入 npm install -D unpl…...
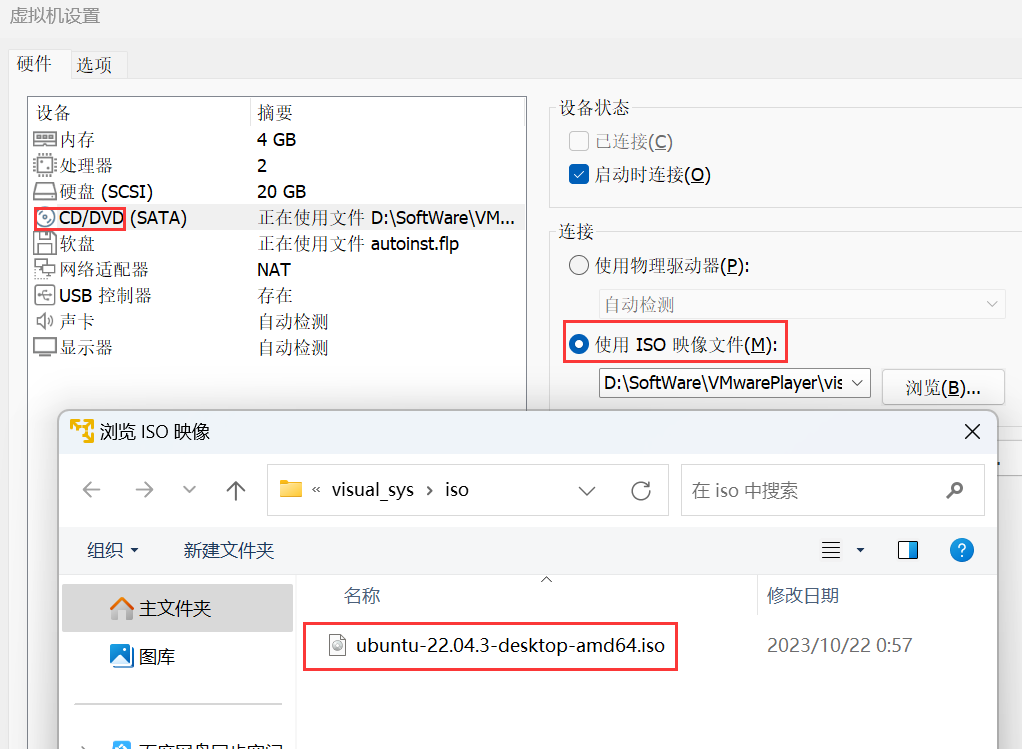
VMwarePlayer安装Ubuntu,切换中文并安装中文输入法
1.下载和安装 虚拟机使用的免费版官网链接:VMwarePlayer Ubuntu镜像下载官网链接:Ubuntu桌面版 自己学习使用,不需要考虑迁移之类的。选择单个磁盘IO性能会更高 安装过程中如果出现如下报错,则用系统管理员身份运行 右击VMwa…...

C# JSON转为实体类和List,以及结合使用
引用 using Newtonsoft.Json;using Newtonsoft.Json.Linq;JSON转实体类 public class Person {public string Name { get; set; }public int Age { get; set; }public string Gender { get; set; } }string jsonStr "{\"name\": \"Tom\", \"a…...
使用TensorRT-LLM进行高性能推理
LLM的火爆之后,英伟达(NVIDIA)也发布了其相关的推理加速引擎TensorRT-LLM。TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。而TensorRT-LLM是在TensorRT基础上针对大模型进一步…...
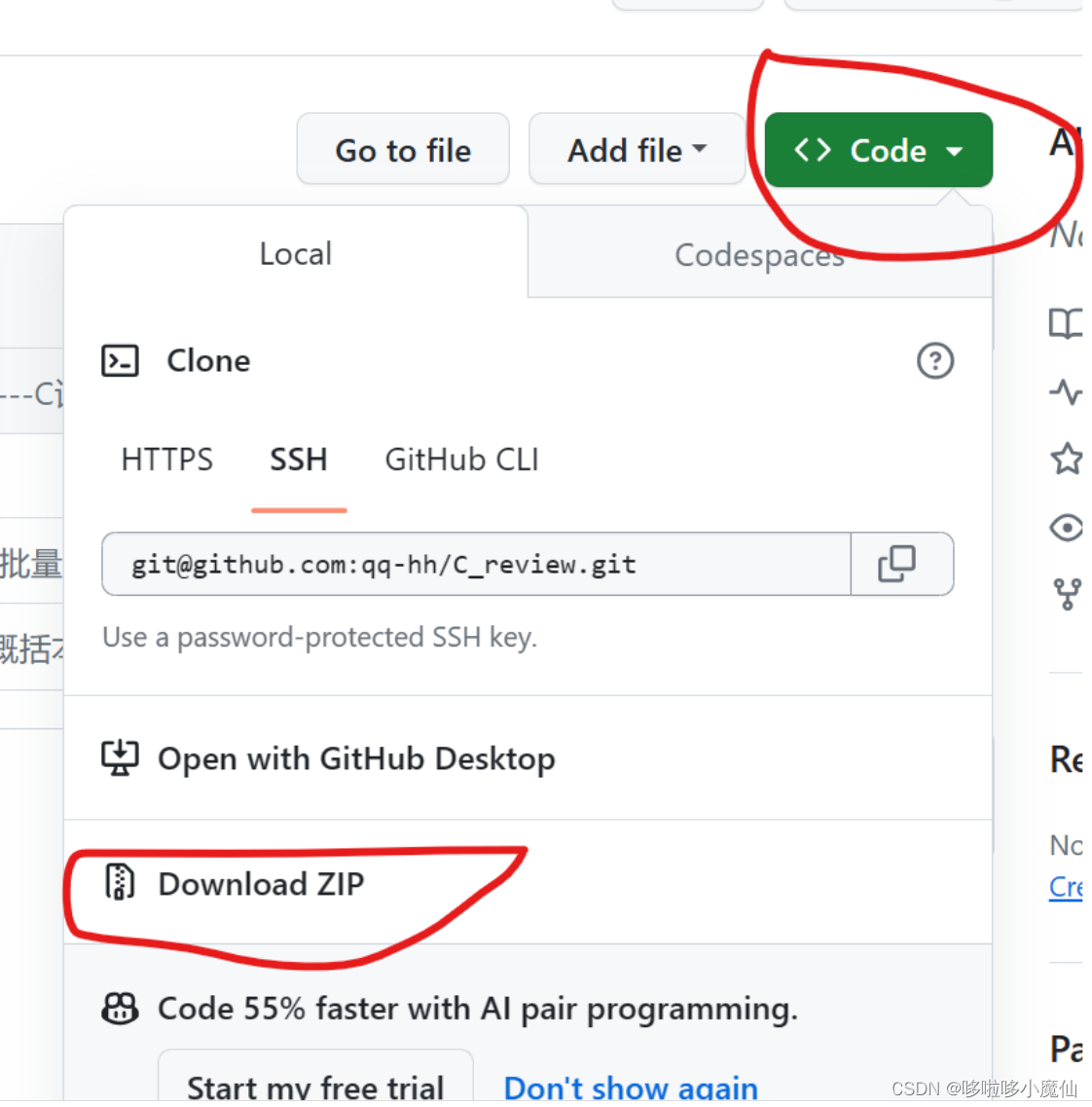
怎么去别人的github工程下载
1、网络 确保网络能够顺利访问github,有的地方的公共网络不能访问github,我之前开过科学上网的会员,发现没必要特意开去访问它。可以直接开手机热点,一般是可以顺利访问的。 2、下载 以我的github开源笔记qq-hh/C_review (gith…...

【java基础-实战3】list遍历时删除元素的方法
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 在实际的业务开发中,容器的遍历可以说是非…...

云计算与云服务
云计算与云服务 1、云计算与云服务概述2、云服务模式(IaaS、PaaS、SaaS、DaaS)3、公有云、私有云和混合云1、云计算与云服务概述 什么是云计算? “云”实质上就是一个网络,狭义上讲,云计算就是一种提供资源的网络,使用者可以随时获取“云”上的资源,按需求量使用,并且…...
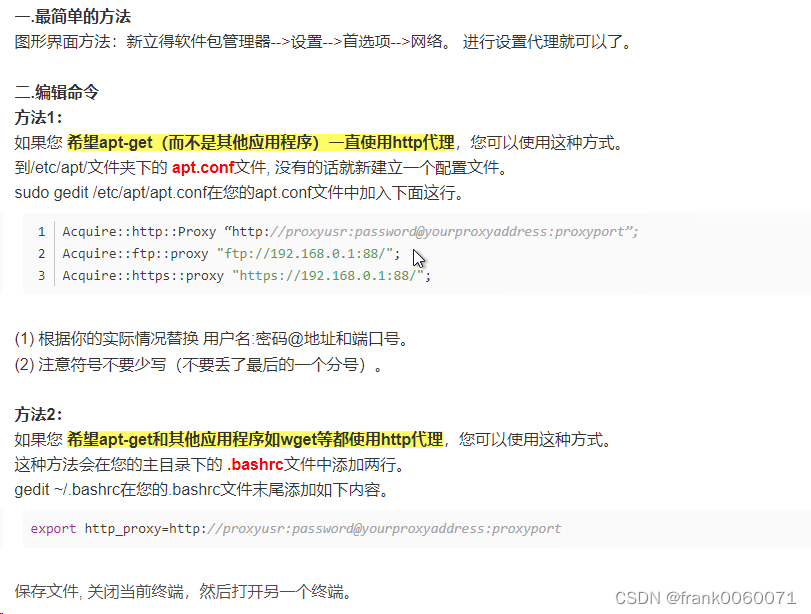
Ubuntu20.4 设置代理
主要是涉及2个代理 涉及apt 可以在、/etc/apt/apt.conf 中进行修改 在系统全局可以在/etc/profile中进行修改...

RustDay06------Exercise[71-80]
71.box的使用 说实话这题没太看懂.敲了个模板跟着提示就过了 // box1.rs // // At compile time, Rust needs to know how much space a type takes up. This // becomes problematic for recursive types, where a value can have as part of // itself another value of th…...

高薪诱惑!大厂AI实习生薪资暴涨6万,小白也能抓住未来机遇?速收藏!
大厂AI实习生薪资暴涨,顶尖学生月薪可达6万,是AI产业高速发展与人才短缺矛盾的结果。大厂争夺未来人才,实习生表现优异者几乎100%获高薪全职offer。高薪背后是供需失衡,大模型算法研发、AI Infra、AI应用研究等岗位最抢手。顶尖院…...

STAP旁瓣干扰抑制:从原理到对抗仿真的实战解析
1. STAP技术入门:空时滤波的降噪艺术 想象一下你在嘈杂的鸡尾酒会上试图听清某个人的谈话。传统方法就像用手捂住一只耳朵(空域滤波),而STAP技术则是同时用手捂住耳朵并配合对方说话的节奏点头(空时联合滤波࿰…...
)
FairyGUI遮罩与滚动视图实战:从UI组件溢出处理到流畅列表的实现(Unity 2022)
FairyGUI遮罩与滚动视图实战:从UI组件溢出处理到流畅列表的实现(Unity 2022) 在Unity游戏开发中,UI系统的灵活性和性能往往是决定用户体验的关键因素。FairyGUI作为一款强大的UI解决方案,其设计哲学和实现机制为开发者…...
)
从零搭建一个视频处理Demo:基于RKMEDIA的VENC/VDEC完整数据流(采集->编码->解码->显示)
从零搭建视频处理Demo:基于RKMEDIA的端到端数据流实战指南 当第一次接触瑞芯微平台的RKMEDIA框架时,很多开发者会被分散的模块和复杂的数据流搞得晕头转向。本文将带你从零开始,构建一个完整的"摄像头采集→编码存储→解码播放"视频…...

**发散创新:基于角色与策略的动态权限控制系统设计与实现**在现代企业级应用中,权限
发散创新:基于角色与策略的动态权限控制系统设计与实现 在现代企业级应用中,权限管理已不再是简单的“用户-角色-资源”映射,而是需要支持细粒度控制、运行时动态调整、多维度策略组合的复杂系统。本文将深入探讨一种融合 RBAC(基…...
编写与调试的5个常见错误)
避坑指南:辰华CHI软件宏命令(Macro Command)编写与调试的5个常见错误
辰华CHI宏命令实战避坑手册:5个高频错误解析与调试技巧 在电化学测试领域,辰华CHI软件的宏命令功能一直是科研人员的得力助手,但就像任何强大的工具一样,它也可能成为效率黑洞——当你在凌晨三点的实验室里,面对满屏红…...

Video Station for DSM 7.2.2:解决群晖新版系统视频管理兼容性问题的完整方案
Video Station for DSM 7.2.2:解决群晖新版系统视频管理兼容性问题的完整方案 【免费下载链接】Video_Station_for_DSM_722 Script to install Video Station in DSM 7.2.2 and DSM 7.3 项目地址: https://gitcode.com/gh_mirrors/vi/Video_Station_for_DSM_722 …...

技术深度解析:OneNote-MD-Exporter 架构设计与无损迁移实战
技术深度解析:OneNote-MD-Exporter 架构设计与无损迁移实战 【免费下载链接】onenote-md-exporter ConsoleApp to export OneNote notebooks to Markdown formats 项目地址: https://gitcode.com/gh_mirrors/on/onenote-md-exporter 在数字化笔记管理领域&am…...

告别复杂建模!3D Face HRN人脸重建模型一键部署与使用全攻略
告别复杂建模!3D Face HRN人脸重建模型一键部署与使用全攻略 1. 从照片到3D模型:这个AI能做什么? 想象一下这样的场景:你手头只有一张普通的证件照,但需要在3D软件中快速创建一个逼真的人脸模型。传统方法可能需要数…...

告别MCU直连U盘的烦恼:用CH376模块为你的Arduino/ESP32项目轻松扩展USB存储
告别MCU直连U盘的烦恼:用CH376模块为你的Arduino/ESP32项目轻松扩展USB存储 你是否遇到过这样的场景:精心设计的Arduino环境监测站运行了一周,采集了上千组温湿度数据,却因为缺乏本地存储功能而被迫丢弃?或是ESP32摄像…...