pensieve运行的经验
1运行run_videopy时出现如下问题:
cmd: Union[List[str], str], ^ SyntaxError: invalid syntax
原因是EasyProcess版本与python版本不对应,解决办法可见之前这篇博客:SyntaxError: invalid syntax。
2解决完上述问题后,输入命令 python run_video.py RL 2 0结果又出现了新的错误:

出错的原因在chromedriver上,解决办法可见之前这篇博客:Message: ‘chromedriver‘ executable may have wrong permissions.
3之后再运行,如果出现这样的错误:
Message: unknown error: net::ERR_CONNECTION_REFUSED(Session info: chrome=xxx.xxx.xxx.xxx)
解决办法,一是看run_video.py文件中的url设置情况,根据项目中其他文件中的代码设置,一般设置url = 'http://localhost:8333/' + 'myindex_' + abr_algo + '.html'。
若没有上述问题,二是要注意RL方法中使用的模型是否在对应的路径中。
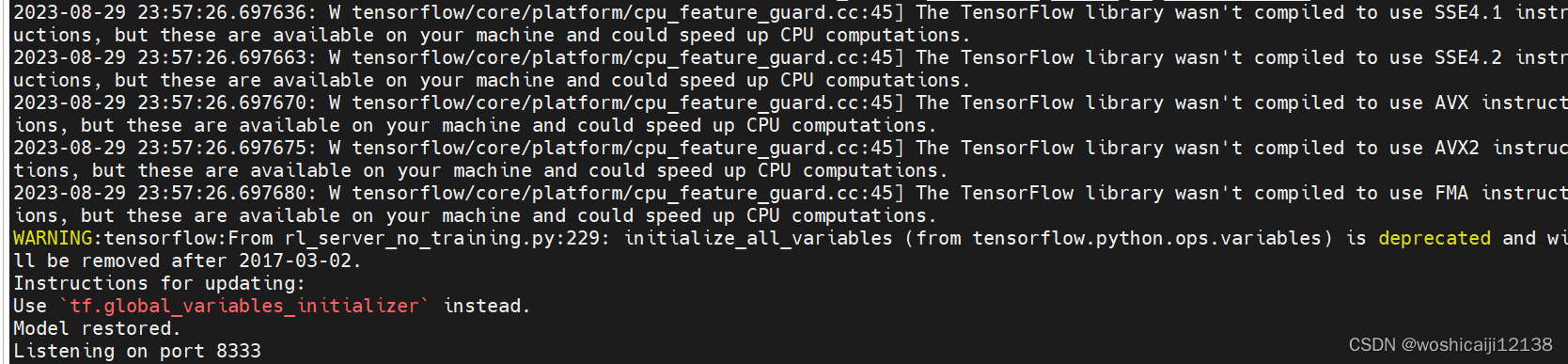
可以单独运行python rl_server_no_training.py 0进行实验,结果发现以下报错:

检查存储模型的目录…/rl_server/results/,发现少了pretrain_linear_reward.ckpt.index文件,立即去github上重新下载一个。
然后再运行 python rl_server_no_training.py 0,结果如下,解决。
4是按照项目Real-world experiments中的说明运行后,发现无法得出结果。
项目内说明:
To run real-world experiments, first setup a server (setup.py automatically installs an apache server and put needed files in /var/www/html). Then, copy over the trained model to rl_server/results and modify the NN_MODEL filed of rl_server/rl_server_no_training.py. Next, modify the url field in real_exp/run_video.py to the server url. Finally, in real_exp/ run
python run_exp.py
The results will be saved to real_exp/results folder. More details can be found in real_exp/README.md.
5 本地测试pensieve代码中rl_server_no_training.py的交互功能
当我在postman中设置好Body

并输入post的内容:‘{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}’。不过post后postman出现错误:
Error: socket hang up
服务器出现报错:
File "E:\anaconda\envs\pensieve\lib\json\decoder.py", line 382, in raw_decoderaise ValueError("No JSON object could be decoded")
ValueError: No JSON object could be decoded
Postman 错误 “Error: socket hang up”:
这个错误通常是因为服务器在处理请求时遇到了问题并关闭了连接,可能是由于代码中的异常引起的。
服务器端错误 “ValueError: No JSON object could be decoded”:
这个错误是因为服务器尝试解析POST请求中的JSON数据时失败了。POST请求中包含JSON数据,但在服务器端尝试解析它时出现问题。第二个问题似乎是导致第一个问题的原因。
遇到这种情况首先检查Postman中的请求头,确保 Content-Type 设置为 “application/json”,以指示服务器接收JSON数据。此外还要注意postman中传输数据的格式,我传输内容设置为’{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}',这是导致错误的原因。应该直接以字典传书就可以:{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}。
Send之后:
问题解决。
当然以上post内容设置适用于postman软件,如果是在python中发送post内容,则要注意了:
import requests
url = 'http://x.x.x.x:x'
# data = {"x":1,"xx":1,"xxx":1,"xxxx":1,"xxxxx":1,"xxxxxx":1} 错误
data = '{"x":1,"xx":1,"xxx":1,"xxxx":1,"xxxxx":1,"xxxxxx":1}'
response = requests.post(url, data=data)
if response.status_code == 200:print('Request successful')print('Response content:', response.text)
else:print('Request failed with status code:', response.status_code)此时data不能为字典,需是字符串,否则服务器也会出现错误:
raise ValueError("No JSON object could be decoded")
ValueError: No JSON object could be decoded
发送端代码会出现错误:
requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",))
正确的反馈:

6 向pensieve代码中rl_server_no_training.py发送post
利用python向后台运行中的rl_server_no_training.py发送post,出现报错:
Traceback (most recent call last):File "test.py", line 4, in <module>response = requests.post(url, data=data)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/api.py", line 117, in postreturn request('post', url, data=data, json=json, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/api.py", line 61, in requestreturn session.request(method=method, url=url, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/sessions.py", line 529, in requestresp = self.send(prep, **send_kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/sessions.py", line 645, in sendr = adapter.send(request, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/adapters.py", line 501, in sendraise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",))这个问题好办,我们检查rl_server_no_training.py那边的情况:
Traceback (most recent call last):File "rl_server_no_training.py", line 298, in <module>main()File "rl_server_no_training.py", line 293, in mainrun()File "rl_server_no_training.py", line 279, in runhttpd = server_class(server_address, handler_class)File "/home/xxx/lib/python2.7/SocketServer.py", line 417, in __init__self.server_bind()File "/home/xxx/envs/pensieve/lib/python2.7/BaseHTTPServer.py", line 108, in server_bindSocketServer.TCPServer.server_bind(self)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/SocketServer.py", line 431, in server_bindself.socket.bind(self.server_address)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/socket.py", line 228, in methreturn getattr(self._sock,name)(*args)
socket.error: [Errno 98] Address already in use地址被占用,rl_server_no_training.py压根没运行成功。
这里利用sudo lsof -i :端口号显示使用系统上端口的进程及其相关网络连接的列表;然后利用kill -9 进程号关闭即可。
7 在代码中增加log记录
为了以后方便在服务器代码运行中检测到错误与问题,决定在服务器代码中加入log记录。
以rl_server_no_training.py为例,首先:
import logging
logging.basicConfig(filename='nohup.out', level=logging.DEBUG)
logger = logging.getLogger('server')
def make_request_handler(input_dict):class Request_Handler(BaseHTTPRequestHandler):def __init__(self, *args, **kwargs):self.input_dict = input_dictself.sess = input_dict['sess']self.log_file = input_dict['log_file']self.actor = input_dict['actor']self.critic = input_dict['critic']self.saver = input_dict['saver']self.s_batch = input_dict['s_batch']self.a_batch = input_dict['a_batch']self.r_batch = input_dict['r_batch']BaseHTTPRequestHandler.__init__(self, *args, **kwargs)def do_POST(self):logger.info('Received a POST request')# 省略logger.debug('Received POST data: %s', post_data)
我开始在run中添加log:(错误做法)
def make_request_handler(input_dict):class Request_Handler(BaseHTTPRequestHandler):def __init__(self, *args, **kwargs):self.input_dict = input_dictself.sess = input_dict['sess']self.log_file = input_dict['log_file']self.actor = input_dict['actor']self.critic = input_dict['critic']self.saver = input_dict['saver']self.s_batch = input_dict['s_batch']self.a_batch = input_dict['a_batch']self.r_batch = input_dict['r_batch']BaseHTTPRequestHandler.__init__(self, *args, **kwargs)def do_POST(self):logger.info('Received a POST request')def run(server_class=HTTPServer, port=8334, log_file_path=LOG_FILE):np.random.seed(RANDOM_SEED)logging.basicConfig(filename='nohup.out', level=logging.DEBUG)logger = logging.getLogger('server')# 省略handler_class = make_request_handler(input_dict=input_dict)但是报错:
File "rl_server_no_training.py", line 75, in do_POSTlogger.info('Received a POST request')
NameError: global name 'logger' is not defined
要使记录器变量在两个函数中都可访问,您可以在更高的范围内定义它,如在模块级别。
请确保将此代码放在脚本的开头,放在使用记录器变量的任何函数或类之前。
修改之后,成功显示记录!

8 浏览器向服务器发送POST请求中因CORS(跨域资源共享)问题导致的net::ERR_FAILED错误
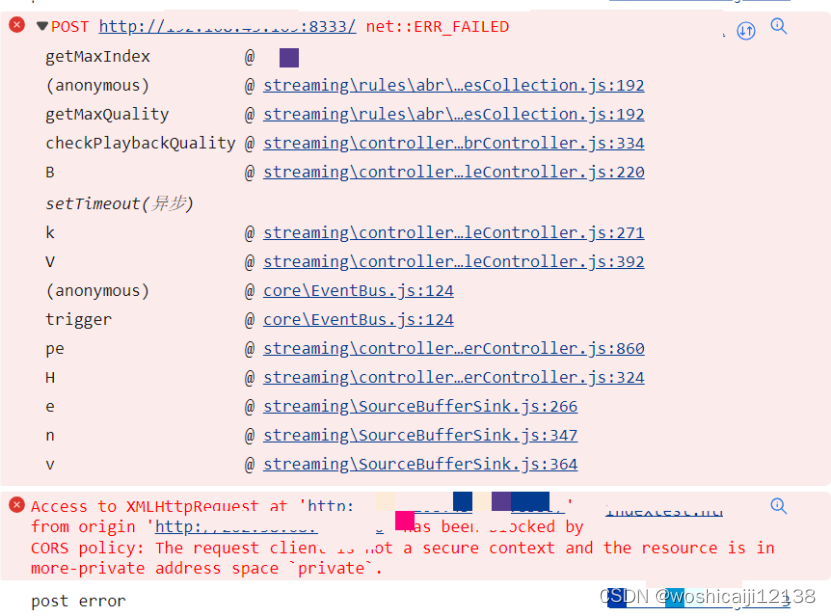
如上图所示,使用浏览器向服务器发送POST请求时出现net::ERR_FAILED错误,经排查是因CORS(跨域资源共享)问题导致。
检查js代码,发现httpRequest.setRequestHeader("Content-type","application/json"),而CORS中的简单请求(Simple Request)要求头只能是text/plain、multipart/form-data、application/x-www-form-urlencoded。
所以我们需要将Content-type设置为application/x-www-form-urlencoded。
原来的代码许多也需要修改,下面是一个示例:
Content-type为application/json时的版本:
const url='http://xxx.xxx.xxx.xxx:8333/';var dict={'RebufferTime':rebuffertime,'lastquality':lastQuality,'lastChunkFinishTime':lastChunkFinishTime,'lastChunkStartTime':lastChunkStartTime,'lastChunkSize':lastChunkSize};console.log(dict)var encodedData = encodeFormData(dict);console.log(encodedData)var httpRequest = new XMLHttpRequest();httpRequest.open('POST',url,true);httpRequest.setRequestHeader("Content-type","application/x-www-form-urlencoded");// httpRequest.setRequestHeader("Content-type","application/json");httpRequest.send(JSON.stringify(encodedData));
Content-type为application/x-www-form-urlencoded时的版本:
function encodeFormData(data) {const formData = new URLSearchParams();for (const key in data) {formData.append(key, data[key]);}return formData.toString();}const url='http://xxx.xxx.xxx.xxx:8333/';var dict={'RebufferTime':rebuffertime,'lastquality':lastQuality,'lastChunkFinishTime':lastChunkFinishTime,'lastChunkStartTime':lastChunkStartTime,'lastChunkSize':lastChunkSize};console.log(dict)var encodedData = encodeFormData(dict);console.log(encodedData)var httpRequest = new XMLHttpRequest();httpRequest.open('POST',url,true);httpRequest.setRequestHeader("Content-type","application/x-www-form-urlencoded");// httpRequest.setRequestHeader("Content-type","application/json");//httpRequest.send(JSON.stringify(encodedData));httpRequest.send(encodedData.toString());
服务器接收端的代码也需要修改,如下是可以正常运行的版本:
content_length = int(self.headers['Content-Length'])
postdata=self.rfile.read(content_length)
parsed_data = parse_qs(postdata)
# 将列表中的字符串转换为浮点数或整数
for key, value_list in parsed_data.items():if key == 'RebufferTime' or key == 'lastChunkFinishTime' or key == 'lastChunkStartTime':parsed_data[key] = float(value_list[0])else:parsed_data[key] = int(value_list[0])
因为接收到的postdata是字符串,例如:“RebufferTime=0.014999866485595703&lastquality=1&lastChunkFinishTime=1696524371.103&lastChunkStartTime=1696524371.088&lastChunkSize=66752”
9 parsed_data = parse_qs(postdata)可能遇到的错误:SyntaxError
parsed_data = parse_qs(postdata)是使用urlparse解析数据字符串,使之转换成字典。
运行parsed_data = parse_qs(postdata)时也有可能出现报错:SyntaxError: Non-ASCII character '\xe7' in file D:/xxx ��Ŀdebug/test3.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
这个错误表明Python脚本文件中包含了非ASCII字符,但是没有指定文件的编码方式。在Python 2.7中,默认的源文件编码是ASCII,如果文件中包含非ASCII字符,就需要在文件的开头声明文件编码。
要解决这个问题,可以在脚本文件的开头添加编码声明,以指定文件的编码方式。例如,如果文件使用UTF-8编码,可以这样声明:
# -*- coding: utf-8 -*-
from urlparse import urlparse, parse_qs
# 示例数据字符串
data_string = "RebufferTime=0.014999866485595703&lastquality=1&lastChunkFinishTime=1696524371.103&lastChunkStartTime=1696524371.088&lastChunkSize=66752"
# 使用urlparse解析数据字符串
parsed_data = parse_qs(data_string)
# 输出转换后的字典
print(parsed_data)10 开启rl_server_no_training.py服务器时的socket.error: [Errno 10049]错误
今天在pycharm运行rl_server_no_training.py欲启动服务器时,却出现如下错误
Traceback (most recent call last):File "xxx/rl_server_no_training.py", line 333, in <module>main()File "xxx/rl_server_no_training.py", line 326, in mainrun(log_file_path=LOG_FILE + '_RL_' + trace_file)File "xxx/rl_server_no_training.py", line 314, in runhttpd = server_class(server_address, handler_class)File "xx\anaconda\envs\pensieve\lib\SocketServer.py", line 420, in __init__self.server_bind()File "xx\anaconda\envs\pensieve\lib\BaseHTTPServer.py", line 108, in server_bindSocketServer.TCPServer.server_bind(self)File "xx\anaconda\envs\pensieve\lib\SocketServer.py", line 434, in server_bindself.socket.bind(self.server_address)File "xx\anaconda\envs\pensieve\lib\socket.py", line 228, in methreturn getattr(self._sock,name)(*args)
socket.error: [Errno 10049] Process finished with exit code 1解决办法可见:socket.error: [Errno 10049]错误解决。
相关文章:
pensieve运行的经验
1运行run_videopy时出现如下问题: cmd: Union[List[str], str], ^ SyntaxError: invalid syntax原因是EasyProcess版本与python版本不对应,解决办法可见之前这篇博客:SyntaxError: invalid syntax。 2解决完上述问题后,输…...
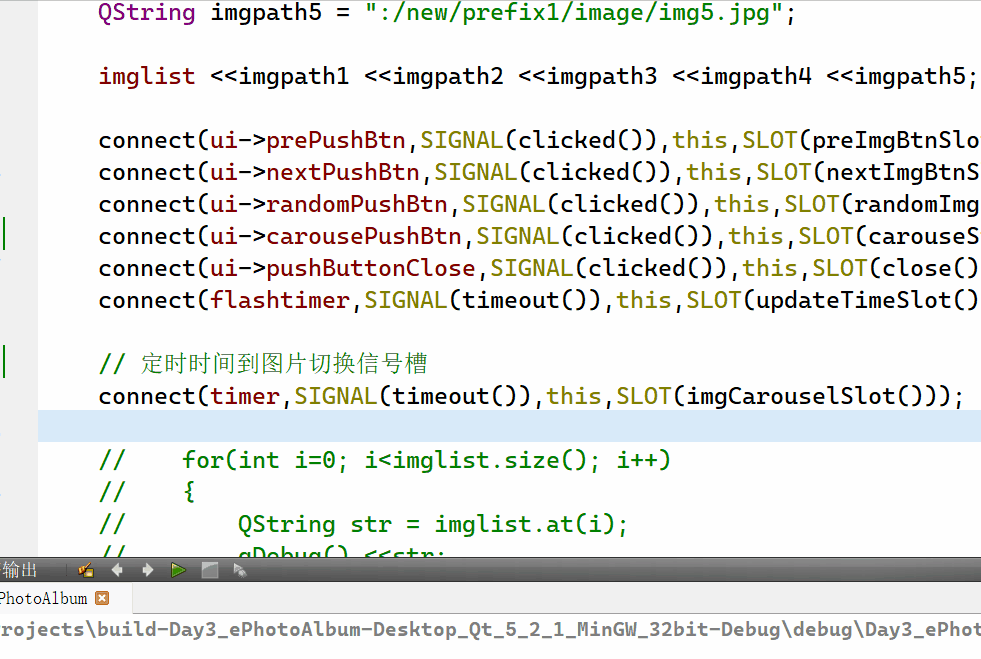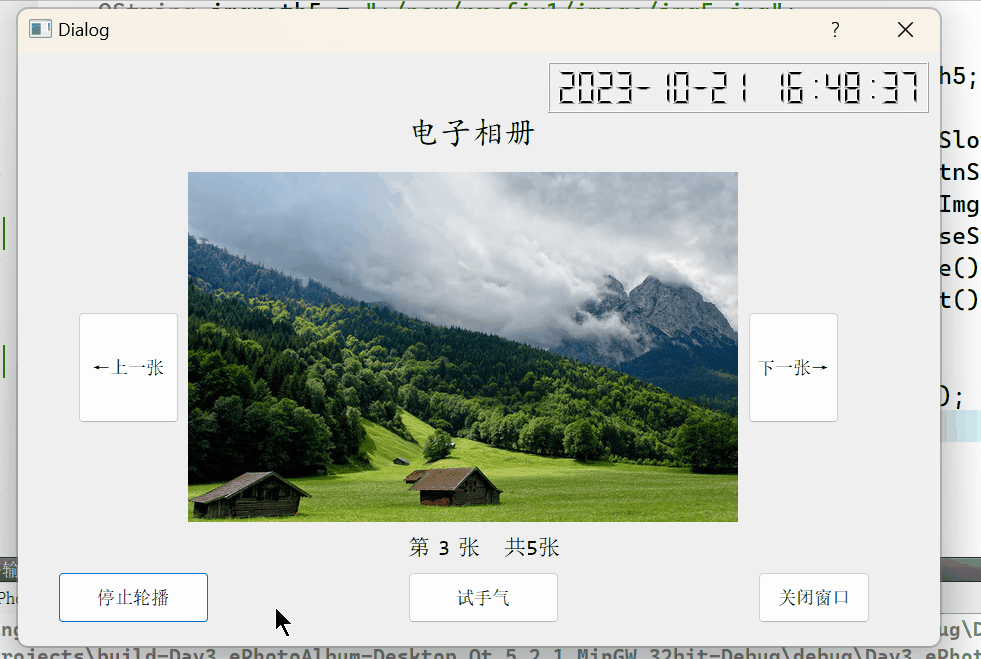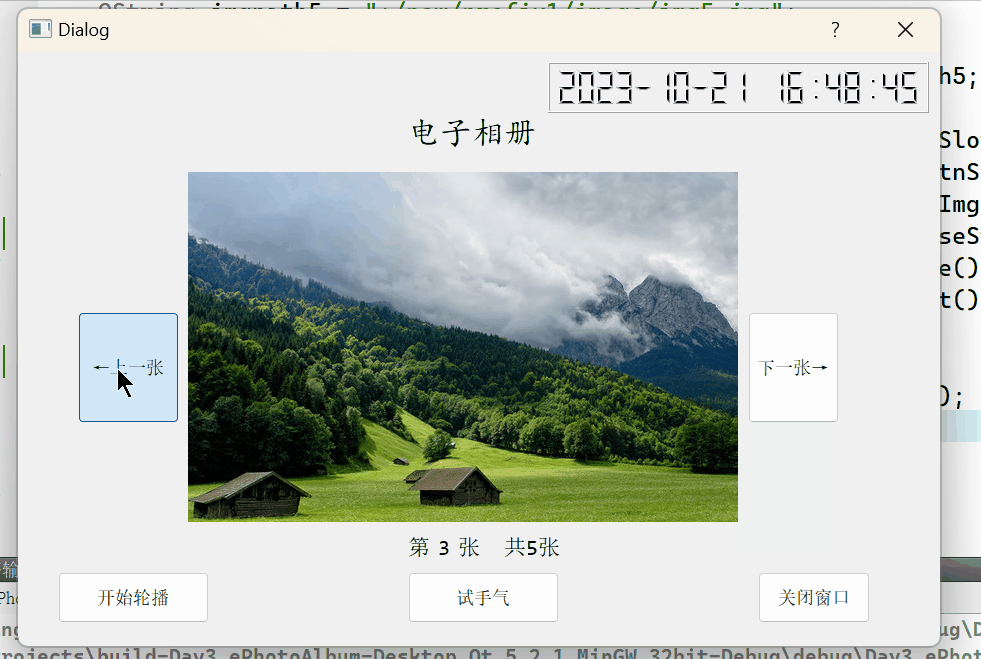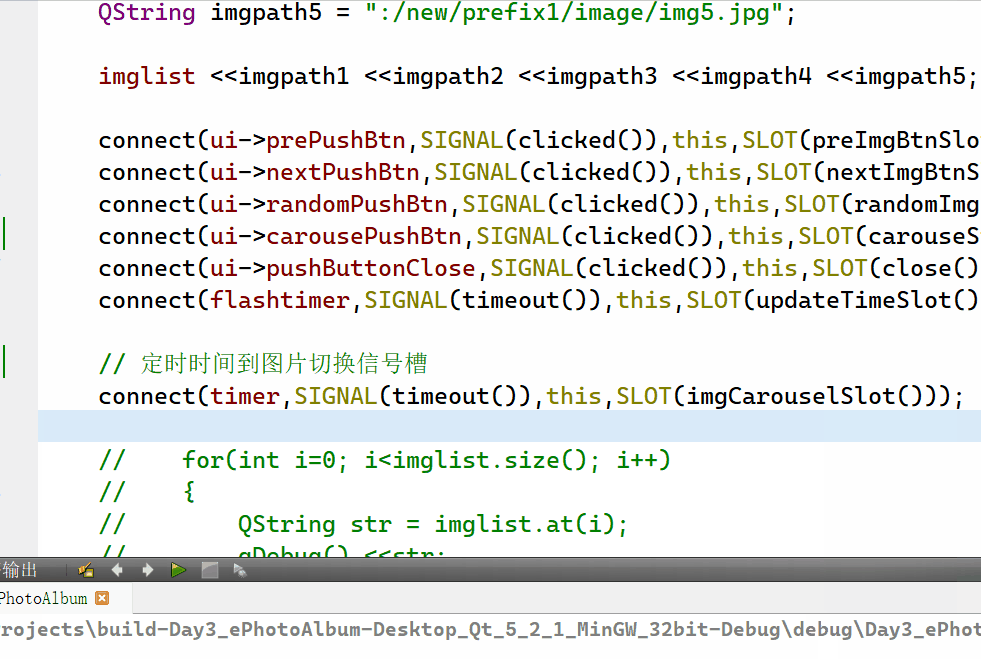
Qt实现一个电子相册
一、要实现的功能 在窗口中可以显示图片,并且能够通过两个按钮进行图片的前进和后退的顺序切换。有一个按钮,通过这个按钮可以从所存图片资源中随机选取一个图片进行展示通过按钮可以控制图片自动轮播顺序切换的开始与停止,显示当前系统的时…...

R语言:因子分析 factor analysis
文章目录 因子分析数据集处理步骤主成分法做因子分析最大似然法做因子分析因子分析 因子分析的用途与主成分分析类似,它也是一种降维方法。由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功,从而有更广泛的应用。 从方法上来说,因子分析比主成分分析更为…...
SOFAStack软件供应链安全产品解析——SCA软件成分分析
近年来,软件供应链安全相关攻击事件呈快速增长态势,造成的危害也越来越严重,为了保障软件供应链安全,各行业主管单位也出台了诸多政策及技术标准。基于内部多年的实践,蚂蚁数科金融级云原生PaaS平台SOFAStack发布完整的…...

vue中ElementUi的el-table表格绑定行点击事件
<el-table v-loading"loading" :data"messagesList" row-click"goToMassage">handleRowClick(row, event, column) {// 在这里处理行点击事件console.log(行点击事件:, row, event, column);}...
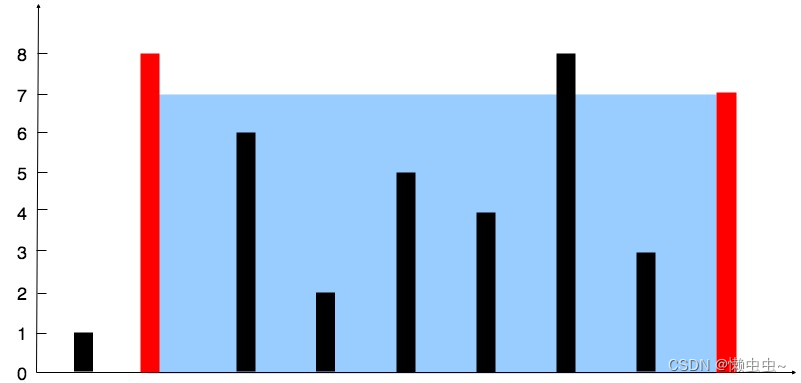
力扣:盛最多水的容器
题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容器。 …...

3D双目跟踪瞳孔识别
人眼数据集通常用于眼部相关的计算机视觉、眼动追踪、瞳孔检测、情感识别以及生物特征识别等领域的研究和开发。以下是一些常见的人眼数据集: BioID Face Database: 这个数据库包含1,521张近距离的人脸图像,其中包括瞳孔位置的标记。它通常用于瞳孔检测和…...

【java】Java项目从开发到部署生产完整流程梳理
文章目录 前言一、开发环境二、项目搭建2.1 Maven创建项目2.1.1 创建maven项目2.1.2 引入依赖2.1.3 maven常用命令 三、SpringBoot基础配置四、项目打包4.1 打包jar4.2 打包war4.2.1 修改项目打包为war包4.2.2 排除内嵌的tomcat,引入外部tomcat4.2.3 添加servlet-ap…...
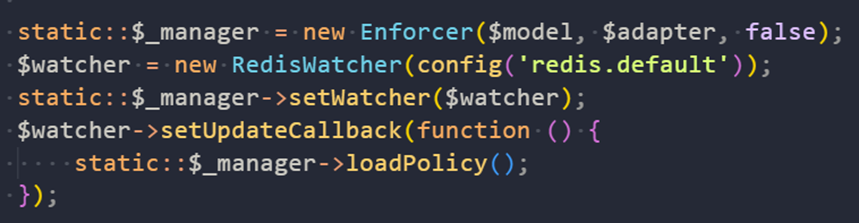
Casbin实战经验大揭秘:教育培训领域的创新实践和高效优化策略
策略描述语言(论文) 摘要: 为了保护云资源的安全,防止数据泄露和非授权访问,必须对云平台的资源访问实施访问控制。然而,目前主流云平台通常采用自己的安全策略语言和访问控制机制,从而造成两个问题&#x…...

MyBatis篇---第一篇
系列文章目录 文章目录 系列文章目录一、什么是MyBatis二、说说MyBatis的优点和缺点三、#{}和${}的区别是什么?一、什么是MyBatis (1)Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL 语句本身,不需要花费精力去处理加载驱动、创建连接、…...

三级分类部分三级目录无法加载,后端接口能在前端返回所有数据
目录 项目场景:三类分类部分不显示问题描述:数据库序号128后的目录不显示原因分析: 数据库&JAVA后端代码:后端接口 解决方案:1 数据库序号问题2 JAVA层面1 递归改成非递归写法2重新写接口: 查询cat_id为…...
Leetcode1839. 所有元音按顺序排布的最长子字符串
Every day a Leetcode 题目来源:1839. 所有元音按顺序排布的最长子字符串 解法1:滑动窗口 要找的是最长美丽子字符串的长度,我们可以用滑动窗口解决。 设窗口内的子字符串为 window,每当 word[right] > window.back() 时&…...

C/C++程序设计和预处理
个人主页:仍有未知等待探索_C语言疑难,数据结构,小项目-CSDN博客 专题分栏:C语言疑难_仍有未知等待探索的博客-CSDN博客 目录 一、引言 二、程序的翻译环境和执行环境 1、什么是程序 2、程序的翻译环境 3、程序的执行环境 三、预处理 1、预定义符…...

openssl生成自签名证书
原网址:https://blog.csdn.net/weixin_41767181/article/details/121531007 windows下安装openssl后,生成自签名证书并打包为P12文件的命令如下: 需要注意的是: 每一级的证书中,证书的公司名称等尽量不要一样根证书…...

JAVA毕业设计100—基于Java+Springboot+Vue的WMS仓库管理系统+移动端微信小程序(源码+数据库+部署视频)
基于JavaSpringbootVue的WMS仓库管理系统移动端(源码数据库部署视频) 一、系统介绍 本系统前后端分离带小程序 本系统分为管理员、用户角色(角色权限可自行分配) 功能列表: 1、 数据管理:物料数据管理、物料Bom管理、物料组管理、物料分类管理、供应…...

深度学习推荐系统架构、Sparrow RecSys项目及深度学习基础知识
文章目录 🌟 技术架构:深度学习推荐系统的经典技术架构长啥样?🍊 一、深度学习推荐系统的技术架构🍊 二、基于用户行为的推荐🍊 三、基于多模态数据的推荐🍊 四、基于知识图谱的推荐 dz…...

ios UI 基础开发二
第一节:UIPickerView、UIPickerViewDataSource、UIPickerViewDelegate 设置约束,如果要设置两个兄弟的约束,可以按住option键,用鼠标右键把a拖到b上面,表示a按照b来对齐 生成随机数 如果后面列的数据,依赖前…...

失配树学习笔记
失配树,是一种奇妙的数据结构,它利用 KMP、LCA 解决求两前缀的最长公共 Border 的问题。 首先介绍一下什么是 Border,我们知道 nxt 数组是前后缀相同的最大长度,Border 相当于是 nxt 数组的弱化版,只是去掉了“最大”…...

【Electron】Not allowed to load local resource
问题描述 使用 audio 标签播放音频文件,控制台报错 Not allowed to load local resource。 Not allowed to load local resource原因分析 通常是安全策略所引起的。Electron 默认情况下禁止加载本地资源,以防止潜在的安全风险。 解决方案 在 main.js…...

Maven 基础教程系列
Maven是一个项目开发管理和理解工具。基于项目对象模型的概念:构建、依赖关系管理、文档创建、站点发布和分发发布都由pom.xml声明性文件控制。Maven可以通过插件进行扩展,以使用许多其他开发工具来报告或构建过程。 一、Maven 使用教程-CSDN博客 二、…...

从理论到实践:深入解析AGPCNet在红外小目标检测中的核心模块与代码实现
1. 红外小目标检测的挑战与AGPCNet的创新价值 红外小目标检测在军事侦察、安防监控等领域具有重要应用,但传统方法面临三大核心难题:首先是目标尺寸过小(通常仅占图像的33到99像素),在复杂背景中容易漏检;其…...

Open UI5 源代码解析之1106:MenuTextFieldItem.js
源代码仓库: https://github.com/SAP/openui5 源代码位置:src\sap.ui.commons\src\sap\ui\commons\MenuTextFieldItem.js MenuTextFieldItem.js 文件深度分析 这不是普通菜单项,而是把输入能力塞进菜单体系的特殊桥接点 MenuTextFieldItem.js 这个文件和前面那些 commo…...

如何使用Prisma管理神经网络训练数据:从入门到精通的完整指南
如何使用Prisma管理神经网络训练数据:从入门到精通的完整指南 【免费下载链接】prisma Next-generation ORM for Node.js & TypeScript | PostgreSQL, MySQL, MariaDB, SQL Server, SQLite, MongoDB and CockroachDB 项目地址: https://gitcode.com/GitHub_Tr…...

C++格式化输出踩坑实录:setprecision和fixed到底怎么用?一个例子讲清楚
C格式化输出深度解析:setprecision与fixed的实战陷阱与解决方案 在金融交易系统开发过程中,我曾遇到一个令人费解的bug:当处理欧元兑美元汇率时,1.23456789被正确显示为1.2346,但当数值变为12.3456789时,输…...

GetQzonehistory:一键永久保存QQ空间说说的完整解决方案
GetQzonehistory:一键永久保存QQ空间说说的完整解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,QQ空间承载了无数人的青春记忆,但…...

低查重AI教材写作秘籍:必备AI工具推荐,快速完成教材编写!
许多教材编写者常常感到遗憾,虽然他们对正文内容进行了精心打磨,但配套资源的缺失却使得整体教学效果受到影响。设计课后练习时往往缺乏创新的思路,制作直观的教学课件又因为技术能力不足而举步维艰,而对于案例的深入解析则因为时…...

)
【2026年最新600套毕设项目分享】微信小程序的新闻资讯系统(30117)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 项目演示视频2 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运…...

2026年怎么搭建OpenClaw?京东云1分钟萌新教程含大模型API与Skill配置
2026年怎么搭建OpenClaw?京东云1分钟萌新教程含大模型API与Skill配置。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办公…...

别再搞混了!一文讲透GIS中.tfw、GDAL、ArcMap的仿射变换六参数对应关系
地理空间数据处理中的仿射变换六参数全解析 当你在处理遥感影像或地图数据时,是否曾被不同GIS工具中的六参数搞得晕头转向?今天我们就来彻底理清.tfw文件、GDAL库和ArcMap中这些神秘数字的对应关系。无论你是GIS开发工程师还是空间数据分析师,…...