Systemverilog覆盖率的合并和计算方式
在systemverilog中,对于一个covergroup来说,可能会有多个instance,我们可能需要对这些instance覆盖率进行操作。
- 只保存covergroup type的覆盖率,不需要保存instance-specified的覆盖率
- coverage type和instance-specified的覆盖率都保存
- 选择coverage type总体覆盖率的计算方式
对于以上的3个问题,可以使用sv里covergroup自带的以下几个控制选项来完成:
| Option name | Type | Default | Description |
| option.per_instance=boolean | Instance-specific coverage options | 0 | Each instance contributes to the overall coverage information for the covergroup type. When true, coverage information for this covergroup instance shall be saved in the coverage database and included in the coverage report. When false, implementations are not required to save instance-specific information. |
| type_option.merge_instances=boolean | Coverage group type (static) options | 0 | When true, cumulative (or type) coverage is computed by merging instances together as the union of coverage of all instances. When false, type coverage is computed as the weighted average of instances. |
| option.get_inst_coverage=boolean | Instance-specific coverage options | 0 | Only applies when the merge_instances type option is set. Enables the tracking of per instance coverage with the get_inst_coverage built-in method. When false, the value returned by get_inst_coverage shall equal the value returned by get_coverage. |
option.per_instance, type_option.merge_instances和option.get_inst_coverage的默认值都是1。要注意的是merge_instances是type_option,也就是说这个coverage group不管例化多少份,merge_instances都是一样的,也可以理解为class里的static变量 (The identifier type_option is a built-in static member of every covergroup, coverpoint, and cross)。其它两个是instanceoption,也就是说在例化covergroup的时候可以更改它们的值,从而造成各种类型的instances,可以理解为内部变量 (Instance-specific option assignment statements in the covergroup definition are evaluated at the time that the covergroup is instantiated. Each instance of a covergroup can initialize an instance-specific option to a different value. The initialized option value affects only that instance.)。
结合上述3个options的功能,我们来看如何解决最开始提出的3个问题。
解决第一个问题
可以把option.per_instance设置为0,或者不配置,因为它的default值是0。这样我们看到的questasim覆盖率结果页面如下:


我们在这个例子里例化了两份cg_dcu_tag covergroup。但最后显示的就单单是covergroup type的结果。
解决第二个问题
可以把option.per_instance设置为1。这样我们看到的questasim覆盖率结果页面如下:
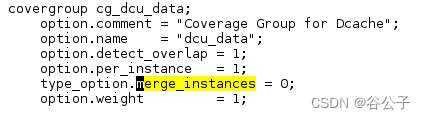

我们在这个例子里例化了两份cg_dcu_data covergroup。因为per_instance=1,所以最后收集到的coverage信息包含covergroup type和covergroup instances的。而且可以看出merge_instances=0,所以covergroup type的覆盖率结果是INST dcu_data和INST dcu_data#1这两个instance的加权平均得到的。(45.15%*1 + 45.12*1)/2 ≈ 45.14%
解决第三个问题
把type_option.merge_instances设置为1或0,会影响covergroup type的覆盖率值。如果设置为0,那么是将各个instance按weight进行加权平均。如果设置为1,是把各个instances的结果或起来。


我们在这个例子里例化了两份cg_dcu_counter covergroup。因为per_instance=1,所以会看到coverage type和coverage instances的结果。还有就是merge_instances=1,所以最后coverage type覆盖率的结果是INST dcu_counter和INST dcu_counter#1的或起来。
其实option.per_instance和type_option.merge_instances各自独立,可以任意组合,上面例子只是组合了3种场景,还有一种场景就是option.per_instance=0,type_option.merge_instances=1。读者可以自行分析。
然后再说下option.get_inst_coverage,这个选项会影响covergroup内置函数get_inst_coverage()的返回结果。如果option.get_inst_coverage=1,那么返回每个特定instance的coverage结果。如果option.get_inst_coverage=0,那么返回总得结果,也就是和get_coverage()内置函数的结果一样。所以读者要根据使用场景自行配置。
覆盖率计算方式
既然这节提到了覆盖率合并,那也顺便说下sv里覆盖率的计算方式。
对于covergroup覆盖率的计算:

对于coverpoint覆盖率的计算:

说明下,coverpoint有两种,1种是用户自动指定bins,另1种是系统自动生成bins。1个bin如果没有转换或者值,那么这个bin的结果会从Ci计算公式里的分母和分子中去掉。也就是不参与计算了。
对于cross覆盖率的计算:

covergroup type覆盖率的计算:
刚才上述也讲过,covergroup type覆盖率的计算有两种方式,如果type_option.merge_instances等于0(false),那么type coverage的计算方式是所有instances的加权平均(weight average)。如果type_option.merge_instances等于1(true),那么type coverage的计算方式是把所有instance的覆盖率结果合并(merge)在一起。因此,当采用加权平均计算方式时,covergroup type coverage的结果单单取决于每个instance,而不是instance内的coverpoints或cross。公式如下:

相关文章:
Systemverilog覆盖率的合并和计算方式
在systemverilog中,对于一个covergroup来说,可能会有多个instance,我们可能需要对这些instance覆盖率进行操作。 只保存covergroup type的覆盖率,不需要保存instance-specified的覆盖率coverage type和instance-specified的覆盖率…...

(周末公众号解读系列)2000字-视觉SLAM综述
参考链接:https://mp.weixin.qq.com/s?__bizMzg2NzUxNTU1OA&mid2247528395&idx1&sn6c9290dd7fd926f11cbaca312fbe99a2&chksmceb84202f9cfcb1410353c805b122e8df2e2b79bd4031ddc5d8678f8b11c356a25f55f488907&scene126&sessionid1677323905…...

力扣29-两数相除
29. 两数相除 给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。 整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 &#x…...
【MindSpore】安装和使用MindSpore 2.0.0版本简单实现数据变换Transforms功能
本篇文章主要是讲讲MindSpore的安装以及根据官方提供的例子实现数据变换功能。 昇思MindSpore是一款开源的AI框架,旨在实现易开发、高效执行、全场景覆盖三大目标。 目录1、加入MindSpore社区2、安装前准备2.1、获取安装命令2.2、安装pip2.3、确认系统环境3、安装Mi…...

PRML笔记4-绪论中推断和决策小结
在推断阶段使用训练数据学习后验概率p(Ck∣x)p(\mathcal{C_k}|\boldsymbol{x})p(Ck∣x)的模型;在决策阶段使用后验概率进行最优的分类;亦或是同时解决推断和决策问题,简单的学习一个函数f(x)f(\boldsymbol{x})f(x),将输入x\bold…...

DSPE-PEG-Streptavidin;Streptavidin-PEG-DSPE;磷脂聚乙二醇链霉亲和素,科研用试剂
DSPE-PEG-Streptavidin 中文名称:二硬脂酰基磷脂酰乙醇胺-聚乙二醇-链霉亲和素 中文别名:磷脂-聚乙二醇-链霉亲和素;链霉亲和素PEG磷脂 英文常用名:DSPE-PEG-Streptavidin;Streptavidin-PEG-DSPE 外观:粉…...
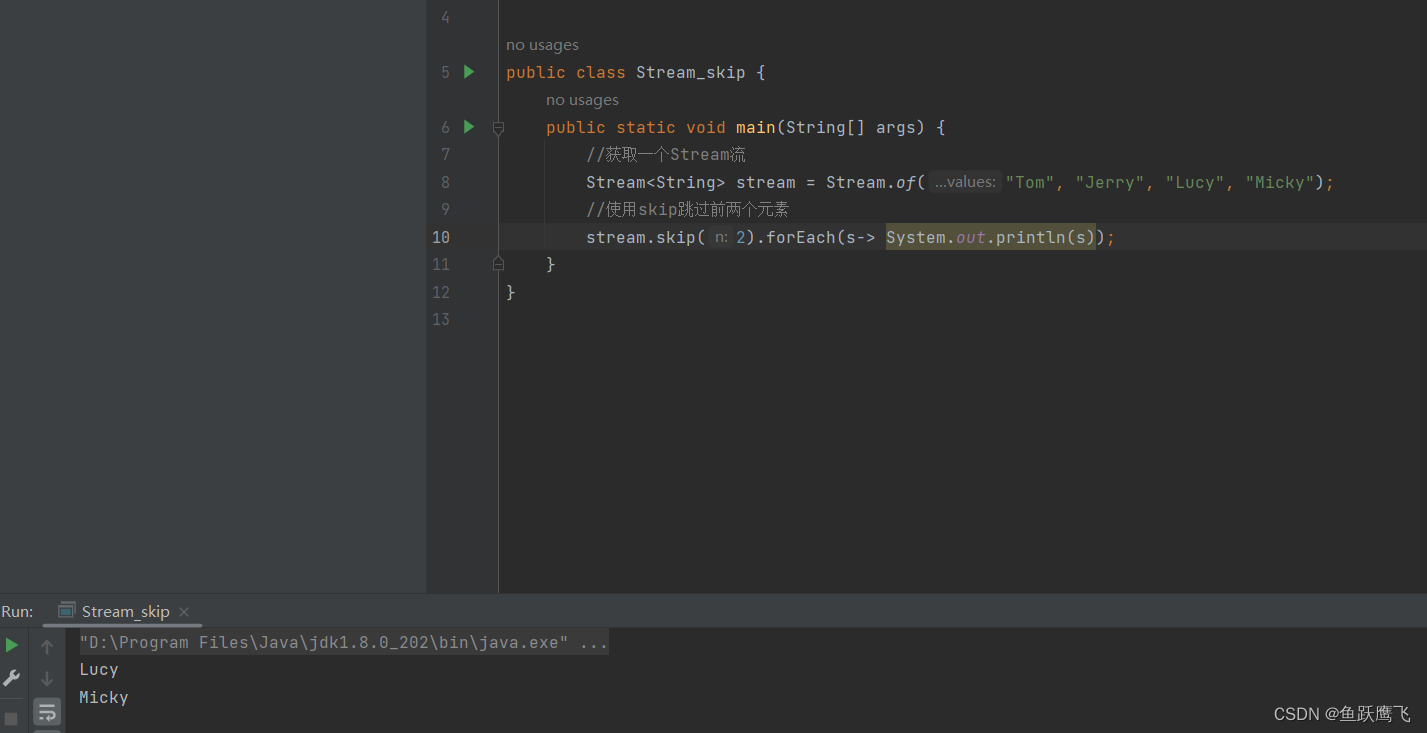
Java中的Stream
Stream流的特点 中间操作返回的是Stream类型,终结操作返回的是void 中间操作的这个Lazy指的是增加待处理操作,而不会真的处理(放队列里),集合中的数据并未实际改变,到终结操作的时候才会把这些放队列里的操…...

【数据库】关系数据理论
第六章关系数据理论 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r9ETJ75y-1677334548439)(imgs/image-20220508202554924.png)] 数据依赖 是一个关系内部属性与属性之间的一种约束关系 函数依赖多值依赖 函数依赖 [外链图片转存失败,源站可…...

初阶C语言——结构体【详解】
文章目录1. 结构体的声明1.1 结构的基础知识1.2 结构的声明1.3 结构成员的类型1.4 结构体变量的定义和初始化2. 结构体成员的访问3. 结构体传参1. 结构体的声明 1.1 结构的基础知识 结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。 …...

盘点:9款身份和访问管理工具
身份和访问管理(IAM)长期以来一直是安全领导者职业生涯的关键“试炼场”,许多人在身份技术部署方面做出了事关成败的决定。 确保安全访问和身份管理是网络安全态势的两大基础 。同时,人员、应用程序和系统登录的方式以及它们彼此集…...
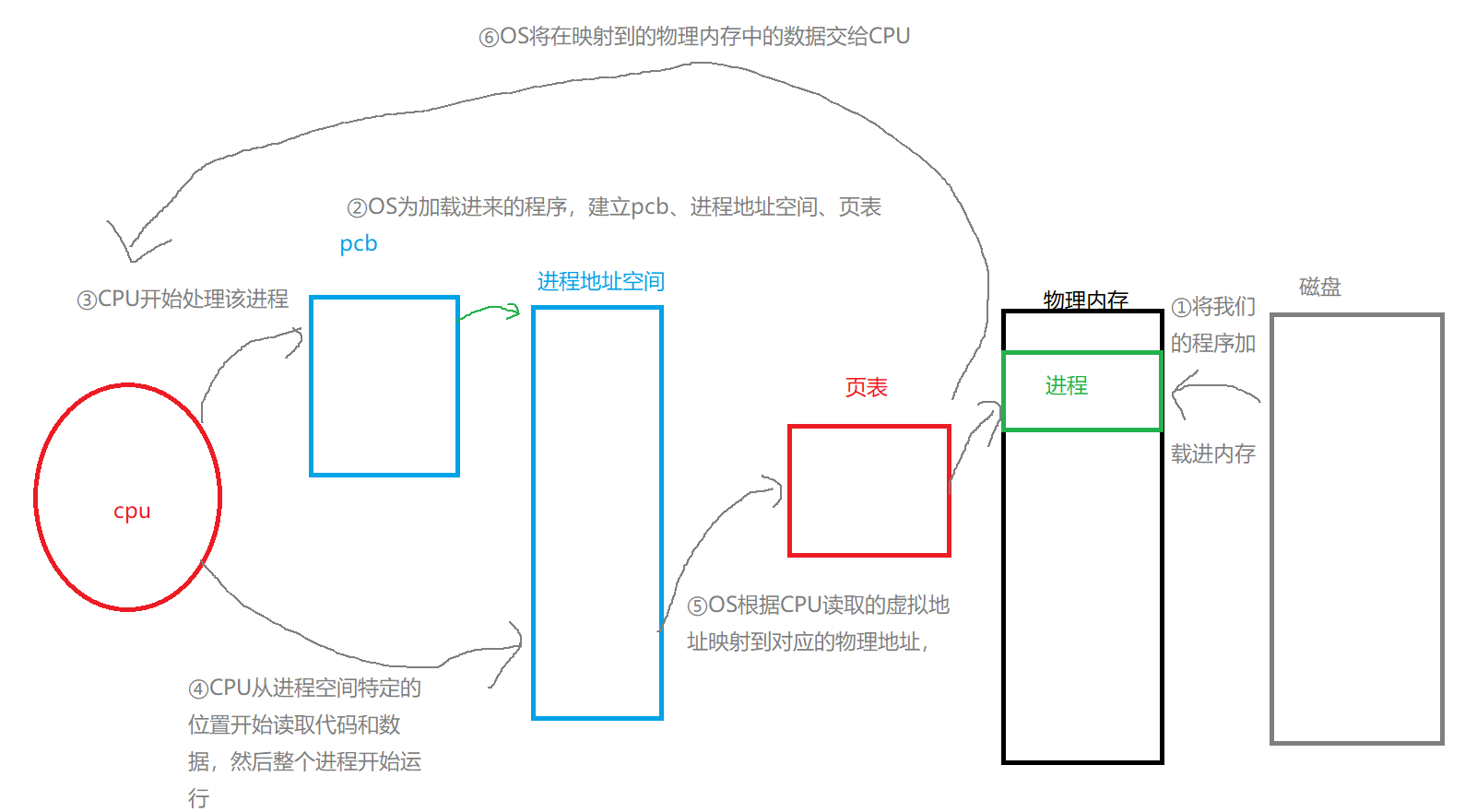
Linux下的进程地址空间
Linux下的进程地址空间程序地址空间回顾从代码结果推结论引入进程地址空间页表为什么要有进程地址空间重新理解进程地址空间程序地址空间回顾 我们在初学C/C的时候,我们会经常看见老师们画这样的内存布局图: 可是这真的是内存吗? 如果不是它…...
Web Spider Ast-Hook 浏览器内存漫游 - 数据检索
文章目录一、资源下载二、通过npm安装anyproxy模块三、anyproxy的介绍以及基本使用1. anyproxy的功能介绍2. anyproxy的基本使用四、给浏览器挂代理五、实操极验demo案例总结提示:以下是本篇文章正文内容,下面案例可供参考 一、资源下载 Github&#x…...

开源启智,筑梦未来!第四届OpenI/O启智开发者大会开幕
2023年2月24日,第四届OpenI/O启智开发者大会在深圳顺利开幕。本次活动由鹏城实验室、新一代人工智能产业技术创新战略联盟(AITISA)主办,OpenI启智社区、中关村视听产业技术创新联盟(AVSA)承办,华…...

CS144-Lab6
概述 在本周的实验中,你将在现有的NetworkInterface基础上实现一个IP路由器,从而结束本课程。路由器有几个网络接口,可以在其中任何一个接口上接收互联网数据报。路由器的工作是根据路由表转发它得到的数据报:一个规则列表&#…...

最好的个人品牌策略是什么样的
在这个自我营销的时代,个人品牌越来越受到人们的重视。您的个人品牌的成功与否取决于您在专业领域拥有的知识,以及拥有将这些知识传达给其他用户的能力。如果人们认为您没有能力并且无法有效地分享有用的知识,那么您就很难获得关注并实现长远…...

第四届国际步态识别竞赛HID2023已经启动,欢迎报名
欢迎参加第四届HID 2023竞赛,证明您的实力,推动步态识别研究发展!本次竞赛的亮点:总额人民币19,000元奖金;最新的SUSTech-Competition步态数据集;比上一届更充裕的准备时间;OpenGait开源程序帮您…...
「2」指针进阶——详解
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 🐰指向函数指针数组的指针(很少用,了解) 🐰回调函数&…...
)
计网笔记 网络层(端到端的服务)
第三章 网络层(端到端的服务) **TCP/IP体系中网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。**网路层不提供服务质量的承诺,不保证分组交付的时限,所传送的分组可能出错、丢失、重复和失序。进程之间通信的…...

[蓝桥杯 2018 省 B] 日志统计——双指针算法
题目描述小明维护着一个程序员论坛。现在他收集了一份“点赞”日志,日志共有 N 行。其中每一行的格式是 ts id,表示在 ts 时刻编号 id 的帖子收到一个“赞”。现在小明想统计有哪些帖子曾经是“热帖”。如果一个帖子曾在任意一个长度为 DD 的时间段内收到…...
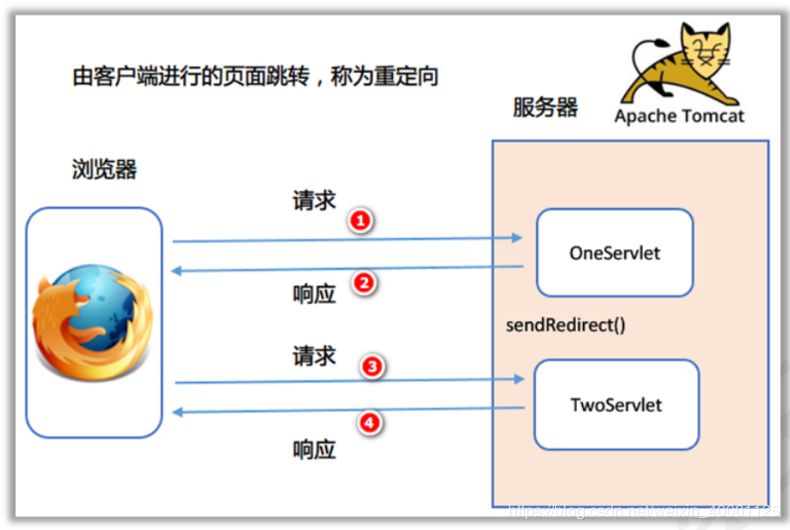
SpringMVC请求转发和重定向
请求转发:forward:重定向:redirect转发:由服务器的页面进行跳转,不需要客户端重新发送请求:特点如下:1、地址栏的请求不会发生变化,显示的还是第一次请求的地址2、请求的次数,有且仅…...

Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘
Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch Cat-Catch作为一款专业…...

面试官视角:我为什么总爱问C语言static、volatile和extern?
面试官视角:为什么C语言的static、volatile和extern是嵌入式面试的必考题? 在嵌入式软件工程师的面试中,static、volatile和extern这三个C语言关键字几乎成了"保留节目"。作为面试官,我见过太多候选人能机械背诵定义&am…...

五分钟完成Python环境配置,用Taotoken调用大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Python环境配置,用Taotoken调用大模型API 对于希望快速体验不同大模型能力的Python开发者而言,通…...

服务器电源、电机驱动、UPS:IRLR3636TRPBF的60V功率MOSFET应用版图
IRLR3636TRPBF:DPAK封装60V/50A N沟道功率MOSFET的大电流开关应用解析在大功率开关电源、不间断电源以及直流电机驱动等领域,功率MOSFET的导通损耗直接影响系统的温升和能效等级。当设计需要在60V电压平台上处理50A级别的大电流时,导通电阻和…...

振弦采集模块设计:从传感器选型到数字信号处理的完整指南
1. 振弦采集读数模块:从物理振动到数字信号的完整旅程在工程测量、结构健康监测以及乐器数字化等领域,我们常常需要精确地捕捉一根弦或类似结构的振动信息。比如,监测桥梁拉索的张力变化、分析古筝琴弦的声学特性,或者检测工业设备…...

猫抓插件:浏览器资源嗅探与下载的完整手册
猫抓插件:浏览器资源嗅探与下载的完整手册 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)是一…...

实在Agent架构实战:彻底化解工厂员工入转调离流程繁琐与HR行政超负荷困局
摘要: 站在2026年这个数字化深水区的节点,制造企业正面临前所未有的管理韧性挑战。工厂员工入转调离流程繁琐已不再仅仅是行政效率问题,而是演变为制约企业规模化扩张与人力成本控制的战略瓶颈。传统数字化手段往往受困于系统烟囱、老旧OA/ER…...

QR码扫描模块全解析:从原理到工程实践
1. 项目概述:不只是“扫一扫”那么简单如果你以为QR码扫描就是个“打开摄像头、对准、识别”的简单功能,那可能错过了它背后一整套精密的技术栈和丰富的应用场景。作为一个在移动应用和嵌入式设备领域折腾了十多年的老码农,我见过太多项目在集…...
)
别再为Gurobi学术许可发愁了!手把手教你从申请到激活(附学信网报告攻略)
Gurobi学术许可全流程实战指南:从申请到Python集成 第一次接触Gurobi优化求解器时,我被它强大的性能所吸引,但随即陷入了学术许可申请的迷茫中。和许多研究生同学一样,我在学信网报告下载、邮件沟通、命令行激活等环节屡屡碰壁。本…...

如何在Windows上轻松安装安卓应用:APK-Installer完整指南
如何在Windows上轻松安装安卓应用:APK-Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接运行安卓应用&am…...