Pytorch从零开始实战06
Pytorch从零开始实战——明星识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——明星识别
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 模型可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是了解如何设置动态学习率。
第一步,导入常用包。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(55)
torch.cuda.manual_seed(55)
torch.cuda.manual_seed_all(55)
random.seed(55)
np.random.seed(55)
创建设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device # device(type='cuda')
数据集
本次数据集使用的一系列明星图片,每一位明星的图片存放在对应的文件夹中,文件夹名为明星的姓名。
使用pathlib查看类别名称
import pathlib
data_dir = './data/star'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames

使用transforms将图片进行预处理,并且使用datasets整合数据集,每个姓名标签对应的一个数字标签。
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/star/", transform=train_transforms)
total_data.class_to_idx

查看随机五张图片。

将数据集以8比2划分为训练集和测试集,使用DataLoader划分批次和随机打乱。
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (1440, 360)
模型选择
本次实验我们直接调用官方的数据集,使用官方预训练的VGG16,冻结模型参数,只训练最后一层的参数。
# 调用官方vgg16
from torchvision.models import vgg16
model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型for param in model.parameters():param.requires_grad = False # 冻结模型的参数,只训练最后一层的参数model.classifier._modules['6'] = nn.Linear(4096, len(classNames)) # 修改vgg16模型中最后一层全连接层,输出目标类别个数
model.to(device)
model

创建模型,使用summary查看参数,VGG16的参数还是比较多的。
from torchsummary import summary
# 将模型转移到GPU中
model = model.to(device)
summary(model, input_size=(3, 224, 224))

开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
设置超参数,本次使用官方的学习率衰减,学习率每经过 4 个 epoch 就会以 0.92 的指数衰减。
lambda1 = lambda epoch: 0.92 ** (epoch // 4)
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.001
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(opt, lr_lambda=lambda1) # 选定调整方法
开始训练,可能是因为只训练最后一层,模型学习的不是很好。
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)scheduler.step()model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s毫秒' % ((T2 - T1)*1000))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")

模型可视化
可视化函数
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
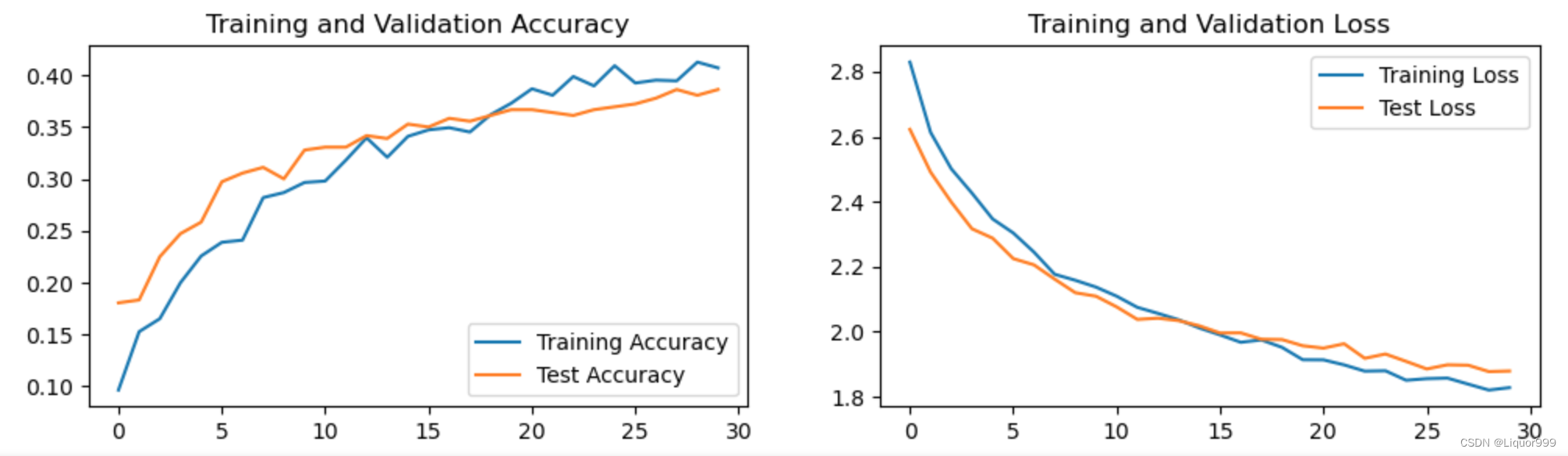
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义预测函数
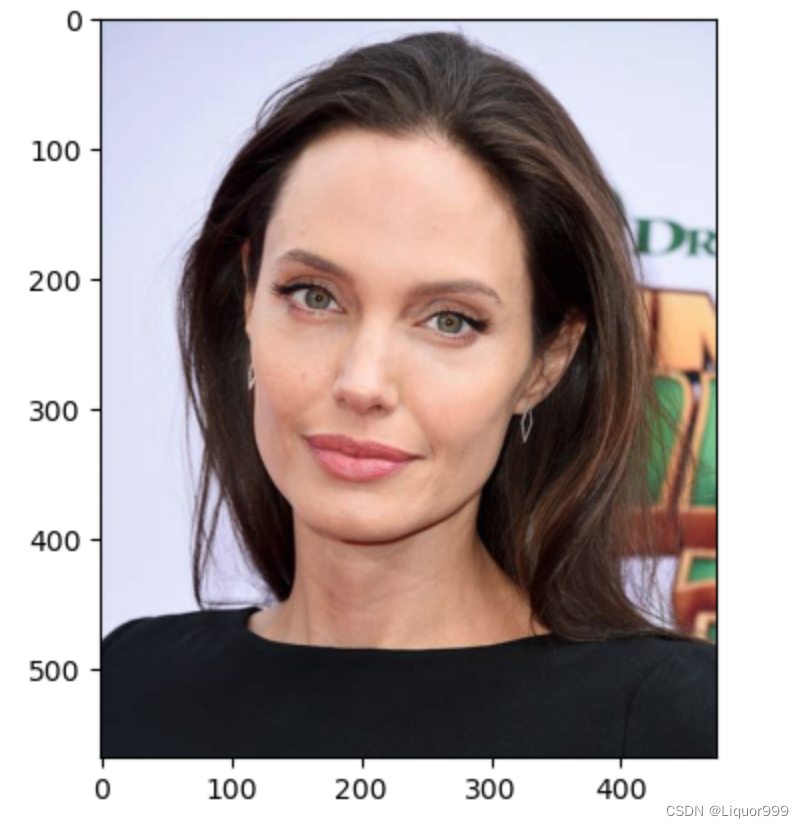
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
调用函数,使用模型预测图片
predict_one_image(image_path='./data/star/Angelina Jolie/001_fe3347c0.jpg', model=model, transform=train_transforms, classes=classes)
# 预测结果是:Angelina Jolie
使用保存的最佳模型查看一下损失。
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.3861111111111111, 1.9115476707617443)
总结
本次调用官方预训练的VGG模型,由于VGG的参数量过大,我们仅训练了最后一层,所以效果不是很好,所以未来数据集比较大的时候,可以放开所有的层重新训练。
相关文章:
Pytorch从零开始实战06
Pytorch从零开始实战——明星识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——明星识别环境准备数据集模型选择开始训练模型可视化模型预测总结 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1c…...

RT-Thread学习笔记(三):线程管理
线程管理 线程管理相关概念什么是时间片轮转调度器锁线程运行机制线程的五种状态 动态和静态创建线程区别动态和静态创建线程优缺点RT-Thread动态线程管理函数动态创建线程动态删除线程 RT-Thread静态线程管理函数静态创建线程 线程其他操作线程启动线程延时获得当前执行的线程…...
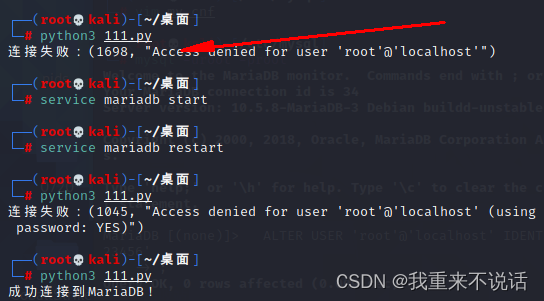
pymysql连接Mariadb/Mysql出现错误(配置正确情况下)解决办法
场景:在kali中使用python中pymysql对Mariadb进行连接,在整个过程中配置全部正确,但是就是无法进行连接,提示结果如下: Access denied for user rootlocalhost解决办法:进入数据库中,将默认密码…...

数据仓库扫盲系列(1):数据仓库诞生原因、基本特点、和数据库的区别
数据仓库的诞生原因 随着互联网的普及,信息技术已经深入到各行各业,并逐步融入到企业的日常运营中。然而,当前企业在信息化建设过程中遇到了一些困境与挑战。 1、历史数据积存。 过去企业的业务系统往往是在较长时间内建设的,很…...
DataX-web安装部署和使用
DataX-web的环境准备 MySQL (5.5) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库 JDK (1.8.0_xxx) 必选 DataX 必选 Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在do…...

sqlmap防御以及文件读写
一.防御 过滤 1.使用过滤函数 $email filter_var($_POST[email], FILTER_VALIDATE_EMAIL); if ($email) { // input is a valid email address } else { // input is not a valid email address 使用 filter_var() 函数和 FILTER_VALIDATE_EMAIL 过滤器来验证用户输…...
【源码】C/C++运动会计分系统 期末设计源码
文章目录 题目介绍功能源码效果展示带报告(内容) 题目介绍 使用语言: 两个版本都会发: 版本1:C语言 版本2: C 代码量: 500 题目介绍: 要求:初始化输入:N-参赛…...

Ubuntu安装Docker
卸载官方库中之前的旧版本 sudo apt-get remove docker docker-engine docker-ce docker.io更新安装包列表 sudo apt-get update安装以下包以使apt可以通过HTTPS使用存储库 sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common添…...

useReducer+createContext真的可以代替Redux吗?
概念 useReducer useReducer 是 React 提供的一个状态管理钩子,通常用于管理组件的复杂状态逻辑。它采用两个参数:reducer 函数和初始状态。Reducer 函数接受当前状态和一个操作(action),并返回一个新的状态。这有点…...
)
Mysql忘记登入密码找回 方法(超详细)
如果你找不到 MySQL 的安装路径,可以尝试以下几种方法: 检查环境变量:打开命令提示符,并运行以下命令: echo %PATH% 这会显示系统的环境变量。查找其中是否包含 MySQL 相关的路径,例如 C:\Program Files…...
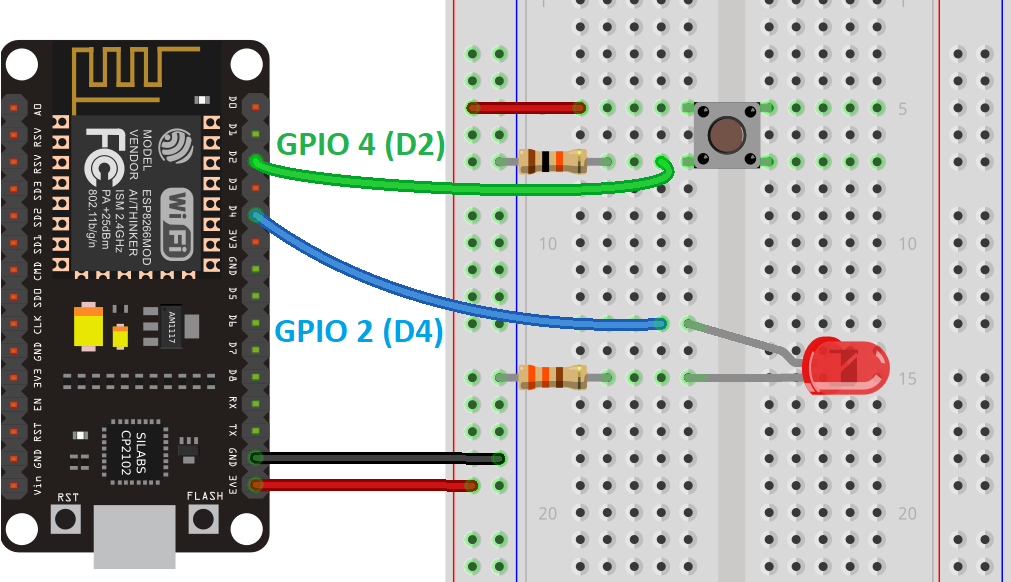
NodeMCU ESP8266 读取按键外部输入信号详解(图文并茂)
NodeMCU ESP8266 读取按键外部输入信号教程(图文并茂) 文章目录 NodeMCU ESP8266 读取按键外部输入信号教程(图文并茂)前言按键输入常用接口pinModedigitalRead 示例代码结论 前言 ESP8266如何检测外部信号的输入,通常…...

Oracle如何插入图片数据?
1、创建表,注意:插入图片的列要定义成BLOB类型 create table image_lob(t_id varchar2(5) not null,t_image blob not null);2、创建图片目录,images为目录名 create or replace directory "images" as f:\pic\;3、创建存储过程&am…...
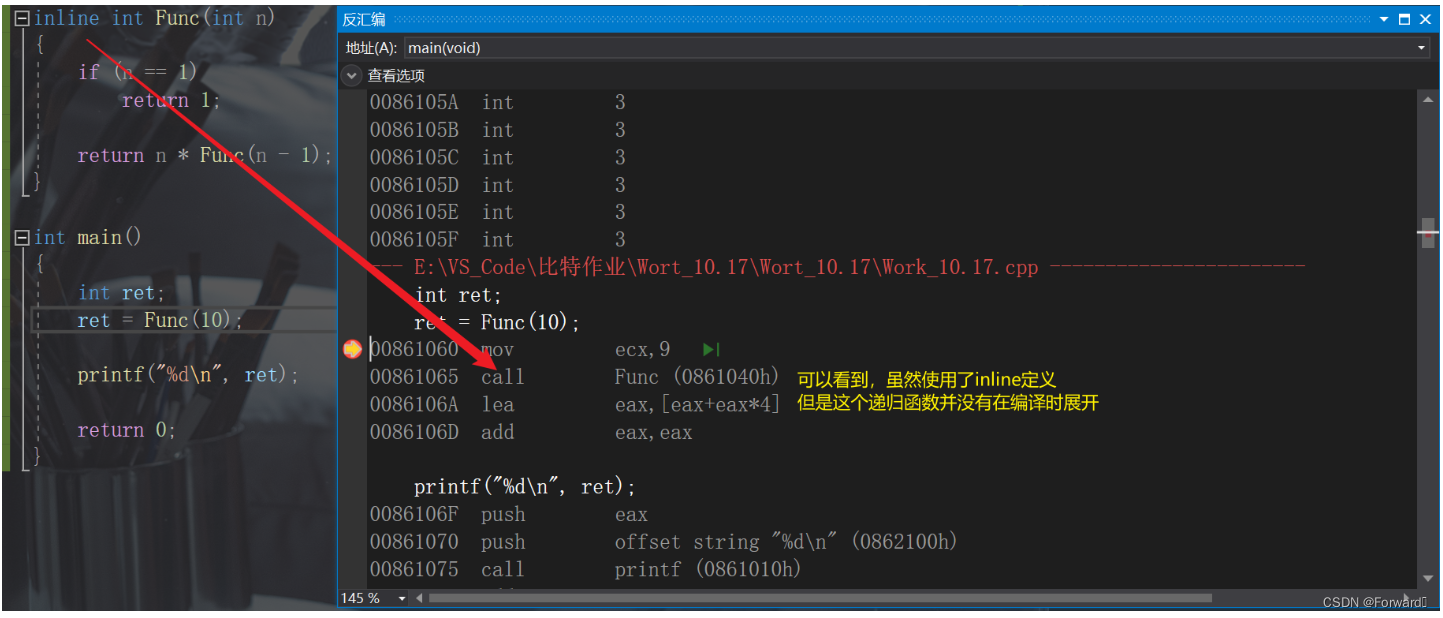
C++特性——inline内联函数
1. 内联函数 1.1 C语言的宏 在C语言中,我们学习了用#define定义的宏函数,例如: #define Add(x, y) ((x) (y)) //两数相加相较于函数,我们知道宏替换具有如下比较明显的优点: 性能优势: 宏在预处理阶段…...
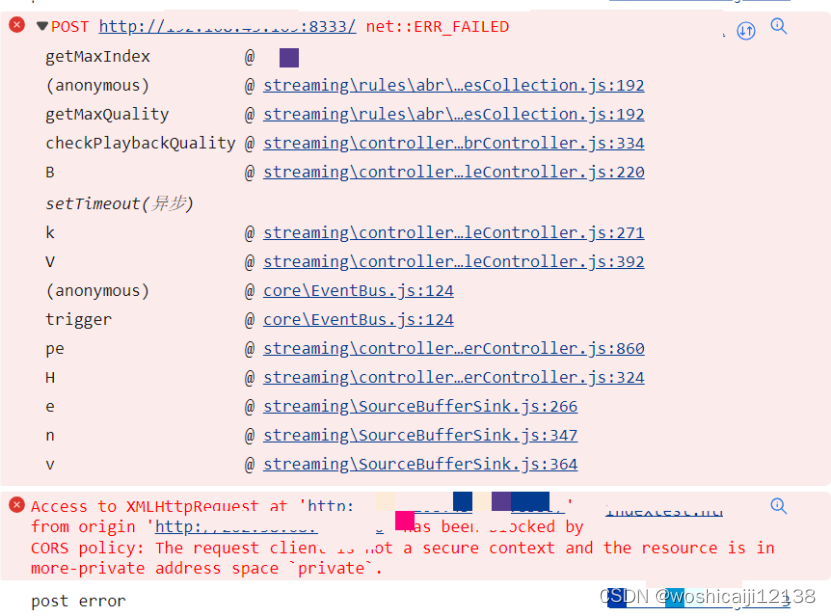
pensieve运行的经验
1运行run_videopy时出现如下问题: cmd: Union[List[str], str], ^ SyntaxError: invalid syntax原因是EasyProcess版本与python版本不对应,解决办法可见之前这篇博客:SyntaxError: invalid syntax。 2解决完上述问题后,输…...
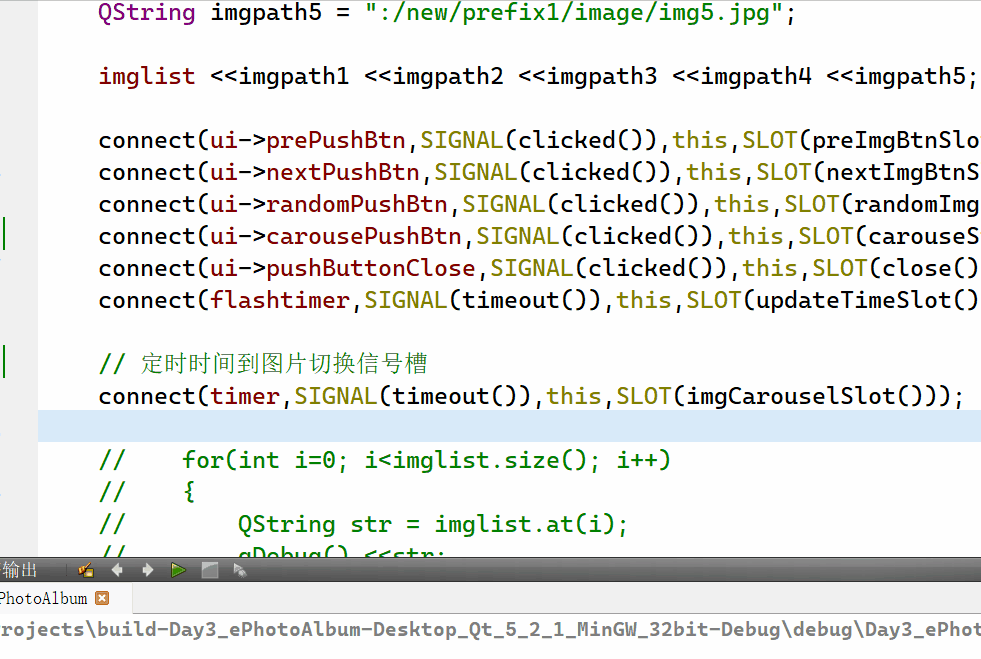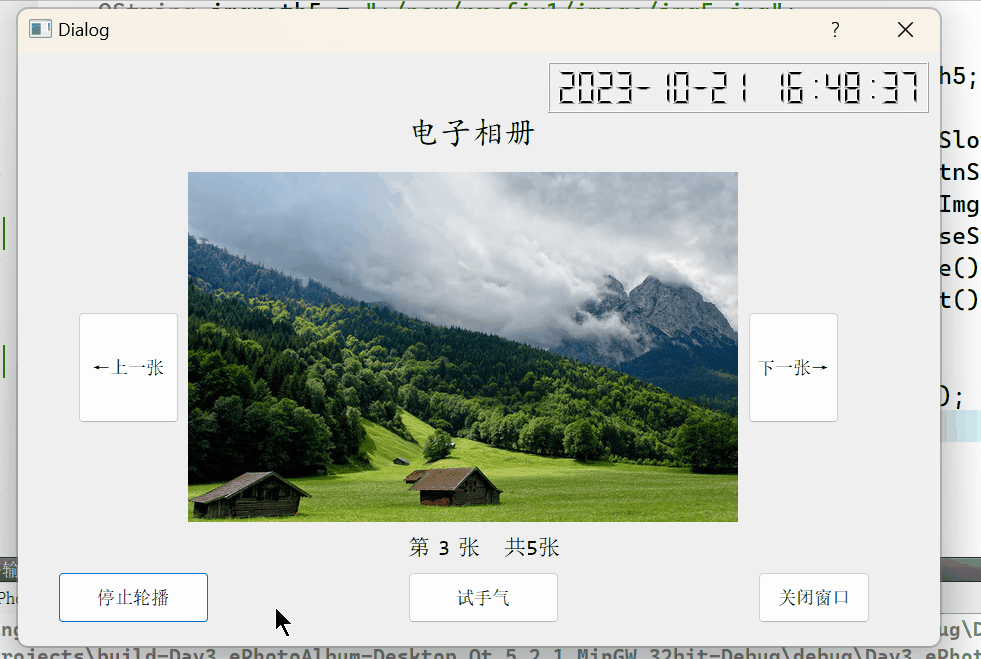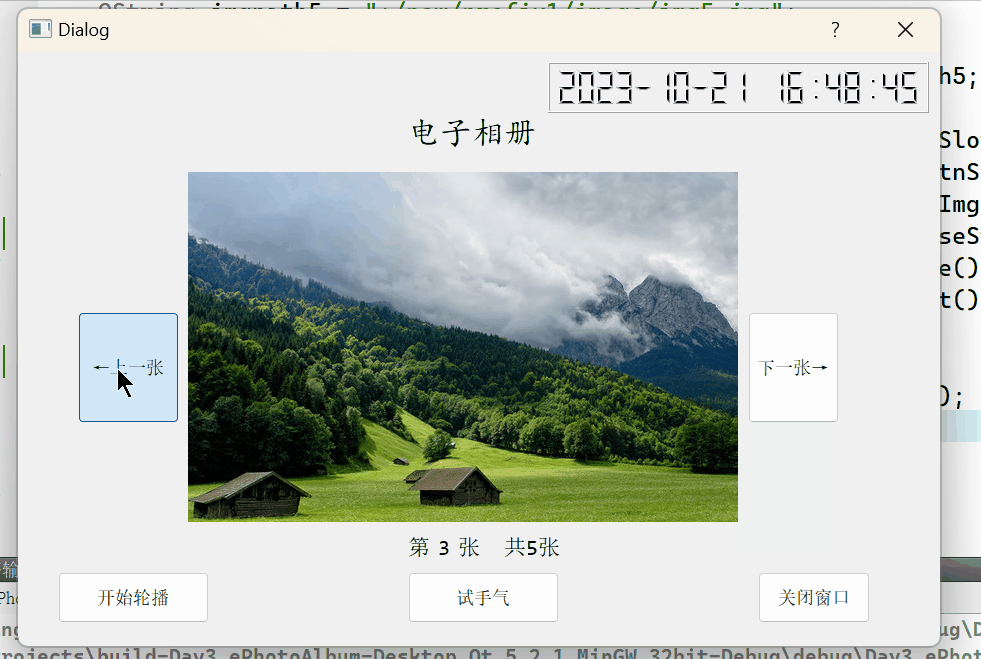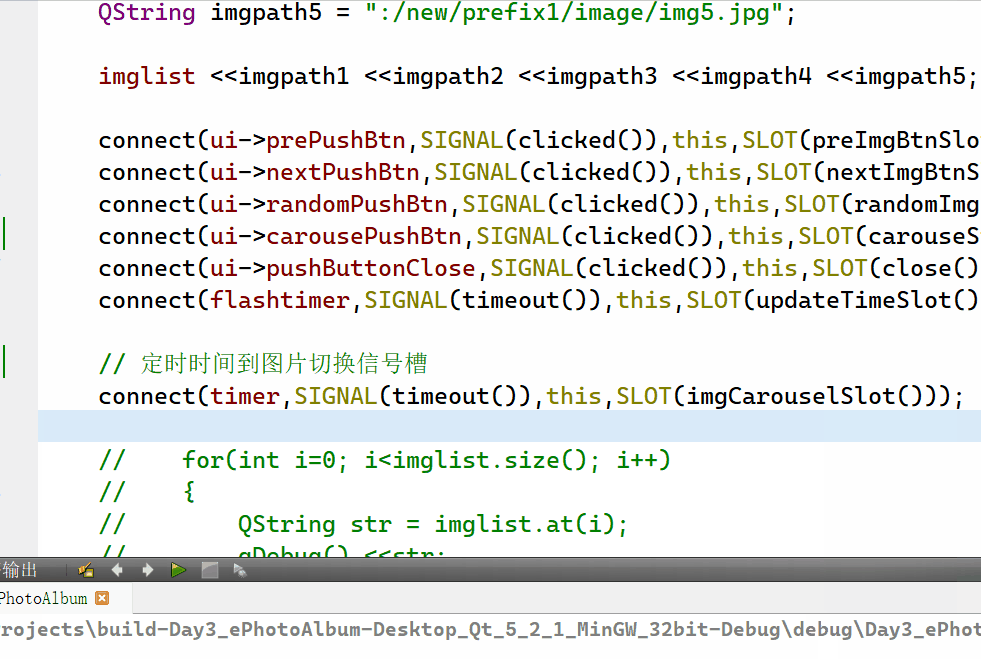
Qt实现一个电子相册
一、要实现的功能 在窗口中可以显示图片,并且能够通过两个按钮进行图片的前进和后退的顺序切换。有一个按钮,通过这个按钮可以从所存图片资源中随机选取一个图片进行展示通过按钮可以控制图片自动轮播顺序切换的开始与停止,显示当前系统的时…...

R语言:因子分析 factor analysis
文章目录 因子分析数据集处理步骤主成分法做因子分析最大似然法做因子分析因子分析 因子分析的用途与主成分分析类似,它也是一种降维方法。由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功,从而有更广泛的应用。 从方法上来说,因子分析比主成分分析更为…...
SOFAStack软件供应链安全产品解析——SCA软件成分分析
近年来,软件供应链安全相关攻击事件呈快速增长态势,造成的危害也越来越严重,为了保障软件供应链安全,各行业主管单位也出台了诸多政策及技术标准。基于内部多年的实践,蚂蚁数科金融级云原生PaaS平台SOFAStack发布完整的…...

vue中ElementUi的el-table表格绑定行点击事件
<el-table v-loading"loading" :data"messagesList" row-click"goToMassage">handleRowClick(row, event, column) {// 在这里处理行点击事件console.log(行点击事件:, row, event, column);}...
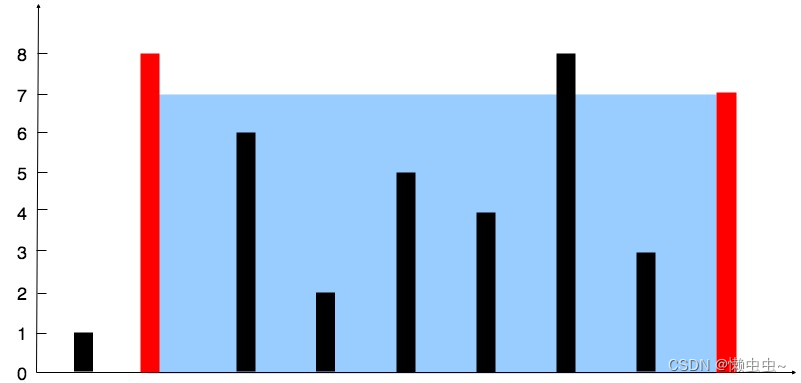
力扣:盛最多水的容器
题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容器。 …...

3D双目跟踪瞳孔识别
人眼数据集通常用于眼部相关的计算机视觉、眼动追踪、瞳孔检测、情感识别以及生物特征识别等领域的研究和开发。以下是一些常见的人眼数据集: BioID Face Database: 这个数据库包含1,521张近距离的人脸图像,其中包括瞳孔位置的标记。它通常用于瞳孔检测和…...

Kubernetes 创造者投身自主 AI,Stacklok 能否打造 AI 领域的“Kubernetes 时刻”?
聚焦责任问题McLuckie 在 2023 年初创立了 Stacklok。他的搭档 Beda 在 2022 年“半退休”,加入是因这是“行业的一个非凡时刻”,有机会用专业知识解决企业关键问题。McLuckie 称最大问题是责任,智能体无法对工作负责,企业仍要对结…...

终极指南:如何免费解锁惠普游戏本全部性能潜力
终极指南:如何免费解锁惠普游戏本全部性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub软件的资源占用…...

通俗易懂讲透 Q-Learning:从零学会强化学习核心算法
通俗易懂讲透 Q-Learning:从零学会强化学习核心算法 Q-Learning 是无模型、基于价值迭代的经典强化学习算法,核心就是让智能体通过不断试错,记住每个状态下做什么动作收益最大,最终学到最优决策策略。一、先搞懂:Q-Lea…...

Python自动化处理配置文件:项目配置管理的最佳实践
项目做大了,配置文件一多就头疼:开发环境用一套配置,生产环境用另一套;有些参数需要加密保存;配置文件分布在不同地方难管理。今天分享Python自动化处理配置文件的完整方案,包括配置读取、环境切换、加密存储、配置校验等功能。 环境准备 pip install python-dotenv py…...

5分钟搭建专属视频门户:MediaCMS让媒体管理变得如此简单
5分钟搭建专属视频门户:MediaCMS让媒体管理变得如此简单 【免费下载链接】mediacms MediaCMS is a modern, fully featured open source video and media CMS, written in Python/Django and React, featuring a REST API. 项目地址: https://gitcode.com/gh_mirr…...
)
老板必看:CMMM评估拿政府补贴的完整攻略(附各地政策与申报流程)
CMMM评估实战指南:如何精准获取政府智能制造补贴 站在2024年的智能制造风口,越来越多的企业管理者发现,CMMM评估不仅是提升生产效能的工具,更是一把打开政府资金支持的"金钥匙"。但面对各地差异化的政策条款和复杂的申…...
)
直播卡顿、首开慢、延时高?别慌!一份超全的排查手册(附FFmpeg/WebRTC实战参数)
直播质量优化全链路实战:从现象定位到参数调优 直播过程中突然出现的卡顿、首开延迟或音画不同步,往往让技术团队如临大敌。不同于点播的事后处理,直播问题的排查需要工程师在分钟级内完成根因定位与修复。本文将构建一套从现象分析到参数调优…...

如何3步破解百度网盘Mac版下载限制?终极免费SVIP体验指南
如何3步破解百度网盘Mac版下载限制?终极免费SVIP体验指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版龟速下载而烦…...

他写了十年 Linux,我白嫖了十年
公众号关注 「奇妙的 Linux 世界」设为「星标」,每天带你玩转 Linux !一个普通技术人的十年坚守:『奇妙的 Linux 世界』十周年记十年。这两个字,每次在脑海里默念,都会让我愣神片刻。不是因为骄傲,而是真的…...

Windows Cleaner:完全免费的C盘清理神器,3步解决磁盘空间不足问题
Windows Cleaner:完全免费的C盘清理神器,3步解决磁盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你的Windows电脑是否经常…...