相似度loss汇总,pytorch code
用于约束图像生成,作为loss。
可梯度优化
- pytorch structural similarity (SSIM) loss https://github.com/Po-Hsun-Su/pytorch-ssim
- https://github.com/harveyslash/Facial-Similarity-with-Siamese-Networks-in-Pytorch/blob/master/Siamese-networks-medium.ipynb
class ContrastiveLoss(torch.nn.Module):"""Contrastive loss function.Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf"""def __init__(self, margin=2.0):super(ContrastiveLoss, self).__init__()self.margin = margindef forward(self, output1, output2, label):euclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))return loss_contrastive
- 多个集合,参看写法 Multi-Similarity Loss for Deep Metric Learning (MS-Loss)
- 参考 https://blog.csdn.net/m0_46204224/article/details/117997854
@LOSS.register('ms_loss')
class MultiSimilarityLoss(nn.Module):def __init__(self, cfg):super(MultiSimilarityLoss, self).__init__()self.thresh = 0.5self.margin = 0.1self.scale_pos = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_POSself.scale_neg = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_NEGdef forward(self, feats, labels):assert feats.size(0) == labels.size(0), \f"feats.size(0): {feats.size(0)} is not equal to labels.size(0): {labels.size(0)}"batch_size = feats.size(0)sim_mat = torch.matmul(feats, torch.t(feats))epsilon = 1e-5loss = list()for i in range(batch_size):pos_pair_ = sim_mat[i][labels == labels[i]]pos_pair_ = pos_pair_[pos_pair_ < 1 - epsilon]neg_pair_ = sim_mat[i][labels != labels[i]]neg_pair = neg_pair_[neg_pair_ + self.margin > min(pos_pair_)]pos_pair = pos_pair_[pos_pair_ - self.margin < max(neg_pair_)]if len(neg_pair) < 1 or len(pos_pair) < 1:continue# weighting steppos_loss = 1.0 / self.scale_pos * torch.log(1 + torch.sum(torch.exp(-self.scale_pos * (pos_pair - self.thresh))))neg_loss = 1.0 / self.scale_neg * torch.log(1 + torch.sum(torch.exp(self.scale_neg * (neg_pair - self.thresh))))loss.append(pos_loss + neg_loss)if len(loss) == 0:return torch.zeros([], requires_grad=True)loss = sum(loss) / batch_sizereturn loss
- Recall@k Surrogate Loss with Large Batches and Similarity Mixup https://github.com/yash0307/RecallatK_surrogate
class RecallatK(torch.nn.Module):def __init__(self, anneal, batch_size, num_id, feat_dims, k_vals, k_temperatures, mixup):super(RecallatK, self).__init__()assert(batch_size%num_id==0)self.anneal = annealself.batch_size = batch_sizeself.num_id = num_idself.feat_dims = feat_dimsself.k_vals = [min(batch_size, k) for k in k_vals]self.k_temperatures = k_temperaturesself.mixup = mixupself.samples_per_class = int(batch_size/num_id)def forward(self, preds, q_id):batch_size = preds.shape[0]num_id = self.num_idanneal = self.annealfeat_dims = self.feat_dimsk_vals = self.k_valsk_temperatures = self.k_temperaturessamples_per_class = int(batch_size/num_id)norm_vals = torch.Tensor([min(k, (samples_per_class-1)) for k in k_vals]).cuda()group_num = int(q_id/samples_per_class)q_id_ = group_num*samples_per_classsim_all = (preds[q_id]*preds).sum(1)sim_all_g = sim_all.view(num_id, int(batch_size/num_id))sim_diff_all = sim_all.unsqueeze(-1) - sim_all_g[group_num, :].unsqueeze(0).repeat(batch_size,1)sim_sg = sigmoid(sim_diff_all, temp=anneal)for i in range(samples_per_class): sim_sg[group_num*samples_per_class+i,i] = 0.sim_all_rk = (1.0 + torch.sum(sim_sg, dim=0)).unsqueeze(dim=0)sim_all_rk[:, q_id%samples_per_class] = 0.sim_all_rk = sim_all_rk.unsqueeze(dim=-1).repeat(1,1,len(k_vals))k_vals = torch.Tensor(k_vals).cuda()k_vals = k_vals.unsqueeze(dim=0).unsqueeze(dim=0).repeat(1, samples_per_class, 1)sim_all_rk = k_vals - sim_all_rkfor given_k in range(0, len(self.k_vals)):sim_all_rk[:,:,given_k] = sigmoid(sim_all_rk[:,:,given_k], temp=float(k_temperatures[given_k]))sim_all_rk[:,q_id%samples_per_class,:] = 0.k_vals_loss = torch.Tensor(self.k_vals).cuda()k_vals_loss = k_vals_loss.unsqueeze(dim=0)recall = torch.sum(sim_all_rk, dim=1)recall = torch.minimum(recall, k_vals_loss)recall = torch.sum(recall, dim=0)recall = torch.div(recall, norm_vals)recall = torch.sum(recall)/len(self.k_vals)return (1.-recall)/batch_size
-
Circle Loss https://github.com/TinyZeaMays/CircleLoss/blob/master/circle_loss.py
-
Torch的官方 https://pytorch.org/docs/1.12/nn.functional.html#loss-functions
-
KL散度
-
Hard Triplet loss
from __future__ import absolute_import
import sysimport torch
from torch import nn
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")class TripletLoss(nn.Module):"""Triplet loss with hard positive/negative mining.Reference:Hermans et al. In Defense of the Triplet Loss for Person Re-Identification. arXiv:1703.07737.Code imported from https://github.com/Cysu/open-reid/blob/master/reid/loss/triplet.py.Args:margin (float): margin for triplet."""def __init__(self, margin=0.3):#三元组的阈值marginsuper(TripletLoss, self).__init__()self.margin = marginself.ranking_loss = nn.MarginRankingLoss(margin=margin)#三元组损失函数#ap an margin y:倍率 Relu(ap - anxy + margin)这个relu就起到和0比较的作用def forward(self, inputs, targets):"""Args:inputs: visualization_feature_map matrix with shape (batch_size, feat_dim)#32x2048targets: ground truth labels with shape (num_classes)#tensor([32])[1,1,1,1,2,3,2,,,,2]32个数,一个数代表ID的真实标签"""n = inputs.size(0)#取出输入的batch# Compute pairwise distance, replace by the official when merged#计算距离矩阵,其实就是计算两个2048维之间的距离平方(a-b)**2=a^2+b^2-2ab#[1,2,3]*[1,2,3]=[1,4,9].sum()=14 点乘dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)dist = dist + dist.t()dist.addmm_(1, -2, inputs, inputs.t())#生成距离矩阵32x32,.t()表示转置dist = dist.clamp(min=1e-12).sqrt() # for numerical stability#clamp(min=1e-12)加这个防止矩阵中有0,对梯度下降不好# For each anchor, find the hardest positive and negativemask = targets.expand(n, n).eq(targets.expand(n, n).t())#利用target标签的expand,并eq,获得mask的范围,由0,1组成,,红色1表示是同一个人,绿色0表示不是同一个人dist_ap, dist_an = [], []#用来存放ap,anfor i in range(n):#i表示行# dist[i][mask[i]],,i=0时,取mask的第一行,取距离矩阵的第一行,然后得到tensor([1.0000e-06, 1.0000e-06, 1.0000e-06, 1.0000e-06])dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))#取某一行中,红色区域的最大值,mask前4个是1,与dist相乘dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))#取某一行,绿色区域的最小值,加一个.unsqueeze(0)将其变成带有维度的tensordist_ap = torch.cat(dist_ap)dist_an = torch.cat(dist_an)# Compute ranking hinge lossy = torch.ones_like(dist_an)#y是个权重,长度像dist-anloss = self.ranking_loss(dist_an, dist_ap, y) #ID损失:交叉商输入的是32xf f.shape=分类数,然后loss用于计算损失#度量三元组:输入的是dist_an(从距离矩阵中,挑出一行(即一个ID)的最大距离),dist_ap#ranking_loss输入 an ap margin y:倍率 loss: Relu(ap - anxy + margin)这个relu就起到和0比较的作用# from IPython import embed# embed()return lossclass MultiSimilarityLoss(nn.Module):def __init__(self, margin=0.7):super(MultiSimilarityLoss, self).__init__()self.thresh = 0.5self.margin = marginself.scale_pos = 2.0self.scale_neg = 40.0def forward(self, feats, labels):assert feats.size(0) == labels.size(0), \f"feats.size(0): {feats.size(0)} is not equal to labels.size(0): {labels.size(0)}"batch_size = feats.size(0)feats = nn.functional.normalize(feats, p=2, dim=1)# Shape: batchsize * batch sizesim_mat = torch.matmul(feats, torch.t(feats))epsilon = 1e-5loss = list()mask = labels.expand(batch_size, batch_size).eq(labels.expand(batch_size, batch_size).t())for i in range(batch_size):pos_pair_ = sim_mat[i][mask[i]]pos_pair_ = pos_pair_[pos_pair_ < 1 - epsilon]neg_pair_ = sim_mat[i][mask[i] == 0]neg_pair = neg_pair_[neg_pair_ + self.margin > min(pos_pair_)]pos_pair = pos_pair_[pos_pair_ - self.margin < max(neg_pair_)]if len(neg_pair) < 1 or len(pos_pair) < 1:continue# weighting steppos_loss = 1.0 / self.scale_pos * torch.log(1 + torch.sum(torch.exp(-self.scale_pos * (pos_pair - self.thresh))))neg_loss = 1.0 / self.scale_neg * torch.log(1 + torch.sum(torch.exp(self.scale_neg * (neg_pair - self.thresh))))loss.append(pos_loss + neg_loss)# pos_loss =if len(loss) == 0:return torch.zeros([], requires_grad=True, device=feats.device)loss = sum(loss) / batch_sizereturn lossif __name__ == '__main__':#测试TripletLoss(nn.Module)use_gpu = Falsemodel = TripletLoss()features = torch.rand(32, 2048)label= torch.Tensor([1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8,8]).long()loss = model(features, label)print(loss)
不可梯度优化
相关文章:

相似度loss汇总,pytorch code
用于约束图像生成,作为loss。 可梯度优化 pytorch structural similarity (SSIM) loss https://github.com/Po-Hsun-Su/pytorch-ssimhttps://github.com/harveyslash/Facial-Similarity-with-Siamese-Networks-in-Pytorch/blob/master/Siamese-networks-medium.ip…...
python中的yolov5结合PyQt5,使用QT designer设计界面没正确启动的解决方法
python中的yolov5结合PyQt5,使用QT designer设计界面没正确启动的解决方法 一、窗体设计test: 默认你已经设计好了窗体后: 这时你需要的是保存生成的untitle.ui到某个文件夹下,然后在命令行中奖.ui转换为.py(,通过…...

Milk-V Duo移植rt-thread smart
前言 (1)PLCT实验室实习生长期招聘:招聘信息链接 (2)首先,我们拿到Milk-V Duo板子之后,我个人建议先移植大核Linux。因为那个资料相对多一点,也简单很多,现象也容易观察到…...

会声会影2024有哪些新功能?好不好用
比如会声会影视频编辑软件,既加入光影、动态特效的滤镜效果,也提供了与色彩调整相关的LUT配置文件滤镜,可选择性大,运用起来更显灵活。会声会影在用户的陪伴下走过20余载,经过上百个版本的优化迭代,已将操作…...

vue3 + axios 中断取消接口请求
前言 最近开发过程中,总是遇到想把正在请求的axios接口取消,这种情况有很多应用场景,举几个例子: 弹窗中接口请求返回图片,用于前端展示,接口还没返回数据,此时关闭弹窗,需要中断接…...

Linux高性能服务器编程——ch6笔记
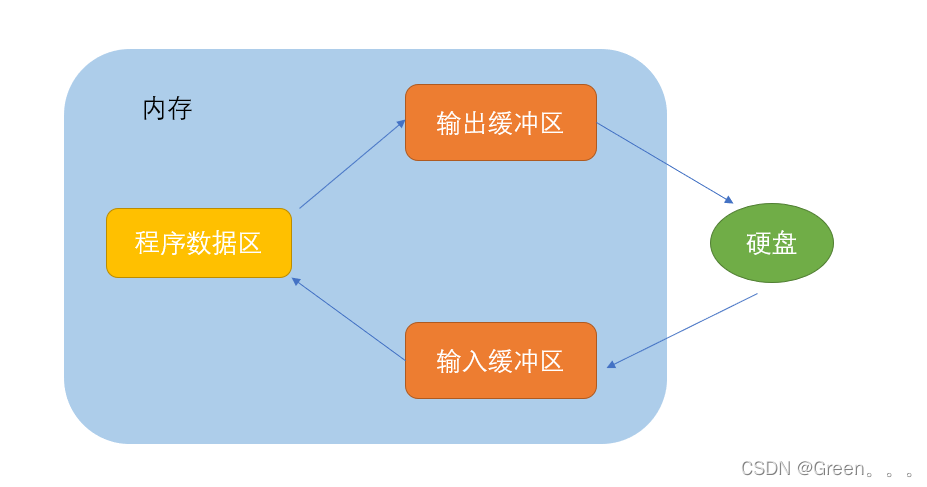
第6章 高级I/O函数 6.1 pipe函数 用于创建一个管道,以实现进程间通信。 int pipe(int fd[2]); 读端文件描述符fd[0]和写端文件描述符fd[1]构成管道的两端,默认是阻塞的,fd[0]读出数据,fd[1]写入数据。管道内部传输的数据是字节…...
【C语言进阶】文件操作
文件操作 1. 为什么使用文件2. 什么是文件2.1程序文件2.2 数据文件2.3 文件名 3. 文件的打开和关闭3.1 文件指针3.2 文件的打开和关闭 4. 文件的顺序读写4.1 对比一组函数 5. 文件的随机读写5.1 fseek5.2 ftell5.3 rewind 6. 文本文件和二进制文件7. 文件读取结束的判定7.1 被错…...
Redis学习(第八章缓存策略)
目录 RdisExample 课程介绍 1.Redis介绍 2.Redis 安装 3. Redis的数据结构 4. Redis缓存特性 5. Redis使用场景 6. Redis客户端-Jedis 7. Jedis Pipeline 8. Redis缓存策略 学习资料 QA 相关问题 http, socket ,tcp的区别 RdisExample 项目代码地址:htt…...

springboot+vue开发的视频弹幕网站动漫网站
springbootvue开发的视频弹幕网站动漫网站 演示视频 https://www.bilibili.com/video/BV1MC4y137Qk/?share_sourcecopy_web&vd_source11344bb73ef9b33550b8202d07ae139b 功能: 前台: 首页(猜你喜欢视频推荐)、轮播图、分类…...

【CSS】常见 CSS 布局
1. 响应式布局 <!DOCTYPE html> <html><head><title>简单的响应式布局</title><style>/* 全局样式 */body {font-family: Arial, sans-serif;margin: 0;padding: 0;}/* 头部样式 */header {background-color: #333;color: #fff;padding: …...
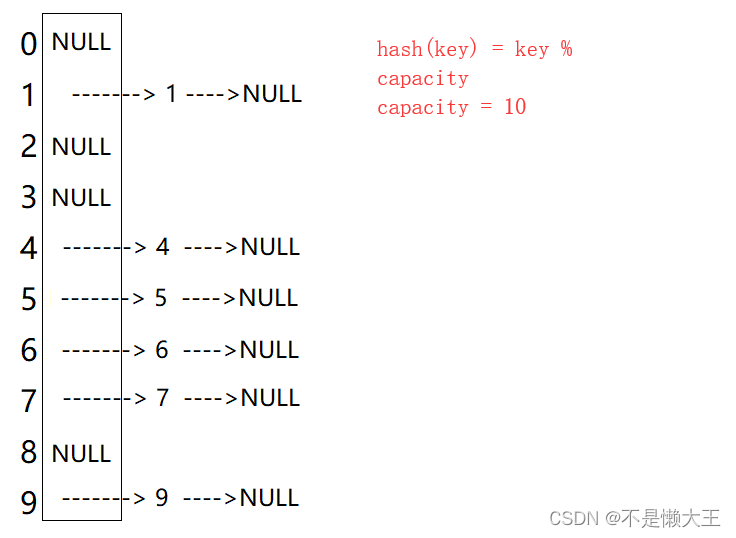
数据结构---HashMap和HashSet
HashMap和HashSet都是存储在哈希桶之中,我们可以先了解一些哈希桶是什么。 像这样,一个数组数组的每个节点带着一个链表,数据就存放在链表结点当中。哈希桶插入/删除/查找节点的时间复杂度是O(1) map代表存入一个key值,一个val值…...

SLAM中相机姿态估计算法推导基础数学总结
相机模型 基本模型 内参 外参 对极几何 对极约束 外积符号 基础矩阵F和本质矩阵E 相机姿态估计问题分为如下两步: 本质矩阵 E t ∧ R Et^{\wedge}R Et∧R因为 t ∧ t^{\wedge} t∧其实就是个3x3的反对称矩阵,所以 E E E也是一个3x3的矩阵 用八点法估计E…...
的意义和区别)
【RS】遥感影像/图片64位、16位(64bit、16bit)的意义和区别
在数字图像处理中,我们常常会听到不同的位数术语,比如64位、16位和8位(64bit、16bit、8bit)。这些位数指的是图像的深度,也就是图像中每个像素可以显示的颜色数。位数越高,图像可以显示的颜色数就越多&…...

【单元测试】--基础知识
一、什么是单元测试 单元测试是软件开发中的一种测试方法,用于验证代码中的单个组件(通常是函数、方法或类)是否按预期工作。它旨在隔离和测试代码的最小单元,以确保其功能正确,提高代码质量和可维护性。单元测试通常…...
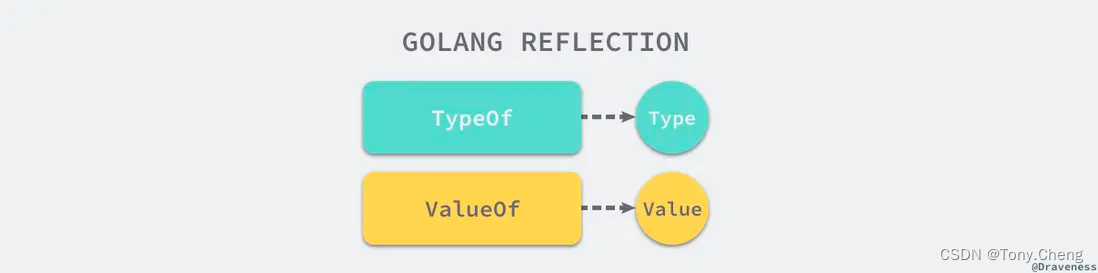
golang 反射机制
在 go 语言中,实现反射能力的是 reflect包,能够让程序操作不同类型的对象。其中,在反射包中有两个非常重要的 类型和 函数,两个函数分别是: reflect.TypeOfreflect.ValueOf 两个类型是 reflect.Type 和 reflect.Value…...
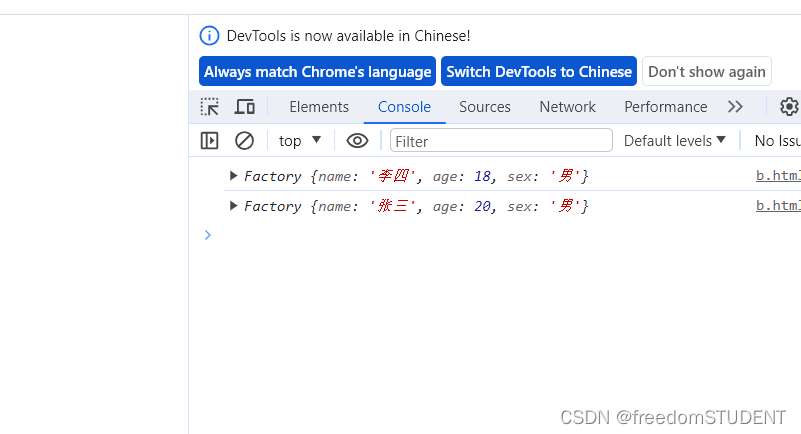
【Javascript】创建对象的几种方式
通过字面量创建对象 通过构造函数创建对象 Object()-------------构造函数 通过构造函数来实例化对象 给person注入属性 Factory工厂 this指向的是对象的本身使⽤new 实例化⼀个对象,就像⼯⼚⼀样...
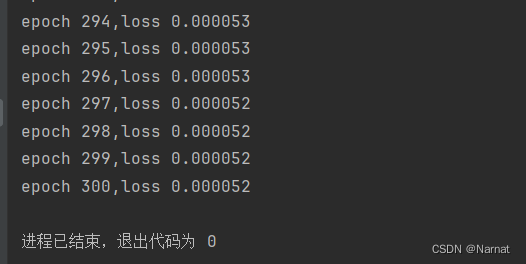
深度学习_3_实战_房价预测
梯度 实战 代码: # %matplotlib inline import random import torch import matplotlib.pyplot as plt # from d21 import torch as d21def synthetic_data(w, b, num_examples):"""生成 Y XW b 噪声。"""X torch.normal(0,…...

HCIA -- 动态路由协议之RIP
一、静态协议的优缺点: 缺点: 1、中大型网络配置量过大 2、不能基于拓扑的变化而实时的变化 优点: 1、不会额外暂用物理资源 2、安全问题 3、计算路径问题 简单、小型网络建议使用静态路由;中大型较复杂网络,建议使用…...

JS常用时间操作moment.js参考文档
Moment.js是一个轻量级的JavaScript时间库,它方便了日常开发中对时间的操作,提高了开发效率。日常开发中,通常会对时间进行下面这几个操作:比如获取时间,设置时间,格式化时间,比较时间等等。下面…...
:Seek 策略)
基于 FFmpeg 的跨平台视频播放器简明教程(九):Seek 策略
系列文章目录 基于 FFmpeg 的跨平台视频播放器简明教程(一):FFMPEG Conan 环境集成基于 FFmpeg 的跨平台视频播放器简明教程(二):基础知识和解封装(demux)基于 FFmpeg 的跨平台视频…...

超越AUC:DCA、NRI与IDI如何为临床预测模型提供更优的评估视角
1. 为什么AUC不够用?临床预测模型评估的痛点 我第一次做临床预测模型的时候,和大多数新手一样,盯着AUC值看了半天。0.75的AUC,看起来还不错?但当我拿着这个模型去找临床医生时,他们问的问题让我哑口无言&am…...
:从算法层到部署层的7类卡点与企业级应对清单)
AGI倒计时进入“工程化攻坚年”(2026–2027双年冲刺指南):从算法层到部署层的7类卡点与企业级应对清单
第一章:SITS2026圆桌:AGI何时到来 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026圆桌论坛上,来自DeepMind、OpenAI、中科院自动化所及东京大学的六位AGI研究者围绕“AGI何时到来”展开深度交锋。分歧远超预期:部分专…...

深入PyTorch源码:手把手调试grid_sample,搞懂-1到1的坐标映射与双线性插值细节
深入PyTorch源码:手把手调试grid_sample,搞懂-1到1的坐标映射与双线性插值细节 在计算机视觉和深度学习领域,图像变形和采样是许多任务的基础操作。PyTorch作为主流深度学习框架,提供了grid_sample这一强大但常被低估的函数。不同…...

银行数据中心基础设施建设与运维管理【2.1】
4. 4. 2 常用设备 UPS 系统中, 常用的设备和装置包括 UPS 输入配电柜、 UPS 主机、 UPS 输出配电柜和电池等。 1. UPS 输入配电柜 UPS 输入配电柜是为 UPS 主机提供交流配电的电器装置, 如图 4⁃38 所示。 图 4⁃38 UPS 输入配电柜 由于在上游的低压配电柜内已经有 UPS 系…...

3个关键步骤实现FanControl中文界面完美配置
3个关键步骤实现FanControl中文界面完美配置 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.Releases…...

2026最权威的十大降重复率网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 日益普及的人工智能生成内容的背景之下, 将文本被识别成AI创作的比率予以降低这一…...

别再傻傻地直接扫了!手把手教你用wafw00f在Windows和Kali上优雅地“试探”网站防火墙
优雅识别Web应用防火墙:wafw00f在Windows与Kali中的实战指南 当安全研究员面对一个陌生网站时,直接发起攻击就像蒙着眼睛走雷区——不仅危险,而且低效。真正的高手总会先做一件事:识别目标网站的防护体系。本文将带你用wafw00f这…...

单例管理化技术中的单例计划单例实施单例验证
单例管理化技术:计划、实施与验证的闭环实践 在软件开发中,单例模式因其全局唯一性和资源高效管理的特点被广泛应用。如何系统化地管理单例的生命周期,确保其正确性与稳定性?单例管理化技术通过“单例计划”“单例实施”“单例验…...

Vue 3定时任务配置终极指南:5分钟学会可视化Cron表达式生成
Vue 3定时任务配置终极指南:5分钟学会可视化Cron表达式生成 【免费下载链接】no-vue3-cron 这是一个 cron 表达式生成插件,基于 vue3.0 与 element-plus 实现 项目地址: https://gitcode.com/gh_mirrors/no/no-vue3-cron 还在为复杂的Cron表达式语法而烦恼吗…...
AMWaveTransition扩展应用:如何适配CollectionView与其他UI组件
AMWaveTransition扩展应用:如何适配CollectionView与其他UI组件 【免费下载链接】AMWaveTransition Custom transition between viewcontrollers holding tableviews 项目地址: https://gitcode.com/gh_mirrors/am/AMWaveTransition AMWaveTransition是一款为…...