一起学数据结构(11)——快速排序及其优化
上篇文章中,解释了插入排序、希尔排序、冒泡排序、堆排序及选择排序的原理及具体代码实现本片文章将针对快速排序,快速排序的几种优化方法、快速排序的非递归进行解释。
目录
1. 快速排序原理解析以及代码实现:
2. 如何保证相遇位置的值一定小于所对应的值:
3 优化最坏情况下快速排序的时间复杂度:
4. 对于快速排序代码书写格式的优化(挖坑法):
5. 对于快速排序代码的另一种书写格式优化(前后指针法):
1. 快速排序原理解析以及代码实现:
给定下面一个数组:

对于快速排序,其中心思想就是首先选取一个值,一般选择数组中最左边的数据,例如本数组中的。创建一个变量,来保存这个值所对应的下标,为了方便表达,将这个变量命名为
。
在确定了之后,分别从两头遍历数组,定义两个变量用于遍历数组,其中,
,
。
对于遍历数组的过程,需要分成两种情况来查看。其中,用于从左向右遍历数组,
用于从右向左遍历数组。当数组从左向右进行遍历时,一旦遇到比
所对应的值大的数据,则停
在这个数据的所对应的下标处。即:

当数组从右向左进行遍历时,一旦遇到比所对应的值小的数据,则
停在这个数据的所对应的下标处。即:
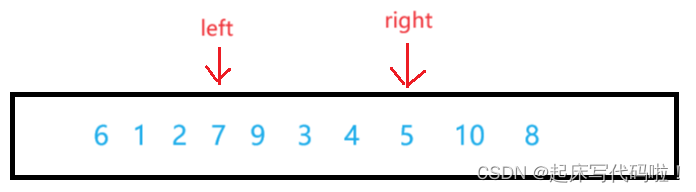
在找到了符合上面规定的值后,交换两个值在数组中的位置:
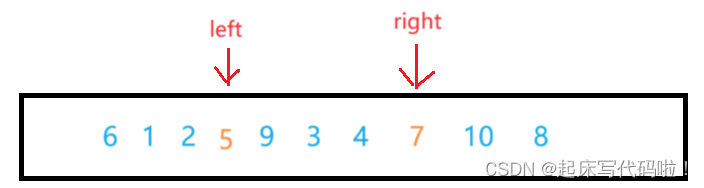
接着继续向下遍历,并且重复之前的动作。当,
相遇时,停止循环,此时的数组可以表示为:

最后,将所对应的值,与此时
或者
所对应的值进行一次交换,便完成了整个流程,用图形表示为:
在进行了上面一整套流程后,此时的数组虽然还是无序,但是可以观察到,所对应的值的右半部分的数组的值都大于
所对应的值。
左半部分数组的值都小于
所对应的值。
对于上述流程,可以用下面的代码进行表示:
//部分快排int PortSort(int* a, int left, int right){int key = left;while (left < right){//先从右边开始找小的while( left < right && a[right] >= a[key]){right--;}//再从左边开始找大的while(left < right && a[left] <= a[key]){left++;}//交换找到的值Swap(&a[left], &a[right]);}Swap(&a[key], &a[left]);return left;}对于上述给出的代码中,需要注意两个点:
1.在进行遍历数组寻找值的时候,必须先从右边开始遍历找小于所对应的值的数据,再从左边找大于
所对应的值的数据,对于原因将会在文章的后面进行探讨
2.在遍历寻找值的循环中,需要注意循环的两个条件,即
并且
,前面的条件是为了防止下面的两种情况:若从左向右遍历时,不存在比
对应的值大的数据,从右向左遍历时,不存在比
对应的值小的数据。以上两种情况均会导致
的范围超出数组下标的范围,对于第二个条件,如果不加上
,一旦在遍历的过程中,遇到了与
对应的值相等的值,会造成死循环。
完成了上述步骤后,数组依然是无序的,为了处理数组中其他的数据,需要利用到类似二叉树中递归的思想来实现:
对于上述数组,他的数组左半部分的数据都是小于所对应的值的,对于数组的右半部分的数据都是大于
所对应的值的,因此在下面的递归中,需要以
为分界线,
的左半部分为一组,右半部分为一组,对这两组值再次进行一次上面给出代码所对应的操作。
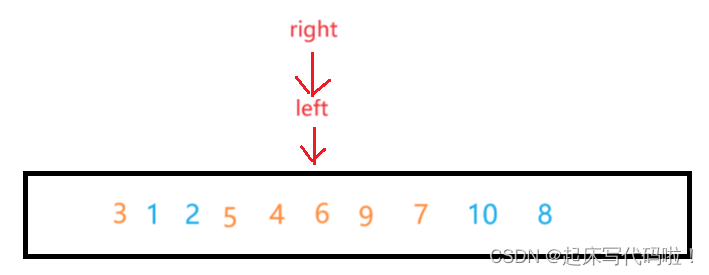
例如,对于左半部分:

此时所对应的值为
,按照上述代码进行操作后,数组可以表示为:
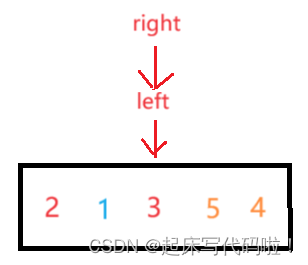
随后,再以为分界线,分出左右部分,对于左右部分进行上述代码的操作,对于左半部分,进行一次操作后,可以表示为:
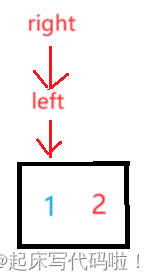
此时,再向下进行递归,的左半区间不存在,
的右半区间只有一个值。因此,对于上面两种情况,视作递归结束的条件。
上面只是展示了每一次的递归中,数组的左半部分的情况,对于右半部分原理相同,这里不再进行赘述。当作伴部分,右半部分的递归都结束后,整个区间会变成有序的区间,即:

对于上述递归,可以用下列代码进行实现:
void QuickSort(int* a, int begin, int end){if (begin >= end)return;int keyi = PortSort(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}测试函数如下:
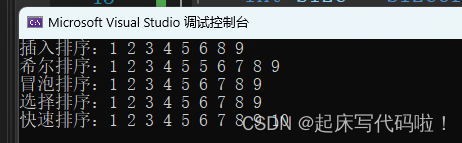
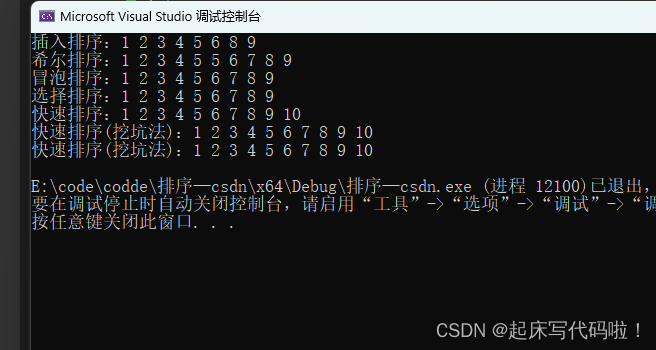
void TestQuickSort()
{int e[] = { 6,1,2,7,9,3,4,5,10,8 };int size = sizeof(e) / sizeof(int);QuickSort(e, 0,size-1);printf("快速排序:");ArrayPrint(e, size);
}结果如下:
2. 如何保证相遇位置的值一定小于 所对应的值:
所对应的值:
上面说到,在进行遍历寻找值这一步骤时,一定要先从右边开始向左遍历来找到比对应的值小的值,再从左边向右开始遍历,来寻找比
对应值大的值,原因如下:
例如对于上面给出的数组,对于相遇的前一步情况:
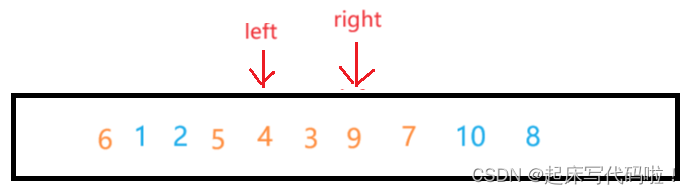
假设左边先进行遍历去寻找值,再从右边向左遍历来寻找值,则二者相遇的位置为:
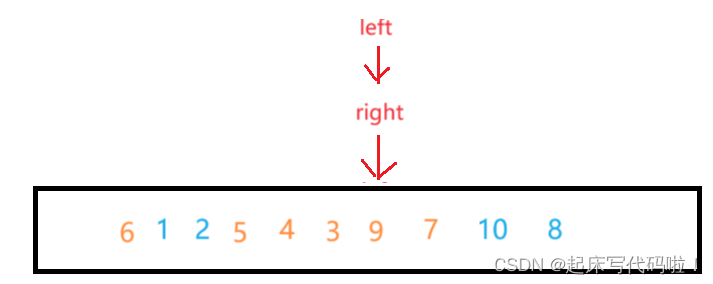
此时,如果按照上面代码的内容对对应的值和
位置对应的值进行交换,则:
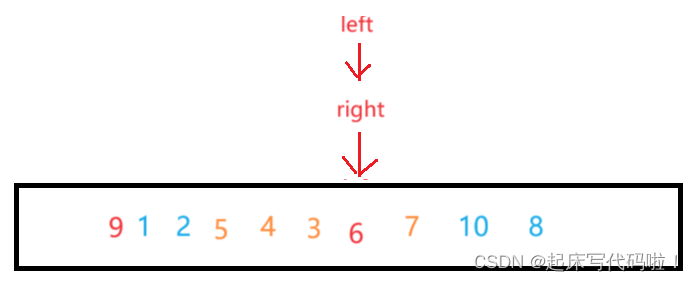
此时,比对应的值大的值不只是只存在右边。
这里需要注意,先从右边往左边遍历的,对应的是的位置在数组的左端。当
在数组的右端时,需要先从左边向右遍历。
3 优化最坏情况下快速排序的时间复杂度:
快速排序的时间复杂度一般都认为是,但是对于下面的一种情况:

前面说到,在快速排序中,当取左端的值时,应该优先从右边开始遍历,对于例子中这种完全升序,或者说大部分区间都是升序的情况,每次从右端进行遍历时,都必须遍历到数组的最左边。因此,对于一个有
个数据的这样的数组来说,从右向左遍历的次数为
次,这种情况下的快速排序的时间复杂度为
。为了优化这种情况,这里引入三数取中的方法。代码如下:因为原理就是简单的两数相比,所以不做过多解释:
//三数取中int GetMidi(int* a, int left, int right){int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[right] > a[mid]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}else//(a[left] > a[mid];{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}} 在构建了三数取中函数之后,需要对之前的快速排序代码进行修改。修改的部分为:首先在函数的开头创建一个变量
用于接受三数取中函数
的返回值。接着,让
对应的数值与后续
下标对应的数据(即最左端,或者最右端)用交换函数交换即可。
4. 对于快速排序代码书写格式的优化(挖坑法):
对于挖坑法,具体的实现原理如下:
首先还是确认以及
所对应的值,例如在下面的例子中
(注:为了方便演示原理,下面的情况不包括三数取中,但是在书写代码时,使用三数取中的方法与上方的使用发放相同)

首先确定一个,这里按照左端处理,创建一个变量
,令
,接着,确定
所在的下标就是第一个坑位。在确认了第一个坑位后,与上面的快速排序相同,都需要先从右端开始遍历来找到比
小的值,即:

随后,直接让所指向的值覆盖到
的位置,再让
指向的位置变成新的坑,即:

再从左边向右进行遍历,找到比小的值,并且让这个值覆盖到坑位
中,再令下图中的
成为新的坑位:

继续从右向左进行遍历,再从左向右遍历,直到相遇为止,即:
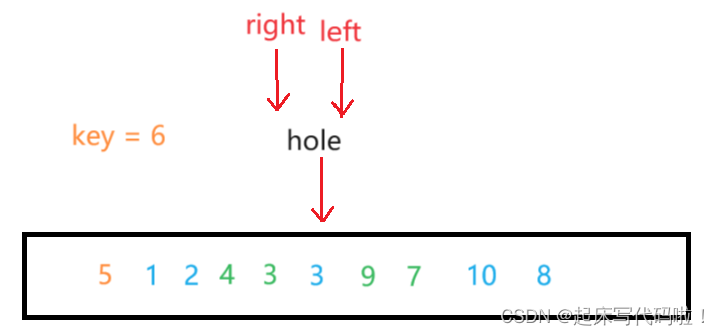
最后,再令二者相遇的位置赋值即可。然后再按照上面的思想递归即可。代码实现为:
//快排优化(挖坑法)int QuickDigSort(int* a, int begin, int end){int mid = GetMidi(a, begin, end);Swap(&a[begin], &a[mid]);int key = a[begin];int hole = begin;while (begin < end){//先从右边开始找小的while (begin < end && a[end] >= key){end--;}a[hole] = a[end];hole = end;//再从左边开始找大的while (begin < end && a[begin] <= key){begin++;}a[hole] = a[begin];hole = begin; }a[hole] = key;return hole; }void QuickSort2(int* a, int begin, int end){if (begin >= end)return;int keyi = QuickDigSort(a, begin, end);QuickSort2(a, begin, keyi - 1);QuickSort2(a, keyi + 1, end);}测试函数如下:
void TestQuickDigSort()
{int f[] = { 6,1,5,3,9,10,7,4,2,8 };int size = sizeof(f) / sizeof(int);QuickSort2(f, 0, size - 1);printf("快速排序(挖坑法):");ArrayPrint(f, size);
}运行结果如下:

5. 对于快速排序代码的另一种书写格式优化(前后指针法):
对于前后指针法,就是通过控制两个指针,这里分别命名为,
。通过控制这两个指针的动作时序来完成对于数组的排序,中心思想如下:
对于指针的作用,就是用来寻找比
小的值(
的意义与上面相同),对于指针
的动作时序,分为下面两种情况: 当
没有遇到比
大的值时,
一直紧跟着
,当
遇到比
大的值后,令
的位置处于这个值的前面。
继续令向后遍历,如果又找到了比
小的值,则交换这个值,与
后面的值。
例如对于下面的数组:
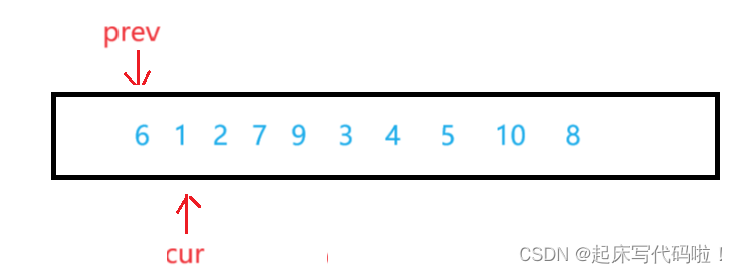
按照上面所说的思想,在没有遇到比
大的值时,
一直紧跟着
运动,即:
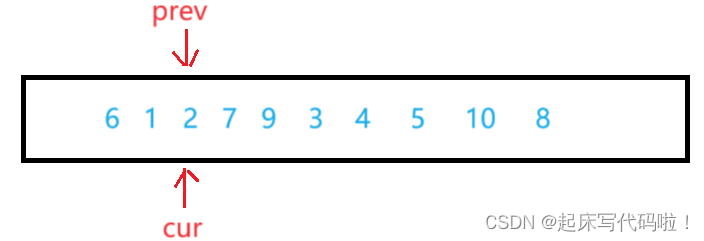
此时,再向下运动,遇到了比
大的值,令
继续向后遍历,直至找到比
小的值,令
停在比
大的值的前面,即:

再向下运动后,遇到了比
小的值,令
后面的值与比
小的值交换,即:

接着继续向下遍历,此时指向的位置为:
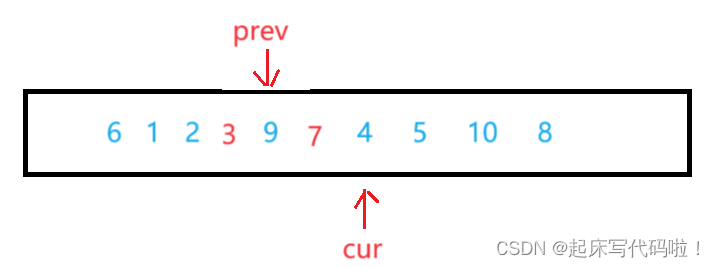
此时再对两个指针指向的值进行交换,即:
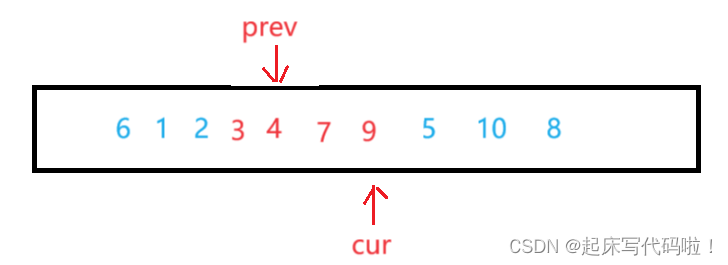
在遍历结束时,数组如下:
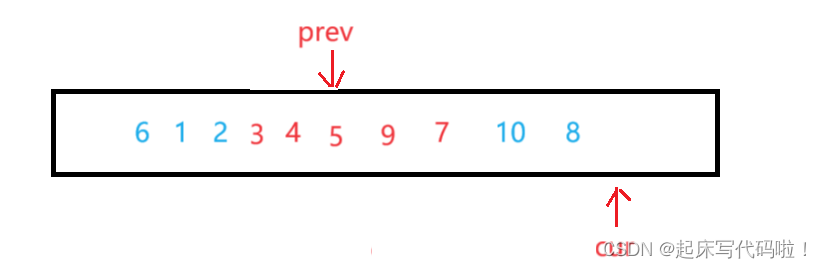
在结束遍历后,交换位置的值与
的值,即:
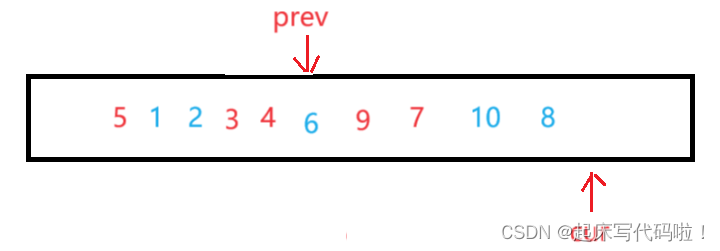
交换完后,比小的值都位于
左边,比
大的值都位于
右边。
总览上面的整个过程,当遇到了比大的值后,两个指针便开始拉开差距。此时
每次向后遍历,都会找到一个比
大的值,并且形成一个比
大的值的区间,在其期间,
一直保持不动,直到
遇到一个
小的值,
在向后指向第一个比
大的值并且交换,此后
每找到一个
小的值,都会把之前
大的值置换到后面,把
小的值置换到前面。
代码如下:
//快速排序(前后指针法)int QuickTailSort(int* a, int begin, int end){int key = begin;int prev = begin, cur = begin+1;while (cur <= end){if (a[cur] < a[key]){Swap(&a[++prev], &a[cur]);}cur++;;}Swap(&a[key], &a[prev]);return prev;}测试函数如下:
void TestQuickTailSort()
{int g[] = { 5,1,6,9,3,10,4,7,2,8 };int size = sizeof(g) / sizeof(int);QuickSort3(g, 0, size - 1);printf("快速排序(挖坑法):");ArrayPrint(g, size);
}运行结果如下:
相关文章:
一起学数据结构(11)——快速排序及其优化
上篇文章中,解释了插入排序、希尔排序、冒泡排序、堆排序及选择排序的原理及具体代码实现本片文章将针对快速排序,快速排序的几种优化方法、快速排序的非递归进行解释。 目录 1. 快速排序原理解析以及代码实现: 2. 如何保证相遇位置的值一…...
Docker开箱即用,开发码农加分项部署技术拿下!
目录 Docker概述 效果呈现 镜像 & 镜像仓库 & 容器 镜像 DockerHub 配置国内源加速 容器 简单的命令解读 Docker基础 常用命令 案例演示 数据卷 什么是数据卷 数据卷命令 演示环节 匿名数据卷 案例演示 自定义挂载位置 案例演示 自定义镜像 镜像结构 Dockerfile …...

计算机算法分析与设计(16)---Dijkstra算法(含C++代码)
文章目录 一、知识概述1.1 算法描述1.2 例题分析 二、代码编写 一、知识概述 1.1 算法描述 1.2 例题分析 二、代码编写 输入: 第一行:图的顶点数n 第二行:图的边数k 第三行:算法起点begin,算法终点end 接下来…...
小团队之间有哪些好用免费的多人协同办公软件
在小团队协作中,选择适合的多人协同办公软件是提高工作效率和团队协作的重要一环。幸运的是,市场上有许多大多数功能都免费的多人协同办公软件,为小团队提供了强大的协作功能和便捷的工作环境。 在本文中,我将根据自己多年的在线…...
codeforces (C++ Morning)
题目: 翻译: 思路: 1、要将四位数显示,每次操作可以选择移动光标(移动到相邻的位置)或者显示数字,计算最少需要多少次操作。 2、用flag表示当前光标位置,sum为记录操作次数&#…...

Oracle数据库备份与恢复exp/imp命令
exp导出工具将数据库中数据备份压缩成一个二进制系统文件,可以在不同OS间迁移 可以导出用户所有对象以及对象中的数据;导出用户所有表或者指定的表;导出数据库中所有对象。 imp所执行的步骤: (1) create table --新建表 (2) inser…...

何为心理承受能力?如何提高心理承受能力?
心理承受能力,也可以理解为人的抗压能力,指的是承受压力,承受逆境的能力。人的一生其实就是在不断的解决问题,见招拆招,遇到问题解决问题,在我们不断学习和锻炼的过程中,提高了我们解决问题的效…...

Seata学习
Seata Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。 官网地址:https://seata.io/zh-cn/index.html 为什么会产生分布式事务? 示例:用户下单后需要创建订单,同时…...
)
探索数据结构世界之排序篇章(超级详细,你想看的都有)
-文章开头必看 1.!!!本文排序默认都是排升序 2.排序是否稳定值指指排完序之后相同数的相对位置是否改变 3.代码相关解释我都写在注释中了,方便对照着看 1.插入排序1.1直接插入排序1.2希尔排序1.2.1单趟1.2.2多趟基础版——排完一…...

偶数科技发布实时湖仓数据平台Skylab 5.3版本
近日, 偶数发布了最新的实时湖仓数据平台 Skylab 5.3 版本。Skylab包含七大产品,分别为云原生分布式数据库 OushuDB、数据分析与应用平台 Kepler、数据资产管理平台 Orbit、自动化机器学习平台 LittleBoy、数据工厂 Wasp、数据开发与调度平台 Flow、系统…...

vant组件是使用?
首先 在vue项目中使用的时候 要先下载组件 使用npm安装 # Vue 3 项目,安装最新版 Vant npm i vant# Vue 2 项目,安装 Vant 2 npm i vantlatest-v2 使用yarn安装或pnpm # 通过 yarn 安装 yarn add vant# 通过 pnpm 安装 pnpm add vant 在框架中引入即…...

CSP-S 2023 游记
开题,首先先把除了第三题的所有题看了一遍。(由于第三题太长,先放着后面再看) 决定顺序先把一二题做了。 看第一题,小小思考了一手,发现暴力可做,于是飞速码完,小小对拍一下&#…...
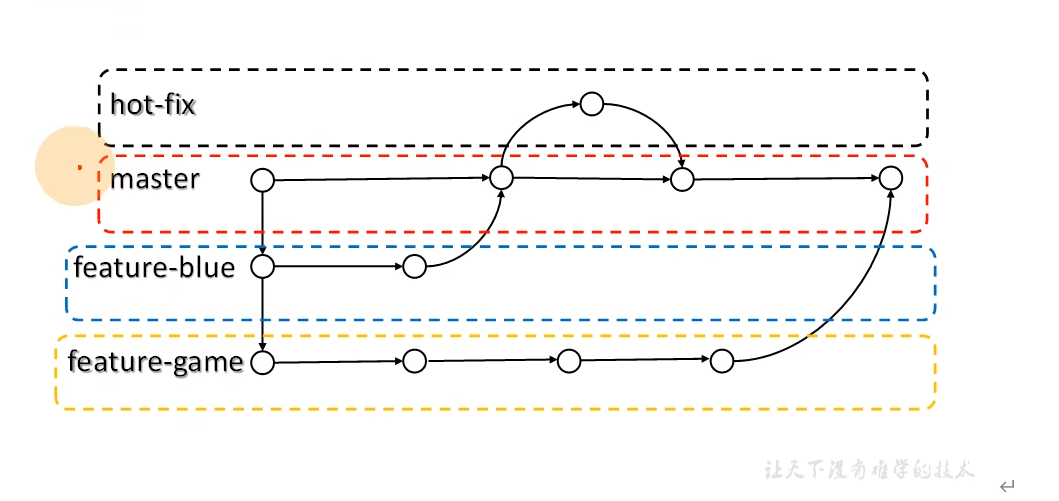
关于Git的入门教程(附GitHub和Gitee的使用方法)
一. Git 概述 Git是一个免费的、开源的分布式版本控制系统,可以快速高效地处理从小型到大型的各种项目。Git易于学习、占地面积小、性能极快。它具有廉价的本地库,方便的暂存区域和多个工作流分支等特性。其性能优于Subversion、CVS、Perforce和ClearCas…...
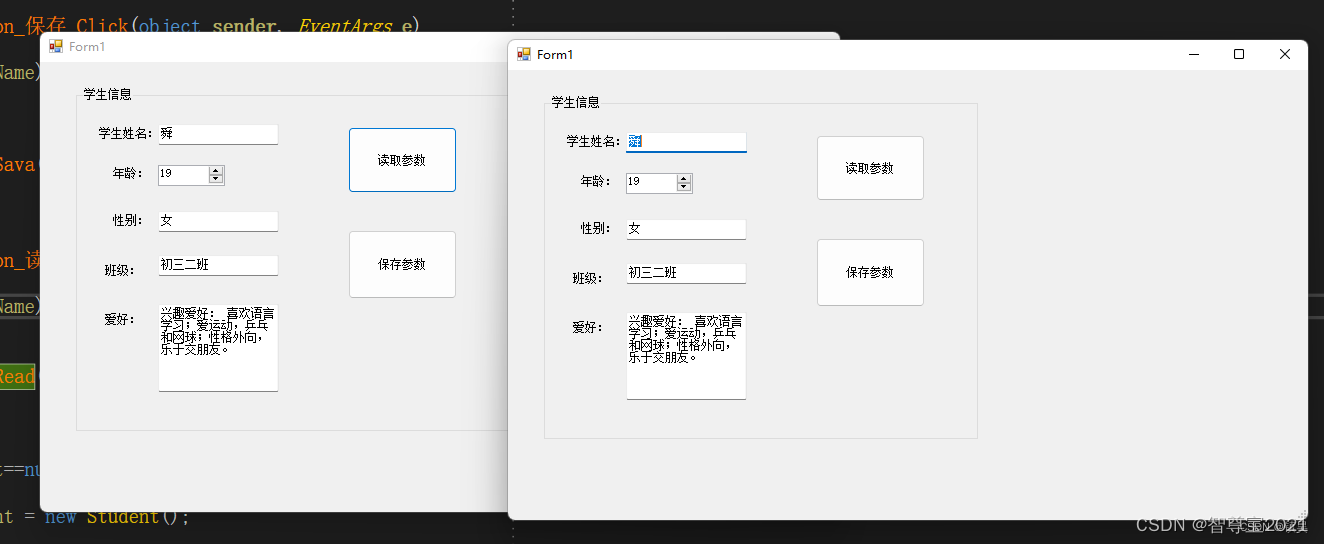
C# winform如何实现数据的保存和读取
在c#winform中我们在写程序时,经常需要进行数据处理,那么数据如何保存和读取(下面我们通过序列化和反序列化的方式来实现) 第一步: 我们建立一个winform窗体 第二步: 构建一个外部实体类(Student类) 第…...

【Java基础面试四十一】、说一说你对static关键字的理解
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:说一说你对static关键字…...
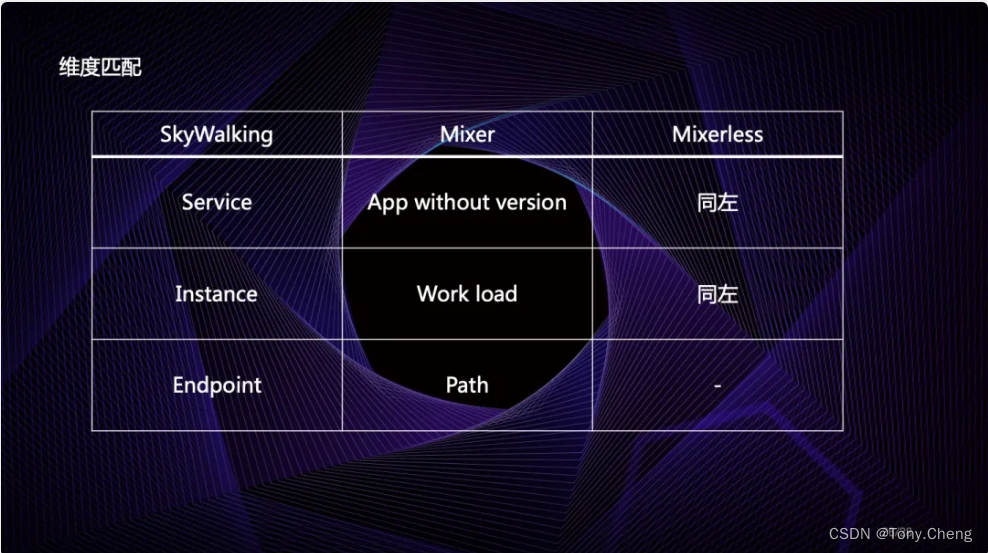
istio介绍(二)
5. kubesphere istio使用 5.1 整体架构 ks-account 提供用户、权限管理相关的 APIks-apiserver 整个集群管理的 API 接口和集群内部各个模块之间通信的枢纽,以及集群安全控制ks-apigateway 负责处理服务请求和处理 API 调用过程中的所有任务ks-console 提供 KubeSp…...

中文编程开发语言工具构件说明:屏幕截取构件的编程操作
屏幕截取 用于截取指定区域的图像。 图 标: 构件类型:不可视 重要属性 l 截取类型 枚举型,设置在截取屏幕时的截取类型。包括:全屏幕、指定区域、活动窗口三种。当全屏幕截取时相当于执行了硬拷屏(PrintScre…...
selenium多窗口、多iframe切换、alert、3种等待
1、多标签/多窗口之间的切换 场景: 在页面操作过程中有时候点击某个链接会弹出新的窗口,这时就需要切换到新打开的窗口上进行操作。这种情况下,需要识别多标签或窗口的情况。 操作方法: switch_to.window()方法:切换…...

物联网AI MicroPython传感器学习 之 RTC时钟模块
学物联网,来万物简单IoT物联网!! 一、产品简介 DS1302 是DALLAS 公司推出的涓流充电时钟芯片,内含有一个实时时钟/日历和31字节静态RAM,实时时钟/日历电路提供秒、分、时、日、周、月、年的信息,每月的天数…...
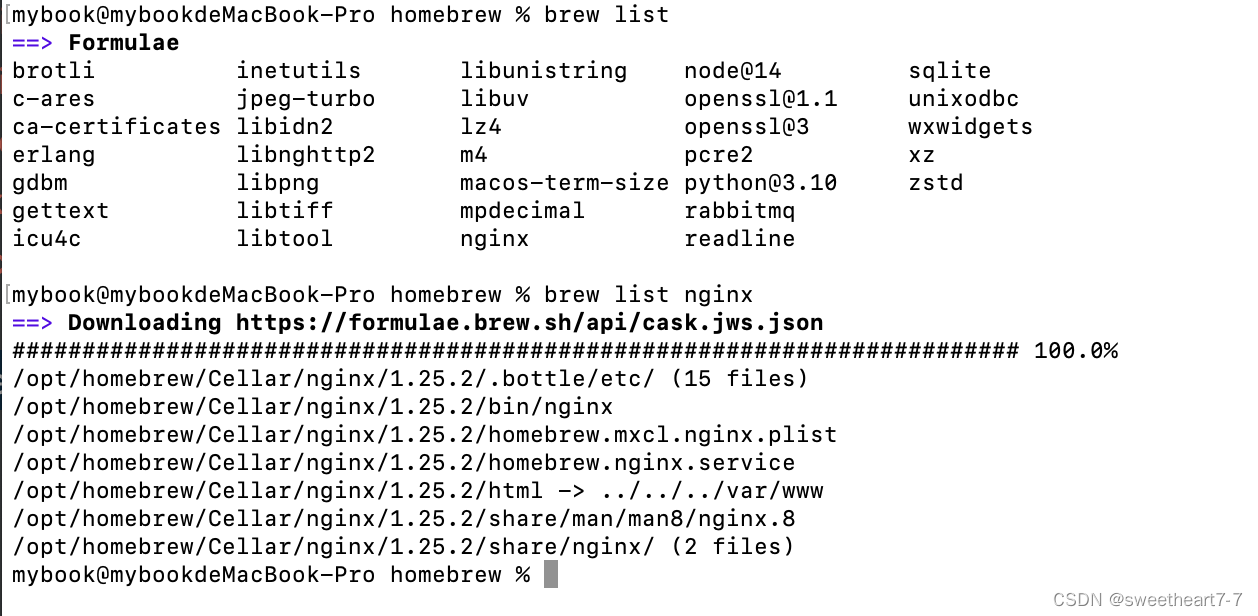
Mac安装nginx(Homebrew)
查看需要安装 nginx 的信息 brew info nginxDocroot 默认为 /usr/local/var/www 在 /opt/homebrew/etc/nginx/nginx.conf 配置文件中默认端口被配置为8080,从而使 nginx 运行时不需要加 sudo nginx将在 /opt/homebrew//etc/nginx/servers/ 目录中加载所有文件 …...
)
告别接线恐惧!用STM32CubeMX+Keil5快速搞定Ra-01S LoRa模块数据收发(附完整工程)
STM32CubeMXKeil5极速开发指南:Ra-01S LoRa模块数据收发实战 在物联网设备爆发式增长的今天,LoRa技术凭借其远距离、低功耗的特性成为LPWAN领域的重要解决方案。而作为嵌入式开发者,如何快速实现LoRa模块与STM32的集成,往往决定着…...

SmartEnum扩展包深度探索:AutoFixture、GuardClauses等工具的最佳实践
SmartEnum扩展包深度探索:AutoFixture、GuardClauses等工具的最佳实践 【免费下载链接】SmartEnum A base class for quickly and easily creating strongly typed enum replacements in C#. 项目地址: https://gitcode.com/gh_mirrors/smar/SmartEnum Smart…...

AssetRipper终极指南:如何轻松提取Unity游戏资源的完整教程
AssetRipper终极指南:如何轻松提取Unity游戏资源的完整教程 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 还在为无法获取…...

SITS2026前沿发布:如何用AI在3秒内生成高精准度代码告警?附可落地的Prompt工程模板
第一章:SITS2026前沿发布:如何用AI在3秒内生成高精准度代码告警?附可落地的Prompt工程模板 2026奇点智能技术大会(https://ml-summit.org) SITS2026正式开源了CodeGuardian v3.1——一个面向生产级代码静态分析的轻量级AI推理引擎ÿ…...

Nacos注册中心实战:Java项目中的服务发现与管理
Nacos注册中心实战:Java项目中的服务发现与管理 前言 随着微服务架构的广泛应用,服务的高效注册与动态发现成为分布式系统的基础设施建设重点。Nacos 作为一款易用且功能强大的注册中心和配置中心,为 Java 项目提供了灵活的服务治理能力。本…...

Unity3D超高清照片墙实战:如何突破8192x8192分辨率限制并稳定运行24小时?
Unity3D超高清照片墙实战:突破8192x8192分辨率限制与24小时稳定运行方案 当我在上海某商业综合体首次看到那块横跨三层楼的巨型互动照片墙时,立刻被其视觉冲击力震撼——直到客户递给我一份96004320分辨率的项目需求书。这个数字让我手指一颤:…...

【maaath】Flutter for OpenHarmony 跨平台实战:集成图片加载与缓存优化方案
Flutter for OpenHarmony 跨平台实战:集成图片加载与缓存优化方案作者:maaath欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net前言 在移动应用开发领域,图片资源的加载与缓存一直是性能优化的关键环节。尤…...

SeleniumBase + Python 自动化工作流优化
在自动化工作流的过程中,如何高效处理网页上的下拉菜单选择问题是许多开发者遇到的挑战。今天,我将结合 SeleniumBase 和 Python 的实例,探讨如何优化自动化脚本以应对网页表单中的下拉选择操作。 背景 在使用 SeleniumBase 进行自动化测试时,我们经常需要与各种类型的表…...

glogg实战指南:跨平台高效日志分析解决方案深度解析
glogg实战指南:跨平台高效日志分析解决方案深度解析 【免费下载链接】glogg A fast, advanced log explorer. 项目地址: https://gitcode.com/gh_mirrors/gl/glogg 面对海量日志文件时,传统文本编辑器和命令行工具的局限性日益凸显:内…...

CN3130 可用太阳能板供电的纽扣电池充电管理芯片
概述: CN3130是可以用太阳能板供电的可充电纽扣电池充电管理芯片。该器件内部包括功率晶体管,应 用时不需要外部的电流检测电阻和阻流二极管。 内部的充电电流自适应模块能够根据输入电源的电流输出能力自动调整充电电流,用户不需要考 虑最坏…...