【UCAS自然语言处理作业一】利用BeautifulSoup爬取中英文数据,计算熵,验证齐夫定律
文章目录
- 前言
- 中文
- 数据爬取
- 爬取界面
- 爬取代码
- 数据清洗
- 数据分析
- 实验结果
- 英文
- 数据爬取
- 爬取界面
- 动态爬取
- 数据清洗
- 数据分析
- 实验结果
- 结论
前言
- 本文分别针对中文,英文语料进行爬虫,并在两种语言上计算其对应的熵,验证齐夫定律
github: ShiyuNee/python-spider (github.com)
中文
数据爬取
本实验对四大名著的内容进行爬取,并针对四大名著的内容展开中文文本分析,统计熵,验证齐夫定律
- 爬取网站: https://5000yan.com/
- 以水浒传的爬取为例展示爬取过程
爬取界面

-
我们需要通过本页面,找到水浒传所有章节对应的
url,从而获取每一个章节的信息 -
可以注意到,这里每个章节都在
class=menu-item的li中,且这些项都包含在class=panbai的ul内,因此,我们对这些项进行提取,就能获得所有章节对应的url -
以第一章为例,页面为

- 可以看到,所有的正文部分都包含在
class=grap的div内,因此,我们只要提取其内部所有div中的文字,拼接在一起即可获得全部正文
- 可以看到,所有的正文部分都包含在
爬取代码
def get_book(url, out_path):root_url = urlheaders={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36'} # chrome浏览器page_text=requests.get(root_url, headers=headers).content.decode()soup1=BeautifulSoup(page_text, 'lxml')res_list = []# 获取所有章节的urltag_list = soup1.find(class_='paiban').find_all(class_='menu-item')url_list = [item.find('a')['href'] for item in tag_list]for item in url_list: # 对每一章节的内容进行提取chapter_page = requests.get(item, headers=headers).content.decode()chapter_soup = BeautifulSoup(chapter_page, 'lxml')res = ''try:chapter_content = chapter_soup.find(class_='grap')except:raise ValueError(f'no grap in the page {item}')chapter_text = chapter_content.find_all('div')print(chapter_text)for div_item in chapter_text:res += div_item.text.strip()res_list.append({'text': res})write_jsonl(res_list, out_path)
- 我们使用
beautifulsoup库,模拟Chrome浏览器的header,对每一本书的正文内容进行提取,并将结果保存到本地
数据清洗
-
因为文本中会有括号,其中的内容是对正文内容的拼音,以及解释。这些解释是不需要的,因此我们首先对去除括号中的内容。注意是中文的括号
def filter_cn(text):a = re.sub(u"\\(.*?)|\\{.*?}|\\[.*?]|\\【.*?】|\\(.*?\\)", "", text)return a -
使用结巴分词,对中文语句进行分词
def tokenize(text):return jieba.cut(text) -
删除分词后的标点符号项
def remove_punc(text):puncs = string.punctuation + "“”,。?、‘’:!;"new_text = ''.join([item for item in text if item not in puncs])return new_text -
对中文中存在的乱码,以及数字进行去除
def get_cn_and_number(text):return re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039])","",text)
整体流程代码如下所示
def collect_data(data_list: list):voc = defaultdict(int)for data in data_list:for idx in range(len(data)):filtered_data = filter_cn(data[idx]['text'])tokenized_data = tokenize(filtered_data)for item in tokenized_data:k = remove_punc(item)k = get_cn_and_number(k)if k != '':voc[k] += 1return voc
数据分析
针对收集好的字典类型数据(key为词,value为词出现的次数),统计中文的熵,并验证齐夫定律
-
熵的计算
def compute_entropy(data: dict):cnt = 0total_num = sum(list(data.values()))print(total_num)for k, v in data.items():p = v / total_numcnt += -p * math.log(p)print(cnt) -
齐夫定律验证(由于词项比较多,为了展示相对细节的齐夫定律图,我们仅绘制前200个词)
def zip_law(data: dict):cnt_list = data.values()sorted_cnt = sorted(enumerate(cnt_list), reverse=True, key=lambda x: x[1])plot_y = [item[1] for item in sorted_cnt[:200]]print(plot_y)x = range(len(plot_y))plot_x = [item + 1 for item in x]plt.plot(plot_x, plot_y)plt.show()
实验结果
-
西游记
- 熵:8.2221(共364221种token)

-
西游记+水浒传
-
熵:8.5814(共836392种token)

-
-
西游记+水浒传+三国演义
-
熵:8.8769(共1120315种token)

-
-
西游记+水浒传+三国演义+红楼梦
-
熵:8.7349(共1585796种token)

-
英文
数据爬取
本实验对英文读书网站上的图书进行爬取,并针对爬取内容进行统计,统计熵,验证齐夫定律
- 爬取网站: Bilingual Books in English | AnyLang
- 以The Little Prince为例介绍爬取过程
爬取界面

-
我们需要通过本页面,找到所有书对应的
url,然后获得每本书的内容 -
可以注意到,每本书的
url都在class=field-content的span中,且这些项都包含在class=ajax-link的a内,因此,我们对这些项进行提取,就能获得所有书对应的url -
以The Little Prince为例,页面为

- 可以看到,所有的正文部分都包含在
class=page n*的div内,因此,我们只要提取其内部所有div中的<p> </p>内的文字,拼接在一起即可获得全部正文
- 可以看到,所有的正文部分都包含在
动态爬取
需要注意的是,英文书的内容较少,因此我们需要爬取多本书。但此页面只有下拉后才会加载出新的书,因此我们需要进行动态爬取
-
使用
selenium加载Chrome浏览器,并模拟浏览器下滑操作,这里模拟5次def down_ope(url):driver = webdriver.Chrome() # 根据需要选择合适的浏览器驱动 driver.get(url) # 替换为你要爬取的网站URL for _ in range(5):driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(5)return driver -
将
driver中的内容传递给BeautifulSoupsoup1=BeautifulSoup(driver.page_source, 'lxml')books = soup1.find_all(class_ = 'field-content')
整体代码为
def get_en_book(url, out_dir):root_url = url + '/en/books/en'headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36'} # chrome浏览器driver = down_ope(root_url)soup1=BeautifulSoup(driver.page_source, 'lxml')books = soup1.find_all(class_ = 'field-content')book_url = [item.a['href'] for item in books]for item in book_url:if item[-4:] != 'read':continueout_path = out_dir + item.split('/')[-2] + '.jsonl'time.sleep(2)try:book_text=requests.get(url + item, headers=headers).content.decode()except:continuesoup2=BeautifulSoup(book_text, 'lxml')res_list = []sec_list = soup2.find_all('div', class_=re.compile('page n.*'))for sec in sec_list:res = ""sec_content = sec.find_all('p')for p_content in sec_content:text = p_content.text.strip()if text != '':res += textprint(res)res_list.append({'text': res})write_jsonl(res_list, out_path)
数据清洗
-
使用
nltk库进行分词def tokenize_en(text):sen_tok = nltk.sent_tokenize(text)word_tokens = [nltk.word_tokenize(item) for item in sen_tok]tokens = []for temp_tokens in word_tokens:for tok in temp_tokens:tokens.append(tok.lower())return tokens -
对分词后的token删除标点符号
def remove_punc(text):puncs = string.punctuation + "“”,。?、‘’:!;"new_text = ''.join([item for item in text if item not in puncs])return new_text -
利用正则匹配只保留英文
def get_en(text):return re.sub(r"[^a-zA-Z ]+", '', text)
整体流程代码如下
def collect_data_en(data_list: list):voc = defaultdict(int)for data in data_list:for idx in range(len(data)):tokenized_data = tokenize_en(data[idx]['text'])for item in tokenized_data:k = remove_punc(item)k = get_en(k)if k != '':voc[k] += 1return voc
数据分析
数据分析部分与中文部分的分析代码相同,都是利用数据清洗后得到的词典进行熵的计算,并绘制图像验证齐夫定律
实验结果
-
10本书(1365212种token)
- 熵:6.8537

-
30本书(3076942种token)
-
熵:6.9168

-
-
60本书(4737396种token)
-
熵:6.9164

-
结论
从中文与英文的分析中不难看出,中文词的熵大于英文词的熵,且二者随语料库的增大都有逐渐增大的趋势。
- 熵的数值与
tokenizer,数据预处理方式有很大关系 - 不同结论可能源于不同的数据量,
tokenizer,数据处理方式
我们分别对中英文在三种不同数据量熵对齐夫定律进行验证
-
齐夫定律:一个词(字)在语料库中出现的频率,与其按照出现频率的排名成反比
-
若齐夫定律成立
- 若我们直接对排序(
Order)与出现频率(Count)进行绘制,则会得到一个反比例图像 - 若我们对排序的对数(
Log Order)与出现频率的对数(Log Count)进行绘制,则会得到一条直线 - 这里由于长尾分布,为了方便分析,只对出现次数最多的
top 1000个token进行绘制
- 若我们直接对排序(
-
从绘制图像中可以看出,齐夫定律显然成立
相关文章:
【UCAS自然语言处理作业一】利用BeautifulSoup爬取中英文数据,计算熵,验证齐夫定律
文章目录 前言中文数据爬取爬取界面爬取代码 数据清洗数据分析实验结果 英文数据爬取爬取界面动态爬取 数据清洗数据分析实验结果 结论 前言 本文分别针对中文,英文语料进行爬虫,并在两种语言上计算其对应的熵,验证齐夫定律github: ShiyuNee…...

微信小程序之个人中心授权登录
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《Vue.js使用》 ⛺️ 越努力 ,越幸运。 1.了解微信授权登录 微信登录官网: 小程序登录https://developers.weixin.qq.com/miniprogram/d…...
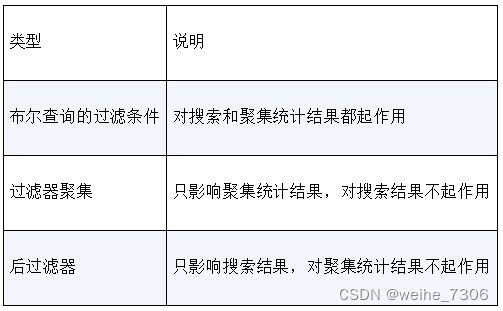
Elasticsearch的聚集统计,可以进行各种统计分析
说明: Elasticsearch不仅是一个大数据搜索引擎,也是一个大数据分析引擎。它的聚集(aggregation)统计的REST端点可用于实现与统计分析有关的功能。Elasticsearch提供的聚集分为三大类。 度量聚集(Metric aggregation):度量聚集可以用于计算搜…...

Webpack 理解 input output 概念
一、介绍 如果还没用过 Webpack 请先阅读 Webpack & 基础入门 再回头看本文。 Webpack 的核心只做两件事,输入管理(Input Management)和输出管理(Output Management),什么花里胡哨的插件和配置都离不…...

【字符函数】
✨博客主页:小钱编程成长记 🎈博客专栏:进阶C语言 🎈相关博文:字符串函数(一)、字符串函数(二) 字符函数 字符函数1.字符分类函数1.1 iscntrl - 判断是否是控制字符1.2 i…...
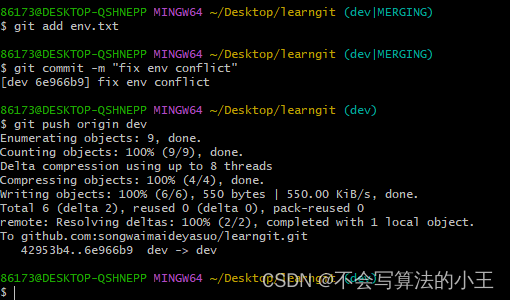
git创建与合并分支
文章目录 创建与合并分支分支管理的概念实际操作 解决冲突分支管理策略Bug分支Feature分支多人协作 创建与合并分支 分支管理的概念 分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码…...

【电子通识】USB TYPE-A 2.0/3.0连接器接口
基础知识 USB TYPE-A连接器又可称为USB-A,现在不少PC、PC周边、手机充电器等等都依然采用了这种扁平的矩形接口,是目前普及度最高的USB接口了。 USB-A亦有分为插头与插座。常见的USB-A数据线的A端就是插头,而充电器上的则是插座。插头和插座…...

org.apache.sshd的SshClient客户端 连接服务器执行命令 示例
引入依赖 <dependency><groupId>org.apache.sshd</groupId><artifactId>sshd-core</artifactId><version>2.9.1</version></dependency>示例代码,可以直接执行,也可以做替换命令、维护session等修改 p…...

STM32 裸机编程 03
MCU 启动和向量表 当 STM32F429 MCU 启动时,它会从 flash 存储区最前面的位置读取一个叫作“向量表”的东西。“向量表”的概念所有 ARM MCU 都通用,它是一个包含 32 位中断处理程序地址的数组。对于所有 ARM MCU,向量表前 16 个地址由 ARM …...

Python ‘list‘ object is not callable错误
我尝试着解决“TypeError: ‘list’ object is not callable”这个错误。在Python编程中,我有时会遇到这个错误。这个错误通常是由于我错误地尝试像函数一样调用一个列表对象。为了解决这个问题,我需要找出错误发生的具体位置,然后进行修正。…...

原生php 实现redis登录五次被禁,隔天再登陆
<?php /*** Created by PhpStorm.* User: finejade* Date: 2023-10-18* Time: 11:08*/ session_start();include_once(header.php); include_once(connect.php); include_once(common.php); include_once(redis.php); try {// 常量 用户错误次数记录define("USER_LOGI…...

24. Kernel 4.19环境下,Cilium网络仍然需要使用iptables
在设计这套容器集群服务时,我从原来的k3s架构中分离出一个问题,那就是容器网络插件应该选择哪个。因为我设计的目标是给服务器领域使用的容器引擎,所以我就不需要考虑太多边缘IOT设备的情况,直接拉满技能找了cilium。cilium借助内核ebpf技术的出现,让我看到了网络性能更好…...
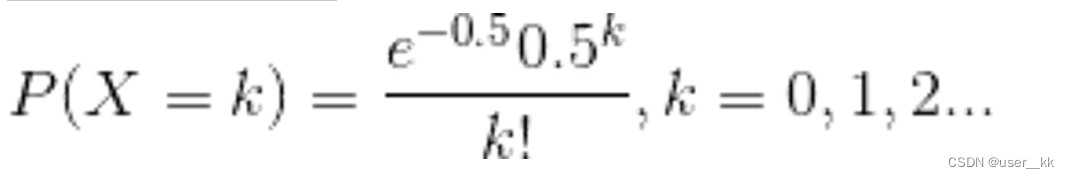
java中的容器(集合),HashMap底层原理,ArrayList、LinkedList、Vector区别,hashMap加载因子0.75原因
一、java中的容器 集合主要分为Collection和Map两大接口;Collection集合的子接口有List、Set;List集合的实现类有ArrayList底层是数组、LinkedList底层是双向非循环列表、Vector;Set集合的实现类有HashSet、TreeSet;Map集合的实现…...

Linux Server 终止后立即重启报错 bind error: Address already in use
先启动Server,再启动Client,然后使用CtrlC关闭Server,马上再运行Server,会得到以下结果: bind error: Address already in use这是因为,虽然Server的应用程序终止了,但TCP协议层的连接并没有完全…...

【Python 千题 —— 基础篇】分解数据
题目描述 题目描述 编写一个程序,输入一个类似 “233,234,235” 格式的字符串,然后提取字符串中的数字,将这些数字存储在列表中,并输出该列表。在这里,我们使用 eval 函数来解析字符串中的数字。 输入描述 输入一个…...

【C++】C++11新特性之右值引用与移动语义
文章目录 一、左值与左值引用二、右值与右值引用三、 左值引用与右值引用比较四、右值引用使用场景和意义1.左值引用的短板2.移动构造和移动赋值3.STL中右值引用的使用 五、万能引用与完美转发1.万能引用2.完美转发 一、左值与左值引用 在C11之前,我们把数据分为常…...

家庭燃气表微信抄表识别系统
1.背景需求 目前家里燃气度数的读数上报,每个月在社区微信群里面将手机拍摄的燃气表读数截图(加住址信息水印),发到群里给抄表员。 2.总体设计 设计目标 功能一:手机上随时可以远程采集读数图片(自动加住…...

EF执行迁移时提示provider: SSL Provider, error: 0 - 证书链是由不受信任的颁发机构颁发的
ef在执行时提示provider: SSL Provider, error: 0 - 证书链是由不受信任的颁发机构颁发的。 只需要在数据库链接字符串后增加EncryptTrue;TrustServerCertificateTrue;即可 再次执行...

视频标注的两个主要方法
视频标注技术 单一图像法 在自动化工具面世之前,视频标注效率不高。各公司使用单一图像法提取视频中的所有帧,然后使用标准图像标注技术将它们作为图像来标注。在30fps的视频中,每分钟有1800帧。这个过程没有利用视频标注的优势,…...

学成在线第一天-项目介绍、项目的搭建、开发流程以及相关面试题
目录 一、项目介绍 二、项目搭建 三、开发流程 四、相关面试题 五、总结 一、项目介绍 背景 业务 技术 背景:首先是整个这个行业的背景 然后基于这个行业的背景引出当前项目的背景 业务:功能模块 功能业务流程 技术:整体架构&am…...

python读取excel数据的详细教学
在Python中读取Excel数据是一个常见的数据处理任务。通过pandas库,你可以轻松地读取、分析和操作Excel文件。以下是如何使用Python读取Excel数据的详细讲解。一、准备工作在开始之前,确保已安装pandas库以及Excel文件处理的依赖库openpyxl。你可以使用以…...

开源Wiki新选择:Outline私有化部署与深度体验指南
1. 为什么选择Outline作为Wiki解决方案 作为一个长期使用Confluence和EverNote的老用户,我深知选择一款合适的知识管理工具有多重要。Outline最初吸引我的是它简洁现代的界面设计,但真正让我决定迁移的是它独特的定位——既保留了传统Wiki的内容组织能力…...

LFM2.5-1.2B-Thinking-GGUF从零开始:无Python环境依赖的纯二进制GGUF部署方案
LFM2.5-1.2B-Thinking-GGUF从零开始:无Python环境依赖的纯二进制GGUF部署方案 1. 平台简介与核心优势 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该镜像采用创新的纯二进制部署方案,完全摆脱…...

YOLO11从零到部署:VOC数据集处理与模型训练全流程详解
1. YOLO11与VOC数据集入门指南 第一次接触YOLO11和VOC数据集时,我也被各种专业术语搞得晕头转向。现在回想起来,其实它们并没有想象中那么复杂。YOLO11是Ultralytics团队推出的最新目标检测模型,相比前代YOLOv8,它在小目标检测和推…...

深度学习模型效率评估:计算量、参数量与推理时间的实战解析
1. 为什么需要关注模型效率? 当你第一次训练深度学习模型时,可能会被准确率冲昏头脑。记得我刚开始做图像分类项目时,用ResNet50在测试集上刷到了95%的准确率,兴奋地准备部署上线。结果在实际应用中,服务器直接崩溃——…...

MSP430与MMC/SD卡SPI通信实现与优化
1. MSP430与MMC/SD卡SPI通信概述在嵌入式系统开发中,外扩存储设备是常见需求。MSP430系列微控制器通过SPI接口与MMC/SD卡通信,为数据采集、日志记录等应用提供了可靠的存储解决方案。SPI(Serial Peripheral Interface)作为一种同步…...

2025届必备的十大降重复率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 通过降低AIGC率,也就是要减少文本里能被认定成是人工智能生成内容的一些特征。这…...

【Unity】解决UGUI的Button无法点击/点击无反应的排查方案
1.UGUI与用户实现交互的基本原理当用户触摸/点击屏幕的时候,会从屏幕接触的那个点,从相机发射一条射线,如果射线中途有UI元素会阻挡射线(Raycast Target),则会根据实际情况执行UI交互的行为。我们可以根据这…...

算法训练营第四天|203. 移除链表元素
本题最关键是要理解 虚拟头结点的使用技巧,这个对链表题目很重要。近期对链表的一系列学习我感觉难度越来越大东西也越来越深奥。后续的学习需要花费更多的时间。#include <stdlib.h>struct ListNode* removeElements(struct ListNode* head, int val) {struc…...

好用的东莞高新技术企业认定哪个公司好
在东莞,高新技术企业认定服务市场竞争激烈,众多企业都在寻求专业可靠的服务机构来助力自己成功认定。那么,哪家公司在这方面表现出色呢?接下来,我们就来深入探讨一下。选择高新技术企业认定服务公司的关键因素专业能力…...