【C++】哈希的应用 -- 布隆过滤器
文章目录
- 一、布隆过滤器提出
- 二、布隆过滤器概念
- 三、布隆过滤器哈希函数个数的选择
- 四、布隆过滤器的实现
- 1.布隆过滤器的插入
- 2.布隆过滤器的查找
- 3.布隆过滤器删除
- 4.完整代码实现
- 五、布隆过滤器总结
- 1.布隆过滤器优点
- 2.布隆过滤器缺陷
- 3.布隆过滤器的应用
- 4.布隆过滤器相关面试题
一、布隆过滤器提出
我们知道位图可以快速的判断某个数据是否在一个集合中,但是位图有如下缺点:
1.位图只适用于数据范围集中的场景,当数据过于分散的时候,就会存在空间的浪费
2.位图只能针对整形,对于非整形的数据无法进行处理
其中位图只能针对整形的缺点我们可以使用仿函数来解决,即针对某一种特定类型定义一个HashFunc函数,将其转换为整形,比如当数据类型为字符串的时候,我们可以使用字符串哈希算法将字符串转换为整形,然后再将这个整形映射到位图中
但是这种方法存在一个很大的缺陷–不同的字符串通过同一个HashFunc函数转换出来的值可能是一样的,也就是说,我们判断一个数在不在的时候就存在误判,在这种情况下:
1.位图中该字符串存在是不准确的,因为该字符串的比特位可能原本是0,但是和其他字符串冲突了,发生了误判,导致该比特位变为了1
2.位图中字符串不在是准确的,因为比特位为0说明该字符串以及可能与该字符串发生冲突的其他字符串都不存在,所以不在是准确的
此外,我们通常会对字符串哈希函数转换出来的值进行取模,以此来节省空间,因为转换出来结果的范围是不确定的,但是取模之后又会增加哈希冲突的概率。
那么我们该如何降低误判率呢?答案是布隆过滤器
二、布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你“某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
我们可以看到,布隆过滤器是通过使用多个哈希函数的方式来降低误判率,即让同一个元素映射多个下标位置,在查询时只能这些位置都为1的时候才表示该值存在,而同一个元素通过不同哈希函数映射出来的不同下标同时被误判的概率肯定是比一个下标位置被误判的概率要低很多的。

需要注意的是,布隆过滤器只能降低误判率,不能彻底消除误判
三、布隆过滤器哈希函数个数的选择
那么是不是映射下标位置的个数越多越好呢,当然不是的,因为一个元素映射的下标位置越多,那么浪费的空间越多,此时我们可以选择哈希表或者红黑树,这样查询的结果还是准确的,对于如何选择哈希函数个数和布隆过滤器长度,这里有一篇大佬写的博客,大家可以参考:详解布隆过滤器的原理,使用场景和注意事项
我们通过这篇博客可以知道,哈希长度,布隆过滤器长度 ,插入元素个数与误判率如下图:

以及他们之间的关系:

对于上面的K取值带入可得:
1.当k取3的时候,m大约为4.3n,即一个插入元素要消耗4个左右的比特位
1.当k取5的时候,m大约为7.2n,即一个插入元素要消耗7个左右的比特位
1.当k取8的时候,m大约为11.6n,即一个插入元素要消耗12个左右的比特位
结合关系图和关系表达式可以得出,哈希函数取3-5个比较合适。
四、布隆过滤器的实现
布隆过滤器的实现很简单,位图使用库中的bitset 即可,字符串哈希算法可以从下面这篇博客中介绍的算法里面挑选几个评分比较高的算法:各种字符串Hash函数
1.布隆过滤器的插入
对个数据的插入,我们只需要让每一个位图都调用set即可,就可以实现,比如下面的例子:

向布隆过滤器中插入:“baidu”

向布隆过滤器中插入:“tencent”

代码实现:
void set(const T& key)
{size_t hashi1 = HashFunc1()(key) % (N * X);size_t hashi2 = HashFunc2()(key) % (N * X);size_t hashi3 = HashFunc3()(key) % (N * X);size_t hashi4 = HashFunc4()(key) % (N * X);_bs.set(hashi1);_bs.set(hashi2);_bs.set(hashi3);_bs.set(hashi4);
}
2.布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
代码实现如下:
bool test(const T& key)
{size_t hashi1 = HashFunc1()(key) % (N * X);if (!_bs.test(hashi1)){return false;}size_t hashi2 = HashFunc2()(key) % (N * X);if (!_bs.test(hashi2)){return false;}size_t hashi3 = HashFunc3()(key) % (N * X);if (!_bs.test(hashi3)){return false;}size_t hashi4 = HashFunc4()(key) % (N * X);if (!_bs.test(hashi4)){return false;}// 前面判断不在都是准确,不存在误判return true; // 可能存在误判,映射几个位置都冲突,就会误判
}
3.布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
1.无法确认元素是否真正在布隆过滤器中
2.存在计数回绕
4.完整代码实现
#pragma oncenamespace hdp
{struct BKDRHash{size_t operator()(const string& key){size_t hash = 0;for (auto ch : key){hash *= 131;hash += ch;}return hash;}};struct APHash{size_t operator()(const string& key){unsigned int hash = 0;int i = 0;for (auto ch : key){if ((i & 1) == 0){hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));}++i;}return hash;}};struct DJBHash{size_t operator()(const string& key){unsigned int hash = 5381;for (auto ch : key){hash += (hash << 5) + ch;}return hash;}};struct JSHash{size_t operator()(const string& s){size_t hash = 1315423911;for (auto ch : s){hash ^= ((hash << 5) + ch + (hash >> 2));}return hash;}};template<size_t N,size_t X = 6,class T=string,class HashFunc1= BKDRHash,class HashFunc2 = APHash,class HashFunc3 = DJBHash,class HashFunc4 = JSHash>class BloomFilter{public:void set(const T& key){size_t hashi1 = HashFunc1()(key) % (N * X);size_t hashi2 = HashFunc2()(key) % (N * X);size_t hashi3 = HashFunc3()(key) % (N * X);size_t hashi4 = HashFunc4()(key) % (N * X);_bs.set(hashi1);_bs.set(hashi2);_bs.set(hashi3);_bs.set(hashi4);}bool test(const T& key){size_t hashi1 = HashFunc1()(key) % (N * X);if (!_bs.test(hashi1)){return false;}size_t hashi2 = HashFunc2()(key) % (N * X);if (!_bs.test(hashi2)){return false;}size_t hashi3 = HashFunc3()(key) % (N * X);if (!_bs.test(hashi3)){return false;}size_t hashi4 = HashFunc4()(key) % (N * X);if (!_bs.test(hashi4)){return false;}// 前面判断不在都是准确,不存在误判return true; // 可能存在误判,映射几个位置都冲突,就会误判}private:std::bitset<N * X> _bs;};void test_bloomfilter1(){// 10:46继续string str[] = { "猪八戒", "孙悟空", "沙悟净", "唐三藏", "白龙马1","1白龙马","白1龙马","白11龙马","1白龙马1" };BloomFilter<10> bf;for (auto& str : str){bf.set(str);}for (auto& s : str){cout << bf.test(s) << endl;}cout << endl;srand(time(0));for (const auto& s : str){cout << bf.test(s + to_string(rand())) << endl;}}void test_bloomfilter2(){srand(time(0));const size_t N = 100000;BloomFilter<N> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集,但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";url += std::to_string(999999 + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)){++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){string url = "zhihu.com";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;}
}
我们可以使用上面两个函数对布隆过滤器进行测试,我们最终会发现误判率是可控的,我们可以根据具体的应用场景来测试调整哈希函数的个数以及布隆过滤器的长度,最终实现出最符合当前应用场景的布隆过滤器
五、布隆过滤器总结
1.布隆过滤器优点
1.增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
2.哈希函数相互之间没有关系,方便硬件并行运算
3.布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4.在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5.数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6.使用同一组散列函数的布隆过滤器可以进行交、并、差运算
2.布隆过滤器缺陷
1.有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
2.不能获取元素本身
3.一般情况下不能从布隆过滤器中删除元素
4.如果采用计数方式删除,可能会存在计数回绕问题
3.布隆过滤器的应用
布隆过滤器是解决位图只能处理整形和数据范围集中的缺陷而提出的,但是哈希函数和取模会导致哈希冲突从而发生误判,为了降低误判率,我们需要合理的选择哈希函数的个树以及布隆过滤器的长度
布隆过滤器适用于不需要完全准确,允许出现一定误判的场景,例如如下场景:
1.用户注册时的昵称判重:某些网站在注册时不允许出现重复昵称,而已注册的昵称都保存在服务器的数据库中,因为数据库存在磁盘是上,访问速度非常慢,所以如果用户没选择一个昵称都去数据库中查找是否存在的话效率是很低的。此时我们就可以在服务器前面加一个布隆过滤器进行过滤–将已注册的昵称都映射到布隆过滤器中,而不在一定是准确的,此时运行用户可以使用该昵称,可以直接返回,不再需要到数据库中进行查找。如果昵称在布隆过滤器中,则提示用户重新输入,但是这个并不影响用户的使用,我们也可以去数据库中进行查找,返回准确的结果。
2.查询个人的数据:比如我们要在公司的客户的数据中以身份证号为key值查找某一个用户的具体信息。由于直接访问数据的效率非常低,此时,我们即可以在服务器前面加一个布隆过滤器。查找方式和第一点一样,不在就直接返回,如果存在,则再到数据库中进行查找再返回查找的结果
在于其他的领域,比如判断一个网站是否是危险网站,我们在点进该网站时就应该显示出信息,此时我们就可以使用布隆过滤器,快速的进行显示。

4.布隆过滤器相关面试题
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
我们需要使用哈希切割的思想–使用相同的哈希函数分别对这两个文件进行切割,切割结果为A0–Ai,B0-Bi;因为哈希函数相同,所以Ai和Bi中的query及发生冲突的query都在同一个小文件中,此时我们只需要分别求出Ai和Bi相同下标小文件中的交集即可。需要注意的是,如果小文件很大,说明某一个或几个query有大量的重复,此时换一个哈希函数再分别对Ai和Bi小文件递归子文件进行哈希切割即可。
对于精确算法来说,我们需要先将Ai号小文件中的元素全部存入set/map中,再依次取Bi号小文件中的数据到set/map中查询即可得到交集,但是最后的结果需要进行去重处理。
相关文章:
【C++】哈希的应用 -- 布隆过滤器
文章目录 一、布隆过滤器提出二、布隆过滤器概念三、布隆过滤器哈希函数个数的选择四、布隆过滤器的实现1.布隆过滤器的插入2.布隆过滤器的查找3.布隆过滤器删除4.完整代码实现 五、布隆过滤器总结1.布隆过滤器优点2.布隆过滤器缺陷3.布隆过滤器的应用4.布隆过滤器相关面试题 一…...

如何在Git中修改远程仓库地址
原文(可不登录复制代码):如何在Git中修改远程仓库地址-北的杂货间 Git是广泛使用的分布式版本控制系统,它允许开发者在本地仓库上工作,并将更改上传到远程仓库。然而,有时候你可能需要修改远程仓库的地址&…...
函数)
Go语言的sync.Once()函数
sync.Once 是 Go 语言标准库 sync 包提供的一个类型,它用于确保一个函数只会被执行一次,即使在多个 goroutine 中同时调用。 sync.Once 包含一个 Do 方法,其签名如下: func (o *Once) Do(f func()) Do 方法接受一个函数作为参数…...

修改 Stable Diffusion 使 api 接口增加模型参数
参考:https://zhuanlan.zhihu.com/p/644545784 1、修改 modules/api/models.py 中的 StableDiffusionTxt2ImgProcessingAPI 增加模型名称 StableDiffusionTxt2ImgProcessingAPI PydanticModelGenerator("StableDiffusionProcessingTxt2Img",StableDiff…...
微信小程序自定义组件及会议管理与个人中心界面搭建
一、自定义tabs组件 1.1 创建自定义组件 新建一个components文件夹 --> tabs文件夹 --> tabs文件 创建好之后win7 以上的系统会报个错误:提示代码分析错误,已经被其他模块引用,只需要在 在project.config.json文件里添加两行配置 &…...
UiPath:一家由生成式AI驱动的流程自动化软件公司
来源:猛兽财经 作者:猛兽财经 总结: (1)UiPath(PATH)的股价并没有因为生成式AI的炒作而上涨,但很可能会成为主要受益者。 (2)即使在严峻的宏观环境下,UiPath的收入还在不…...

使用AI编写测试用例——详细教程
随着今年chatGPT的大热,每个行业都试图从这项新技术当中获得一些收益我之前也写过一篇测试领域在AI技术中的探索:软件测试中的AI——运用AI编写测试用例现阶段AI还不能完全替代人工测试用例编写,但是如果把AI当做一个提高效率的工具ÿ…...
又哭又笑,这份面试宝典要是早遇到就好了
01、算法原理 选择排序(Selection sort)是一种简单直观的排序算法。 第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素&#…...
订单30分钟自动关闭的五种解决方案
1 前言 在开发中,往往会遇到一些关于延时任务的需求。例如 生成订单30分钟未支付,则自动取消生成订单60秒后,给用户发短信 对上述的任务,我们给一个专业的名字来形容,那就是延时任务 。那么这里就会产生一个问题,这…...

【vSphere 8 自签名 VMCA 证书】企业 CA 签名证书替换 vSphere VMCA CA 证书Ⅰ—— 生成 CSR
目录 替换拓扑图证书关系示意图说明 & 关联博文1. 默认证书截图2. 使用 certificate-manager 生成CSR2.1 创建存放CSR的目录2.2 记录PNID和IP2.3 生成CSR2.4 验证CSR 参考资料 替换拓扑图 证书关系示意图 本系列博文要实现的拓扑是 说明 & 关联博文 因为使用企业 …...

【diffusion model】扩散模型入门
写在最前,参加DataWhale 10月组队学习。 参考资料: HuggingFace 开源diffusion-models-class 1.扩散模型介绍 2.调用模型生成一张赛博风格的猫咪图片 2.1 安装依赖包 %pip install -qq -U diffusers datasets transformers accelerate ftfy pyarrow9…...

[Spring]为什么Spring动态代理默认使用CGlib,而不是JDK代理?
文章目录 原因一:CGlib不需要接口原因二:CGlib效率高原因三:JDK代理会导致注解失效如果希望使用JDK代理扩展AOP in Spring Boot, is it a JDK dynamic proxy or a Cglib dynamic proxy?SpringSpringBoot 原因一:CGlib不需要接口 …...
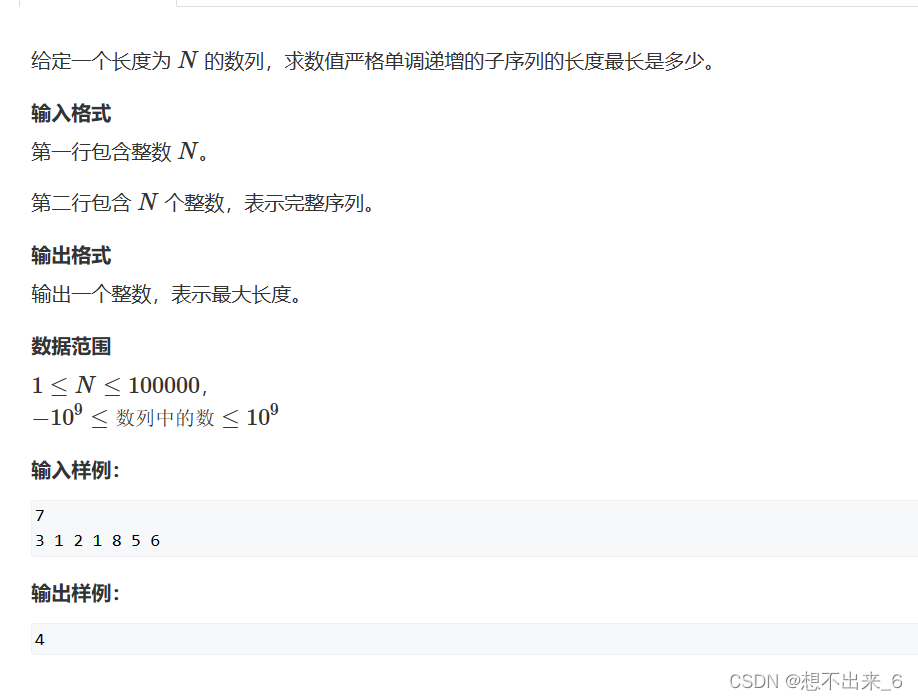
最长上升子序列(二分)代码模板
用二分的思想求最长上升子序列的思想就是保持单调性,用一个q[]数组来作为一个单调数组。 每次将a[i]放进q数组中,但是要保持单调性,q数组的长度就是答案。 q[]数组中存的是所以以下标为长度的最长子序列的结尾的最小值。 理解q[]数组的意义…...
存储优化知识复习一详细版解析
存储优化 知识复习一 一、 选择题 1、1948 年,____提出了“信息熵”(shāng) 的概念,解决了对信息的量化度量问题。 A、薛定谔 B、香农 C、克劳修斯 D、纳什 【参考答案】B2、 RAID2.0技术下,LUN是建立在____上。 A、硬盘 B、条带 C、Chun…...
“暂停加息,股市低迷:242只股票创新低,比特币突破2.8万美元后看涨趋势不可挡!“
11 月1日 FOMC 会议 美联储主席杰罗姆鲍威尔周五在纽约发表讲话,毫不意外地,他采取了更加鸽派的立场,因为在不确定的世界中,美国政府的过度杠杆化和可能即将到来的经济衰退已成为共识。 根据鲍威尔对未来加息的最低限度讨论&…...

微信小程序会议OA系统其他页面
前言: 及上一文章:https://blog.csdn.net/djssubddbj/article/details/133895170?spm1001.2014.3001.5501我们所写的会议OA的首页,在这个上面我们继续完成我们的会议OA系统,这是我们的本期所要完成的页面 自定义组件 微信小程序…...
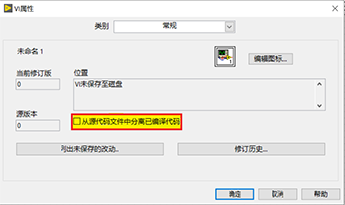
LabVIEW中使用Get LV Class Default Value 出现错误1498
LabVIEW中使用Get LV Class Default Value 出现错误1498 在LabVIEW中开发了一个应用程序,其中包含可以在执行时动态配置插件的基类。生成可执行文件后,当应用程序要执行子类时,收到以下错误信息。 Error1498 occurred at Gen LV Class Defa…...
RabbitMQ中的核心概念和交换机类型
目录 一、RabbitMQ相关概念二、Exchange类型三、RabbitMQ概念模型总结 一、RabbitMQ相关概念 Producer:生产者,就是投递消息的一方。生产者创建消息,然后发布到RabbitMQ中。消息一般可以包含两个部分:消息体和附加消息。 消息体…...
HarmonyOS开发:Log工具类源码分析
前言 一转眼就十月中旬了,国庆的劲真大,到现在还未缓过来,以至于要更新的文章迟迟未发布,大家可以看到,最近一段时间的文章,都是关于HarmonyOS相关的,两个原因吧,一是我司有这样的任…...
FFmpeg和rtsp服务器搭建视频直播流服务
下面使用的是ubuntu的,window系统可以参考: 通过rtsp-simple-server和ffmpeg实现录屏并发布视频直播_rtsp simple server_病毒宇宇的博客-CSDN博客 一、安装rtsp-simple-server (1)下载rtsp-simple-server 下载地址:R…...

如何把MAX31865的精度榨干?STM32驱动PT100三线制测温的校准与优化实战
如何将MAX31865的精度发挥到极致:PT100三线制高精度测温实战指南 在工业自动化、实验室设备以及精密仪器控制领域,温度测量的准确性往往直接影响整个系统的可靠性和产品质量。MAX31865作为一款专为RTD(电阻温度检测器)设计的信号调…...

Python异步爬虫实战:巧用Session池化解ServerDisconnectedError连接风暴
1. 为什么你的异步爬虫总被服务器断开? 最近在帮一个朋友优化爬虫时,发现他遇到了典型的ServerDisconnectedError问题。每次运行到2000多个请求时,服务器就会无情地断开连接。这种情况在高并发爬虫中特别常见,特别是当你像大多数教…...

终极指南:用Ryujinx在PC上免费畅玩Switch游戏的完整教程
终极指南:用Ryujinx在PC上免费畅玩Switch游戏的完整教程 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上体验《塞尔达传说:旷野之息》的广阔世界&…...

【Linux从入门到精通】第1篇:开篇辞——我们为什么要学Linux?从服务器霸主到Android内核
目录 一、引言:我们为什么要学Linux? 二、Linux与Windows/macOS:三种哲学的分野 三、Linux发行版图谱:选对第一套系统 1. Debian系:社区驱动的稳定基石 2. RedHat系:企业应用的事实标准 3. Arch系&…...

WinUtil:5步掌握Windows系统优化与软件管理的终极指南
WinUtil:5步掌握Windows系统优化与软件管理的终极指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil WinUtil是Windows系统优化与…...

从“0x7C显示b”说开去:图解单片机GPIO驱动数码管的底层电路与电平逻辑
从“0x7C显示b”说开去:图解单片机GPIO驱动数码管的底层电路与电平逻辑 数码管作为嵌入式系统中最基础的人机交互元件之一,其驱动原理看似简单却蕴含着硬件与软件协同工作的精妙设计。许多初学者能够熟练编写P00x7C这样的代码让数码管显示字母"b&qu…...

Calibre路径本地化技术解析:告别拼音目录,拥抱原生中文路径
Calibre路径本地化技术解析:告别拼音目录,拥抱原生中文路径 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文)命…...

C#实战:基于TCP与MLLP协议构建HL7医疗数据接收与解析服务
1. 为什么需要HL7医疗数据接收服务? 医疗信息化系统之间的数据交换一直是个头疼的问题。记得我第一次对接医院HIS系统时,对方只给了一份HL7协议文档,当时完全摸不着头脑。传统的数据库中间表方式虽然简单,但实时性差;W…...

传统SLAM使用CUDA加速,优势究竟有多大?
深度学习在SLAM中主要用于:动态目标剔除、语义SLAM的目标检测与分割。特征点提取与匹配(SuperPoint、SuperGlue)。场景描述符与重定位。工程建议:CUDA对传统SLAM有明显优势,尤其在视觉稠密前端、激光点云匹配、后端优化…...

STM32CubeIDE用户看过来:用CMake管理你的自定义代码模块,让项目结构更清晰
STM32CubeIDE用户进阶指南:用CMake重构项目架构的五个关键策略 当你面对第17个基于STM32CubeMX生成的项目时,是否发现那些散落在各个角落的驱动代码越来越难以管理?我们曾在一个工业控制器项目中,因为模块耦合度过高导致功能更新时…...