MySQL——八、MySQL索引视图
MySQL
- 一、视图
- 1、什么是视图
- 2、为什么需要视图
- 3、视图的作用和优点
- 4、创建视图
- 5、视图使用规则
- 6、修改视图
- 7、删除视图
- 二、索引
- 1、什么是索引
- 2、索引优缺点
- 3、索引分类
- 4、索引的设计原则
- 5、创建索引
- 5.1 创建表是创建索引
- 5.2 create index
- 5.3 ALTER TABLE
- 6、删除索引
- 7、MySQL使用索引的场景
- MySQL索引的优化
- 8、SQL如何使用索引
- 9、聚簇索引和非聚簇索引
- 9.1 非聚簇索引
- 9.2 聚簇索引
一、视图
1、什么是视图
视图通过以定制的方式显示来自一个或多个表的数据
视图是一种数据库对象,用户可以像查询普通表一样查询视图
视图内其实没有存储任何数据,它只是对表的一个查询
视图的定义保存在数据字典内,创建视图所基于对表称为“基表”
2、为什么需要视图
例如经常要对emp和dept表进行连接查询,每次都要做表的连接,写同样的一串语句,同时由于工资列队数据比较敏感,对外要求不可见。对这样的问题就可以通过视图来解决。
3、视图的作用和优点
作用:
- 控制安全
- 保存查询数据
优点:
- 提供了灵活一致级别安全性。
- 隐藏了数据的复杂性
- 简化了用户的SQL指令
- 通过重命名列,从另一个角度提供数据
4、创建视图
CREATE [OR REPLACE] VIEW 视图名
[(alias[, alias]...)]--为视图字段指定别名
AS subquery
[WITH READ ONLY];
创建视图, EMP_V_10, 包括10号部门的所有雇员信息。
CREATE VIEW emp_v_10
AS SELECT employee_id,first_name,last_name,salary
FROM employees
WHERE manager_id;
查看视图:
SELECT * FROM emp_v_10;

5、视图使用规则
- 视图必须有唯一命名
- 在mysql中视图的数量没有限制
- 创建视图必须从管理员那里获得必要的权限
- 视图支持嵌套,也就是说可以利用其他视图检索出来的数据创建新的视图
- 在视图中可以使用OREDR BY,但是如果视图内已经使用该排序子句,则视图的ORDER BY将覆盖前面的ORDER BY。
- 视图不能索引,也不能关联触发器或默认值
- 视图可以和表同时使用
6、修改视图
使用CREATE OR REPLACE VIEW 语句修改EMP_V_10 视图. 为每个列指定列名。
CREATE OR REPLACE VIEW emp_v_10
(id, name, sal, dept_id)
AS SELECT id,name,
salary, dept_id
FROM employees
WHERE dept_id = 10;
在CREATE VIEW 语句中字段与子查询中的字段必须一一对应,否则就别指定别名,或在子查询中指定别名使用ALTER VIEW 语句修改EMP_V_10 视图. 为每个列指定列名。
ALTER VIEW emp_v_10
(id, name, sal, dept_id)
AS SELECT id,name,
salary, dept_id
FROM employees
WHERE dept_id = 10;
在CREATE VIEW 语句中字段与子查询中的字段必须一一对应,否则就别指定别名,或在子查询中指定别名创建复杂视图,创建一个从两个表中查询数据,并进行分组计算的复杂视图。
CREATE VIEW dept_sum_vu_10
(name, minsal, maxsal, avgsal)
AS SELECT d.name, MIN(e.salary),
MAX(e.salary),AVG(e.salary)
FROM employees e, departments d
WHERE e.dept_id = d. id
AND e.dept_id = 10;
7、删除视图
查询库中哪些是视图表:
show table status where comment ='view';
删掉视图不会导致数据的丢失,因为视图是基于数据库的表之上的一个查询定义。
DROP VIEW view_name;
案例演示:
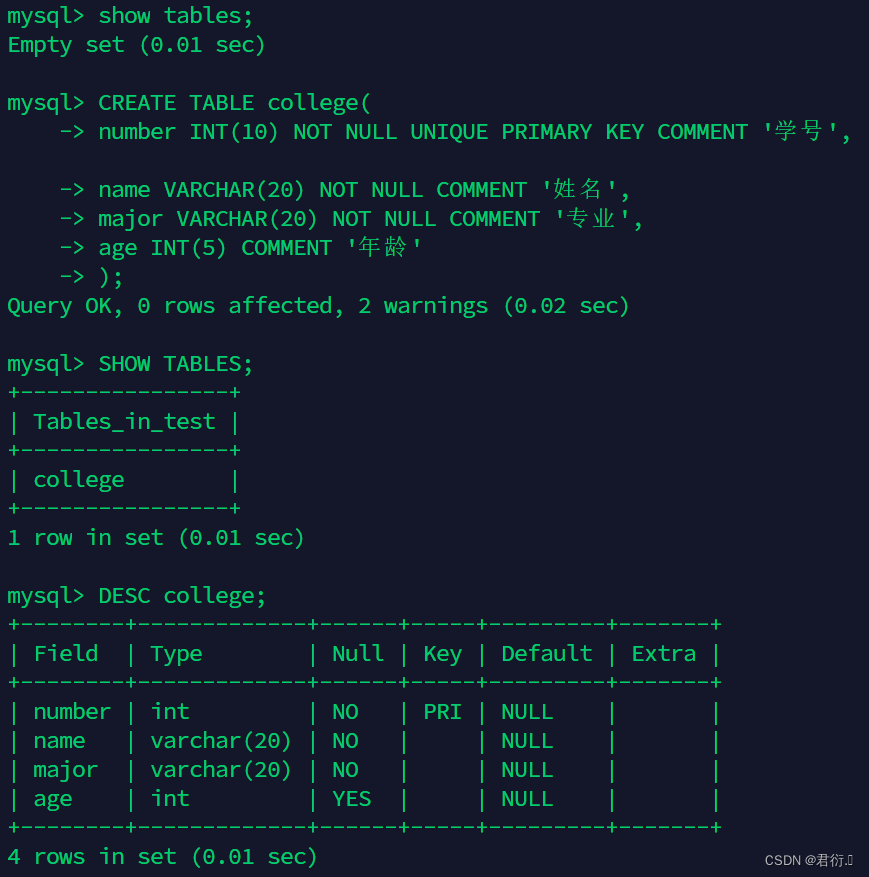
- 1、在数据库example下创建college表。College表内容如下所示
| 字段名 | 字段描述 | 数据类型 | 主键 | 外键 | 非空 | 唯一 | 自增 |
|---|---|---|---|---|---|---|---|
| number | 学号 | INT(10) | 是 | 否 | 是 | 是 | 否 |
| name | 姓名 | VARCHAR(20) | 否 | 否 | 是 | 否 | 否 |
| major | 专业 | VARCHAR(20) | 否 | 否 | 是 | 否 | 否 |
| age | 年龄 | NT(5) | 否 | 否 | 否 | 否 | 否 |
CREATE TABLE college(number INT(10) NOT NULL UNIQUE PRIMARY KEY COMMENT '学号',name VARCHAR(20) NOT NULL COMMENT '姓名',major VARCHAR(20) NOT NULL COMMENT '专业',age INT(5) COMMENT '年龄'
);
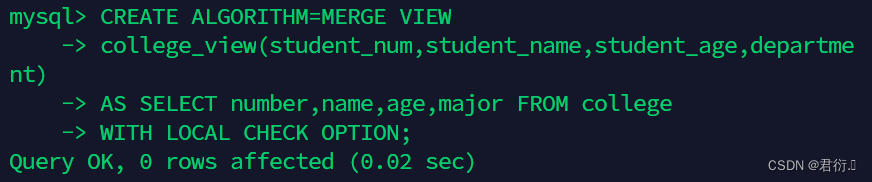
- 2、在student表上创建视图college_view。视图的字段包括student_num、student_name、student_age和department。ALGORITHM设置为MERGE类型,并且为视图加上WITH LOCAL CHECK OPTION条件
CREATE ALGORITHM=MERGE VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major FROM college
WITH LOCAL CHECK OPTION;
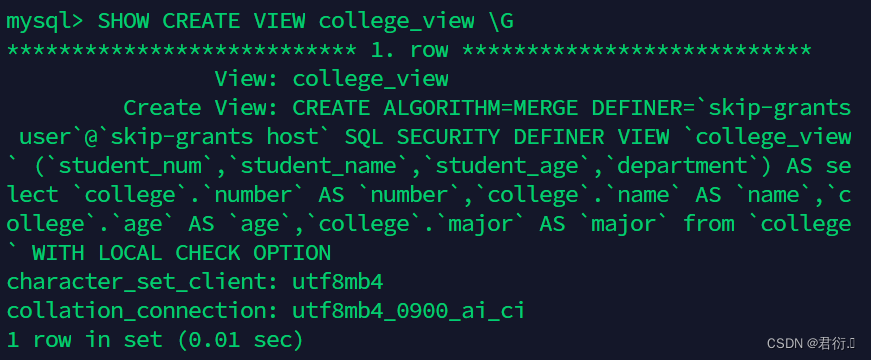
- 3、查看视图college_view的详细结构
SHOW CREATE VIEW college_view \G
- 4、 更新视图。向视图中插入3条记录。记录内容如下表所示
| umer | name | major | age |
|---|---|---|---|
| 0901 | 张三 | 外语 | 20 |
| 0902 | 李四 | 计算机 | 22 |
| 0903 | 王五 | 计算机 | 19 |
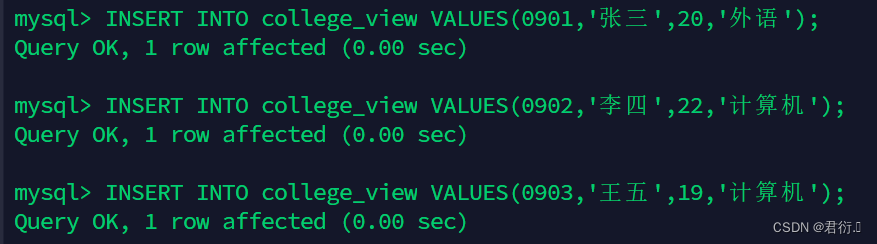
INSERT INTO college_view VALUES(0901,'张三',20,'外语');
INSERT INTO college_view VALUES(0902,'李四',22,'计算机');
INSERT INTO college_view VALUES(0903,'王五',19,'计算机');
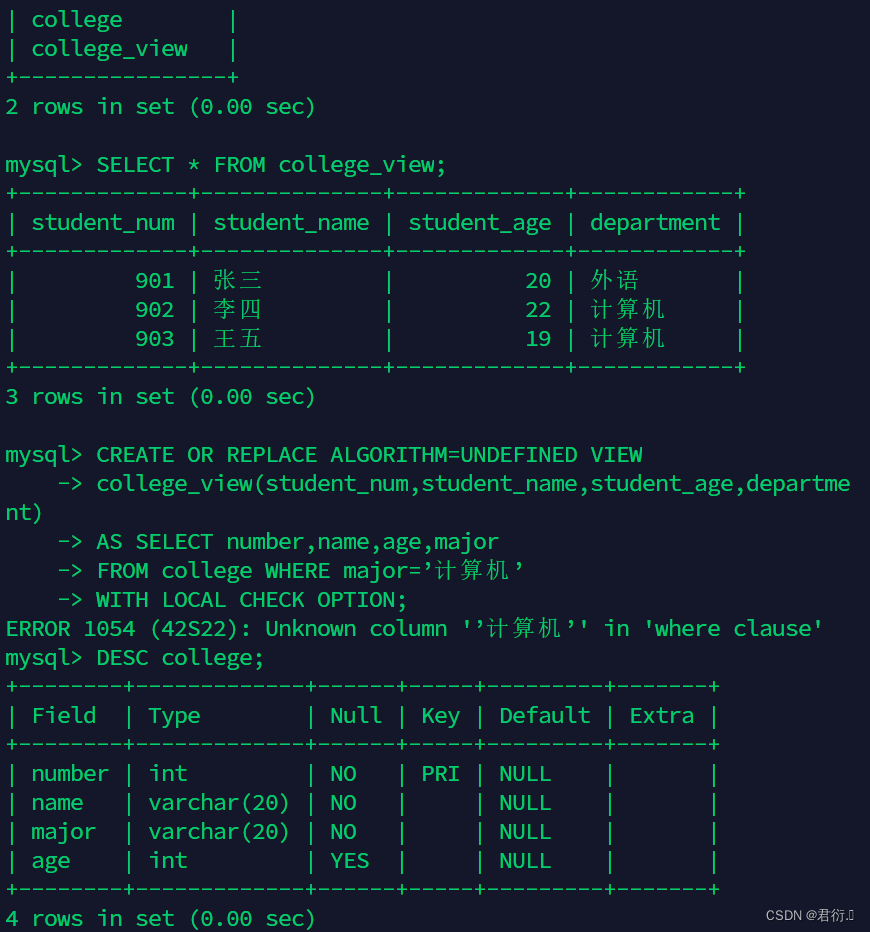
- 5 、修改视图,使其显示专业为计算机的信息,其他条件不变
方法一:
CREATE OR REPLACE ALGORITHM=UNDEFINED VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major
FROM college WHERE major=’计算机’
WITH LOCAL CHECK OPTION;
方法二:
ALTER ALGORITHM=UNDEFINED VIEW
college_view(student_num,student_name,student_age,department)
AS SELECT number,name,age,major
FROM college WHERE major=’计算机’
WITH LOCAL CHECK OPTION;
- 6 、删除视图college_view
DROP VIEW college_view;
二、索引
索引是一种特殊的数据库结构,可以用来快速查询数据库表中的特定记录。索引是提高数据库性能的重要方式。
MySQL中,所有的数据类型都可以被索引。MySQL的索引包括普通索引、惟一性索引、全文索引、单列索引、多列索引和空间索引等。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。(注意:一般数据库默认都会为主键生成索引)。
1、什么是索引
模式(schema)中的一个数据库对象
在数据库中用来加速对表的查询
通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O
与表独立存放,但不能独立存在,必须属于某个表
由数据库自动维护,表被删除时,该表上的索引自动被删除。
索引的作用类似于书的目录,几乎没有一本书没有目录,
因此几乎没有一张表没有索引。
索引的原理
就是把无序的数据变成有序的查询
- 把创建的索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
2、索引优缺点
-
索引的优点是
-
- 可以提高检索数据的速度,这是创建索引的最主要的原因;对于有依赖关系的子表和父表之间的
联合查询时,可以提高查询速度;使用分组和排序子句进行数据查询时,同样可以显著节省查询中分组和排序的时间。
- 可以提高检索数据的速度,这是创建索引的最主要的原因;对于有依赖关系的子表和父表之间的
-
索引的缺点是
-
- 创建和维护索引需要耗费时间,耗费时间的数量随着数据量的增加而增加;索引需要占用物理空
间,每一个索引要占一定的物理空间;增加、删除和修改数据时,要动态的维护索引,造成数据的维护速度降低了。
- 创建和维护索引需要耗费时间,耗费时间的数量随着数据量的增加而增加;索引需要占用物理空
3、索引分类
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
MySQL的索引包括普通索引、惟一性索引、全文索引、单列索引、多列索引和空间索引等。
- 按数据结构分类
从数据结构来看,MySQL常见索引有B+Tree索引,HASH索引,Full-Text索引。
每一种存储引擎支持的索引类型不一定相同:
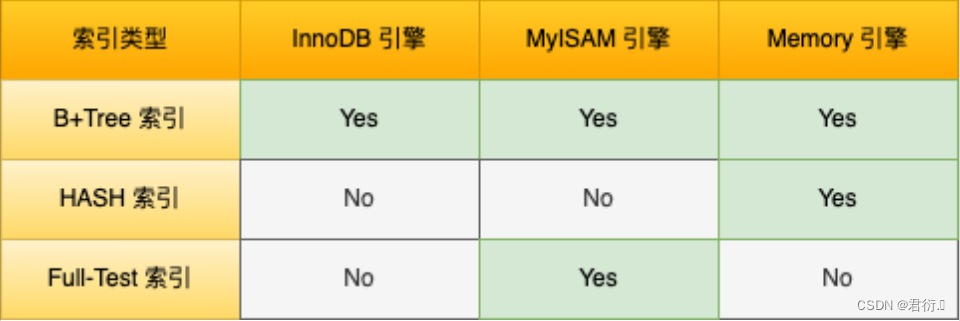
InnoDB 是在 MySQL 5.5 之后成为默认的 MySQL 存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引: -
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
-
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
-
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。创建的主键索引和二级索引默认使用的是 B+Tree 索引。
4、索引的设计原则
为了使索引的使用效率更高,在创建索引的时候必须考虑在哪些字段上创建索引和创建什么类型的索引。本小
节将向读者介绍一些索引的设计原则。
- 选择惟一性索引
- 为经常需要排序、分组和联合操作的字段建立索引
- 为常作为查询条件的字段建立索引
- 限制索引的数目
- 尽量使用数据量少的索引
- 尽量使用前缀来索引
- 删除不再使用或者很少使用的索引
5、创建索引
创建索引是指在某个表的一列或多列上建立一个索引,以便提高对表的访问速度。创建索引有三种方式,这三种方式分别是创建表的时候创建索引、在已经存在的表上创建索引和使用ALTER TABLE语句来创建索引。
5.1 创建表是创建索引
创建表的时候可以直接创建索引,这种方式最简单、方便。其基本形式如下:
CREATE TABLE 表名 ( 属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
…
属性名 数据类型
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[别名](属性名1 [(长度)] [ASC | DESC])
);
- 1、普通索引
# 直接创建索引
CREATE INDEX index_name ON table(column(length))
# 创建表的时候同时创建索引
Create table index1(Id int,Name varchar(20),Sex boolean,index(id),
);
# 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
# 查询索引
Show create table index1 \G
# 查询某张表中索引情况
show index from table_name;
# 使用计划查询SQL使用索引情况
Explain select * from index1 where id=1 \G
# 删除索引
DROP INDEX index_name ON table
- 2、创建唯一性索引 ,当然也有多种创建方式
Create table index2(Id int unique,Name varchar(20),Unique index index2_id(id asc)
);
- 3、创建全文索引(FULLTEXT)
MySQL从3.23.23版开始支持全文索引和全文检索,FULLTEXT索引仅可用于 MyISAM 表;他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加。
对于较大的数据集,将你的资料输入一个没有FULLTEXT索引的表中,然后创建索引,其速度比把资料输入现有FULLTEXT索引的速度更为快。不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间非常消耗硬盘空间的做法。只能创建在char,varchar或text类型的字段上。
create table index3(Id int,Info varchar(20),Fulltext index index3_info(info)
);
explain select * from table where id=1;
-
EXPLAIN分析结果的含义:
-
- table:这是表的名字。
-
- type:连接操作的类型,ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
-
- possible_keys:可能可以利用的索引的名字
-
- Key:它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
-
- key_len:索引中被使用部分的长度,以字节计。
-
- ref:它显示的是列的名字(或单词“const”),MySQL将根据这些列来选择行
-
- rows:MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1
-
- Extra:这里可能出现许多不同的选项,其中大多数将对查询产生负面影响
-
4、创建单列索引
Create table index4(Id int,Subject varchar(30),Index index4_st(subject(10))
);
- 5、创建多列索引
使用多列索引时一定要特别注意,只有使用了索引中的第一个字段时才会触发索引。如果没有使用索引中的第一个字段,那么这个多列索引就不会起作用。也就是说多个单列索引与单个多列索引的查询效果不同,因为执行查询时,MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
Create table index5(Id int,Name varchar(20),Sex char(4),Index index5_ns(name,sex)
);
- 6、创建空间索引
Create table index6(Id int,Space geometry not null,Spatial index index6_sp(space)
)engine=myisam;
建空间索引时,表的存储引擎必须是myisam类型,而且索引字段必须有非空约束。空间数据类型包括geometry,point,linestring和polygon类型等。平时很少用到。
5.2 create index
首先保证已经存在表,才能使用这个命令创建索引。
在已经存在的表上,可以直接为表上的一个或几个字段创建索引。基本形式如下:help create index
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (属性名 [ (长度) ] [ ASC | DESC] );
- 1.创建普通索引
CREATE INDEX index_name ON table(column(length))
- 2.创建惟一性索引
CREATE UNIQUE INDEX indexName ON table(column(length))
- 3.创建全文索引
CREATE FULLTEXT INDEX index_content ON article(content)
- 4.创建单列索引
CREATE INDEX index3_name on index3 (name(10));
- 5.创建多列索引
- 6.创建空间索引
5.3 ALTER TABLE
用ALTER TABLE语句来创建索引,也是存在表的情况下。
在已经存在的表上,可以通过ALTER TABLE语句直接为表上的一个或几个字段创建索引。基本形式如下:
ALTER TABLE 表名 ADD [ UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名(属性名 [ (长度) ] [ ASC | DESC]);
- 1.创建普通索引
ALTER TABLE table_name ADD INDEX index_name (column(length))
- 2.创建惟一性索引
ALTER TABLE table_name ADD UNIQUE indexName (column(length))
- 3.创建全文索引
ALTER TABLE index3 add fulltext index index3_name(name);
- 4.创建单列索引
ALTER TABLE index3 add index index3_name(name(10));
- 5.创建多列索引
- 6.创建空间索引
6、删除索引
删除索引是指将表中已经存在的索引删除掉。一些不再使用的索引会降低表的更新速度,影响数据库的性能。
对于这样的索引,应该将其删除。本节将详细讲解删除索引的方法。
对应已经存在的索引,可以通过DROP语句来删除索引。基本形式如下:
DROP INDEX 索引名 ON 表名 ;
索引示例:
- 1、 在数据库job下创建workInfo表。创建表的同时在id字段上创建名为index_id的唯一性索引,而且以降序的格式排列。workInfo表内容如下所示
| 字段描述 | 数据类型 | 主键 | 外键 | 非空 | 唯一 | 自增 |
|---|---|---|---|---|---|---|
| id | 编号 | INT(10) | 是 | 否 | 是 | 是 |
| name | 职位名称 | VARCHAR(20) | 否 | 否 | 是 | 否 |
| type | 职位类别 | VARCHAR(10) | 否 | 否 | 否 | 否 |
| address | 工作地址 | VARCHAR(50) | 否 | 否 | 否 | 否 |
| wage | 工资 | INT | 否 | 否 | 否 | 否 |
| contents | 工作内容 | TINYTEXT | 否 | 否 | 否 | 否 |
| extra | 附加信息 | TEXT | 否 | 否 | 否 | 否 |
CREATE TABLE workInfo(id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT,name VARCHAR(20) NOT NULL,type VARCHAR(10),address VARCHAR(50),tel VARCHAR(20),wage INT,content TINYTEXT,extra TEXT,UNIQUE INDEX index_id(id DESC));
- 2 、使用create index语句为name字段创建长度为10的索引index_name
CREATE INDEX index_name ON workInfo(name(10));
- 3 、使用alter table语句在type和address上创建名为index_t的索引
ALTER TABLE workInfo ADD INDEX index_t(type,address);
- 4 、将workInfo表的存储引擎更改为MyISAM类型
ALTER TABLE workInfo ENGINE=MyISAM;
- 5 、使用alter table语句在extra字段上创建名为index_ext的全文索引
ALTER TABLE workInfo ADD FULLTEXT INDEX index_ext(extra);
- 6 、删除workInfo表的唯一性索引index_id
DROP INDEX index_id ON workInfo;
实例测试MySQL使用索引带来的效率提升:
- 1、创建测试表
create table test1(id int,num int,pass varchar(50)
);
create table test2(id int,num int,pass varchar(50),index idIdx (id)
);
create table test3(id int,num int,pass varchar(50)
);
- 2、向表test1里插入1000000条数据
for ((i=1;i<=1000000;i++));do `mysql -p123456 -uroot -e "insert into it.test1
values($i,floor($i+rand()*$i),md5($i));"`; done > /tmp/mysql.txt 2>&1
# 注意:测试时可以插入300000条记录
mysql> select count(*) from test1;
+----------+
| count(*) |
+----------+
| 300000 |
+----------+
1 row in set (0.12 sec)
- 3、在有索引和没有索引的情况下执行查询
-
- 1)没有创建索引时查询
mysql> reset query cache;
mysql> explain select num,pass from test3 where id>=5000 and id<5050;
-
- 2)创建索引后再次查询
mysql> reset query cache;
mysql> explain select num,pass from test2 where id>=5000 and id<5050;
- 4、在有索引和没有索引的情况下新增数据
-
- 1)没有创建索引时插入数据
mysql> insert into test3 select * from test1;
Query OK, 300000 rows affected (1.00 sec)
Records: 300000 Duplicates: 0 Warnings: 0
- 2)创建索引后再次插入数据
mysql> insert into test2 select * from test1;
Query OK, 300000 rows affected (1.17 sec)
Records: 300000 Duplicates: 0 Warnings: 0
7、MySQL使用索引的场景
- 1.快速查找符合where条件的记录
- 2.快速确定候选集。若where条件使用了多个索引字段,则MySQL会优先使用能使候选记录集规模最小的那个索引,以便尽快淘汰不符合条件的记录。
- 3.如果表中存在几个字段构成的联合索引,则查找记录时,这个联合索引的最左前缀匹配字段也会被自动作为索引来加速查找。
例如,若为某表创建了3个字段(c1, c2, c3)构成的联合索引,则(c1), (c1, c2), (c1, c2, c3)均会作为索引,(c2, c3)就不会被作为索引,而(c1, c3)其实只利用到c1索引。 - 4.多表做join操作时会使用索引(如果参与join的字段在这些表中均建立了索引的话)。
- 5.若某字段已建立索引,求该字段的min()或max()时,MySQL会使用索引
- 6.对建立了索引的字段做sort或group操作时,MySQL会使用索引
MySQL索引的优化
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。下面是一些总结以及收藏的MySQL索引的注意事项和优化方法。
何时使用聚集索引或非聚集索引
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
| 列经常被分组排序 | 使用 | 使用 |
| 返回某范围内的数据 | 使用 | 不使用 |
| 一个或极少不同值 | 不使用 | 不使用 |
| 小数目的不同值 | 使用 | 不使用 |
| 大数目的不同值 | 不使用 | 使用 |
| 频繁更新的列 | 不使用 | 使用 |
| 外键列 | 使用 | 使用 |
| 主键列 | 使用 | 使用 |
| 频繁修改索引列 | 不使用 | 使用 |
8、SQL如何使用索引
- 1.B-Tree可被用于sql中对列做比较的表达式,如=, >, >=, <, <=及between操作
- 2.若like语句的条件是不以通配符开头的常量串,MySQL也会使用索引。比如,
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%'或SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%'可以利用索引,而SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%'(以通配符开头)和SELECT * FROM tbl_name WHERE key_col LIKE other_col(like条件不是常量串)无法利用索引。
对于形如LIKE '%string%'的sql语句,若通配符后面的string长度大于3,则MySQL会利用Turbo Boyer-Moore algorithm算法进行查找. - 3.若已对名为col_name的列建了索引,则形如"col_name is null"的SQL会用到索引。
- 4.对于联合索引,sql条件中的最左前缀匹配字段会用到索引。
- 5.若sql语句中的where条件不只1个条件,则MySQL会进行Index Merge优化来缩小候选集范围
MySQL只对一下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引(版本不同,可能会有变化)。
9、聚簇索引和非聚簇索引
9.1 非聚簇索引
索引节点的叶子页面就好比一片叶子。叶子头便是索引键值。
先创建一张表:
CREATE TABLE `user` (
`id` INT NOT NULL ,
`name` VARCHAR NOT NULL ,
`class` VARCHAR NOT NULL);
对于MYISAM引擎,如果创建 id 和 name 为索引。对于下面查询:
select * from user where id = 1
会利用索引,先在索引树中快速检索到 id,但是要想取到id对应行数据,必须找到改行数据在硬盘中的存储位置,因此MYISAM引擎的索引,叶子页面上不仅存储了主键id 还存储着 数据存储的地址信息。如图:
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 磁盘 | 磁盘 | 磁盘 | 磁盘 |
| 地址 | 地址 | 地址 | 地址 |
像这样的索引就称为非聚簇索引。
非聚簇索引的二级索引与主键索引类似。假设我们对name添加索引,那么name的索引树叶子将是如下结构:
| zhangsan | lisi | wangwu | laoliu |
|---|---|---|---|
| 磁盘 | 磁盘 | 磁盘 | 磁盘 |
| 地址 | 地址 | 地址 | 地址 |
9.2 聚簇索引
对于非聚簇索引来说,每次通过索引检索到所需行号后,还需要通过叶子上的磁盘地址去磁盘内取数据(回行)消耗时间。为了优化这部分回行取数据时间,InnoDB 引擎采用了聚簇索引。
聚簇索引,即将数据存入索引叶子页面上。对于 InnoDB 引擎来说,叶子页面不再存该行对应的地址,而是直接存储数据:
| 3 | 4 | 5 | 6 |
|---|---|---|---|
| name1 | name2 | name3 | name4 |
| class1 | class2 | class3 | class4 |
这样便避免了回行操作所带来的时间消耗。 使得 InnoDB 在某些查询上比 MyISAM 还要快!
关于查询时间,一般认为 MyISAM 牺牲了功能换取了性能,查询更快。但事实并不一定如此。多数情况下,MyISAM 确实比 InnoDB 查的快 。但是查询时间受多方面因素影响。InnoDB 查询变慢得原因是因为支持事务、回滚等等,使得 InnoDB的叶子页面实际上还包含有事务id(换句话说就是版本号) 以及回滚指针。
在二级索引方面, InnoDB 与 MyISAM 有很大区别。
InnoDB默认对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,InnoDB 会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
假设对 InnoDB 引擎上表name字段加索引,那么name索引叶子页面则只会存储主键id:
| name1 | name2 | name3 | name4 |
|---|---|---|---|
| 3 | 4 | 5 | 6 |
检索时,先通过name索引树找到主索引id,再通过id在主索引树的聚簇索引叶子页面取出数据。
相关文章:
MySQL——八、MySQL索引视图
MySQL 一、视图1、什么是视图2、为什么需要视图3、视图的作用和优点4、创建视图5、视图使用规则6、修改视图7、删除视图 二、索引1、什么是索引2、索引优缺点3、索引分类4、索引的设计原则5、创建索引5.1 创建表是创建索引5.2 create index5.3 ALTER TABLE 6、删除索引7、MySQL…...
)
力扣100097. 合法分组的最少组数(哈希+贪心)
题目描述: 给你一个长度为 n 下标从 0 开始的整数数组 nums 。 我们想将下标进行分组,使得 [0, n - 1] 内所有下标 i 都 恰好 被分到其中一组。 如果以下条件成立,我们说这个分组方案是合法的: 对于每个组 g ,同一…...
uniapp map地图实现marker聚合点,并点击marker触发事件
1.uniapp官方文档说明 2.关键代码片段 // 仅调用初始化,才会触发 on.("markerClusterCreate", (e) > {})this._mapContext.initMarkerCluster({enableDefaultStyle: false, // 是否使用默认样式zoomOnClick: true, // 点击聚合的点,是否…...
【Mysql】Mysql中的B+树索引(六)
概述 从上一章节我们了解到InnoDB 的数据页都是由7个部分组成,然后各个数据页之间可以组成一个双向链表 ,而每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表 ,每个数据页都会为存储在它里边儿的记录生成一个页目录 ÿ…...
【Dockerfile镜像实战】构建LNMP环境并运行Wordpress网站平台
这里写目录标题 一、项目背景和要求二、项目环境三、部署过程1)创建自定义网络2)部署NginxStep1 创建工作目录并上传相关软件包Step2 编写Dockerfile文件Step3 编写配置文件nginx.confStep4 创建nginx镜像Step5 运行容器 3)部署MysqlStep1 创…...

【工具】利用ffmpeg将网页中的.m3u8视频文件转化为.mp4格式
目录 0.环境 1.背景 2.前提 3.详细描述 1)在网站上找到你想下载的视频的.m3u8链接 2)打开命令行,用ffmpeg命令进行转化 3)过程&结果截图 0.环境 windows64 ffmpeg 1.背景 网页上有个.m3u8格式的视频文件,…...

Git简洁安装方式和使用方式【附安装包资源,Git基础操作,如拉取项目、上传代码、拉取代码】
文章目录 软件安装包安装步骤常用使用方式注意拉取项目上传代码或文件选择文件添加到本地Git存储库的缓存区将缓存区的更改提交到本地Git存储库,并设置提交信息将本地Git存储库的更新推送到远程Git仓库中上传示例拉取别人所上传的代码 常见问题上传代码失败…...
【29】c++设计模式——>策略模式
策略模式 C中的策略模式(Strategy Pattern)是一种行为型设计模式,它允许在运行时选择算法的行为。策略模式通过将算法封装成独立的类,并且使它们可以互相替换,从而使得算法的变化独立于使用算法的客户端。 策略模式通…...
2023Jenkins连接k8s
首先配置k8s config文件 1.方式获取k8s密钥 cat .kube/config 2.导出方式或者密钥 kubectl config view --raw > k8s-config-admin pipeline {agent {kubernetes {yaml apiVersion: v1kind: Podmetadata:labels:some-label: devopsspec:containers:- name: dockerimage: d…...
SpringBoot 入门 参数接收 必传参数 数组 集合 时间接收
接口声明 RestController //表示该类为请求处理类public class HttpDeal {RequestMapping("/login")//这个方法处理哪一个地址过来的请求public String hello(){return "返回给浏览器";}}接收参数 RequestMapping("/login")public String logi…...

【Qt之JSON文件】QJsonDocument、QJsonObject、QJsonArray等类介绍及使用
Qt之JSON相关类介绍 QJsonDocument常用函数枚举类型 QJsonDocument::DataValidation枚举类型 QJsonDocument::JsonFormat构造函数静态函数成员函数示例 QJsonObject常用函数构造函数:成员函数: QJsonObject 与 QVariantMap 相互转换 QJsonArray常用函数构…...

阿里云今年有双十一活动吗?不好说
阿里云今年有双十一活动吗?不好说,因为去年就没有。阿里云双11优惠活动是一项大型的促销活动,每年都有,但是去年没有双十一活动,不知道今年2023年阿里云是否有双11优惠活动。但是阿里云百科aliyunbaike.com猜想&#x…...

【驱动开发】创建设备节点、ioctl函数的使用
一、控制三盏灯的亮灭 头文件: #ifndef __HEAD_H__ #define __HEAD_H__ typedef struct{unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t; #define PHY_LED1_ADDR 0X50006000 #def…...
Tomcat启动控制台乱码问题
修改Tomcat/conf/logging.properties...

学习周总结
http://t.csdnimg.cn/DKki2 http://t.csdnimg.cn/NvudJ 项目进度 做了大概的主界面,然后做了一个客户端和服务端的分离,实现了在客户端发送的信息,在服务端能收到;客户端和服务端的制作是我之前有写的一个http://t.csdnimg.cn/…...

如何在不恢复出厂设置的情况下解锁 Android 手机密码?
当您忘记 Android 手机的密码时,可能会有压力,尤其是当您不想恢复出厂设置并删除所有数据时。但是,有一些方法可以在不诉诸如此激烈的步骤的情况下解锁手机。我们将在这篇文章中教您如何在不恢复出厂设置的情况下解锁 Android 手机密码。我们…...

移动设备管理对企业IT 安全的增强
移动设备管理 (MDM) 是通过定义策略和部署安全控制(如移动应用程序管理、移动内容管理和条件 Exchange 访问)来管理移动设备的过程。 完整的MDM解决方案可以管理在Android,iOS,Windows,macOS&a…...

app分发的一些流程
应用分发的流程通常包括以下步骤: 开发应用程序:首先,您需要开发您的应用程序。这包括编写代码、设计用户界面、测试应用程序等等。确保您的应用程序符合各个应用商店的规范和要求,以确保顺利通过审核。 准备应用材料:…...

深入浅出讲解Spring IOC和DI的区别
Spring IOC和DI的区别 一,介绍 前言 很多人都会把ioc和di说成同一个东西,其实IOC和DI虽然在概念上可以笼统地视为同一事物,但其本质上存在区别。IOC(Inverse of Control,控制反转)从容器的角度描述&#…...

文件操作 IO
文件(File) 狭义的文件: 指的是硬盘上的文件和目录 广义的文件: 泛指计算机中很多软硬件资源(操作系统中把很多硬件和软件资源抽象成了文件, 按照文件的方式同意管理) 本章内容只讨论狭义的文件 路径 绝对路径: 以c: , d: 盘符开头的路径相对路径: 以当前所在的目录为基准(…...

泵箱控制协议
安装泵箱调试电路板基于CIU32步进电机的驱动 D:\zhuoqing\window\ARM\Keil\CIU32\2026\April\TestF003PWMPIO-V1\Source\main.c AD\Test\2026\April\StepMotorDrvF003A4950V1.SchDoc 01 泵箱控制协议一、接口修改 泵箱中的接线,包括有三组线缆, 一是步进…...
)
告别手动检查!用CANoe XML测试库搞定CAN总线自动化测试(附周期/错误帧/信号检测实战代码)
CANoe XML测试库实战:构建汽车电子自动化测试框架的完整指南 在汽车电子开发领域,测试工程师每天需要面对数百个CAN报文周期检查、信号变化验证和错误帧监测等重复性工作。传统手动测试不仅效率低下,还容易遗漏关键问题。本文将展示如何利用C…...

5分钟掌握Input Leap:一套键鼠控制多台电脑的终极方案
5分钟掌握Input Leap:一套键鼠控制多台电脑的终极方案 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 还在为办公桌上多台电脑设备之间频繁切换键盘鼠标而烦恼吗?Input Leap这款…...

Path of Building PoE2:3步掌握流放之路2角色规划器的终极指南
Path of Building PoE2:3步掌握流放之路2角色规划器的终极指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 还在为《流放之路2》复杂的角色构建而烦恼吗?每次天赋加点都像在黑…...

泉盛UV-K5/K6终极自定义固件指南:解锁专业对讲机的隐藏潜能
泉盛UV-K5/K6终极自定义固件指南:解锁专业对讲机的隐藏潜能 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 你是否曾觉得手中的泉盛UV…...

百度网盘下载加速终极指南:如何用PDown免费突破限速限制
百度网盘下载加速终极指南:如何用PDown免费突破限速限制 【免费下载链接】pdown 百度网盘下载器,2020百度网盘高速下载 项目地址: https://gitcode.com/gh_mirrors/pd/pdown 你是否曾经为百度网盘的下载速度而烦恼?当你急需下载一个重…...

3个场景解锁抖音下载器:从零开始掌握高效素材收集
3个场景解锁抖音下载器:从零开始掌握高效素材收集 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

告别手动配置!利用ESPHome+巴法云MQTT桥接,优雅管理你的ESP8266设备到HA
ESPHome巴法云MQTT桥接:打造智能家居设备的工业化管理方案 当你的智能家居设备数量突破两位数时,那种为每个ESP8266单独编写Arduino代码、逐个修改YAML配置的日子就该结束了。这不是关于如何点亮第一个LED灯的教程,而是为已经跨过入门阶段&am…...

高效免费在线流程图工具:GraphvizOnline 完整使用指南
高效免费在线流程图工具:GraphvizOnline 完整使用指南 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为绘制复杂的系统架构图而烦恼吗?GraphvizOnline 是一款革命性…...

手把手教你校准ICM-20948磁力计:从‘八字法’到代码实现,解决姿态角‘指南针’不准
ICM-20948磁力计校准实战:从基础原理到三维空间校准代码实现 当你第一次拿到ICM-20948这样的9轴运动传感器时,可能会被其丰富的功能所吸引——三轴加速度计、三轴陀螺仪加上三轴磁力计,理论上可以完美解算出设备在空间中的姿态。但实际使用中…...