RDD算子操作(基本算子和常见算子)
目录
一、基本算子
1.map算子
2.flatMap算子
3.filter算子
4.foreach算子
5.saveAsTextFile算子
6.redueceByKey算子
二、常用Transformation算子
1.mapValues算子
2.groupBy算子
3.distinct算子
4.union算子
5.join算子
6.intersection算子
7.glom算子
8.groupByKey算子
9.sortBy算子
10.sortByKey算子
三、常用Action算子
1.countByKey算子
2.collect算子
3.reduce算子
4.takeSample算子
5.takeOrdered算子
四、分区操作算子
1.mapPartitions算子
2.foreachPartition算子
3.partitionBy算子
4.repartition算子和coalesce算子
一、基本算子
RDD中map、filter、flatMap及foreach等函数为最基本算子,都是都RDD中每个元素进行操作,将元素传递到函数中进行转换。
1.map算子
map(f:T=>U): RDD[T]=>RDD[U],表示将RDD经由某一函数f后,转变为另一个RDD。
功能:map算子,是将RDD的数据一条条处理(处理的逻辑 基于map算子中接受的处理函数),返回新的RDD。

#cording:utf-8
from pyspark import SparkConf,SparkContextif __name__ == "__main__":# 构建SparkContext对象conf = SparkConf().setAppName('test').setMaster("local[*]")sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6],3)# 定义方法,作为算子的传入函数体def add(data):return data * 10print(rdd.map(add).collect())# 更简单的方式 是定义lambda表达式来写匿名函数print(rdd.map(lambda data:data * 10).collect())'''对于算子的接受函数来说,两种方法都可以lambda表达式 适用于 一行代码就搞定的函数体,如果是多行,需要定义独立的方法
''' 2.flatMap算子
2.flatMap算子
flatMap(f:T=>Seq[U]): RDD[T]=>RDD[U]),表示将RDD经由某一函数f后,转变为一个新的 RDD,但是与map 不同,RDD中的每一个元素会被映射成新的0到多个元素(f 函数返回的是一个序列Seq)。
功能:对RDD执行map操作,然后进行解除嵌套操作。
#cording:utf-8
from pyspark import SparkConf,SparkContextif __name__ == "__main__":# 构建SparkContext对象conf = SparkConf().setAppName('test').setMaster("local[*]")sc = SparkContext(conf=conf)rdd = sc.parallelize(["hadoop hadoop spark","spark hadoop hadoop","hadoop flink spark"])#得到所有的单词,组成RDDrdd2 = rdd.map(lambda line: line.split(" "))rdd3 = rdd.flatMap(lambda line: line.split(" "))print(rdd2.collect())print(rdd3.collect()) 3.filter算子
3.filter算子
filter(f.T=>Bool): RDD[T]=>RDD[T],表示将 RDD经由某一函数f后,只保留f返回True的数据,组成新的RDD。
功能:过滤想要的数据进行保留,返回值是True的数据保留,返回值是False的数据则会被丢弃。

#corfding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)# 通过filter算子过滤奇数rdd = sc.parallelize((1,2,3,4,5,6,7,8,9,10))result_rdd = rdd.filter(lambda x: x % 2 == 1)print(result_rdd.collect())
4.foreach算子
foreach(func),将函数 func应用在数据集的每一个元素上,通常用于更新一个累加器,或者和外部存储系统进行交互,例如 Redis。
功能:对RDD的每一个元素,执行你提供的逻辑的操作(和map一个意思),但是这个方法没有返回值。
ps:该算子是分区(Executor)直接执行的,跳过Driver,由分区所在的Executor直接执行。

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 5, 4, 2, 3, 6])print(rdd.foreach(lambda x: 10 * x))print('----------------------------------')print(rdd.foreach(lambda x: print(10 * x)))

5.saveAsTextFile算子
saveAsTextFile(path:String),数据集内部的元素会调用其 toString方法,转换为字符串形式,然后根据传入的路径保存成文本文件,既可以是本地文件系统,也可以是HDFS等。
ps:该算子是分区(Executor)直接执行的,跳过Driver,由分区所在的Executor直接执行。
#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 5, 4, 2, 3, 6])rdd.saveAsTextFile('hdfs://pyspark01/output/out1')
6.redueceByKey算子
功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。

#cording:utf-8
from pyspark import SparkConf,SparkContextif __name__ == "__main__":# 构建SparkContext对象conf = SparkConf().setAppName('test').setMaster("local[*]")sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),('b',1),('a',1),('a',1),('b',1),('c',1),('a',1)])#使用reduceByKey函数进行聚合reduce_rdd = rdd.reduceByKey(lambda a,b : a + b).collect()print("聚合结果:",reduce_rdd)
二、常用Transformation算子
1.mapValues算子
功能:针对二元元组RDD,对其内部的二元元组的Value执行map操作。

#cording:utf-8
from pyspark import SparkConf,SparkContextif __name__ == "__main__":# 构建SparkContext对象conf = SparkConf().setAppName('test').setMaster("local[*]")sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',2),('b',11),('a',1)])#使用map函数map_rdd = rdd.map(lambda x: (x[0],x[1]*10)).collect()print("结果:",map_rdd)# 使用mapValue函数value_rdd = rdd.mapValues(lambda value: value*10).collect()print("结果:",value_rdd)
2.groupBy算子
功能:将RDD数据进行分组。

#cording:utf8from pyspark import SparkConf,SparkContextif __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)# 创建数据test_rdd = sc.parallelize([('a',1),('b',1),('a',2),('b',2),('b',3)])# 通过groupBy函数对数据进行分组# groupBy函数传入函数的意思是:通过这个函数,来确定按照谁来分组(返回谁即可)# 分组规则和SQL一致:也就是相同的在同一个组(Hash分组)result_1 = test_rdd.groupBy(lambda t: t[0])result_2 = result_1.map(lambda t: (t[0],list(t[1])))print(result_1.collect())print(result_2.collect())
3.distinct算子
功能:对RDD数据进行去重复,返回新的RDD。

#cording:utf8from pyspark import SparkConf,SparkContextif __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)rdd_1 = sc.parallelize((1,2,1,2,3,4,5,6))rdd_2 = sc.parallelize([('a',1),('b',1),('a',1),('a',1),('b',1),('c',1),('a',1)])# 使用distinct算子进行去重print('数字:',rdd_1.distinct().collect())print('元组:',rdd_2.distinct().collect())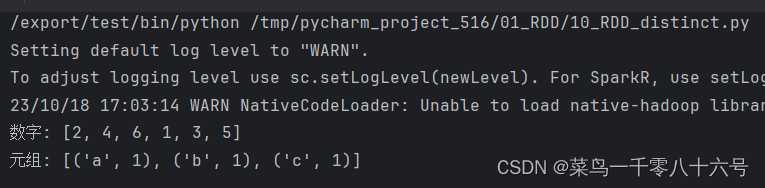
4.union算子
功能:将两个RDD合并成一个RDD返回。只合并不去重,RDD的类型不同也是可以合并的。
#corfding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)# 通过union算子合并RDDrdd_1 = sc.parallelize((1,2,3,4,5))rdd_2 = sc.parallelize((6,7,8,9,10))print(rdd_1.union(rdd_2).collect())
5.join算子
功能:对两个RDD执行join操作(可实现SQL外/内连接),join算子只能用于二元元组。

#corfding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu'),(1004,'zhaoliu')])rdd2 = sc.parallelize([(1001,'销售部'),(1002,'科技部')])# 通过join算子来进行rdd之间的关联# 对于join算子来说,关联条件按照二元元组的key来进行关联print(rdd1.join(rdd2).collect())# 左外连接,右外连接可以更换一下rdd的顺序或者调用rightOuterJoin即可print(rdd1.leftOuterJoin(rdd2).collect())
6.intersection算子
功能:求两个RDD的交集,返回一个新的RDD。
#corfding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([('a',1),('b',3)])rdd2 = sc.parallelize([('a',1),('c',1)])# 通过intersection算子求出RDD的交集 取出并返回新的RDDprint(rdd1.intersection(rdd2).collect())
7.glom算子
功能:将RDD的数据,加上嵌套,这个嵌套按照分区来进行,比如RDD数据[1,2,3,4,5]有两个分区,那么glom后,数据变成:[[1,2,3],[4,5]]。
#corfding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('test').setMaster('local[*]')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9,10])print(rdd1.glom().collect())# 解嵌套操作print(rdd1.glom().flatMap(lambda x: x).collect())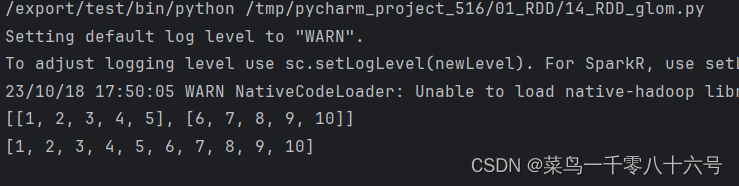
8.groupByKey算子
功能:针对KV型RDD,自动按照key分组。
#cording:utf8from pyspark import SparkConf,SparkContextif __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)# 创建数据test_rdd = sc.parallelize([('a',1),('b',1),('a',2),('b',2),('b',3)])# 使用groupByKey算子result_1 = test_rdd.groupByKey()#查看结果result_2 = result_1.map(lambda t: (t[0],list(t[1])))print(result_1.collect())print(result_2.collect())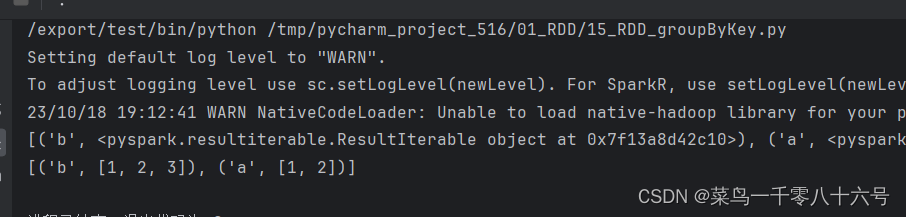
9.sortBy算子
功能:对RDD数据进行排序,基于你指定的排序依据。

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([('c',3),('f',1),('b',11),('c',3),('e',1),('n',9),('a',1)],3)# 使用sortBy对RDD执行排序# 按照value 数字进行排序# 参数1函数:表示的是,告知spark,按照数据的哪个列进行排序# 参数2:True表示升序 False表示降序# 参数3:排序的分区数'''注意:如果要全局有序,排序分区数设置为1'''print('按照value排序:',rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=3).collect())# 按照key进行排序print('按照key排序:',rdd.sortBy(lambda x: x[0], ascending=True, numPartitions=3).collect()) 10.sortByKey算子
10.sortByKey算子
功能:针对KV型RDD,按照Key进行排序

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),('E',1),('C',1),('D',1),('b',1),('g',1),('h',1),( "y" ,1),('u',1),('i',1),('o',1),('p',1),( 'm',1),('n',1),('L',1),('k',1),('f',1)],3)# 根据字母的小写排序print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: key.lower()).collect())
三、常用Action算子
1.countByKey算子
功能:统计key出现的次数(一般适用于KV型RDD)
import json
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.textFile('../input/words.txt')rdd2 = rdd.flatMap(lambda x: x.split(' ')).map(lambda x: (x,1))# 通过countByKey来对key进行计数,这是一个Action算子result = rdd2.countByKey()print(result)print(type(result))
2.collect算子
功能:将RDD各个分区的数据,统一收集到Driver中,形成一个list对象。这个算子,是将RDD各个分区数据都拉取到Driver,注意的是,RDD是分布式对象,其数据量可以很大,所以用这个算子之前,要心知肚明的了解结果数据集不会太大,不然,会把Driver内存撑爆。
3.reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合。

import json
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6])print(rdd.reduce(lambda a,b: a+b))
4.takeSample算子
功能:随机抽样RDD数据,随机数种子数字可以随便传,如果传同一个数字,那么取出的结果是一致的。一般参数三不传,spark会自动给与一个随机的种子。

from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10,1,2])print('True:',rdd.takeSample(True,22))print('False:',rdd.takeSample(False,22))print('无随机种子1:',rdd.takeSample(True,5))print('无随机种子2:', rdd.takeSample(True, 5))print('有随机种子1:',rdd.takeSample(True,5,1))print('有随机种子2:', rdd.takeSample(True, 5, 1))

5.takeOrdered算子
功能:对RDD进行排序取前N个。

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,5,4,2,3,6])print('普通:',rdd.takeOrdered(3))# 函数操作只会对结果产生影响,不会影响数据本身print("传入函数:",rdd.takeOrdered(3, lambda x: -x))
四、分区操作算子
1.mapPartitions算子
功能:与map功能相似,但区别是,mapPartition一次被传递的是一整个分区的数据,是作为一个迭代器(一次性list)对象传入过来,而map是一个一个数据的传递。
#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 5, 4, 2, 3, 6],3)def process(iter):result = list()for it in iter:result.append(it * 10)return result# mapPartitions算子相比于map算子,节省了大量打IO操作,每一个分区只需要进行一次IO操作即可print('输出结果:',rdd.mapPartitions(process).collect())
2.foreachPartition算子
功能:和普通的foreach一致,一次处理的是一整个分区的数据。
#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 5, 4, 2, 3, 6],3)def process(iter):result = list()for it in iter:result.append(it * 10)print(result)rdd.foreachPartition(process)

3.partitionBy算子
功能:对RDD进行自定义分区操作。

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([('hadoop',1),('hadoop',1),('hello',1),('spark',1),('flink',1),('spark',1)])# 使用partitionBy自定义分区def process(x):if 'hadoop' == x or 'hello' == x:return 0if 'spark' == x:return 1return 2# 使用glom算子将每个分区的数据进行嵌套print('显示分区:',rdd.partitionBy(3, process).glom().collect())

4.repartition算子和coalesce算子
功能:对RDD的分区执行重新分区(仅数量)
ps:对分区的数量进行操作,一定要慎重,一般情况下,我们写Spark代码除了要求全局排序设置为1个分区外多数时候,所有API中关于分区相关的代码我们都不太理会。因为,如果你改分区了,会影响并行计算(内存迭代的并行管道数量)后面学分区如果增加,极大可能导致shuffle。

#cording:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('test')sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 5, 4, 2, 3, 6],3)# repartition 修改分区# 减少分区print("减少分区为1:",rdd.repartition(1).getNumPartitions())# 增加分区print("增加分区为5:", rdd.repartition(5).getNumPartitions())# coalesce 修改分区# 减少分区print("减少分区为1:",rdd.coalesce(1).getNumPartitions())# 增加分区 ps:coalesce增加分区数量需要指定参数shuffle为True才能1成功修改print("减少分区为5:", rdd.coalesce(5).getNumPartitions())print("减少分区为5:",rdd.coalesce(5, shuffle=True).getNumPartitions())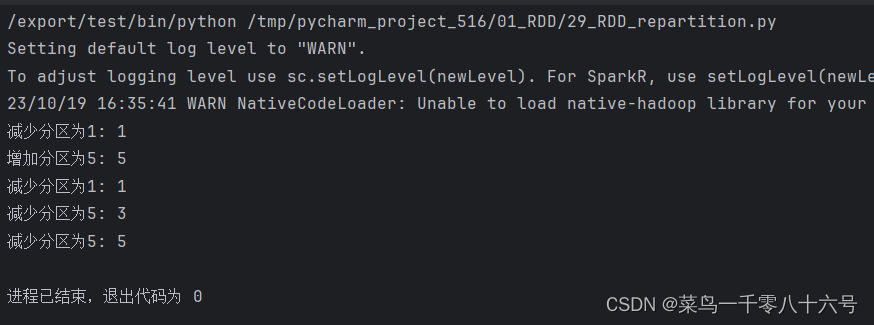
相关文章:
RDD算子操作(基本算子和常见算子)
目录 一、基本算子 1.map算子 2.flatMap算子 3.filter算子 4.foreach算子 5.saveAsTextFile算子 6.redueceByKey算子 二、常用Transformation算子 1.mapValues算子 2.groupBy算子 3.distinct算子 4.union算子 5.join算子 6.intersection算子 7.glom算子 8.groupByKey算…...

互联网Java工程师面试题·Java 面试篇·第五弹
目录 79、适配器模式和装饰器模式有什么区别? 80、适配器模式和代理模式之前有什么不同? 81、什么是模板方法模式? 82、什么时候使用访问者模式? 83、什么时候使用组合模式? 84、继承和组合之间有什么不同&#…...

常见的测试理论面试问题
请解释软件生存周期是什么? 软件生存周期是指从软件开发到维护的过程,包括可行性研究、需求分析、软件设计、编码、测试、发布和维护等活动。这个过程也被称为“生命周期模型”。 软件测试的目的是什么? 软件测试的目的是发现软件中的错误…...

把JS中的map方法玩出花来
一 map是什么 map(callbackFn) map(callbackFn, thisArg)map() 方法是一个迭代方法。它为数组中的每个元素调用一次提供的 callbackFn 函数,并用结果构建一个新数组。 参数 callbackFn 数组中的每个元素执行的函数。它的返回值作为一个元素被添加为新数组中。该…...
)
液晶显示计算器(延时程序)
#include "delay.h" /*------------------------------------------------ uS延时函数,含有输入参数 unsigned char t,无返回值 unsigned char 是定义无符号字符变量,其值的范围是 0~255 这里使用晶振12M,精确延时请…...

线性代数2:梯队矩阵形式
图片来自 Europeana on Unsplash 一、前言 欢迎阅读的系列文章的第二篇文章,内容是线性代数的基础知识,线性代数是机器学习背后的基础数学。在我之前的文章中,我介绍了线性方程和系统、矩阵符号和行缩减运算。本文将介绍梯队矩阵形式…...
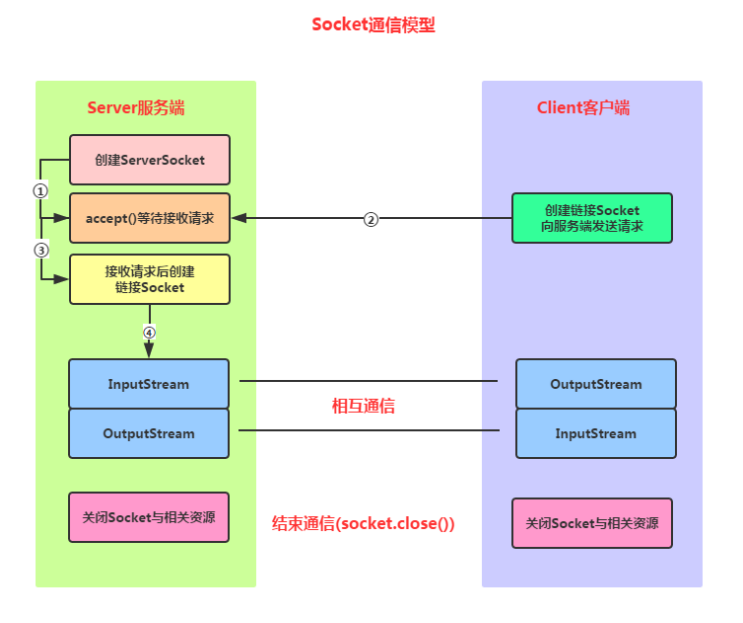
【JavaEE】网络编程(网络编程基础、Socket套接字)
一、网络编程基础 1.1、什么是网络编程? 网络编程,指网络上的主机,通过不同的进程,以编程的方式实现网络通信(或称为网络数据传输) 注意:我们只要满足进程不同就行;所以即便是同一…...

Node学习笔记之模块化
一、介绍 1.1 什么是模块化与模块 ? 将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为 模块化 其中拆分出的 每个文件就是一个模块 ,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他 模块使用 1…...

用matlab求解线性规划
文章目录 1、用单纯形表求解线性规划绘制单纯形表求解: 2、用matlab求解线性规划——linprog()函数问题:补充代码:显示出完整的影子价格向量 1、用单纯形表求解线性规划 求解线性规划 m i n − 3 x 1 − 4 x 2 x 3 min -3x_1-4x_2x_3 min−…...
)
antd获取/更改form表单数据(表单域数据)
创建ref引用 formRef React.createRef();表单和ref绑定 //ref{this.formRef} 先给Form <Form ref{this.formRef} name"control-ref" onFinish{this.onFinish}><Form.Item name"name" label"Name" rules{[{ required: true }]}>…...

Go学习第三章——运算符与进制
Go学习第三章——运算符与进制 1 算术运算符2 关系运算符3 逻辑运算符4 赋值运算符5 其他运算符5.1 位运算符5.2 跟指针有关的运算符 6 运算符的优先级7 获取用户终端输入8 进制转换8.1 进制基本使用8.2 进制之间的转换8.3 原码 反码 补码8.4 位运算符详解 运算符是—种特殊的符…...
H3C IMC dynamiccontent.properties.xhtm 远程命令执行
我举手向苍穹,并非一定要摘星取月,我只是需要这个向上的、永不臣服的姿态。 构造payload: /imc/javax.faces.resource/dynamiccontent.properties.xhtml pfdrtsc&lnprimefaces&pfdriduMKljPgnOTVxmOB%2BH6%2FQEPW9ghJMGL3PRdkfmbii…...
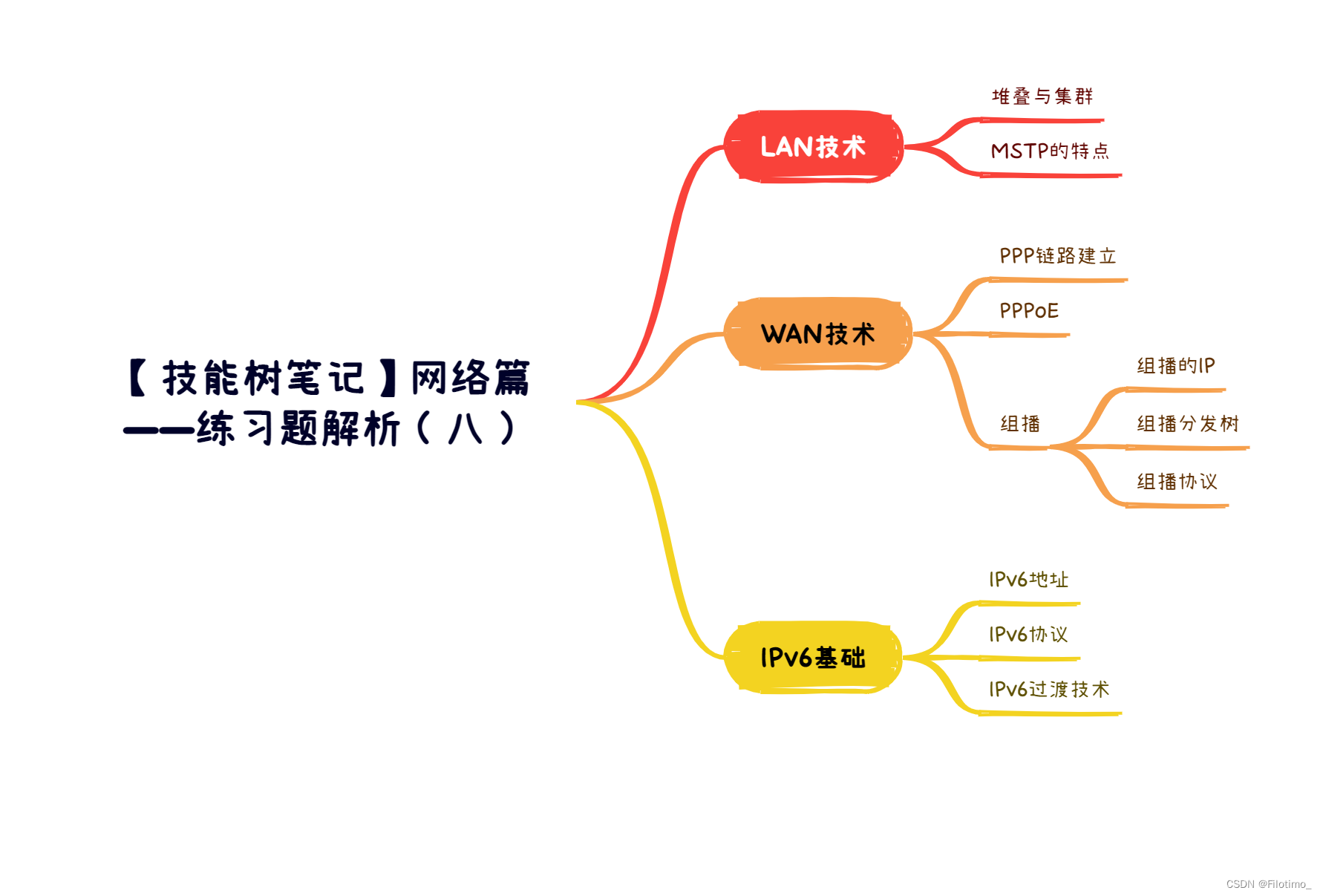
【技能树笔记】网络篇——练习题解析(八)
目录 前言 一、LAN技术 1.1 堆叠与集群 1.2 MSTP的特点 二、WAN技术 2.1 PPP链路建立 2.2 PPPoE 2.3 组播 2.3.1 组播的IP 2.3.2 组播分发树 2.3.3 组播协议 三、IPv6基础 3.1 IPv6地址 3.2 IPv6协议 3.3 IPv6过渡技术 总结 🌈嗨!我是Filotimo__…...
)
laravel框架介绍(二)
方法1.windows 可以直接下载 Composer-Setup.exe 方法2.配置php.exe目录环境变量,下载 composer.phar和php.exe平级目录, 新建 composer.bat 文件编辑以下内容 php "%~dp0composer.phar" %* 运行composer.bat ,出现版本号为成功 执行 composer self-update 以保持 Co…...

USB学习(1):USB基础之接口类型、协议标准、引脚分布、架构、时序和数据格式
连接计算机外围设备最简单的方法是通过USB(通用串行总线)。USB是即插即用接口,可以将扫描仪、打印机、数码相机、闪存驱动器等计算机外围设备连接到计算机上。本篇文章就来介绍一下USB的一些基础知识,包括。 文章目录 1 接口类型和标准规范2 引脚分布3 …...

less和scss语法详解
比较好的博客文章:Less使用语法(详细):https://blog.csdn.net/weixin_44646763/article/details/114193426 SCSS基本语法:https://www.jianshu.com/p/4efaac23cdb6 总结:我理解的点: 1、符号声…...
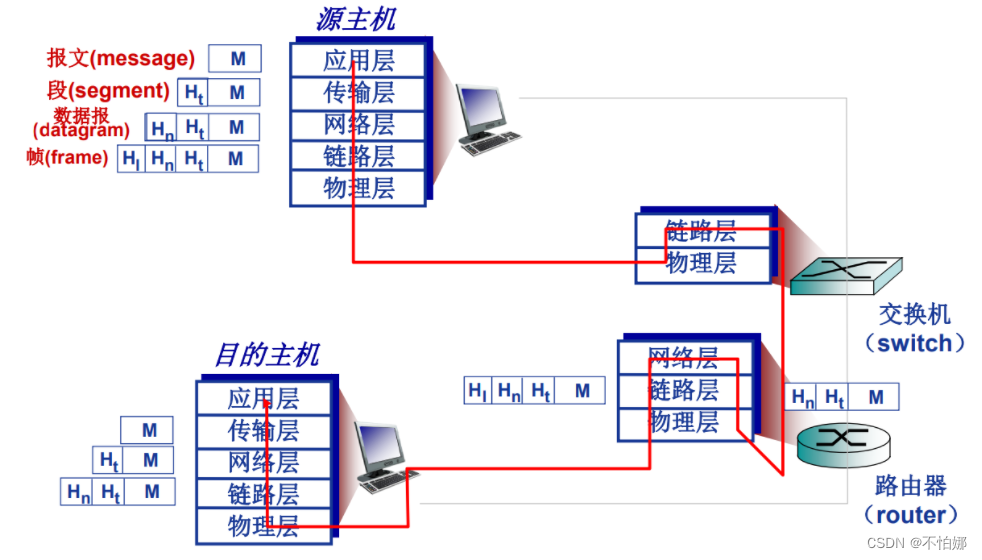
【计算机网络笔记】TCP/IP参考模型基本概念,包括五层参考模型
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

RSA加密与签名的区别
文章目录 一、签名验签原理二 RSAUtils 工具类三、通过x509Certificate来获取CA证书的基本信息四、 通过公钥获取公钥长度 一、签名验签原理 签名的本质其实就是加密,但是由于签名无需还原成明文,因此可以在加密前进行哈希处理。所以签名其实就是哈希加…...

arcgis js api 4.x通过TileLayer类加载arcgis server10.2发布的切片服务跨域问题的解决办法
1.错误复现 2.解决办法 2.1去https://github.com/Esri/resource-proxy 网站下载代理配置文件,我下载的是最新的1.1.2版本,这里根据后台服务器配置情况不同有三种配置文件,此次我用到的是DotNet和Java. 2.2 DotNet配置 2.2.1 对proxy文件增加…...

如何让chatGPT给出高质量的回答?
如何让chatGPT给出高质量的回答? ChatGPT从入门到进阶教程合集_哔哩哔哩_bilibili 公式 【指令词】【背景】【输入】【输出要求】 1. 指令词 ——精准任务or命令 如:简述、解释、翻译、总结、润色 2. 背景 ——补充信息 如:简述一篇讲解…...

Windows右键菜单管理终极指南:3分钟告别杂乱菜单,效率翻倍
Windows右键菜单管理终极指南:3分钟告别杂乱菜单,效率翻倍 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否厌倦了每次右键点击文件…...

window环境下使用类似tail的命令跟踪滚动的日志
可以,而且有好几种方法,Windows 上完全能实现类似 Linux tail -f 滚动看日志的效果。1)最简单:PowerShell 自带(不用装软件)实时滚动刷新日志:powershellGet-Content app.log -Wait -Tail 20-Wa…...

从手动压枪到智能补偿:罗技鼠标宏如何革新绝地求生射击体验
从手动压枪到智能补偿:罗技鼠标宏如何革新绝地求生射击体验 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这类战术竞…...

探索当前主流配送算法的运作方式
就我了解的而言,目前主流配送平台主要依赖强化学习(RL)、深度神经网络(DNN)和图神经网络(GNN)等技术来优化订单匹配与派单策略。强化学习模型用于模拟配送场景,通过不断试错训练出最…...

打开 Word 提示环境变量错误怎么办?一文讲清注册表修复方法
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

TMSpeech:5分钟配置Windows本地实时语音转文字终极指南
TMSpeech:5分钟配置Windows本地实时语音转文字终极指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 想要一个完全免费、无需联网的实时语音转文字工具吗?TMSpeech正是你需要的解决方案。这…...

从原理到实战:深度相机在机器人避障中的核心算法解析
1. 深度相机如何成为机器人的"火眼金睛" 第一次接触深度相机时,我被它输出的彩色点云图震撼到了——就像给机器人装上了孙悟空的火眼金睛,普通摄像头只能看到平面图像,而深度相机却能直接"看"到物体的远近。这种三维视觉…...

没带手表那天我反而跑顺了:找回你的“自动负载均衡”
没记录的汗水,是不是就白流了?老马今天跟你聊聊咱们这个系列的最后一篇:脱表。一个周末,我起了个大早,换好衣服穿好跑鞋,习惯性地拿起手表准备出门。结果一按屏幕——黑的,昨晚忘充电了。按说这…...
)
从一笔转账看懂银行账务:客户、账户、科目与总账的完整数据流转(附实操SQL)
从一笔转账透视银行账务系统的技术架构与数据流转 当你在手机银行点击"确认转账"按钮时,系统背后发生了什么?这个看似简单的操作,实际上触发了一场精密的数据交响乐。作为金融科技从业者,理解资金在银行系统中的完整流转…...

SAP PP实战:MRP Area怎么用?手把手教你按产线、委外供应商拆分物料计划
SAP PP实战:MRP Area精细化物料计划管理指南 引言 在制造业生产计划管理中,物料需求计划(MRP)的精确性直接影响着生产效率与成本控制。传统以工厂为单位的MRP运行模式往往难以应对复杂生产环境下的精细化需求——当多条产线并行运…...