用 pytorch 训练端对端验证码识别神经网络并进行 C++ 移植
文章目录
- 前言
- 安装
- 安装 pytorch
- 安装 libtorch
- 安装 opencv(C++)
- 准备
- 数据集
- 获取训练数据
- 下载
- 标定
- 编码
- 预分析
- 数据集封装格式
- 神经网络搭建
- 神经网络训练
- 神经网络测试
- 神经网络预测
- C++ 移植
- 模型转换
- 通过跟踪转换为 Torch Script
- 通过注解转换为 Torch Script
- 编写 C++ 代码
- 编译环境搭建
- C++ 库管理
- 方法一:手动配置 visual studio 环境
- 方法二:cmake 配置环境
- python 调用 C++ 程序
前言
训练和测试验证码来自中南大学教务系统登录验证码:http://csujwc.its.csu.edu.cn/
部分代码参考自该 github 项目:dee1024/pytorch-captcha-recognition
标记好的训练数据:
链接:https://pan.baidu.com/s/1xGmvY8FuKm9jP2HW48wI3A
提取码:fana
训练好的神经网络模型( TrainNetwork.py 得到的模型):
链接:https://pan.baidu.com/s/1-cZCLNuYs-1MOu1NI42UOw
提取码:4wsv
环境:
- 操作系统:Windows 10
- CPU:Intel i5-9300
- GPU:GTX 1650
- 深度学习框架:pytorch 1.6,libtorch 1.6
- CUDA 11
- python 3.8
- opencv 4.4.0(C++)
- visual studio 2019
安装
安装 pytorch
pytorch 是 torch 的 python 版本,也是我们常用的深度学习框架。
首先进入官网:https://pytorch.org/
在安装栏根据自己的环境配置选择相应的 pytorch 版本,获得安装指令。

例如 Windows 的 pip 安装:在命令行输入
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
后回车等待一段时间即可完成安装。
如何查看 CUDA 版本?
如果是英伟达的显卡,打开英伟达显卡的控制面板。点击 系统信息 -> 组件,即可看到 CUDA 版本。
例如我的电脑的 CUDA 版本为 11.0.228,但是安装低版本 CUDA (10.1) 的 pytorch 也同样可以使用。

安装 libtorch
libtorch 是 torch 的 C++ 版本。libtorch 的版本必须与 pytorch 一致!
同样是 pytorch 的安装栏,Package 选择 libtorch,Langugae 选择 C++/Java。
获得如下的下载链接:

我选择的是 Release version,点击相应链接下载完毕后解压在合适的目录下。
安装 opencv(C++)
opencv 主要用来进行 C++ 程序的图像处理。
和 libtorch 安装类似,在下载页面 https://opencv.org/releases/ 选择相应的操作系统。例如选择 Windows 系统,跟随安装程序选择合适的安装目录即可完成安装。
准备
该项目使用到的需要额外安装的 python 库:
numpyrequestsmatplotlib:绘图skimage:负责图像处理
新建一个目录,在目录下新建:
TrainImages 目录:存放训练数据TestImages 目录:存放检验数据Network.py:神经网络定义code.py:编码规则Dataset.py:数据集定义TrainNetwork.py:神经网络训练TestNetwork.py:神经网络测试
数据集
获取训练数据
下载
采用 python 脚本进行批量下载,下载的图片用时间戳命名。
提供一个下载脚本,将其复制到项目的主目录再运行:
import requests
import timeCaptchaUrl = 'http://csujwc.its.csu.edu.cn/verifycode.servlet'
root = '.\\TrainImages\\' #图片保存目录
DownloadNumber = 0def GetOneCaptcha(time_label):global DownloadNumbertry:r = requests.get(CaptchaUrl)r.raise_for_status()with open(root + '_' + time_label + '.png','wb') as f:f.write(r.content)DownloadNumber = DownloadNumber + 1except:passdef Download(CaptchaNumber):while(DownloadNumber < CaptchaNumber):GetOneCaptcha(str(int(time.time()*1000)))print("已下载 {0:>4} 个".format(DownloadNumber),end = '\r')print("\n下载完毕")if __name__ == "__main__": Download(100) #下载100张
标定
人工标记(自己标定了600多张,眼睛都要花了),标记的效果大概这样:

编码
预分析
经过大量验证码数据分析可以得出中南大学教务系统验证码具有如下规律:
- 包含四个字符
- 字符分为小写英文字母和数字
- 数字包括 1,2,3
- 英文字母包括 b,c,m,n,v,x,z
所以神经网络需要对一个字符作十分类,总共四个字符,输出包含四十个元素的一维特征向量。

端对端神经网络输入图片直接输出结果,输出的每10个元素中最大的(代表概率最大)为神经网络的预测字符。
code.py 文件内容如下,负责 array 类型和字符串类型的转换。
import numpy as npchar_table = ['1', '2', '3', 'b', 'c', 'm', 'n', 'v', 'x', 'z']def encode(raw_string): # 编码out_code = np.zeros(40)for i, c in enumerate(raw_string):out_code[i * 10 + char_table.index(c)] = 1return out_codedef decode(raw_code): # 解码out_string = ''raw_code = raw_code.reshape(4, 10)raw_code = np.argmax(raw_code, 1)for i in raw_code:out_string += char_table[i]return out_string
例程:
string = 'mn3z'
code = encode(string)
string = decode(code)
print(code)
print(string)
运行结果:
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 1. 0.0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
mn3z
数据集封装格式
Dataset.py 文件内容如下,自己定义的数据集需要继承 pytorch 的 torch.utils.data.Dataset 类,而且必须重写 __len__ 和 __getitem__ 方法。
-
__init__:folder参数为数据集所在的目录名称,transform参数为数据的变换方式,这里为转换Tensor类型。train_image_file_paths为含有目录内所有图片路径的列表。
-
__len__:获取数据集长度。根据前面的获取的train_image_file_paths即可知道数据集长度。 -
__getitem__:根据索引获取数据,类似于列表。返回包含Tensor类型数据的元组。-
skimage.io.imread()为skimage库的图像读取函数,as_grey参数表示是否转换为灰度图(即图片三通道转单通道)。 -
skimage.transform.resize()为skimage库的图像变形函数,在这里图像被变形为 45x45 大小。- 注意:如果使用其他图像处理库(例如
Pillow)的图像变形函数得出的图像可能不一样,最好在训练,测试,预测时统一使用一个图像处理库。
- 注意:如果使用其他图像处理库(例如
-
label为图片的标签编码,例如图片1b13_1589636262331.png通过split('_')[0]即可得到标签,在经过前面提到的encode()函数编码。 -
输出的
Tensor类型数据通过.float()方法全部转为浮点型。
-
-
torch.utils.data.Dataloader为 pytorch 的数据集装载方法,数据集必须经过装载才能输入进神经网络。batch_size参数为小批量训练每批的大小(pytorch 采用小批量训练),shuffle参数表示是否打乱数据集。 -
get_train_data_loader()和get_test_data_loader()函数用来获取训练集和测试集,通过batch_size参数定义批量大小。
import os
import torch
from torch.utils.data import DataLoader,Dataset
import torchvision.transforms as transforms
from skimage import io,transform
import codeclass mydataset(Dataset):def __init__(self, folder, transform=None):self.train_image_file_paths = [os.path.join(folder, image_file) for image_file in os.listdir(folder)] #获取含有目录内所有图片路径的列表self.transform = transformdef __len__(self):return len(self.train_image_file_paths)def __getitem__(self, idx):image_root = self.train_image_file_paths[idx] #图片路径image_name = image_root.split(os.path.sep)[-1] #图片名称image = io.imread(image_root,as_gray = True) #读取图片并转为灰度图image = transform.resize(image,(45,45)) #将图片转为 45x45 大小if self.transform is not None:image = self.transform(image) #转换图片label = code.encode(image_name.split('_')[0]) #编码return image.float(), torch.from_numpy(label).float()Transform = transforms.Compose([transforms.ToTensor() #转换为 Tensor 类型
])def get_train_data_loader(batch_size = 16): #获取训练集dataset = mydataset('.\\TrainImages', transform = Transform)return DataLoader(dataset, batch_size, shuffle = True)def get_test_data_loader(batch_size = 1): #获取测试集dataset = mydataset('.\\TestImages', transform = Transform)return DataLoader(dataset, batch_size, shuffle = True)
神经网络搭建
神经网络的总体结构如图,为典型的 CNN 网络。
该 CNN 网络部分结构与 AlexNet 相似,输入N x 45 x 45(N 为输入图片个数)的灰度图像,前向环节按照从左到右顺序分别是卷积层,池化层,卷积层,池化层,全连接层。其中,图像经过卷积层后还要经过批归一化,经过池化层后采用 ReLU 作为激活函数。在训练时加入了 Dropout 环节以增强神经网络的泛化能力。
输出 N x 40(N 为输入图片个数)one - hot 标签,每 10 个元素为一组代表一个字符,这 10 个元素代表了每个类别的概率,后续需要经过处理来输出最终的结果。


Network.py 文件内容如下,自己定义的神经网络需要继承 pytorch 的 torch.nn.Module 类。而且必须重写 __init__ 和 forward 方法。
-
__init__:负责神经网络的初始化,num_class和num_char分别为字符种类数和字符个数,由上分析可知分别为 10 和 4。下面的一些方法涉及到深度学习的知识,最好有相关的基础。-
torch.nn.Sequential():pytorch 的一个封装神经网络环节的方法。 -
torch.nn.Conv2d():卷积层。 -
torch.nn.BatchNorm2d():批归一化层。请参考该博客:https://blog.csdn.net/vict_wang/article/details/88075861
-
torch.nn.Dropout(0.5)在 Dropout 环节中,神经网络将每个隐藏神经元的输出设置为零(概率为 0.5)。 以这种方式“脱落”的神经元不会对前向传播做出贡献,也不会参与反向传播。
因此,每次出现输入时,神经网络都会对不同的体系结构进行采样,但是所有这些体系结构都会共享权重。由于神经元不能依靠特定其他神经元的存在,因此该技术减少了神经元的复杂共适应。 因此,它被迫学习更强大的功能,这些功能可与其他神经元的许多不同随机子集结合使用。
-
torch.nn.MaxPool2d()池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出,最大池化函数给出相邻矩形区域内的最大值。不管采用什么样的池化函数,当输入作出少量平移时,池化能够帮助输入的表示近似不变。对于平移的不变性是指当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。
-
torch.nn.RELU()在神经网络中,线性整流作为神经元的激活函数,定义了该神经元在线性变换之后的非线性输出结果。换言之,对于进入神经元的来自上一层神经网络的输入向量,使用线性整流激活函数的神经元会输出
m a x ( 0 , w T x + b ) max(0,w^Tx+b) max(0,wTx+b)
至下一层神经元或作为整个神经网络的输出(取决现神经元在网络结构中所处位置)。 -
torch.nn.Linear全连接层在整个卷积神经网络中起到 “分类器”的作用。全连接层连接前面卷积池化后得到的所有特征,将输出值赋予分类器。
-
-
forward:神经网络的前向传播,正是通过该方法神经网络把输入进的图片数据转换为输出向量(即识别结果)。pytorch 要求输入的数据维度为 N x C x H x W,N:输入的图片个数,C:图片的通道数。
#神经网络定义import torch
import torch.nn as nnclass Net(nn.Module):def __init__(self,num_class = 10,num_char = 4):super(Net,self).__init__()self.num_class = num_class #标签个数self.num_char = num_char #字符个数self.conv1 = nn.Sequential(nn.Conv2d(1,16,6),nn.BatchNorm2d(16),nn.Dropout(0.5),nn.MaxPool2d(2,2),nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(16,8,3),nn.BatchNorm2d(8),nn.Dropout(0.5),nn.MaxPool2d(2,2),nn.ReLU())self.fc = nn.Linear(8*9*9,self.num_class*self.num_char)def forward(self,x):x = self.conv1(x)x = self.conv2(x)x = x.view(x.size(0),-1)x = self.fc(x)return x
神经网络训练
TrainNetwork.py 文件内容如下,负责神经网络的训练。
-
num_epochs:训练轮数,即重复输入训练集的次数。 -
learning_rate:学习率,梯度下降法里的重要参数,越小梯度下降越慢,太大会导致神经网络发散。 -
torch.device:pytorch 的设备设置,表示数据是在 CPU 上计算还是在 GPU 上计算。通过
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')获取电脑的可用设备。通过
.to(device)方法将数据或神经网络模型移动到设定好的设备上,例如移动到 GPU 上就可以加快神经网络的训练速度。 -
训练时要将神经网络置于训练模式:
.train(),此时神经网络的 Dropout 环节会开启。 -
torch.nn.MultiLabelSoftMarginLoss:多标签分类损失函数,参数为神经网络的预测标签和图片实际标签。通过预测出的数据和实际数据的差异计算出损失值,损失值代表了神经网络预测的准确性。越小神经网络在数据集上的准确性表现得越好。数学形式如下:
l o s s ( x , y ) = − ∑ i y [ i ] ∗ log ( ( 1 + e x p ( − x [ i ] ) ) − 1 ) + ( 1 − y [ i ] ) ∗ log ( e x p ( − x [ i ] ) 1 + e x p ( − x [ i ] ) ) ) loss(x,y)=-\sum_i{y[i]*\log{((1+exp(-x[i]))^{-1})}}+(1-y[i])*\log{}(\frac{exp(-x[i])}{1+exp(-x[i])})) loss(x,y)=−i∑y[i]∗log((1+exp(−x[i]))−1)+(1−y[i])∗log(1+exp(−x[i])exp(−x[i]))) -
torch.optim.Adam:Adam 优化算法,参数为神经网络的参数cnn.parameters()和学习率learning_ratepytorch 可以自动进行梯度计算。神经网络每进行一次损失值计算,优化器清空保存的梯度然后执行后向传播得到新的梯度,并基于此执行优化算法。
请参考该博客:https://www.cnblogs.com/yifdu25/p/8183587.html
-
torch.save(cnn.state_dict(), ".\\model.pt"):保存神经网络的部分数据
import torch
import torch.nn as nn
from torch.autograd import Variable
import Dataset
import code
from Network import Net#训练参数
num_epochs = 30 #训练轮数
learning_rate = 0.001 #学习率def main():device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')cnn = Net() #初始化神经网络cnn.to(device) cnn.train() #训练模式print('初始化神经网络')criterion = nn.MultiLabelSoftMarginLoss() #损失函数optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate) #优化器#训练神经网络train_dataloader = Dataset.get_train_data_loader(batch_size=16)for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_dataloader):images = Variable(images).to(device)labels = Variable(labels.float()).to(device)predict_labels = cnn(images)loss = criterion(predict_labels, labels)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 10 == 0:print("当前轮数:", epoch, "当前步数:", i, "损失值:", loss.item())if (i+1) % 20 == 0:torch.save(cnn.state_dict(), ".\\model.pt")print("保存模型")torch.save(cnn.state_dict(), ".\\model.pt")print("保存最后的模型")if __name__ == '__main__':main()
运行结果:
初始化神经网络
当前轮数: 0 当前步数: 9 损失值: 0.3719463050365448
当前轮数: 0 当前步数: 19 损失值: 0.3350425958633423
保存模型
当前轮数: 0 当前步数: 29 损失值: 0.30613207817077637
………………
当前轮数: 29 当前步数: 9 损失值: 0.006565847899764776
当前轮数: 29 当前步数: 19 损失值: 0.002701024990528822
保存模型
当前轮数: 29 当前步数: 29 损失值: 0.005611632019281387
保存最后的模型
神经网络测试
TestNetwork.py 文件内容如下,负责神经网络训练后的测试。
将神经网络的输出标签和图片实际标签比较得出神经网络的识别是否正确,在比较时需要通过 code.decode(predict_label.data.numpy()) 将神经网络的输出结果(Tensor 类型)转换字符串形式。
测试时要将神经网络置于计算模式:.eval(),此时神经网络的 Dropout 环节会关闭。
import torch
import Dataset
from Network import Net
import codedef test_network(dataloader):net = Net() #初始化神经网络net.load_state_dict(torch.load('.\\model.pt')) #加载模型net.eval() #计算模式output_list = [] #存放预测结果for i, (image, label) in enumerate(dataloader):predict_label = net(image)label = code.decode(label.data.numpy())predict_label = code.decode(predict_label.data.numpy())if predict_label == label:output_list.append(1)else:output_list.append(0)if (i+1)%10 == 0:acc = sum(output_list) / len(output_list)print("{} 张正确率:{} %".format(i+1,acc*100))acc = sum(output_list) / len(output_list)print("总正确率:{} %".format(acc*100))if __name__ == '__main__':test_network(Dataset.get_test_data_loader(batch_size=1))#获取测试集运行结果:
10 张正确率:100.0 %
20 张正确率:100.0 %
30 张正确率:100.0 %
………………
170 张正确率:98.82352941176471 %
180 张正确率:98.88888888888889 %
190 张正确率:98.94736842105263 %
200 张正确率:99.0 %
总正确率:99.0 %
可以看到正确率已经非常高了。
神经网络预测
由于有现成的验证码 URL,所以采用在线预测。提供一个预测脚本:
# pytorch 预测import torch
from skimage import io,transform,color
from Network import Net
import matplotlib.pyplot as plt
import codedef predict(img_path): net = Net()net.load_state_dict(torch.load('.\\model.pt'))net.eval()for i in range(25):img = io.imread(img_path)plt.subplot(5,5,i+1)plt.imshow(img)img = color.rgb2gray(img)img = transform.resize(img,(45,45))img = torch.from_numpy(img).float().view(1,1,45,45)out = net(img).view(1,-1).data.numpy()output = code.decode(out)plt.title(output)plt.axis('off')plt.show()if __name__ == '__main__': predict('http://csujwc.its.csu.edu.cn/verifycode.servlet')
神经网络输入单个图片时同样也要进行图像处理转换为 1 x 1 x 45 x 45 的维度。
这里调用了 matplotlib 库来同时显示图片和预测结果。
预测结果如下:

C++ 移植
pytorch 进行神经网络的搭建和训练固然很方便,但是当部署到实际中来时就显得效率一般。例如网络爬虫需要识别验证码以进行登录,运行 python 程序的话光是加载 torch 库就要花一段时间,这对于不需要一次进行大量图片识别的网络爬虫是一种拖累。所以需要编写 C++ 程序来加载神经网路模型以提高程序运行的效率。
部分来自官方教程:https://pytorch.org/tutorials/advanced/cpp_export.html
模型转换
pytorch 提供了一种统一的模型描述语言 Torch Script 供其他编程语言程序加载,下面介绍两种将我们训练出来的模型转换为 Torch Script 的方法,也可以参考这篇博客:https://blog.csdn.net/xxradon/article/details/86504906
通过跟踪转换为 Torch Script
将模型的实例以及示例输入传递给 torch.jit.trace 函数。
这个方法适用于对任意类型输入有固定格式输出的神经网络。
import torch
from Network import Netnet = Net()
net.load_state_dict(torch.load('.\\model.pt'))
example = torch.rand(1, 1, 45, 45)
scrpit_net = torch.jit.trace(net,example)
script_net.save('.\\model_script.pt')
跟踪器有可能生成警告,因为有就地赋值(torch.rand())。
通过注解转换为 Torch Script
这个方法适用于对不同类型输入有不同格式输出的神经网络。
import torch
from Network import Netnet = Net()
net.load_state_dict(torch.load('.\\model.pt'))
scrpit_net = torch.jit.script(net)
script_net.save('.\\model_script.pt')
编写 C++ 代码
源.cpp 文件内容如下,调用了 opencv 库和 libtorch 库。
-
decode()解码函数,类似于前面 python 的解码函数。 -
C++ 程序通过主函数的入口参数
argc(参数个数) 和argv[](参数集) 获取传入程序的参数,例如在windows 命令行中输入:program.exe arg1 arg2即可向程序传入两个参数:
arg1和arg2,在程序中读取argv[0]和argv[1]即可知道这两个参数的值。在本程序中传入的参数为前面保存的神经网络模型的路径和图片的路径。
-
torch::jit::script::Module module = torch::jit::load(argv[1])通过模型路径读取模型并创建神经网络,十分简便。 -
cv::imread()为 opencv 的图像读取函数,输入图片路径即可返回Mat类型的图像数据矩阵。 -
cv::resize()为 opencv 的图像变形函数,在这里使图片变形为 45 x 45。 -
cv::cvtColor()为 opencv 的图像色域改变函数,opencv 读取的图像通道和我们常见的 RGB 通道不同,它是 BGR,在这里我们只需要将它转变为单通道(即灰度图)。 -
image.convertTo(image, CV_32FC1);为Mat类型的数据类型转换方法,在这里转换为32为浮点型单通道。因为在前面的 pytorch 节我们知道输入给神经网络的Tensor类型的数据都经过.float()方法转换为了32位浮点型。 -
cv::vconcat()为 opencv 的图像拼接函数,在这里是在图像个数维上进行拼接。 -
使用
write标记images变量是否已赋值,因为我们要将所有的输入图片拼接成一个整体再转换为 Tensor 传给神经网络以加快程序运行速度。 -
torch::from_blob()为 libtorch 提供的Mat类型转Tensor类型的函数接口,我们可以看到最终输入给神经网络的数据维度为 N x 1 x 45 x 45 (N 为图片个数),和前面的 pytorch 输入一致。 -
std::vector<torch::jit::IValue> inputs;inputs.push_back(input_tensors);auto outputs = module.forward(inputs).toTensor();这三条语句为我在网上查到的一种固定写法,大概是要将
Tensor类型的数据放在一种叫向量的数据结构里才能传递给神经网络。 -
最总通过
std::cout直接输出识别结果,多图片时输出结果以单空格隔开。
也不知道为什么,发现把模型置于计算模式时(module.eval();)输出结果是错误的。
/*
神经网络调用程序,根据命令行参数直接输出识别结果,可一次识别多张,上限100张
参数顺序:神经网络模型路径,图片1路径,……,图片n路径
*/#include <torch/script.h>
#include <opencv2/opencv.hpp>
#include <iostream>
#include <memory>std::string decode(at::Tensor code) //解码函数
{int char_num = 4; //字符个数int a;std::string str = ""; //输出字符串std::string table[10] = {"1", "2", "3", "b", "c", "m", "n", "v", "x", "z"}; //编码对照表code = code.view({ -1, 10 });code = torch::argmax(code, 1);for (int i = 0; i < char_num; i++){a = code[i].item().toInt();str += table[a];}return str;
}int main(int argc, const char *argv[])
{if (argc < 3 || argc > 102){std::cerr << "调用错误!" << std::endl;return -1;}try{int image_num = argc - 2; //读取的图片数量bool write = false;torch::jit::script::Module module = torch::jit::load(argv[1]); //读取模型cv::Mat images; //保存图片数据for (int i = 0; i < image_num; i++){cv::Mat image = cv::imread(argv[i + 2]); //读取图片cv::resize(image, image, cv::Size(45, 45)); //变形成为45 x 45cv::cvtColor(image, image, cv::COLOR_BGR2GRAY); //转成灰度图image.convertTo(image, CV_32FC1); //转换为32位浮点型if (!write){images = image;write = true;}else{cv::vconcat(images, image, images); //拼接图像}}auto input_tensors = torch::from_blob(images.data, {image_num, 1, 45, 45 }); //将mat转成tensorstd::vector<torch::jit::IValue> inputs;inputs.push_back(input_tensors);auto outputs = module.forward(inputs).toTensor();std::cout << decode(outputs[0]);for (int i = 1; i < image_num; i++){auto result = decode(outputs[i]);//解码std::cout << ' ' << result;}return 0;}catch (...) //捕获任意异常{std::cerr << "程序执行出错!" << std::endl;return -1;}
}
编译环境搭建
下面介绍两种编译环境的搭载方法,一种是直接在 visual studio 中配置,一种是官方推荐的用 cmake 配置 visual studio 环境。
确保已安装 visual studio 的 C++ 部件,下面所有方法都以 visual studio 2019 为 IDE,程序编译类型为 x64 release。
C++ 库管理
在前面我们已安装了 libtorch 和 opencv,以 libtorch 1.6.0 (release) 和 opencv 4.4.0 为例,假设它们放在一个文件夹:D:\CplusLib\

程序需要的动态链接库位置:
- libtorch:
D:\CplusLib\libtorch\lib - opencv:
D:\CplusLib\opencv\build\x64\vc15\bin
接下来我们需要将这些动态链接库的路径添加进环境变量,以便 C++ 程序通过环境变量找寻这些动态链接库。
以 Windows 10 系统为例,右键 此电脑,选择 属性 -> 高级系统设置 -> 环境变量 打开界面。

有两种环境变量:用户变量和系统变量,一种只针对一个用户有效,另一种对所有用户都有效。
我们添加系统变量的 path 项,双击 path,点击 新建 输入路径:

点击 确定 -> 确定
方法一:手动配置 visual studio 环境
直接在 visual studio 环境中配置要一个一个去写包含的库的路径和动态链接库的名称。我是采用属性表的形式直接让工程项目读取,这样每创建一个新工程就不用重复配置了。
以上面的库安装路径为基础提供每个库的属性表:
-
libtorch(release):
libtorch.Cpp.x64.user.props<?xml version="1.0" encoding="utf-8"?> <Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003"><ImportGroup Label="PropertySheets" /><PropertyGroup Label="UserMacros" /><PropertyGroup><IncludePath>D:\CplusLib\libtorch\include;D:\CplusLib\libtorch\include\torch;$(IncludePath)</IncludePath><LibraryPath>D:\CplusLib\libtorch\lib;$(LibraryPath)</LibraryPath></PropertyGroup><ItemDefinitionGroup><Link><AdditionalDependencies>asmjit.lib;c10.lib;c10_cuda.lib;caffe2_detectron_ops_gpu.lib;caffe2_module_test_dynamic.lib;caffe2_nvrtc.lib;clog.lib;cpuinfo.lib;dnnl.lib;fbgemm.lib;libprotobuf-lite.lib;libprotobuf.lib;libprotoc.lib;mkldnn.lib;torch.lib;torch_cpu.lib;torch_cuda.lib;%(AdditionalDependencies)</AdditionalDependencies></Link></ItemDefinitionGroup><ItemGroup /> </Project> -
opencv (release):
opencv.Cpp.x64.user.props<?xml version="1.0" encoding="utf-8"?> <Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003"><ImportGroup Label="PropertySheets" /><PropertyGroup Label="UserMacros" /><PropertyGroup><IncludePath>D:\CplusLib\opencv\build\include;D:\CplusLib\opencv\build\include\opencv2;$(IncludePath)</IncludePath><LibraryPath>D:\CplusLib\opencv\build\x64\vc15\lib;$(LibraryPath)</LibraryPath></PropertyGroup><ItemDefinitionGroup><Link><AdditionalDependencies>opencv_world440.lib;%(AdditionalDependencies)</AdditionalDependencies></Link></ItemDefinitionGroup><ItemGroup /> </Project>
其中: IncludePath 是库的包含路径,LibraryPath 是链接库路径,AdditionalDependencies 是链接库名称。
如何导入属性表?
在 visual studio 中点击 属性管理器,右键 Release|x64 -> 添加现有属性表。最后效果如图:

新建 C++ 项目,将我们前面编写的 C++ 文件添加进来,按照如图配置:

点击 本地 Windows调试器 即可完成编译。
方法二:cmake 配置环境
首先安装 cmake:https://cmake.org/download/
比如 Windows 64位系统选择 cmake-3.18.2-win64-x64.msi,跟随安装程序即可完成安装。
新建一个目录 D:\CaptchaRecognize\,在目录下新建 CMakeLists.txt:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(CaptchaRecognize)SET(CMAKE_BUILE_TYPE RELEASE)INCLUDE_DIRECTORIES(
D:/CplusLib/libtorch/include
D:/CplusLib/libtorch/include/torch
D:/CplusLib/opencv/build/include
D:/CplusLib/opencv/build/include/opencv2
)SET(TORCH_LIBRARIES D:/CplusLib/libtorch/lib)
SET(OpenCV_LIBS D:/CplusLib/opencv/build/x64/vc15/lib)LINK_DIRECTORIES(
${TORCH_LIBRARIES}
${OpenCV_LIBS}
)add_executable(CaptchaRecognize 源.cpp)target_link_libraries(CaptchaRecognize
asmjit.lib
c10.lib
c10_cuda.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
caffe2_nvrtc.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
libprotobuf-lite.lib
libprotobuf.lib
libprotoc.lib
mkldnn.lib
torch.lib
torch_cpu.lib
torch_cuda.lib
opencv_world440.lib
)set_property(TARGET CaptchaRecognize PROPERTY CXX_STANDARD 14)
该文件中的一些属性和属性表的内容相似。将 源.cpp 复制到该目录下,新建目录 build。

打开 Cmake 进行如下配置:

点击 configure -> finish,然后点击 Generate 生成 visual studio 工程。
在 build 目录中找到工程文件并打开,打开 解决方案资源管理器,右键 CaptchaRecognize -> 设为启动项目

编译属性:
点击 本地 Windows调试器 即可完成编译。
python 调用 C++ 程序
该 C++ 程序的命令行调用示例:
CaptchaRecognize.exe model_script.pt pic1.png pic2.png
在 python 中通过 os.popen('command').read() 即可像命令行一样调用 C++ 程序并读取程序的输出结果。
例如:
import osresult = os.popen('CaptchaRecognize.exe model_script.pt pic1.png pic2.png').read() #调用 C++ 程序
result = result.split(' ')
由前面可知 C++ 程序输出的结果由单空格隔开,通过 .split(' ') 可得到含所有图片识别结果的列表。
这篇文章花了我很长时间,如果觉得不错不妨点个赞哦
相关文章:
用 pytorch 训练端对端验证码识别神经网络并进行 C++ 移植
文章目录 前言安装安装 pytorch安装 libtorch安装 opencv(C) 准备数据集获取训练数据下载标定 编码预分析 数据集封装格式 神经网络搭建神经网络训练神经网络测试神经网络预测C 移植模型转换通过跟踪转换为 Torch Script通过注解转换为 Torch Script 编写…...

leetcode 739. 每日温度、496. 下一个更大元素 I
739. 每日温度 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: …...

Photon——Fusion服务器(Failed to find entry-points:System.Exception: )
文章目录 前言解决方案:1.报警信息如下2.选择3d urp3.引入Fusion之后选择包管理,点击Burst中的Advanced Project Settings4.勾选两个预设选项5.引入官网unity.burst6.更新后报警消失总结前言 制作局域网游戏,出现未找到进入点报警 Failed to find entry-points 解决方案: …...

双十一必买好物,这四款好物你值得拥有
随着科技的不断发展,智能家电已经成为我们生活中不可或缺的一部分。在双十一期间,各大品牌都会推出各种优惠活动,以更优惠的价格购买到心仪的智能家电。比如智能超声波清洗机,智能门锁,它们不仅提高了我们的生活质量&a…...

视频号视频如何下载(WeChatVideoDownloader)
背景介绍 最近需要一个视频号里面的视频进行宣传用,网上找了很多方法都不行,特别是下载抓包工具Fiddler,然后监控HTTPS请求的,截取URL把URL中20302改成20304,再用IDM工具下载对应的资源,最后修改后缀名.mp…...

【Java-框架-SpringMVC】(01) SpringMVC框架的简单创建与使用,快速上手 - 简易版
前言 【描述】 "SpringMVC"框架的简单创建与使用,快速上手; 【环境】 系统"Windows",软件"IntelliJ IDEA 2021.1.3(Ultimate Edition)";“Java版本"1.8.0_202”,“Spring"版…...
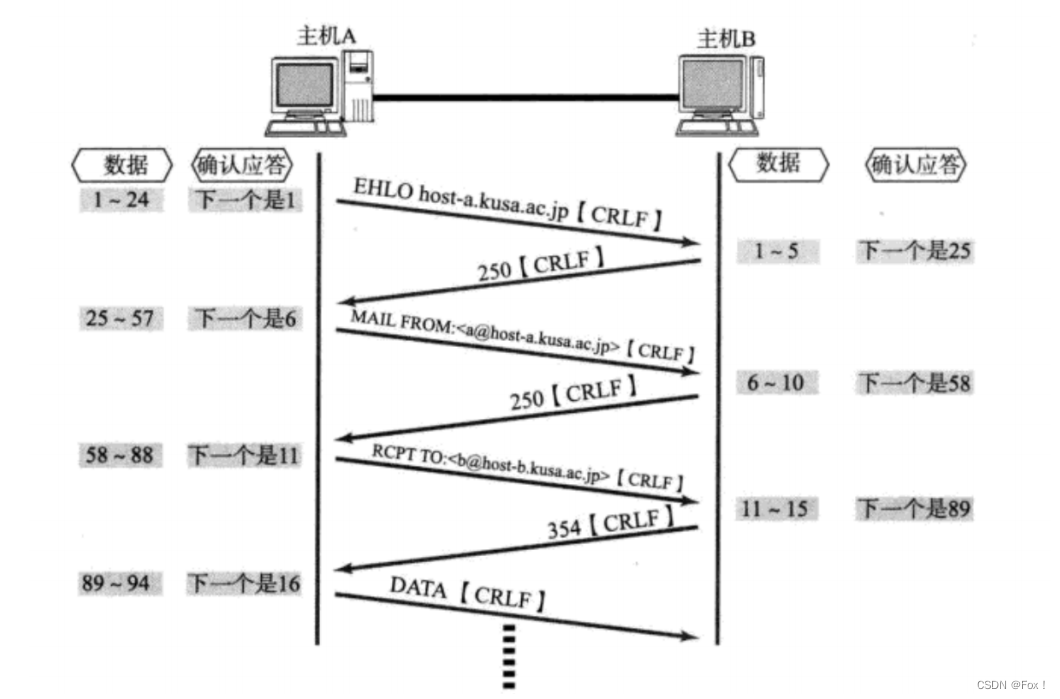
【计算机网络】UDP/TCP协议
文章目录 :peach:1 UDP协议:peach:1.1 :apple:UDP协议端格式:apple:1.2 :apple:UDP的特点:apple:1.3 :apple:UDP的缓冲区:apple:1.4 :apple:UDP使用注意事项:apple:1.5 :apple:基于UDP的应用层协议:apple: 2 :peach:TCP协议:peach:2.1 :apple:TCP协议端格式:apple:2.2 :apple:确…...

【前端设计模式】之享元模式
享元模式是一种结构型设计模式,它通过共享对象来减少内存使用和提高性能。在前端开发中,享元模式可以用于优化大量相似对象的创建和管理,从而提高页面的加载速度和用户体验。 享元模式特性 共享对象:享元模式通过共享相似对象来…...

C++前缀和算法:合并石头的最低成本原理、源码及测试用例
本文涉及的基础知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 动态规划,日后完成。 题目 有 n 堆石头排成一排,第 i 堆中有 stones[i] 块石头。 每次 移动 需要将 连续的 k 堆石头合并为一堆,而…...

maven 安装本地jar失败 错误指南
Maven 安装本地 jar 失败 安装命令: mvn install:install-file -Dfile文件路径地址 -DgroupIdcom.allinpay.sdk -DartifactIdtop-sdk-java -Dversion1.0.5 -Dpackagingjar 错误描述 : Unknown lifecycle phase “.allinpay.sdk”. You must specify a valid lifecycle phase o…...
【Spring Boot 源码学习】HttpEncodingAutoConfiguration 详解
Spring Boot 源码学习系列 HttpEncodingAutoConfiguration 详解 引言往期内容主要内容1. CharacterEncodingFilter2. HttpEncodingAutoConfiguration2.1 加载自动配置组件2.2 过滤自动配置组件2.2.1 涉及注解2.2.2 characterEncodingFilter 方法2.2.3 localeCharsetMappingsCus…...
uni-app--》基于小程序开发的电商平台项目实战(七)完结篇
🏍️作者简介:大家好,我是亦世凡华、渴望知识储备自己的一名在校大学生 🛵个人主页:亦世凡华、 🛺系列专栏:uni-app 🚲座右铭:人生亦可燃烧,亦可腐败…...

手写banner切换方式
<template><!-- banner轮播切换 --><div class"banner-wrapper"><div class"banner-info"><ul class"box" ref"box"><li v-for"(item, index) in bannerList" :key"index">&…...
技术文档工具『Writerside』抢鲜体验
前言 2023 年 10 月 16 日,JetBrains 宣布以早期访问状态推出 Writerside,基于 IntelliJ 平台的 JetBrains IDE,开发人员可使用它编写、构建、测试和发布技术文档,可以作为 JetBrains IDE 中的插件使用,也可以作为独立…...
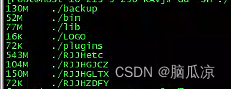
Centos磁盘爆满_openEuler系统磁盘爆满清理方法---Linux工作笔记060
磁盘爆满,监控部门就会报警,报警就要处理,但是程序员并不擅长做运维的工作,记录一下把...以后用到会方便: 使用df -h命令可以看到,对应的磁盘占用情况,这里我的/dev/mapper/openeuler-root这个目录 占用的磁盘比较多,到了百分之95了.. 往往就是这个跟目录,我这里/data目录是自…...

dubbo启动提示端口号已经被占用
本地dubbo项目启动提示: java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContext(DefaultCacheAwareContextLoaderDelegate.java:132) at org.sp…...

LeetCode每日一题——2678. Number of Senior Citizens
文章目录 一、题目二、题解 一、题目 You are given a 0-indexed array of strings details. Each element of details provides information about a given passenger compressed into a string of length 15. The system is such that: The first ten characters consist o…...

按摩 推拿上门服务小程序源码 家政上门服务系统源码
按摩 推拿上门服务小程序源码 家政上门服务系统源码 上门服务系统是一款基于互联网和移动应用的高端家政服务预订平台,它集成了用户、服务员、客户三方的需求于一体,为广大市民提供方便、高效、安全、舒适的家居服务体验,让你在家当皇帝&…...

排列排序问题---2023 年华中科技大学程序设计竞赛新生赛
解析: 将序列分为多段,每段必须连续并且单调,输出段数-1即可 #include<bits/stdc.h> using namespace std; #define int long long const int N1e65; int n,a[N]; signed main(){scanf("%lld",&n);for(int i1;i<n;i)…...
数据恢复怎么做?记好这款堪比数据恢复专家的软件!
“我真的受够了数据总是莫名其妙丢失了!但是我的电脑知识又很有限,文件丢失后我都不知道应该采取什么方法来进行恢复。谁能给我介绍一些方法呀?” 数据丢失是一场噩梦,无论是因为误删除、硬盘损坏、病毒攻击还是其他原因。然而&am…...

神经网络发展简史:从LeNet到EfficientNet
神经网络发展简史:从LeNet到EfficientNet大家好,我是资深AI讲师与学习规划师。专注计算机视觉教学与算法研发,过去三年我帮超过2500名有Python 基础的入门者,从"像素是什么"到"独立跑通CV项目"。今天这篇长文…...

gridDim 最好是sm 的整数 吗
这个问题问得非常到位,而且是一个**“看起来应该对,但其实不完全对”的经典误区**。我帮你把结论和工程直觉都讲清楚。一、先给结论(直接说清楚)❌ gridDim 不需要是 SM 的整数倍 ✅ 但gridDim 至少要“远大于 SM 数量”ÿ…...

2026年ReactNative热更新主流方案深度对比
React Native热更新方案对比:Shiply、CodePush、Expo、Pushy 与自建,谁才是最佳选择? 在移动应用迭代节奏不断加快的背景下,热更新已成为保障用户体验与业务敏捷的重要技术路径。React Native 的热更新可在不通过应用商店审核的情…...

GitHub中文界面插件终极指南:3分钟实现全平台中文化
GitHub中文界面插件终极指南:3分钟实现全平台中文化 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾被GitHub满屏…...

PROJECT MOGFACE创意编程项目展示:自动生成交互式网页小游戏
PROJECT MOGFACE创意编程项目展示:自动生成交互式网页小游戏 你有没有过这样的瞬间?脑子里突然蹦出一个绝妙的游戏点子,比如“一个控制小方块躲避从天而降的障碍物”,但一想到要写HTML、CSS、JavaScript,还要调试物理…...

RexUniNLU真实生成效果:医疗问诊记录中症状实体+情感倾向联合输出
RexUniNLU真实生成效果:医疗问诊记录中症状实体情感倾向联合输出 1. 引言:当AI能看懂病历和感受情绪 想象一下,一位医生每天要面对几十份电子病历和问诊记录。他需要快速找出病人的关键症状,同时还要判断病人描述病情时的情绪状…...
)
告别DWConv卡顿!用Pytorch手把手实现CVPR 2023的PConv(附完整代码与性能对比)
告别DWConv卡顿!用PyTorch手把手实现CVPR 2023的PConv(附完整代码与性能对比) 在移动端和边缘计算场景中,模型推理速度往往成为制约落地的关键瓶颈。许多工程师发现,即使采用深度可分离卷积(DWConv…...

【自动驾驶】从轨迹规划到安全评估:核心术语场景化解读
1. 自动驾驶技术链路全景解读 想象一下你坐在一辆自动驾驶汽车里,车辆正行驶在晚高峰的城市道路上。左侧突然有外卖电动车强行变道,右前方公交车正在靠站,而你的车需要在这复杂的场景中做出毫秒级的反应。这背后是一套完整的"感知-决策-…...

为什么有些论文答辩特别轻松,老师不敢卡?
很多人参加完答辩,心里都会冒出一个疑问:同样是答辩,为什么有的人上台之后特别顺? 陈述完,老师点点头,简单问两句,提几条小修改,基本就过去了。整个过程看起来很轻松,甚至…...

kube-capacity企业级应用:大规模集群资源管理的10个最佳实践
kube-capacity企业级应用:大规模集群资源管理的10个最佳实践 【免费下载链接】kube-capacity A simple CLI that provides an overview of the resource requests, limits, and utilization in a Kubernetes cluster 项目地址: https://gitcode.com/gh_mirrors/ku…...