CVer从0入门NLP(一)———词向量与RNN模型
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊专栏推荐:深度学习网络原理与实战
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
文章目录
- CVer从0入门NLP(一)———词向量与RNN模型
- 写在前面
- 词向量
- RNN模型
- RNN模型结构
- 手撸RNN
- 参考连接
CVer从0入门NLP(一)———词向量与RNN模型
写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
之前的博客中,我都为大家介绍的是计算机视觉的知识,今天准备和大家唠唠NLP的内容。其实呢,对于NLP,我也是初学者,之前只是有一个大概的了解,所以本系列会以一个初学者的视角带大家走进NLP的世界,如果博客中有解释不到位的地方,希望各位大佬指正。🍭🍭🍭
当然了,NLP的内容很多,你如果在网上搜NLP学习路线的话你会看的眼花缭乱,本系列主要会介绍一些重要的知识点,一些历史久远的模型就不介绍了,我个人觉得用处不大,我们的目标是像经典模型看齐,如GPT系列,BERT家族等等。🍡🍡🍡
本系列目前准备先分三节介绍,后面会慢慢补充新内容。第一节先从词向量为切入点,然后介绍RNN模型并手撸一个RNN;第二节会介绍RNN的改进LSTM及ELMO模型;第三节会详细介绍GPT和BERT,以及它们的相同点和不同点。🍬🍬🍬
词向量
我们知道,NLP任务中我们处理的对象是一个个的词,但是计算机根本不认识我们的词啊,需要将其转换为适合计算机处理的数据类型。一种常见的做法是独热编码(one-hot编码),假设我们现在要对“秃”、“头”,“小”,“苏”四个字进行独热编码,其结果如下:

可以看出,上图可以用一串数字表示出“秃”、“头”,“小”,“苏”这四个汉字,如用1 0 0 0表示“秃”,用0 1 0 0表示“头”…
但是这种表示方法是否存在缺陷呢?大家都可以思考思考,我给出两点如下:
- 这种编码方式对于我这个案例来说貌似是还蛮不错的,但是大家有没有想过,对于一个文本翻译任务来说,往往里面有大量大量的汉字,假设有10000个,那么一个单独的字,如“秃”就需要一个1×10000维的矩阵来表示,而且矩阵中有9999个0,这无疑是对空间的一种浪费。
- 这种编码方式无法表示两个相关单词的关系,如“秃”和“头”这两个单词明显是有某种内在的关系的,但是独热编码却无法表示这种关系【余弦相似度为0,后文对余弦相似度有介绍】。
基于以上的两点,我觉得我们的对词的编码应该符合以下几点要求:
- 我们可以将词表示为数字向量。
- 我们尽可能的节省空间的消耗。
- 我们可以轻松计算向量之间的相似程度。
我们先来看这样的一个例子,参考:The Illustrated Word2vec🎅🏽🎅🏽🎅🏽🍚🍚🍚
现在正值秋招大好时机,大家的工作都找的怎么样了腻,祝大家都能找到令自己满意的工作。在投简历的过程中,我们会发现很多公司都会有性格测试这一环节,这个测试会咨询你一系列的问题,然后从多个维度来对你的性格做全面分析。其中,测试测试者的内向或外向往往是测试中的一个维度,假设我(Jay)的内向/外向得分为38(满分100),则我们可以绘制下图:

为了更好的表示数据,我们将数据限制到-1~1范围内,如下:

这样我们就可以对Jay这个人是否外向做一个大致的评价,但是人是复杂的,仅仅从一个维度来分析一个人的性格肯定是不准确的,因此,我们再来添加一个维度来综合评价Jay这个人的性格特点:

可以看到,现在我们就可以从两个维度来描述Jay这个人了,在上图的坐标系中就是一个坐标为(-0.4,0.8)的点,或者说是从原点到(-0.4,0.8)的向量。当然了,如何还有别人有这样的两个维度,我就能通过比较他们的向量来表示他们的相似性。

从上图可以和明显的看出,Person1和Jay更像,但是这是我们直观的感受,我们可不可以通过数值来反应他们之间的相似度呢,当然可以,一种常见的计算相似度的方法是余弦相似度cosine_similarity,结果如下:

🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷
不知道大家知不知道计算余弦相似度,这里简单介绍一下:
余弦相似度是一种用于衡量两个向量之间相似性的度量方法,通常在自然语言处理和信息检索等领域广泛使用。它计算两个向量之间的夹角余弦值,值越接近1表示两个向量越相似,值越接近-1表示两个向量越不相似,值接近0表示两个向量之间没有明显的相似性。
余弦相似度的计算公式如下:
余弦相似度= A ⋅ B ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣ \frac{A \cdot B}{||A||||B||} ∣∣A∣∣∣∣B∣∣A⋅B
其中:
- A 和 B 是要比较的两个向量。
- A ⋅ B A \cdot B A⋅B 表示向量** A A A**与向量 ** B B B**的点积(内积)。
- ** ∣ ∣ A ∣ ∣ ||A|| ∣∣A∣∣**和 ∣ ∣ B ∣ ∣ ||B|| ∣∣B∣∣ 分别表示向量 ** A A A**与向量 ** B B B**的范数(模)。
可以来简单举个例子:
假设有两个向量 A = [ 2 , 3 ] A=[2,3] A=[2,3]、 B = [ 1 , 4 ] B=[1,4] B=[1,4]。我们来计算它们之间的余弦相似度:
A ⋅ B = ( 2 × 1 ) + ( 3 × 4 ) = 14 A \cdot B=(2×1)+(3×4)=14 A⋅B=(2×1)+(3×4)=14
∣ ∣ A ∣ ∣ = 2 2 + 3 2 = 13 ||A||=\sqrt{2^2+3^2}=\sqrt{13} ∣∣A∣∣=22+32=13
∣ ∣ B ∣ ∣ = 1 2 + 4 2 = 17 ||B||=\sqrt{1^2+4^2}=\sqrt{17} ∣∣B∣∣=12+42=17
则:余弦相似度= A ⋅ B ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣ = 14 13 17 ≈ 0.86 \frac{A \cdot B}{||A||||B||}=\frac{14}{\sqrt{13}\sqrt{17}}\approx0.86 ∣∣A∣∣∣∣B∣∣A⋅B=131714≈0.86
🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷
上面展示的是从两个维度刻画一个人的性格,但是在实际中比两维更多,国外心理学家研究了五个主要人格,所以我们可以将上面的二维扩展到五维,如下图所示:

显然,现在我们有五个维度的数据,我们无法通过平面向量的形式来观察不同人物之前的相似性,但是我们仍然可以计算他们之前的相似度,如下:

通过上面的性格测评小例子,我想告诉大家的是我们可以把诸如"外向/内向"、“自卑/自负”等性格特征表述成向量的形式,并且每个人都可以用这些种向量形式表示,同时我们可以根据这种向量的表述来计算每个人之前的相似度。
同样的道理,人可以,那么词也可以,我们把一个个词表示成这样的向量形式,这种向量表示形式就是词向量。那么词向量到底长什么样呢?我们一起来看看“King”这个词的词向量(这是在维基百科上训练好的),如下:
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
这一共有50个数字,即表示我们选择了50个维度的特征来表示“king”这个词,也即这个向量表示“king”这个词。同样的道理,别的单词也会有属于他们自己的向量表示,形式和上面的是一样的,都是50维,但是里面具体的值不同。为了方便展示不同词之间的联系,我们将表示“king”的词向量换一种方式展示,根据其值的不同标记成不同的颜色(若数值接近2,则为红色;接近0,则为白色;接近-2,则为蓝色),如下图:

当然了,我们用同样的道理,会得到其它词的词向量表示,如下:

可以看到,“Man”和“Woman”之前的相似程度似乎比它们和“King”之前的相似程度高,这也是符合我们直觉的,即“Man”和“Woman”之前的联系似乎比较大。
这就说明,经过把词变成词向量之后,我们可以发现不同词之前的相关程度了。这里你可能会问了,怎么把词变成词向量呢?不急,我们马上解答。🧃🧃🧃
我们再拿我们一开始“秃”、“头”,“小”,“苏”四个字为例,我们使用独热编码编码这四个字后,它们之间的余弦相似度都为0,无法表示它们之间的相关程度,因此使用独热编码作为词向量效果不好。那么改使用什么呢,一种可能的方案是Word Embedding。我们先来说说通过Word Embedding可以达到什么样的效果,同样拿“秃”、“头”,“小”,“苏”四个字为例,使用Word Embedding后它们的分布是这样的:

即“秃”和“头”在某个空间中离的比较近,说明这两个词的相关性较大。即Word Embedding可以从较高的维度去考虑一些词,那么会发现一些词之前存在某种关联。
那么如何进行Word Embedding,如何得到我们的词向量呢?首先我需要让大家认识到一点,进行Word Embedding,其实重点就是寻找一个合适的矩阵Q。然后将我们之前的one hot编码乘上Q,,比如“秃”的one hot 编码是1 0 0 0,假设我们寻找到了一个矩阵Q,

那么我们将它们两个相乘,就得到了“秃”的词向量:
词向量“秃”:

同理,我们可以得到其它几个词的词向量:

好了,到这里你或许明白了我们的目标就是寻找一个变化矩阵Q。那么这个Q又是怎么寻找的呢,其实呢,这个Q矩阵是训练出来的。一开始,有一种神经网络语言模型,叫做NNLM,它在完成它的任务的时候产生了一种副产物,这个副产物就是这个矩阵Q。【这里我们不细讲了,大家感兴趣的去了解一下,资料很多】后面人们发现这个副产物挺好用,因为可以进行Word Embedding,将词变成词向量嘛。于是科研人员就进一步研究,设计出了Word2Vec模型,这个模型是专门用来得到这个矩阵Q的。【后面我们也叫这个矩阵Q为Embedding矩阵】🥗🥗🥗
Word2Vec模型有两个结构,如下:
- CBOW,这种模型类似于完型填空,核心思想是把一个句子中间的某个词挡住,然后用这个词的上下文单词去预测这个被挡住的词。🍚🍚🍚
- Skip-gram,这个和CBOW结构刚好相反,它的核心思想是根据一个给定的词去预测这个词的上下文。🍚🍚🍚
它们的区别可以用下图表示:

至于它们具体是怎么实现的我不打算讲,感兴趣的可以去搜搜。我简单说说它的思路:在它们训练时,首先会随机初始化一个Embedding表和Context表,然后我们会根据输入单词去查找两个表,并计算它们的点积,这个点击表示输入和上下文的相似程度,接着会根据这个相似程度来设计损失函数,最后根据损失不断的调整两个表。当训练完成后,我们就得到了我们的Embedding表,也就是Q矩阵。🍗🍗🍗
RNN模型
上一小节我们介绍了词向量,它解决的是我们NLP任务中输入问题。下面我们将一起来唠唠NLP任务中的常见模型。🍄🍄🍄
RNN模型结构
RNN(循环神经网络)我想大家多少都有所耳闻吧,它主要用于解决时序问题,例如时间序列、自然语言文本、音频信号等。
话不多说,我们直接来看RNN的模型图,如下:

啊,什么,这这点!!!?你或许感到震惊,RNN的模型结构就这么点儿???是的,没错,就这些。🥗🥗🥗首先,它有一个输入 X t X_t Xt,这是一个序列输入,比如某时刻的输入为 x i x_i xi, x i x_i xi会输入到模块A中【注意:这里不止一个输入,还会有一个输入 h i − 1 h_{i-1} hi−1一起送入模块A】,然后模块A输出一个值 h i h_i hi。接着会将输出 h i h_i hi和下一个输入 x i + 1 x_{i+1} xi+1送入模块A,得到输出 h i + 1 h_{i+1} hi+1。【注意:最基础的RNN的输出和 h t h_t ht是一样的】重复上面的过程,就是RNN啦。
上面的图用一个循环表示RNN,其实看起来还是比较不舒服,那么我们把这个循环展开,其结构就会比较清晰了,如下图所示:

知道了RNN的大体结构,我觉得你或与会对模块A的结构很敢兴趣,那我劝你不要太敢兴趣。🧃🧃🧃因为模块A真的很简单,就是一个tanh层,如下:

enmmmm,就是这么简单,如果你对此结构还存有疑惑的话,那么字写看看后文的代码手撸RNN部分,或许能解决你的大部分疑惑。
到这里,其实RNN的模型结构就讲完了,是不是很简单呢。🍭🍭🍭那么下面讲什么呢?自然是RNN存在什么问题,这样才能过渡到后面更加牛*的网络嘛。🍄🍄🍄
那么RNN存在什么问题呢?那就是长距离依赖问题,何为长距离依赖呢?他和短距离依赖是相对的概念,我们来举个例子来介绍什么是长距离依赖,什么是短距离依赖:
-
对于这样一句话:“我爱在足球场上踢__”,我们是不是很容易得到空格里的答案,因为在空格前几个字有足球场,所以我们知道这里要填“足球”。这种能根据上下文附近就判断预测答案的就是短距离依赖。【短距离依赖的图示如下】

-
对于这样一句话:“我爸爸从小就带我去足球场踢足球,我的爱好就是足球。我和爸爸关系非常好,经常带我一起玩耍,…,真是一个伟大的父亲。长大后,我的爱好一直没变,现在我就要去踢__”,大家感受到了嘛,这里空格中要填的词我们要往上文找很就才可以发现,这种预测答案需要看上文很远距离找到答案的就是长距离依赖。

也就是说,RNN网络对于长距离依赖的问题效果很不好,因此我们后面会对RNN网络进行改进,进而提高其对长距离依赖的能力。🥝🥝🥝
手撸RNN
想必大家通过上文的讲述,已经对RNN的代码结构有了一定的认识,下面我们就来使用Pytorch来实现一个RNN网络,让大家对其有一个更加清晰的认识。🥂🥂🥂
这部分的思路是这样的,我先给大家调用一下官方封装好的RNN模型,展示模型输入输出的结果;然后再手撸一个RNN函数,来验证其结果是否和官方一致。
好了,我们就先来使用官方定义好的RNN模型来实现,具体可以看这个连接:RNN🍵🍵🍵
import torch
import torch.nn as nn
bs, T = 2, 3 #批大小,输入序列长度
input_size, hidden_size = 2, 3 # 输入特征大小,隐含层特征大小
input = torch.randn(bs, T, input_size) # 随机初始化一个输入特征序列
h_prev = torch.zeros(bs, hidden_size) # 初始隐含状态
我们先来打印看一下input和h_prev以及它们的shape,如下:

我们来解释一下这些变量,input就是我们输入的数据,他的维度为(2, 3, 2),三个维度分别表示(bs, T, input_size),即(批大小,输入序列长度,输入特征大小)。我这样介绍大家可能还一头雾水,我结合input的打印结果给大家介绍,首先很明显这是一个维度为(2, 3, 2)的向量,这个大家都知道哈,不知道我就真没办法啦,去补补课吧。🍸🍸🍸那么这个向量的第一个维度是2,就代表我们1个batch有两条数据,每个都是(3, 2)维度的向量,如下:

这个和计算机视觉中的bs(batch_size)是一个意思啦,接下来我们来看每条数据,即这个(3,2)维的向量,以第一条为例:这个3表示输入序列长度,表示每条数据又有三个小部分构成,分别为[-0.0657, -0.9015]、[-0.0324, -0.5666]、[-0.2630, 2.4861]。这是什么意思呢,这表示我们的输入会分三次送入RNN网络中,分别是 x 0 、 x 1 、 x 2 x_0、x_1、x_2 x0、x1、x2,不知道这样大家能否理解,我画个图大家就知道了,如下:

大家可能发现了,这个维度的3个数据就相当于3个词,分别一步步的送入RNN网络中,那么其实最后一个维度2,也就是输入特征大小也很好理解了,它就表示每个词的维度,就是我们前文所说的词向量,那么我们这里就是每个词向量有两个维度的特征。🍚🍚🍚
通过上文的介绍,我想大家了解input这个输入了,那么h_prev是什么呢,其是隐层的输出,也就是上图中的 h 0 、 h 1 、 h 2 h_0、h_1、h_2 h0、h1、h2。
接着我们就来调用pytorch中RNN的API:
# 调用pytorch RNN API
rnn = nn.RNN(input_size, hidden_size, batch_first=True)
rnn_output, state_final = rnn(input, h_prev.unsqueeze(0))
batch_first=True这个参数是定义我们输入的格式为(bs, T, input_size)的,pytorch文档中都解释的很详细,大家自己去看一下就好。至于这个h_prev.unsqueeze(0)这里加了第一个维度,这是由于RNN API的输入要求是三维的向量,如下:

我们来看看输出的rnn_output和state_final的值和shape吧,如下:

rnn_output其实就是每个隐藏层的输出,而state_final则是最终的输出,在基础的RNN中,state_final的值就等于最后一个隐藏层的输出,我们从数值上也可以发现,如下:

为了方便大家理解,再画一个图,如下:【注意:图都是以batch中一条数据为例表示的】

那么上文就为大家介绍了如何使用pytorch官方API实现RNN,但是这样我们无法看到RNN内部是如何实现的,那么这样我们就来手动实现一个RNN。其实很简单,主要就是用到了一个公式,如下:

这个公式可以在pytorch官方文档中看到,其实不知道大家发现没有,其实这个公式和卷积神经网络的公式是很像的,只不过RNN这里有两个输入而已。还有一点和大家说一下,上图公式中含有转置,实现起来转置来转置去的会很绕,上面的公式其实和下面是一样的【上下两个 x t x_t xt维度其实变了】:

为了简便起见,我用不带转置的进行代码编写,大家先理解好这个,最后我也会把带转置的代码放出来,这时候理解带转置的可能更容易点。
# 手写一个rnn_forward函数,实现RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):bs, T ,input_size = input.shapeh_dim = weight_ih.shape[0]h_out = torch.zeros(bs, T, h_dim)for t in range(T):x = input[:,t,:].unsqueeze(2) w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1)w_hh_batch = weight_hh.unsqueeze(0).tile(bs, 1, 1)w_times_x = torch.bmm(x.transpose(1, 2), w_ih_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)w_times_h = torch.bmm(h_prev.unsqueeze(2).transpose(1, 2), w_hh_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)h_prev = torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)h_out[:,t,:] = h_prevreturn h_out, h_prev.unsqueeze(0)
我们看到代码并不长,所以其实还是很简单的,最主要的是大家注意for t in range(T)这个循环,就是不断的取输入序列中的向量送入RNN网络,比如开始是 x 0 x_0 x0送入、接着是 x 1 x_1 x1送入…依次类推,后面的几行代码都是围绕 h t = tanh ( W i h x t + b i h + W h h h ( t − 1 ) + b h h ) h_{t}=\tanh \left(W_{i h} x_{t}+b_{i h}+W_{h h} h_{(t-1)}+b_{h h}\right) ht=tanh(Wihxt+bih+Whhh(t−1)+bhh)进行编写的,具体的细节大家慢慢调试吧,相信难不住你。因为设计到很多向量运算,所以特别要注意维度的变化。🍗🍗🍗
接下来我们要验证一下我们实现的RNN是否正确,但是我们需要传入 W i h 、 b i h 、 W h h 、 b h h W_{ih}、b_{ih}、W_{hh}、b_{hh} Wih、bih、Whh、bhh参数,这几个参数怎么得到呢,我们可以在rnn中看到这几个参数的值,我们也只有用这个才能保证我们最后的结果和官方的一致,我们可以来简单看看这几个值,如下:

接着我们就可以将这里面的参数传入到rnn_forward函数中,如下:
custom_rnn_output, custom_state_final = rnn_forward(input, rnn.weight_ih_l0, rnn.weight_hh_l0, rnn.bias_ih_l0, rnn.bias_hh_l0, h_prev)
同样,我们来打印一下custom_rnn_output和custom_state_final,如下:

经过对比,你可以发现,使用官方API和使用我们自定义的函数实现的RNN的输出是一样,这就验证了我们方法的正确性。
下面给出带转置的,即 h t = tanh ( x t W i h T + b i h + h t − 1 W h h T + b h h ) h_{t}=\tanh \left(x_{t} W_{i h}^{T}+b_{i h}+h_{t-1} W_{h h}^{T}+b_{h h}\right) ht=tanh(xtWihT+bih+ht−1WhhT+bhh)这个表达式的代码供大家参考,如下:
# custom 手写一个rnn_forward函数,实现RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):bs, T, input_size = input.shapeh_dim = weight_ih.shape[0]h_out = torch.zeros(bs, T, h_dim)for t in range(T):x = input[:, t, :].unsqueeze(2)w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1)w_hh_batch = weight_hh.unsqueeze(0).tile(bs, 1, 1)w_times_x = torch.bmm(x.transpose(1, 2), w_ih_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)w_times_h = torch.bmm(h_prev.unsqueeze(2).transpose(1, 2), w_hh_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)h_prev = torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)h_out[:, t, :] = h_prevreturn h_out, h_prev.unsqueeze(0)
参考连接
1、The Illustrated Word2vec
2、理解 LSTM 网络
3、Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
4、Understanding LSTM Networks
5、预训练语言模型的前世今生
6、PyTorch源码教程与前沿人工智能算法复现讲解
如若文章对你有所帮助,那就🛴🛴🛴

相关文章:
CVer从0入门NLP(一)———词向量与RNN模型
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…...
乐观锁和悲观锁
目录 悲观锁:乐观锁:CAS算法:版本号机制:write_condition 机制:时间戳:ReentrantLock 类: 独占锁:synchronized 关键字: 悲观锁: 1、理解:总是假设最坏的情况…...

用 pytorch 训练端对端验证码识别神经网络并进行 C++ 移植
文章目录 前言安装安装 pytorch安装 libtorch安装 opencv(C) 准备数据集获取训练数据下载标定 编码预分析 数据集封装格式 神经网络搭建神经网络训练神经网络测试神经网络预测C 移植模型转换通过跟踪转换为 Torch Script通过注解转换为 Torch Script 编写…...

leetcode 739. 每日温度、496. 下一个更大元素 I
739. 每日温度 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: …...

Photon——Fusion服务器(Failed to find entry-points:System.Exception: )
文章目录 前言解决方案:1.报警信息如下2.选择3d urp3.引入Fusion之后选择包管理,点击Burst中的Advanced Project Settings4.勾选两个预设选项5.引入官网unity.burst6.更新后报警消失总结前言 制作局域网游戏,出现未找到进入点报警 Failed to find entry-points 解决方案: …...

双十一必买好物,这四款好物你值得拥有
随着科技的不断发展,智能家电已经成为我们生活中不可或缺的一部分。在双十一期间,各大品牌都会推出各种优惠活动,以更优惠的价格购买到心仪的智能家电。比如智能超声波清洗机,智能门锁,它们不仅提高了我们的生活质量&a…...

视频号视频如何下载(WeChatVideoDownloader)
背景介绍 最近需要一个视频号里面的视频进行宣传用,网上找了很多方法都不行,特别是下载抓包工具Fiddler,然后监控HTTPS请求的,截取URL把URL中20302改成20304,再用IDM工具下载对应的资源,最后修改后缀名.mp…...

【Java-框架-SpringMVC】(01) SpringMVC框架的简单创建与使用,快速上手 - 简易版
前言 【描述】 "SpringMVC"框架的简单创建与使用,快速上手; 【环境】 系统"Windows",软件"IntelliJ IDEA 2021.1.3(Ultimate Edition)";“Java版本"1.8.0_202”,“Spring"版…...
【计算机网络】UDP/TCP协议
文章目录 :peach:1 UDP协议:peach:1.1 :apple:UDP协议端格式:apple:1.2 :apple:UDP的特点:apple:1.3 :apple:UDP的缓冲区:apple:1.4 :apple:UDP使用注意事项:apple:1.5 :apple:基于UDP的应用层协议:apple: 2 :peach:TCP协议:peach:2.1 :apple:TCP协议端格式:apple:2.2 :apple:确…...

【前端设计模式】之享元模式
享元模式是一种结构型设计模式,它通过共享对象来减少内存使用和提高性能。在前端开发中,享元模式可以用于优化大量相似对象的创建和管理,从而提高页面的加载速度和用户体验。 享元模式特性 共享对象:享元模式通过共享相似对象来…...

C++前缀和算法:合并石头的最低成本原理、源码及测试用例
本文涉及的基础知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 动态规划,日后完成。 题目 有 n 堆石头排成一排,第 i 堆中有 stones[i] 块石头。 每次 移动 需要将 连续的 k 堆石头合并为一堆,而…...

maven 安装本地jar失败 错误指南
Maven 安装本地 jar 失败 安装命令: mvn install:install-file -Dfile文件路径地址 -DgroupIdcom.allinpay.sdk -DartifactIdtop-sdk-java -Dversion1.0.5 -Dpackagingjar 错误描述 : Unknown lifecycle phase “.allinpay.sdk”. You must specify a valid lifecycle phase o…...
【Spring Boot 源码学习】HttpEncodingAutoConfiguration 详解
Spring Boot 源码学习系列 HttpEncodingAutoConfiguration 详解 引言往期内容主要内容1. CharacterEncodingFilter2. HttpEncodingAutoConfiguration2.1 加载自动配置组件2.2 过滤自动配置组件2.2.1 涉及注解2.2.2 characterEncodingFilter 方法2.2.3 localeCharsetMappingsCus…...
uni-app--》基于小程序开发的电商平台项目实战(七)完结篇
🏍️作者简介:大家好,我是亦世凡华、渴望知识储备自己的一名在校大学生 🛵个人主页:亦世凡华、 🛺系列专栏:uni-app 🚲座右铭:人生亦可燃烧,亦可腐败…...

手写banner切换方式
<template><!-- banner轮播切换 --><div class"banner-wrapper"><div class"banner-info"><ul class"box" ref"box"><li v-for"(item, index) in bannerList" :key"index">&…...
技术文档工具『Writerside』抢鲜体验
前言 2023 年 10 月 16 日,JetBrains 宣布以早期访问状态推出 Writerside,基于 IntelliJ 平台的 JetBrains IDE,开发人员可使用它编写、构建、测试和发布技术文档,可以作为 JetBrains IDE 中的插件使用,也可以作为独立…...
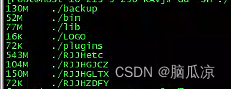
Centos磁盘爆满_openEuler系统磁盘爆满清理方法---Linux工作笔记060
磁盘爆满,监控部门就会报警,报警就要处理,但是程序员并不擅长做运维的工作,记录一下把...以后用到会方便: 使用df -h命令可以看到,对应的磁盘占用情况,这里我的/dev/mapper/openeuler-root这个目录 占用的磁盘比较多,到了百分之95了.. 往往就是这个跟目录,我这里/data目录是自…...

dubbo启动提示端口号已经被占用
本地dubbo项目启动提示: java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContext(DefaultCacheAwareContextLoaderDelegate.java:132) at org.sp…...

LeetCode每日一题——2678. Number of Senior Citizens
文章目录 一、题目二、题解 一、题目 You are given a 0-indexed array of strings details. Each element of details provides information about a given passenger compressed into a string of length 15. The system is such that: The first ten characters consist o…...

按摩 推拿上门服务小程序源码 家政上门服务系统源码
按摩 推拿上门服务小程序源码 家政上门服务系统源码 上门服务系统是一款基于互联网和移动应用的高端家政服务预订平台,它集成了用户、服务员、客户三方的需求于一体,为广大市民提供方便、高效、安全、舒适的家居服务体验,让你在家当皇帝&…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...