领先一步,效率翻倍:PieCloudDB Database 预聚集特性让查询速度飞起来!
在大数据时代,如何有效地管理和处理海量数据成为了企业面临的核心挑战。为此,拓数派推出了首款数据计算引擎 PieCloudDB Database,作为一款全新的云原生虚拟数仓,旨在提供更高效、更灵活的数据处理解决方案。
PieCloudDB 的设计理念源于对用户使用体验和查询效率的深度理解。在实现存算分离的同时,PieCloudDB 专门设计和打造了全新的存储引擎「简墨」等模块。针对云场景和分析型场景,PieCloudDB 还设计了高效的预聚集(Pre-Aggregate)特性。本文将详细介绍 PieCloudDB 如何运用预聚集技术优化数据处理流程,改善用户体验。
作为云原生虚拟数仓,PieCloudDB 充分借助云计算所提供的基础设施服务,包括大规模分布式集群、虚拟机、容器等。这些特性使得 PieCloudDB 能更好地适应动态的和不断变化的工作负载需求。同时,PieCloudDB 也积极拓展其自身的特性,实现高可用、易扩展和弹性伸缩,以满足企业不断增长的业务需求。
PieCloudDB 实现了一个重要创新功能:预聚集(Pre-Aggregate)。 该功能通过 PieCloudDB 的全新的存储引擎「简墨」(JANM),在数据插入时即时计算数据列的 Aggregate 信息,并将其预先保存以供后续使用。这种方法摒弃了在查询时进行复杂计算的传统方式,从而大大提升了查询速度。此外,由于聚合数据保存在文件中,可以实现快速访问并直接应用于查询。
PieCloudDB 会根据用户的查询自动生成带有 Pre-Aggregate 的计划,使得查询过程尽可能地快速且准确。 当需要聚合数据时,系统会检查预存储的聚合值,并直接读取符合条件的 Aggregate 数据。这样避免了查询过程中扫描整个数据集的需求,可以大幅提升查询速度。
对于部分满足条件的块,PieCloudDB 将会回归原来的处理方式计算 Aggregate 值。 这样既能利用已经预聚合的数据,又只需计算缺少的部分,从而降低计算成本并提高运算效率。
1 预聚集的原理
为了能够增加 Aggregate 的查询性能,PieCloudDB 采用了以「空间」换取「时间」的策略,在写入数据的时候,在存储层中将相关的 Aggregate 进行预先计算并保存,从而在查询的时候可以快速找到需要的 Aggregate 数据。
上面解决了 Aggregate 数据来源问题,下面将介绍如何拿到预先计算的 Aggregate 数据。为了能够实现正确获取下推的 Aggregate 数据,PieCloudDB 的优化器与执行器被进一步改造,增加了两个新的 Pre-Aggregate 计算节点。改造前后的计划树(plan tree) 的对比如下图所示:
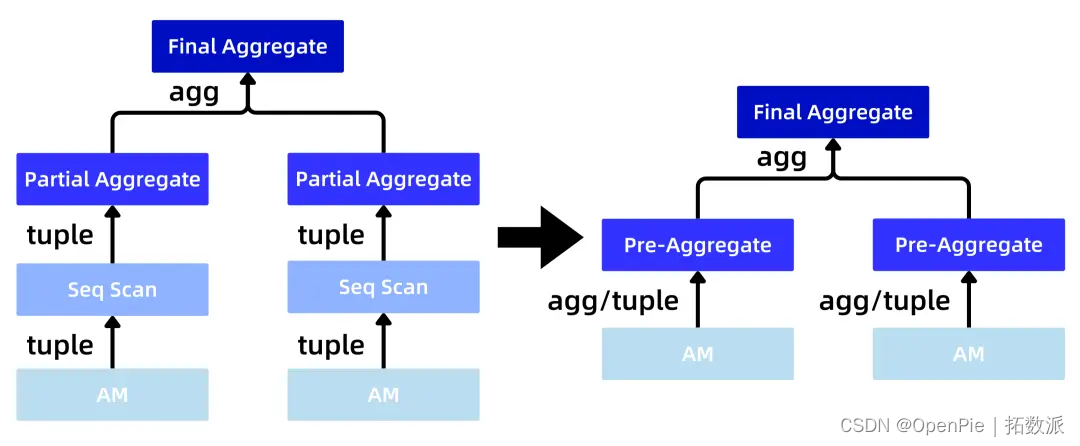 改造前后 plan tree 对比图
改造前后 plan tree 对比图
存储引擎「简墨」会在数据插入时,即时更新 Aggregate 信息。在上图中的 Pre-Aggregate 计算节点会从 AM(access method)中取出预先计算的 Aggregate 数据,如果没有找到合适的 Aggregate 数据,Pre-Aggregate 计算节点也会从 AM 中找出满足条件的 tuple 计算出对应的 Aggregate 数据,返回给上层计算节点使用。这样就解决了怎么正确找到下推的 Aggregate 数据的问题。
Pre-Aggregate 是 OLAP 优化技术中 Zone Maps 的具体实现。即预先计算一批元组属性值的聚合并预先保存,数据库检查预计算的聚集信息决定是否要访问该 block。即上面所述的如果找到可用的 Aggregate 数据则直接返回,否则访问该 block 检索具体元组。
对于带条件的 Pre-Aggregate 来说,其效果取决于预先计算所涉及的数据范围。PieCloudDB 将预聚集范围缩小至块文件,针对每个块文件分别进行预计算存储,从而保证带条件的预聚集查询效果。
2 预聚集的使用演示
下面给出了如何开启 Preagg Block Scan 以及支持 Block Skipping 的 Preagg Bitmap Block Scan 的使用方式。最后给出了对应的性能对比图。
2.1 Preagg Block Scan 使用方式
-- 创建 t 表
create table t(a int, b int, c int);-- 写入三行数据
insert into t values(1,2,3);
insert into t values(3,3,5);
insert into t values(4,4,6);-- 开启 preagg,默认是开启的
set pdb_enable_preagg = on;-- 执行如下的 query
explain (costs off) select sum(b), avg(c), count(*) from t;QUERY PLAN
------------------------------------------------Finalize Aggregate-> Gather Motion 3:1 (slice1; segments: 3)-> Pre-Aggregate Block Scan on tOptimizer: Postgres query optimizer
(4 rows)-- 开启后的执行结果
select sum(b), avg(c), count(*) from t;sum | avg | count
-----+--------------------+-------9 | 4.6666666666666667 | 3
(1 row)-- 关闭 preagg
set pdb_enable_preagg = off;-- 执行同一条 query
explain (costs off) select sum(b), avg(c), count(*) from t;QUERY PLAN
------------------------------------------------Aggregate-> Gather Motion 3:1 (slice1; segments: 3)-> Seq Scan on tOptimizer: Postgres query optimizer
(4 rows)-- 关闭后的执行结果
select sum(b), avg(c), count(*) from t;sum | avg | count
-----+--------------------+-------9 | 4.6666666666666667 | 3
(1 row)
2.2 Preagg Bitmap Block Scan 使用方式
create table t(a int, b int);
insert into t values(generate_series(1, 20), generate_series(100, 120));
insert into t values(generate_series(21, 60), generate_series(121, 160));-- 开启 preagg,默认是开启的
set pdb_enable_preagg = on;
-- 下面是开启 Pre-Aggregate Bitmap Block Scan 的几个 guc
set enable_seqscan = off;
set enable_bitmapscan = on;
set enable_indexscan = on;-- 执行如下的 query
explain (costs off) select max(a), sum(a) from t where a > 10 and a < 50;QUERY PLAN
---------------------------------------------------------------Finalize Aggregate-> Gather Motion 3:1 (slice1; segments: 3)-> Partial Aggregate-> Pre-Aggregate Bitmap Block Scan on tRecheck Cond: ((a > 10) AND (a < 50))-> Bitmap Index Scan on tIndex Cond: ((a > 10) AND (a < 50))Optimizer: Postgres query optimizer
(8 rows)-- 开启后的执行结果
select max(a), sum(a) from t where a > 10 and a < 50;max | sum
-----+------49 | 1170
(1 row)-- 关闭 preagg
set pdb_enable_preagg = off;-- 执行同一条 query
explain (costs off) select max(a), sum(a) from t where a > 10 and a < 50;QUERY PLAN
---------------------------------------------------------------Finalize Aggregate-> Gather Motion 3:1 (slice1; segments: 3)-> Partial Aggregate-> Bitmap Heap Scan on tRecheck Cond: ((a > 10) AND (a < 50))-> Bitmap Index Scan on tIndex Cond: ((a > 10) AND (a < 50))Optimizer: Postgres query optimizer
(8 rows)-- 关闭后的执行结果
select max(a), sum(a) from t where a > 10 and a < 50;max | sum
-----+------49 | 1170
(1 row)
2.3 性能对比
测试表:
create table preaggdata (a int, b int);
测试语句:
explain analyze select sum(a), avg(a), count(*), max(b) from preaggdata;

耗时对比图如下所示:
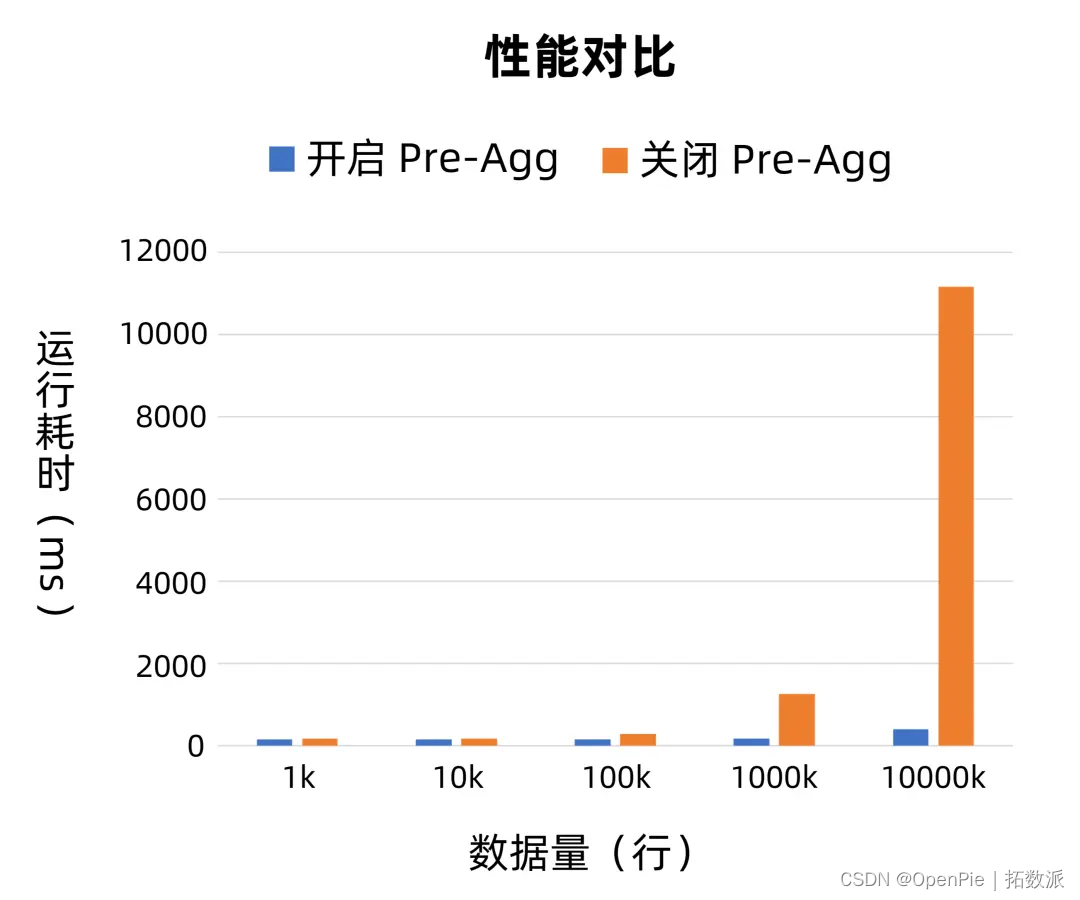
耗时对比图
从上面的测试数据和对比图可以看出,未开启 Pre-Agg 时,随着数据量的增大,耗时不断增大,且增加的速度也会越来越快;而开启 Pre-Agg 时,耗时是平稳的增长的,增长的速度也不快。当数据量达到 10000K 时,实现了近 28 倍的速度提升。
3 预聚集未来演变之路
目前,Pre-Aggregate 采用「空间」换「时间」的策略来提升性能效率。为了扩大 Pre-Aggregate 的应用范围,优化用户体验,我们将不断推动技术研发,扩大应用场景,并提供更加丰富、多元的功能。
无论是通过优化数据处理方式,拓展支持的函数类型,还是引进新的查询处理机制,我们都在锲而不舍地努力实现这一目标。相信很快,Pre-Aggregate 将能够为复杂的查询场景提供更高效、更精准的解决方案,从而逐步深化其在数据分析和处理领域的应用影响力。

相关文章:
领先一步,效率翻倍:PieCloudDB Database 预聚集特性让查询速度飞起来!
在大数据时代,如何有效地管理和处理海量数据成为了企业面临的核心挑战。为此,拓数派推出了首款数据计算引擎 PieCloudDB Database,作为一款全新的云原生虚拟数仓,旨在提供更高效、更灵活的数据处理解决方案。 PieCloudDB 的设计理…...
系统性认知网络安全
前言:本文旨在介绍网络安全相关基础知识体系和框架 目录 一.信息安全概述 信息安全研究内容及关系 信息安全的基本要求 保密性Confidentiality: 完整性Integrity: 可用性Availability: 二.信息安全的发展 20世纪60年代&…...

MySQL查看数据库、表容量大小
1. 查看所有数据库容量大小 selecttable_schema as 数据库,sum(table_rows) as 记录数,sum(truncate(data_length/1024/1024, 2)) as 数据容量(MB),sum(truncate(index_length/1024/1024, 2)) as 索引容量(MB)from information_schema.tablesgroup by table_schemaorder by su…...

什么是全链路压测?
随着互联网技术的发展和普及,越来越多的互联网公司开始重视性能压测,并将其纳入软件开发和测试的流程中。 阿里巴巴在2014 年双11 大促活动保障背景下提出了全链路压测技术,能更好的保障系统可用性和稳定性。 什么是全链路压测?…...

EGL函数翻译--eglChooseConfig
EGL函数翻译–eglChooseConfig 函数名 EGLBoolean eglChooseConfig( EGLDisplay display,EGLint const* attrib_list,EGLConfig* configs,EGLint config_size,EGLint* num_config);参数描述 参数display: EGLDisplay的显示连接。 参数attrib_list: 指定"frame Buffer(帧…...
详细介绍如何使用Ipopt非线性求解器求解带约束的最优化问题
本文中将详细介绍如何使用Ipopt非线性求解器求解带约束的最优化问题,结合给出的带约束的最优化问题示例,给出相应的完整的C程序,并给出详细的解释和注释,以及编译规则等 一、Ipopt库的安装和测试 本部分内容在之前的文章《Ubuntu2…...

跳跃游戏Ⅱ-----题解报告
题目:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 与Ⅰ不同的是,这次要求找出最小的跳跃次数。思路也很简单,在每一次跳跃之后都更新最远的跳跃距离。 举个列子: 输入:2,3,1,1,4 第一次…...
JVM 基础篇:类加载器
一.了解JVM 1.1什么是JVM JVM是Java Virtual Machine(Java虚拟机)的缩写,是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟计算机功能来实现的,JVM屏蔽了与具体操作系统平台相关的信息,Java程序只需…...
文本批量处理,高效便捷的管理利器!
您是否曾经为了批量处理文本数据而烦恼?冗长的文本文件,繁琐的处理步骤,让您的工作变得异常困难。现在,我们向您推荐一款文本批量处理工具,它能够快速、准确地处理大量文本数据,让您的管理工作更加高效便捷…...
百度松果20231022作业
越狱 盒子与球 斯特林第二类数(用dp求)*盒子的阶乘 int dp[11][11]; //n>k int A(int x){int res1;fer(i,2,x1)res*i;return res; } signed main(){IOS;dp[2][1]dp[2][2]dp[1][1]1;fer(i,3,11){dp[i][1]1;fer(j,2,i){dp[i][j]j*dp[i-1][j]dp[i-1][j-…...
cropper+jq(图片裁剪上传)
<link rel"stylesheet" href"../../cropper/cropper.css"> <script type"text/javascript" src"../../cropper/cropper.js"></script> 没有引入jquery的原因 引入jquery <script src"../jquery-1.10.2.js…...

运行 `npm install` 时的常见问题与解决方案
运行 npm install 时的常见问题与解决方案 问题一:网络连接问题 描述: 运行 npm install 时,可能会遇到网络连接问题,导致无法正常下载依赖包。 报错示例: npm ERR! network connection timed outnpm ERR! connect…...
【2023年11月第四版教材】软考高项极限冲刺篇笔记(1)
1 你要接受一些观点 1、不明白的不要去试图理解了,死记硬背 2、要快速过知识点,卡住是不行的,慢也是没有任何作用的。 3、将厚厚的知识,变为薄薄的重点。标红必背 4、成熟度等级,很多知识领域都有,就是评价在一个领域达到的级别。 5、记得搜一下当年的高频科技词汇 6、选…...
http post协议发送本地压缩数据到服务器
1.客户端程序 import requests import os # 指定服务器的URL url "http://192.168.1.9:8000/upload"# 压缩包文件路径 folder_name "upload" file_name "test.7z" headers {Folder-Name: folder_name,File-Name: file_name } # 发送POST请求…...
系列十三、Redis的哨兵机制
一、概述 Sentinel(哨兵)是Redis的高可用解决方案,由一个或者多个Sentinel实例组成集群,可以监视任意多个主服务器,以及这些服务器下属的所有从服务器,并在被监视的主服务器下线或者宕机时,自动…...

设置Unity URP管线中的渲染开关
在上一节中,我们添加了外轮廓线,但这个外轮廓线在所有使用该Shader的网格上是始终存在的。 如果我们想做一个开关,决定是否打开外轮廓线时,我们可以使用一个新的Uniform bool值,然后判断bool是否为true来开启外轮廓线…...
神器抓包工具 HTTP Analyzer v7.5 的下载,安装,使用,破解说明以及可能遇到的问题
文章目录 1、HTTP Analyzer 工具能干什么?2、HTTP Analyzer 如何下载?3、如何安装?4、如何使用?5、如何破解?6、Http AnalyzerStd V7可能遇到的问题 1、HTTP Analyzer 工具能干什么? A1:HTTP A…...

虚幻引擎:代理
一、代理类型 1.单薄代理 特点:允许有返回值,允许有参数,只可以一对一的传递消息就算绑定多个,但是总会被最后一个覆盖 2.多播代理 特点:不允许有返回值,允许有参数允许一对多传递消息 3.动态代理 …...

Openssl数据安全传输平台004:Socket C-API封装为C++类 / 服务端及客户端代码框架和实现
文章目录 0. 代码仓库1. 客户端C API2. 客户端C API的封装分析2.1 sckClient_init()和sckClient_destroy()2.2 sckClient_connect2.3 sckClient_closeconn()2.4 sckClient_send()2.5 sckClient_rev()2.6 sck_FreeMem 3. 客户端C API4. 服务端C API5. 服务端C6. 客户端和服务端代…...

网络协议--Traceroute程序
8.1 引言 由Van Jacobson编写的Traceroute程序是一个能更深入探索TCP/IP协议的方便可用的工具。尽管不能保证从源端发往目的端的两份连续的IP数据报具有相同的路由,但是大多数情况下是这样的。Traceroute程序可以让我们看到IP数据报从一台主机传到另一台主机所经过…...

HagiCode Soul 平台技术解析:从需求萌发到独立平台的演进之路奶
1 安装与初始化 # 全局安装 OpenSpec npm install -g fission-ai/openspeclatest # 在项目目录下初始化 cd /path/to/your-project openspec init 初始化时,OpenSpec 会提示你选择使用的 AI 工具(Claude Code、Cursor、Trae、Qoder 等)。 3 O…...

猫抓浏览器扩展终极指南:一站式网页资源嗅探解决方案
猫抓浏览器扩展终极指南:一站式网页资源嗅探解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法下载网页视频、音频而烦…...

手把手教你用Cursor的.cursorrules文件,定制你的专属Python/React开发AI伙伴
用.cursorrules文件打造你的智能编程伙伴:Python/React开发者的终极配置指南 在当今快节奏的软件开发环境中,AI编程助手已经成为提升效率的必备工具。而Cursor作为其中的佼佼者,其真正的威力往往被大多数开发者所低估——通过精心设计的.curs…...

macOS用户必看:BongoCat键盘输入无响应?3步权限配置终极指南
macOS用户必看:BongoCat键盘输入无响应?3步权限配置终极指南 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 你是否遇到过这…...

别再手动写SFTP工具类了!用Hutool 5.8.26 + JSch搞定文件传输,附完整代码和并发避坑指南
HutoolJSch实现高效SFTP文件传输:从基础到高并发实战 如果你还在为Java项目中的SFTP文件传输重复编写工具类,是时候解放双手了。Hutool 5.8.26结合JSch提供的SFTP封装,不仅能减少90%的样板代码,还能避免那些只有踩过坑才知道的并发…...

Python的__getattr__中的完整性
Python中的__getattr__方法是一个强大的钩子函数,用于在访问不存在的属性时动态处理请求。它的完整性设计不仅体现了Python的灵活性,也为开发者提供了更多控制权。理解__getattr__的完整性机制,能够帮助开发者构建更健壮、更智能的对象模型。…...

GreaterWMS开源仓库管理系统:从传统仓储到智能供应链的三大技术突破
GreaterWMS开源仓库管理系统:从传统仓储到智能供应链的三大技术突破 【免费下载链接】GreaterWMS This Inventory management system is the currently Ford Asia Pacific after-sales logistics warehousing supply chain process . After I leave Ford , I start …...

别再重启电脑了!用`sudo killall coreaudiod`一键解决Mac声音设备不刷新或消失问题
深入解析macOS音频服务:如何优雅管理声音设备与coreaudiod守护进程 每次打开Mac的音量控制菜单,看到那一长串早已不用的虚拟音频设备,是不是觉得既碍眼又影响效率?作为技术人员,我们追求的不仅是解决问题,更…...

基于MPC与事件触发通信的多智能体协同路径跟踪代码功能说明
无人船编队 无人车编队 MPC 模型预测控制 多智能体协同控制 一致性 MATLAB 无人车 USV 带原文献一、代码整体架构与核心目标 1. 核心目标 本套MATLAB源码针对多智能体协同路径跟踪(Cooperative Path Following, CPF) 问题,实现了受输入约束&a…...

CHORD-X代码生成能力展示:根据研报结论自动输出数据分析脚本
CHORD-X代码生成能力展示:根据研报结论自动输出数据分析脚本 最近在试用一个挺有意思的模型,叫CHORD-X。大家可能知道它在文本生成、对话方面挺强的,但我发现它还有个隐藏技能,或者说一个特别实用的能力延伸——它能看懂你写的分…...