【Python语言速回顾】——函数模块类与对象
目录
引入
一、函数
1、函数概述
2、参数和返回值
3、函数的调用
二、模块
1、模块概述
2、模块应用实例
三、类与对象
1、面向对象概述
2、类
3、类的特点
引入
为了使程序实现的代码更加简单。需要把程序分成越来越小的组成部分,3种方式——函数、对象、模块。
一、函数
1、函数概述
C语言大括号{}里是函数体,python种缩进块里是函数体(配合def和冒号:)
函数外面定义的变量是全局变量(大写配合下划线)
函数内部定义的局部变量(小写配合下划线),只在内部有效
def foodprice(per_price,number):sum_price = per_price*numberreturn sum_price
PER_PRICE = float(input('请输入单价:'))
NUMBER = float(input('请输入数量:'))
SUM_PRICE = foodprice(PER_PRICE,NUMBER)
print('一共',SUM_PRICE,'元')==========运行结果==========
请输入单价:15
请输入数量:4
一共 60.0 元若想在函数内部修改全局变量,并使之在整个程序生效用关键字global:
def foodprice(per_price,number):global PER_PRICEPER_PRICE = 10sum_price = per_price*numberreturn sum_price2、参数和返回值
在python种,函数参数分为3种:位置参数、可变参数、关键字参数。参数的类型不同,参数的传递方式也不同。
①位置参数
位置参数:传入参数值按照位置顺序依次赋给参数。
传递方式:直接传入参数即可,如果有多个参数,位置先后顺序不可改变。若交换顺序,函数结果则不同
def sub(x,y):return x-y
>>> sub(10,5)
5
>>> sub(5,10)
-5②关键字参数
关键字参数:通过参数名指定需要赋值的参数,可忽略参数顺序
传递方式:2种,一是直接传入参数,二是先将参数封装成字典,再在封装后的字典前添加两个星号**传入
>>> sub(y=5,x=10)
5
>>> sub(**{'y':5,'x':10})
5③默认值参数
当函数调用忘记给某个参数值时,会使用默认值代替(以防报错)
def sub(x=100,y=50):return x-y
>>> sub()
50
>>> sub(51)
1
>>> sub(10,5)
5④可变参数
可变参数:在定义函数参数时,我们不知道到底需要几个参数,只要在参数前面加上星号*即可。
def var(*param):print('可变参数param中第3个参数是:',param[2])print('可变参数param的长度是:',len(param))
>>> var('BUCT',1958,'Liming',100,'A')
可变参数param中第3个参数是: Liming
可变参数param的长度是: 5除了可变参数,后也可有普通参数(普参需要用关键字参数传值):
def var(*param,str1):print('可变参数param中第3个参数是:',param[2])print('可变参数param的长度是:',len(param))print('我是普通参数:',str1)
>>> var('BUCT',1958,'Liming',100,'A',str1 = '普参')
可变参数param中第3个参数是: Liming
可变参数param的长度是: 5
我是普通参数: 普参⑤函数的返回值
若没有用return指定返回值,则返回一个空None
result = var('BUCT',1958,'Liming',100,'A',str1 = '普参')
>>> print(result)
None若将函数改为:
def var(*param,str1):print('可变参数param中第3个参数是:',param[2])print('可变参数param的长度是:',len(param))print('我是普通参数:',str1)return param
>>> print(result)
('BUCT', 1958, 'Liming', 100, 'A')
3、函数的调用
自定义函数:先定义再调用
内置函数:直接调用,有的在特定模块里,需要先import相应模块
①嵌套调用
内嵌函数/内部函数:在函数内部再定义一个函数,作用域只在其相邻外层函数缩进块内部。
②使用闭包
闭包:函数式编程的一个重要的语法结构,在一个内部函数里对外部作用域(不是全局作用域)的变量进行引用。此时这个内部函数叫做闭包函数,如下sub2(b)就是引用了a,为闭包函数:
def sub(a):def sub2(b):result = a-breturn resultreturn sub2
print(sub(10)(5))
运行结果:5注:闭包本质还是内嵌函数,不能再全局域访问,外部函数sub的局部变量对于闭包来说是全局变量,可以访问但是不能修改。
③递归调用
递归:严格说其属于算法范畴,不属于语法范围。函数调用自身的行为叫做递归。
两个条件:调用函数自身、设置了正确的返回条件。如计算正整数N的阶乘:
常规迭代算法:
def factorial(n):result = nfor i in range(1,n):result *= ireturn result
print(factorial(10))
运行结果:3628800迭代算法:
def factorial(n):if n == 1:return 1else:return n*factorial(n-1)
print(factorial(10))
运行结果:3628800注:python默认递归深度为100层(限制),也可用sys.setrecursionlimit(x)指定递归深度。递归有危险(消耗时间和空间),因为它是基于弹栈和出栈操作;递归忘记返回时/未设置正确返回条件时,会使程序崩溃,消耗掉所有内存。
二、模块
1、模块概述
模块实际上是一种更为高级的封装。前面容器(元组,列表)是对数据的封装,函数是对语句的封装,类是方法和属性的封装,模块就是对程序的封装。——就是我们保存的实现特定功能的.py文件
命名空间:一个包含了一个或多个变量名称和它们各自对应的对象值的字典,python可调用局部命名空间和全局命名空间中的变量。
如果一个局部变量与全局变量重名,则再函数内部调用局部变量时,会屏蔽全局变量。
如果要修改函数内全局变量的值,需要借助global
①模块导入方法
方法一:
import modulename
import modulename1,modulename2使用函数时modulename.functionname()即可
方法二:
from modulename import functionname1,functionname2方法三:
import modulename as newname相当于给模块起了个新名字,便于记忆也方便调用
②自定义模块和包
自定义模块:
编写的mine.py文件放在与调用程序同一目录下,在其他文件中使用时就可import mine使用。
自定义包:
在大型项目开发中,为了避免模块名重复,python引入了按目录来组织模块的方法,称为包(package)。
包是一个分层级的文件目录结构,定义了有模块、子包、子包下的子包等组成的命名空间。
只要顶层报名不与其他人重名,内部的所有模块都不会冲突。——P114
③安装第三方包
pip install xxxx
2、模块应用实例
①日期和时间相关:datatime模块
导入:
from datetime import datetime
#不能import datetime,可以import datetime.datetime(因为datetime模块里还有一个datetime类)获取当前日期时间:
>>> now = datetime.now()
>>> print(now)
2023-10-05 17:28:24.303285获取指定日期时间:
>>> dt = datetime(2020,12,12,11,30,45)
>>> print(dt)
2020-12-12 11:30:45datetime与timestamp互相转换:
把1970-1-1 00:00:00 UTC+00:00的时间作为epoch time,记为0,当前时间就是相对于epoch time的秒数,称为timestamp。
计算机中存储的当前时间是以timestamp表示的,与时区无关,全球各地计算机在任意时刻的timestamp是相同的。
>>> dt = dt.timestamp()
>>> print(dt)
1607743845.0
#再转换回去:
>>> dt = datetime.fromtimestamp(dt)
>>> print(dt)
2020-12-12 11:30:45str转换为datetime:
用户输入的日期和时间类型是字符串,要处理日期和时间,必须把str转换为datetime
>>> test = datetime.strptime('2023-10-05 17:49:00','%Y-%m-%d %H:%M:%S') #特殊字符规定了格式
>>> print(test)
2023-10-05 17:49:00datetime转换为str:
若已有datetime对象,要把它格式化为字符才能显示给用户
>>> now = datetime.now()
>>> print(now.strftime('%a,%b %d %H:%M'))
Thu,Oct 05 17:28datetime加减计算:(再导入timedelta类)
>>> from datetime import datetime,timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2023, 10, 5, 17, 58, 9, 377124)
>>> now + timedelta(hours = 2)
datetime.datetime(2023, 10, 5, 19, 58, 9, 377124)
>>> now - timedelta(days = 3)
datetime.datetime(2023, 10, 2, 17, 58, 9, 377124)本地时间转换为UTC时间:(再导入timedelta、timezone类)
本地时间为系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。datetime里面有时区属性tzinfo。
>>> from datetime import datetime,timedelta,timezone
>>> new_utc = timezone(timedelta(hours = 8)) #创建新时区UTC+8:00
>>> new_utc1 = timezone(timedelta(hours = 7)) #创建新时区UTC+7:00
>>> now = datetime.now()
>>> now
datetime.datetime(2023, 10, 5, 18, 9, 17, 667655)
>>> test = now.replace(tzinfo = new_utc) #为当前时间强制设置新的时区
>>> test
datetime.datetime(2023, 10, 5, 18, 9, 17, 667655, tzinfo=datetime.timezone(datetime.timedelta(0, 28800)))
>>> test1 = now.replace(tzinfo = new_utc1) #为当前时间强制设置新的时区UTC+7:00
>>> test1
datetime.datetime(2023, 10, 5, 18, 9, 17, 667655, tzinfo=datetime.timezone(datetime.timedelta(0, 25200)))时区转换:
先用datetime类提供的utcnow()方法获取当前UTC时间,再用astimezone()方法转换为任意时区的时间
②读写JSON数据:json模块
JSON是一种轻量级的数据交换格式,等同于python里面的字典格式,里面可以包含方括号括起来的数组(列表)。json模块专门解决json格式的数据,提供4种方法:dumps()、dump()、loads()、load()
dumps()、dump()实现序列化功能:
dumps()实现将数据序列化为字符串str,而使用dump()时必须传文件描述符,将序列化的字符串str保存到文件中。
>>> import json
>>> json.dumps('huang')
'"huang"'
>>> json.dumps(13.14)
'13.14'
>>> dict1 = {'name':'huang','school':'buct'}
>>> json.dumps(dict1)
'{"name": "huang", "school": "buct"}'>>> with open("D:\\json_test.json","w",encoding = 'utf-8')as file_test:json.dump(dict1,file_test,indent = 4)
运行结果:dump()方法将字典数据dict_test保存到D盘文件夹下的json_test.json文件中,里面的内容如下
{"name": "huang","school": "buct"
}loads()、load()是反序列化方法:
loads()只完成了反序列化,load()只接收文件描述符,完成了读取文件和反序列化。
>>> json.loads(json.dumps(dict1)) #loads直接操作程序中的字典
{'name': 'huang', 'school': 'buct'} #dumps将字典序列化成str,loads又使其恢复字典身份>>> with open("D:\\json_test.json","r",encoding = 'utf-8')as file_test: #读刚才保存的序列化str字符串数据test_loads = json.loads(file_test.read()) #用loads实现反序列化file_test.seek(0) #重新定位在文件的第0位及开始位置test_load = json.load(file_test) #用load实现反序列化
>>> print(test_loads)
{'name': 'huang', 'school': 'buct'}
>>> print(test_load)
{'name': 'huang', 'school': 'buct'}③系统相关:sys模块
sys是python自带模块,包含了与系统相关的信息。可通过help(sys)或dir(sys)查看sys模块的可用方法(很多),下面列举几种。
sys.path包含输入模块的目录名列表:
>>> sys.path
['','D:\\python3.6.6\\Lib\\idlelib',
'D:\\python3.6.6\\python36.zip',
'D:\\python3.6.6\\DLLs',
'D:\\python3.6.6\\lib',
'D:\\python3.6.6',
'D:\\python3.6.6\\lib\\site-packages']该命令获取了指定模块搜索路径的字符串集合。将写好的模块放在上面得到的某个路径下,就可以在使用import导入时正确找到,也可以用sys.path.append(自定义路径)添加模块路径。——“自定义模块乱放程序是找不到的!”
sys.argv在外部向程序内部传递参数:
????
sys.argv变量是一个包含了命令行参数的字符串列表,利用命令行向程序传递参数。其中脚本的名称是sys.argv列表的第一个参数。
④数学:math模块
math模块也是python自带模块,包含了和数学运算公式相关的信息——P125
⑤随机数:random模块
列举常用模块:
生成随机整数(需指定上下限,且下限小于上限):randint
import random
>>> random.randint(10,2390) #生成指定范围内的随机整数
2375生成随机浮点数:random
>>> random.random()
0.9935870033845187
>>> random.uniform(10,100)
27.07308173076904
>>> random.uniform(100,10)
18.198994262912336随机字符:choice
>>> random.choice('98%$333#@')
'3'洗牌:shuffle
>>> test = ['a','B',1,2,5,'%']
>>> random.shuffle(test)
>>> print(test)
[5, 1, 2, 'a', 'B', '%']三、类与对象
1、面向对象概述
面向对象编程(Object Oriented Programming,OOP),是一种程序设计思想,是以建立模型体现出来的抽象思维过程和面向对象的方法。
模型是用来反映现实世界中的事物特征的,是对事物特征和变化规律的抽象化,是更普遍、更集中、更深刻地描述客体的特征。
OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
术语简介:
1、类:是创建对象的代码段,描述了对象的特征、属性、要实现的功能,以及采用的方法等。
2、属性:描述了对象的静态特征。
3、方法:描述了对象的动态动作。
4、对象:对象是类的一个实例,就是模拟真实事件,把数据和代码段都集合到一起,即属性、方法的集合。
5、实例:就是类的实体。
6、实例化:创建类的一个实例过程。
7、封装:把对象的属性、方法、事件集中到一个统一的类中,并对调用者屏蔽其中的细节。
8、继承:一个类共享另一个类的数据结构和方法的机制称为继承。起始类称为基类、超类、父类,而继承类称为派生类、子类。继承类是对被继承类的拓展。
9、多态:一个同样的函数对于不同的对象可以具有不同的实现。
10、接口:定义了方法、属性的结构,为其成员提供违约,不提供实现。不能直接从接口创建对象,必须首先创建一个类来实现接口所定义的内容。
11、重载:一个方法可以具有许多不同的接口,但方法的名称是相同的。
12、事件:事件是由某个外部行为所引发的对象方法。
13、重写:在派生类中,对基类某个方法的程序代码及进行重新编码,使其实现不同的功能。
14、构造函数:是创建对象所调用的特殊方法。
15、析构函数:是释放对象时所调用的特殊方法。2、类
①类的定义
类就是对象的属性和方法的拼接,静态的特征称为属性,动态的动作称为方法。
>>> class Person: #规定类名以大写字母开头#属性skincolor = "yellow"high = 185weight = 75#方法def goroad(self):print("人走路动作的测试...")def sleep(self):print("睡觉,晚安!")②类的使用(类实例化为对象)
>>> p = Person() #将类实例化为对象,注意后面要加括号()③类的构造方法及专有方法
类的构造方法:__int__(self)。只要实例化一个对象,此方法就会在对象被创建时自动调用——实例化对象时是可以传入参数的,这些参数会自动传入__int__(self,param1,param2...)方法中,可以通过重写这个方法来自定义对象的初始化操作。
>>> class Bear:def __init__(self,name):self.name = namedef kill(self):print("%s是保护动物不可猎杀"%self.name)>>> a = Bear("狗熊")
>>> a.kill()
狗熊是保护动物不可猎杀解释:与Person()相比,这里重写了__init__()方法,不然默认为__init__(self)。在Bear()中给了一个参数name,成了__init__(self,name),第一个参数self是默认的,所以调用时把“狗熊”传给了name。也可以给name默认参数,这样即使忘记传入参数,程序也不会报错:
>>> class Bear:def __init__(self,name = "狗熊"):self.name = namedef kill(self):print("%s是保护动物不可猎杀"%self.name)>>> b = Bear()
>>> b.kill()
狗熊是保护动物不可猎杀
>>> c = Bear("丹顶鹤")
>>> c.kill()
丹顶鹤是保护动物不可猎杀④类的访问权限
在C++和JAVA中是通过关键字public、private来表明访问权限是共有的还是私有的。在python中,默认情况下对象的属性和方法是公开的、公有的,通过点(.)操作符来访问。如上面的kill()函数(方法)的访问,也可以访问变量:
>>> class Test:name = "大连橡塑">>> a = Test()
>>> a.name
'大连橡塑'若变量前面加上双下划线(__)就表示声明为私有变量就不可访问:
>>> class Test:__name = "君欣旅店">>> a = Test()
>>> a.__name
Traceback (most recent call last):File "<pyshell#4>", line 1, in <module>a.__name
AttributeError: 'Test' object has no attribute '__name'可利用函数方法访问私有变量:
>>> class Test:__name = "君欣旅店"def getname(self):return self.__name>>> a = Test()
>>> a.getname()
'君欣旅店'也可通过"_类名__变量名"格式访问私有变量:
>>> a._Test__name
'君欣旅店'(由此可见python的私有机制是伪私有,python的类是没有权限控制的,变量可以被外界调用)
⑤获取对象信息
类实例化对象后(如a = Test()),对象就可以调用类的属性和方法:
即a.getname()、a.name、a.kill()这些
3、类的特点
①封装
形式上看,对象封装了属性就是变量,而方法和函数是独立性很强的模块,封装就是一种信息掩蔽技术,使数据更加安全!
如列表实质上是python的一个序列对象,sort()就是其中一个方法/函数:
>>> list1 = ['E','C','B','A','D']
>>> list1.sort()
>>> list1
['A', 'B', 'C', 'D', 'E']②多态
不同对象对同一方法响应不同的行动就是多态(内部方法/函数名相同,但是不同类里面定义的功能不同):
>>> class Test1:def func(self):print("这是响应1...")
>>> class Test2:def func(self):print("这是响应2...")
>>> x = Test1()
>>> y = Test2()
>>> x.func()
这是响应1...
>>> y.func()
这是响应2...注意:self相当于C++的this指针。由同一个类可以生成无数个对象,这些对象都源于同一个类的属性和方法,当一个对象的方法被调用时,对象会将自身作为第一个参数传给self参数,接收self参数时,python就知道是哪个对象在调用方法了。
③继承
继承是子类自动共享父类数据和方法的机制。语法格式如下:
class ClassName(BaseClassName):
...
ClassName:子类名称,第一个字母必须大写。
BaseClassName/paraname:父类名称。子类可继承父类的任何属性和方法,如下定义类Test_list继承列表list的属性和方法(append和sort):
>>> class Test_list(list):pass>>> list1 = Test_list()
>>> list1.append('B')
>>> list1
['B']
>>> list1.append('UCT')
>>> list1
['B', 'UCT']
>>> list1.sort()
>>> list1
['B', 'UCT']使用类继承机制时的注意事项:
a、若子类中定义与父类同名的方法或属性,自动覆盖父类里对应的属性或方法。
b、子类重写父类中同名的属性或方法,若被重写的子类同名的方法里面没有引入父类同名的方法,实例化对象调用父类的同名方法就会出错:
import random
class Dog:def __init__(self):self.x = random.randint(1,100) #两个缩进self.y = random.randint(1,100)def run_Dog(self):self.x += 1print("狗狗的位置是:",self.x,self.y)class Dog1(Dog):passclass Dog2(Dog):def __init__(self):self.hungry = True def eat(self):if self.hungry:print("狗想吃东西了!")self.hungry = Falseelse:print("狗吃饱了!")调用:
>>> dog = Dog()
>>> dog.run_Dog()
狗狗的位置是: 62 69
>>> dog1 = Dog1()
>>> dog1.run_Dog()
狗狗的位置是: 29 89
>>> dog2 = Dog2()
>>> dog2.eat()
狗想吃东西了!
>>> dog2.eat()
狗吃饱了!
>>> dog2.run_Dog() #报错报错!!!分析:子类Dog2重写了父类(基类)Dog的构造函数__init__(self),则父类构造函数里的方法被覆盖。要解决此问题,就要在子类里面重写父类同名方法时,先引入父类的同名方法,两种技术:a、调用未绑定的父类方法;b、使用super函数
a、调用未绑定的父类方法——语法格式:paraname.func(self)。父类名.方法名.(self)
对上面示例代码的Dog2类更改:
def __init__(self):Dog.__init__(self) #加了这一行self.hungry = True
调用:
>>> dog2 = Dog2()
>>> dog2.run_Dog()
狗狗的位置是: 85 16b、使用super函数,该函数可以自动找到父类方法和传入的self参数,语法格式:super().func([parameter])。parameter为可选参数,若是self可省略。
对上面示例代码的Dog2类更改:
def __init__(self):super().__init__() #加了这一行self.hungry = True调用:
>>> dog2 = Dog2()
>>> dog2.run_Dog()
狗狗的位置是: 96 82使用super函数的方便之处在于不用写任何关于基类(父类)的名称,直接写重写的方法即可,会自动去父类去寻找,尤其在多重继承中,或者子类有多个祖先类时,能自动跳过多种层级去寻找。如果以后要更改父类,直接修改括号()里面的父类名称即可,不用再修改重写的同名方法里的内容。
④多重继承
一个子类同时继承多个父类的属性和方法:
class Classname(Base1,Base2,Base3):...虽然多重继承的机制可以使子类继承多个属性和方法,但是容易导致代码混乱,引起不可预见的Bug,一般尽量避免使用。

相关文章:
【Python语言速回顾】——函数模块类与对象
目录 引入 一、函数 1、函数概述 2、参数和返回值 3、函数的调用 二、模块 1、模块概述 2、模块应用实例 三、类与对象 1、面向对象概述 2、类 3、类的特点 引入 为了使程序实现的代码更加简单。需要把程序分成越来越小的组成部分,3种方式——函数、对象…...
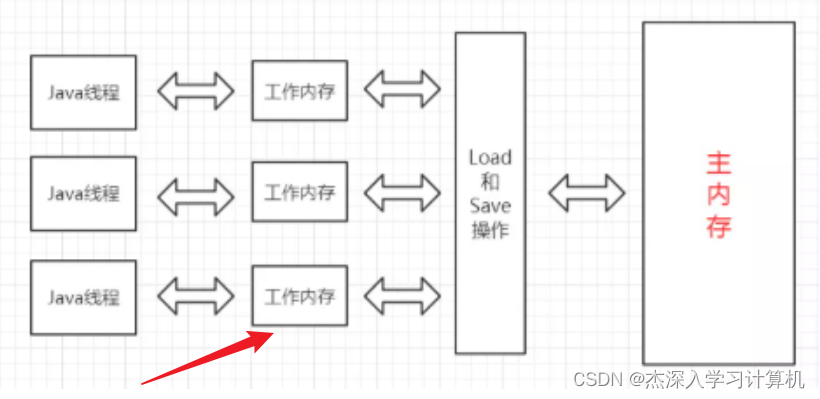
【JavaEE】Java的多线程编程基础知识 -- 多线程篇(2)
Java多线程编程基础知识 一、多线程的创建二、Thread类常用的方法和API2.1 Thread 的几个常见的属性2.2 start 启动一个线程2.3 终止一个线程2.4 等待一个线程-join()2.5 线程休眠函数 -sleep() 三、线程状态3.1 观察所有线程的状态3.2 线程状态和线程转移的意义 四、线程安全&…...
)
MFC Windows 程序设计[330]之表头控件例程(附源码)
MFC Windows 程序设计[330]之表头控件例程 程序之美前言主体运行效果核心代码逻辑分析结束语程序之美 前言 MFC是微软公司提供的一个类库(class libraries),以C++类的形式封装了Windows API,并且包含一个应用程序框架,以减少应用程序开发人员的工作量。其中包含大量Wind…...

SettingsIntelligence
Android Settings 系列文章: Android Settings解析SettingsIntelligenceSettingsProvider 首语 Android Settings中搜索功能帮助我们可以快速访问设置项,进行自定义设置,以得到更佳的使用体验。Android Settings搜索的实现实际不在Setting…...

C#WPF Prism框架区域管理应用实例
本文实例演示C#WPFPrism框架区域管理应用实例 目录 一、Prism框架区域 二、不使用Prism框架的RegionManager 三、使用Prism框架的RegionManager 一、Prism框架区域...
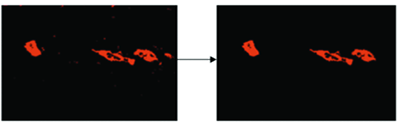
LabVIEW基于机器视觉的钢轨表面缺陷检测系统
LabVIEW基于机器视觉的钢轨表面缺陷检测系统 机器视觉检测技术和LabVIEW软件程序,可以实现轨道工件的表面质量。CMOS彩色工业相机采集的图像通过图像预处理、图像阈值分割、形态分析、特征定位和图案匹配进行处理和分析。图形显示界面采用LabVIEW软件编程设计&…...

Qt程序的发布和打包,任何电脑都可以安装
## 1. Qt程序的发布 当Qt程序编写完成通过IDE编译就可以得到对应的可执行程序,这个可执行程序在本地运行是完全没有问题的(因为在本地有Qt环境,程序运行过程中可以加载到相关的动态库),但是如果我们想把这个Qt程序给到其他小伙伴使用可能就会出问题了,原因如下: 对方电…...
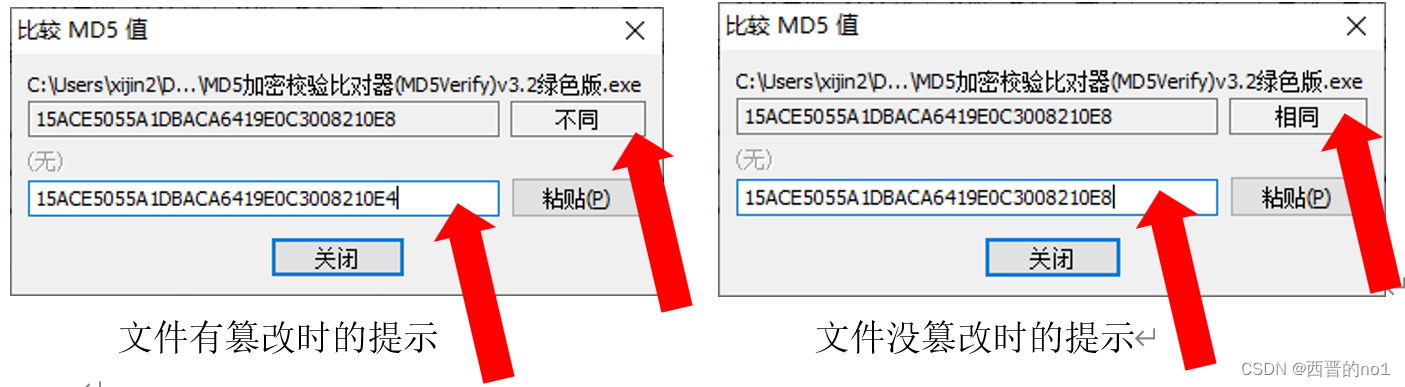
MD5生成和校验
MD5生成和校验 2021年8月19日席锦 任何类型的一个文件,它都只有一个MD5值,并且如果这个文件被修改过或者篡改过,它的MD5值也将改变。因此,我们会对比文件的MD5值,来校验文件是否是有被恶意篡改过。 什么是MD5ÿ…...

PostgreSQL 正则表达式匹配字段
在 PostgreSQL 数据库中,可以使用 ~ 和 !~ 操作符进行正则表达式的匹配和否定匹配。还可以使用 :: 操作符进行正则表达式的模式匹配。 例如,假设我们有一个名为 users 的表,其中有一个名为 email 的字段,我们可以使用以下 SQL 语句…...
关于iterm2的美化
iterm2 美化 笔者公司最近给发了一个新 M1 mac pro,所以一些软件需要重新安装。其中比较麻烦就是iterm2的一个美化工程 , 由于每次安装的效果都不尽相同所以这次写一个博客来记录一下 安装的过程 。 全程高能开始: 使用brew 来安装 iterm2 …...

Hook原理--逆向开发
今天我们将继续讲解逆向开发工程另一个重要内容--Hook原理讲解。Hook,可以中文译为“挂钩”或者“钩子”,逆向开发中改变程序运行的一种技术。按照如下过程进行讲解 Hook概述Hook技术方式fishhook原理及实例符号表查看函数名称总结 一、Hook概述 在逆…...

做数据可视化,谨记三大要点
数据可视化报表就是“一图胜千言”的最佳例子。数据可视化,也就是将数据图形化、图表化,以良好的视觉效果呈现数据,达到发现、分析、预测、监控、决策等目的。要想做出一份优秀的数据可视化报表,那就要在做报表时谨记三大要点&…...

软件设计原则-接口隔离原则讲解以及代码示例
接口隔离原则 一,介绍 1.前言 接口隔离原则(Interface Segregation Principle,ISP)是面向对象设计中的一个原则,提倡使用多个专门的接口,而不使用单一的大接口。它最早由Robert C. Martin在其《敏捷软件…...

yolov8x-p2 实现 tensorrt 推理
简述 在最开始的yolov8提供的不同size的版本,包括n、s、m、l、x(模型规模依次增大,通过depth, width, max_channels控制大小),这些都是通过P3、P4和P5提取图片特征; 正常的yolov8对象检测模型输出层是P3、…...

Type Script的变量类型
Typescript 的重要特性之一就是数据有类型了。 常见的类型如:字符串、数值、布尔等都有了明确的定义。 变量声明的格式 let 变量名:类型 初始值;字符型 let str:string "abc";数值型 数值型也支持不同的进制,用前缀区分 支持 整…...

系统架构师备考倒计时13天(每日知识点)
1. 数据仓库四大特点 面向主题的。操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。集成的。数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整…...

20 | Spring Data JPA 中文文档
Spring Data JPA 中文文档 1. 前言 Spring Data JPA 为 Jakarta Persistence API(JPA)提供 repository 支持。它简化了需要访问JPA数据源的应用程序的开发。 1.1. 项目元数据 版本控制: https://github.com/spring-projects/spring-data-jpaBug跟踪:…...

【AOA-VMD-LSTM分类故障诊断】基于阿基米德算法AOA优化变分模态分解VMD的长短期记忆网络LSTM分类算法(Matlab代码)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

K8s:Pod 中 command、args 与 Dockerfile 中 CMD、 ENTRYPOINT 的对应关系
写在前面 前几天被问到,这里整理笔记之前也没怎么注意这个问题理解不足小伙伴帮忙指正 曾以为老去是很遥远的事,突然发现年轻是很久以前的事了。时光好不经用,抬眼已是半生,所谓的中年危机,真正让人焦虑的不是孤单、不…...

Visual Studio Code (VS Code)安装教程
Visual Studio Code(简称“VS Code”)。 1.下载安装包 VS Code的官网: Visual Studio Code - Code Editing. Redefined 首先提及一下,vscode是不需要破解操作的; 第一步,看好版本,由于我的系…...

终极指南:为什么Tree of Thoughts思维树算法能提升AI推理能力70%?
终极指南:为什么Tree of Thoughts思维树算法能提升AI推理能力70%? 【免费下载链接】tree-of-thoughts Plug in and Play Implementation of Tree of Thoughts: Deliberate Problem Solving with Large Language Models that Elevates Model Reasoning by…...

8大网盘直链下载助手:告别限速困扰,一键获取真实下载地址
8大网盘直链下载助手:告别限速困扰,一键获取真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

Janus-Pro-7B企业知识管理:基于AI的文档智能检索与摘要
Janus-Pro-7B企业知识管理:基于AI的文档智能检索与摘要 你是不是也遇到过这种情况?公司服务器里堆满了产品手册、项目报告、会议纪要,想找个资料得翻半天,最后还不一定能找到。或者,一份几十页的技术文档摆在面前&…...

终极Windows与Office激活指南:5分钟完成智能激活的完整解决方案
终极Windows与Office激活指南:5分钟完成智能激活的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统或Office办公套件的激活问题而烦恼?…...

影像诊断四剑客:B超、X光、CT、核磁共振如何各显神通
1. 影像诊断四剑客:谁是你的最佳拍档? 第一次去医院做影像检查时,面对医生开的B超、X光、CT、核磁共振检查单,你是不是也一头雾水?这四种检查看起来都很高科技,但价格相差悬殊,等待时间也各不相…...
)
别再死磕A*了!用MATLAB从零实现RRT*路径规划(附完整代码与避坑指南)
从A到RRT:MATLAB实战高维空间路径规划全解析 当传统栅格搜索算法在机器人关节空间或复杂三维环境中捉襟见肘时,概率采样方法正成为新一代路径规划的核心利器。本文将带您深入理解RRT算法相对于A的突破性优势,并通过MATLAB完整实现过程&#…...

SD-PPP:Photoshop与AI绘图工作流的革命性融合
SD-PPP:Photoshop与AI绘图工作流的革命性融合 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 在创意设计领域,传统工作流程中设计师需要在多个软件间频繁切换,这种割裂的操作模式…...

Jimeng AI Studio实操案例:LoRA风格库管理与热加载最佳实践
Jimeng AI Studio实操案例:LoRA风格库管理与热加载最佳实践 1. 引言:为什么需要LoRA动态管理? 想象一下这样的场景:你正在使用AI生成图片,突然想要尝试不同的艺术风格。传统方式需要重启整个应用,重新加载…...

Hunyuan-MT Pro多语言落地:支持阿拉伯语从右向左排版+Unicode特殊字符处理
Hunyuan-MT Pro多语言落地:支持阿拉伯语从右向左排版Unicode特殊字符处理 1. 项目概述 Hunyuan-MT Pro是一个基于腾讯混元(Hunyuan-MT-7B)开源模型构建的现代化翻译Web终端。它结合了Streamlit的便捷交互与混元模型强大的多语言理解能力&am…...

RTX 4090用户必看:Anything to RealCharacters 2.5D转真人引擎环境部署与性能调优
RTX 4090用户必看:Anything to RealCharacters 2.5D转真人引擎环境部署与性能调优 获取更多AI镜像 想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领…...