Hadoop3教程(三十一):(生产调优篇)异构存储
文章目录
- (157)异构存储概述
- 概述
- 异构存储的shell操作
- (158)异构存储案例实操
- 参考文献
(157)异构存储概述
概述
异构存储,也叫做冷热数据分离。其中,经常使用的数据被叫做是热数据,不经常使用的数据被叫做冷数据。
把冷热数据,分别存储在不同的存储介质里,从而达到对每个介质的利用率最高,从而实现整体最佳性能,或者说性价比更高(比如说高性能硬盘放经常使用的数据)。
简单的说,就是这么一个问题:经常使用的数据、不经常使用的数据,是分别放在固态硬盘里更好,还是放在机械硬盘里更好,亦或者是放在内存里更好?
一般来讲,集群里会有这么几种存储类型:
- RAM_DISK:内存镜像文件系统;
- SSD:SSD固态硬盘;
- DISK:普通磁盘。在HDFS中,如果没有主动声明,那么数据目录存储类型默认都是DISK;
- ARCHIVE:没有特指哪种存储介质,主要是指计算能力弱而存储密度比较高的存储介质,用来解决数据量的容量扩增问题,一般用于归档;
关于存储策略:

注意, 默认存储策略是HOT策略 ,即所有副本都保存在磁盘里。
访问速度最快的是Lazy_persist策略,一个副本保存在内存中,其它副本保存在磁盘中。
异构存储的shell操作
(1)查看当前有哪些存储策略可以用
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -listPolicies
(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
(5)查看某个路径下的文件块的分布
bin/hdfs fsck <path> -files -blocks -locations
(6)查看集群节点
hadoop dfsadmin -report
可以看到,跟纠删码一样,异构存储针对的对象,也是某一个路径。
(158)异构存储案例实操
这块在教程里比较长,都是实验各种存储策略的代码,所以只挑选个人感兴趣的地方做简单记录,就不批量复制了,仅做了解即可。
关于集群如何识别自己的存储介质的类型?
是无法自动辨别的,需要在节点的hdfs-site.xml中手动指定,一个路径如果你指定了是SSD的话,那集群就认为它就是SSD。
举例,我要给一个节点,配置上SSD目录和RAM_DISK目录,就可以打开该节点上的hdfs-site.xml,添加或修改如下信息:
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.storage.policy.enabled</name><value>true</value>
</property>
<property><name>dfs.datanode.data.dir</name> <value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>
上面代码里,第一个property是设置副本数量为2,第二个property是设置异构存储策略为打开状态,最后一个property则是将两个路径分别指定成SSD目录和RAM_DISK目录。
教程里一共列举了5个节点,分别修改它们的hdfs-site.xml,做不同的存储类型分配,如下:
| 节点 | 存储类型分配 |
|---|---|
| hadoop102 | RAM_DISK,SSD |
| hadoop103 | SSD,DISK |
| hadoop104 | DISK,RAM_DISK |
| hadoop105 | ARCHIVE |
| hadoop106 | ARCHIVE |
我们在HDFS上创建一个新目录,然后上传一个新文件到目录里:
hadoop fs -mkdir /hdfsdata
hadoop fs -put /opt/module/hadoop-3.1.3/NOTICE.txt /hdfsdata
新建的目录默认是HOT存储策略,即所有副本都存储在DISK上,我们可以验证一下,即使用下面命令,查看上传的文件块分布:
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
其实执行命令之后,打印出来的信息有很多,我们只展示了一小部分,从输出上可以看到,一个副本存储在了104的DISK目录下,另一个副本存储在了103的DISK目录下。
接下来,我们尝试将这个目录的存储策略修改为WARM策略,即一个副本在DISK上,其他副本在ARCHIVE上。
(1)首先,修改这个目录的存储策略修改为WARM策略
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM
(2)再次查看文件块分布,我们可以看到文件块依然放在原处。
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations
(3)我们需要让他HDFS按照存储策略自行移动文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs mover /hdfsdata
(4)再次查看文件块分布,
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs fsck /hdfsdata -files -blocks -locations[DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
可以看到,执行了hdfs mover /hdfsdata之后,在103的DISK目录里的那个副本没有变化,另一个副本移动到了105上的ARCHIVE目录里。
接下来,教程里按照上面的流程,依次测试了其他几种策略,基本流程和命令都是一样的,所以这里就不展示了。
唯一需要注意的,是LAZY_PERSIST策略,理论上执行了策略之后,会达到一个副本在RAM_DISK,即内存中,另一个副本在DISK中的效果。但实际中并不是。有两个原因:
一是在Hadoop的配置文件里,有一个dfs.datanode.max.locked.memory,它控制了你往内存里存储副本数据的大小,这个参数默认是0,即不能往内存里存数据。
二是如果你用的是linux虚拟机的话,虚拟机也会限制你往内存中放数据的大小。
基于这两个原因,实际中的LAZY_PERSIST策略并不会生效。从而导致所有副本都被放进了DISK目录里。
如果实在想往内存里放副本,可以尝试将dfs.datanode.max.locked.memory修改为文件块大小(默认128M)的倍数,但是生产中是不推荐的。毕竟放在内存里容易宕机丢失,后果还是蛮严重的。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(三十一):(生产调优篇)异构存储
文章目录 (157)异构存储概述概述异构存储的shell操作 (158)异构存储案例实操参考文献 (157)异构存储概述 概述 异构存储,也叫做冷热数据分离。其中,经常使用的数据被叫做是热数据&…...

网络协议--UDP:用户数据报协议
11.1 引言 UDP是一个简单的面向数据报的运输层协议:进程的每个输出操作都正好产生一个UDP数据报,并组装成一份待发送的IP数据报。这与面向流字符的协议不同,如TCP,应用程序产生的全体数据与真正发送的单个IP数据报可能没有什么联…...
vscode摸鱼插件开发
不知道大家在写代码的时候,摸不摸鱼,是不是时不时得打开一下微博,看看今天发生了什么大事,又有谁塌房,而你没有及时赶上。 为此,我决定开发一个vscode插件,来查看微博热搜 插件名称࿱…...
音频录制和处理软件 Audio Hijack mac中文版说明
Audio Hijack mac是一款功能强大的音频录制和处理软件,它可以帮助用户从各种来源捕获和处理音频。 首先,Audio Hijack具有灵活的音频捕获功能。它支持从多个来源录制音频,包括麦克风、应用程序、网络流媒体、硬件设备等等。你可以选择捕获整个…...

寻找二叉树一个节点的后继节点
后继节点:中序遍历的后一个节点 普通二叉树:中序遍历得到一个list,时间复杂度O(n) 本题的二叉树:有父节点的指针,后继节点与原节点的距离为1,因此可以直接通过父节点找到下一个节点 优化:节点…...

如何能够获取到本行业的能力架构图去了解自己的能力缺陷与短板,从而能清晰的去弥补差距?
如何能够获取到本行业的能力架构图去了解自己的能力缺陷与短板,从而能清晰的去弥补差距? 获取并利用能力架构图(Competency Model)来了解自己在特定行业或职位中的能力缺陷和短板,并据此弥补差距,是一个非常…...

红队打靶:Misdirection打靶思路详解(vulnhub)
目录 写在开头 第一步:主机发现与端口扫描 第二步:Web渗透(80端口,战术放弃) 第三步:Web渗透(8080端口) 第四步:sudo bash提权 第五步:/etc/passwd利…...

10.23归并排序
课上 归并排序 最大时,就是两个都是完全倒序,但注意一定有一个序列先用完,此时剩一个序列只有一个元素,不用比较,直接加入,所以就是nn-1, 最小时,是都是完全有序,且一个序列中的元…...
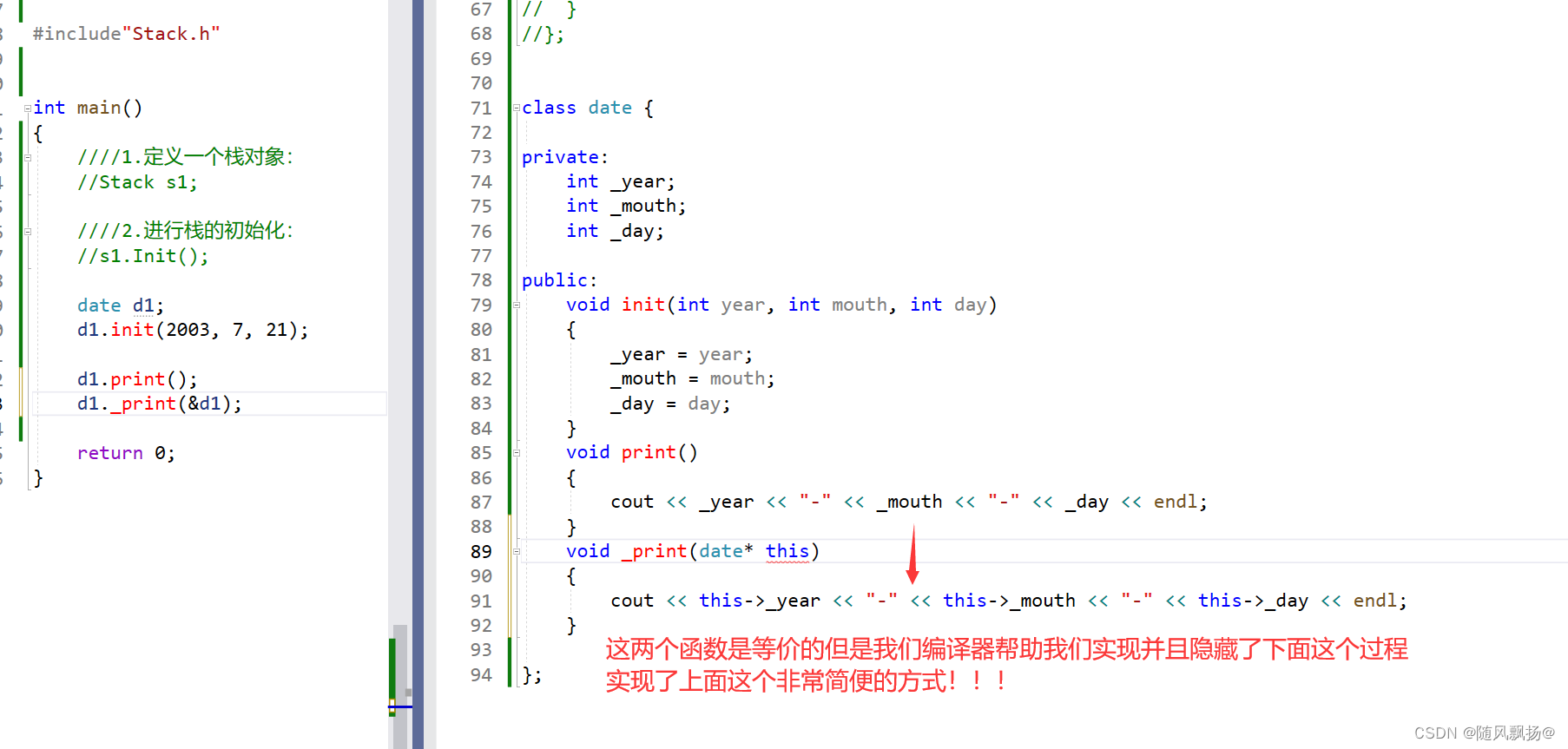
[C++]:2初识C++(auto) + 类和对象上:
[TOC](初识C(auto) 类和对象上) 一.初始C 1.auto关键字:(C11) 1.作为一个变量的类型给这个类型初始化,auto自动识别初始化这个变量值的类型,为auto类型的这个变量开辟一个合适的空间。 补充: 1.typeid(变量名).name—>可以打…...

大学英语试卷
大学英语试卷 If everyone learns to set forth facts and reason things out in social life, many of the contradictions are easy to ____. A. oblige B. engage C. resolve D. commitIf we let the fastest runner set the____, the others will fall behind. A. pace B.…...

SpringBoot Lombok的使用
目录 下载Lombok插件 Lombok的用法 获取日志对象 生成get,set方法 Lombok框架的实现原理 Lombok的常用注解 下载Lombok插件 要使用Lombok首先要确保idea安装了lombok插件 在项目中添加 lombok依赖 在<dependency>里右键生成点击edit starters 插件(没有就下载,可…...

后台管理系统SQL注入漏洞
对于edu来说,是新人挖洞较好的平台,本次记录一次走运的捡漏0x01 前景 在进行fofa盲打站点的时候,来到了一个后台管理处看到集市二字,应该是edu站点 确认目标身份(使用的quake进行然后去ipc备案查询) 网…...

变量常用函数
查看变量类型 type(变量名) 用来查询变量所指的对象类型 >>> a, b, c, d 20, 5.5, True, 43j >>> print(type(a), type(b), type(c), type(d)) <class int> <class float> <class bool> <class complex> 基础数据类型 # coding…...
)
从零学算法(LCR 157)
某店铺将用于组成套餐的商品记作字符串 goods,其中 goods[i] 表示对应商品。请返回该套餐内所含商品的 全部排列方式 。 返回结果 无顺序要求,但不能含有重复的元素。 示例 1: 输入:goods “agew” 输出:[“aegw”,“aewg”,“ag…...

mysql 优化 聚簇索引=主键索引吗
在 InnoDB 引擎中,每张表都会有一个特殊的索引“聚簇索引”,也被称之为聚集索引,它是用来存储行数据的。一般情况下,聚簇索引等同于主键索引,但这里有一个前提条件,那就是这张表需要有主键,只有…...

c# ManualResetEvent WaitHandle 实现同步
//本文演示了ManualResetEvent 类的非静态set()、Reset()、WaitOne()和 //WaitHandle类的静态方法WaitAllWaitAll() //它们用于线程间的同步控制。 //实现了如下功能:线程1(定时控制)通知线程2和线程3采集数据 //线程2和3数据采集完了&am…...
使用Packstack安装器安装一体化OpenStack云平台
【实训目的】 初步掌握OpenStack快捷安装的方法。掌握OpenStack图形界面的基本操作。 【实训准备】 (1)准备一台能够安装OpenStack的实验用计算机,建议使用VMware虚拟机。 (2)该计算机应安装CentOS 7,建…...

【Rust】4 一文讲解重点 pattern matching | trait | 生命周期 | 闭包 | 迭代器 | 智能指针 | 并发与并行
文章目录 一、pattern matching二、trait2.1 常见 trait2.1.1 Copy 和 Clone2.1.2 PartialEq 和 Eq2.1.3 PartialOrd 和 Ord2.1.4 Hash2.1.5 From, Into, TryFrom, TryInto 2.2 概念2.2.1 关联类型2.2.2 关联常量2.3.3 泛型关联类型2.3.3.1 示例: 用泛型关联类型, 创建集合工厂…...
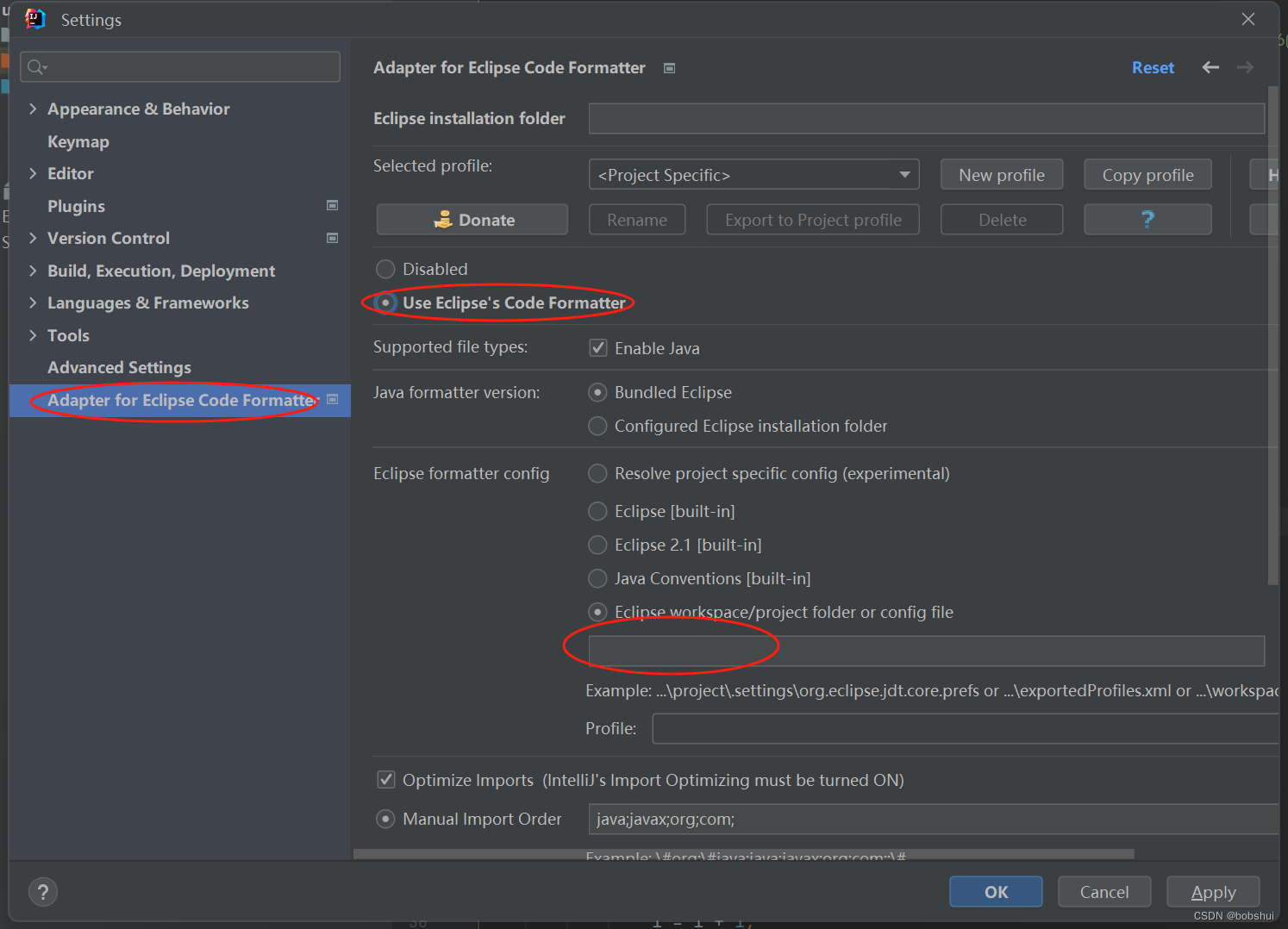
idea Java代码格式化规范
文章目录 引入基础知识代码模板idea模板eclipse模板1.安装插件2.生成配置文件3.导入配置文件 附录一:xml配置项说明附录二:赠送 引入 最近在公司开发中,遇到了一点小问题,组内各同事的格式化规范不一致。一来导致代码样式并不统一…...
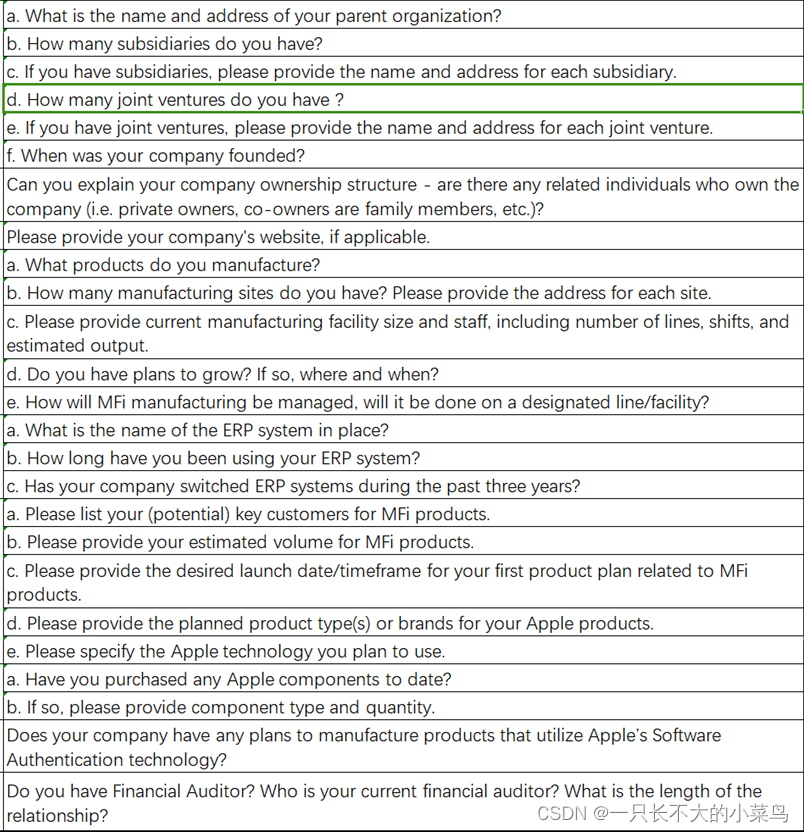
apple MFI工厂认证,干货,为防止MFI工作人员查看,已设置VIP阅读
一开始以为审核特别严格,准备了好久,经历过了之后会发现很简单,1个小时完成了所有审核事项。 好好招待审计员,比如能接送就接送,到点吃饭就尽量约时间吃饭后再审计,找个正式的会议室,该摆盘水果就摆上,让审计员感觉到公司是很重视这次的MFI审核,但是不能贿赂发红包那…...

Ollama部署granite-4.0-h-350m:轻量模型本地运行完整教程
Ollama部署granite-4.0-h-350m:轻量模型本地运行完整教程 1. 为什么选择granite-4.0-h-350m 1.1 轻量级模型的优势 granite-4.0-h-350m是一个仅有350M参数的轻量级指令模型,专为本地部署和资源受限环境设计。相比动辄数十GB的大型模型,它具…...

终极加速方案:Surge与Core ML集成指南,让机器学习推理性能提升300%
终极加速方案:Surge与Core ML集成指南,让机器学习推理性能提升300% 在当今AI应用爆炸式增长的时代,机器学习模型推理速度已成为决定用户体验的关键因素。如果你正在为iOS或macOS应用开发机器学习功能,那么Surge这个基于Accelerat…...

大麦网自动抢票Python脚本:5步实现高成功率智能购票系统
大麦网自动抢票Python脚本:5步实现高成功率智能购票系统 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 想要在热门演唱会门票秒光前抢到心仪的座位吗?…...

Is620伺服驱动电机成熟量产伺服控制器开发设计方案及代码完整原理图
伺服控制器开发设计方案成熟量产伺服控制器方案 Is620伺服驱动电机,提供DSP程序和原理图,代码完整,学习工业代码的范例,采用ES232,RS485及CAN通讯接口处提供刚性表设置,惯性识别及振动抑制功能抄起示波器探头直奔实验…...
)
Java 25虚拟线程与Project Loom深度绑定解析(2025生产环境禁用清单首次公开)
第一章:Java 25虚拟线程与Project Loom深度绑定解析(2025生产环境禁用清单首次公开)Java 25正式将Project Loom的虚拟线程(Virtual Threads)从预览特性升级为**完全标准化、JVM内建的并发原语**,但这一演进…...

科研进展 | JAG: 大光斑高光谱激光雷达遥感辐射传输模型从垂直视角解锁森林叶绿素分布密码
大光斑高光谱激光雷达辐射传输模型: 垂直视角解锁叶绿素分布密码当森林的 “健康密码” 藏在垂直分层的枝叶间,传统遥感技术难以触及森林冠层中下层的生化奥秘? 近日,电子科技大学定量遥感团队白杰副研究员(师资博士后)…...

用例模型,分析模型,领域模型和数据模型比较
用例模型、分析模型、领域模型、数据模型比较 在软件工程和系统分析中,用例模型、分析模型、领域模型、数据模型分别服务于不同阶段和不同目的。理解它们的区别与联系,有助于系统分析师构建完整、一致的解决方案。 一、各模型核心定位 模型 英文 核心目标 主要视角 主要受众…...

什么年代了怎么还在用bash啊?现代化shell开箱体验: fish, nu, elvish口
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

Tauri 2.0 Shell插件避坑指南:预设参数覆盖、权限配置与Command.create的正确姿势
Tauri 2.0 Shell插件深度实战:参数控制、权限设计与Command最佳实践 当你在Tauri项目中尝试通过Shell插件调用外部程序时,是否遇到过参数莫名失效、权限配置不生效的困扰?本文将带你深入tauri-apps/plugin-shell的设计哲学,通过真…...

[Refactor]CPP Learn Data Day 信
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...