rust学习——泛型 (Generics)
文章目录
- 泛型 Generics
- 泛型详解
- 结构体中使用泛型
- 枚举中使用泛型
- 方法中使用泛型
- 为具体的泛型类型实现方法
- const 泛型(Rust 1.51 版本引入的重要特性)
- const 泛型表达式
- 泛型的性能
泛型 Generics
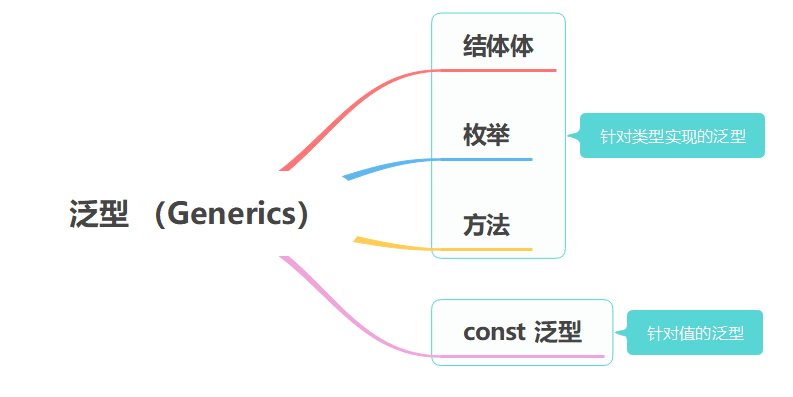
Go 语言在 2022 年,就要正式引入泛型,被视为在 1.0 版本后,语言特性发展迈出的一大步,为什么泛型这么重要?到底什么是泛型?Rust 的泛型有几种? 本章将一一为你讲解。
我们在编程中,经常有这样的需求:用同一功能的函数处理不同类型的数据,例如两个数的加法,无论是整数还是浮点数,甚至是自定义类型,都能进行支持。在不支持泛型的编程语言中,通常需要为每一种类型编写一个函数:
fn add_i8(a:i8, b:i8) -> i8 {a + b
}
fn add_i32(a:i32, b:i32) -> i32 {a + b
}
fn add_f64(a:f64, b:f64) -> f64 {a + b
}fn main() {println!("add i8: {}", add_i8(2i8, 3i8));println!("add i32: {}", add_i32(20, 30));println!("add f64: {}", add_f64(1.23, 1.23));
}
上述代码可以正常运行,但是很啰嗦,如果你要支持更多的类型,那么会更繁琐。程序员或多或少都有强迫症,一个好程序员的公认特征就是 —— 懒,这么勤快的写一大堆代码,显然不是咱们的优良传统,是不?
在开始讲解 Rust 的泛型之前,先来看看什么是多态。
在编程的时候,我们经常利用多态。通俗的讲,多态就是好比坦克的炮管,既可以发射普通弹药,也可以发射制导炮弹(导弹),也可以发射贫铀穿甲弹,甚至发射子母弹,没有必要为每一种炮弹都在坦克上分别安装一个专用炮管,即使生产商愿意,炮手也不愿意,累死人啊。所以在编程开发中,我们也需要这样“通用的炮管”,这个“通用的炮管”就是多态。
实际上,泛型就是一种多态。泛型主要目的是为程序员提供编程的便利,减少代码的臃肿,同时可以极大地丰富语言本身的表达能力,为程序员提供了一个合适的炮管。想想,一个函数,可以代替几十个,甚至数百个函数,是一件多么让人兴奋的事情:
fn add<T>(a:T, b:T) -> T {a + b
}fn main() {println!("add i8: {}", add(2i8, 3i8));println!("add i32: {}", add(20, 30));println!("add f64: {}", add(1.23, 1.23));
}
将之前的代码改成上面这样,就是 Rust 泛型的初印象,这段代码虽然很简洁,但是并不能编译通过,我们会在后面进行详细讲解,现在只要对泛型有个大概的印象即可。
泛型详解
上面代码的 T 就是泛型参数,实际上在 Rust 中,泛型参数的名称你可以任意起,但是出于惯例,我们都用 T ( T 是 type 的首字母)来作为首选,这个名称越短越好,除非需要表达含义,否则一个字母是最完美的。
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
fn largest<T>(list: &[T]) -> T {
该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest 对泛型参数 T 进行了声明,然后才在函数参数中进行使用该泛型参数 list: &[T] (还记得 &[T] 类型吧?这是数组切片)。
总之,我们可以这样理解这个函数定义:函数 largest 有泛型类型 T,它有个参数 list,其类型是元素为 T 的数组切片,最后,该函数返回值的类型也是 T。
下面是一个错误的泛型函数的实现:
fn largest<T>(list: &[T]) -> T {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}
运行后报错:
error[E0369]: binary operation `>` cannot be applied to type `T` // `>`操作符不能用于类型`T`--> src/main.rs:5:17|
5 | if item > largest {| ---- ^ ------- T| || T|
help: consider restricting type parameter `T` // 考虑对T进行类型上的限制 :|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {| ++++++++++++++++++++++
因为 T 可以是任何类型,但不是所有的类型都能进行比较,因此上面的错误中,编译器建议我们给 T 添加一个类型限制:使用 std::cmp::PartialOrd 特征(Trait)对 T 进行限制,特征在下一节会详细介绍,现在你只要理解,该特征的目的就是让类型实现可比较的功能。
还记得我们一开始的 add 泛型函数吗?如果你运行它,会得到以下的报错:
error[E0369]: cannot add `T` to `T` // 无法将 `T` 类型跟 `T` 类型进行相加--> src/main.rs:2:7|
2 | a + b| - ^ - T| || T|
help: consider restricting type parameter `T`|
1 | fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {| +++++++++++++++++++++++++++
同样的,不是所有 T 类型都能进行相加操作,因此我们需要用 std::ops::Add 对 T 进行限制:
fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {a + b
}
进行如上修改后,就可以正常运行。
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,下面代码定义了一个坐标点 Point,它可以存放任何类型的坐标值:
struct Point<T> {x: T,y: T,
}fn main() {let integer = Point { x: 5, y: 10 };let float = Point { x: 1.0, y: 4.0 };
}
这里有两点需要特别的注意:
- 提前声明,跟泛型函数定义类似,首先我们在使用泛型参数之前必需要进行声明
Point,接着就可以在结构体的字段类型中使用T来替代具体的类型 - x 和 y 是相同的类型
第二点非常重要,如果使用不同的类型,那么它会导致下面代码的报错:
struct Point<T> {x: T,y: T,
}fn main() {let p = Point{x: 1, y :1.1};
}
错误如下:
error[E0308]: mismatched types //类型不匹配--> src/main.rs:7:28|
7 | let p = Point{x: 1, y :1.1};| ^^^ 期望y是整数,但是却是浮点数
当把 1 赋值给 x 时,变量 p 的 T 类型就被确定为整数类型,因此 y 也必须是整数类型,但是我们却给它赋予了浮点数,因此导致报错。
如果想让 x 和 y 既能类型相同,又能类型不同,就需要使用不同的泛型参数:
struct Point<T,U> {x: T,y: U,
}
fn main() {let p = Point{x: 1, y :1.1};
}
切记,所有的泛型参数都要提前声明:Point ! 但是如果你的结构体变成这鬼样:struct Woo,那么你需要考虑拆分这个结构体,减少泛型参数的个数和代码复杂度。
枚举中使用泛型
提到枚举类型,Option 永远是第一个应该被想起来的,在之前的章节中,它也多次出现:
enum Option<T> {Some(T),None,
}
Option 是一个拥有泛型 T 的枚举类型,它第一个成员是 Some(T),存放了一个类型为 T 的值。得益于泛型的引入,我们可以在任何一个需要返回值的函数中,去使用 Option 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T),或者没有值 None。
对于枚举而言,卧龙凤雏永远是绕不过去的存在:如果是 Option 是卧龙,那么 Result 就一定是凤雏,得两者可得天下:
enum Result<T, E> {Ok(T),Err(E),
}
这个枚举和 Option 一样,主要用于函数返回值,与 Option 用于值的存在与否不同,Result 关注的主要是值的正确性。
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
上一章中,我们讲到什么是方法以及如何在结构体和枚举上定义方法。方法上也可以使用泛型:
struct Point<T> {x: T,y: T,
}impl<T> Point<T> {fn x(&self) -> &T {&self.x}
}fn main() {let p = Point { x: 5, y: 10 };println!("p.x = {}", p.x());
}
使用泛型参数前,依然需要提前声明:impl,只有提前声明了,我们才能在Point中使用它,这样 Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。需要注意的是,这里的 Point 不再是泛型声明,而是一个完整的结构体类型,因为我们定义的结构体就是 Point 而不再是 Point。
除了结构体中的泛型参数,我们还能在该结构体的方法中定义额外的泛型参数,就跟泛型函数一样:
struct Point<T, U> {x: T,y: U,
}impl<T, U> Point<T, U> {fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {Point {x: self.x,y: other.y,}}
}fn main() {let p1 = Point { x: 5, y: 10.4 };let p2 = Point { x: "Hello", y: 'c'};let p3 = p1.mixup(p2);println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}
这个例子中,T,U 是定义在结构体 Point 上的泛型参数,V,W 是单独定义在方法 mixup 上的泛型参数,它们并不冲突,说白了,你可以理解为,一个是结构体泛型,一个是函数泛型。
为具体的泛型类型实现方法
对于 Point 类型,你不仅能定义基于 T 的方法,还能针对特定的具体类型,进行方法定义:
impl Point<f32> {fn distance_from_origin(&self) -> f32 {(self.x.powi(2) + self.y.powi(2)).sqrt()}
}
这段代码意味着 Point 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point 实例则没有定义此方法。这个方法计算点实例与坐标(0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
这样我们就能针对特定的泛型类型实现某个特定的方法,对于其它泛型类型则没有定义该方法。
const 泛型(Rust 1.51 版本引入的重要特性)
在之前的泛型中,可以抽象为一句话:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型,那有没有针对值的泛型?可能很多同学感觉很难理解,值怎么使用泛型?不急,我们先从数组讲起。
在数组那节,有提到过很重要的一点:[i32; 2] 和 [i32; 3] 是不同的数组类型,比如下面的代码:
fn display_array(arr: [i32; 3]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(arr);let arr: [i32;2] = [1,2];display_array(arr);
}
运行后报错:
error[E0308]: mismatched types // 类型不匹配--> src/main.rs:10:19|
10 | display_array(arr);| ^^^ 期望一个长度为3的数组,却发现一个长度为2的
结合代码和报错,可以很清楚的看出,[i32; 3] 和 [i32; 2] 确实是两个完全不同的类型,因此无法用同一个函数调用。
首先,让我们修改代码,让 display_array 能打印任意长度的 i32 数组:
fn display_array(arr: &[i32]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(&arr);let arr: [i32;2] = [1,2];display_array(&arr);
}
很简单,只要使用数组切片,然后传入 arr 的不可变引用即可。
接着,将 i32 改成所有类型的数组:
fn display_array<T: std::fmt::Debug>(arr: &[T]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(&arr);let arr: [i32;2] = [1,2];display_array(&arr);
}
也不难,唯一要注意的是需要对 T 加一个限制 std::fmt::Debug,该限制表明 T 可以用在 println!("{:?}", arr) 中,因为 {:?} 形式的格式化输出需要 arr 实现该特征。
通过引用,我们可以很轻松的解决处理任何类型数组的问题,但是如果在某些场景下引用不适宜用或者干脆不能用呢?你们知道为什么以前 Rust 的一些数组库,在使用的时候都限定长度不超过 32 吗?因为它们会为每个长度都单独实现一个函数,简直。。。毫无人性。难道没有什么办法可以解决这个问题吗?
好在,现在咱们有了 const 泛型,也就是针对值的泛型,正好可以用于处理数组长度的问题:
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(arr);let arr: [i32; 2] = [1, 2];display_array(arr);
}
如上所示,我们定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,这个和之前讲的泛型没有区别,而重点在于 N 这个泛型参数,它是一个基于值的泛型参数!因为它用来替代的是数组的长度。
N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N ,它基于的值类型是 usize。
在泛型参数之前,Rust 完全不适合复杂矩阵的运算,自从有了 const 泛型,一切即将改变。
const 泛型表达式
假设我们某段代码需要在内存很小的平台上工作,因此需要限制函数参数占用的内存大小,此时就可以使用 const 泛型表达式来实现:
// 目前只能在nightly版本下使用
#![allow(incomplete_features)]
#![feature(generic_const_exprs)]fn something<T>(val: T)
whereAssert<{ core::mem::size_of::<T>() < 768 }>: IsTrue,// ^-----------------------------^ 这里是一个 const 表达式,换成其它的 const 表达式也可以
{//
}fn main() {something([0u8; 0]); // oksomething([0u8; 512]); // oksomething([0u8; 1024]); // 编译错误,数组长度是1024字节,超过了768字节的参数长度限制
}// ---pub enum Assert<const CHECK: bool> {//
}pub trait IsTrue {//
}impl IsTrue for Assert<true> {//
}
泛型的性能
在 Rust 中泛型是零成本的抽象,意味着你在使用泛型时,完全不用担心性能上的问题。
但是任何选择都是权衡得失的,既然我们获得了性能上的巨大优势,那么又失去了什么呢?Rust 是在编译期为泛型对应的多个类型,生成各自的代码,因此损失了编译速度和增大了最终生成文件的大小。
具体来说:
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。
让我们看看一个使用标准库中 Option 枚举的例子:
let integer = Some(5);
let float = Some(5.0);
当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option 的值并发现有两种 Option:一种对应 i32 另一种对应 f64。为此,它会将泛型定义 Option 展开为 Option_i32 和 Option_f64,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样:
enum Option_i32 {Some(i32),None,
}enum Option_f64 {Some(f64),None,
}fn main() {let integer = Option_i32::Some(5);let float = Option_f64::Some(5.0);
}
我们可以使用泛型来编写不重复的代码,而 Rust 将会为每一个实例编译其特定类型的代码。这意味着在使用泛型时没有运行时开销;当代码运行,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
相关文章:
rust学习——泛型 (Generics)
文章目录 泛型 Generics泛型详解结构体中使用泛型枚举中使用泛型方法中使用泛型为具体的泛型类型实现方法 const 泛型(Rust 1.51 版本引入的重要特性)const 泛型表达式 泛型的性能 泛型 Generics Go 语言在 2022 年,就要正式引入泛型…...

【USRP】通信之有线通信
有线通信: 有线通信是指使用物理线路或媒体(例如,铜线、同轴电缆、光纤)进行数据、声音和视频传输的通信方式。由于它依赖于实体传输媒介,有线通信通常具有较高的稳定性和可靠性,并能支持长距离的高带宽通…...

【算法】BFS
BFS广度优先搜索 1. 概念理解 广度优先搜索(BFS)是指,以一个起点(原点、结点、根)为基本点,向其所要搜索的方向扩散,并最终到达目标点的搜索方法。 2. 应用方向 有迷宫问题、层序遍历等应用。 3. 迷宫问题 以迷宫问题为例。 当想要从左…...
ZYNQ7020开发(二):zynq linux系统编译
文章目录 一、编译前准备二、SDK编译三、编译步骤总结四、问题汇总 一、编译前准备 1.设置环境变量 source /opt/pkg/petalinux/2020.2/settings.sh/opt/pkg/petalinux/2020.2是上一节petalinux的安装目录 2.创建 petalinux 工程 进入petalinux安装目录(例如:/op…...

Kafka 自动配置部署信息的脚本记录
自动配置 Kafka 整理服务器内容时,发现一个测试 Kafka 的的一个脚本,它可以自动部署 Kafka ,指定三个参数,完成 Kafka 的配置过程。 basePath$1 brokerId$2 zookeeperConnect$3 localIpifconfig |grep inet| awk {print $2}| he…...

数据分析入门
B站:01第一课 数据分析岗位职责和数据分析师_哔哩哔哩_bilibili 一、岗位:数据分析师 Q1 数据分析师在公司做什么工作? 数据来源于公司核心业务,通过监测业务健康度来确定业务的健康状况; 通过对用户精细化分析&am…...
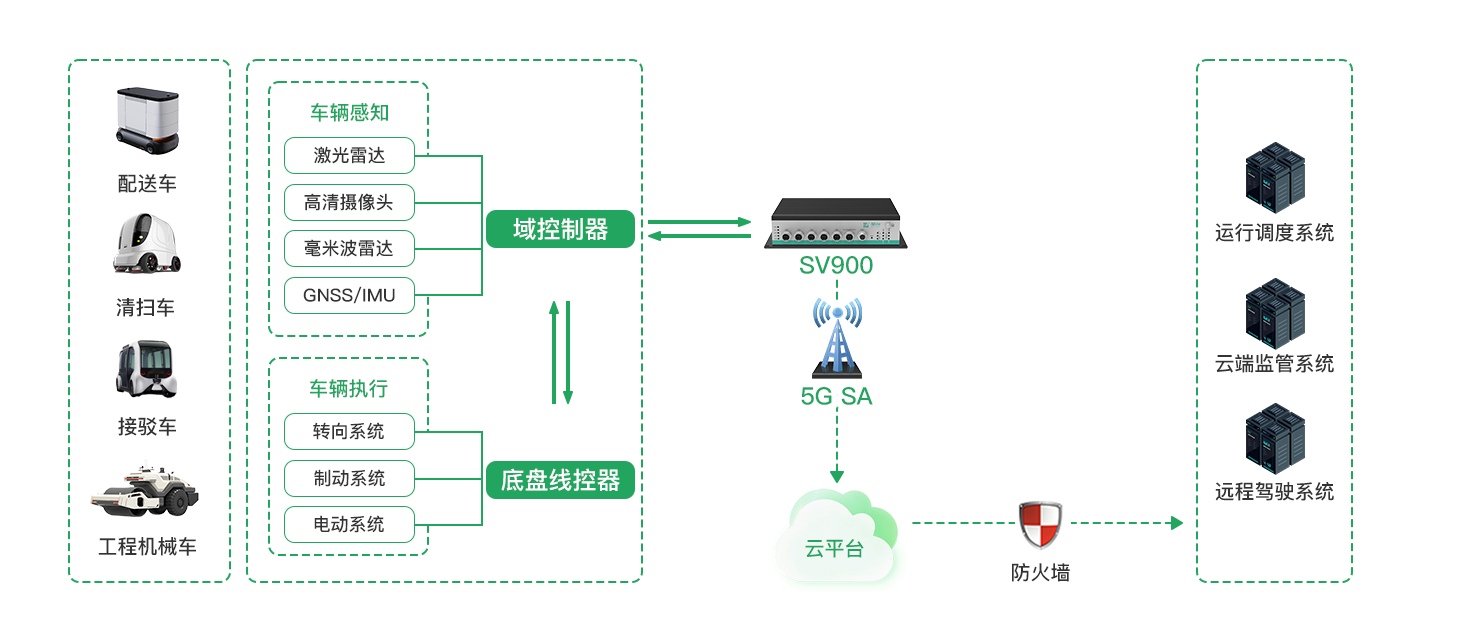
车载网关通信能力解析——SV900-5G车载网关推荐
随着车联网的发展,各类车载设备对车载网关的需求日益增长。车载网关作为车与车、车与路、车与云之间连接的关键设备,其通信能力直接影响整个系统的性能。本文将详细解析车载网关的通信能力,并推荐性价比高的SV900-5G车载网关。 链接直达:https://www.key-iot.com/i…...

服务器中了mkp勒索病毒怎么处理,mkp勒索病毒解密,数据恢复
10月份以来,云天数据恢复中心陆续接到很多企业的求助,企业的服务器遭到了mkp勒索病毒攻击,导致企业的服务器数据库被加密,严重影响了企业工作,通过这一波mkp勒索病毒的攻击,云天数据恢复工程师为大家总结了…...

义乌再次位列第一档!2022年跨境电商综试区评估结果揭晓!
义乌跨境电商综试区捷报频传,在商务部公布的“2022年跨境电子商务综合试验区评估”结果中,中国(义乌)跨境电子商务综合试验区(以下简称:“跨境综试区”)评估结果为成效明显,综合排名…...
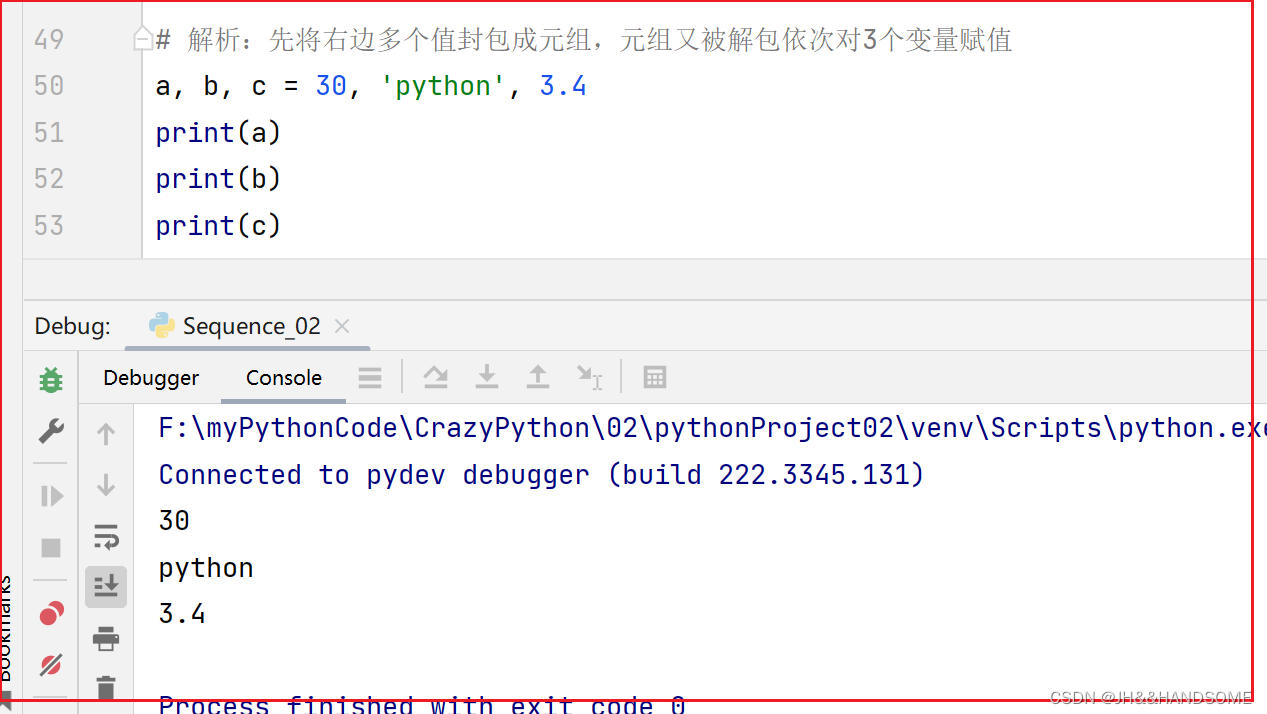
07、Python -- 序列相关函数与封包解包
目录 使用函数字符串也能比较大小序列封包序列解包多变量同时赋值 最大值、最小值、长度 序列解包与封包 使用函数 len()、max()、min() 函数可获取元组、列表的长度、最大值和最小值。 字符串也能比较大小 字符串比较大小时,将会依次按字符串中每个字符对应的编…...
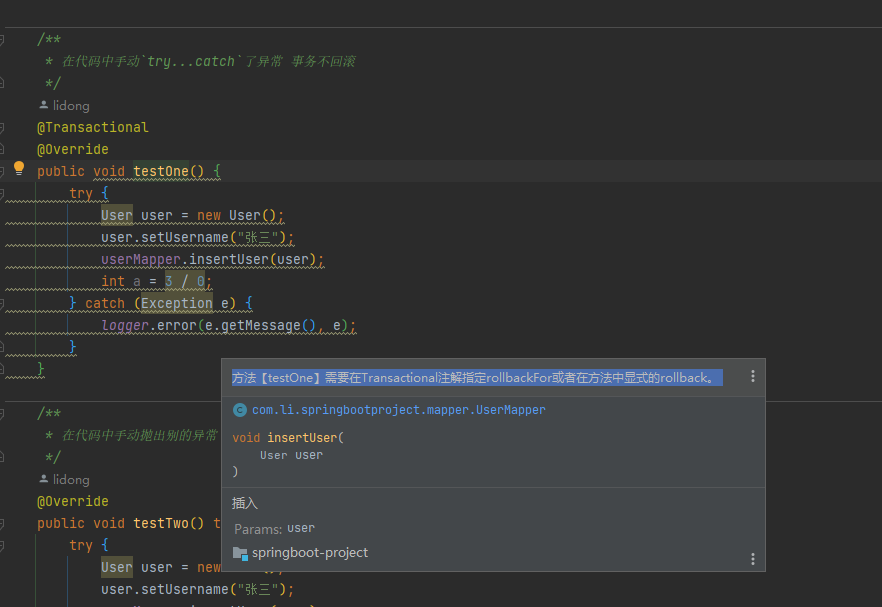
# Spring 事务失效场景
Spring 事务失效场景 文章目录 Spring 事务失效场景前言事务不生效未开启事务事务方法未被Spring管理访问权限问题基于接口的代理源码解读 CGLIB代理 方法用final修饰同一类中的方法调用多线程调用不支持事务 事务不回滚设置错误的事务传播机制捕获了异常手动抛了别的异常自定义…...
【java】A卷+B卷)
华为OD 停车场车辆统计(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

出差学小白知识No6:LD_PRELOAD变量路径不对找不到库文件
交叉编译的时候出现以下问题,显示LD_PRELOAD变量找不到路劲 首先先查看一下LD_PRELOAD的路径:echo $LD_PRELOAD 如果输出一大串,那么先进行清空:unset LD_PRELOAD 重新给LD_PRELOAD进行赋值他的路径和库文件: expor…...

利用dns协议发起ddos反射攻击
利用DNS服务器发起反射型DDOS,攻击带宽 基本思路: 1、利用any类型的dns查询,可完成发送少量请求数据,获得大量返回数据。 2、将原请求地址改为受害者地址,则dns会向受害者返回大量数据,占用带宽 警告&…...

Tcl基础知识
一、概述 Tcl 语言的全称 Tool Command Language,即工具命令语言。这种需要在 EDA 工具中使用的相当之多,或者说几乎每个 EDA 工具都支持 Tcl 语言,并将它作为自己的命令shell。 静态时序分析中多用的 Synopsys Tcl 语言,…...

Go中的编程模式:Pipeline
本文章我们重点来介绍一下 Go 编程中的 Pipeline 模式。用过 Linux 命令行的人都不会陌生,它是一种把各种命令拼接起来完成一个更强功能的技术方法,在C语言中也有pipe管道的叫法,具体的有兴趣的同学也可以去了解。 现在的流式处理、函数式编程、应用网关对微服务进行简单的…...
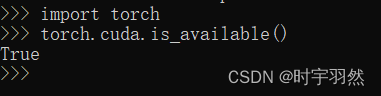
2023最新pytorch安装教程,简单易懂,面向初学者(Anaconda+GPU)
一、前言 目前是2023.1.27,鉴于本人安装过程中踩得坑,安装之前我先给即将安装pytorch的各位提个醒,有以下几点需要注意 1.判断自己电脑是否有GPU 注意这点很重要,本教程面向有NVIDA显卡的电脑,如果你的电脑没有GPU或者使用AMD显…...

Redis为什么变慢了
一、Redis为什么变慢了 1.Redis真的变慢了吗? 对 Redis 进行基准性能测试 例如,我的机器配置比较低,当延迟为 2ms 时,我就认为 Redis 变慢了,但是如果你的硬件配置比较高,那么在你的运行环境下,可能延迟是 0.5ms 时就可以认为 Redis 变慢了。 所以,你只有了解了你的…...

空中计算(Over-the-Air Computation)学习笔记
文章目录 写在前面 写在前面 本文是论文A Survey on Over-the-Air Computation的阅读笔记: 通信和计算通常被视为独立的任务。 从工程的角度来看,这种方法是非常有效的,因为可以执行孤立的优化。 然而,对于许多面向计算的应用程序…...

如何高效率地阅读论文
▚ 01 Active versus passive reading: how to read scientific papers? 📢小疑则小悟,大疑则大悟,不疑则不悟。 If you read/do research with small questions in mind, you learn small things. If you do so with big questions in…...

从YOLO到餐桌:构建校园食堂智能结算系统的实战指南
1. 为什么选择YOLO做食堂智能结算? 在校园食堂这种特殊场景下,菜品识别面临着诸多挑战:餐盘堆叠造成的遮挡、反光餐具带来的光线干扰、相似菜品的细微差异(比如青椒炒肉和土豆炒肉)。传统图像处理方法需要针对每种菜品…...

芯片互连的“速度革命”:铜互连为何能替代铝,成为高端芯片标配?
在芯片的内部结构中,除了负责运算、存储的晶体管,还有一套贯穿芯片全局的“信号传输网络”——芯片互连技术。它就像芯片内部的“高速公路网”,将亿万级晶体管精准连接,实现电信号的快速传输,支撑芯片的运算和存储功能…...

Android Camera开发避坑指南:HAL3与MediaCodec整合的那些坑
Android Camera开发避坑指南:HAL3与MediaCodec整合的那些坑 在移动设备的多媒体开发中,Camera HAL3与MediaCodec的整合堪称"地狱级"难度。我曾在一个旗舰机项目中,因为这两个模块的配合问题导致视频录制帧率从30fps暴跌到12fps&…...

Ollama一键部署【书生·浦语】internlm2-chat-1.8b:镜像免配置实操手册
Ollama一键部署【书生浦语】internlm2-chat-1.8b:镜像免配置实操手册 想体验一个轻量又好用的中文对话模型吗?今天给大家介绍一个超级简单的部署方法,让你在几分钟内就能用上【书生浦语】的 internlm2-chat-1.8b 模型。这个模型只有18亿参数…...

深度解析N_m3u8DL-CLI-SimpleG:图形化M3U8下载工具技术指南
深度解析N_m3u8DL-CLI-SimpleG:图形化M3U8下载工具技术指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 在流媒体视频处理领域,M3U8格式已成为主流的分…...

5分钟快速上手:网易云音乐NCM加密文件解密转换终极指南
5分钟快速上手:网易云音乐NCM加密文件解密转换终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密NCM文件无法在其他设备播放而烦恼吗?ncmdump是一款高效、智能的NCM格式转换…...

2026年正规的geo推广合作投放,究竟能带来怎样的营销新突破?
在2026年,营销领域正经历着前所未有的变革,随着AI技术的飞速发展,传统营销方式逐渐显露出局限性,而GEO推广合作投放作为一种新兴的营销手段,正逐渐成为企业关注的焦点。那么,正规的GEO推广合作投放究竟能为…...

如何快速下载Google Drive共享文件:Python开发者的终极解决方案
如何快速下载Google Drive共享文件:Python开发者的终极解决方案 【免费下载链接】google-drive-downloader Minimal class to download shared files from Google Drive. 项目地址: https://gitcode.com/gh_mirrors/go/google-drive-downloader 前言 在Pyth…...

Arduino RTCtime库:标准time.h兼容的DS1307/DS3231驱动
1. 项目概述RTCtime 是一款专为 Arduino 平台设计的实时时钟(RTC)驱动库,核心目标是在硬件 RTC 模块与标准 C 运行时时间系统之间建立语义一致、类型兼容的桥梁。它并非一个独立的时间计算引擎,而是对底层硬件寄存器操作的封装层&…...

OpenClaw资源监控:Qwen3.5-9B预警系统异常与自动处理
OpenClaw资源监控:Qwen3.5-9B预警系统异常与自动处理 1. 为什么需要智能化的资源监控 去年夏天,我的开发机因为磁盘写满导致线上服务日志无法写入,造成了整整两小时的服务中断。这件事让我意识到:传统的监控告警系统存在两个致命…...