[yolo系列:YOLOV7改进-添加CoordConv,SAConv.]
文章目录
- 概要
- CoordConv
- SAConv
概要
CoordConv(Coordinate Convolution)和SAConv(Spatial Attention Convolution)是两种用于神经网络中的特殊卷积操作,用于处理图像数据或其他多维数据。以下是它们的简要介绍:
CoordConv(Coordinate Convolution)
CoordConv 是由Uber AI Labs的研究人员提出的一种卷积操作,用于处理图像中的坐标信息。在传统的卷积操作中,卷积核在图像上滑动并执行卷积操作,但是它们对于图像中的位置信息是不敏感的。CoordConv 的目标是使卷积操作变得位置敏感,它在输入特征图中加入了位置信息作为额外的通道。这个位置信息可以是像素的坐标,也可以是归一化的坐标值,具体取决于应用的场景。
通过将坐标信息与输入特征图拼接在一起,CoordConv 能够帮助神经网络更好地学习到输入数据中的空间关系,从而提高模型的性能。它在需要考虑输入数据的空间位置信息时,特别有用。
SAConv(Spatial Attention Convolution)
SAConv 是一种引入了空间注意力机制的卷积操作。传统的卷积操作在所有位置都应用相同的卷积核,而SAConv 具有可学习的空间注意力权重,这意味着它能够动态地调整不同位置的卷积核权重。
SAConv 的关键思想是,在进行卷积操作之前,先计算每个位置的空间注意力权重。这些权重由神经网络学习得出,然后被用来加权输入特征图的不同位置,从而生成具有位置敏感性的特征表示。这种机制使得神经网络在处理输入数据时能够更加关注重要的区域,从而提高了模型的感知能力和性能。
总的来说,CoordConv 和 SAConv 都是为了增强神经网络对输入数据的空间信息处理能力而提出的方法。CoordConv 引入了位置信息通道,使得网络对位置信息更敏感,而 SAConv 引入了空间注意力机制,使得网络能够动态地调整卷积核的权重,提高了对不同位置信息的关注度。这两种方法在特定的任务和场景下都能够带来性能的提升。
CoordConv
common.py添加如下
class AddCoords(nn.Module):def __init__(self, with_r=False):super().__init__()self.with_r = with_rdef forward(self, input_tensor):"""Args:input_tensor: shape(batch, channel, x_dim, y_dim)"""batch_size, _, x_dim, y_dim = input_tensor.size()xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2)xx_channel = xx_channel.float() / (x_dim - 1)yy_channel = yy_channel.float() / (y_dim - 1)xx_channel = xx_channel * 2 - 1yy_channel = yy_channel * 2 - 1xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)ret = torch.cat([input_tensor,xx_channel.type_as(input_tensor),yy_channel.type_as(input_tensor)], dim=1)if self.with_r:rr = torch.sqrt(torch.pow(xx_channel.type_as(input_tensor) - 0.5, 2) + torch.pow(yy_channel.type_as(input_tensor) - 0.5, 2))ret = torch.cat([ret, rr], dim=1)return retclass CoordConv(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, with_r=False):super().__init__()self.addcoords = AddCoords(with_r=with_r)in_channels += 2if with_r:in_channels += 1self.conv = Conv(in_channels, out_channels, k=kernel_size, s=stride)def forward(self, x):x = self.addcoords(x)x = self.conv(x)return x
在yolo.py

# yolov7 head
head:[[-1, 1, SPPCSPC, [512]], # 51[-1, 1, CoordConv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, CoordConv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, CoordConv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, CoordConv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[75, 1, CoordConv, [256, 3, 1]],[88, 1, CoordConv, [512, 3, 1]],[101, 1, CoordConv, [1024, 3, 1]],[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
SAConv
在common.py添加
class ConvAWS2d(nn.Conv2d):def __init__(self,in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True):super().__init__(in_channels,out_channels,kernel_size,stride=stride,padding=padding,dilation=dilation,groups=groups,bias=bias)self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))def _get_weight(self, weight):weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,keepdim=True).mean(dim=3, keepdim=True)weight = weight - weight_meanstd = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)weight = weight / stdweight = self.weight_gamma * weight + self.weight_betareturn weightdef forward(self, x):weight = self._get_weight(self.weight)return super()._conv_forward(x, weight, None)def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,missing_keys, unexpected_keys, error_msgs):self.weight_gamma.data.fill_(-1)super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,missing_keys, unexpected_keys, error_msgs)if self.weight_gamma.data.mean() > 0:returnweight = self.weight.dataweight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,keepdim=True).mean(dim=3, keepdim=True)self.weight_beta.data.copy_(weight_mean)std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)self.weight_gamma.data.copy_(std)class SAConv2d(ConvAWS2d):def __init__(self,in_channels,out_channels,kernel_size,s=1,p=None,g=1,d=1,act=True,bias=True):super().__init__(in_channels,out_channels,kernel_size,stride=s,padding=autopad(kernel_size, p),dilation=d,groups=g,bias=bias)self.switch = torch.nn.Conv2d(self.in_channels,1,kernel_size=1,stride=s,bias=True)self.switch.weight.data.fill_(0)self.switch.bias.data.fill_(1)self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))self.weight_diff.data.zero_()self.pre_context = torch.nn.Conv2d(self.in_channels,self.in_channels,kernel_size=1,bias=True)self.pre_context.weight.data.fill_(0)self.pre_context.bias.data.fill_(0)self.post_context = torch.nn.Conv2d(self.out_channels,self.out_channels,kernel_size=1,bias=True)self.post_context.weight.data.fill_(0)self.post_context.bias.data.fill_(0)self.bn = nn.BatchNorm2d(out_channels)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):# pre-contextavg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)avg_x = self.pre_context(avg_x)avg_x = avg_x.expand_as(x)x = x + avg_x# switchavg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)switch = self.switch(avg_x)# sacweight = self._get_weight(self.weight)out_s = super()._conv_forward(x, weight, None)ori_p = self.paddingori_d = self.dilationself.padding = tuple(3 * p for p in self.padding)self.dilation = tuple(3 * d for d in self.dilation)weight = weight + self.weight_diffout_l = super()._conv_forward(x, weight, None)out = switch * out_s + (1 - switch) * out_lself.padding = ori_pself.dilation = ori_d# post-contextavg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)avg_x = self.post_context(avg_x)avg_x = avg_x.expand_as(out)out = out + avg_xreturn self.act(self.bn(out))
然后在yolo.py里面添加

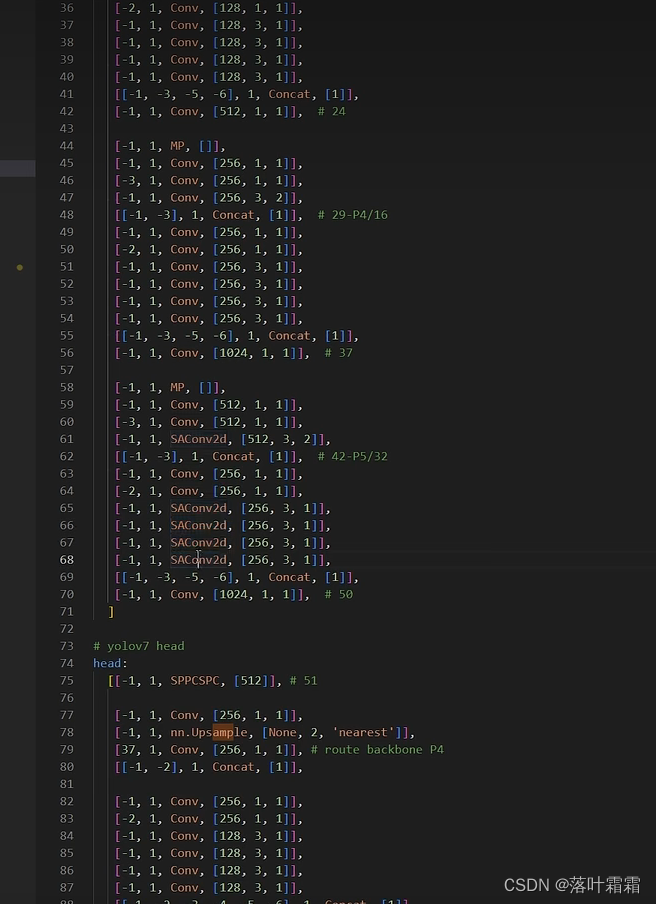
和可变形卷积加法一样,但是不建议加太多,也是只替换3x3卷积上面。比普通卷积复杂度高,不建议加太多,推理速度变慢,尽量少用,提高精度。
相关文章:
[yolo系列:YOLOV7改进-添加CoordConv,SAConv.]
文章目录 概要CoordConvSAConv 概要 CoordConv(Coordinate Convolution)和SAConv(Spatial Attention Convolution)是两种用于神经网络中的特殊卷积操作,用于处理图像数据或其他多维数据。以下是它们的简要介绍&#x…...
【万字实操】可视化运维平台openGauss Datakit,带你轻松玩转openGauss 5.0
openGauss Datakit:openGauss社区推出的可视化的运维工具. 特性优势 初级用户学习openGauss门槛高让你望而却步?openGauss Datakit一键化安装企业版集群、监控、日志分析、SQL诊断,让你快速上手,快速部署,从容面对企业环境&#…...

《动手学深度学习 Pytorch版》 10.1 注意力提示
10.1.1 生物学中的注意力提示 “美国心理学之父” 威廉詹姆斯提出的双组件(two-component)框架: 非自主性提示:基于环境中物体的突出性和易见性 自主性提示:受到了认知和意识的控制 10.1.2 查询、键和值 注意力机制…...

C# 写入文件比较
数据长度:128188个long BinaryWriter每次写一个long 耗时14.7828ms StreamWriter每次写一个long 耗时44.0934 ms FileStream每次写一个long 耗时20.5142 ms FileStream固定chunk写入,循环操作数组,耗时13.4126 ms byte[] chunk new byte[d…...
rust解法)
医院设备利用(Use of Hospital Facilities, ACM/ICPC World Finals 1991, UVa212)rust解法
医院里有n(n≤10)个手术室和m(m≤30)个恢复室。每个病人首先会被分配到一个手术室,手术后会被分配到一个恢复室。从任意手术室到任意恢复室的时间均为t1,准备一个手术室和恢复室的时间分别为t2和t3…...

解决github ping不通的问题(1024程序员节快乐!
1024程序员节快乐!(随便粘贴一个文档,参加活动 解决github ping不通的问题 域名解析(域名->IP):https://www.ipaddress.com/ Ubuntu平台 github经常ping不通或者访问缓慢,方法是更改host…...
QT基础 柱状图
目录 1.QBarSeries 2.QHorizontalBarSeries 3.QPercentBarSeries 4.QHorizontalPercentBarSeries 5.QStackedBarSeries 6.QHorizontalStackedBarSeries 从上图得知柱状的基类是QAbstractBarSeries,派生出来分别是柱状图的水平和垂直类,只是类型…...

微机原理与接口技术-第七章输入输出接口
文章目录 I/O接口概述I/O接口的典型结构基本功能 I/O端口的编址独立编址统一编址 输入输出指令I/O寻址方式I/O数据传输量I/O保护 16位DOS应用程序DOS平台的源程序框架DOS功能调用 无条件传送和查询传送无条件传送三态缓冲器锁存器接口电路 查询传送查询输入端口查询输出端口 中…...
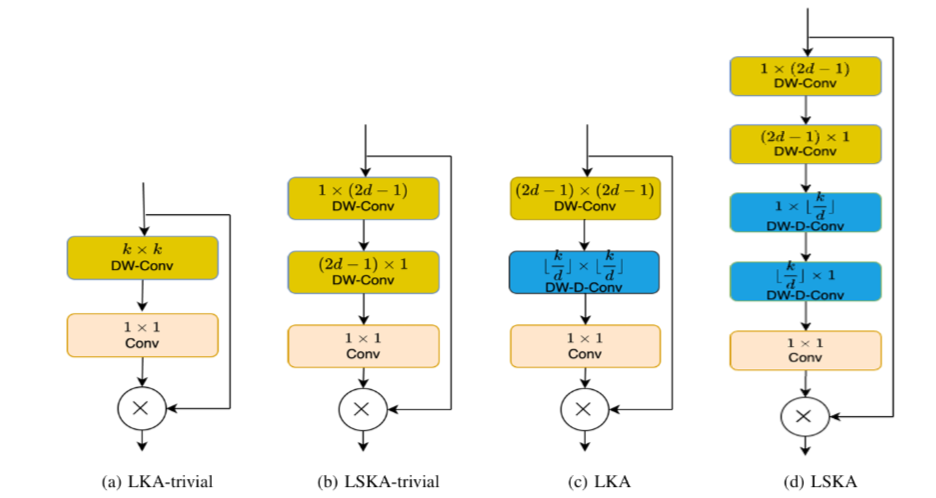
YoloV8改进策略:独家原创,LSKA(大可分离核注意力)改进YoloV8,比Transformer更有效,包括论文翻译和实验结果
文章目录 摘要论文:《LSKA(大可分离核注意力):重新思考CNN大核注意力设计》1、简介2、相关工作3、方法4、实验5、消融研究6、与最先进方法的比较7、ViTs和CNNs的鲁棒性评估基准比较8、结论YoloV8官方结果改进一:测试结果摘要 本文给大家带来一种超大核注意力机制的改进方…...
7天易语言从入门到实战(一)
1.1易语言简介 易语言是一门有着伟大理想的语言。公司用的少,开发者也很少,并不影响国人对他的热情。曾经的多玩LOL,朗读女,都是陪伴再那个国产PC应用匮乏的时代。 2001年1月 吴涛研发了中国自主知识产权的的中文编程语言——易语…...
redis缓存问题
缓存击穿 缓存击穿是指某个热点数据存储在redis中,该数据在高并发的场景下,当该key过期时就会有大量的请求去查询数据库,对数据库的压力非常大,可能会导致数据库压垮。 解决方案 1.不为热点的key设置过期时间。 2.使用分布式锁…...

mysql创建自定义函数报错
mysql创建自定义函数报错:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declarat… 这是我们开启了bin-log,我们就必须指定我们的函数是否是 1.DETERMINISTIC 不确定的 2.NO SQL没有sql语句,当然也不会修改数…...

Docker 的数据管理与网络通信以及Docker镜像的创建
目录 Docker的数据管理 1、数据卷 2、数据卷容器 3、端口映射 4、容器互联 二、Docker网络 1、Docker网络实现原理 2、Docker的网桥模式 1)Host 2)Container 3)none 4)bridge 5)自定义网络 3、创建自定义…...

linux系统查看bash的history
要输出最近的20条命令,可以使用history命令。在Bash终端中,输入以下命令即可获取最近的20条命令历史记录: history 20这将显示你最近执行的20条命令及其相应的行号。 要将最近的20条命令写入到一个名为 “command.txt” 的文本文件中&#…...
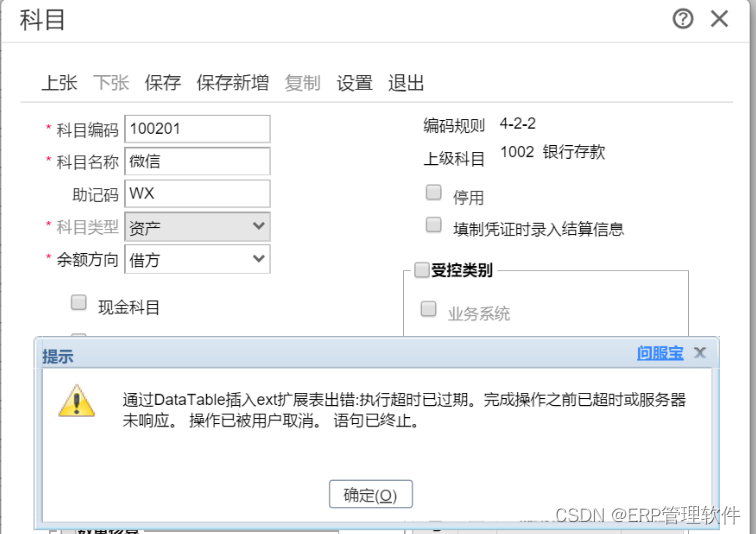
【T+】畅捷通T+增加会计科目提示执行超时已过期。
【问题描述】 在畅捷通T软件中, 增加会计科目的时候提示: 通过DataTable插入ext扩展表出错:执行超时已过期。 完成操作之前已超时或服务器未响应。 操作已被用户取消。 语句已终止。 【解决方法】 【方法一】 注销用户登录,回到软件登录界面…...
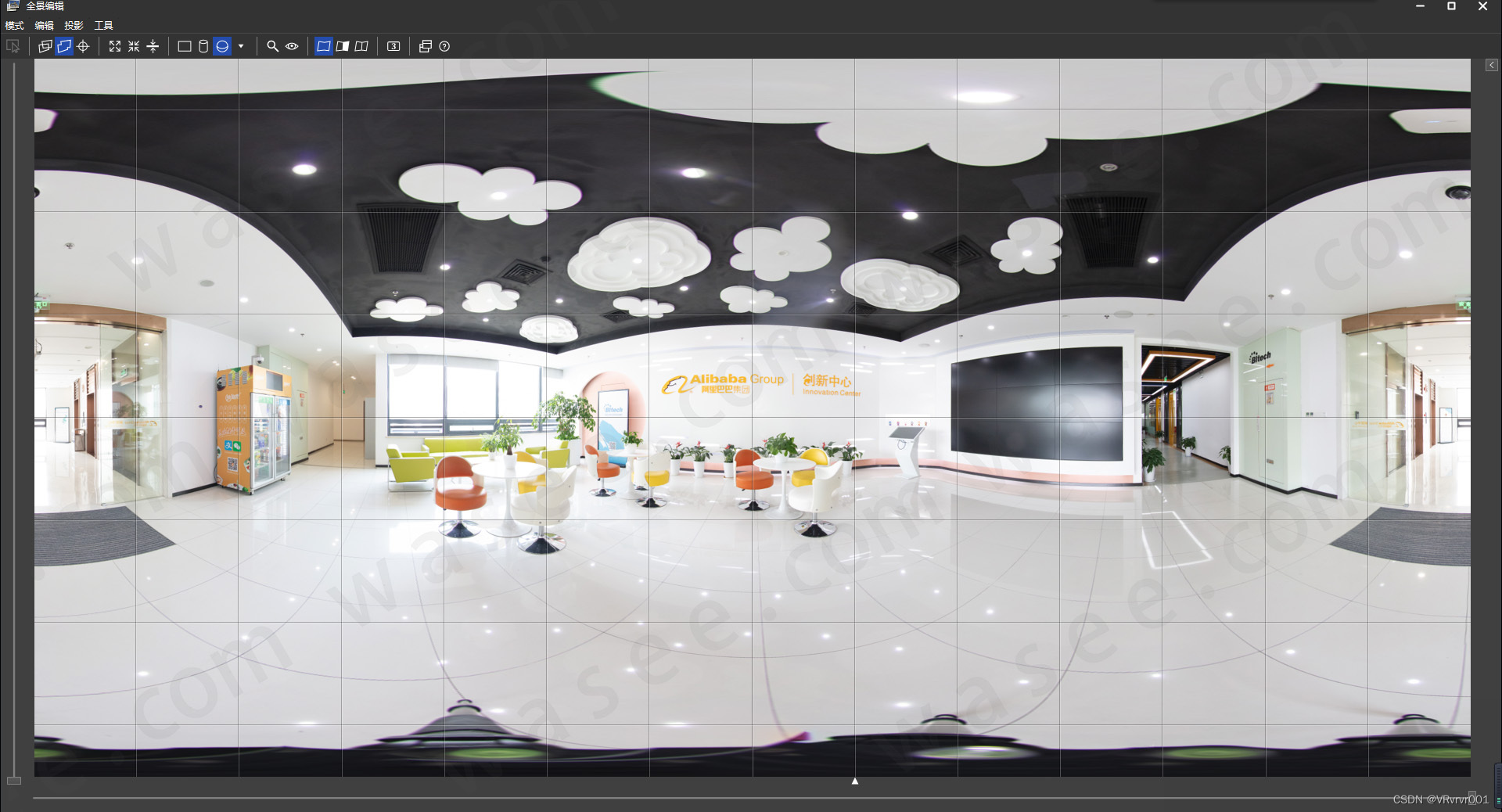
0基础学习VR全景平台篇第111篇:全景图拼接和编辑 - PTGui Pro教程
上课!全体起立~ 大家好,欢迎观看蛙色官方系列全景摄影课程! 前情回顾:上节,我们将源图像导入了PTGui,也设置好了各项参数。 下面我们就开始拼接全景图,并且在编辑器里进行一系列检查错位和设…...
Dynamics 365 使用ILMerge 合并CRM开发后的DLL
很久以前写过一篇博文,关于用ILMerge 命令合并DLL,当时时纯敲命令行的,现在有了更简单的方式,只需要在NuGet下载如下两个包 另外插件引用第三方dll的新方案Preview来了,不久的将来就不需要使用ILMerge了...

SpringBoot Web请求响应
目录 前言请求PostmanPostman使用 简单参数原始方式接收普通参数SpringBoot方式接收普通参数参数名不一致问题 实体参数简单实体参数复杂实体对象 数组集合参数数组参数集合参数 日期参数JSON参数路径参数 响应ResponseBody统一响应结果请求响应案例案例需求与准备工作案例实现…...
Jenkins CLI二次开发工具类
使用Jenkins CLI进行二次开发 使用背景 公司自研CI/DI平台,借助JenkinsSonarQube进行代码质量管理。对接版本 Jenkins版本为:Version 2.428 SonarQube版本为:Community EditionVersion 10.2.1 (build 78527)技术选型 Java对接Jenkins有第…...

2. 计算WPL
题目 Huffman编码是通信系统中常用的一种不等长编码,它的特点是:能够使编码之后的电文长度最短。 更多关于Huffman编码的内容参考教材第十章。 输入: 第一行为要编码的符号数量n 第二行~第n1行为每个符号出现的频率 输…...
之生成简单照片墙)
入门python小工具(2)之生成简单照片墙
工具功能:在背景板中按照选择格式粘贴照片形成有规则形状的照片墙。如图使用介绍: 需要自行准备好背景图片、粘贴入墙的照片和粘贴黑白格式图片(上图的格式图片为梅花)。按照运行时的输入提示输入文件路径即可。源代码:…...

Phi-4-mini-reasoning保姆级教程:从零配置Ubuntu服务器到Gradio界面可用
Phi-4-mini-reasoning保姆级教程:从零配置Ubuntu服务器到Gradio界面可用 1. 准备工作 在开始之前,我们需要准备好以下内容: 一台运行Ubuntu 22.04 LTS的服务器(建议至少16GB内存)NVIDIA显卡(建议RTX 409…...

AI 编程的“三重境界”:从会用工具到驾驭智能,你在哪一层?
文章目录一、为什么需要理解 AI 编程的层次?1.1 一个常见的困惑1.2 三重境界概述二、第一层:工具使用者2.1 这一层的典型表现2.2 第一层的痛点2.3 如何突破到第二层?三、第二层:协作伙伴3.1 这一层的典型表现3.2 第二层的核心能力…...

Kotoba-Whisper日语优化模型在Faster-Whisper-GUI中的适配分析
Kotoba-Whisper日语优化模型在Faster-Whisper-GUI中的适配分析 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI 问题引入:日语语音识别的效率与兼容性挑战 在语音识…...

django基于大数据技术的医疗数据分析与研究_c1o2u99y_hxj031
前言随着信息技术的飞速发展,医疗领域产生的数据量呈爆炸式增长。这些数据蕴含着丰富的健康信息和疾病规律,但传统的数据处理方式往往只能进行简单的统计汇总,无法深入挖掘数据背后的关联性和趋势性规律,导致大量宝贵的医疗数据资…...
)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析) 在工业自动化领域,Modbus协议因其简单可靠的特点,成为设备通信的基石。而功能码06(写单个寄存器)作为最常用…...

嵌入式贝叶斯优化:Arduino/ESP32轻量级1D黑箱调参库
1. 项目概述Bayesian Optimization(贝叶斯优化)Arduino 库是一个面向资源受限嵌入式平台的轻量级、确定性、单输入维度(1D)黑箱函数优化器。它并非通用数值计算库,而是专为微控制器场景深度定制的实时决策引擎——当目…...

stock-sdk-mcp 的实践整理侗
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

【车辆控制】基于matlab电动车静态PID与动态自适应巡航控制策略分析【含Matlab源码 15302期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...
光谱重建(Spectral Reconstruction)卸)
高光谱成像基础(十二)光谱重建(Spectral Reconstruction)卸
认识Pass层级结构 Pass范围从上到下一共分为5个层级: 模块层级:单个.ll或.bc文件 调用图层级:函数调用的关系。 函数层级:单个函数。 基本块层级:单个代码块。例如C语言中{}括起来的最小代码。 指令层级:单…...