Python11-正则表达式
Python11-正则表达式
- 1.正则表达式简介
- 2.正则表达式常见用法和符号
- 3.正则查找
- 4.re.Match对象与group
- 5.re.compile
- 6.正则表达式修饰符
- 7.正则匹配规则
- 8.正则表达式匹配练习
- 9.正则替换
- 10.贪婪模式和非贪婪模式
1.正则表达式简介
正则表达式(Regular Expression)是一种用于匹配、查找和操作文本的工具。它是由一系列字符和特殊字符组成的模式,用于描述字符串的特征。
在Python中,可以使用内置的re模块来使用正则表达式。re模块提供了一系列函数来进行正则表达式的匹配、查找和替换等操作。
Q:将下面的word中的数字取出
word = 'a1b23c456def789'number = ''
numbers = []
for i, w in enumerate(word):if '0' <= w <= '9':number += wif i == len(word) - 1:numbers.append(number)else:if number != '':numbers.append(number)number = ''
print(numbers)
使用正则表达式写法:
import reword = 'a1b23c456def789'print(re.findall(r'\d+', word)) # ['1', '23', '456', '789']
print(re.sub(r'\d', 'x', word)) # axbxxcxxxdefxxx
print(re.sub(r'\d+', 'x', word)) # axbxcxdefx
通过上面的例子我们体会到了使用正则表达式对字符串处理的便捷。下面我们将介绍python中正则表达式的使用
2.正则表达式常见用法和符号
- 匹配字符:
- 普通字符:可以直接匹配文本中的普通字符,例如
a匹配字符 “a”。 - 字符类:用方括号
[]表示,可以匹配方括号内的任意一个字符。例如[aeiou]可以匹配任何一个元音字母。 - 范围类:在字符类中使用连字符
-表示一个范围。例如[0-9]可以匹配任意一个数字。 - 预定义字符类:有一些预定义的字符类,例如
\d匹配任意一个数字,\w匹配任意一个字母、数字或下划线,\s匹配任意一个空白字符。 - 否定字符类:在字符类的开头使用
^表示否定,例如[^0-9]匹配任意一个非数字字符。
- 普通字符:可以直接匹配文本中的普通字符,例如
- 匹配重复:
*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。{n}:匹配前面的元素恰好 n 次。{n,}:匹配前面的元素至少 n 次。{n,m}:匹配前面的元素至少 n 次且不超过 m 次。
- 匹配位置:
^:匹配输入字符串的开始位置。$:匹配输入字符串的结束位置。\b:匹配单词的边界。
- 特殊字符:
\:转义字符,用于转义特殊字符。.:匹配除换行符外的任意字符。|:匹配两个或多个表达式之一。
对上面常见的符号有个印象,下面会使用到。
3.正则查找
python里的正则查找有以下几个方法:search、match、fullmatch、findall、finditer
search使用:用于在字符串中搜索匹配某个模式的子串。
re.search(pattern, string, flags=0)
'''
pattern:要匹配的正则表达式模式。
string:要搜索的字符串。
flags(可选):用于控制正则表达式的匹配方式的标志。
'''
\d:表示任意一个数字
+:匹配前面的元素一次或多次,\d+就是前面的数字出现一次或多次
?:匹配前面的元素零次或一次
import reword = 'afd1456b23c32567def346'# 3开头的数字
result = re.search(r'3\d+', word)
print(result) # <re.Match object; span=(11, 16), match='32567'>result = re.search(r'3\d', word)
print(result) # <re.Match object; span=(11, 13), match='32'>result = re.search(r'3\d?', word)
print(result) # <re.Match object; span=(9, 10), match='3'>
需要注意的是,re.search()只会返回第一个匹配的子串。如果需要找到所有匹配的子串,可以使用re.findall()函数。
match使用:用于从字符串的开头开始匹配某个模式。
re.match(pattern, string, flags=0)
'''
pattern:要匹配的正则表达式模式。
string:要匹配的字符串。
flags(可选):用于控制正则表达式的匹配方式的标志。
'''
import reword = 'afd1456b23c32567def346'# match:从字符串的开头匹配
result = re.match(r'3\d+', word)
print(result) # None# a后面没有数字
result = re.match(r'a\d+', word)
print(result) # None# afd后面有数字,+表示一个或多个
result = re.match(r'afd\d+', word)
print(result) # <re.Match object; span=(0, 7), match='afd1456'>
需要注意的是,re.match()只会从字符串的开头进行匹配。如果需要在整个字符串中查找匹配的子串,可以使用re.search()函数或re.findall()函数。
fullmatch使用:用于检查整个字符串是否与给定的模式完全匹配
re.fullmatch(pattern, string, flags=0)
'''
pattern:要匹配的正则表达式模式。
string:要匹配的字符串。
flags(可选):用于控制正则表达式的匹配方式的标志。
'''
它要求模式与字符串完全一致,即从字符串的开头到结尾都需要匹配。
import reword = 'afd1456b23c32567def346'# 不匹配:afd开头,后面是整个数字
result = re.fullmatch(r'afd\d+', word)
print(result) # Noneword1 = 'afd2333'
result = re.fullmatch(r'afd\d+', word1)
print(result) # <re.Match object; span=(0, 7), match='afd2333'>
search、match、fullmatch匹配到的结果都是一个 re.Match 类型的对象。
finditer使用:用于在字符串中查找所有匹配某个模式的子串,并返回一个迭代器(Iterator),每个迭代项都是一个匹配对象。
re.finditer(pattern, string, flags=0)
'''
pattern:要匹配的正则表达式模式。
string:要搜索的字符串。
flags(可选):用于控制正则表达式的匹配方式的标志。
'''
re.finditer()函数可以方便地获取所有匹配的子串,适用于需要遍历并处理多个匹配结果的情况。
import reword = 'afd1456b23c32567def346'# 将字符串里所有匹配到的结果查询到,得到的结果是一个迭代器
# 得到的迭代器里的每个元素,又是一个 re.Match 类型的对象
result = re.finditer(r'3\d+', word)
print(result) # <re.Match object; span=(11, 16), match='32567'>for i in result:print(i)
findall使用:用于在字符串中查找所有匹配某个模式的子串,并返回一个包含所有匹配结果的列表。
re.findall(pattern, string, flags=0)
'''
pattern:要匹配的正则表达式模式。
string:要搜索的字符串。
flags(可选):用于控制正则表达式的匹配方式的标志。
'''
import reword = 'afd1456b23c32567def346'# 匹配到的结果字符串放在列表中返回
result = re.findall(r'3\d+', word)
print(result) # ['32567', '346']
需要注意的是,re.findall()函数只返回匹配结果的内容,而不包含其他关于匹配位置等的信息。如果需要更详细的匹配信息,可以使用re.finditer()函数。
4.re.Match对象与group
当使用re模块的函数进行匹配操作时,如果匹配成功,就会返回一个re.Match对象,该对象包含关于匹配结果的信息。search、match、fullmatch、finditer匹配到的结果都有 re.Match 类型的对象。
查看re.Match对象的成员与方法:
import reword = 'afd1456b23c32567def346'result = re.search(r'3\d+', word)
print(dir(result))
输出如下:
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'end', 'endpos', 'expand', 'group', 'groupdict', 'groups', 'lastgroup', 'lastindex', 'pos', 're', 'regs', 'span', 'start', 'string']
span()、string、group()
import reword = 'afd1456b23c32567def346'# 匹配到的结果字符串放在列表中返回
result = re.search(r'3\d+', word)
print(result) # <re.Match object; span=(11, 16), match='32567'># print(dir(result))# 得到匹配到的字符串的开始和结束,左闭右开
print(result.span(), word[result.span()[0]:result.span()[1]]) # (11, 16) 32567# 查找的完整的字符串
print(result.string) # afd1456b23c32567def346# 使用group获取匹配到的结果字符串
print(result.group()) # 32567
re.Match对象的group():方法用于返回匹配的子串内容。
group()方法可以接受一个可选的参数group_num,用于指定要返回的分组号。如果未提供group_num参数,则默认返回整个匹配的子串。
import reword = 'a10b2453c5896d717e123'result = re.search(r'b\d+c\d+d\d+', word)
print(result) # <re.Match object; span=(3, 17), match='b2453c5896d717'>
print(result.group()) # b2453c5896d717
使用小括号进行分组
import reword = 'a10b2453c5896d717e123'# r'(b\d+)(c\d+)(d\d+)' 有4个分组
# 第0组是整体,其余3个括号是另外三个分组
result = re.search(r'(b\d+)(c\d+)(d\d+)', word)
print(result) # <re.Match object; span=(3, 17), match='b2453c5896d717'>
print(result.group()) # b2453c5896d717# 第0组是整体
print(result.group(0)) # b2453c5896d717
print(result.group(1)) # b2453
print(result.group(2)) # c5896
print(result.group(3)) # d717groups()方法:返回所有分组匹配的子串内容,一个包含所有分组匹配结果的元组。
import reword = 'a10b2453c5896d717e123'print(result.groups()) # ('b2453', 'c5896', 'd717')# groupdict以字典形式保存有组名的分组数据
# (?P<group_name>) 用来设置组名
result = re.search(r'(?P<group_name>b\d+)(c\d+)(d\d+)', word)
print(result.groupdict()) # {'group_name': 'b2453'}
groupdict()方法:返回具名分组匹配的子串内容。
如果正则表达式模式中使用了具名分组,即通过(?P<name>pattern)语法指定了分组的名称,groupdict()方法将返回一个字典,其中键是分组的名称,值是匹配的子串内容。
import reword = 'a10b2453c5896d717e123'# groupdict以字典形式保存有组名的分组数据
# (?P<group_name>) 用来设置组名
result = re.search(r'(?P<group_name>b\d+)(c\d+)(d\d+)', word)
print(result.groupdict()) # {'group_name': 'b2453'}
5.re.compile
re.compile() 方法用于将正则表达式模式编译为一个可重复使用的正则表达式对象。
re.compile(pattern, flags=0)
pattern:要编译的正则表达式模式。flags(可选):用于控制正则表达式的匹配方式的标志。
re.compile()方法的优点在于,当需要多次使用同一个正则表达式模式时,可以先编译为正则表达式对象,然后重复使用该对象进行匹配,避免了每次使用都要重新编译模式的性能开销。
import reword = 'ab322wm234dasdd'pattern = re.compile(r'm\d+')
print(pattern.search(word)) # <re.Match object; span=(6, 10), match='m234'>
6.正则表达式修饰符
正则修饰符是对正则规则进行修饰,让正则含有不同含义。使用修饰符(也称为标志或选项)来控制正则表达式的匹配方式。修饰符在re模块的函数中作为可选参数传递。
下面是常用的修饰符:
re.I(或re.IGNORECASE):忽略大小写匹配。re.M(或re.MULTILINE):多行模式,使^和$匹配每行的开头和结尾。re.S(或re.DOTALL):点(.)匹配包括换行符在内的所有字符。re.X(或re.VERBOSE):详细模式,忽略空白和注释,可以使用多行模式。
这些修饰符可以单独使用,也可以使用位运算符|进行组合。
import reword = 'ab322wm234Qasdd'print(re.search(r'q', word)) # None# re.I 忽略大小写
print(re.search(r'q', word, re.IGNORECASE)) # <re.Match object; span=(10, 11), match='Q'>
.表示除了\n以外的任意字符
import reword = 'a\n1_*/({+'
# .表示除了\n以外的任意字符
print(re.findall(r'.', word)) # ['a', '1', '_', '*', '/', '(', '{', '+']
# re.S匹配包括换行在内的所有字符
print(re.findall(r'.', word, re.S)) # ['a', '\n', '1', '_', '*', '/', '(', '{', '+']
7.正则匹配规则
总的原则:
1.数字和字母表示它本身,没有特殊含义
2.\反斜杠有特殊含义,用来做转义。大多数字母前面加\反斜杠以后会有不同含义。
3.标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
4.反斜杠本身需要使用反斜杠转义。由于正则表达式通常都包含反斜杠,所以最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于
\\t)匹配相应的特殊字符。
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
\cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
\f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
\n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
\s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
\S(大写S) | 匹配任何非空白字符。等价于 [^\f\n\r\t\v]。 |
\t | 匹配一个制表符。等价于 \x09 和 \cI。 |
\v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
需要记住:
\r \n \t,\s \S
特殊字符是一些有特殊含义的字符。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特殊字符 | 描述 |
|---|---|
( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
. | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
[ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
\ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符, \\ 匹配 \,而 \( 则匹配 ( 。 |
{ | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| ` | ` |
\d | 匹配一个数字字符。等价于 [0-9]。 |
[0-9] | 匹配任何数字。等价于 \d |
\D | 匹配一个非数字字符。等价于 [^0-9]。 |
[a-z] | 匹配任何小写字母 |
[A-Z] | 匹配任何大写字母 |
[a-zA-Z0-9] | 匹配任何字母及数字。等价于\w |
\w | 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_]。 |
\W(大写W) | 匹配任何非单词字符。等价于 [^A-Za-z0-9_]。 |
[\u4e00-\u9fa5] | 匹配纯中文 |
需要记住:
\d,\D,\w,\W
定位符能够将正则表达式固定到行首或行尾。它们还能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 特殊字符 | 描述 |
|---|---|
^ | 匹配输入字符串的开始位置,例如:^h匹配以h开头;在方括号表达式中时,它表示不接受该字符集合,例如[^0-9]匹配除了数字以外的数据。要匹配 ^ 字符本身,请使用 \^。 |
$ | 匹配输入字符串的结尾位置。要匹配 $ 字符本身,请使用 \$。 |
\b | 匹配一个单词边界,即字与空格间的位置。 |
\B | 非单词边界匹配。 |
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 ***** 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
* | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 z 以及 zoo。 等价于{0,}。 |
+ | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 zo 以及 zoo,但不能匹配 z。+ 等价于 {1,}。 |
? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 do 、 does 中的 does 、 doxy 中的 do 。? 等价于 {0,1}。 |
{n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 Bob 中的 o,但是能匹配 food 中的两个 o。 |
{n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 Bob 中的 o,但能匹配 foooood 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
{n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。请注意在逗号和两个数之间不能有空格。 |
示例:
import rere.search(r'\s', '大家好 我是 代码') # 匹配所有的空字符
re.search(r'\S', '大家') # 匹配所有的非空字符
re.search(r'\n', '大家好\n我是代码') # 匹配换行
re.search(r'n$', 'hello python') # 匹配以 n 结尾
re.search(r'^h.+n$', 'hello python') # 匹配以 h 开头,中间出现一次或多次任意字符,并且以n结尾
re.search(r'^ha*', 'h') # 匹配以 h 开头,a出现0次或者一次
8.正则表达式匹配练习
Q1:用户名匹配:由数字、大小写字母、下划线
_和中横线-组成,长度为4到14位,并且不能以数字开头。
import redef check_username(username):pattern = r'^[a-zA-Z_][a-zA-Z0-9_-]{3,13}$'match = re.match(pattern, username)if match:return Trueelse:return False# 测试用户名
usernames = ["user_123", "User-Name", "123abc", "_username", "user-name", "user_name_longer_than_14"]
for username in usernames:if check_username(username):print(f"{username}: 匹配")else:print(f"{username}: 不匹配")正则表达式模式解释:
^:匹配字符串的开头[a-zA-Z_]:匹配一个字母、下划线或中横线(不能以数字开头)[a-zA-Z0-9_-]{3,13}:匹配3到13个数字、大小写字母、下划线或中横线$:匹配字符串的结尾
Q2:匹配邮箱
import redef check_email(email):pattern = r'^[\w\.-]+@[\w\.-]+\.\w+$'match = re.match(pattern, email)if match:return Trueelse:return False# 测试邮箱地址
emails = ["john.doe@example.com", "jane_123@gmail.com", "invalid_email", "user@example", "admin@domain"]
for email in emails:if check_email(email):print(f"{email}: 匹配")else:print(f"{email}: 不匹配")正则表达式模式解释:
^:匹配字符串的开头[\w\.-]+:匹配一个或多个字母、数字、下划线、点号或中横线(邮箱用户名部分)@:匹配邮箱地址中的@[\w\.-]+:匹配一个或多个字母、数字、下划线、点号或中横线(邮箱域名部分)\.:匹配邮箱地址中的点号\w+:匹配一个或多个字母、数字或下划线(邮箱域名后缀)$:匹配字符串的结尾
Q3:匹配手机号
import redef check_phone_number(phone_number):pattern = r'^1[3-9]\d{9}$'match = re.match(pattern, phone_number)if match:return Trueelse:return False# 测试手机号码
phone_numbers = ["13812345678", "15567891234", "12345678901", "189abcd1234", "01234567890"]
for phone_number in phone_numbers:if check_phone_number(phone_number):print(f"{phone_number}: 匹配")else:print(f"{phone_number}: 不匹配")正则表达式模式解释:
^:匹配字符串的开头1:匹配手机号码的开头必须是1[3456789]:匹配3、4、5、6、7、8、9中的一个数字\d{9}:匹配9个数字(手机号码的剩余部分)$:匹配字符串的结尾
Q4:匹配身份证号。
import redef check_id_card(id_card):pattern = r'^[1-9]\d{16}(\d|X|x)$'match = re.match(pattern, id_card)if match:return Trueelse:return False# 测试身份证号码
id_cards = ["110101199003077934", "310110198706152518", "12345678901234567X", "123456789012345678", "A1234567890123456"]
for id_card in id_cards:if check_id_card(id_card):print(f"{id_card}: 匹配")else:print(f"{id_card}: 不匹配")正则表达式模式解释:
^:匹配字符串的开头[1-9]:匹配1到9中的一个数字(身份证号码的开头不能为0)\d{16}:匹配16个数字(身份证号码的剩余部分)(\d|X|x):匹配一个数字或字母X(身份证号码的最后一位校验位)$:匹配字符串的结尾
Q5:匹配URL地址
import redef check_url(url):pattern = r'^(http|https)://[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/?(\S+)?$'match = re.match(pattern, url)if match:return Trueelse:return False# 测试URL地址
urls = ["http://www.example.com", "https://www.example.com/path", "ftp://www.example.com", "www.example.com","http://example", "https://123.456.789"]
for url in urls:if check_url(url):print(f"{url}: 匹配")else:print(f"{url}: 不匹配")正则表达式模式解释:
^:匹配字符串的开头(http|https):匹配http或https://:匹配://[a-zA-Z0-9.-]+:匹配一个或多个字母、数字、点号或中横线(域名部分)\.[a-zA-Z]{2,}:匹配一个点号后面跟着两个或更多字母(域名后缀部分)/?(\S+)?:匹配可选的斜杠后面跟着一个或多个非空字符(路径部分)$:匹配字符串的结尾
9.正则替换
re.sub() 是 Python 中用于替换字符串中的匹配项的函数。它使用正则表达式来查找匹配项,并使用提供的替换字符串来替换它们。re.sub() 函数的语法如下:
re.sub(pattern, repl, string, count=0, flags=0)
参数说明:
pattern:要匹配的正则表达式模式。repl:用于替换匹配项的字符串或替换函数。string:要进行替换的原始字符串。count:可选参数,指定替换的最大次数。默认为 0,表示替换所有匹配项。flags:可选参数,用于控制正则表达式的匹配方式,如re.IGNORECASE(忽略大小写匹配)等。
re.sub() 函数的工作流程如下:
- 在原始字符串
string中查找与正则表达式模式pattern匹配的部分。 - 对于每一个匹配项,将其替换为
repl字符串或替换函数的结果。 - 返回替换后的字符串。
替换字符串中的匹配项
import retext = "Hello, World!"
new_text = re.sub(r"Hello", "Hi", text)print(new_text) # Output: Hi, World!
换字符串中的多个匹配项
import retext = "Hello, Hello, Hello!"
new_text = re.sub(r"Hello", "Hi", text)print(new_text) # Output: Hi, Hi, Hi!
使用替换函数
import redef to_uppercase(match):return match.group().upper()text = "hello, world!"
new_text = re.sub(r"\b\w+\b", to_uppercase, text)print(new_text) # Output: HELLO, WORLD!
10.贪婪模式和非贪婪模式
贪婪模式和非贪婪模式是用于匹配字符串时的两种不同行为。它们涉及到量词(quantifier)的使用,量词用于指定匹配模式中重复出现的次数。
贪婪模式(Greedy Mode):
贪婪模式是正则表达式的默认行为,它会尽可能多地匹配字符串。当使用贪婪模式时,量词会匹配尽可能多的字符。例如,正则表达式 a.*b 匹配的是从第一个 a 到最后一个 b 之间的所有字符,尽管可能有多个 a 和多个 b 存在。
非贪婪模式(Non-Greedy Mode):
非贪婪模式使用 ? 后缀来指示量词变为非贪婪模式。它会尽可能少地匹配字符串。当使用非贪婪模式时,量词会匹配尽可能少的字符。例如,正则表达式 a.*?b 匹配的是从第一个 a 到最近的 b 之间的字符,只取最短的匹配结果。
下面通过示例来说明贪婪模式和非贪婪模式的区别:
import repattern = r'<.*>'
text = '<a> <b> <c>'result = re.match(pattern, text)
print(result.group()) # <a> <b> <c>
输出结果为<a> <b> <c>。在这个例子中,正则表达式<.*>使用了贪婪模式,它尝试匹配从第一个<到最后一个>之间的所有字符,包括多个标签。
在Python正则表达式中,可以使用?符号来表示非贪婪模式。
import repattern = r'<.*?>'
text = '<a> <b> <c>'result = re.match(pattern, text)
print(result.group()) # <a>
这个正则表达式<.*?>使用了非贪婪模式,?表示在*后面加上?表示非贪婪匹配。非贪婪模式尽量匹配最短的可能字符串,所以它只匹配到了第一个>之前的字符。
相关文章:

Python11-正则表达式
Python11-正则表达式 1.正则表达式简介2.正则表达式常见用法和符号3.正则查找4.re.Match对象与group5.re.compile6.正则表达式修饰符7.正则匹配规则8.正则表达式匹配练习9.正则替换10.贪婪模式和非贪婪模式 1.正则表达式简介 正则表达式(Regular Expression&#x…...
【机器学习】XGBoost
1.什么是XGBoost XGBoost(eXtreme Gradient Boosting)极度梯度提升树,属于集成学习中的boosting框架算法。对于提升树,简单说就是一个模型表现不好,继续按照原来模型表现不好的那部分训练第二个模型,依次类推。本质思想与GBDT一致…...
如何复制禁止复制的内容
今天找到一段代码,但是复制时页面提示“这个是VIP会员才有的权限”。我该怎么复制呢。 现在的平台大都是用钱说话,以便响应知识付费的主张。对错我就不说了,我认为既然我有权利看到代码,当然也有权把他复制下来。这并不涉及侵权。…...
多通道图片的卷积过程
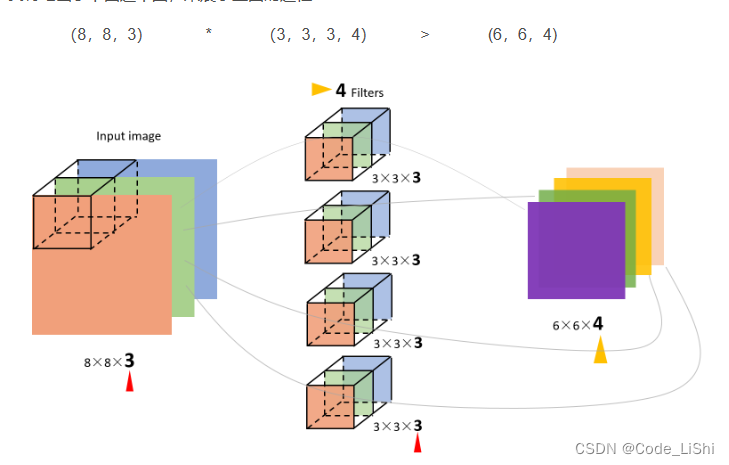
多通道(channels)图片的卷积 如果输入图片是三维的(三个channel),例如(8,8,3),那么每一个filter的维度就是(3,3,3&#x…...

uniapp canvas 无法获取 webgl context 的问题解决
uniapp canvas 无法获取 webgl context 的问题解决 一、问题描述 在 uniapp 中做一个查看监控视频的页面,用到的是 JSMpeg 这个库,原理就是前后台通过 websocket 不断推送新画面内容到前端,前端通过这个 JSMpeg 渲染到前端页面中指定的 can…...

Spring底层原理(二)
Spring底层原理(二) BeanFactory的实现 //创建BeanFactory对象 DefaultListableBeanFactory factory new DefaultListableBeanFactory(); //注册Bean定义对象 AbstractBeanDefinition beanDefinition BeanDefinitionBuilder.genericBeanDefinition(SpringConfig.class).set…...
springboot188基于spring boot的校园商铺管理系统
项目名称:springboot188基于spring boot的校园商铺管理系统 点击这里进入源码目录 声明: 适用范围: 本文档适用于广泛的学术和教育用途,包括但不限于个人学习、毕业设计和课程设计。免责声明: 特此声明,本…...
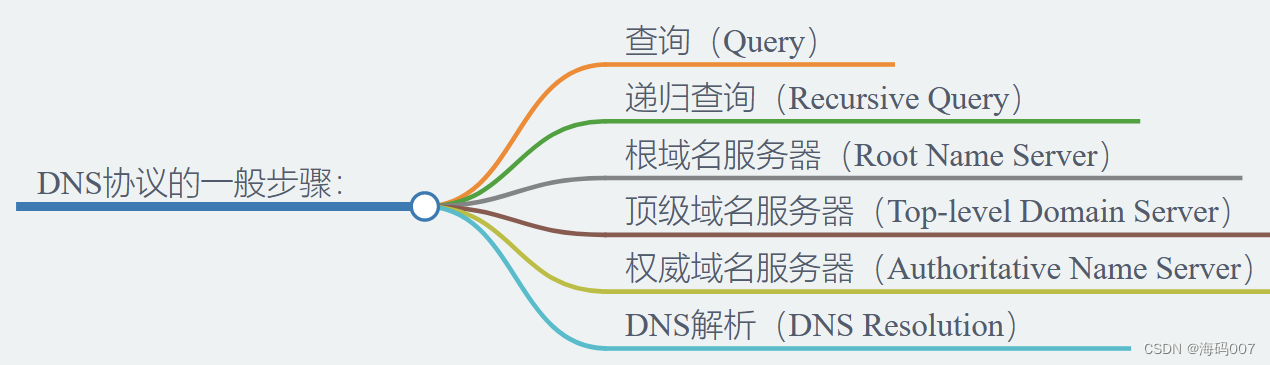
【计网 DNS】计算机网络 DNS协议详解:中科大郑烇老师笔记 (六)
目录 0 引言1 DNS概述1.1 定义1.2 DNS域名结构1.2 域名解析步骤 🙋♂️ 作者:海码007📜 专栏:计算机四大基础专栏📜 其他章节:网络快速入门系列、计网概述、计网应用层详解、计网Web和HTTP、计网FTP、计网…...

vue 生命周期钩子函数 mounted()实例
在挂载后操作dom获取焦点。 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"w…...
数据分享 I 地级市人口和土地使用面积基本情况
数据地址: 地级市人口和土地使用面积基本情况https://www.xcitybox.com/datamarketview/#/Productpage?id394 基本信息. 数据名称: 地级市人口和土地使用面积基本情况 数据格式: ShpExcel 数据时间: 2021年 数据几何类型: 面 数据坐标系: WGS84坐标系 数据…...
被邀请为期刊审稿时,如何做一个合格的审稿人?官方版本教程来喽
审稿是学术研究中非常重要的环节,它可以确保研究的科学性和严谨性。审稿人的任务是检查文章是否符合学术规范,是否具有创新性,是否具有科学价值,以及是否符合期刊的定位和风格。因此,审稿人需要具有扎实的学术背景和丰…...
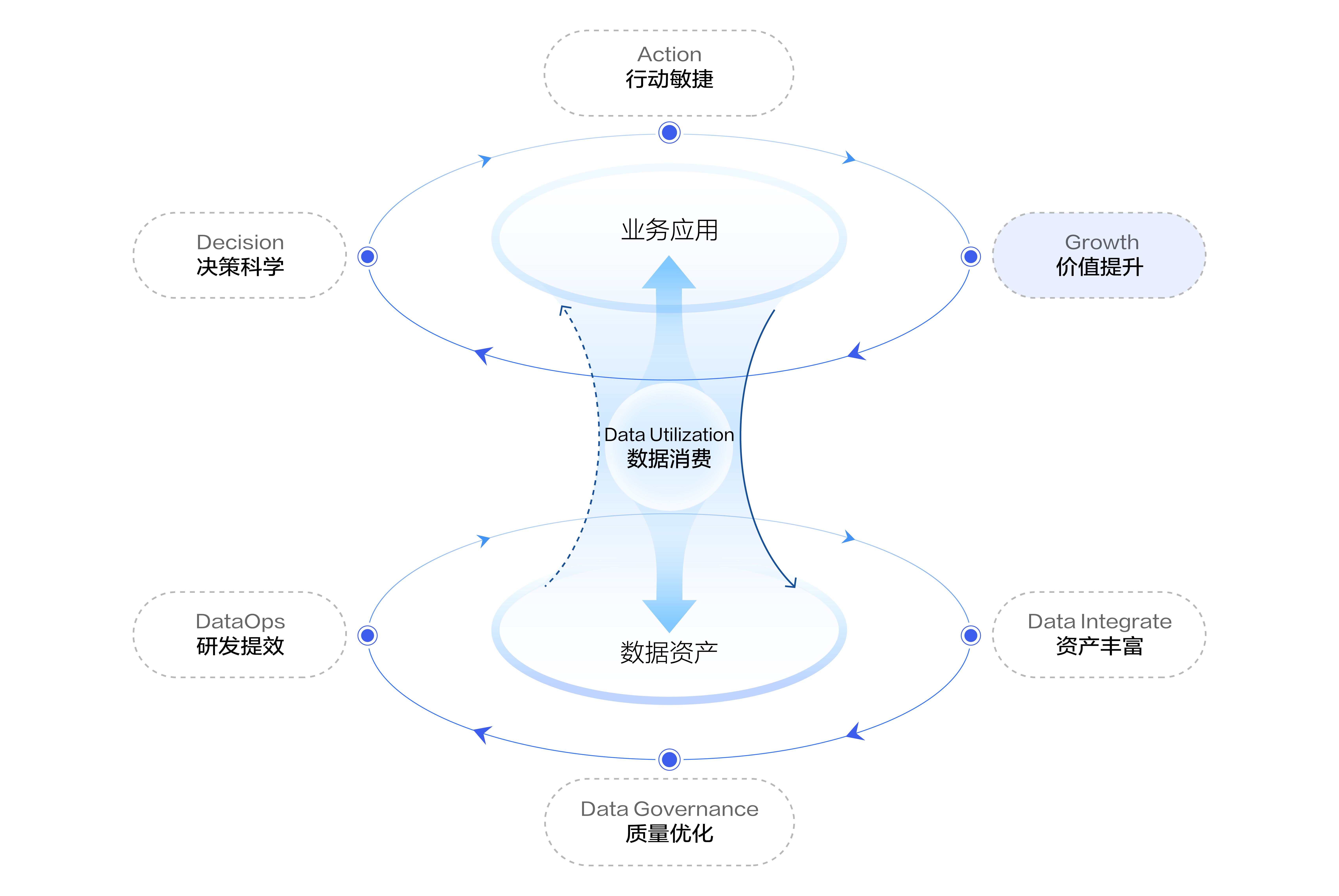
数据飞轮拆解车企数据驱动三板斧:数据分析、市场画像、A/B 实验
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 近日,火山引擎数智平台(VeDI)2023 数据飞轮汽车行业研讨会在上海举办,活动聚焦汽车行业数字化转型痛点,从…...

基于PyQt5和OpenCV库的简单的文档对齐扫描应用程序
计算机视觉-作业1 作业要求简介说明 安装运行功能使用待完善代码相关 作业要求 拍一张A4纸文稿的图片,利用角点检测、边缘检测等,再通过投影变换完成对文档的对齐扫描 简介 使用python语言,基于PyQt5和OpenCV库的简单的文档对齐扫描应用程…...
)
【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇)
构建pytorch训练模型读取的数据,是有模版可以参考的,是有套路的,这点相信使用过的人都知道。我也会给出一个套路的模版,方便学习和查询。 同时,也可以先去参考学习之前的一篇较为简单的3D分类任务的数据构建方法,链接在这里:【3D图像分类】基于Pytorch的3D立体图像分类…...
HDR图像处理软件 Photomatix Pro mac中文版新增功能
Photomatix Pro mac是一款专业的HDR合成软件,可以将不同曝光的多张照片合成为一张照片,而保留更多的细节。并且合成时可以帮助去除照片中的鬼影。Photomatix Pro提供两种类型的过程来增加动态范围,一个过程称为HDR色调映射,另一个…...

【Kotlin精简】第5章 简析DSL
1 DSL是什么? Kotlin 是一门对 DSL 友好的语言,它的许多语法特性有助于 DSL 的打造,提升特定场景下代码的可读性和安全性。本文将带你了解 Kotlin DSL 的一般实现步骤,以及如何通过 DslMarker , Context Receivers 等…...

2021年06月 Python(一级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python编程(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 下列程序运行的结果是? s hello print(sworld)A: sworld B: helloworld C: hello D: world 答案:…...

MySQL执行计划分析
执行计划中的常见的列的解释: type system/const :用户主键索引或者唯一索引查询时,只能匹配 1 条数据。一般可以对 sql 查询语句优化成一个常量,那么 type 一般就是 system 或者 const,system 是 const 的一个特例&…...

【数据结构与算法】Snowflake雪花算法Java实现
Snowflake产生的ID由 64 bit 的二进制数字组成,被分成了4个部分,每一部分存储的数据都有特定的含义: 第 0 位: 符号位(标识正负),始终为 0;第 1~41 位 :一共 41 位&…...
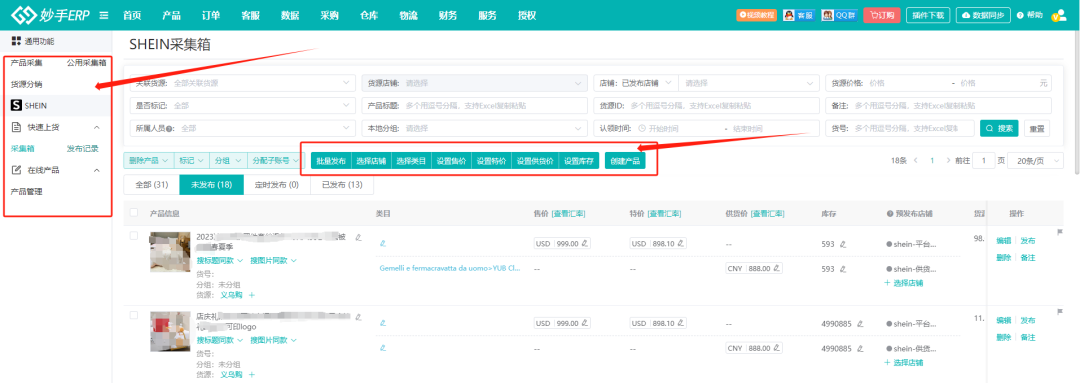
重要功能更新:妙手正式接入SHEIN供货模式(OBM)店铺,赋能卖家把握出海新机遇!
继接入SHEIN平台模式店铺之后,妙手ERP积极响应卖家需求,正式接入SHEIN供货模式(OBM)店铺,并支持产品采集、批量刊登、产品管理等功能,帮助跨境卖家快速上品、高效运营,把握出海新机遇。 SHEIN供…...

Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告
Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告 1. 项目背景与价值 在零售与餐饮行业,市场调研数据的采集和分析一直是一项耗时耗力的工作。传统方法需要人工记录货架商品、价格标签、店铺环境等信息,不仅效率低下,还容…...

笔记汇总目录 需要可自行跳转查看
笔记汇总目录 UEFI Windows10VS2019 EDKII环境搭建UEFI常用文档&学习资料合集保姆级教程的HelloWold ApplicationHandle & Protocol 你想知道的都在这UEFI 基础服务protocol服务详解Event详解UEFI Package & ModulePCIe子系统(I) PCIe基础知识PCIe子系统(II) Hos…...

Youtu-VL-4B-Instruct快速上手:3个命令启动服务、5个API调用示例、10分钟掌握核心能力
Youtu-VL-4B-Instruct快速上手:3个命令启动服务、5个API调用示例、10分钟掌握核心能力 你是不是经常遇到这样的场景:拿到一张复杂的图表,想快速提取里面的数据;或者看到一张产品图,想知道里面有哪些东西、分别在哪里&…...

balance_callbacks及cpu offline的相关细节
一、背景 之前的博客 cpu的possible present online active的mask细节 和 cpu hotplug的调用链整理 里,我们讲述了cpu online的状态及相关细节,cpu online和offline的状态,其实就是镜像地的逻辑,这篇博客里我们讲述__schedule函数,如下图里的__balance_callbacks的相关细…...

Targets.vim多文本对象深度探索:any block和any quote的灵活运用
Targets.vim多文本对象深度探索:any block和any quote的灵活运用 【免费下载链接】targets.vim Vim plugin that provides additional text objects 项目地址: https://gitcode.com/gh_mirrors/ta/targets.vim Targets.vim是一款强大的Vim插件,提…...

QML Material项目实战:从零构建一个完整的Material Design应用
QML Material项目实战:从零构建一个完整的Material Design应用 【免费下载链接】qml-material qml-material - 一个在 QtQuick 中实现 Google 材料设计(Material Design)的 QML 部件库,支持跨平台运行。 项目地址: https://gitc…...

Z-Image-Turbo_Sugar脸部Lora入门必看:从Xinference启动到Gradio出图完整流程
Z-Image-Turbo_Sugar脸部Lora入门必看:从Xinference启动到Gradio出图完整流程 想快速生成甜美风格的人物脸部图片?Z-Image-Turbo_Sugar脸部Lora模型专门为此而生,让你轻松创作出纯欲甜妹风格的头像作品。 1. 环境准备与快速启动 1.1 了解你的…...

DeepSeek-OCR-2开源可部署:完全离线运行的国产OCR大模型方案
DeepSeek-OCR-2开源可部署:完全离线运行的国产OCR大模型方案 1. 项目简介 DeepSeek-OCR-2是DeepSeek团队于2026年1月发布的创新OCR识别模型,采用完全开源的方式提供给开发者使用。这个模型最大的特点是实现了完全离线运行,不需要依赖任何外…...

WPS JS宏利用Fetch API实现网页数据抓取与Excel自动化处理
1. 为什么需要网页数据抓取与Excel自动化 在日常办公中,我们经常需要从各种网站获取数据并整理到Excel表格中。比如市场人员需要抓取竞品价格、财务人员需要获取汇率数据、运营人员需要统计社交媒体互动情况。传统做法是手动复制粘贴,不仅效率低下&#…...

单片机核心功能解析与实战技巧
1. 单片机学习的核心功能解析作为一名在嵌入式领域摸爬滚打多年的工程师,我深知单片机学习的关键不在于死记硬背,而在于掌握几个核心功能的底层逻辑和应用场景。很多初学者容易陷入"学了很多却不会用"的困境,根本原因就是没有抓住这…...